 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Scene-aware Egocentric 3D Human Pose Estimation
Dec 20, 2022
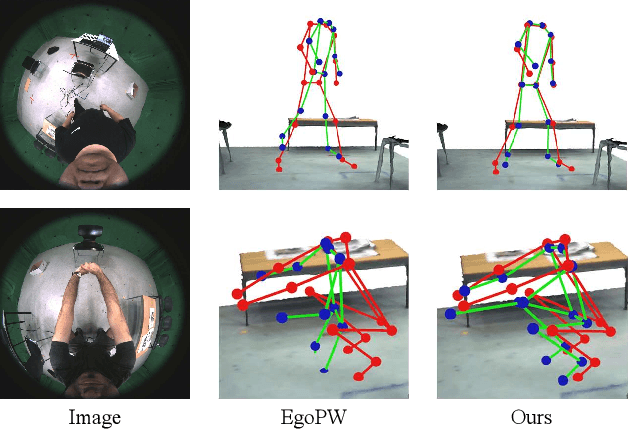
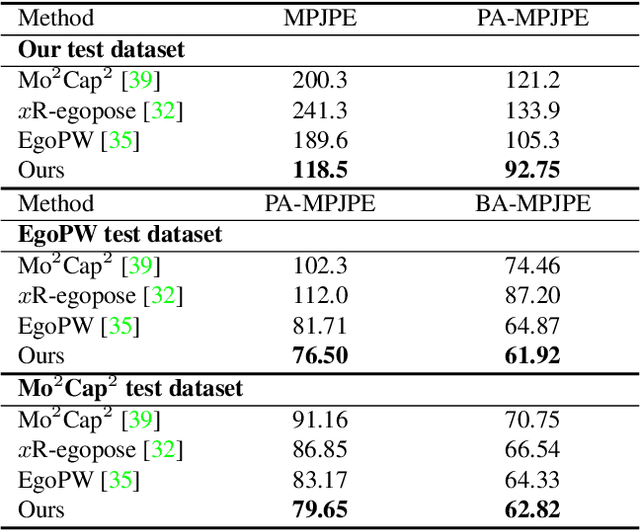
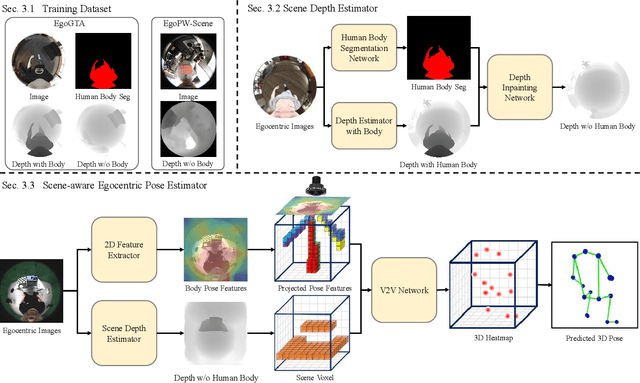

Egocentric 3D human pose estimation with a single head-mounted fisheye camera has recently attracted attention due to its numerous applications in virtual and augmented reality. Existing methods still struggle in challenging poses where the human body is highly occluded or is closely interacting with the scene. To address this issue, we propose a scene-aware egocentric pose estimation method that guides the prediction of the egocentric pose with scene constraints. To this end, we propose an egocentric depth estimation network to predict the scene depth map from a wide-view egocentric fisheye camera while mitigating the occlusion of the human body with a depth-inpainting network. Next, we propose a scene-aware pose estimation network that projects the 2D image features and estimated depth map of the scene into a voxel space and regresses the 3D pose with a V2V network. The voxel-based feature representation provides the direct geometric connection between 2D image features and scene geometry, and further facilitates the V2V network to constrain the predicted pose based on the estimated scene geometry. To enable the training of the aforementioned networks, we also generated a synthetic dataset, called EgoGTA, and an in-the-wild dataset based on EgoPW, called EgoPW-Scene. The experimental results of our new evaluation sequences show that the predicted 3D egocentric poses are accurate and physically plausible in terms of human-scene interaction, demonstrating that our method outperforms the state-of-the-art methods both quantitatively and qualitatively.
Towards Efficient and Scale-Robust Ultra-High-Definition Image Demoireing
Jul 20, 2022


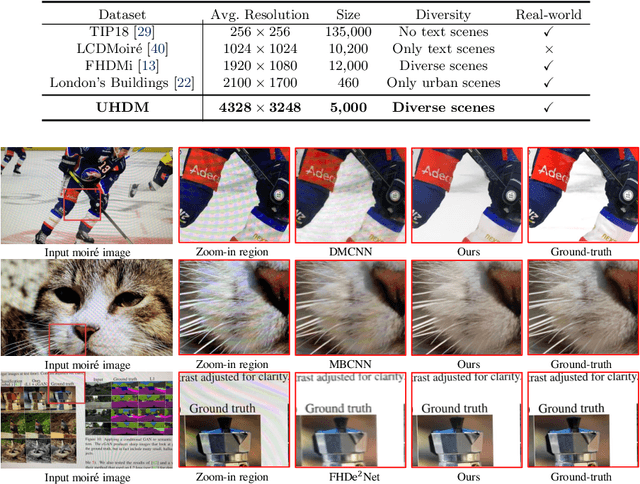
With the rapid development of mobile devices, modern widely-used mobile phones typically allow users to capture 4K resolution (i.e., ultra-high-definition) images. However, for image demoireing, a challenging task in low-level vision, existing works are generally carried out on low-resolution or synthetic images. Hence, the effectiveness of these methods on 4K resolution images is still unknown. In this paper, we explore moire pattern removal for ultra-high-definition images. To this end, we propose the first ultra-high-definition demoireing dataset (UHDM), which contains 5,000 real-world 4K resolution image pairs, and conduct a benchmark study on current state-of-the-art methods. Further, we present an efficient baseline model ESDNet for tackling 4K moire images, wherein we build a semantic-aligned scale-aware module to address the scale variation of moire patterns. Extensive experiments manifest the effectiveness of our approach, which outperforms state-of-the-art methods by a large margin while being much more lightweight. Code and dataset are available at https://xinyu-andy.github.io/uhdm-page.
Efficient Adaptive Ensembling for Image Classification
Jun 15, 2022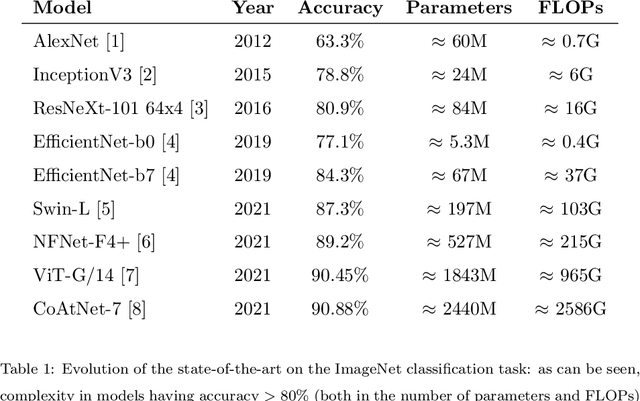
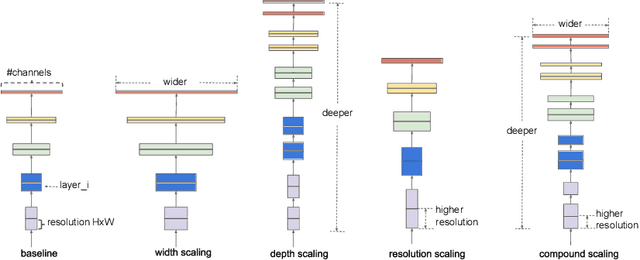
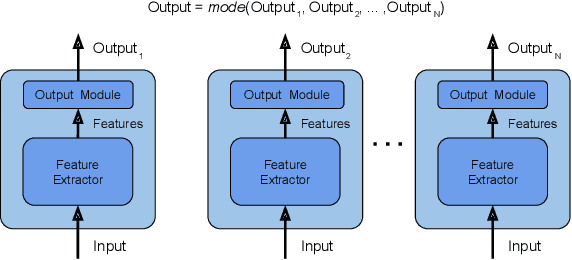
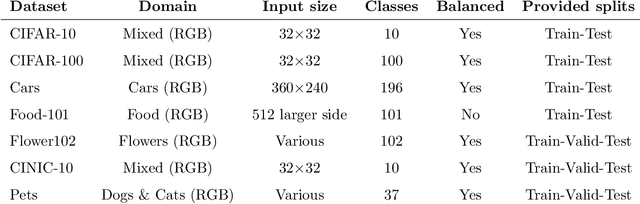
In recent times, except for sporadic cases, the trend in Computer Vision is to achieve minor improvements over considerable increases in complexity. To reverse this tendency, we propose a novel method to boost image classification performances without an increase in complexity. To this end, we revisited ensembling, a powerful approach, not often adequately used due to its nature of increased complexity and training time, making it viable by specific design choices. First, we trained end-to-end two EfficientNet-b0 models (known to be the architecture with the best overall accuracy/complexity trade-off in image classification) on disjoint subsets of data (i.e. bagging). Then, we made an efficient adaptive ensemble by performing fine-tuning of a trainable combination layer. In this way, we were able to outperform the state-of-the-art by an average of 0.5\% on the accuracy with restrained complexity both in terms of number of parameters (by 5-60 times), and FLoating point Operations Per Second (by 10-100 times) on several major benchmark datasets, fully embracing the green AI.
Reinforcement Learning in Medical Image Analysis: Concepts, Applications, Challenges, and Future Directions
Jun 28, 2022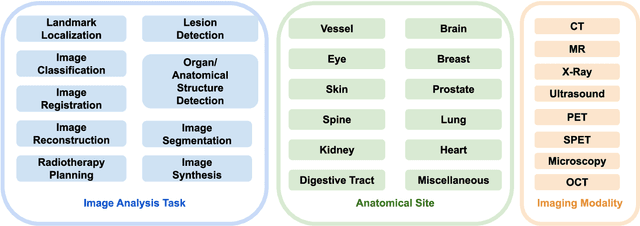
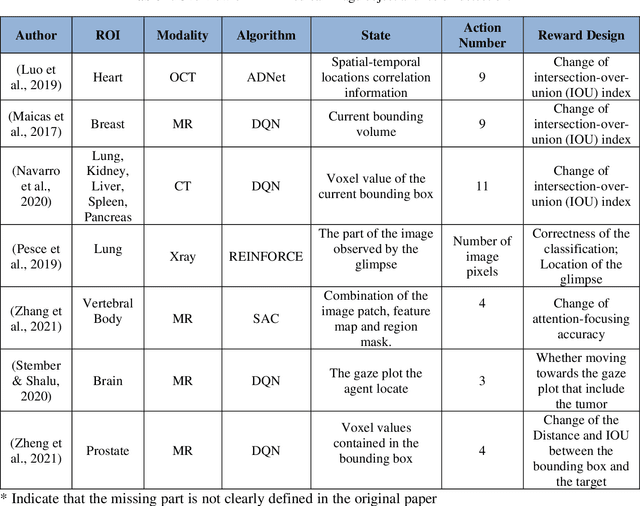
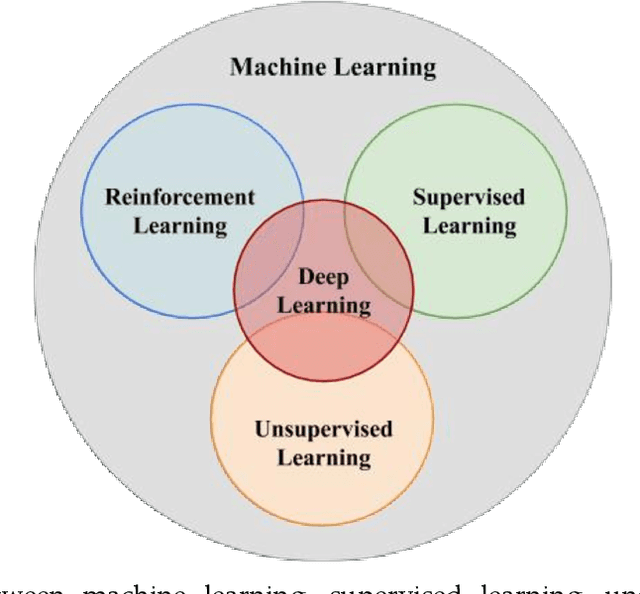
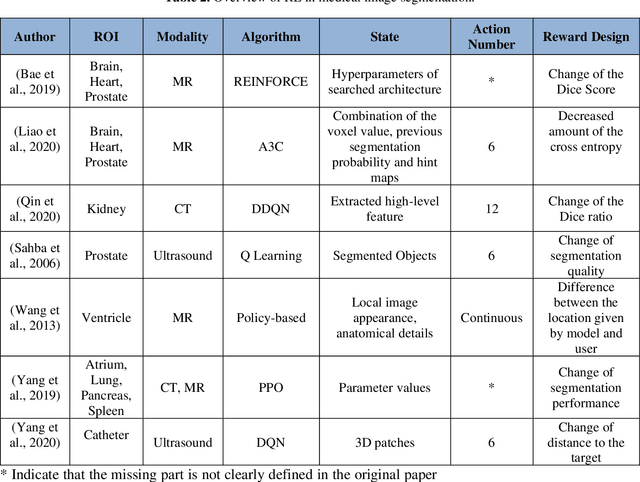
Motivation: Medical image analysis involves tasks to assist physicians in qualitative and quantitative analysis of lesions or anatomical structures, significantly improving the accuracy and reliability of diagnosis and prognosis. Traditionally, these tasks are finished by physicians or medical physicists and lead to two major problems: (i) low efficiency; (ii) biased by personal experience. In the past decade, many machine learning methods have been applied to accelerate and automate the image analysis process. Compared to the enormous deployments of supervised and unsupervised learning models, attempts to use reinforcement learning in medical image analysis are scarce. This review article could serve as the stepping-stone for related research. Significance: From our observation, though reinforcement learning has gradually gained momentum in recent years, many researchers in the medical analysis field find it hard to understand and deploy in clinics. One cause is lacking well-organized review articles targeting readers lacking professional computer science backgrounds. Rather than providing a comprehensive list of all reinforcement learning models in medical image analysis, this paper may help the readers to learn how to formulate and solve their medical image analysis research as reinforcement learning problems. Approach & Results: We selected published articles from Google Scholar and PubMed. Considering the scarcity of related articles, we also included some outstanding newest preprints. The papers are carefully reviewed and categorized according to the type of image analysis task. We first review the basic concepts and popular models of reinforcement learning. Then we explore the applications of reinforcement learning models in landmark detection. Finally, we conclude the article by discussing the reviewed reinforcement learning approaches' limitations and possible improvements.
Retrieval-Augmented Multimodal Language Modeling
Nov 22, 2022
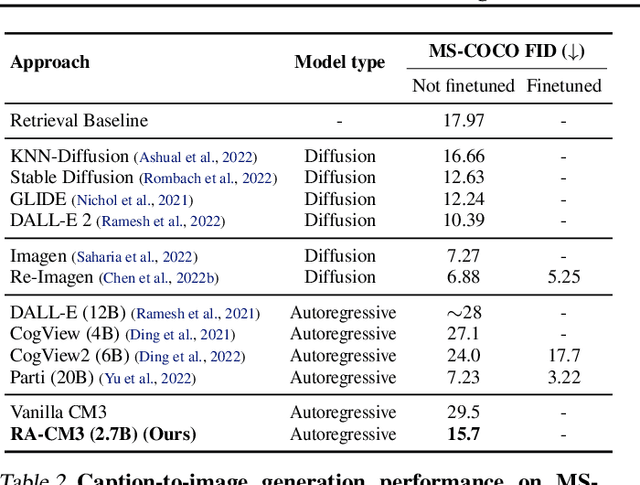
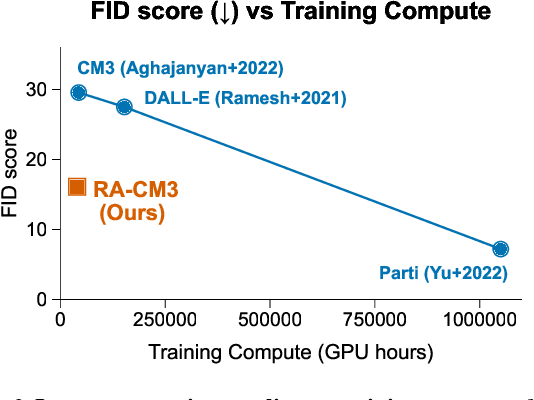
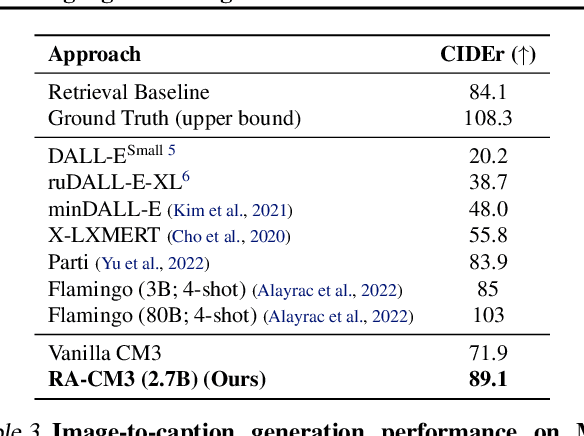
Recent multimodal models such as DALL-E and CM3 have achieved remarkable progress in text-to-image and image-to-text generation. However, these models store all learned knowledge (e.g., the appearance of the Eiffel Tower) in the model parameters, requiring increasingly larger models and training data to capture more knowledge. To integrate knowledge in a more scalable and modular way, we propose a retrieval-augmented multimodal model, which enables a base multimodal model (generator) to refer to relevant knowledge fetched by a retriever from external memory (e.g., multimodal documents on the web). Specifically, we implement a retriever using the pretrained CLIP model and a generator using the CM3 Transformer architecture, and train this model using the LAION dataset. Our resulting model, named Retrieval-Augmented CM3 (RA-CM3), is the first multimodal model that can retrieve and generate mixtures of text and images. We show that RA-CM3 significantly outperforms baseline multimodal models such as DALL-E and CM3 on both image and caption generation tasks (12 FID and 17 CIDEr improvements on MS-COCO), while requiring much less compute for training (<30% of DALL-E). Moreover, we show that RA-CM3 exhibits novel capabilities such as knowledge-intensive image generation and multimodal in-context learning.
Event Camera Data Pre-training
Jan 05, 2023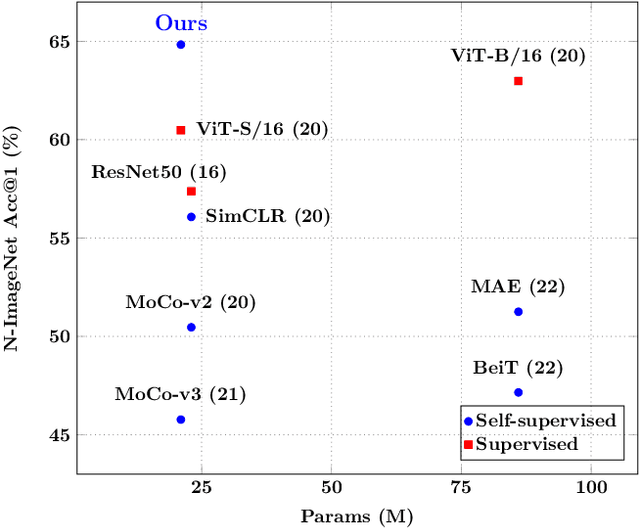
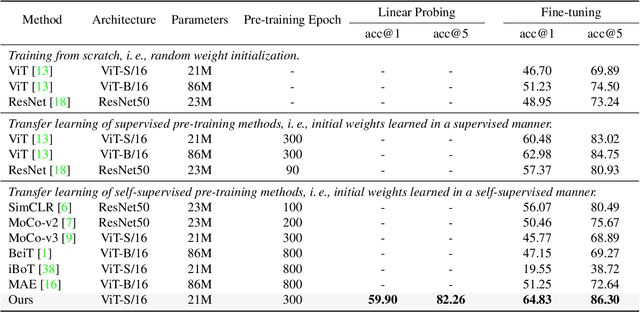
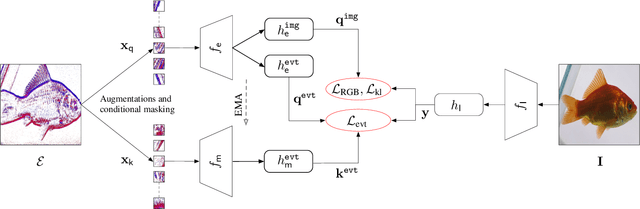
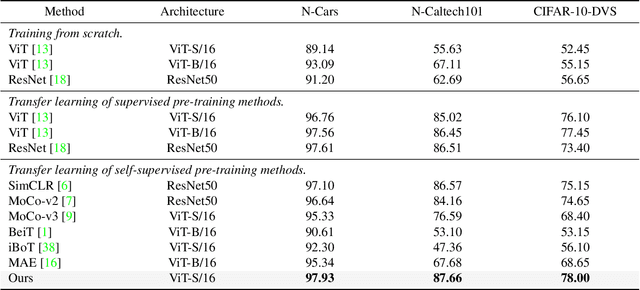
This paper proposes a pre-trained neural network for handling event camera data. Our model is trained in a self-supervised learning framework, and uses paired event camera data and natural RGB images for training. Our method contains three modules connected in a sequence: i) a family of event data augmentations, generating meaningful event images for self-supervised training; ii) a conditional masking strategy to sample informative event patches from event images, encouraging our model to capture the spatial layout of a scene and fast training; iii) a contrastive learning approach, enforcing the similarity of embeddings between matching event images, and between paired event-RGB images. An embedding projection loss is proposed to avoid the model collapse when enforcing event embedding similarities. A probability distribution alignment loss is proposed to encourage the event data to be consistent with its paired RGB image in feature space. Transfer performance in downstream tasks shows superior performance of our method over state-of-the-art methods. For example, we achieve top-1 accuracy at 64.83\% on the N-ImageNet dataset.
LostNet: A smart way for lost and find
Jan 05, 2023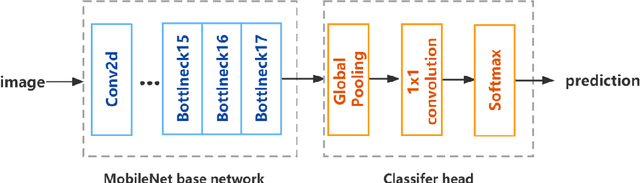
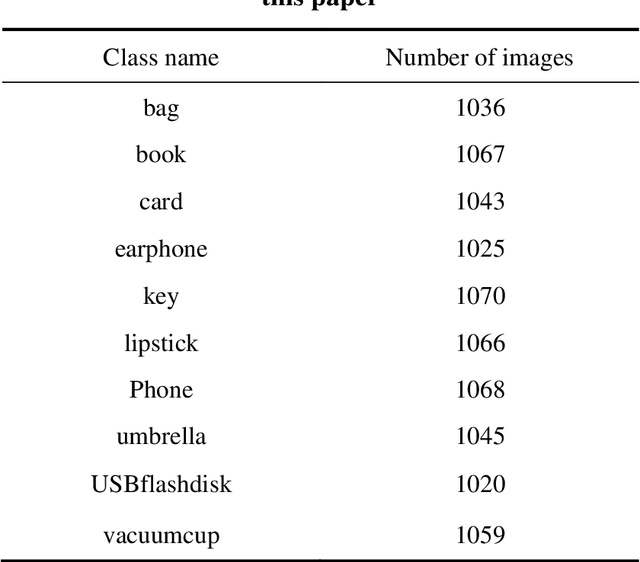
Due to the enormous population growth of cities in recent years, objects are frequently lost and unclaimed on public transportation, in restaurants, or any other public areas. While services like Find My iPhone can easily identify lost electronic devices, more valuable objects cannot be tracked in an intelligent manner, making it impossible for administrators to reclaim a large number of lost and found items in a timely manner. We present a method that significantly reduces the complexity of searching by comparing previous images of lost and recovered things provided by the owner with photos taken when registered lost and found items are received. In this research, we will primarily design a photo matching network by combining the fine-tuning method of MobileNetv2 with CBAM Attention and using the Internet framework to develop an online lost and found image identification system. Our implementation gets a testing accuracy of 96.8% using only 665.12M GLFOPs and 3.5M training parameters. It can recognize practice images and can be run on a regular laptop.
Weakly Supervised Learning Significantly Reduces the Number of Labels Required for Intracranial Hemorrhage Detection on Head CT
Nov 29, 2022

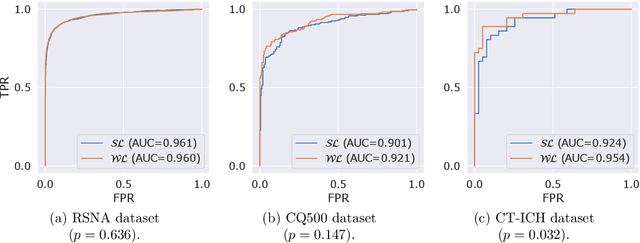
Modern machine learning pipelines, in particular those based on deep learning (DL) models, require large amounts of labeled data. For classification problems, the most common learning paradigm consists of presenting labeled examples during training, thus providing strong supervision on what constitutes positive and negative samples. This constitutes a major obstacle for the development of DL models in radiology--in particular for cross-sectional imaging (e.g., computed tomography [CT] scans)--where labels must come from manual annotations by expert radiologists at the image or slice-level. These differ from examination-level annotations, which are coarser but cheaper, and could be extracted from radiology reports using natural language processing techniques. This work studies the question of what kind of labels should be collected for the problem of intracranial hemorrhage detection in brain CT. We investigate whether image-level annotations should be preferred to examination-level ones. By framing this task as a multiple instance learning problem, and employing modern attention-based DL architectures, we analyze the degree to which different levels of supervision improve detection performance. We find that strong supervision (i.e., learning with local image-level annotations) and weak supervision (i.e., learning with only global examination-level labels) achieve comparable performance in examination-level hemorrhage detection (the task of selecting the images in an examination that show signs of hemorrhage) as well as in image-level hemorrhage detection (highlighting those signs within the selected images). Furthermore, we study this behavior as a function of the number of labels available during training. Our results suggest that local labels may not be necessary at all for these tasks, drastically reducing the time and cost involved in collecting and curating datasets.
Versatile Diffusion: Text, Images and Variations All in One Diffusion Model
Nov 20, 2022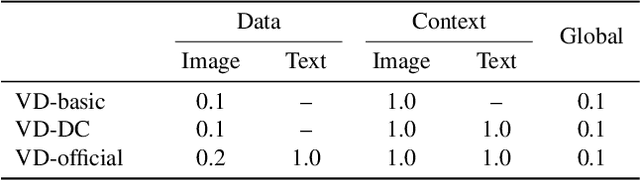
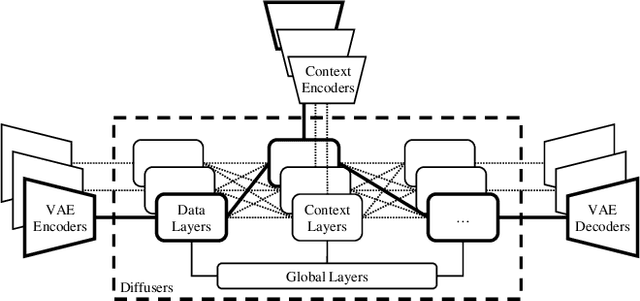
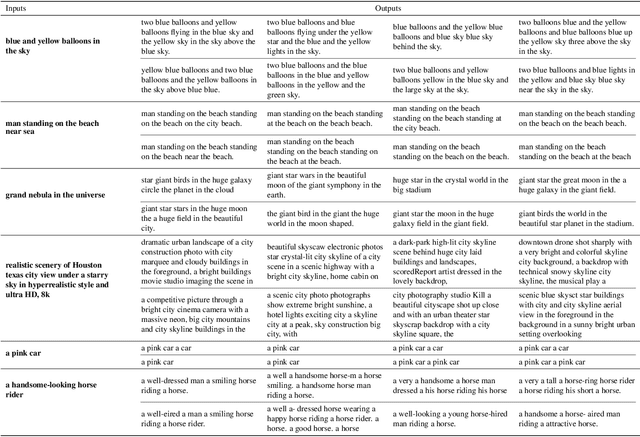
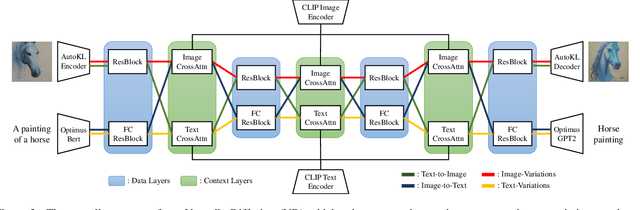
The recent advances in diffusion models have set an impressive milestone in many generation tasks. Trending works such as DALL-E2, Imagen, and Stable Diffusion have attracted great interest in academia and industry. Despite the rapid landscape changes, recent new approaches focus on extensions and performance rather than capacity, thus requiring separate models for separate tasks. In this work, we expand the existing single-flow diffusion pipeline into a multi-flow network, dubbed Versatile Diffusion (VD), that handles text-to-image, image-to-text, image-variation, and text-variation in one unified model. Moreover, we generalize VD to a unified multi-flow multimodal diffusion framework with grouped layers, swappable streams, and other propositions that can process modalities beyond images and text. Through our experiments, we demonstrate that VD and its underlying framework have the following merits: a) VD handles all subtasks with competitive quality; b) VD initiates novel extensions and applications such as disentanglement of style and semantic, image-text dual-guided generation, etc.; c) Through these experiments and applications, VD provides more semantic insights of the generated outputs. Our code and models are open-sourced at https://github.com/SHI-Labs/Versatile-Diffusion.
Structure-Encoding Auxiliary Tasks for Improved Visual Representation in Vision-and-Language Navigation
Nov 20, 2022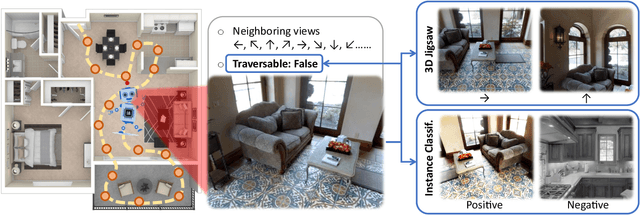
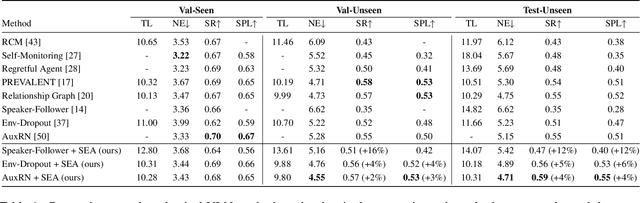
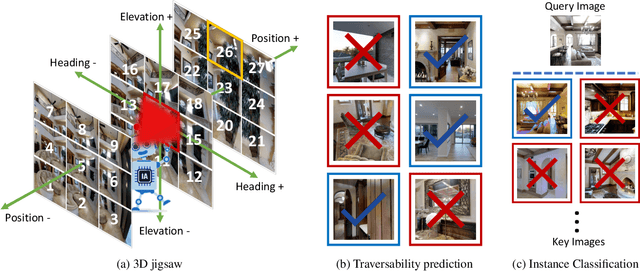
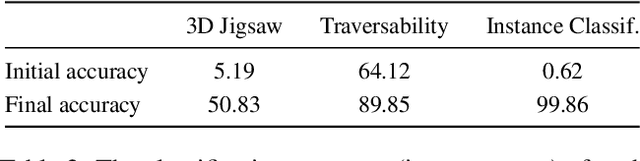
In Vision-and-Language Navigation (VLN), researchers typically take an image encoder pre-trained on ImageNet without fine-tuning on the environments that the agent will be trained or tested on. However, the distribution shift between the training images from ImageNet and the views in the navigation environments may render the ImageNet pre-trained image encoder suboptimal. Therefore, in this paper, we design a set of structure-encoding auxiliary tasks (SEA) that leverage the data in the navigation environments to pre-train and improve the image encoder. Specifically, we design and customize (1) 3D jigsaw, (2) traversability prediction, and (3) instance classification to pre-train the image encoder. Through rigorous ablations, our SEA pre-trained features are shown to better encode structural information of the scenes, which ImageNet pre-trained features fail to properly encode but is crucial for the target navigation task. The SEA pre-trained features can be easily plugged into existing VLN agents without any tuning. For example, on Test-Unseen environments, the VLN agents combined with our SEA pre-trained features achieve absolute success rate improvement of 12% for Speaker-Follower, 5% for Env-Dropout, and 4% for AuxRN.