 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
3D-EPI Blip-Up/Down Acquisition (BUDA) with CAIPI and Joint Hankel Structured Low-Rank Reconstruction for Rapid Distortion-Free High-Resolution T2* Mapping
Dec 01, 2022
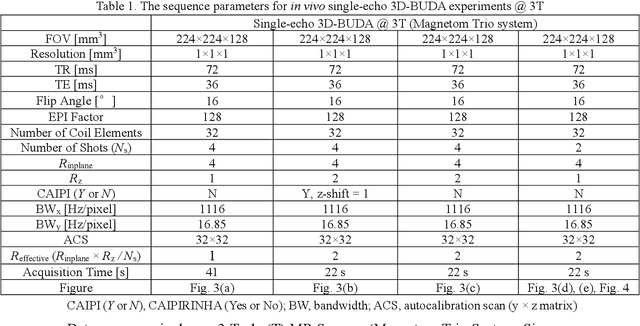
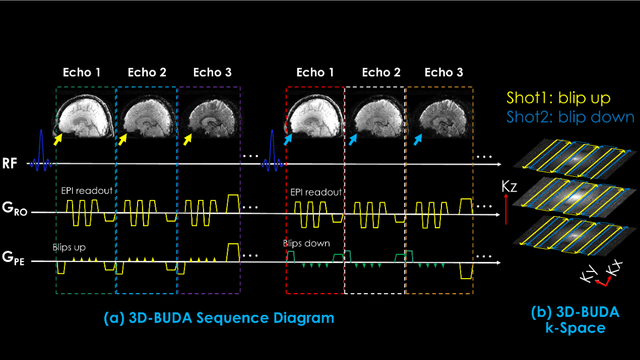
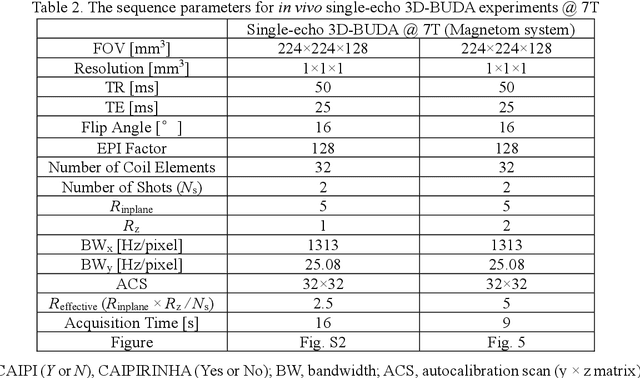

Purpose: This work aims to develop a novel distortion-free 3D-EPI acquisition and image reconstruction technique for fast and robust, high-resolution, whole-brain imaging as well as quantitative T2* mapping. Methods: 3D-Blip-Up and -Down Acquisition (3D-BUDA) sequence is designed for both single- and multi-echo 3D GRE-EPI imaging using multiple shots with blip-up and -down readouts to encode B0 field map information. Complementary k-space coverage is achieved using controlled aliasing in parallel imaging (CAIPI) sampling across the shots. For image reconstruction, an iterative hard-thresholding algorithm is employed to minimize the cost function that combines field map information informed parallel imaging with the structured low-rank constraint for multi-shot 3D-BUDA data. Extending 3D-BUDA to multi-echo imaging permits T2* mapping. For this, we propose constructing a joint Hankel matrix along both echo and shot dimensions to improve the reconstruction. Results: Experimental results on in vivo multi-echo data demonstrate that, by performing joint reconstruction along with both echo and shot dimensions, reconstruction accuracy is improved compared to standard 3D-BUDA reconstruction. CAIPI sampling is further shown to enhance the image quality. For T2* mapping, T2* values from 3D-Joint-CAIPI-BUDA and reference multi-echo GRE are within limits of agreement as quantified by Bland-Altman analysis. Conclusions: The proposed technique enables rapid 3D distortion-free high-resolution imaging and T2* mapping. Specifically, 3D-BUDA enables 1-mm isotropic whole-brain imaging in 22 s at 3 T and 9 s on a 7 T scanner. The combination of multi-echo 3D-BUDA with CAIPI acquisition and joint reconstruction enables distortion-free whole-brain T2* mapping in 47 s at 1.1x1.1x1.0 mm3 resolution.
The Swiss Army Knife for Image-to-Image Translation: Multi-Task Diffusion Models
Apr 06, 2022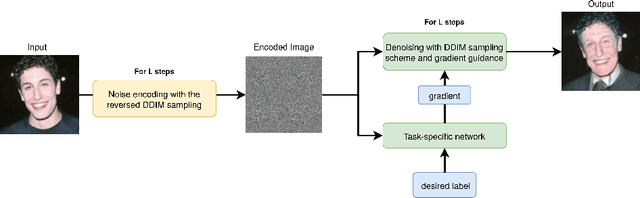



Recently, diffusion models were applied to a wide range of image analysis tasks. We build on a method for image-to-image translation using denoising diffusion implicit models and include a regression problem and a segmentation problem for guiding the image generation to the desired output. The main advantage of our approach is that the guidance during the denoising process is done by an external gradient. Consequently, the diffusion model does not need to be retrained for the different tasks on the same dataset. We apply our method to simulate the aging process on facial photos using a regression task, as well as on a brain magnetic resonance (MR) imaging dataset for the simulation of brain tumor growth. Furthermore, we use a segmentation model to inpaint tumors at the desired location in healthy slices of brain MR images. We achieve convincing results for all problems.
Universal adaptive optics for microscopy through embedded neural network control
Jan 06, 2023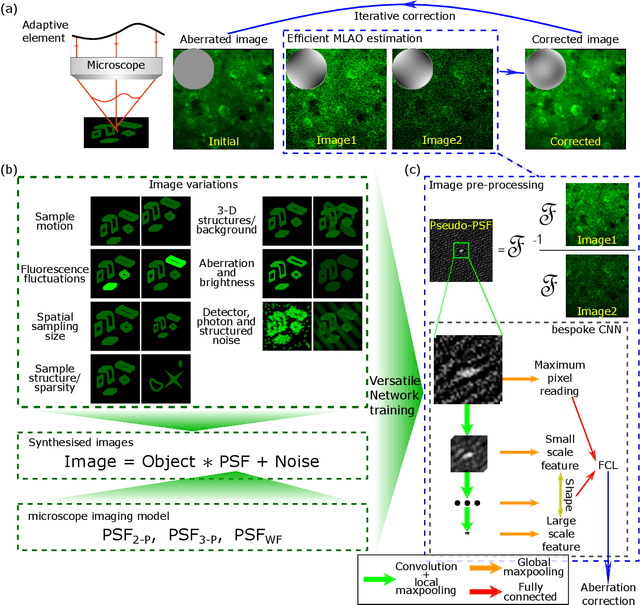
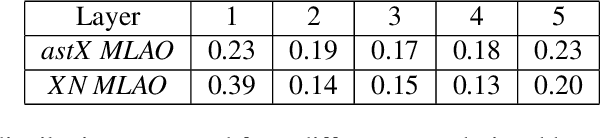
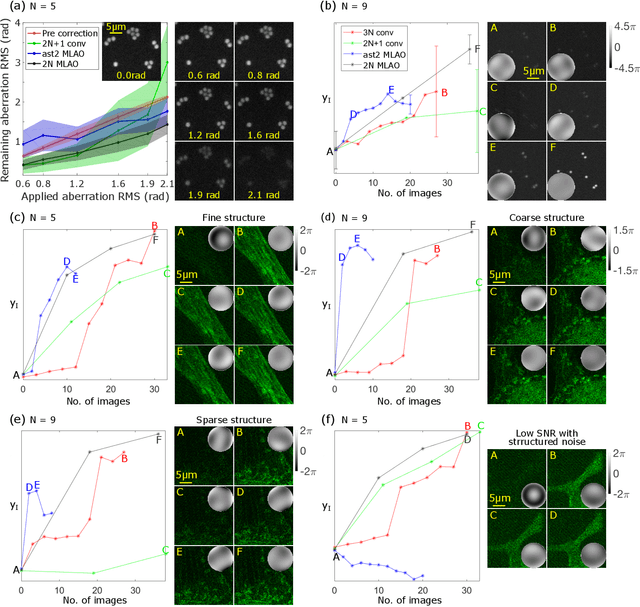
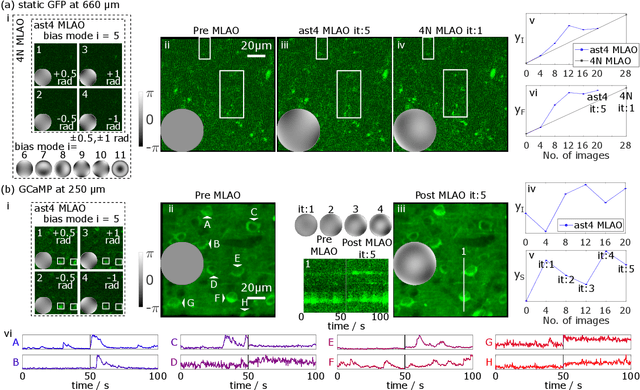
The resolution and contrast of microscope imaging is often affected by aberrations introduced by imperfect optical systems and inhomogeneous refractive structures in specimens. Adaptive optics (AO) compensates these aberrations and restores diffraction limited performance. A wide range of AO solutions have been introduced, often tailored to a specific microscope type or application. Until now, a universal AO solution -- one that can be readily transferred between microscope modalities -- has not been deployed. We propose versatile and fast aberration correction using a physics-based machine learning (ML) assisted wavefront-sensorless AO control method. Unlike previous ML methods, we used a bespoke neural network (NN) architecture, designed using physical understanding of image formation, that was embedded in the control loop of the microscope. The approach means that not only is the resulting NN orders of magnitude simpler than previous NN methods, but the concept is translatable across microscope modalities. We demonstrated the method on a two-photon, a three-photon and a widefield three-dimensional (3D) structured illumination microscope. Results showed that the method outperformed commonly-used modal-based sensorless AO methods. We also showed that our ML-based method was robust in a range of challenging imaging conditions, such as extended 3D sample structures, specimen motion, low signal to noise ratio and activity-induced fluorescence fluctuations. Moreover, as the bespoke architecture encapsulated physical understanding of the imaging process, the internal NN configuration was no-longer a ``black box'', but provided physical insights on internal workings, which could influence future designs.
Progressive Feature Upgrade in Semi-supervised Learning on Tabular Domain
Dec 01, 2022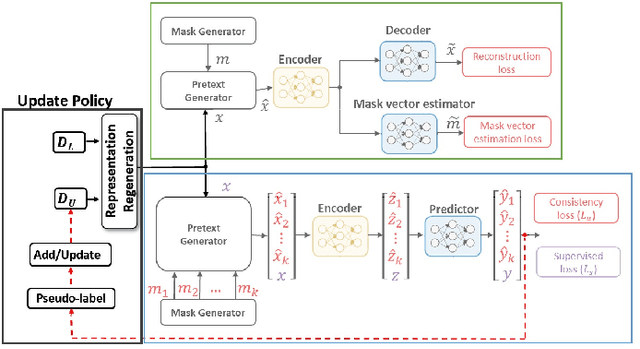
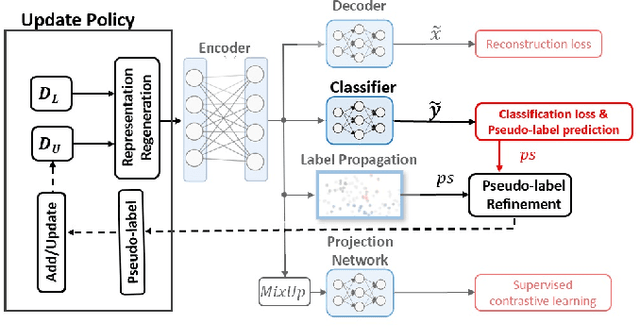
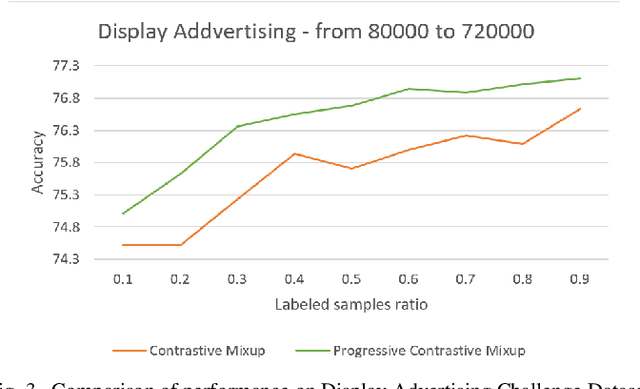
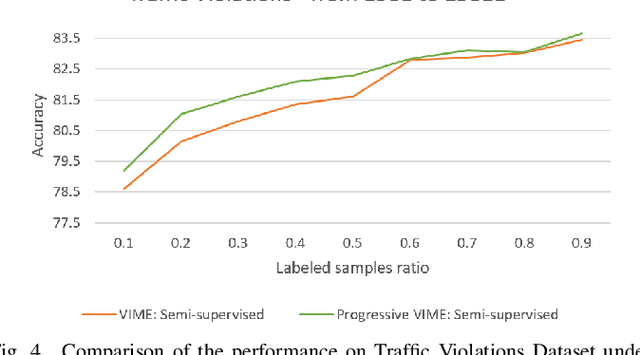
Recent semi-supervised and self-supervised methods have shown great success in the image and text domain by utilizing augmentation techniques. Despite such success, it is not easy to transfer this success to tabular domains. It is not easy to adapt domain-specific transformations from image and language to tabular data due to mixing of different data types (continuous data and categorical data) in the tabular domain. There are a few semi-supervised works on the tabular domain that have focused on proposing new augmentation techniques for tabular data. These approaches may have shown some improvement on datasets with low-cardinality in categorical data. However, the fundamental challenges have not been tackled. The proposed methods either do not apply to datasets with high-cardinality or do not use an efficient encoding of categorical data. We propose using conditional probability representation and an efficient progressively feature upgrading framework to effectively learn representations for tabular data in semi-supervised applications. The extensive experiments show superior performance of the proposed framework and the potential application in semi-supervised settings.
Expanding Small-Scale Datasets with Guided Imagination
Dec 08, 2022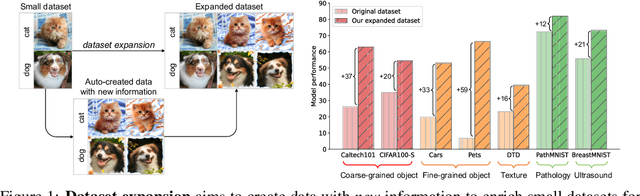
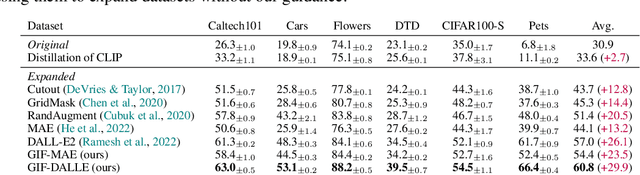
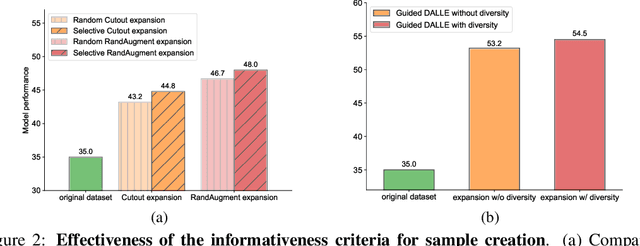

The power of Deep Neural Networks (DNNs) depends heavily on the training data quantity, quality and diversity. However, in many real scenarios, it is costly and time-consuming to collect and annotate large-scale data. This has severely hindered the application of DNNs. To address this challenge, we explore a new task of dataset expansion, which seeks to automatically create new labeled samples to expand a small dataset. To this end, we present a Guided Imagination Framework (GIF) that leverages the recently developed big generative models (e.g., DALL-E2) and reconstruction models (e.g., MAE) to "imagine" and create informative new data from seed data to expand small datasets. Specifically, GIF conducts imagination by optimizing the latent features of seed data in a semantically meaningful space, which are fed into the generative models to generate photo-realistic images with new contents. For guiding the imagination towards creating samples useful for model training, we exploit the zero-shot recognition ability of CLIP and introduce three criteria to encourage informative sample generation, i.e., prediction consistency, entropy maximization and diversity promotion. With these essential criteria as guidance, GIF works well for expanding datasets in different domains, leading to 29.9% accuracy gain on average over six natural image datasets, and 12.3% accuracy gain on average over three medical image datasets. The source code will be released: \url{https://github.com/Vanint/DatasetExpansion}.
To be or not to be stable, that is the question: understanding neural networks for inverse problems
Nov 24, 2022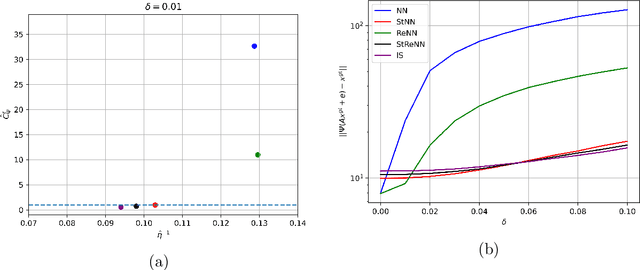

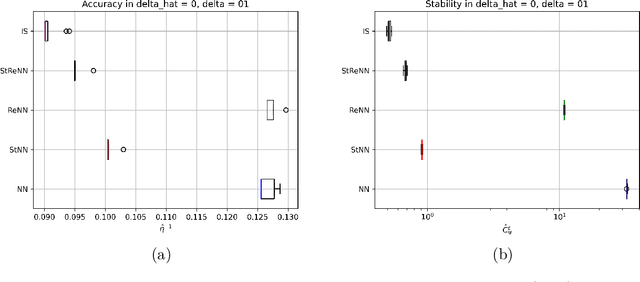
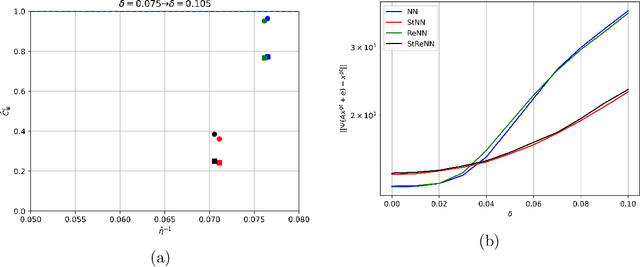
The solution of linear inverse problems arising, for example, in signal and image processing is a challenging problem, since the ill-conditioning amplifies the noise on the data. Recently introduced deep-learning based algorithms overwhelm the more traditional model-based approaches but they typically suffer from instability with respect to data perturbation. In this paper, we theoretically analyse the trade-off between neural networks stability and accuracy in the solution of linear inverse problems. Moreover, we propose different supervised and unsupervised solutions, to increase network stability by maintaining good accuracy, by inheriting, in the network training, regularization from a model-based iterative scheme. Extensive numerical experiments on image deblurring confirm the theoretical results and the effectiveness of the proposed networks in solving inverse problems with stability with respect to noise.
Translating Text Synopses to Video Storyboards
Dec 31, 2022


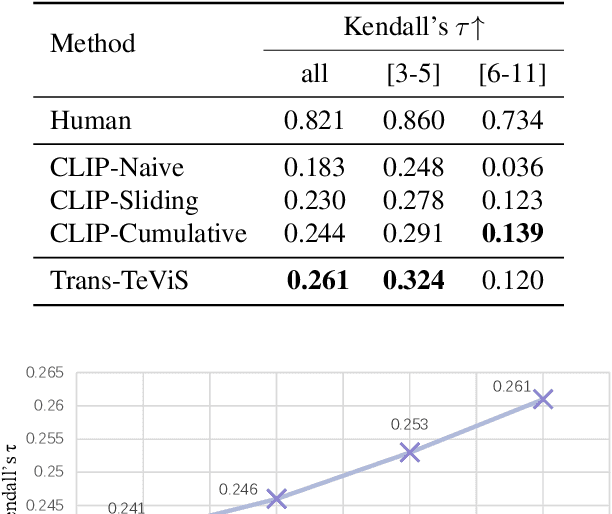
A storyboard is a roadmap for video creation which consists of shot-by-shot images to visualize key plots in a text synopsis. Creating video storyboards however remains challenging which not only requires association between high-level texts and images, but also demands for long-term reasoning to make transitions smooth across shots. In this paper, we propose a new task called Text synopsis to Video Storyboard (TeViS) which aims to retrieve an ordered sequence of images to visualize the text synopsis. We construct a MovieNet-TeViS benchmark based on the public MovieNet dataset. It contains 10K text synopses each paired with keyframes that are manually selected from corresponding movies by considering both relevance and cinematic coherence. We also present an encoder-decoder baseline for the task. The model uses a pretrained vision-and-language model to improve high-level text-image matching. To improve coherence in long-term shots, we further propose to pre-train the decoder on large-scale movie frames without text. Experimental results demonstrate that our proposed model significantly outperforms other models to create text-relevant and coherent storyboards. Nevertheless, there is still a large gap compared to human performance suggesting room for promising future work.
Recursive classification of satellite imaging time-series: An application to water and land cover mapping
Jan 04, 2023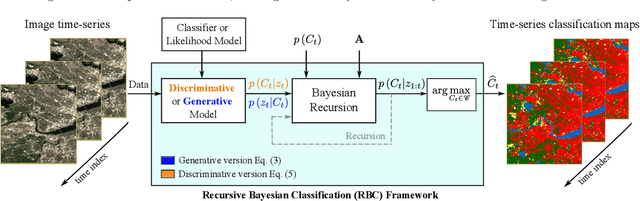
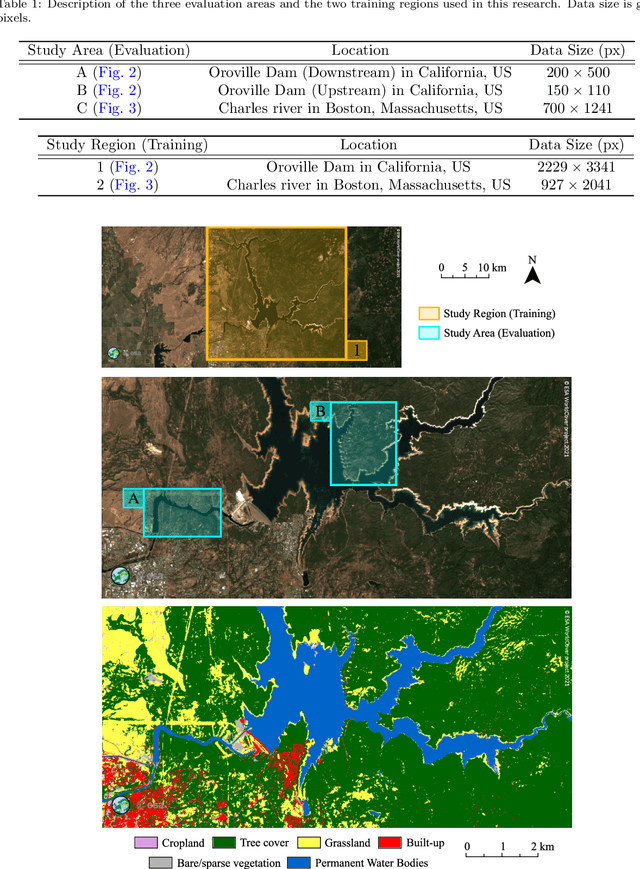
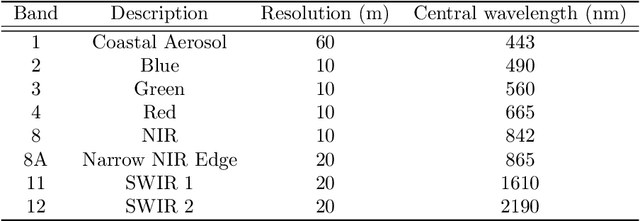

A wide variety of applications of fundamental importance for security, environmental protection and urban development need access to accurate land cover monitoring and water mapping, for which the analysis of optical remote sensing imagery is key. Classification of time-series images, particularly with recursive methods, is of increasing interest in the current literature. Nevertheless, existing recursive approaches typically require large amounts of training data. This paper introduces a recursive classification framework that provides high accuracy while requiring low computational cost and minimal supervision. The proposed approach transforms a static classifier into a recursive one using a probabilistic framework that is robust to non-informative image variations. A water mapping and a land cover experiment are conducted analyzing Sentinel-2 satellite data covering two areas in the United States. The performance of three static classification algorithms and their recursive versions is compared, including a Gaussian Mixture Model (GMM), Logistic Regression (LR) and Spectral Index Classifiers (SICs). SICs consist in a new approach that we introduce to convert the Modified Normalized Difference Water Index (MNDWI) and the Normalized Difference Vegetation Index (NDVI) into probabilistic classification results. Two state-of-the-art deep learning-based classifiers are also used as benchmark models. Results show that the proposed method significantly increases the robustness of existing static classifiers in multitemporal settings. Our method also improves the performance of deep learning-based classifiers without the need of additional training data.
PI-Trans: Parallel-ConvMLP and Implicit-Transformation Based GAN for Cross-View Image Translation
Jul 09, 2022
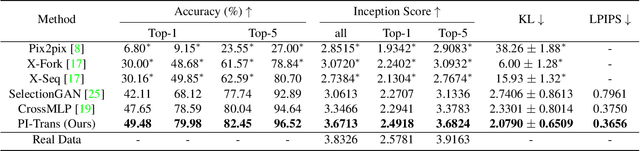
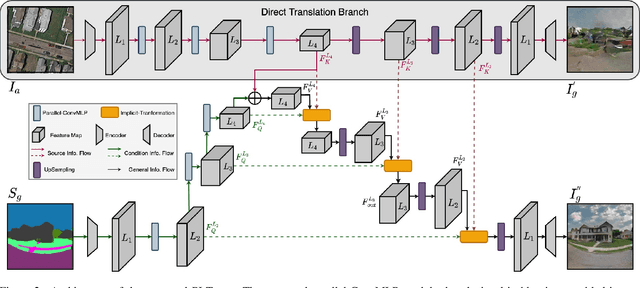
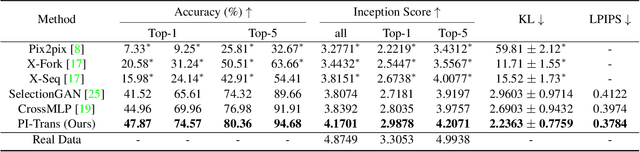
For semantic-guided cross-view image translation, it is crucial to learn where to sample pixels from the source view image and where to reallocate them guided by the target view semantic map, especially when there is little overlap or drastic view difference between the source and target images. Hence, one not only needs to encode the long-range dependencies among pixels in both the source view image and target view the semantic map but also needs to translate these learned dependencies. To this end, we propose a novel generative adversarial network, PI-Trans, which mainly consists of a novel Parallel-ConvMLP module and an Implicit Transformation module at multiple semantic levels. Extensive experimental results show that the proposed PI-Trans achieves the best qualitative and quantitative performance by a large margin compared to the state-of-the-art methods on two challenging datasets. The code will be made available at https://github.com/Amazingren/PI-Trans.
In-situ monitoring additive manufacturing process with AI edge computing
Jan 02, 2023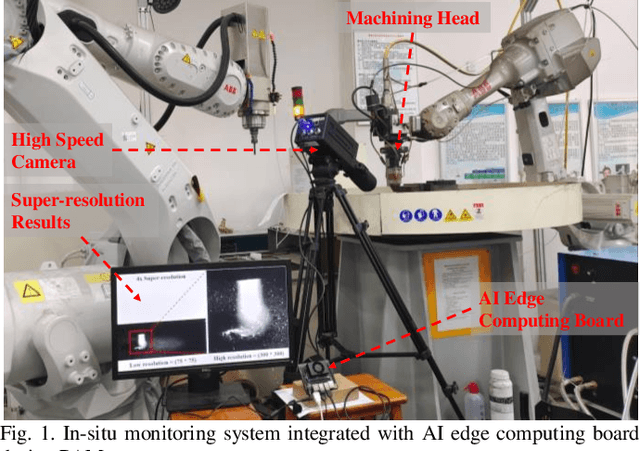
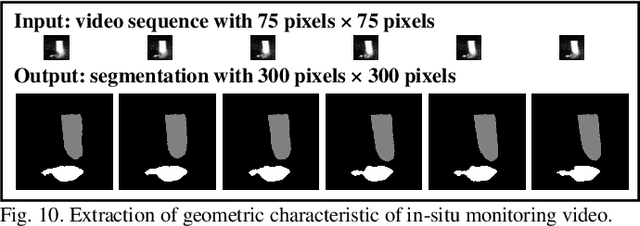
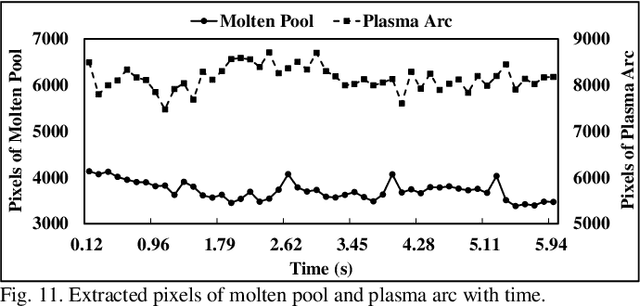

In-situ monitoring system can be used to monitor the quality of additive manufacturing (AM) processes. In the case of digital image correlation (DIC) based in-situ monitoring systems, high-speed cameras were used to capture images of high resolutions. This paper proposed a novel in-situ monitoring system to accelerate the process of digital images using artificial intelligence (AI) edge computing board. It built a visual transformer based video super resolution (ViTSR) network to reconstruct high resolution (HR) videos frames. Fully convolutional network (FCN) was used to simultaneously extract the geometric characteristics of molten pool and plasma arc during the AM processes. Compared with 6 state-of-the-art super resolution methods, ViTSR ranks first in terms of peak signal to noise ratio (PSNR). The PSNR of ViTSR for 4x super resolution reached 38.16 dB on test data with input size of 75 pixels x 75 pixels. Inference time of ViTSR and FCN was optimized to 50.97 ms and 67.86 ms on AI edge board after operator fusion and model pruning. The total inference time of the proposed system was 118.83 ms, which meets the requirement of real-time quality monitoring with low cost in-situ monitoring equipment during AM processes. The proposed system achieved an accuracy of 96.34% on the multi-objects extraction task and can be applied to different AM processes.