 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DI-Retinex: Digital-Imaging Retinex Theory for Low-Light Image Enhancement
Apr 04, 2024
Many existing methods for low-light image enhancement (LLIE) based on Retinex theory ignore important factors that affect the validity of this theory in digital imaging, such as noise, quantization error, non-linearity, and dynamic range overflow. In this paper, we propose a new expression called Digital-Imaging Retinex theory (DI-Retinex) through theoretical and experimental analysis of Retinex theory in digital imaging. Our new expression includes an offset term in the enhancement model, which allows for pixel-wise brightness contrast adjustment with a non-linear mapping function. In addition, to solve the lowlight enhancement problem in an unsupervised manner, we propose an image-adaptive masked reverse degradation loss in Gamma space. We also design a variance suppression loss for regulating the additional offset term. Extensive experiments show that our proposed method outperforms all existing unsupervised methods in terms of visual quality, model size, and speed. Our algorithm can also assist downstream face detectors in low-light, as it shows the most performance gain after the low-light enhancement compared to other methods.
MC$^2$: Multi-concept Guidance for Customized Multi-concept Generation
Apr 12, 2024Customized text-to-image generation aims to synthesize instantiations of user-specified concepts and has achieved unprecedented progress in handling individual concept. However, when extending to multiple customized concepts, existing methods exhibit limitations in terms of flexibility and fidelity, only accommodating the combination of limited types of models and potentially resulting in a mix of characteristics from different concepts. In this paper, we introduce the Multi-concept guidance for Multi-concept customization, termed MC$^2$, for improved flexibility and fidelity. MC$^2$ decouples the requirements for model architecture via inference time optimization, allowing the integration of various heterogeneous single-concept customized models. It adaptively refines the attention weights between visual and textual tokens, directing image regions to focus on their associated words while diminishing the impact of irrelevant ones. Extensive experiments demonstrate that MC$^2$ even surpasses previous methods that require additional training in terms of consistency with input prompt and reference images. Moreover, MC$^2$ can be extended to elevate the compositional capabilities of text-to-image generation, yielding appealing results. Code will be publicly available at https://github.com/JIANGJiaXiu/MC-2.
Adapting CNNs for Fisheye Cameras without Retraining
Apr 12, 2024The majority of image processing approaches assume images are in or can be rectified to a perspective projection. However, in many applications it is beneficial to use non conventional cameras, such as fisheye cameras, that have a larger field of view (FOV). The issue arises that these large-FOV images can't be rectified to a perspective projection without significant cropping of the original image. To address this issue we propose Rectified Convolutions (RectConv); a new approach for adapting pre-trained convolutional networks to operate with new non-perspective images, without any retraining. Replacing the convolutional layers of the network with RectConv layers allows the network to see both rectified patches and the entire FOV. We demonstrate RectConv adapting multiple pre-trained networks to perform segmentation and detection on fisheye imagery from two publicly available datasets. Our approach requires no additional data or training, and operates directly on the native image as captured from the camera. We believe this work is a step toward adapting the vast resources available for perspective images to operate across a broad range of camera geometries.
Allowing humans to interactively guide machines where to look does not always improve human-AI team's classification accuracy
Apr 14, 2024Via thousands of papers in Explainable AI (XAI), attention maps \cite{vaswani2017attention} and feature attribution maps \cite{bansal2020sam} have been established as a common means for finding how important each input feature is to an AI's decisions. It is an interesting, unexplored question whether allowing users to edit the feature importance at test time would improve a human-AI team's accuracy on downstream tasks. In this paper, we address this question by leveraging CHM-Corr, a state-of-the-art, ante-hoc explainable classifier \cite{taesiri2022visual} that first predicts patch-wise correspondences between the input and training-set images, and then base on them to make classification decisions. We build CHM-Corr++, an interactive interface for CHM-Corr, enabling users to edit the feature attribution map provided by CHM-Corr and observe updated model decisions. Via CHM-Corr++, users can gain insights into if, when, and how the model changes its outputs, improving their understanding beyond static explanations. However, our user study with 18 users who performed 1,400 decisions finds no statistical significance that our interactive approach improves user accuracy on CUB-200 bird image classification over static explanations. This challenges the hypothesis that interactivity can boost human-AI team accuracy~\cite{sokol2020one,sun2022exploring,shen2024towards,singh2024rethinking,mindlin2024beyond,lakkaraju2022rethinking,cheng2019explaining,liu2021understanding} and raises needs for future research. We open-source CHM-Corr++, an interactive tool for editing image classifier attention (see an interactive demo \href{http://137.184.82.109:7080/}{here}). % , and it lays the groundwork for future research to enable effective human-AI interaction in computer vision. We release code and data on \href{https://github.com/anguyen8/chm-corr-interactive}{github}.
CosmicMan: A Text-to-Image Foundation Model for Humans
Apr 01, 2024We present CosmicMan, a text-to-image foundation model specialized for generating high-fidelity human images. Unlike current general-purpose foundation models that are stuck in the dilemma of inferior quality and text-image misalignment for humans, CosmicMan enables generating photo-realistic human images with meticulous appearance, reasonable structure, and precise text-image alignment with detailed dense descriptions. At the heart of CosmicMan's success are the new reflections and perspectives on data and models: (1) We found that data quality and a scalable data production flow are essential for the final results from trained models. Hence, we propose a new data production paradigm, Annotate Anyone, which serves as a perpetual data flywheel to produce high-quality data with accurate yet cost-effective annotations over time. Based on this, we constructed a large-scale dataset, CosmicMan-HQ 1.0, with 6 Million high-quality real-world human images in a mean resolution of 1488x1255, and attached with precise text annotations deriving from 115 Million attributes in diverse granularities. (2) We argue that a text-to-image foundation model specialized for humans must be pragmatic -- easy to integrate into down-streaming tasks while effective in producing high-quality human images. Hence, we propose to model the relationship between dense text descriptions and image pixels in a decomposed manner, and present Decomposed-Attention-Refocusing (Daring) training framework. It seamlessly decomposes the cross-attention features in existing text-to-image diffusion model, and enforces attention refocusing without adding extra modules. Through Daring, we show that explicitly discretizing continuous text space into several basic groups that align with human body structure is the key to tackling the misalignment problem in a breeze.
Severity Controlled Text-to-Image Generative Model Bias Manipulation
Apr 03, 2024Text-to-image (T2I) generative models are gaining wide popularity, especially in public domains. However, their intrinsic bias and potential malicious manipulations remain under-explored. Charting the susceptibility of T2I models to such manipulation, we first expose the new possibility of a dynamic and computationally efficient exploitation of model bias by targeting the embedded language models. By leveraging mathematical foundations of vector algebra, our technique enables a scalable and convenient control over the severity of output manipulation through model bias. As a by-product, this control also allows a form of precise prompt engineering to generate images which are generally implausible with regular text prompts. We also demonstrate a constructive application of our manipulation for balancing the frequency of generated classes - as in model debiasing. Our technique does not require training and is also framed as a backdoor attack with severity control using semantically-null text triggers in the prompts. With extensive analysis, we present interesting qualitative and quantitative results to expose potential manipulation possibilities for T2I models. Key-words: Text-to-Image Models, Generative Models, Backdoor Attacks, Prompt Engineering, Bias
Benchmarking the Cell Image Segmentation Models Robustness under the Microscope Optical Aberrations
Apr 12, 2024Cell segmentation is essential in biomedical research for analyzing cellular morphology and behavior. Deep learning methods, particularly convolutional neural networks (CNNs), have revolutionized cell segmentation by extracting intricate features from images. However, the robustness of these methods under microscope optical aberrations remains a critical challenge. This study comprehensively evaluates the performance of cell instance segmentation models under simulated aberration conditions using the DynamicNuclearNet (DNN) and LIVECell datasets. Aberrations, including Astigmatism, Coma, Spherical, and Trefoil, were simulated using Zernike polynomial equations. Various segmentation models, such as Mask R-CNN with different network heads (FPN, C3) and backbones (ResNet, VGG19, SwinS), were trained and tested under aberrated conditions. Results indicate that FPN combined with SwinS demonstrates superior robustness in handling simple cell images affected by minor aberrations. Conversely, Cellpose2.0 proves effective for complex cell images under similar conditions. Our findings provide insights into selecting appropriate segmentation models based on cell morphology and aberration severity, enhancing the reliability of cell segmentation in biomedical applications. Further research is warranted to validate these methods with diverse aberration types and emerging segmentation models. Overall, this research aims to guide researchers in effectively utilizing cell segmentation models in the presence of minor optical aberrations.
Real-time Noise Source Estimation of a Camera System from an Image and Metadata
Apr 04, 2024Autonomous machines must self-maintain proper functionality to ensure the safety of humans and themselves. This pertains particularly to its cameras as predominant sensors to perceive the environment and support actions. A fundamental camera problem addressed in this study is noise. Solutions often focus on denoising images a posteriori, that is, fighting symptoms rather than root causes. However, tackling root causes requires identifying the noise sources, considering the limitations of mobile platforms. This work investigates a real-time, memory-efficient and reliable noise source estimator that combines data- and physically-based models. To this end, a DNN that examines an image with camera metadata for major camera noise sources is built and trained. In addition, it quantifies unexpected factors that impact image noise or metadata. This study investigates seven different estimators on six datasets that include synthetic noise, real-world noise from two camera systems, and real field campaigns. For these, only the model with most metadata is capable to accurately and robustly quantify all individual noise contributions. This method outperforms total image noise estimators and can be plug-and-play deployed. It also serves as a basis to include more advanced noise sources, or as part of an automatic countermeasure feedback-loop to approach fully reliable machines.
* 16 pages, 16 figures, 12 tables, Project page: https://github.com/MaikWischow/Noise-Source-Estimation
Neural Ordinary Differential Equation based Sequential Image Registration for Dynamic Characterization
Apr 02, 2024Deformable image registration (DIR) is crucial in medical image analysis, enabling the exploration of biological dynamics such as organ motions and longitudinal changes in imaging. Leveraging Neural Ordinary Differential Equations (ODE) for registration, this extension work discusses how this framework can aid in the characterization of sequential biological processes. Utilizing the Neural ODE's ability to model state derivatives with neural networks, our Neural Ordinary Differential Equation Optimization-based (NODEO) framework considers voxels as particles within a dynamic system, defining deformation fields through the integration of neural differential equations. This method learns dynamics directly from data, bypassing the need for physical priors, making it exceptionally suitable for medical scenarios where such priors are unavailable or inapplicable. Consequently, the framework can discern underlying dynamics and use sequence data to regularize the transformation trajectory. We evaluated our framework on two clinical datasets: one for cardiac motion tracking and another for longitudinal brain MRI analysis. Demonstrating its efficacy in both 2D and 3D imaging scenarios, our framework offers flexibility and model agnosticism, capable of managing image sequences and facilitating label propagation throughout these sequences. This study provides a comprehensive understanding of how the Neural ODE-based framework uniquely benefits the image registration challenge.
MedCLIP-SAM: Bridging Text and Image Towards Universal Medical Image Segmentation
Mar 29, 2024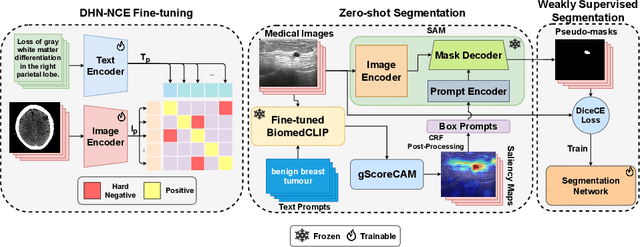
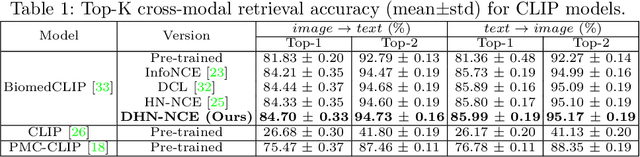
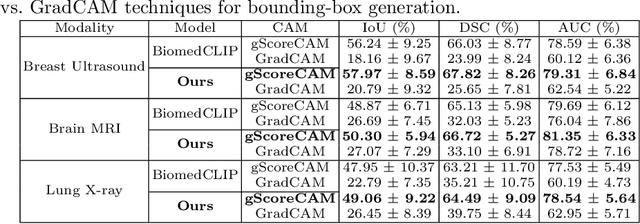

Medical image segmentation of anatomical structures and pathology is crucial in modern clinical diagnosis, disease study, and treatment planning. To date, great progress has been made in deep learning-based segmentation techniques, but most methods still lack data efficiency, generalizability, and interactability. Consequently, the development of new, precise segmentation methods that demand fewer labeled datasets is of utmost importance in medical image analysis. Recently, the emergence of foundation models, such as CLIP and Segment-Anything-Model (SAM), with comprehensive cross-domain representation opened the door for interactive and universal image segmentation. However, exploration of these models for data-efficient medical image segmentation is still limited, but is highly necessary. In this paper, we propose a novel framework, called MedCLIP-SAM that combines CLIP and SAM models to generate segmentation of clinical scans using text prompts in both zero-shot and weakly supervised settings. To achieve this, we employed a new Decoupled Hard Negative Noise Contrastive Estimation (DHN-NCE) loss to fine-tune the BiomedCLIP model and the recent gScoreCAM to generate prompts to obtain segmentation masks from SAM in a zero-shot setting. Additionally, we explored the use of zero-shot segmentation labels in a weakly supervised paradigm to improve the segmentation quality further. By extensively testing three diverse segmentation tasks and medical image modalities (breast tumor ultrasound, brain tumor MRI, and lung X-ray), our proposed framework has demonstrated excellent accuracy.