 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Global Sensing and Measurements Reuse for Image Compressed Sensing
Jun 23, 2022
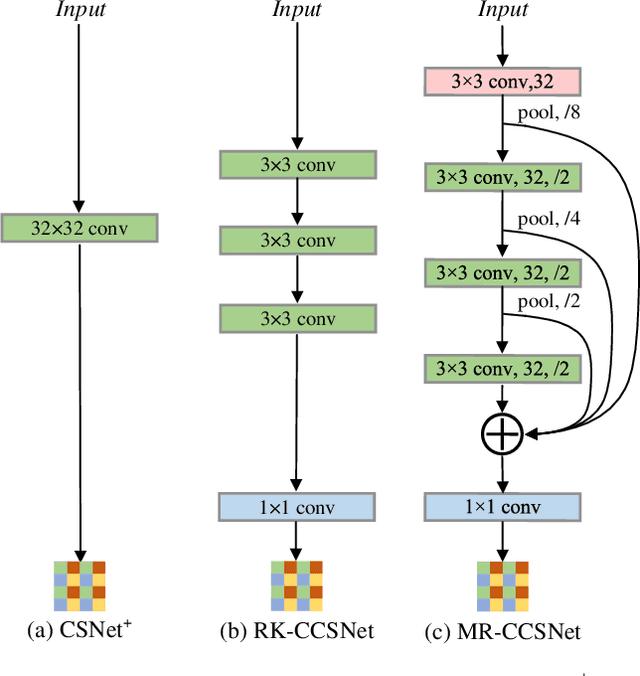
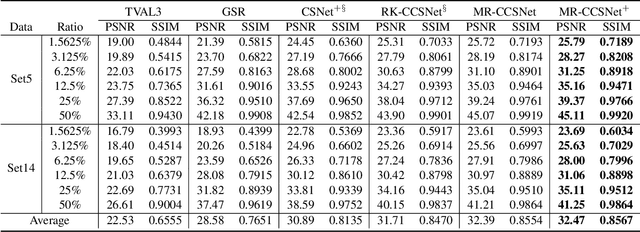
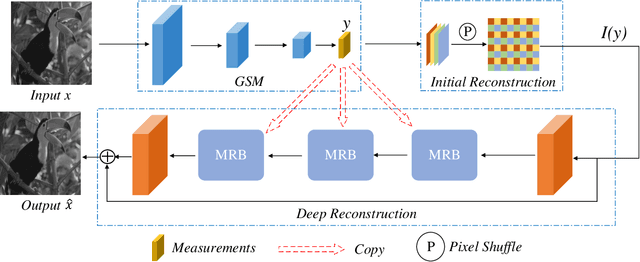
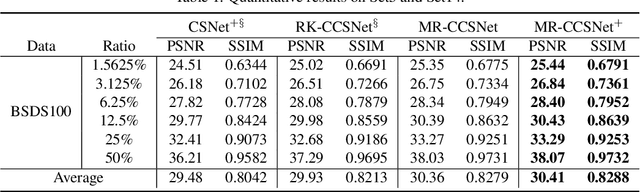
Recently, deep network-based image compressed sensing methods achieved high reconstruction quality and reduced computational overhead compared with traditional methods. However, existing methods obtain measurements only from partial features in the network and use them only once for image reconstruction. They ignore there are low, mid, and high-level features in the network\cite{zeiler2014visualizing} and all of them are essential for high-quality reconstruction. Moreover, using measurements only once may not be enough for extracting richer information from measurements. To address these issues, we propose a novel Measurements Reuse Convolutional Compressed Sensing Network (MR-CCSNet) which employs Global Sensing Module (GSM) to collect all level features for achieving an efficient sensing and Measurements Reuse Block (MRB) to reuse measurements multiple times on multi-scale. Finally, experimental results on three benchmark datasets show that our model can significantly outperform state-of-the-art methods.
Deep learning pipeline for image classification on mobile phones
May 31, 2022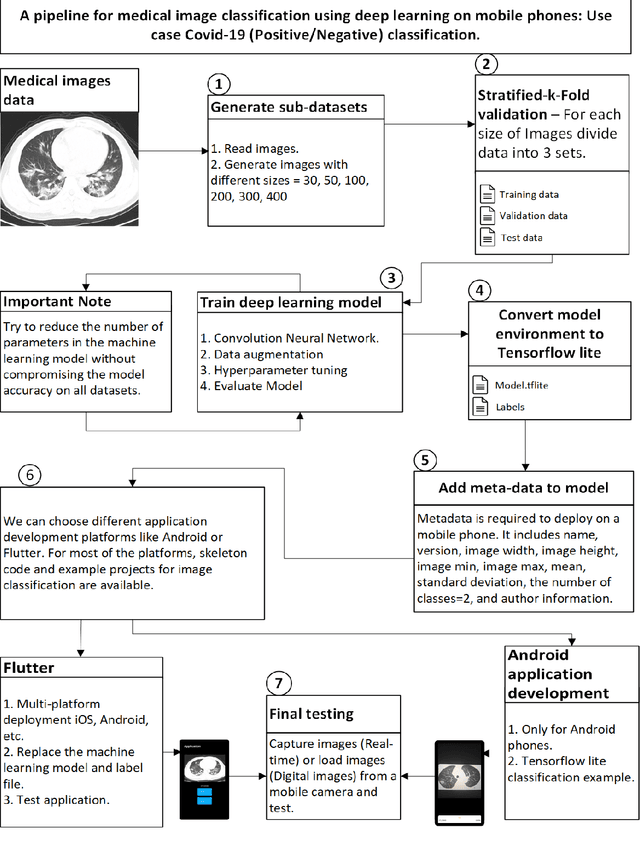
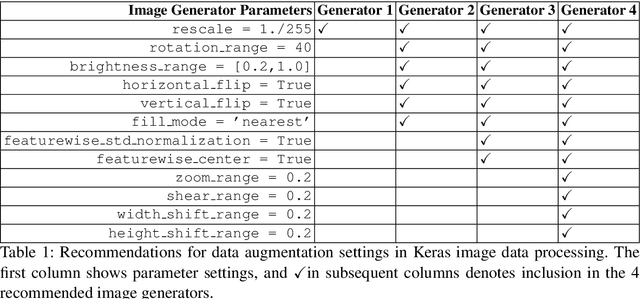
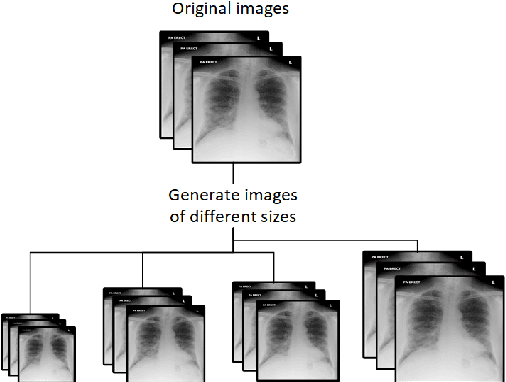
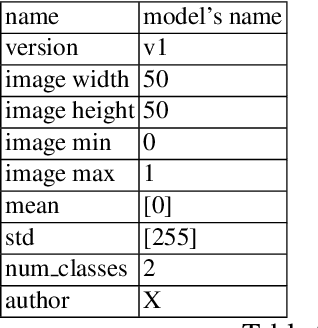
This article proposes and documents a machine-learning framework and tutorial for classifying images using mobile phones. Compared to computers, the performance of deep learning model performance degrades when deployed on a mobile phone and requires a systematic approach to find a model that performs optimally on both computers and mobile phones. By following the proposed pipeline, which consists of various computational tools, simple procedural recipes, and technical considerations, one can bring the power of deep learning medical image classification to mobile devices, potentially unlocking new domains of applications. The pipeline is demonstrated on four different publicly available datasets: COVID X-rays, COVID CT scans, leaves, and colorectal cancer. We used two application development frameworks: TensorFlow Lite (real-time testing) and Flutter (digital image testing) to test the proposed pipeline. We found that transferring deep learning models to a mobile phone is limited by hardware and classification accuracy drops. To address this issue, we proposed this pipeline to find an optimized model for mobile phones. Finally, we discuss additional applications and computational concerns related to deploying deep-learning models on phones, including real-time analysis and image preprocessing. We believe the associated documentation and code can help physicians and medical experts develop medical image classification applications for distribution.
* 20 pages
Scribble2D5: Weakly-Supervised Volumetric Image Segmentation via Scribble Annotations
May 13, 2022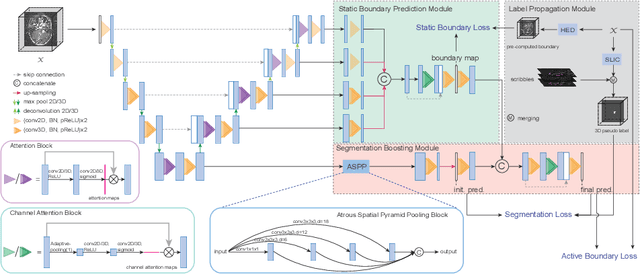
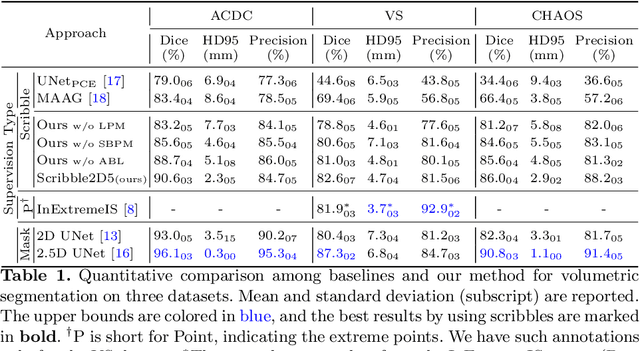

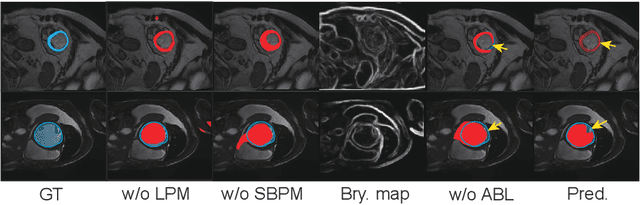
Recently, weakly-supervised image segmentation using weak annotations like scribbles has gained great attention, since such annotations are much easier to obtain compared to time-consuming and label-intensive labeling at the pixel/voxel level. However, because scribbles lack structure information of region of interest (ROI), existing scribble-based methods suffer from poor boundary localization. Furthermore, most current methods are designed for 2D image segmentation, which do not fully leverage the volumetric information if directly applied to image slices. In this paper, we propose a scribble-based volumetric image segmentation, Scribble2D5, which tackles 3D anisotropic image segmentation and improves boundary prediction. To achieve this, we augment a 2.5D attention UNet with a proposed label propagation module to extend semantic information from scribbles and a combination of static and active boundary prediction to learn ROI's boundary and regularize its shape. Extensive experiments on three public datasets demonstrate Scribble2D5 significantly outperforms current scribble-based methods and approaches the performance of fully-supervised ones. Our code is available online.
An AI-Powered VVPAT Counter for Elections in India
Dec 09, 2022
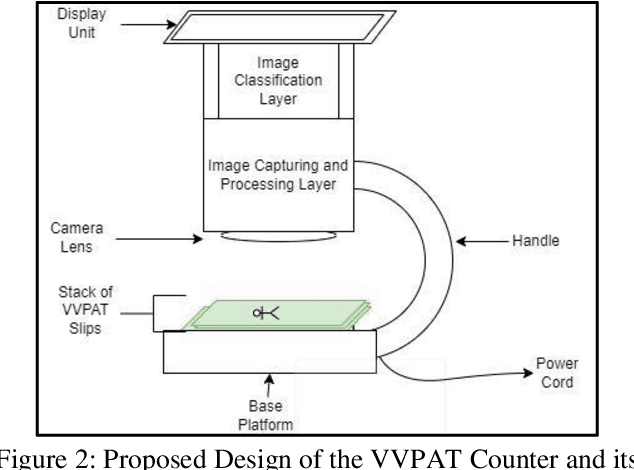

The Election Commission of India has introduced Voter Verified Paper Audit Trail since 2019. This mechanism has increased voter confidence at the time of casting the votes. However, physical verification of the VVPATs against the party level counts from the EVMs is done only in 5 (randomly selected) machines per constituency. The time required to conduct physical verification becomes a bottleneck in scaling this activity for 100% of machines in all constituencies. We proposed an automated counter powered by image processing and machine learning algorithms to speed up the process and address this issue.
DiffusionSDF: Conditional Generative Modeling of Signed Distance Functions
Nov 24, 2022
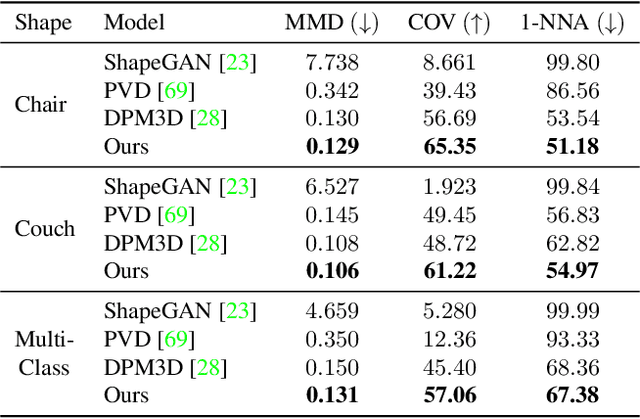
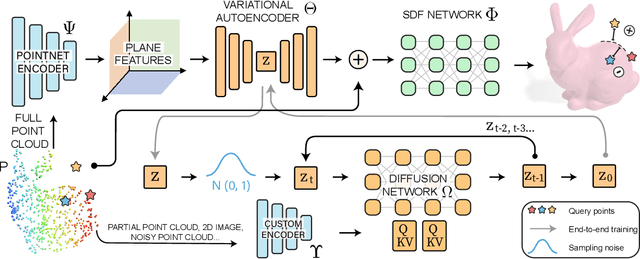
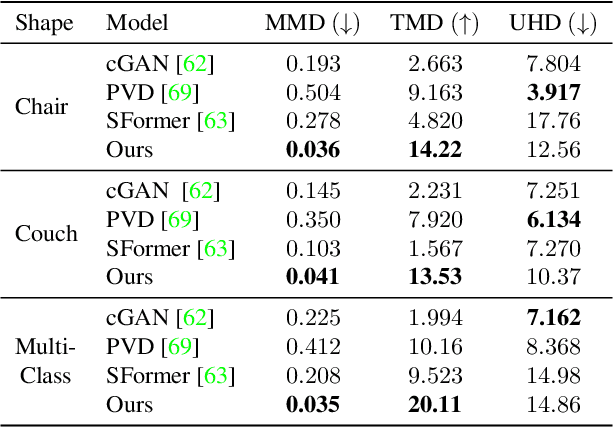
Probabilistic diffusion models have achieved state-of-the-art results for image synthesis, inpainting, and text-to-image tasks. However, they are still in the early stages of generating complex 3D shapes. This work proposes DiffusionSDF, a generative model for shape completion, single-view reconstruction, and reconstruction of real-scanned point clouds. We use neural signed distance functions (SDFs) as our 3D representation to parameterize the geometry of various signals (e.g., point clouds, 2D images) through neural networks. Neural SDFs are implicit functions and diffusing them amounts to learning the reversal of their neural network weights, which we solve using a custom modulation module. Extensive experiments show that our method is capable of both realistic unconditional generation and conditional generation from partial inputs. This work expands the domain of diffusion models from learning 2D, explicit representations, to 3D, implicit representations.
Multiscale Voxel Based Decoding For Enhanced Natural Image Reconstruction From Brain Activity
May 27, 2022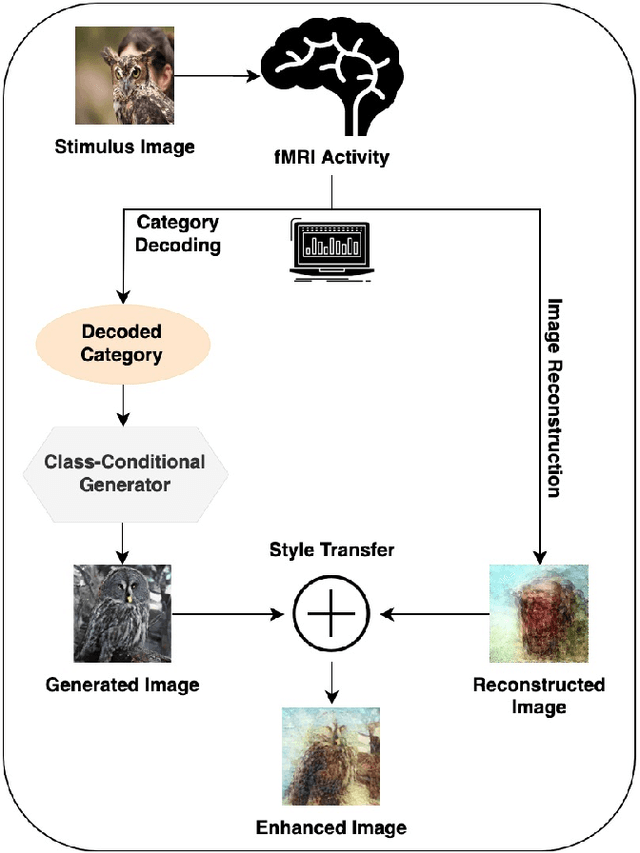



Reconstructing perceived images from human brain activity monitored by functional magnetic resonance imaging (fMRI) is hard, especially for natural images. Existing methods often result in blurry and unintelligible reconstructions with low fidelity. In this study, we present a novel approach for enhanced image reconstruction, in which existing methods for object decoding and image reconstruction are merged together. This is achieved by conditioning the reconstructed image to its decoded image category using a class-conditional generative adversarial network and neural style transfer. The results indicate that our approach improves the semantic similarity of the reconstructed images and can be used as a general framework for enhanced image reconstruction.
Recovering Sign Bits of DCT Coefficients in Digital Images as an Optimization Problem
Nov 02, 2022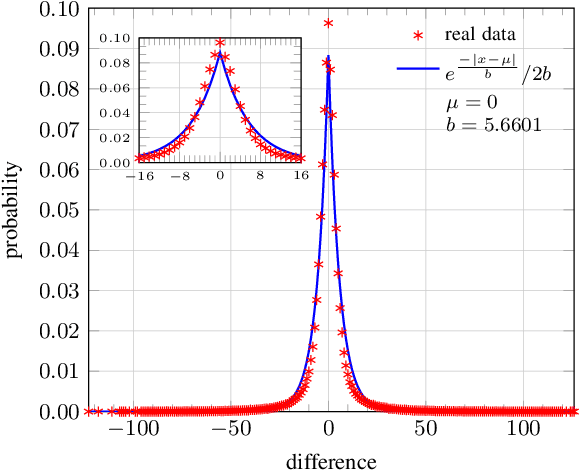
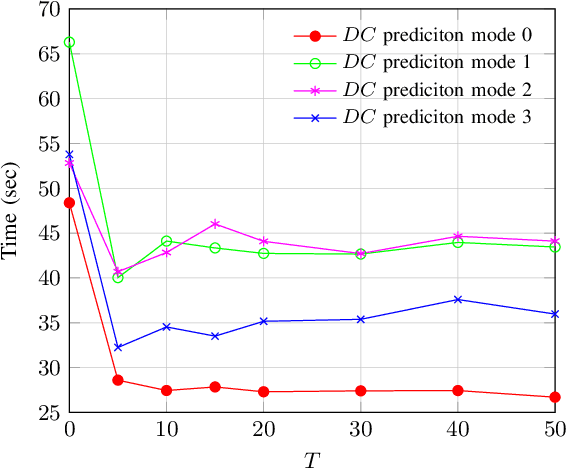
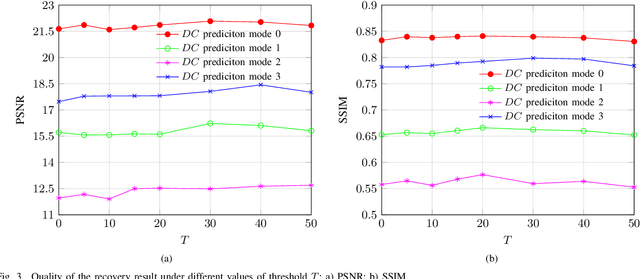

Recovering unknown, missing, damaged, distorted or lost information in DCT coefficients is a common task in multiple applications of digital image processing, including image compression, selective image encryption, and image communications. This paper investigates recovery of a special type of information in DCT coefficients of digital images: sign bits. This problem can be modelled as a mixed integer linear programming (MILP) problem, which is NP-hard in general. To efficiently solve the problem, we propose two approximation methods: 1) a relaxation-based method that convert the MILP problem to a linear programming (LP) problem; 2) a divide-and-conquer method which splits the target image into sufficiently small regions, each of which can be more efficiently solved as an MILP problem, and then conducts a global optimization phase as a smaller MILP problem or an LP problem to maximize smoothness across different regions. To the best of our knowledge, we are the first who considered how to use global optimization to recover sign bits of DCT coefficients. We considered how the proposed methods can be applied to JPEG-encoded images and conducted extensive experiments to validate the performances of our proposed methods. The experimental results showed that the proposed methods worked well, especially when the number of unknown sign bits per DCT block is not too large. Compared with other existing methods, which are all based on simple error-concealment strategies, our proposed methods outperformed them with a substantial margin, both according to objective quality metrics (PSNR and SSIM) and also our subjective evaluation. Our work has a number of profound implications, e.g., more sign bits can be discarded to develop more efficient image compression methods, and image encryption methods based on sign bit encryption can be less secure than we previously understood.
Multi-modal Retinal Image Registration Using a Keypoint-Based Vessel Structure Aligning Network
Jul 21, 2022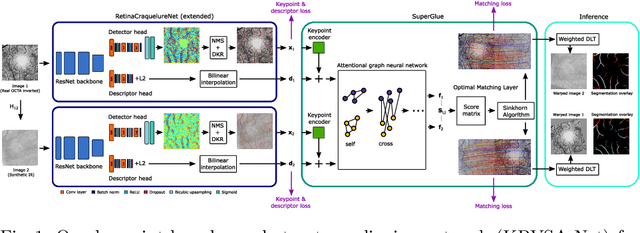
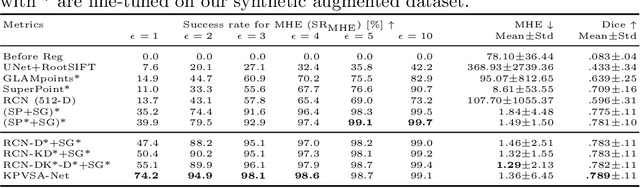

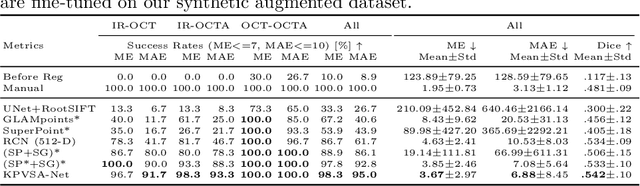
In ophthalmological imaging, multiple imaging systems, such as color fundus, infrared, fluorescein angiography, optical coherence tomography (OCT) or OCT angiography, are often involved to make a diagnosis of retinal disease. Multi-modal retinal registration techniques can assist ophthalmologists by providing a pixel-based comparison of aligned vessel structures in images from different modalities or acquisition times. To this end, we propose an end-to-end trainable deep learning method for multi-modal retinal image registration. Our method extracts convolutional features from the vessel structure for keypoint detection and description and uses a graph neural network for feature matching. The keypoint detection and description network and graph neural network are jointly trained in a self-supervised manner using synthetic multi-modal image pairs and are guided by synthetically sampled ground truth homographies. Our method demonstrates higher registration accuracy as competing methods for our synthetic retinal dataset and generalizes well for our real macula dataset and a public fundus dataset.
Detecting Recolored Image by Spatial Correlation
Apr 23, 2022
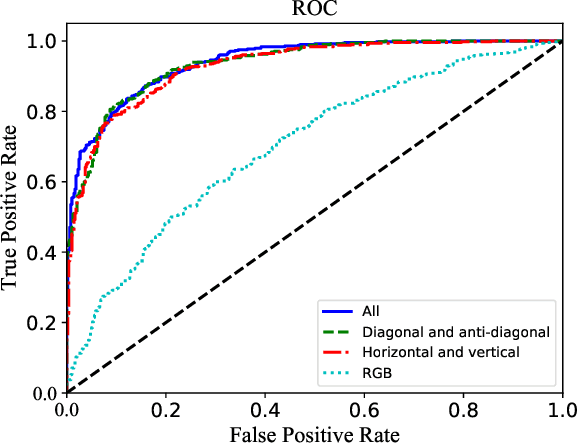
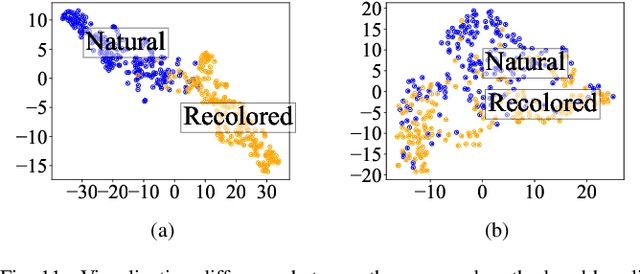
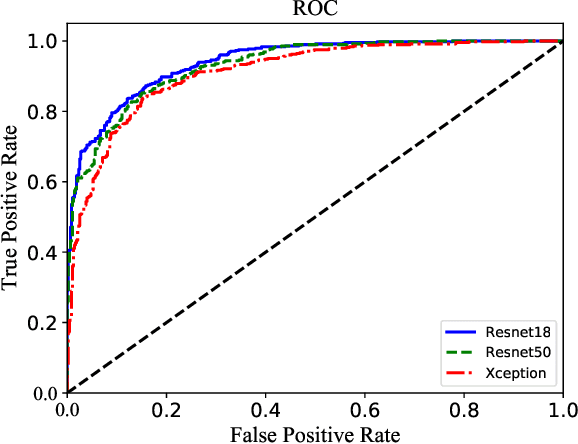
Image forensics, aiming to ensure the authenticity of the image, has made great progress in dealing with common image manipulation such as copy-move, splicing, and inpainting in the past decades. However, only a few researchers pay attention to an emerging editing technique called image recoloring, which can manipulate the color values of an image to give it a new style. To prevent it from being used maliciously, the previous approaches address the conventional recoloring from the perspective of inter-channel correlation and illumination consistency. In this paper, we try to explore a solution from the perspective of the spatial correlation, which exhibits the generic detection capability for both conventional and deep learning-based recoloring. Through theoretical and numerical analysis, we find that the recoloring operation will inevitably destroy the spatial correlation between pixels, implying a new prior of statistical discriminability. Based on such fact, we generate a set of spatial correlation features and learn the informative representation from the set via a convolutional neural network. To train our network, we use three recoloring methods to generate a large-scale and high-quality data set. Extensive experimental results in two recoloring scenes demonstrate that the spatial correlation features are highly discriminative. Our method achieves the state-of-the-art detection accuracy on multiple benchmark datasets and exhibits well generalization for unknown types of recoloring methods.
Exploiting Category Names for Few-Shot Classification with Vision-Language Models
Dec 04, 2022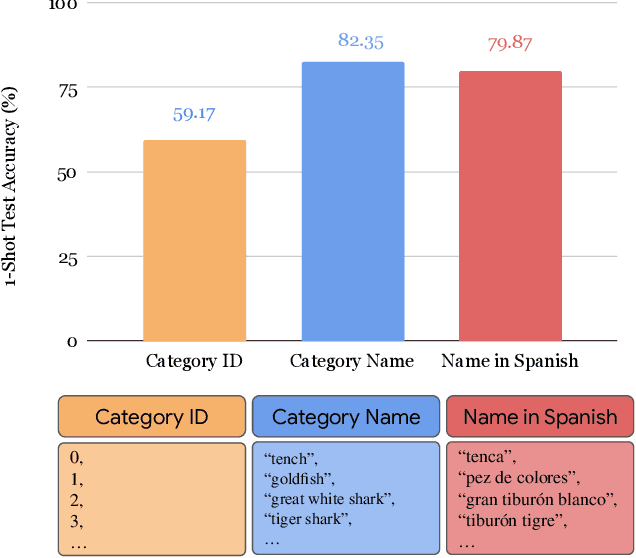
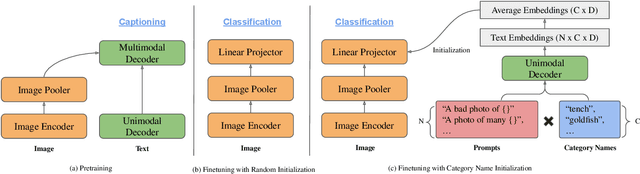
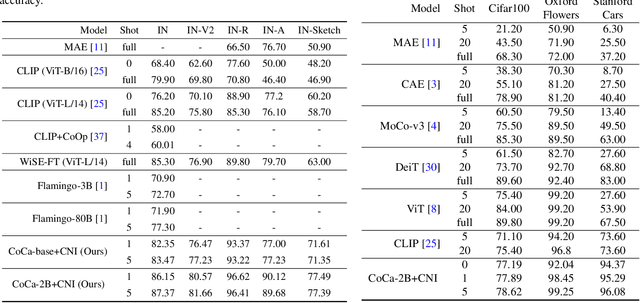
Vision-language foundation models pretrained on large-scale data provide a powerful tool for many visual understanding tasks. Notably, many vision-language models build two encoders (visual and textual) that can map two modalities into the same embedding space. As a result, the learned representations achieve good zero-shot performance on tasks like image classification. However, when there are only a few examples per category, the potential of large vision-language models is often underperformed, mainly due to the gap between a large number of parameters and a relatively small amount of training data. This paper shows that we can significantly improve the performance of few-shot classification by using the category names to initialize the classification head. More interestingly, we can borrow the non-perfect category names, or even names from a foreign language, to improve the few-shot classification performance compared with random initialization. With the proposed category name initialization method, our model obtains the state-of-the-art performance on a number of few-shot image classification benchmarks (e.g., 87.37\% on ImageNet and 96.08\% on Stanford Cars, both using five-shot learning). We also investigate and analyze when the benefit of category names diminishes and how to use distillation to improve the performance of smaller models, providing guidance for future research.