 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Generalized Unfolding Networks for Image Restoration
Apr 28, 2022
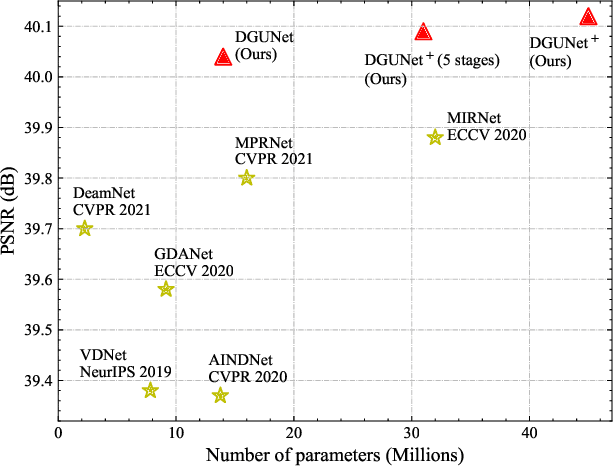
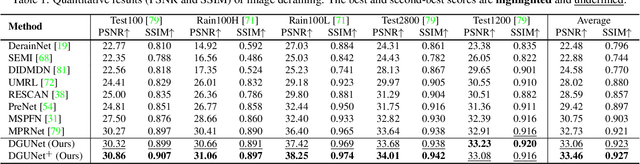
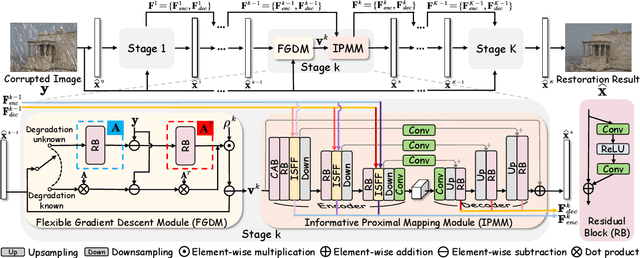
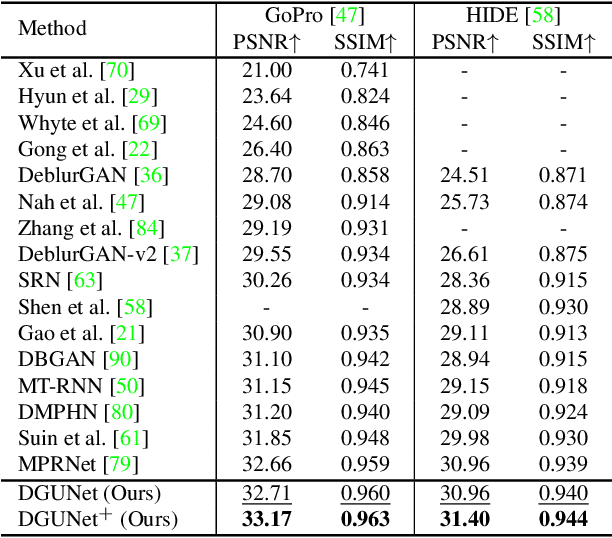
Deep neural networks (DNN) have achieved great success in image restoration. However, most DNN methods are designed as a black box, lacking transparency and interpretability. Although some methods are proposed to combine traditional optimization algorithms with DNN, they usually demand pre-defined degradation processes or handcrafted assumptions, making it difficult to deal with complex and real-world applications. In this paper, we propose a Deep Generalized Unfolding Network (DGUNet) for image restoration. Concretely, without loss of interpretability, we integrate a gradient estimation strategy into the gradient descent step of the Proximal Gradient Descent (PGD) algorithm, driving it to deal with complex and real-world image degradation. In addition, we design inter-stage information pathways across proximal mapping in different PGD iterations to rectify the intrinsic information loss in most deep unfolding networks (DUN) through a multi-scale and spatial-adaptive way. By integrating the flexible gradient descent and informative proximal mapping, we unfold the iterative PGD algorithm into a trainable DNN. Extensive experiments on various image restoration tasks demonstrate the superiority of our method in terms of state-of-the-art performance, interpretability, and generalizability. The source code is available at https://github.com/MC-E/Deep-Generalized-Unfolding-Networks-for-Image-Restoration.
Is one annotation enough? A data-centric image classification benchmark for noisy and ambiguous label estimation
Jul 13, 2022
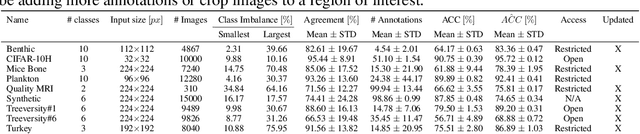
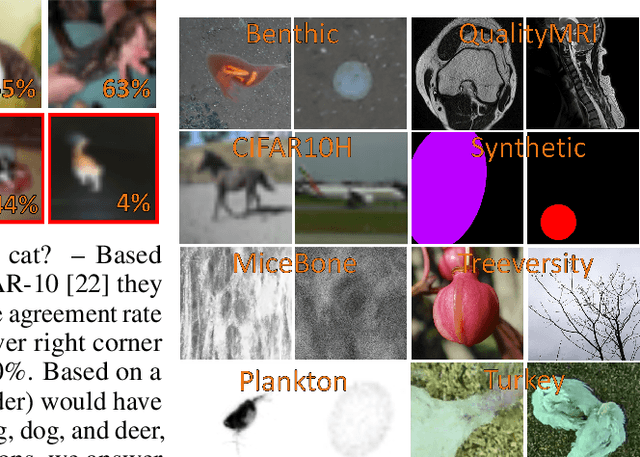
High-quality data is necessary for modern machine learning. However, the acquisition of such data is difficult due to noisy and ambiguous annotations of humans. The aggregation of such annotations to determine the label of an image leads to a lower data quality. We propose a data-centric image classification benchmark with nine real-world datasets and multiple annotations per image to investigate and quantify the impact of such data quality issues. We focus on a data-centric perspective by asking how we could improve the data quality. Across thousands of experiments, we show that multiple annotations allow a better approximation of the real underlying class distribution. We identify that hard labels can not capture the ambiguity of the data and this might lead to the common issue of overconfident models. Based on the presented datasets, benchmark baselines, and analysis, we create multiple research opportunities for the future.
1st Place Solutions for UG2+ Challenge 2022 ATMOSPHERIC TURBULENCE MITIGATION
Oct 30, 2022

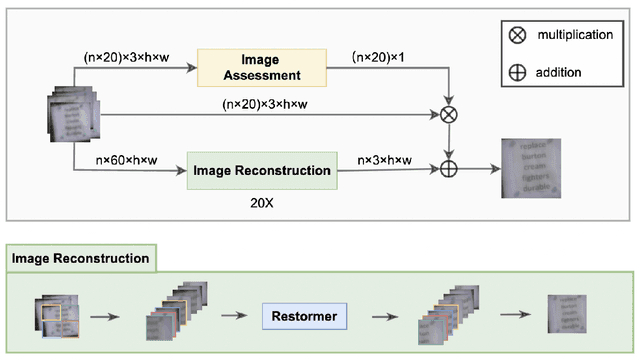

In this technical report, we briefly introduce the solution of our team ''summer'' for Atomospheric Turbulence Mitigation in UG$^2$+ Challenge in CVPR 2022. In this task, we propose a unified end-to-end framework to reconstruct a high quality image from distorted frames, which is mainly consists of a Restormer-based image reconstruction module and a NIMA-based image quality assessment module. Our framework is efficient and generic, which is adapted to both hot-air image and text pattern. Moreover, we elaborately synthesize more than 10 thousands of images to simulate atmospheric turbulence. And these images improve the robustness of the model. Finally, we achieve the average accuracy of 98.53\% on the reconstruction result of the text patterns, ranking 1st on the final leaderboard.
Low-Complexity Loeffler DCT Approximations for Image and Video Coding
Jul 29, 2022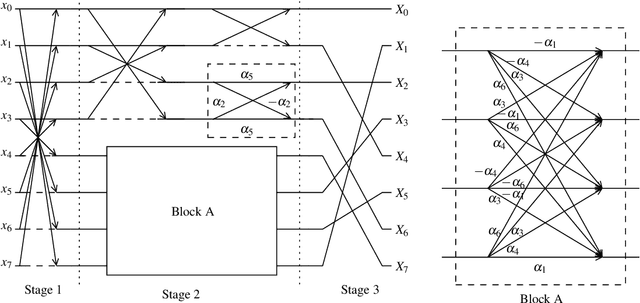
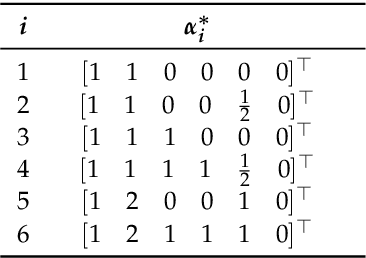

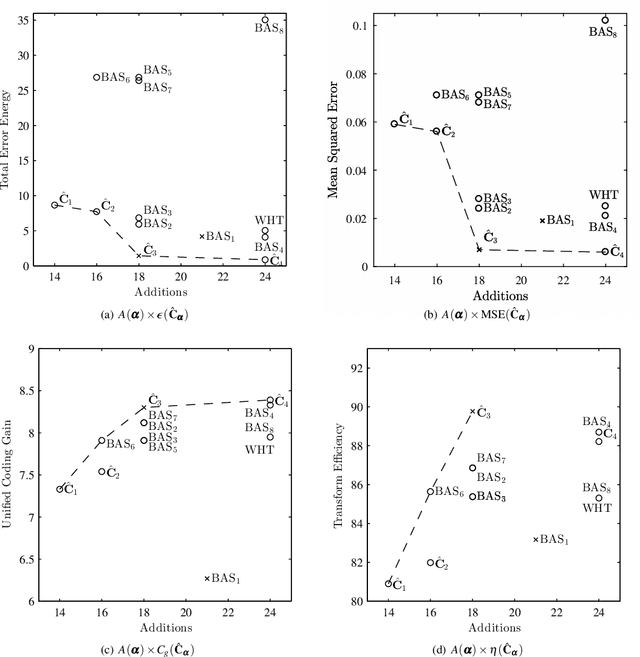
This paper introduced a matrix parametrization method based on the Loeffler discrete cosine transform (DCT) algorithm. As a result, a new class of eight-point DCT approximations was proposed, capable of unifying the mathematical formalism of several eight-point DCT approximations archived in the literature. Pareto-efficient DCT approximations are obtained through multicriteria optimization, where computational complexity, proximity, and coding performance are considered. Efficient approximations and their scaled 16- and 32-point versions are embedded into image and video encoders, including a JPEG-like codec and H.264/AVC and H.265/HEVC standards. Results are compared to the unmodified standard codecs. Efficient approximations are mapped and implemented on a Xilinx VLX240T FPGA and evaluated for area, speed, and power consumption.
* 25 pages, 11 figures, 7 tables
Exploiting Category Names for Few-Shot Classification with Vision-Language Models
Dec 04, 2022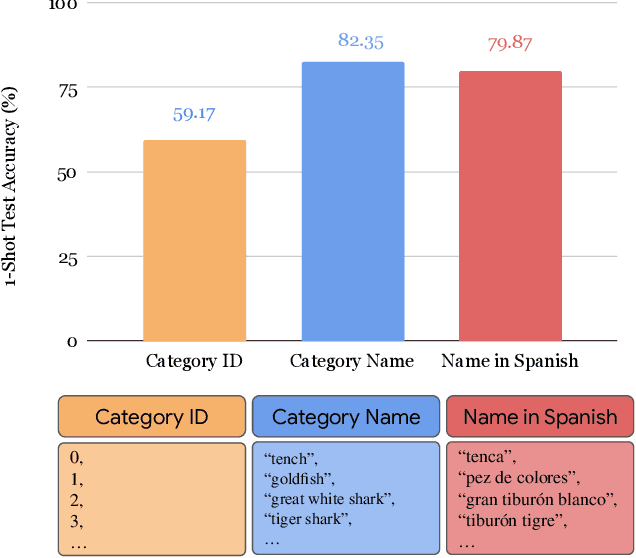
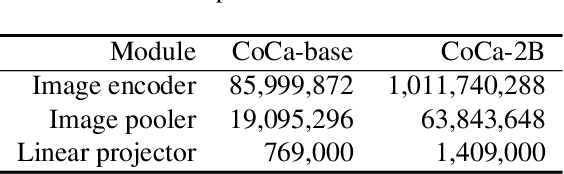
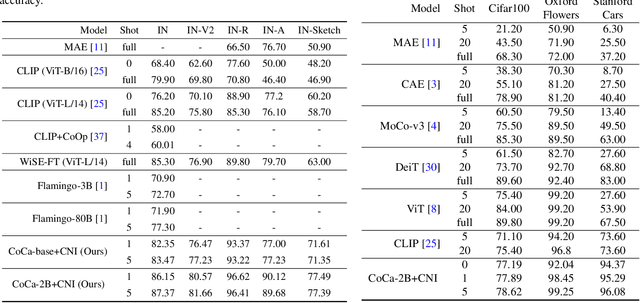
Vision-language foundation models pretrained on large-scale data provide a powerful tool for many visual understanding tasks. Notably, many vision-language models build two encoders (visual and textual) that can map two modalities into the same embedding space. As a result, the learned representations achieve good zero-shot performance on tasks like image classification. However, when there are only a few examples per category, the potential of large vision-language models is often underperformed, mainly due to the gap between a large number of parameters and a relatively small amount of training data. This paper shows that we can significantly improve the performance of few-shot classification by using the category names to initialize the classification head. More interestingly, we can borrow the non-perfect category names, or even names from a foreign language, to improve the few-shot classification performance compared with random initialization. With the proposed category name initialization method, our model obtains the state-of-the-art performance on a number of few-shot image classification benchmarks (e.g., 87.37\% on ImageNet and 96.08\% on Stanford Cars, both using five-shot learning). We also investigate and analyze when the benefit of category names diminishes and how to use distillation to improve the performance of smaller models, providing guidance for future research.
IRISformer: Dense Vision Transformers for Single-Image Inverse Rendering in Indoor Scenes
Jun 16, 2022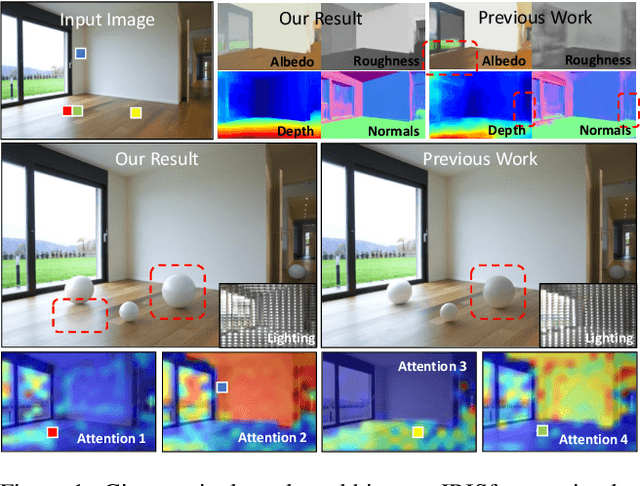
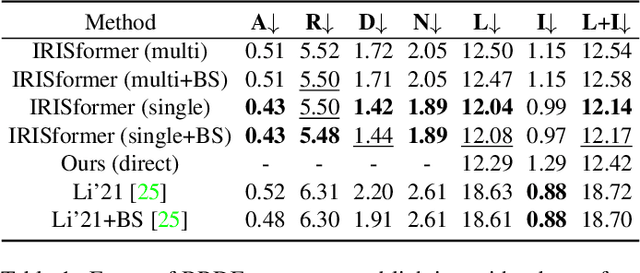

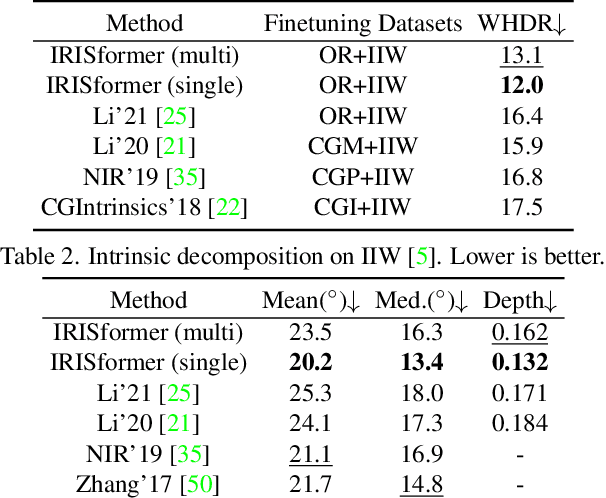
Indoor scenes exhibit significant appearance variations due to myriad interactions between arbitrarily diverse object shapes, spatially-changing materials, and complex lighting. Shadows, highlights, and inter-reflections caused by visible and invisible light sources require reasoning about long-range interactions for inverse rendering, which seeks to recover the components of image formation, namely, shape, material, and lighting. In this work, our intuition is that the long-range attention learned by transformer architectures is ideally suited to solve longstanding challenges in single-image inverse rendering. We demonstrate with a specific instantiation of a dense vision transformer, IRISformer, that excels at both single-task and multi-task reasoning required for inverse rendering. Specifically, we propose a transformer architecture to simultaneously estimate depths, normals, spatially-varying albedo, roughness and lighting from a single image of an indoor scene. Our extensive evaluations on benchmark datasets demonstrate state-of-the-art results on each of the above tasks, enabling applications like object insertion and material editing in a single unconstrained real image, with greater photorealism than prior works. Code and data are publicly released at https://github.com/ViLab-UCSD/IRISformer.
Spatially Multi-conditional Image Generation
Mar 25, 2022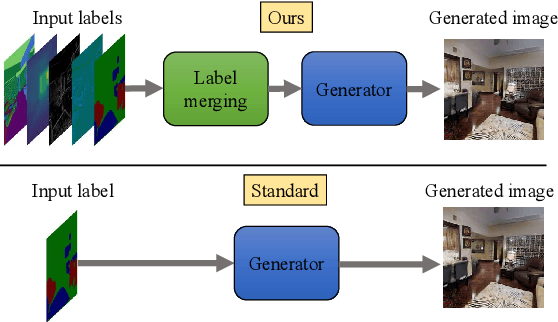

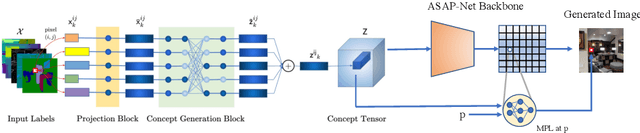
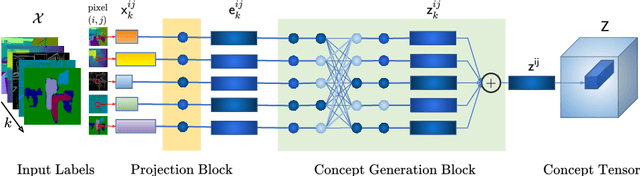
In most scenarios, conditional image generation can be thought of as an inversion of the image understanding process. Since generic image understanding involves the solving of multiple tasks, it is natural to aim at the generation of images via multi-conditioning. However, multi-conditional image generation is a very challenging problem due to the heterogeneity and the sparsity of the (in practice) available conditioning labels. In this work, we propose a novel neural architecture to address the problem of heterogeneity and sparsity of the spatially multi-conditional labels. Our choice of spatial conditioning, such as by semantics and depth, is driven by the promise it holds for better control of the image generation process. The proposed method uses a transformer-like architecture operating pixel-wise, which receives the available labels as input tokens to merge them in a learned homogeneous space of labels. The merged labels are then used for image generation via conditional generative adversarial training. In this process, the sparsity of the labels is handled by simply dropping the input tokens corresponding to the missing labels at the desired locations, thanks to the proposed pixel-wise operating architecture. Our experiments on three benchmark datasets demonstrate the clear superiority of our method over the state-of-the-art and the compared baselines.
Cardiac Adipose Tissue Segmentation via Image-Level Annotations
Jun 09, 2022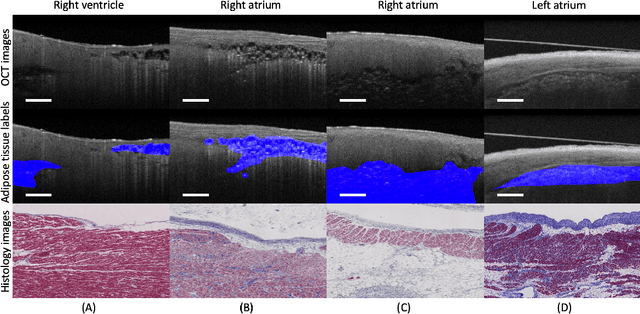
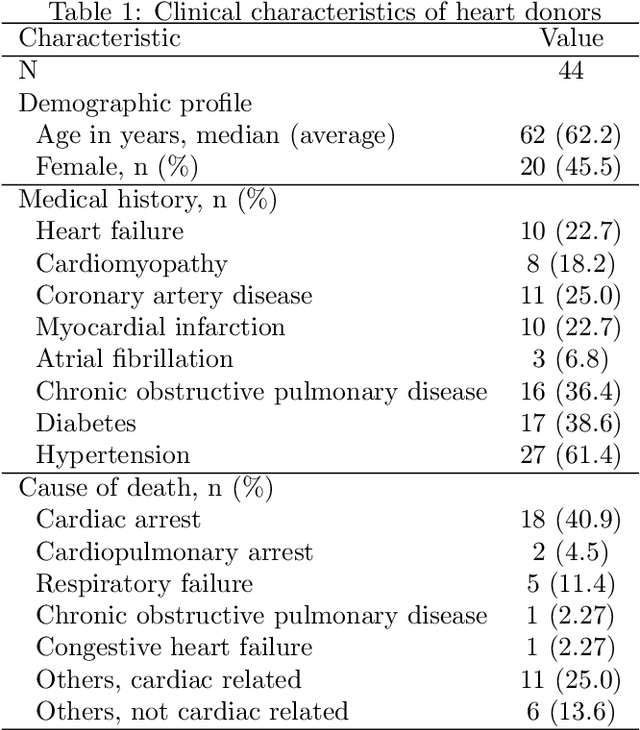
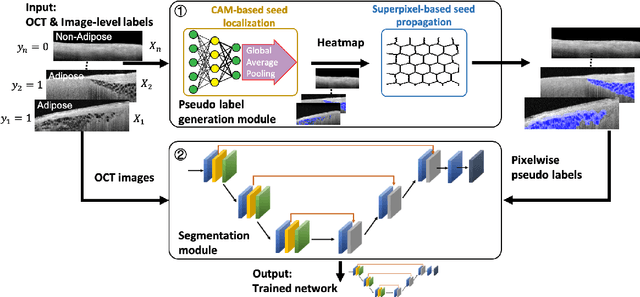

Automatically identifying the structural substrates underlying cardiac abnormalities can potentially provide real-time guidance for interventional procedures. With the knowledge of cardiac tissue substrates, the treatment of complex arrhythmias such as atrial fibrillation and ventricular tachycardia can be further optimized by detecting arrhythmia substrates to target for treatment (i.e., adipose) and identifying critical structures to avoid. Optical coherence tomography (OCT) is a real-time imaging modality that aids in addressing this need. Existing approaches for cardiac image analysis mainly rely on fully supervised learning techniques, which suffer from the drawback of workload on labor-intensive annotation process of pixel-wise labeling. To lessen the need for pixel-wise labeling, we develop a two-stage deep learning framework for cardiac adipose tissue segmentation using image-level annotations on OCT images of human cardiac substrates. In particular, we integrate class activation mapping with superpixel segmentation to solve the sparse tissue seed challenge raised in cardiac tissue segmentation. Our study bridges the gap between the demand on automatic tissue analysis and the lack of high-quality pixel-wise annotations. To the best of our knowledge, this is the first study that attempts to address cardiac tissue segmentation on OCT images via weakly supervised learning techniques. Within an in-vitro human cardiac OCT dataset, we demonstrate that our weakly supervised approach on image-level annotations achieves comparable performance as fully supervised methods trained on pixel-wise annotations.
SSGVS: Semantic Scene Graph-to-Video Synthesis
Nov 17, 2022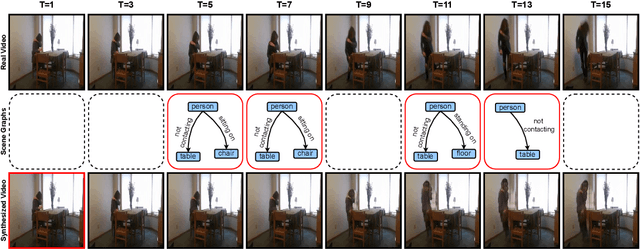

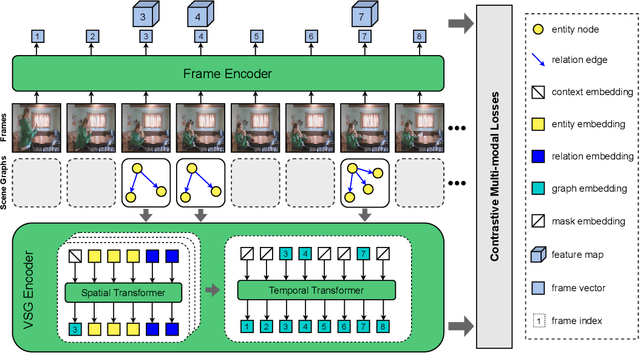

As a natural extension of the image synthesis task, video synthesis has attracted a lot of interest recently. Many image synthesis works utilize class labels or text as guidance. However, neither labels nor text can provide explicit temporal guidance, such as when an action starts or ends. To overcome this limitation, we introduce semantic video scene graphs as input for video synthesis, as they represent the spatial and temporal relationships between objects in the scene. Since video scene graphs are usually temporally discrete annotations, we propose a video scene graph (VSG) encoder that not only encodes the existing video scene graphs but also predicts the graph representations for unlabeled frames. The VSG encoder is pre-trained with different contrastive multi-modal losses. A semantic scene graph-to-video synthesis framework (SSGVS), based on the pre-trained VSG encoder, VQ-VAE, and auto-regressive Transformer, is proposed to synthesize a video given an initial scene image and a non-fixed number of semantic scene graphs. We evaluate SSGVS and other state-of-the-art video synthesis models on the Action Genome dataset and demonstrate the positive significance of video scene graphs in video synthesis. The source code will be released.
HOReeNet: 3D-aware Hand-Object Grasping Reenactment
Nov 11, 2022
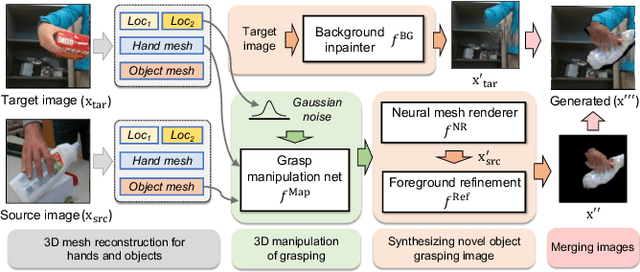

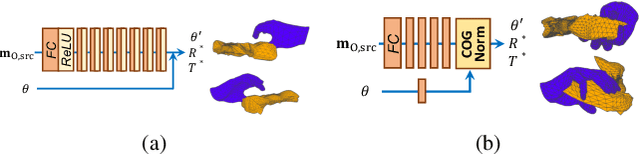
We present HOReeNet, which tackles the novel task of manipulating images involving hands, objects, and their interactions. Especially, we are interested in transferring objects of source images to target images and manipulating 3D hand postures to tightly grasp the transferred objects. Furthermore, the manipulation needs to be reflected in the 2D image space. In our reenactment scenario involving hand-object interactions, 3D reconstruction becomes essential as 3D contact reasoning between hands and objects is required to achieve a tight grasp. At the same time, to obtain high-quality 2D images from 3D space, well-designed 3D-to-2D projection and image refinement are required. Our HOReeNet is the first fully differentiable framework proposed for such a task. On hand-object interaction datasets, we compared our HOReeNet to the conventional image translation algorithms and reenactment algorithm. We demonstrated that our approach could achieved the state-of-the-art on the proposed task.