 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Explaining Deepfake Detection by Analysing Image Matching
Jul 20, 2022

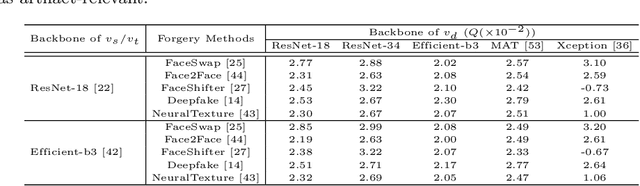
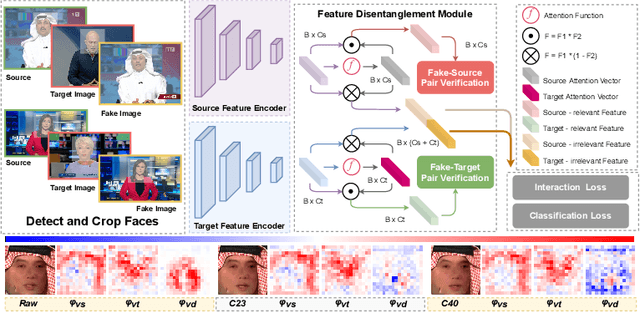
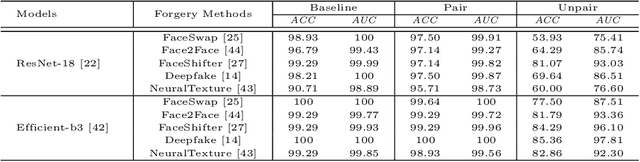
This paper aims to interpret how deepfake detection models learn artifact features of images when just supervised by binary labels. To this end, three hypotheses from the perspective of image matching are proposed as follows. 1. Deepfake detection models indicate real/fake images based on visual concepts that are neither source-relevant nor target-relevant, that is, considering such visual concepts as artifact-relevant. 2. Besides the supervision of binary labels, deepfake detection models implicitly learn artifact-relevant visual concepts through the FST-Matching (i.e. the matching fake, source, target images) in the training set. 3. Implicitly learned artifact visual concepts through the FST-Matching in the raw training set are vulnerable to video compression. In experiments, the above hypotheses are verified among various DNNs. Furthermore, based on this understanding, we propose the FST-Matching Deepfake Detection Model to boost the performance of forgery detection on compressed videos. Experiment results show that our method achieves great performance, especially on highly-compressed (e.g. c40) videos.
MLC at HECKTOR 2022: The Effect and Importance of Training Data when Analyzing Cases of Head and Neck Tumors using Machine Learning
Nov 30, 2022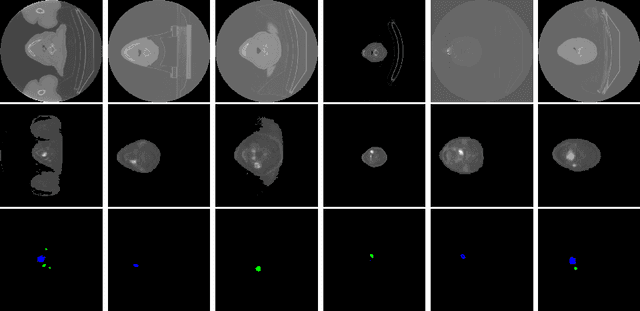
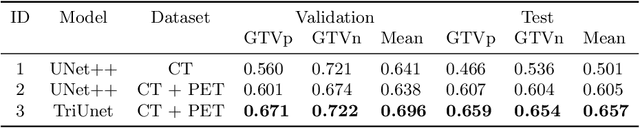
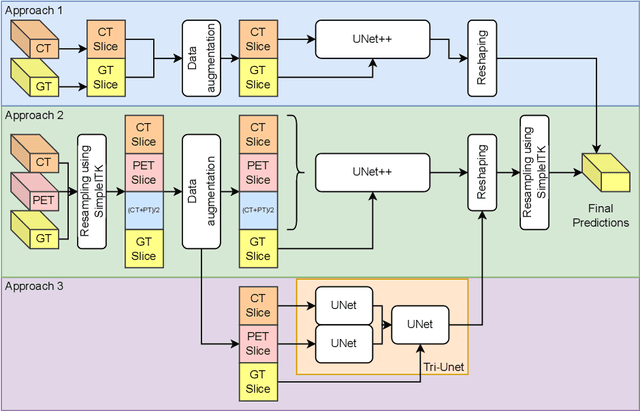

Head and neck cancers are the fifth most common cancer worldwide, and recently, analysis of Positron Emission Tomography (PET) and Computed Tomography (CT) images has been proposed to identify patients with a prognosis. Even though the results look promising, more research is needed to further validate and improve the results. This paper presents the work done by team MLC for the 2022 version of the HECKTOR grand challenge held at MICCAI 2022. For Task 1, the automatic segmentation task, our approach was, in contrast to earlier solutions using 3D segmentation, to keep it as simple as possible using a 2D model, analyzing every slice as a standalone image. In addition, we were interested in understanding how different modalities influence the results. We proposed two approaches; one using only the CT scans to make predictions and another using a combination of the CT and PET scans. For Task 2, the prediction of recurrence-free survival, we first proposed two approaches, one where we only use patient data and one where we combined the patient data with segmentations from the image model. For the prediction of the first two approaches, we used Random Forest. In our third approach, we combined patient data and image data using XGBoost. Low kidney function might worsen cancer prognosis. In this approach, we therefore estimated the kidney function of the patients and included it as a feature. Overall, we conclude that our simple methods were not able to compete with the highest-ranking submissions, but we still obtained reasonably good scores. We also got interesting insights into how the combination of different modalities can influence the segmentation and predictions.
Knowledge Distillation based Degradation Estimation for Blind Super-Resolution
Nov 30, 2022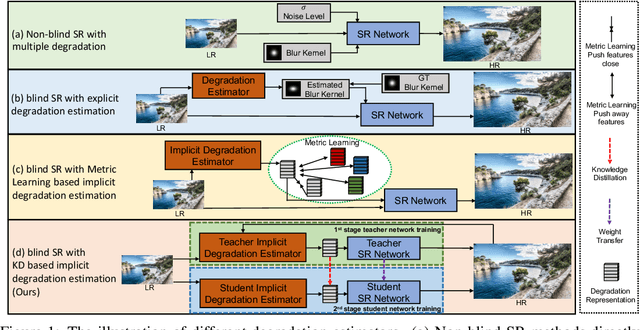
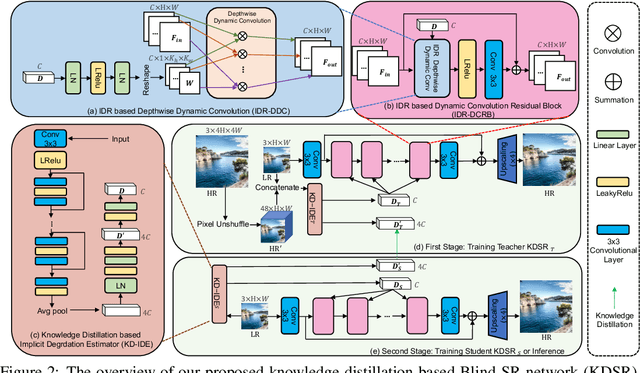
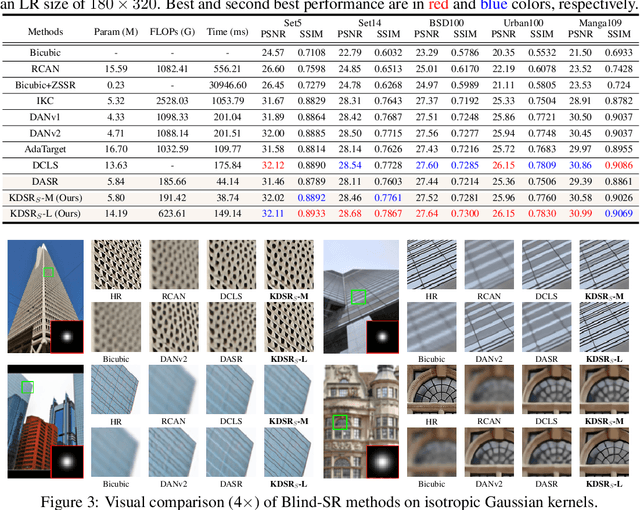
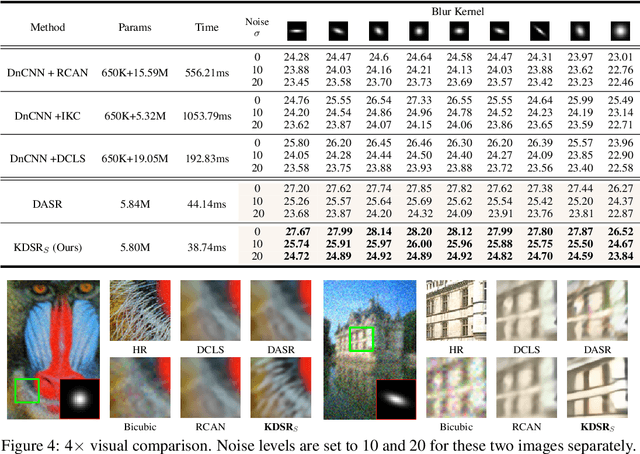
Blind image super-resolution (Blind-SR) aims to recover a high-resolution (HR) image from its corresponding low-resolution (LR) input image with unknown degradations. Most of the existing works design an explicit degradation estimator for each degradation to guide SR. However, it is infeasible to provide concrete labels of multiple degradation combinations (\eg, blur, noise, jpeg compression) to supervise the degradation estimator training. In addition, these special designs for certain degradation, such as blur, impedes the models from being generalized to handle different degradations. To this end, it is necessary to design an implicit degradation estimator that can extract discriminative degradation representation for all degradations without relying on the supervision of degradation ground-truth. In this paper, we propose a Knowledge Distillation based Blind-SR network (KDSR). It consists of a knowledge distillation based implicit degradation estimator network (KD-IDE) and an efficient SR network. To learn the KDSR model, we first train a teacher network: KD-IDE$_{T}$. It takes paired HR and LR patches as inputs and is optimized with the SR network jointly. Then, we further train a student network KD-IDE$_{S}$, which only takes LR images as input and learns to extract the same implicit degradation representation (IDR) as KD-IDE$_{T}$. In addition, to fully use extracted IDR, we design a simple, strong, and efficient IDR based dynamic convolution residual block (IDR-DCRB) to build an SR network. We conduct extensive experiments under classic and real-world degradation settings. The results show that KDSR achieves SOTA performance and can generalize to various degradation processes. The source codes and pre-trained models will be released.
Personalizing Federated Medical Image Segmentation via Local Calibration
Jul 11, 2022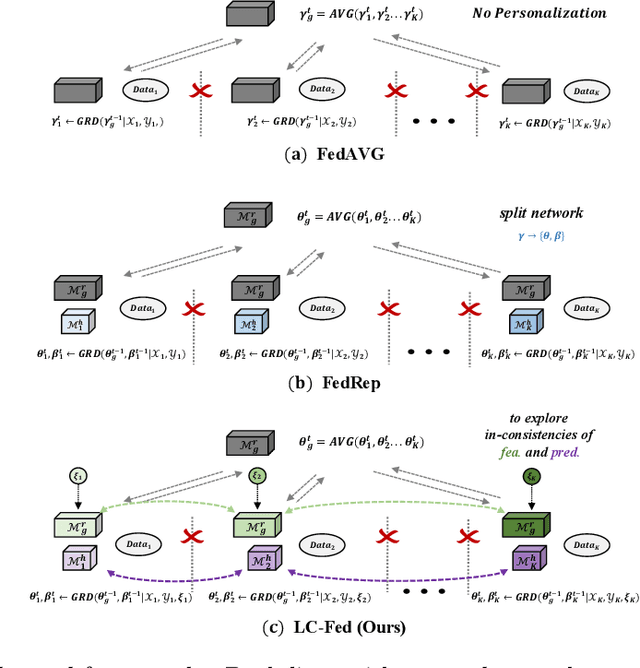
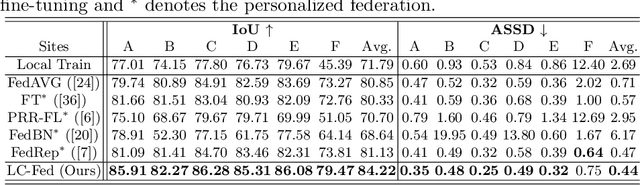
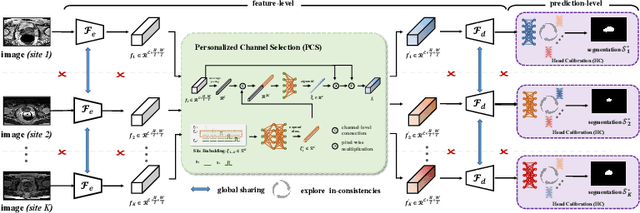
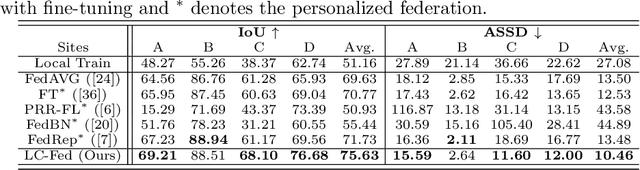
Medical image segmentation under federated learning (FL) is a promising direction by allowing multiple clinical sites to collaboratively learn a global model without centralizing datasets. However, using a single model to adapt to various data distributions from different sites is extremely challenging. Personalized FL tackles this issue by only utilizing partial model parameters shared from global server, while keeping the rest to adapt to its own data distribution in the local training of each site. However, most existing methods concentrate on the partial parameter splitting, while do not consider the \textit{inter-site in-consistencies} during the local training, which in fact can facilitate the knowledge communication over sites to benefit the model learning for improving the local accuracy. In this paper, we propose a personalized federated framework with \textbf{L}ocal \textbf{C}alibration (LC-Fed), to leverage the inter-site in-consistencies in both \textit{feature- and prediction- levels} to boost the segmentation. Concretely, as each local site has its alternative attention on the various features, we first design the contrastive site embedding coupled with channel selection operation to calibrate the encoded features. Moreover, we propose to exploit the knowledge of prediction-level in-consistency to guide the personalized modeling on the ambiguous regions, e.g., anatomical boundaries. It is achieved by computing a disagreement-aware map to calibrate the prediction. Effectiveness of our method has been verified on three medical image segmentation tasks with different modalities, where our method consistently shows superior performance to the state-of-the-art personalized FL methods. Code is available at https://github.com/jcwang123/FedLC.
D2HNet: Joint Denoising and Deblurring with Hierarchical Network for Robust Night Image Restoration
Jul 07, 2022
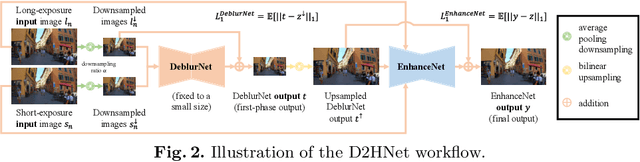
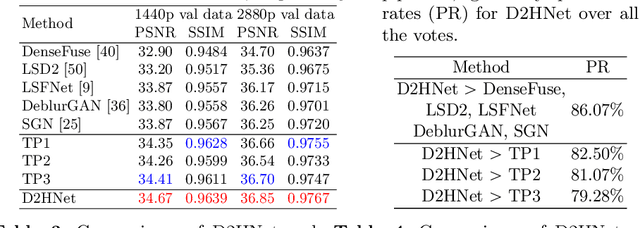
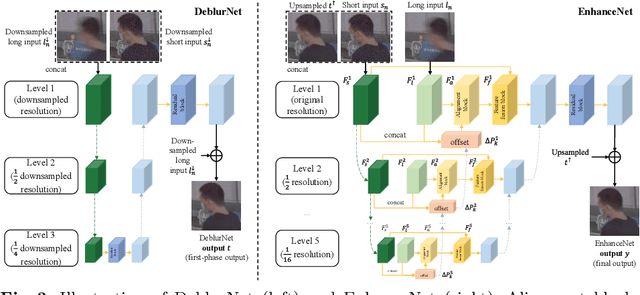
Night imaging with modern smartphone cameras is troublesome due to low photon count and unavoidable noise in the imaging system. Directly adjusting exposure time and ISO ratings cannot obtain sharp and noise-free images at the same time in low-light conditions. Though many methods have been proposed to enhance noisy or blurry night images, their performances on real-world night photos are still unsatisfactory due to two main reasons: 1) Limited information in a single image and 2) Domain gap between synthetic training images and real-world photos (e.g., differences in blur area and resolution). To exploit the information from successive long- and short-exposure images, we propose a learning-based pipeline to fuse them. A D2HNet framework is developed to recover a high-quality image by deblurring and enhancing a long-exposure image under the guidance of a short-exposure image. To shrink the domain gap, we leverage a two-phase DeblurNet-EnhanceNet architecture, which performs accurate blur removal on a fixed low resolution so that it is able to handle large ranges of blur in different resolution inputs. In addition, we synthesize a D2-Dataset from HD videos and experiment on it. The results on the validation set and real photos demonstrate our methods achieve better visual quality and state-of-the-art quantitative scores. The D2HNet codes, models, and D2-Dataset can be found at https://github.com/zhaoyuzhi/D2HNet.
DAQE: Enhancing the Quality of Compressed Images by Finding the Secret of Defocus
Nov 20, 2022
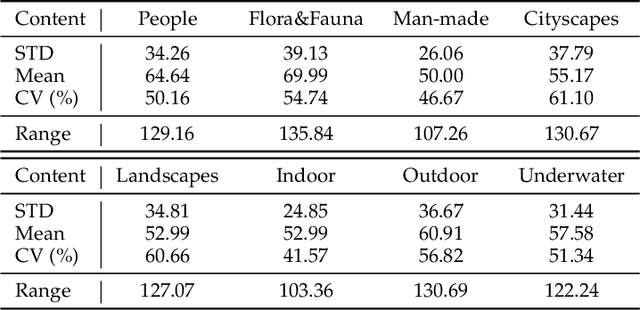

Image defocus is inherent in the physics of image formation caused by the optical aberration of lenses, providing plentiful information on image quality. Unfortunately, the existing quality enhancement approaches for compressed images neglect the inherent characteristic of defocus, resulting in inferior performance. This paper finds that in compressed images, the significantly defocused regions are with better compression quality and two regions with different defocus values possess diverse texture patterns. These findings motivate our defocus-aware quality enhancement (DAQE) approach. Specifically, we propose a novel dynamic region-based deep learning architecture of the DAQE approach, which considers the region-wise defocus difference of compressed images in two aspects. (1) The DAQE approach employs fewer computational resources to enhance the quality of significantly defocused regions, while more resources on enhancing the quality of other regions; (2) The DAQE approach learns to separately enhance diverse texture patterns for the regions with different defocus values, such that texture-wise one-on-one enhancement can be achieved. Extensive experiments validate the superiority of our DAQE approach in terms of quality enhancement and resource-saving, compared with other state-of-the-art approaches.
Synthesizing Annotated Image and Video Data Using a Rendering-Based Pipeline for Improved License Plate Recognition
Sep 28, 2022


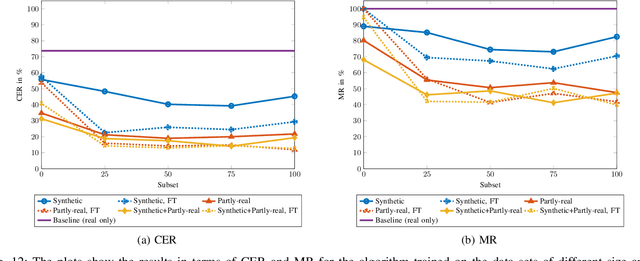
An insufficient number of training samples is a common problem in neural network applications. While data augmentation methods require at least a minimum number of samples, we propose a novel, rendering-based pipeline for synthesizing annotated data sets. Our method does not modify existing samples but synthesizes entirely new samples. The proposed rendering-based pipeline is capable of generating and annotating synthetic and partly-real image and video data in a fully automatic procedure. Moreover, the pipeline can aid the acquisition of real data. The proposed pipeline is based on a rendering process. This process generates synthetic data. Partly-real data bring the synthetic sequences closer to reality by incorporating real cameras during the acquisition process. The benefits of the proposed data generation pipeline, especially for machine learning scenarios with limited available training data, are demonstrated by an extensive experimental validation in the context of automatic license plate recognition. The experiments demonstrate a significant reduction of the character error rate and miss rate from 73.74% and 100% to 14.11% and 41.27% respectively, compared to an OCR algorithm trained on a real data set solely. These improvements are achieved by training the algorithm on synthesized data solely. When additionally incorporating real data, the error rates can be decreased further. Thereby, the character error rate and miss rate can be reduced to 11.90% and 39.88% respectively. All data used during the experiments as well as the proposed rendering-based pipeline for the automated data generation is made publicly available under (URL will be revealed upon publication).
Source-Free Unsupervised Domain Adaptation with Norm and Shape Constraints for Medical Image Segmentation
Sep 03, 2022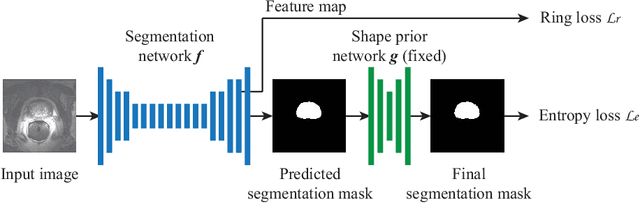


Unsupervised domain adaptation (UDA) is one of the key technologies to solve a problem where it is hard to obtain ground truth labels needed for supervised learning. In general, UDA assumes that all samples from source and target domains are available during the training process. However, this is not a realistic assumption under applications where data privacy issues are concerned. To overcome this limitation, UDA without source data, referred to source-free unsupervised domain adaptation (SFUDA) has been recently proposed. Here, we propose a SFUDA method for medical image segmentation. In addition to the entropy minimization method, which is commonly used in UDA, we introduce a loss function for avoiding feature norms in the target domain small and a prior to preserve shape constraints of the target organ. We conduct experiments using datasets including multiple types of source-target domain combinations in order to show the versatility and robustness of our method. We confirm that our method outperforms the state-of-the-art in all datasets.
PCCT: Progressive Class-Center Triplet Loss for Imbalanced Medical Image Classification
Jul 11, 2022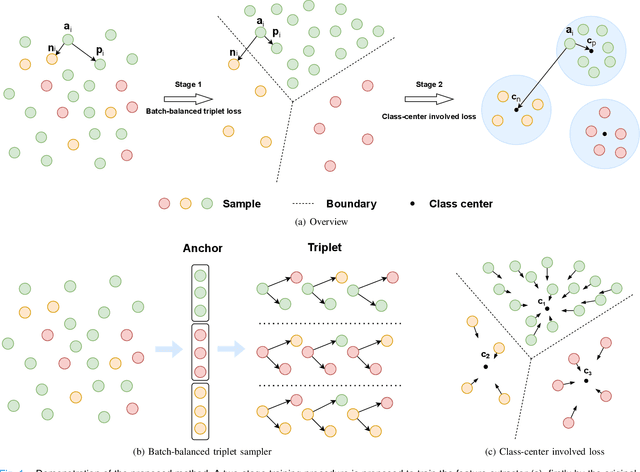
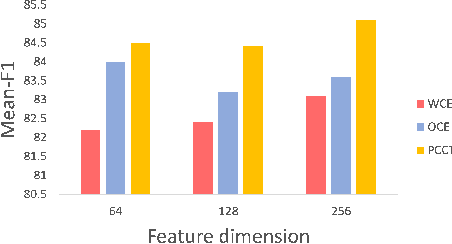

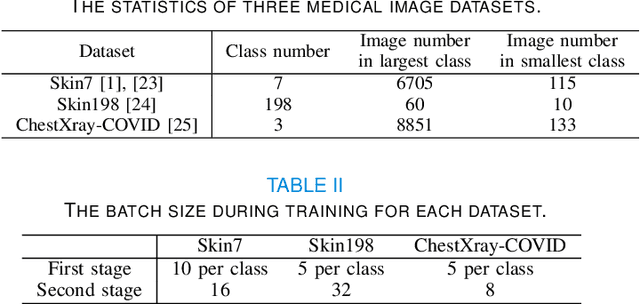
Imbalanced training data is a significant challenge for medical image classification. In this study, we propose a novel Progressive Class-Center Triplet (PCCT) framework to alleviate the class imbalance issue particularly for diagnosis of rare diseases, mainly by carefully designing the triplet sampling strategy and the triplet loss formation. Specifically, the PCCT framework includes two successive stages. In the first stage, PCCT trains the diagnosis system via a class-balanced triplet loss to coarsely separate distributions of different classes. In the second stage, the PCCT framework further improves the diagnosis system via a class-center involved triplet loss to cause a more compact distribution for each class. For the class-balanced triplet loss, triplets are sampled equally for each class at each training iteration, thus alleviating the imbalanced data issue. For the class-center involved triplet loss, the positive and negative samples in each triplet are replaced by their corresponding class centers, which enforces data representations of the same class closer to the class center. Furthermore, the class-center involved triplet loss is extended to the pair-wise ranking loss and the quadruplet loss, which demonstrates the generalization of the proposed framework. Extensive experiments support that the PCCT framework works effectively for medical image classification with imbalanced training images. On two skin image datasets and one chest X-ray dataset, the proposed approach respectively obtains the mean F1 score 86.2, 65.2, and 90.66 over all classes and 81.4, 63.87, and 81.92 for rare classes, achieving state-of-the-art performance and outperforming the widely used methods for the class imbalance issue.
DeepMatcher: A Deep Transformer-based Network for Robust and Accurate Local Feature Matching
Jan 08, 2023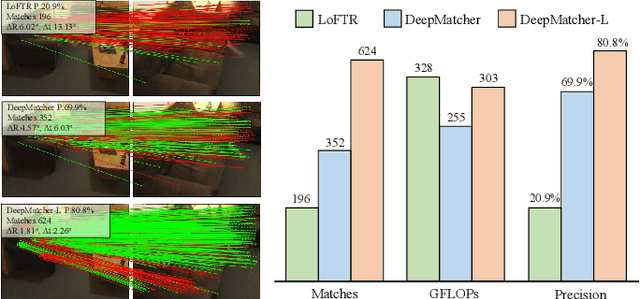
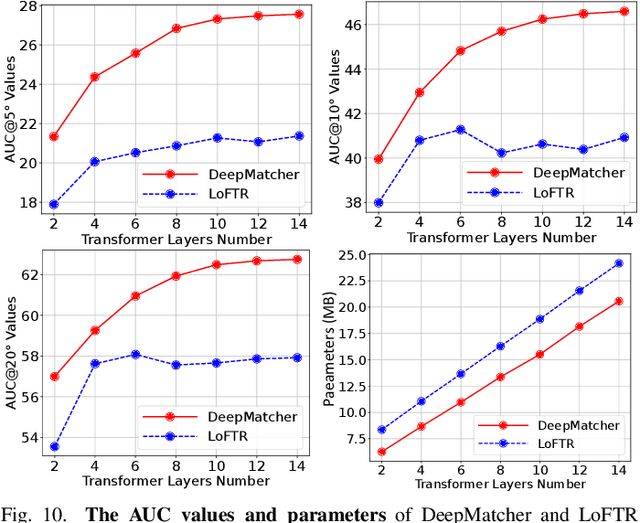
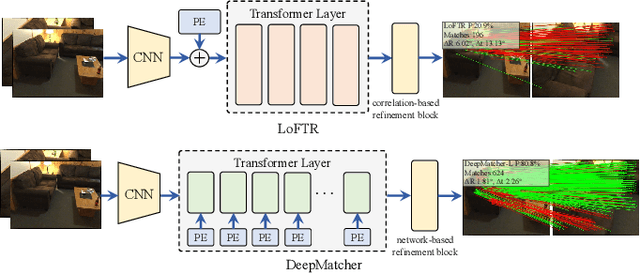
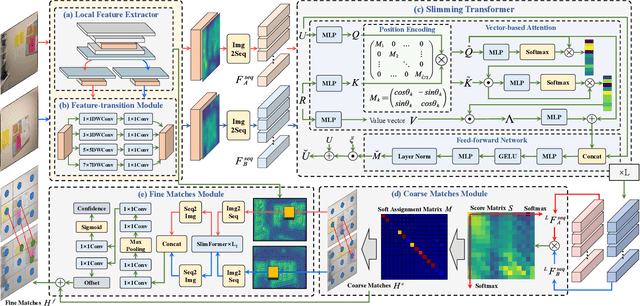
Local feature matching between images remains a challenging task, especially in the presence of significant appearance variations, e.g., extreme viewpoint changes. In this work, we propose DeepMatcher, a deep Transformer-based network built upon our investigation of local feature matching in detector-free methods. The key insight is that local feature matcher with deep layers can capture more human-intuitive and simpler-to-match features. Based on this, we propose a Slimming Transformer (SlimFormer) dedicated for DeepMatcher, which leverages vector-based attention to model relevance among all keypoints and achieves long-range context aggregation in an efficient and effective manner. A relative position encoding is applied to each SlimFormer so as to explicitly disclose relative distance information, further improving the representation of keypoints. A layer-scale strategy is also employed in each SlimFormer to enable the network to assimilate message exchange from the residual block adaptively, thus allowing it to simulate the human behaviour that humans can acquire different matching cues each time they scan an image pair. To facilitate a better adaption of the SlimFormer, we introduce a Feature Transition Module (FTM) to ensure a smooth transition in feature scopes with different receptive fields. By interleaving the self- and cross-SlimFormer multiple times, DeepMatcher can easily establish pixel-wise dense matches at coarse level. Finally, we perceive the match refinement as a combination of classification and regression problems and design Fine Matches Module to predict confidence and offset concurrently, thereby generating robust and accurate matches. Experimentally, we show that DeepMatcher significantly outperforms the state-of-the-art methods on several benchmarks, demonstrating the superior matching capability of DeepMatcher.