 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Extrinsic Bayesian Optimizations on Manifolds
Dec 29, 2022
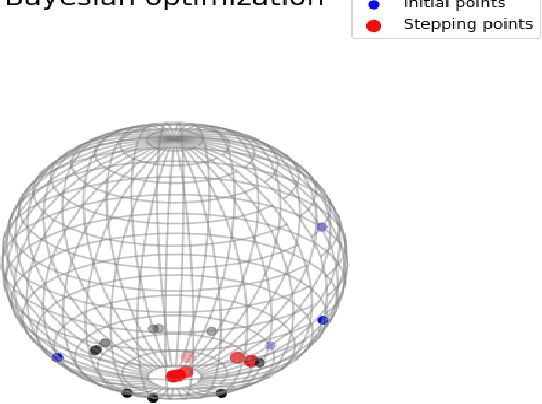
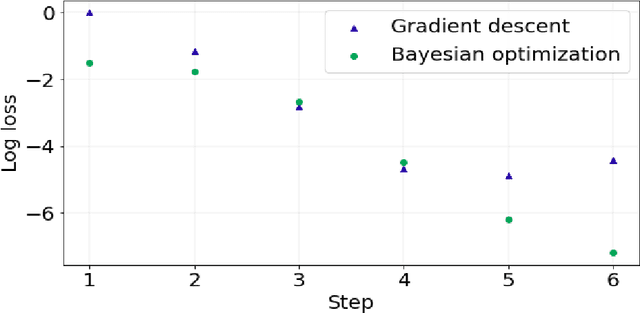
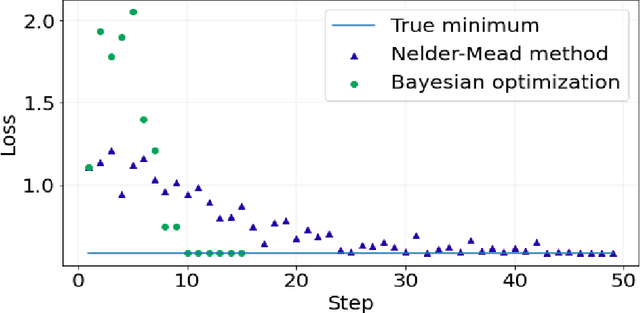
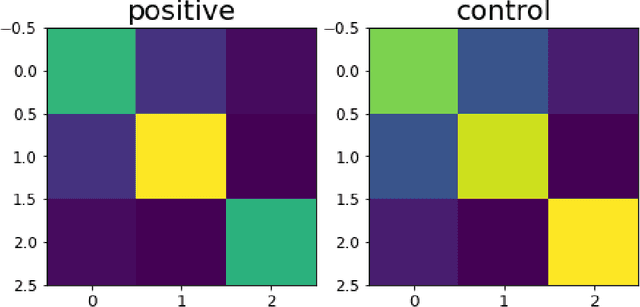
We propose an extrinsic Bayesian optimization (eBO) framework for general optimization problems on manifolds. Bayesian optimization algorithms build a surrogate of the objective function by employing Gaussian processes and quantify the uncertainty in that surrogate by deriving an acquisition function. This acquisition function represents the probability of improvement based on the kernel of the Gaussian process, which guides the search in the optimization process. The critical challenge for designing Bayesian optimization algorithms on manifolds lies in the difficulty of constructing valid covariance kernels for Gaussian processes on general manifolds. Our approach is to employ extrinsic Gaussian processes by first embedding the manifold onto some higher dimensional Euclidean space via equivariant embeddings and then constructing a valid covariance kernel on the image manifold after the embedding. This leads to efficient and scalable algorithms for optimization over complex manifolds. Simulation study and real data analysis are carried out to demonstrate the utilities of our eBO framework by applying the eBO to various optimization problems over manifolds such as the sphere, the Grassmannian, and the manifold of positive definite matrices.
TPFNet: A Novel Text In-painting Transformer for Text Removal
Oct 27, 2022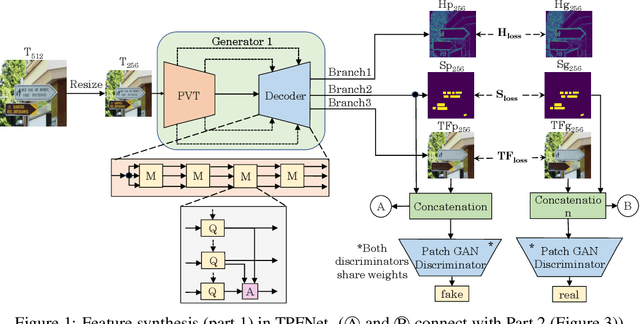
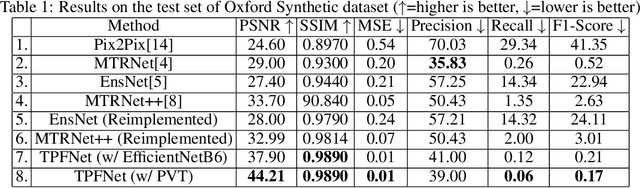
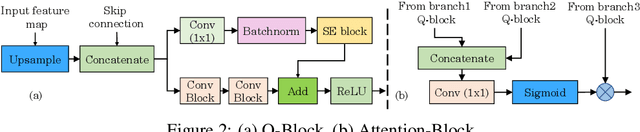
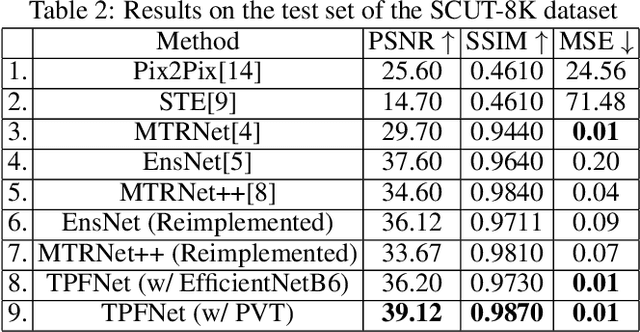
Text erasure from an image is helpful for various tasks such as image editing and privacy preservation. In this paper, we present TPFNet, a novel one-stage (end-toend) network for text removal from images. Our network has two parts: feature synthesis and image generation. Since noise can be more effectively removed from low-resolution images, part 1 operates on low-resolution images. The output of part 1 is a low-resolution text-free image. Part 2 uses the features learned in part 1 to predict a high-resolution text-free image. In part 1, we use "pyramidal vision transformer" (PVT) as the encoder. Further, we use a novel multi-headed decoder that generates a high-pass filtered image and a segmentation map, in addition to a text-free image. The segmentation branch helps locate the text precisely, and the high-pass branch helps in learning the image structure. To precisely locate the text, TPFNet employs an adversarial loss that is conditional on the segmentation map rather than the input image. On Oxford, SCUT, and SCUT-EnsText datasets, our network outperforms recently proposed networks on nearly all the metrics. For example, on SCUT-EnsText dataset, TPFNet has a PSNR (higher is better) of 39.0 and text-detection precision (lower is better) of 21.1, compared to the best previous technique, which has a PSNR of 32.3 and precision of 53.2. The source code can be obtained from https://github.com/CandleLabAI/TPFNet
D2HNet: Joint Denoising and Deblurring with Hierarchical Network for Robust Night Image Restoration
Jul 07, 2022
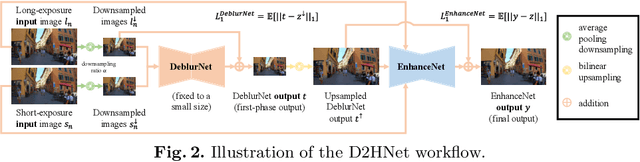
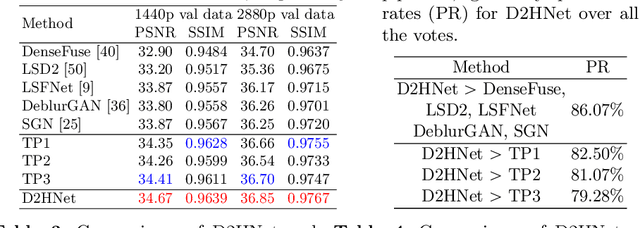
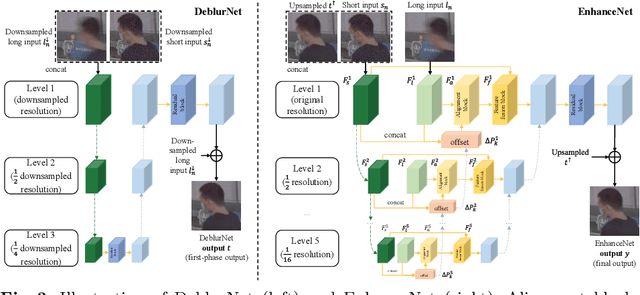
Night imaging with modern smartphone cameras is troublesome due to low photon count and unavoidable noise in the imaging system. Directly adjusting exposure time and ISO ratings cannot obtain sharp and noise-free images at the same time in low-light conditions. Though many methods have been proposed to enhance noisy or blurry night images, their performances on real-world night photos are still unsatisfactory due to two main reasons: 1) Limited information in a single image and 2) Domain gap between synthetic training images and real-world photos (e.g., differences in blur area and resolution). To exploit the information from successive long- and short-exposure images, we propose a learning-based pipeline to fuse them. A D2HNet framework is developed to recover a high-quality image by deblurring and enhancing a long-exposure image under the guidance of a short-exposure image. To shrink the domain gap, we leverage a two-phase DeblurNet-EnhanceNet architecture, which performs accurate blur removal on a fixed low resolution so that it is able to handle large ranges of blur in different resolution inputs. In addition, we synthesize a D2-Dataset from HD videos and experiment on it. The results on the validation set and real photos demonstrate our methods achieve better visual quality and state-of-the-art quantitative scores. The D2HNet codes, models, and D2-Dataset can be found at https://github.com/zhaoyuzhi/D2HNet.
Exposure Correction Model to Enhance Image Quality
Apr 22, 2022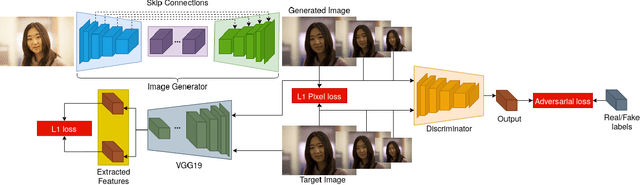
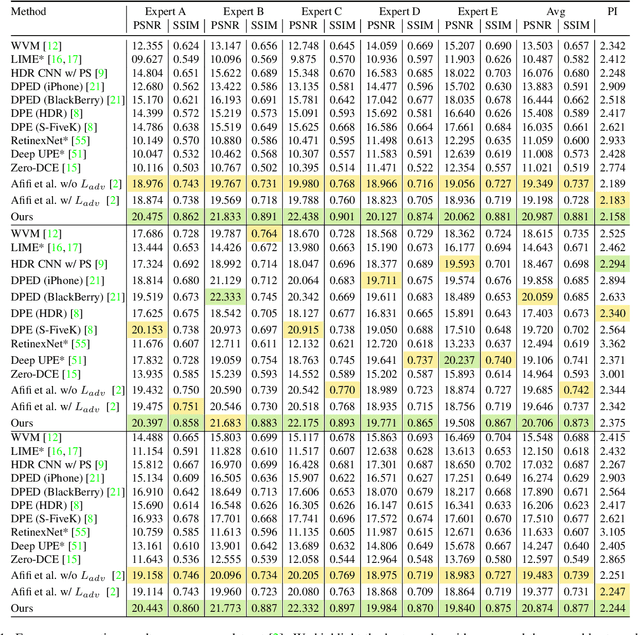

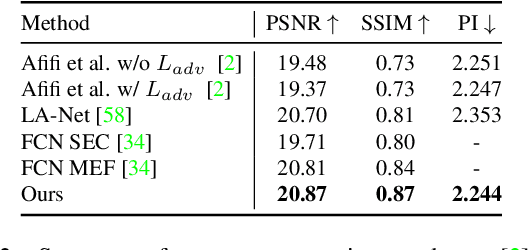
Exposure errors in an image cause a degradation in the contrast and low visibility in the content. In this paper, we address this problem and propose an end-to-end exposure correction model in order to handle both under- and overexposure errors with a single model. Our model contains an image encoder, consecutive residual blocks, and image decoder to synthesize the corrected image. We utilize perceptual loss, feature matching loss, and multi-scale discriminator to increase the quality of the generated image as well as to make the training more stable. The experimental results indicate the effectiveness of proposed model. We achieve the state-of-the-art result on a large-scale exposure dataset. Besides, we investigate the effect of exposure setting of the image on the portrait matting task. We find that under- and overexposed images cause severe degradation in the performance of the portrait matting models. We show that after applying exposure correction with the proposed model, the portrait matting quality increases significantly. https://github.com/yamand16/ExposureCorrection
Personalizing Federated Medical Image Segmentation via Local Calibration
Jul 11, 2022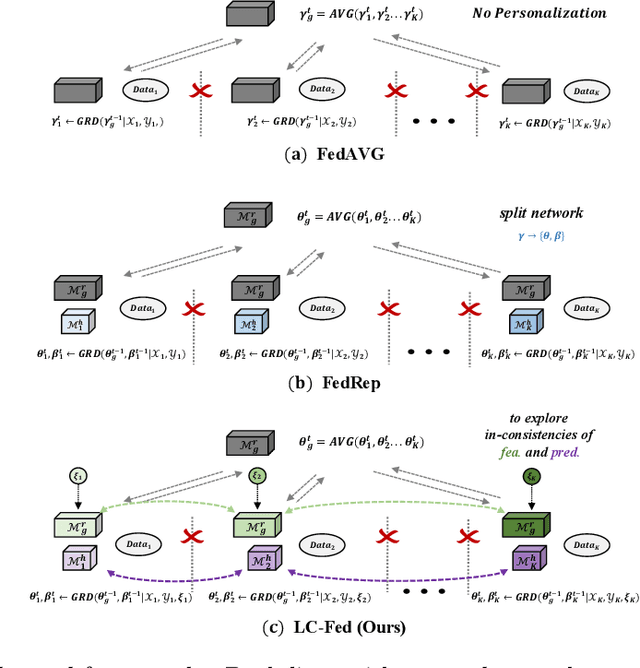
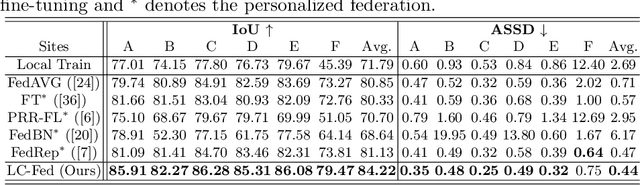
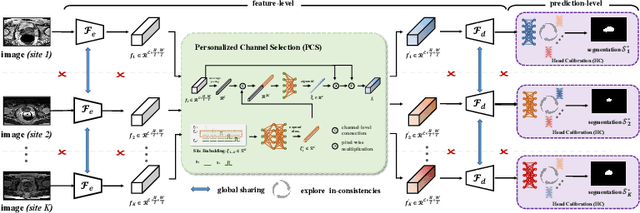
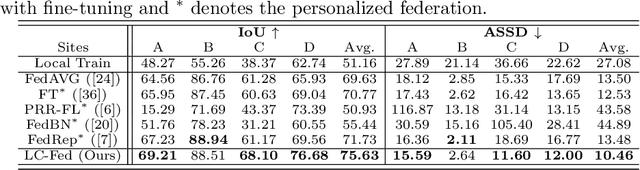
Medical image segmentation under federated learning (FL) is a promising direction by allowing multiple clinical sites to collaboratively learn a global model without centralizing datasets. However, using a single model to adapt to various data distributions from different sites is extremely challenging. Personalized FL tackles this issue by only utilizing partial model parameters shared from global server, while keeping the rest to adapt to its own data distribution in the local training of each site. However, most existing methods concentrate on the partial parameter splitting, while do not consider the \textit{inter-site in-consistencies} during the local training, which in fact can facilitate the knowledge communication over sites to benefit the model learning for improving the local accuracy. In this paper, we propose a personalized federated framework with \textbf{L}ocal \textbf{C}alibration (LC-Fed), to leverage the inter-site in-consistencies in both \textit{feature- and prediction- levels} to boost the segmentation. Concretely, as each local site has its alternative attention on the various features, we first design the contrastive site embedding coupled with channel selection operation to calibrate the encoded features. Moreover, we propose to exploit the knowledge of prediction-level in-consistency to guide the personalized modeling on the ambiguous regions, e.g., anatomical boundaries. It is achieved by computing a disagreement-aware map to calibrate the prediction. Effectiveness of our method has been verified on three medical image segmentation tasks with different modalities, where our method consistently shows superior performance to the state-of-the-art personalized FL methods. Code is available at https://github.com/jcwang123/FedLC.
Robustifying Deep Vision Models Through Shape Sensitization
Nov 14, 2022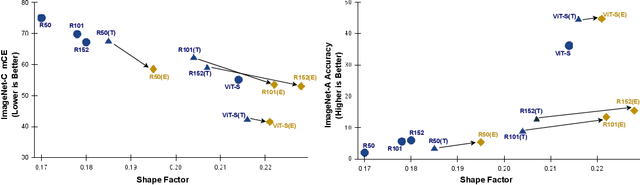
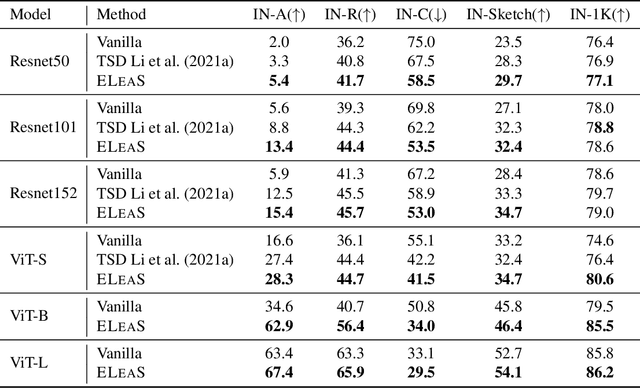
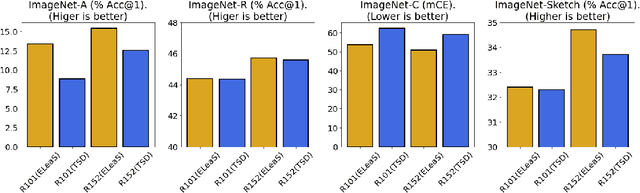
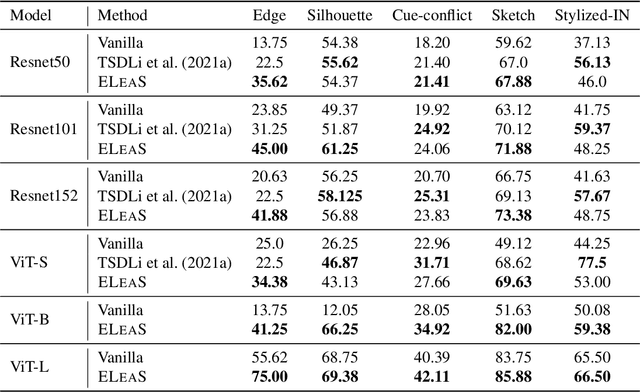
Recent work has shown that deep vision models tend to be overly dependent on low-level or "texture" features, leading to poor generalization. Various data augmentation strategies have been proposed to overcome this so-called texture bias in DNNs. We propose a simple, lightweight adversarial augmentation technique that explicitly incentivizes the network to learn holistic shapes for accurate prediction in an object classification setting. Our augmentations superpose edgemaps from one image onto another image with shuffled patches, using a randomly determined mixing proportion, with the image label of the edgemap image. To classify these augmented images, the model needs to not only detect and focus on edges but distinguish between relevant and spurious edges. We show that our augmentations significantly improve classification accuracy and robustness measures on a range of datasets and neural architectures. As an example, for ViT-S, We obtain absolute gains on classification accuracy gains up to 6%. We also obtain gains of up to 28% and 8.5% on natural adversarial and out-of-distribution datasets like ImageNet-A (for ViT-B) and ImageNet-R (for ViT-S), respectively. Analysis using a range of probe datasets shows substantially increased shape sensitivity in our trained models, explaining the observed improvement in robustness and classification accuracy.
Explaining Deepfake Detection by Analysing Image Matching
Jul 20, 2022
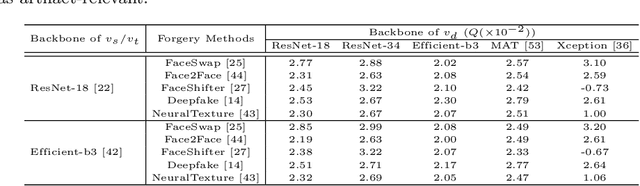
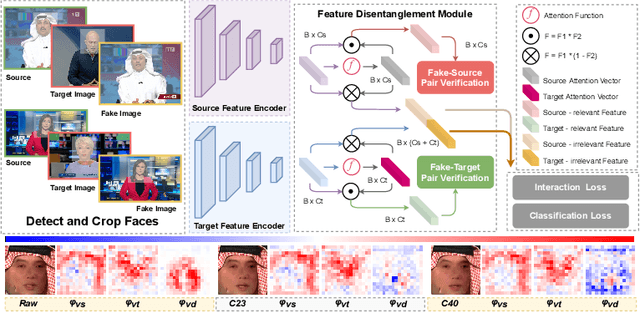
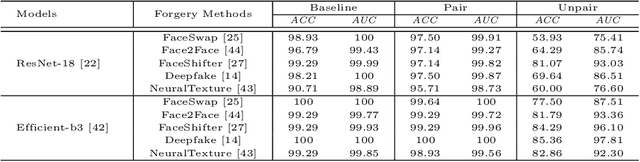
This paper aims to interpret how deepfake detection models learn artifact features of images when just supervised by binary labels. To this end, three hypotheses from the perspective of image matching are proposed as follows. 1. Deepfake detection models indicate real/fake images based on visual concepts that are neither source-relevant nor target-relevant, that is, considering such visual concepts as artifact-relevant. 2. Besides the supervision of binary labels, deepfake detection models implicitly learn artifact-relevant visual concepts through the FST-Matching (i.e. the matching fake, source, target images) in the training set. 3. Implicitly learned artifact visual concepts through the FST-Matching in the raw training set are vulnerable to video compression. In experiments, the above hypotheses are verified among various DNNs. Furthermore, based on this understanding, we propose the FST-Matching Deepfake Detection Model to boost the performance of forgery detection on compressed videos. Experiment results show that our method achieves great performance, especially on highly-compressed (e.g. c40) videos.
ORCa: Glossy Objects as Radiance Field Cameras
Dec 08, 2022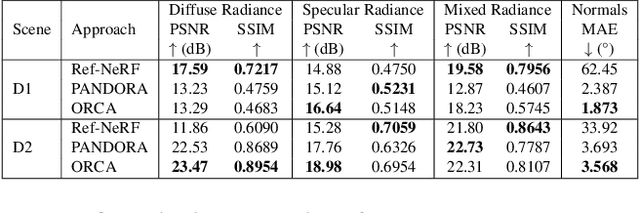
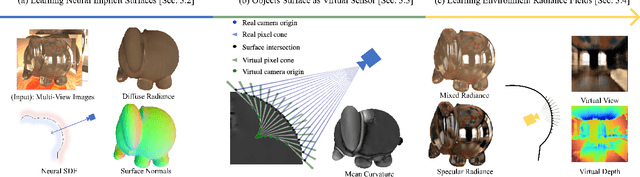
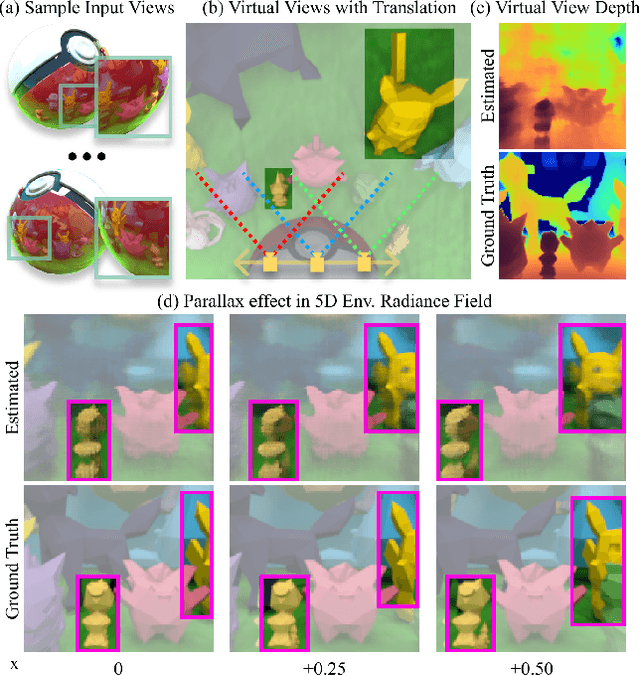
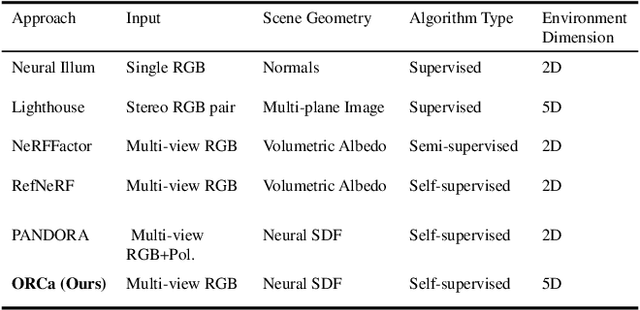
Reflections on glossy objects contain valuable and hidden information about the surrounding environment. By converting these objects into cameras, we can unlock exciting applications, including imaging beyond the camera's field-of-view and from seemingly impossible vantage points, e.g. from reflections on the human eye. However, this task is challenging because reflections depend jointly on object geometry, material properties, the 3D environment, and the observer viewing direction. Our approach converts glossy objects with unknown geometry into radiance-field cameras to image the world from the object's perspective. Our key insight is to convert the object surface into a virtual sensor that captures cast reflections as a 2D projection of the 5D environment radiance field visible to the object. We show that recovering the environment radiance fields enables depth and radiance estimation from the object to its surroundings in addition to beyond field-of-view novel-view synthesis, i.e. rendering of novel views that are only directly-visible to the glossy object present in the scene, but not the observer. Moreover, using the radiance field we can image around occluders caused by close-by objects in the scene. Our method is trained end-to-end on multi-view images of the object and jointly estimates object geometry, diffuse radiance, and the 5D environment radiance field.
Re-purposing Perceptual Hashing based Client Side Scanning for Physical Surveillance
Dec 08, 2022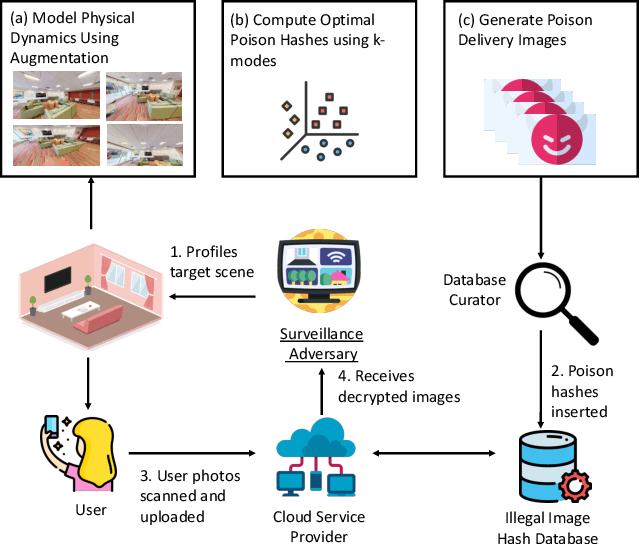
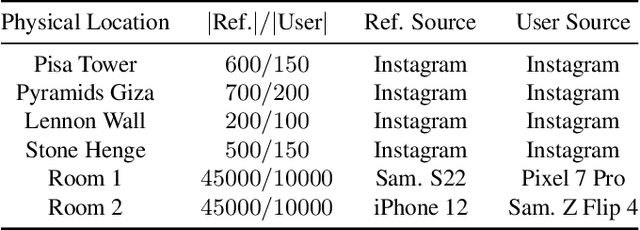
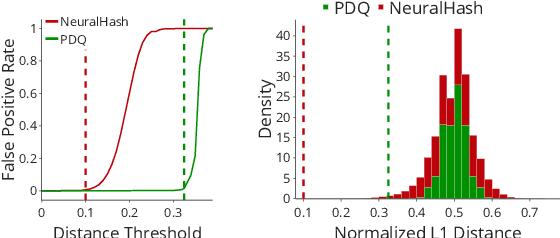

Content scanning systems employ perceptual hashing algorithms to scan user content for illegal material, such as child pornography or terrorist recruitment flyers. Perceptual hashing algorithms help determine whether two images are visually similar while preserving the privacy of the input images. Several efforts from industry and academia propose to conduct content scanning on client devices such as smartphones due to the impending roll out of end-to-end encryption that will make server-side content scanning difficult. However, these proposals have met with strong criticism because of the potential for the technology to be misused and re-purposed. Our work informs this conversation by experimentally characterizing the potential for one type of misuse -- attackers manipulating the content scanning system to perform physical surveillance on target locations. Our contributions are threefold: (1) we offer a definition of physical surveillance in the context of client-side image scanning systems; (2) we experimentally characterize this risk and create a surveillance algorithm that achieves physical surveillance rates of >40% by poisoning 5% of the perceptual hash database; (3) we experimentally study the trade-off between the robustness of client-side image scanning systems and surveillance, showing that more robust detection of illegal material leads to increased potential for physical surveillance.
Deep Joint Source-Channel Coding Over Cooperative Relay Networks
Nov 12, 2022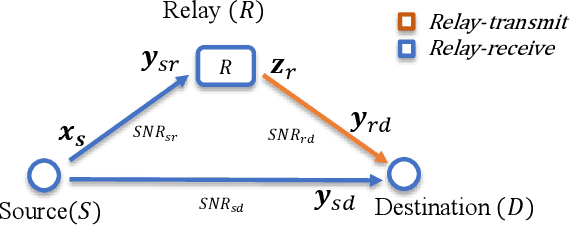
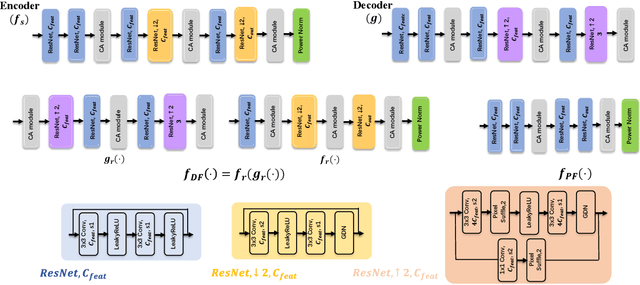
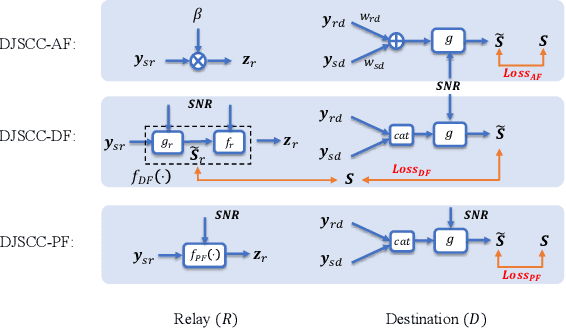
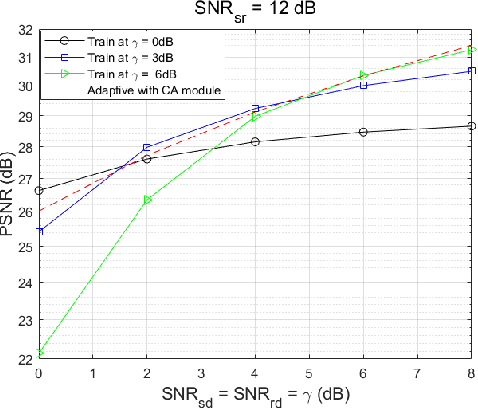
This paper presents a novel deep joint source-channel coding (DeepJSCC) scheme for image transmission over a half-duplex cooperative relay channel. Specifically, we apply DeepJSCC to two basic modes of cooperative communications, namely amplify-and-forward (AF) and decode-and-forward (DF). In DeepJSCC-AF, the relay simply amplifies and forwards its received signal. In DeepJSCC-DF, on the other hand, the relay first reconstructs the transmitted image and then re-encodes it before forwarding. Considering the excessive computation overhead of DeepJSCC-DF for recovering the image at the relay, we propose an alternative scheme, called DeepJSCC-PF, in which the relay processes and forwards its received signal without necessarily recovering the image. Simulation results show that the proposed DeepJSCC-AF, DF, and PF schemes are superior to the digital baselines with BPG compression with polar codes and provides a graceful performance degradation with deteriorating channel quality. Further investigation shows that the PSNR gain of DeepJSCC-DF/PF over DeepJSCC-AF improves as the channel condition between the source and relay improves. Moreover, DeepJSCC-PF scheme achieves a similar performance to DeepJSCC-DF with lower computational complexity.