 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Geometry-Aware Reference Synthesis for Multi-View Image Super-Resolution
Jul 21, 2022
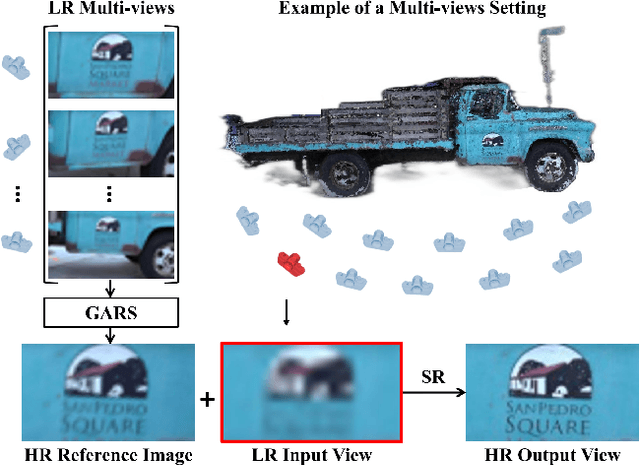
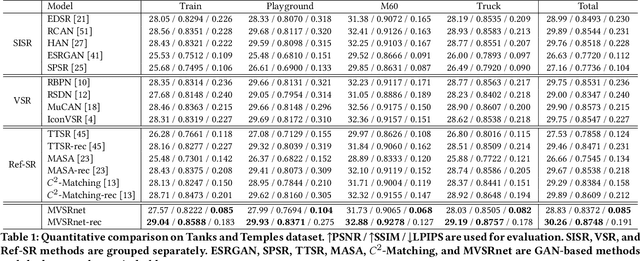

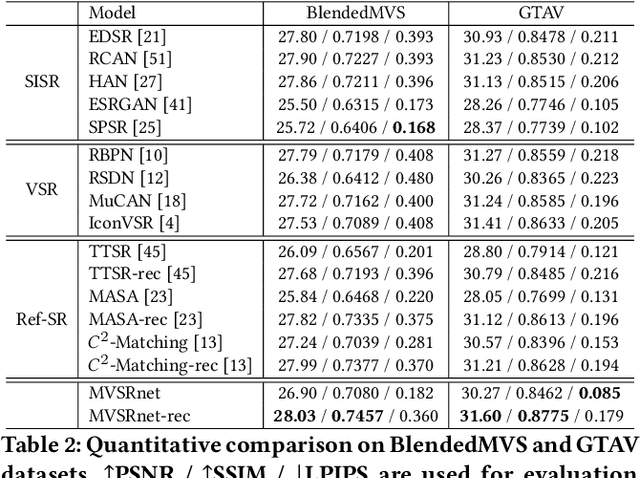
Recent multi-view multimedia applications struggle between high-resolution (HR) visual experience and storage or bandwidth constraints. Therefore, this paper proposes a Multi-View Image Super-Resolution (MVISR) task. It aims to increase the resolution of multi-view images captured from the same scene. One solution is to apply image or video super-resolution (SR) methods to reconstruct HR results from the low-resolution (LR) input view. However, these methods cannot handle large-angle transformations between views and leverage information in all multi-view images. To address these problems, we propose the MVSRnet, which uses geometry information to extract sharp details from all LR multi-view to support the SR of the LR input view. Specifically, the proposed Geometry-Aware Reference Synthesis module in MVSRnet uses geometry information and all multi-view LR images to synthesize pixel-aligned HR reference images. Then, the proposed Dynamic High-Frequency Search network fully exploits the high-frequency textural details in reference images for SR. Extensive experiments on several benchmarks show that our method significantly improves over the state-of-the-art approaches.
Neural Implicit k-Space for Binning-free Non-Cartesian Cardiac MR Imaging
Dec 16, 2022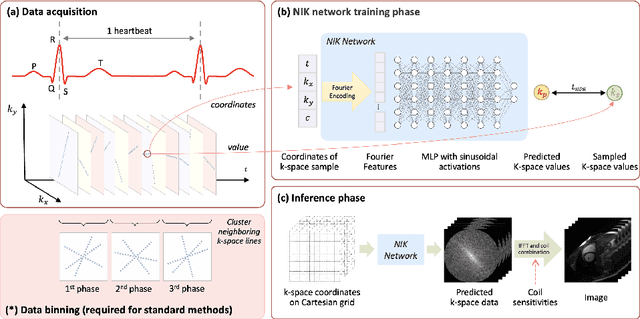
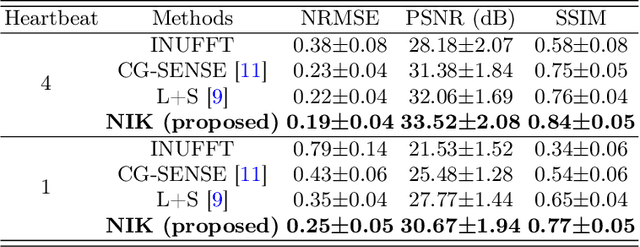
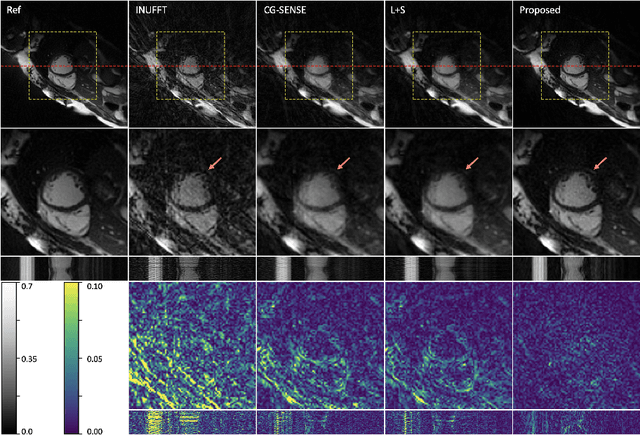
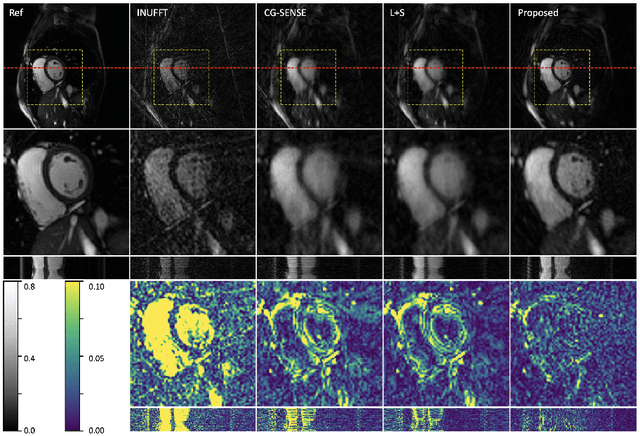
In this work, we propose a novel image reconstruction framework that directly learns a neural implicit representation in k-space for ECG-triggered non-Cartesian Cardiac Magnetic Resonance Imaging (CMR). While existing methods bin acquired data from neighboring time points to reconstruct one phase of the cardiac motion, our framework allows for a continuous, binning-free, and subject-specific k-space representation.We assign a unique coordinate that consists of time, coil index, and frequency domain location to each sampled k-space point. We then learn the subject-specific mapping from these unique coordinates to k-space intensities using a multi-layer perceptron with frequency domain regularization. During inference, we obtain a complete k-space for Cartesian coordinates and an arbitrary temporal resolution. A simple inverse Fourier transform recovers the image, eliminating the need for density compensation and costly non-uniform Fourier transforms for non-Cartesian data. This novel imaging framework was tested on 42 radially sampled datasets from 6 subjects. The proposed method outperforms other techniques qualitatively and quantitatively using data from four and one heartbeat(s) and 30 cardiac phases. Our results for one heartbeat reconstruction of 50 cardiac phases show improved artifact removal and spatio-temporal resolution, leveraging the potential for real-time CMR.
Semi-Siamese Network for Robust Change Detection Across Different Domains with Applications to 3D Printing
Dec 16, 2022
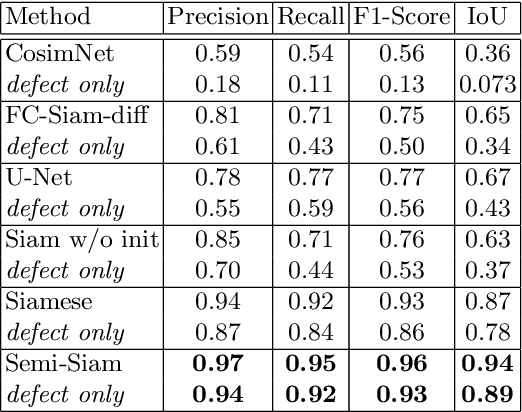

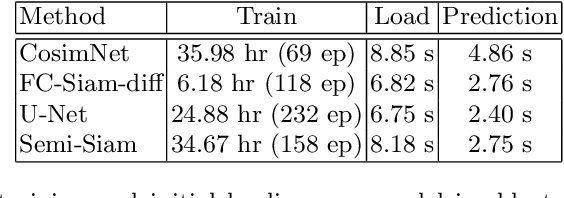
Automatic defect detection for 3D printing processes, which shares many characteristics with change detection problems, is a vital step for quality control of 3D printed products. However, there are some critical challenges in the current state of practice. First, existing methods for computer vision-based process monitoring typically work well only under specific camera viewpoints and lighting situations, requiring expensive pre-processing, alignment, and camera setups. Second, many defect detection techniques are specific to pre-defined defect patterns and/or print schematics. In this work, we approach the automatic defect detection problem differently using a novel Semi-Siamese deep learning model that directly compares a reference schematic of the desired print and a camera image of the achieved print. The model then solves an image segmentation problem, identifying the locations of defects with respect to the reference frame. Unlike most change detection problems, our model is specially developed to handle images coming from different domains and is robust against perturbations in the imaging setup such as camera angle and illumination. Defect localization predictions were made in 2.75 seconds per layer using a standard MacBookPro, which is comparable to the typical tens of seconds or less for printing a single layer on an inkjet-based 3D printer, while achieving an F1-score of more than 0.9.
Advanced Data Augmentation Approaches: A Comprehensive Survey and Future directions
Jan 14, 2023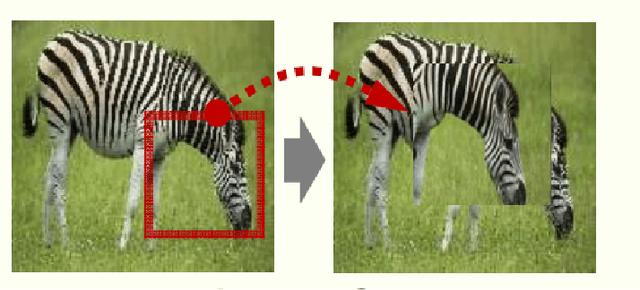
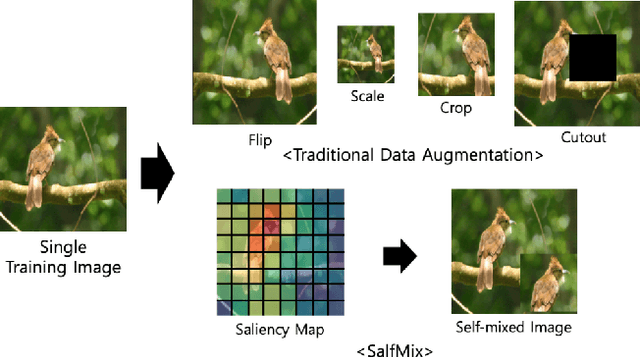


Deep learning (DL) algorithms have shown significant performance in various computer vision tasks. However, having limited labelled data lead to a network overfitting problem, where network performance is bad on unseen data as compared to training data. Consequently, it limits performance improvement. To cope with this problem, various techniques have been proposed such as dropout, normalization and advanced data augmentation. Among these, data augmentation, which aims to enlarge the dataset size by including sample diversity, has been a hot topic in recent times. In this article, we focus on advanced data augmentation techniques. we provide a background of data augmentation, a novel and comprehensive taxonomy of reviewed data augmentation techniques, and the strengths and weaknesses (wherever possible) of each technique. We also provide comprehensive results of the data augmentation effect on three popular computer vision tasks, such as image classification, object detection and semantic segmentation. For results reproducibility, we compiled available codes of all data augmentation techniques. Finally, we discuss the challenges and difficulties, and possible future direction for the research community. We believe, this survey provides several benefits i) readers will understand the data augmentation working mechanism to fix overfitting problems ii) results will save the searching time of the researcher for comparison purposes. iii) Codes of the mentioned data augmentation techniques are available at https://github.com/kmr2017/Advanced-Data-augmentation-codes iv) Future work will spark interest in research community.
Scaling Laws for Generative Mixed-Modal Language Models
Jan 10, 2023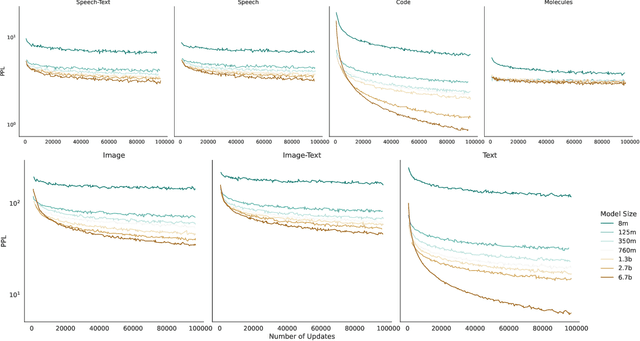
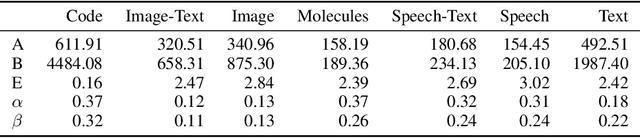
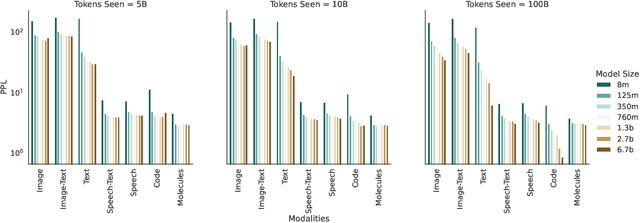
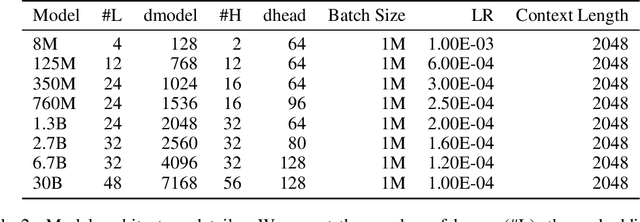
Generative language models define distributions over sequences of tokens that can represent essentially any combination of data modalities (e.g., any permutation of image tokens from VQ-VAEs, speech tokens from HuBERT, BPE tokens for language or code, and so on). To better understand the scaling properties of such mixed-modal models, we conducted over 250 experiments using seven different modalities and model sizes ranging from 8 million to 30 billion, trained on 5-100 billion tokens. We report new mixed-modal scaling laws that unify the contributions of individual modalities and the interactions between them. Specifically, we explicitly model the optimal synergy and competition due to data and model size as an additive term to previous uni-modal scaling laws. We also find four empirical phenomena observed during the training, such as emergent coordinate-ascent style training that naturally alternates between modalities, guidelines for selecting critical hyper-parameters, and connections between mixed-modal competition and training stability. Finally, we test our scaling law by training a 30B speech-text model, which significantly outperforms the corresponding unimodal models. Overall, our research provides valuable insights into the design and training of mixed-modal generative models, an important new class of unified models that have unique distributional properties.
Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling
Jan 10, 2023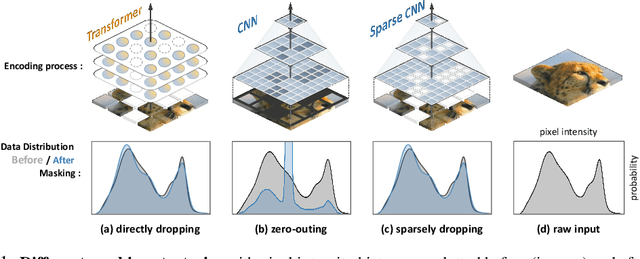
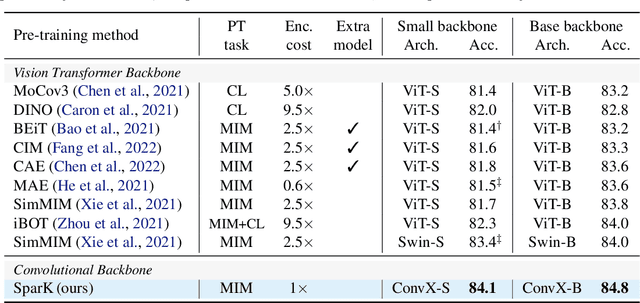
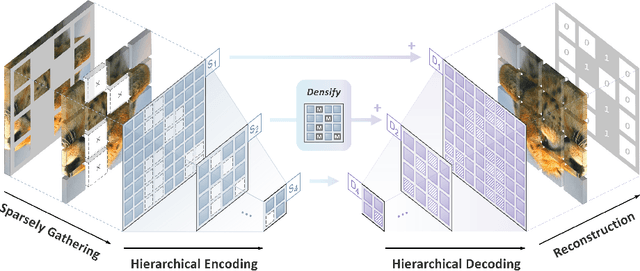
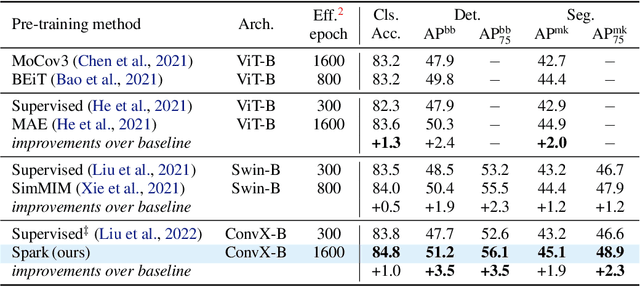
We identify and overcome two key obstacles in extending the success of BERT-style pre-training, or the masked image modeling, to convolutional networks (convnets): (i) convolution operation cannot handle irregular, random-masked input images; (ii) the single-scale nature of BERT pre-training is inconsistent with convnet's hierarchical structure. For (i), we treat unmasked pixels as sparse voxels of 3D point clouds and use sparse convolution to encode. This is the first use of sparse convolution for 2D masked modeling. For (ii), we develop a hierarchical decoder to reconstruct images from multi-scale encoded features. Our method called Sparse masKed modeling (SparK) is general: it can be used directly on any convolutional model without backbone modifications. We validate it on both classical (ResNet) and modern (ConvNeXt) models: on three downstream tasks, it surpasses both state-of-the-art contrastive learning and transformer-based masked modeling by similarly large margins (around +1.0%). Improvements on object detection and instance segmentation are more substantial (up to +3.5%), verifying the strong transferability of features learned. We also find its favorable scaling behavior by observing more gains on larger models. All this evidence reveals a promising future of generative pre-training on convnets. Codes and models are released at https://github.com/keyu-tian/SparK.
Benchmarking Robustness in Neural Radiance Fields
Jan 10, 2023
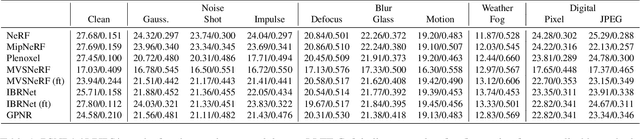


Neural Radiance Field (NeRF) has demonstrated excellent quality in novel view synthesis, thanks to its ability to model 3D object geometries in a concise formulation. However, current approaches to NeRF-based models rely on clean images with accurate camera calibration, which can be difficult to obtain in the real world, where data is often subject to corruption and distortion. In this work, we provide the first comprehensive analysis of the robustness of NeRF-based novel view synthesis algorithms in the presence of different types of corruptions. We find that NeRF-based models are significantly degraded in the presence of corruption, and are more sensitive to a different set of corruptions than image recognition models. Furthermore, we analyze the robustness of the feature encoder in generalizable methods, which synthesize images using neural features extracted via convolutional neural networks or transformers, and find that it only contributes marginally to robustness. Finally, we reveal that standard data augmentation techniques, which can significantly improve the robustness of recognition models, do not help the robustness of NeRF-based models. We hope that our findings will attract more researchers to study the robustness of NeRF-based approaches and help to improve their performance in the real world.
Automated Quantification of Traffic Particulate Emissions via an Image Analysis Pipeline
Nov 24, 2022
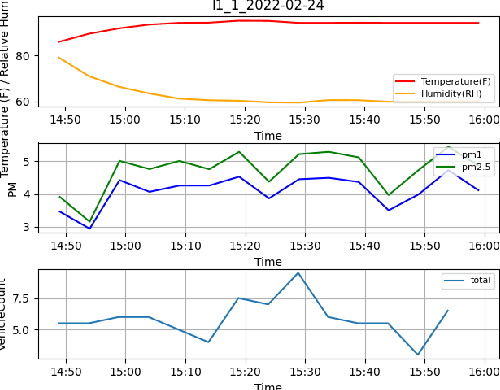
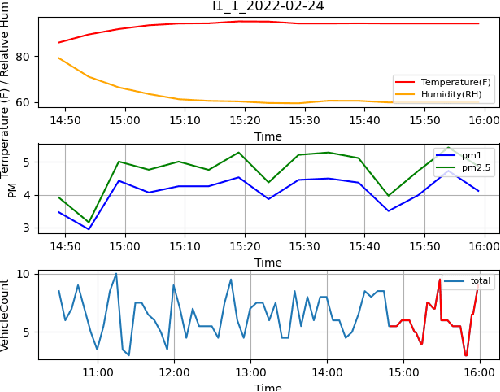
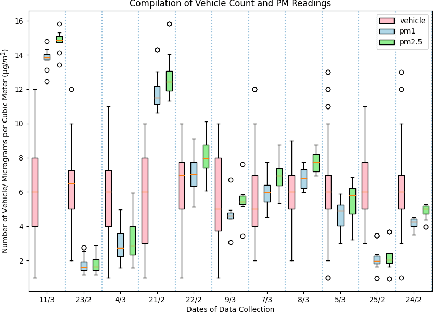
Traffic emissions are known to contribute significantly to air pollution around the world, especially in heavily urbanized cities such as Singapore. It has been previously shown that the particulate pollution along major roadways exhibit strong correlation with increased traffic during peak hours, and that reductions in traffic emissions can lead to better health outcomes. However, in many instances, obtaining proper counts of vehicular traffic remains manual and extremely laborious. This then restricts one's ability to carry out longitudinal monitoring for extended periods, for example, when trying to understand the efficacy of intervention measures such as new traffic regulations (e.g. car-pooling) or for computational modelling. Hence, in this study, we propose and implement an integrated machine learning pipeline that utilizes traffic images to obtain vehicular counts that can be easily integrated with other measurements to facilitate various studies. We verify the utility and accuracy of this pipeline on an open-source dataset of traffic images obtained for a location in Singapore and compare the obtained vehicular counts with collocated particulate measurement data obtained over a 2-week period in 2022. The roadside particulate emission is observed to correlate well with obtained vehicular counts with a correlation coefficient of 0.93, indicating that this method can indeed serve as a quick and effective correlate of particulate emissions.
Facial Image Reconstruction from Functional Magnetic Resonance Imaging via GAN Inversion with Improved Attribute Consistency
Jul 03, 2022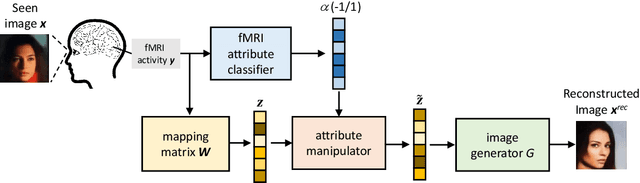

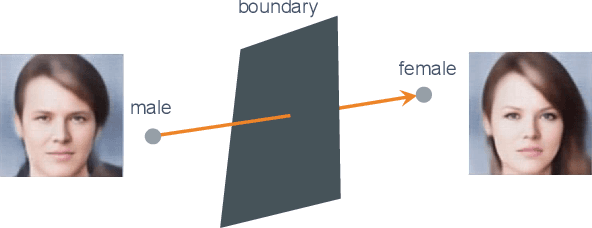

Neuroscience studies have revealed that the brain encodes visual content and embeds information in neural activity. Recently, deep learning techniques have facilitated attempts to address visual reconstructions by mapping brain activity to image stimuli using generative adversarial networks (GANs). However, none of these studies have considered the semantic meaning of latent code in image space. Omitting semantic information could potentially limit the performance. In this study, we propose a new framework to reconstruct facial images from functional Magnetic Resonance Imaging (fMRI) data. With this framework, the GAN inversion is first applied to train an image encoder to extract latent codes in image space, which are then bridged to fMRI data using linear transformation. Following the attributes identified from fMRI data using an attribute classifier, the direction in which to manipulate attributes is decided and the attribute manipulator adjusts the latent code to improve the consistency between the seen image and the reconstructed image. Our experimental results suggest that the proposed framework accomplishes two goals: (1) reconstructing clear facial images from fMRI data and (2) maintaining the consistency of semantic characteristics.
DiffusionInst: Diffusion Model for Instance Segmentation
Dec 07, 2022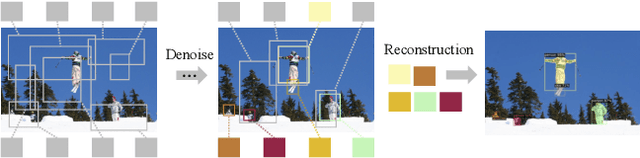
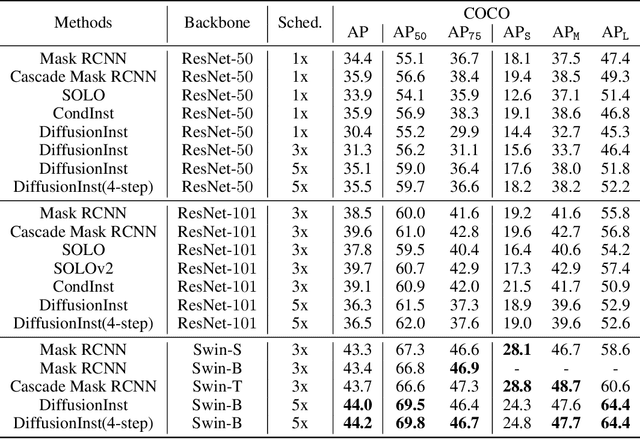
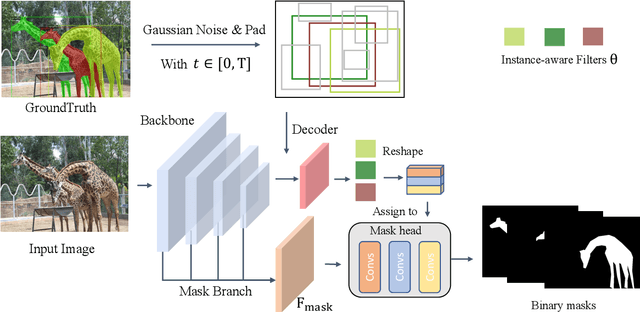
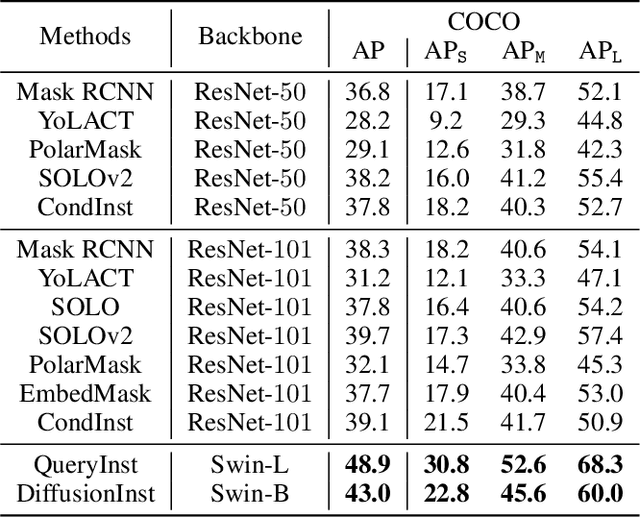
Recently, diffusion frameworks have achieved comparable performance with previous state-of-the-art image generation models. Researchers are curious about its variants in discriminative tasks because of its powerful noise-to-image denoising pipeline. This paper proposes DiffusionInst, a novel framework that represents instances as instance-aware filters and formulates instance segmentation as a noise-to-filter denoising process. The model is trained to reverse the noisy groundtruth without any inductive bias from RPN. During inference, it takes a randomly generated filter as input and outputs mask in one-step or multi-step denoising. Extensive experimental results on COCO and LVIS show that DiffusionInst achieves competitive performance compared to existing instance segmentation models. We hope our work could serve as a simple yet effective baseline, which could inspire designing more efficient diffusion frameworks for challenging discriminative tasks. Our code is available in https://github.com/chenhaoxing/DiffusionInst.