 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Rawgment: Noise-Accounted RAW Augmentation Enables Recognition in a Wide Variety of Environments
Oct 28, 2022
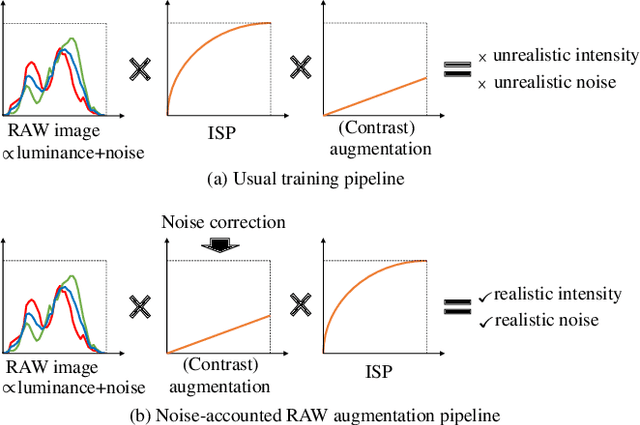
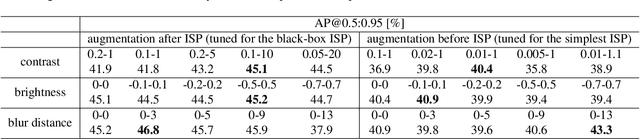
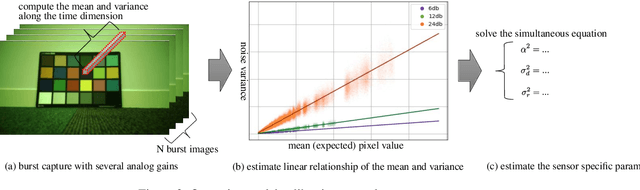
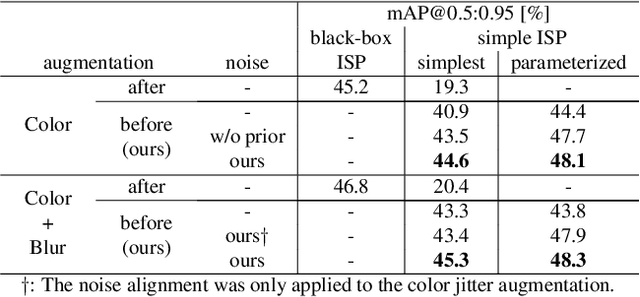
Image recognition models that can work in challenging environments (e.g., extremely dark, blurry, or high dynamic range conditions) must be useful. However, creating a training dataset for such environments is expensive and hard due to the difficulties of data collection and annotation. It is desirable if we could get a robust model without the need of hard-to-obtain dataset. One simple approach is to apply data augmentation such as color jitter and blur to standard RGB (sRGB) images in simple scenes. Unfortunately, this approach struggles to yield realistic images in terms of pixel intensity and noise distribution due to not considering the non-linearity of Image Signal Processor (ISP) and noise characteristics of an image sensor. Instead, we propose a noise-accounted RAW image augmentation method. In essence, color jitter and blur augmentation are applied to a RAW image before applying non-linear ISP, yielding realistic intensity. Furthermore, we introduce a noise amount alignment method that calibrates the domain gap in noise property caused by the augmentation. We show that our proposed noise-accounted RAW augmentation method doubles the image recognition accuracy in challenging environments only with simple training data.
Hyper-Connected Transformer Network for Co-Learning Multi-Modality PET-CT Features
Oct 28, 2022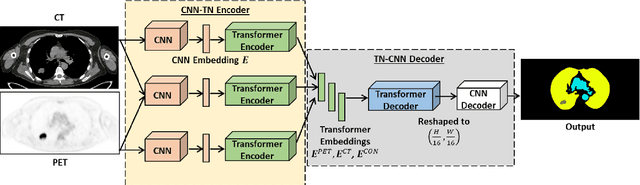

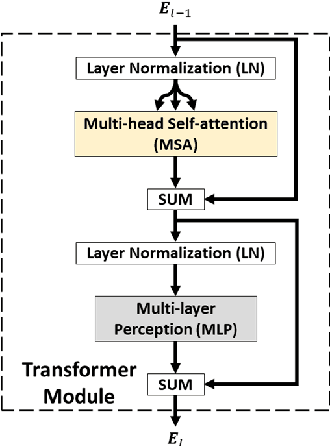
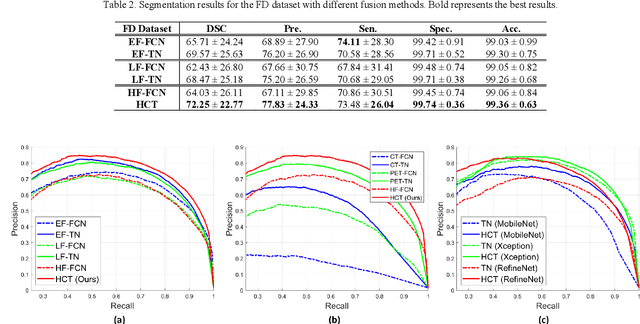
[18F]-Fluorodeoxyglucose (FDG) positron emission tomography - computed tomography (PET-CT) has become the imaging modality of choice for diagnosing many cancers. Co-learning complementary PET-CT imaging features is a fundamental requirement for automatic tumor segmentation and for developing computer aided cancer diagnosis systems. We propose a hyper-connected transformer (HCT) network that integrates a transformer network (TN) with a hyper connected fusion for multi-modality PET-CT images. The TN was leveraged for its ability to provide global dependencies in image feature learning, which was achieved by using image patch embeddings with a self-attention mechanism to capture image-wide contextual information. We extended the single-modality definition of TN with multiple TN based branches to separately extract image features. We introduced a hyper connected fusion to fuse the contextual and complementary image features across multiple transformers in an iterative manner. Our results with two non-small cell lung cancer and soft-tissue sarcoma datasets show that HCT achieved better performance in segmentation accuracy when compared to state-of-the-art methods. We also show that HCT produces consistent performance across various image fusion strategies and network backbones.
Highly accurate quantum optimization algorithm for CT image reconstructions based on sinogram patterns
Jul 06, 2022
Computed tomography has been developed as a non-destructive technique for observing internal images of samples. It was difficult to obtain a clean CT image due to various artifacts generated during scanning and limitations of backprojection. Recently, an iterative optimization algorithm has been developed that uses the entire sinogram to make small errors in various artifacts. In this paper, we introduce a method of representing CT images using a combination of qubits. Each qubit variable can represent the internal structure of a real sample by energy optimization. We tested simple image samples in a quantum annealer and a gated model quantum computer.
Oracle Guided Image Synthesis with Relative Queries
Apr 28, 2022

Isolating and controlling specific features in the outputs of generative models in a user-friendly way is a difficult and open-ended problem. We develop techniques that allow an oracle user to generate an image they are envisioning in their head by answering a sequence of relative queries of the form \textit{"do you prefer image $a$ or image $b$?"} Our framework consists of a Conditional VAE that uses the collected relative queries to partition the latent space into preference-relevant features and non-preference-relevant features. We then use the user's responses to relative queries to determine the preference-relevant features that correspond to their envisioned output image. Additionally, we develop techniques for modeling the uncertainty in images' predicted preference-relevant features, allowing our framework to generalize to scenarios in which the relative query training set contains noise.
Will Large-scale Generative Models Corrupt Future Datasets?
Nov 15, 2022
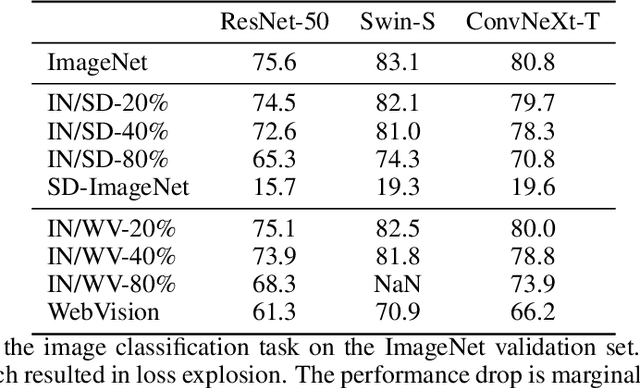

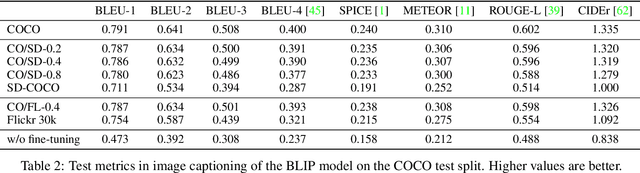
Recently proposed large-scale text-to-image generative models such as DALL$\cdot$E 2, Midjourney, and StableDiffusion can generate high-quality and realistic images from users' prompts. Not limited to the research community, ordinary Internet users enjoy these generative models, and consequently a tremendous amount of generated images have been shared on the Internet. Meanwhile, today's success of deep learning in the computer vision field owes a lot to images collected from the Internet. These trends lead us to a research question: "will such generated images impact the quality of future datasets and the performance of computer vision models positively or negatively?" This paper empirically answers this question by simulating contamination. Namely, we generate ImageNet-scale and COCO-scale datasets using a state-of-the-art generative model and evaluate models trained on ``contaminated'' datasets on various tasks including image classification and image generation. Throughout experiments, we conclude that generated images negatively affect downstream performance, while the significance depends on tasks and the amount of generated images. The generated datasets are available via https://github.com/moskomule/dataset-contamination.
A Low-Shot Object Counting Network With Iterative Prototype Adaptation
Nov 15, 2022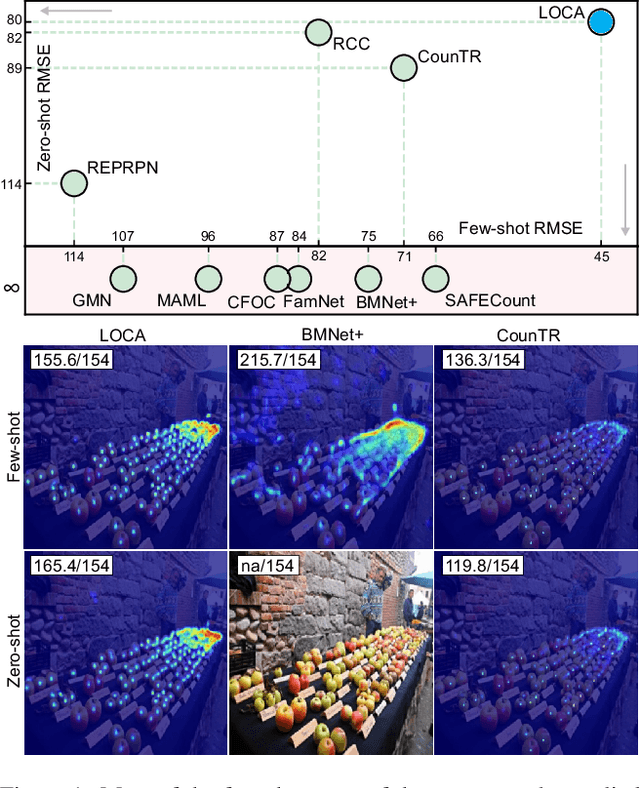
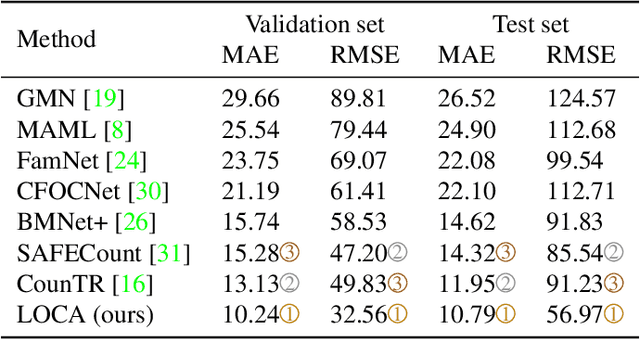
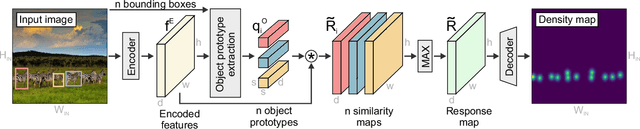
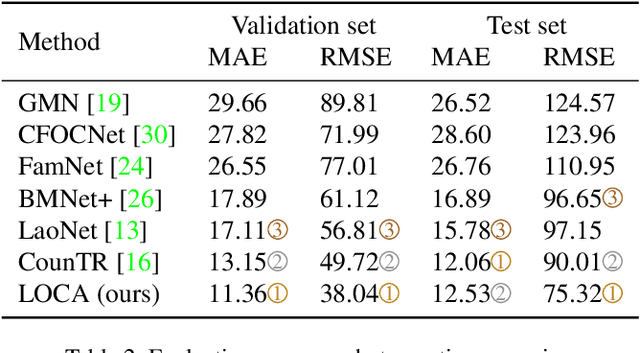
We consider low-shot counting of arbitrary semantic categories in the image using only few annotated exemplars (few-shot) or no exemplars (no-shot). The standard few-shot pipeline follows extraction of appearance queries from exemplars and matching them with image features to infer the object counts. Existing methods extract queries by feature pooling, but neglect the shape information (e.g., size and aspect), which leads to a reduced object localization accuracy and count estimates. We propose a Low-shot Object Counting network with iterative prototype Adaptation (LOCA). Our main contribution is the new object prototype extraction module, which iteratively fuses the exemplar shape and appearance queries with image features. The module is easily adapted to zero-shot scenario, enabling LOCA to cover the entire spectrum of low-shot counting problems. LOCA outperforms all recent state-of-the-art methods on FSC147 benchmark by 20-30% in RMSE on one-shot and few-shot and achieves state-of-the-art on zero-shot scenarios, while demonstrating better generalization capabilities.
Exploiting Category Names for Few-Shot Classification with Vision-Language Models
Dec 04, 2022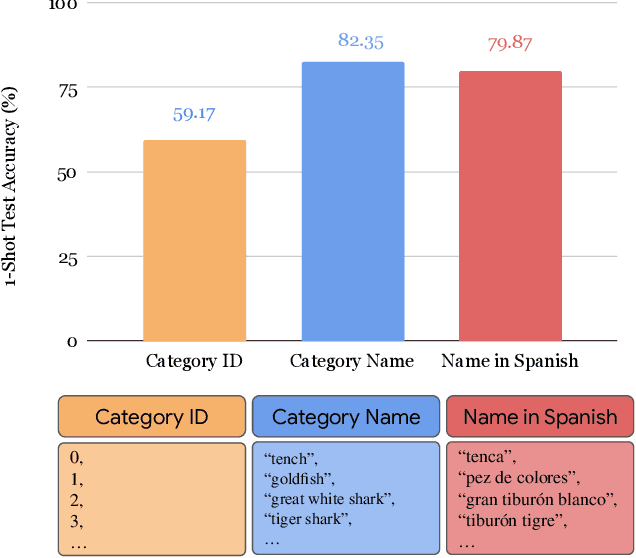
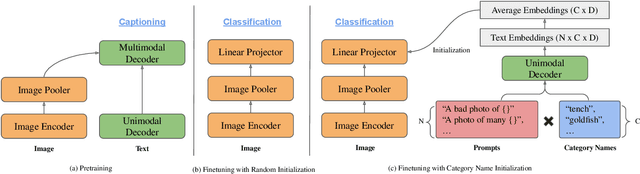
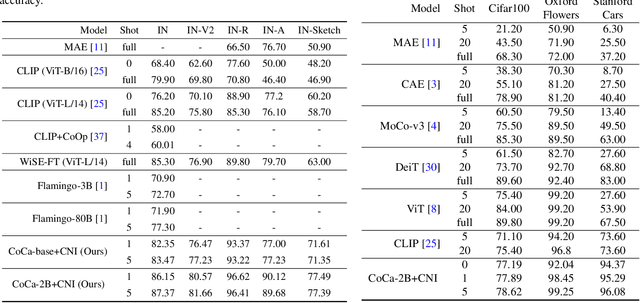
Vision-language foundation models pretrained on large-scale data provide a powerful tool for many visual understanding tasks. Notably, many vision-language models build two encoders (visual and textual) that can map two modalities into the same embedding space. As a result, the learned representations achieve good zero-shot performance on tasks like image classification. However, when there are only a few examples per category, the potential of large vision-language models is often underperformed, mainly due to the gap between a large number of parameters and a relatively small amount of training data. This paper shows that we can significantly improve the performance of few-shot classification by using the category names to initialize the classification head. More interestingly, we can borrow the non-perfect category names, or even names from a foreign language, to improve the few-shot classification performance compared with random initialization. With the proposed category name initialization method, our model obtains the state-of-the-art performance on a number of few-shot image classification benchmarks (e.g., 87.37\% on ImageNet and 96.08\% on Stanford Cars, both using five-shot learning). We also investigate and analyze when the benefit of category names diminishes and how to use distillation to improve the performance of smaller models, providing guidance for future research.
Channel Importance Matters in Few-Shot Image Classification
Jun 20, 2022

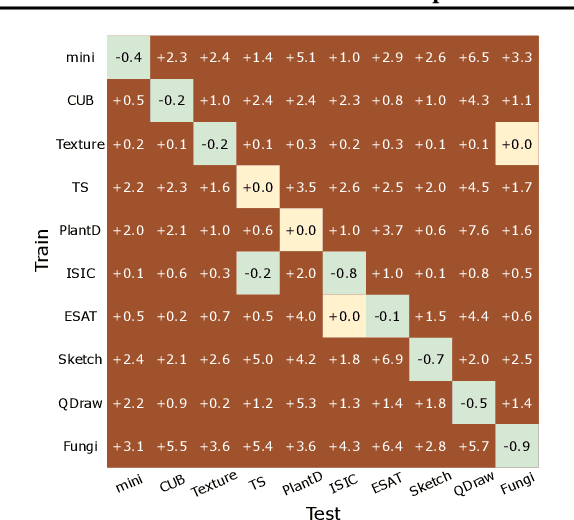
Few-Shot Learning (FSL) requires vision models to quickly adapt to brand-new classification tasks with a shift in task distribution. Understanding the difficulties posed by this task distribution shift is central to FSL. In this paper, we show that a simple channel-wise feature transformation may be the key to unraveling this secret from a channel perspective. When facing novel few-shot tasks in the test-time datasets, this transformation can greatly improve the generalization ability of learned image representations, while being agnostic to the choice of training algorithms and datasets. Through an in-depth analysis of this transformation, we find that the difficulty of representation transfer in FSL stems from the severe channel bias problem of image representations: channels may have different importance in different tasks, while convolutional neural networks are likely to be insensitive, or respond incorrectly to such a shift. This points out a core problem of the generalization ability of modern vision systems and needs further attention in the future. Our code is available at https://github.com/Frankluox/Channel_Importance_FSL.
Shakes on a Plane: Unsupervised Depth Estimation from Unstabilized Photography
Dec 22, 2022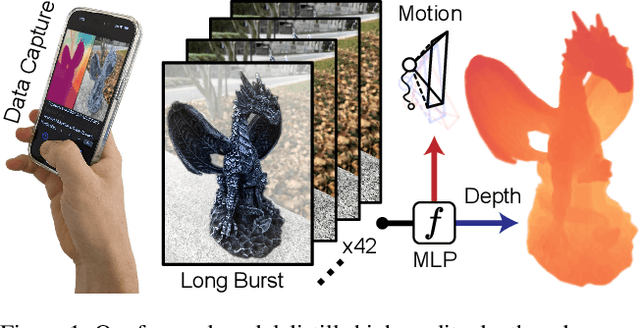
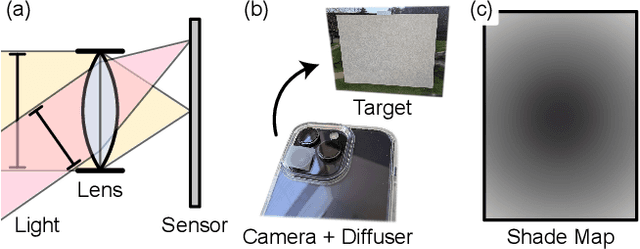
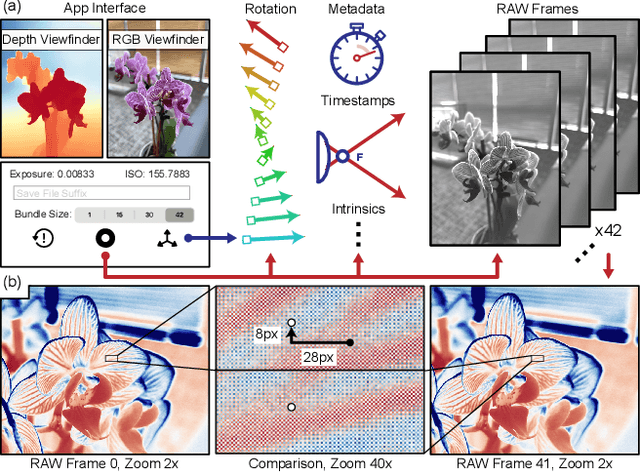
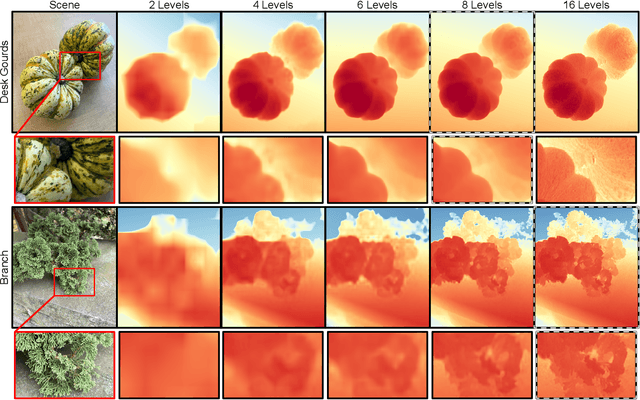
Modern mobile burst photography pipelines capture and merge a short sequence of frames to recover an enhanced image, but often disregard the 3D nature of the scene they capture, treating pixel motion between images as a 2D aggregation problem. We show that in a "long-burst", forty-two 12-megapixel RAW frames captured in a two-second sequence, there is enough parallax information from natural hand tremor alone to recover high-quality scene depth. To this end, we devise a test-time optimization approach that fits a neural RGB-D representation to long-burst data and simultaneously estimates scene depth and camera motion. Our plane plus depth model is trained end-to-end, and performs coarse-to-fine refinement by controlling which multi-resolution volume features the network has access to at what time during training. We validate the method experimentally, and demonstrate geometrically accurate depth reconstructions with no additional hardware or separate data pre-processing and pose-estimation steps.
Understanding and Improving the Role of Projection Head in Self-Supervised Learning
Dec 22, 2022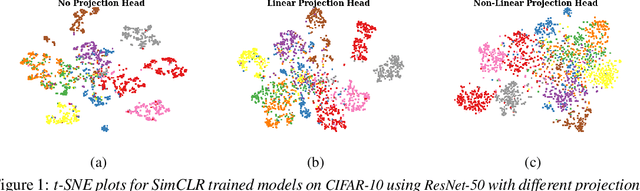
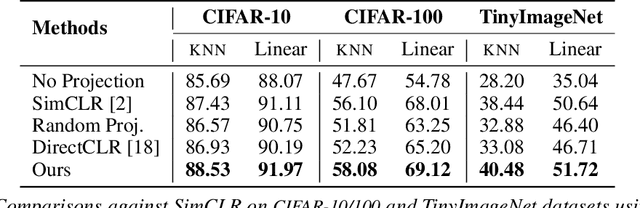
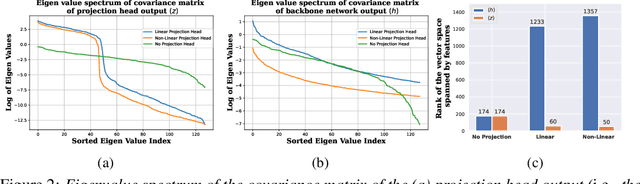
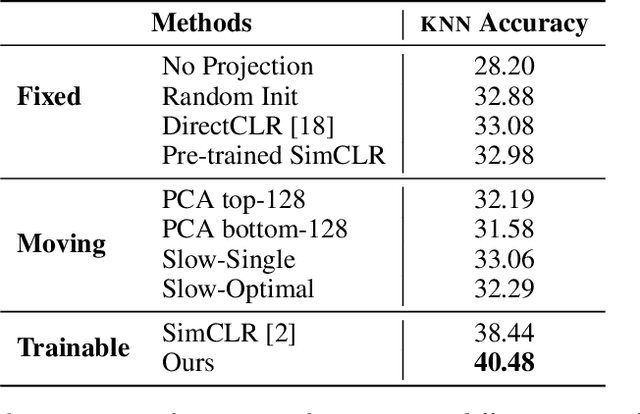
Self-supervised learning (SSL) aims to produce useful feature representations without access to any human-labeled data annotations. Due to the success of recent SSL methods based on contrastive learning, such as SimCLR, this problem has gained popularity. Most current contrastive learning approaches append a parametrized projection head to the end of some backbone network to optimize the InfoNCE objective and then discard the learned projection head after training. This raises a fundamental question: Why is a learnable projection head required if we are to discard it after training? In this work, we first perform a systematic study on the behavior of SSL training focusing on the role of the projection head layers. By formulating the projection head as a parametric component for the InfoNCE objective rather than a part of the network, we present an alternative optimization scheme for training contrastive learning based SSL frameworks. Our experimental study on multiple image classification datasets demonstrates the effectiveness of the proposed approach over alternatives in the SSL literature.