 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Review of Causality for Learning Algorithms in Medical Image Analysis
Jun 11, 2022
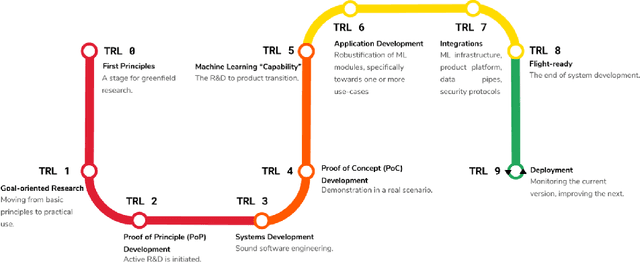

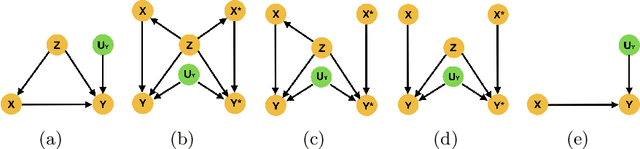
Medical image analysis is a vibrant research area that offers doctors and medical practitioners invaluable insight and the ability to accurately diagnose and monitor disease. Machine learning provides an additional boost for this area. However, machine learning for medical image analysis is particularly vulnerable to natural biases like domain shifts that affect algorithmic performance and robustness. In this paper we analyze machine learning for medical image analysis within the framework of Technology Readiness Levels and review how causal analysis methods can fill a gap when creating robust and adaptable medical image analysis algorithms. We review methods using causality in medical imaging AI/ML and find that causal analysis has the potential to mitigate critical problems for clinical translation but that uptake and clinical downstream research has been limited so far.
Nervus: A Comprehensive Deep Learning Classification, Regression, and Prognostication Tool for both Medical Image and Clinical Data Analysis
Dec 12, 2022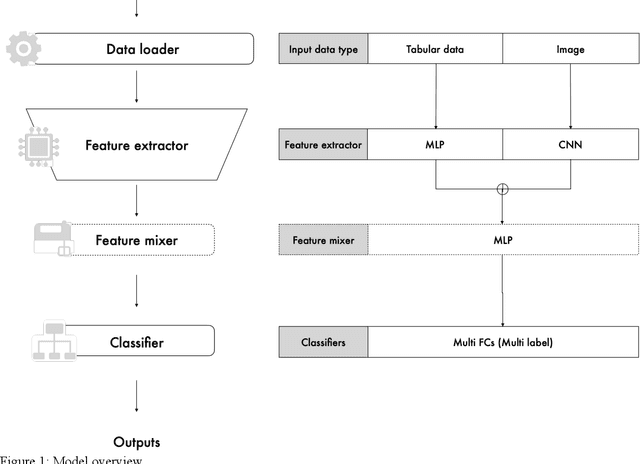
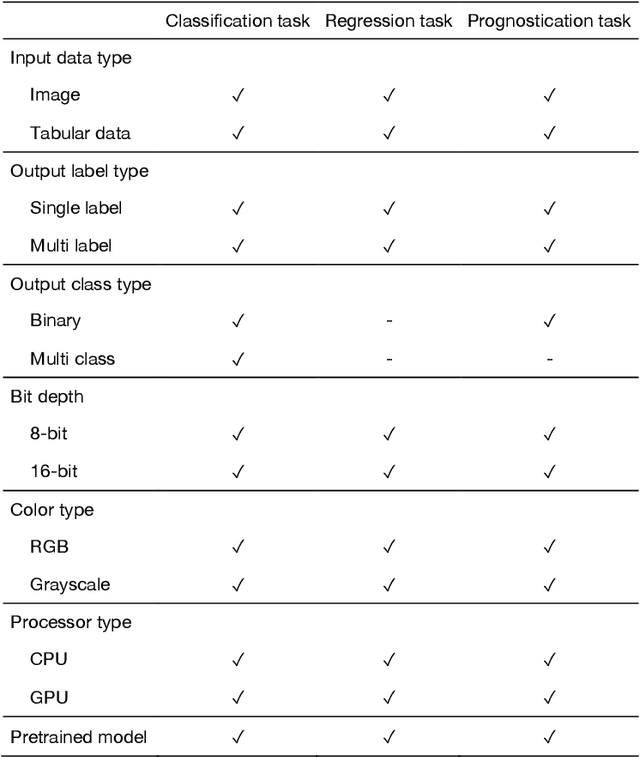
The goal of our research is to create a comprehensive and flexible library that is easy to use for medical imaging research, and capable of handling grayscale images, multiple inputs (both images and tabular data), and multi-label tasks. We have named it Nervus. Based on the PyTorch library, which is suitable for AI for research purposes, we created a four-part model to handle comprehensive inputs and outputs. Nervus consists of four parts. First is the dataloader, then the feature extractor, the feature mixer, and finally the classifier. The dataloader preprocesses the input data, the feature extractor extracts the features between the training data and ground truth labels, feature mixer mixes the features of the extractors, and the classifier classifies the input data from feature mixer based on the task. We have created Nervus, which is a comprehensive and flexible model library that is easy to use for medical imaging research which can handle grayscale images, multi-inputs and multi-label tasks. This will be helpful for researchers in the field of radiology.
Finetune like you pretrain: Improved finetuning of zero-shot vision models
Dec 01, 2022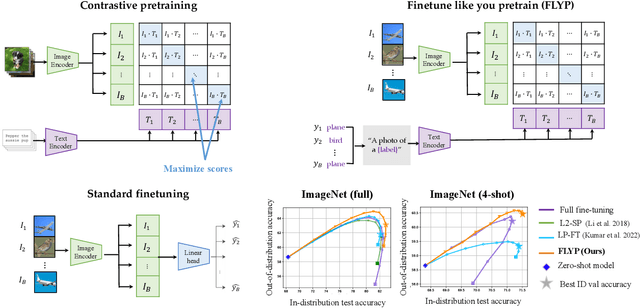
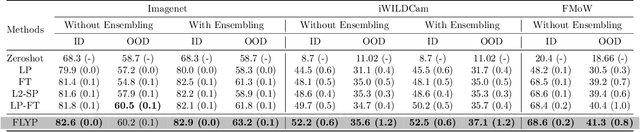
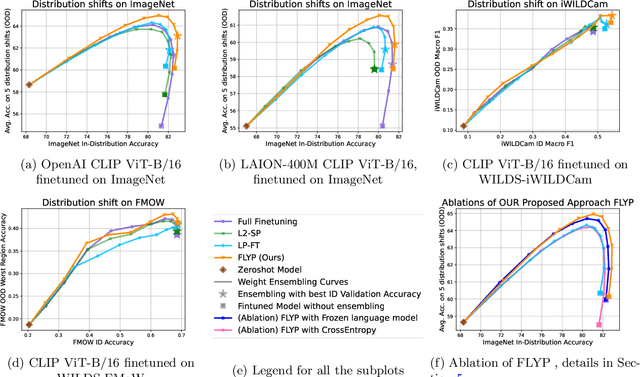
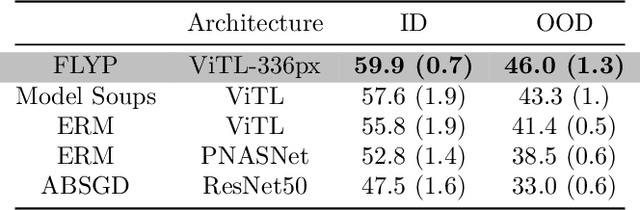
Finetuning image-text models such as CLIP achieves state-of-the-art accuracies on a variety of benchmarks. However, recent works like WiseFT (Wortsman et al., 2021) and LP-FT (Kumar et al., 2022) have shown that even subtle differences in the finetuning process can lead to surprisingly large differences in the final performance, both for in-distribution (ID) and out-of-distribution (OOD) data. In this work, we show that a natural and simple approach of mimicking contrastive pretraining consistently outperforms alternative finetuning approaches. Specifically, we cast downstream class labels as text prompts and continue optimizing the contrastive loss between image embeddings and class-descriptive prompt embeddings (contrastive finetuning). Our method consistently outperforms baselines across 7 distribution shifts, 6 transfer learning, and 3 few-shot learning benchmarks. On WILDS-iWILDCam, our proposed approach FLYP outperforms the top of the leaderboard by $2.3\%$ ID and $2.7\%$ OOD, giving the highest reported accuracy. Averaged across 7 OOD datasets (2 WILDS and 5 ImageNet associated shifts), FLYP gives gains of $4.2\%$ OOD over standard finetuning and outperforms the current state of the art (LP-FT) by more than $1\%$ both ID and OOD. Similarly, on 3 few-shot learning benchmarks, our approach gives gains up to $4.6\%$ over standard finetuning and $4.4\%$ over the state of the art. In total, these benchmarks establish contrastive finetuning as a simple, intuitive, and state-of-the-art approach for supervised finetuning of image-text models like CLIP. Code is available at https://github.com/locuslab/FLYP.
Fair contrastive pre-training for geographic images
Nov 16, 2022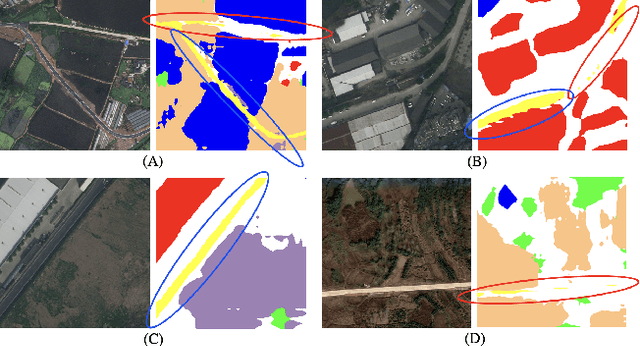
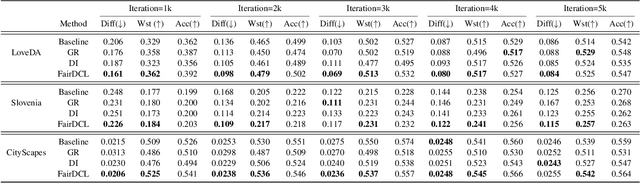
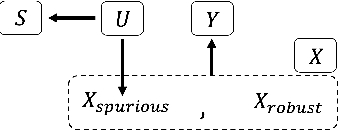
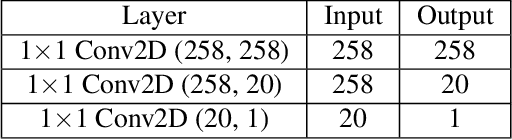
Contrastive representation learning is widely employed in visual recognition for geographic image data (remote-sensing such as satellite imagery or proximal sensing such as street-view imagery), but because of landscape heterogeneity, models can show disparate performance across spatial units. In this work, we consider fairness risks in land-cover semantic segmentation which uses pre-trained representation in contrastive self-supervised learning. We assess class distribution shifts and model prediction disparities across selected sensitive groups: urban and rural scenes for satellite image datasets and city GDP level for a street view image dataset. We propose a mutual information training objective for multi-level latent space. The objective improves feature identification by removing spurious representations of dense local features which are disparately distributed across groups. The method achieves improved fairness results and outperforms state-of-the-art methods in terms of precision-fairness trade-off. In addition, we validate that representations learnt with the proposed method include lowest sensitive information using a linear separation evaluation. This work highlights the need for specific fairness analyses in geographic images, and provides a solution that can be generalized to different self-supervised learning methods or image data. Our code is available at: https://anonymous.4open.science/r/FairDCL-1283
Scene Aware Person Image Generation through Global Contextual Conditioning
Jun 06, 2022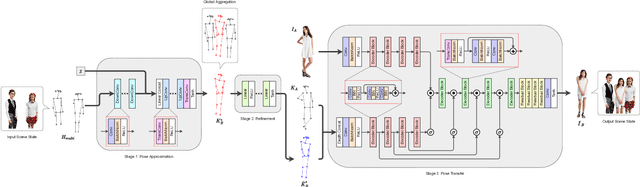
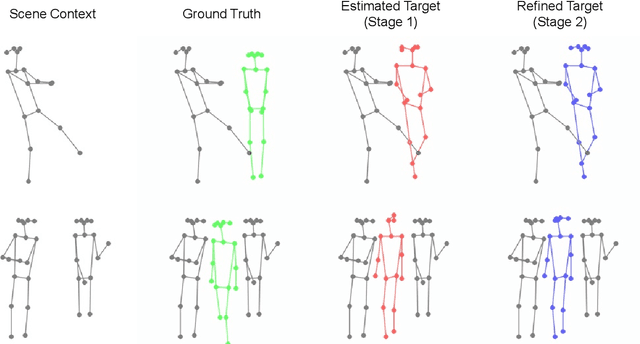


Person image generation is an intriguing yet challenging problem. However, this task becomes even more difficult under constrained situations. In this work, we propose a novel pipeline to generate and insert contextually relevant person images into an existing scene while preserving the global semantics. More specifically, we aim to insert a person such that the location, pose, and scale of the person being inserted blends in with the existing persons in the scene. Our method uses three individual networks in a sequential pipeline. At first, we predict the potential location and the skeletal structure of the new person by conditioning a Wasserstein Generative Adversarial Network (WGAN) on the existing human skeletons present in the scene. Next, the predicted skeleton is refined through a shallow linear network to achieve higher structural accuracy in the generated image. Finally, the target image is generated from the refined skeleton using another generative network conditioned on a given image of the target person. In our experiments, we achieve high-resolution photo-realistic generation results while preserving the general context of the scene. We conclude our paper with multiple qualitative and quantitative benchmarks on the results.
Non-uniform Sampling Strategies for NeRF on 360{\textdegree} images
Dec 07, 2022
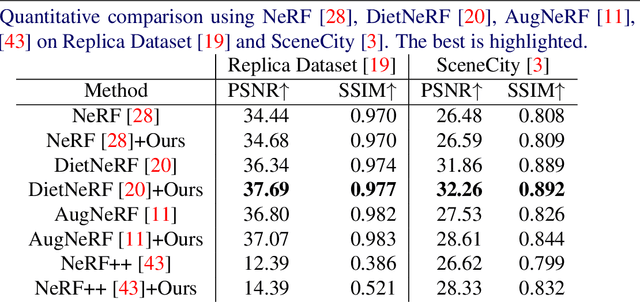
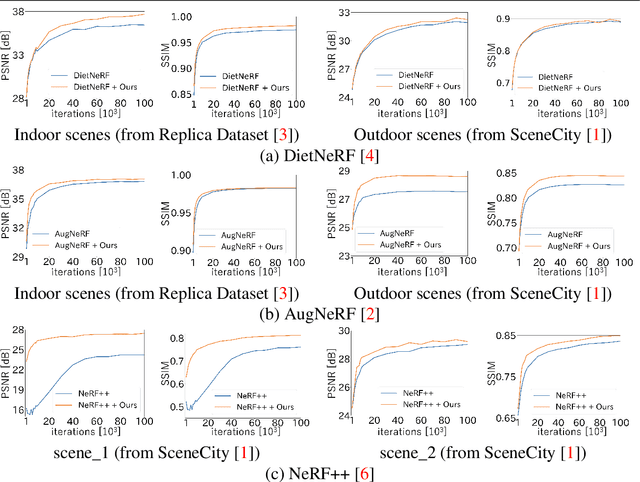

In recent years, the performance of novel view synthesis using perspective images has dramatically improved with the advent of neural radiance fields (NeRF). This study proposes two novel techniques that effectively build NeRF for 360{\textdegree} omnidirectional images. Due to the characteristics of a 360{\textdegree} image of ERP format that has spatial distortion in their high latitude regions and a 360{\textdegree} wide viewing angle, NeRF's general ray sampling strategy is ineffective. Hence, the view synthesis accuracy of NeRF is limited and learning is not efficient. We propose two non-uniform ray sampling schemes for NeRF to suit 360{\textdegree} images - distortion-aware ray sampling and content-aware ray sampling. We created an evaluation dataset Synth360 using Replica and SceneCity models of indoor and outdoor scenes, respectively. In experiments, we show that our proposal successfully builds 360{\textdegree} image NeRF in terms of both accuracy and efficiency. The proposal is widely applicable to advanced variants of NeRF. DietNeRF, AugNeRF, and NeRF++ combined with the proposed techniques further improve the performance. Moreover, we show that our proposed method enhances the quality of real-world scenes in 360{\textdegree} images. Synth360: https://drive.google.com/drive/folders/1suL9B7DO2no21ggiIHkH3JF3OecasQLb.
Unsupervised Visual Defect Detection with Score-Based Generative Model
Nov 29, 2022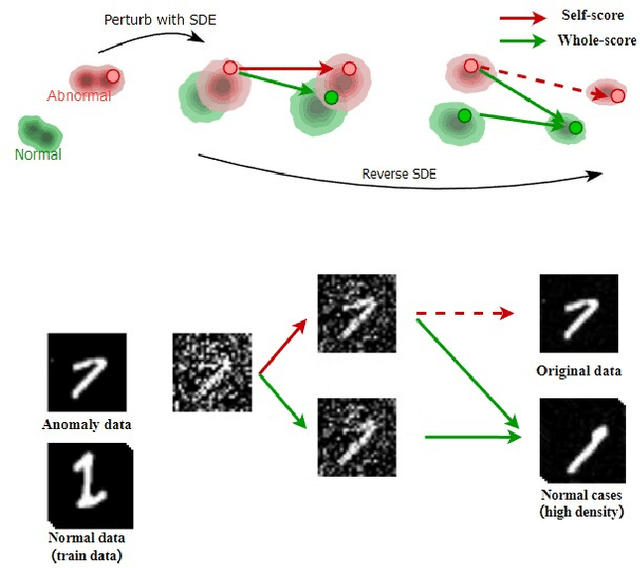
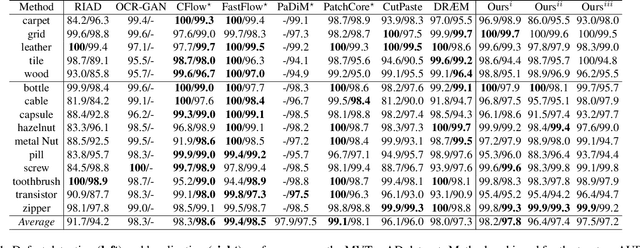

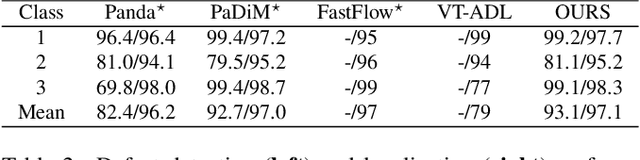
Anomaly Detection (AD), as a critical problem, has been widely discussed. In this paper, we specialize in one specific problem, Visual Defect Detection (VDD), in many industrial applications. And in practice, defect image samples are very rare and difficult to collect. Thus, we focus on the unsupervised visual defect detection and localization tasks and propose a novel framework based on the recent score-based generative models, which synthesize the real image by iterative denoising through stochastic differential equations (SDEs). Our work is inspired by the fact that with noise injected into the original image, the defects may be changed into normal cases in the denoising process (i.e., reconstruction). First, based on the assumption that the anomalous data lie in the low probability density region of the normal data distribution, we explain a common phenomenon that occurs when reconstruction-based approaches are applied to VDD: normal pixels also change during the reconstruction process. Second, due to the differences in normal pixels between the reconstructed and original images, a time-dependent gradient value (i.e., score) of normal data distribution is utilized as a metric, rather than reconstruction loss, to gauge the defects. Third, a novel $T$ scales approach is developed to dramatically reduce the required number of iterations, accelerating the inference process. These practices allow our model to generalize VDD in an unsupervised manner while maintaining reasonably good performance. We evaluate our method on several datasets to demonstrate its effectiveness.
Minimum Noticeable Difference based Adversarial Privacy Preserving Image Generation
Jun 17, 2022
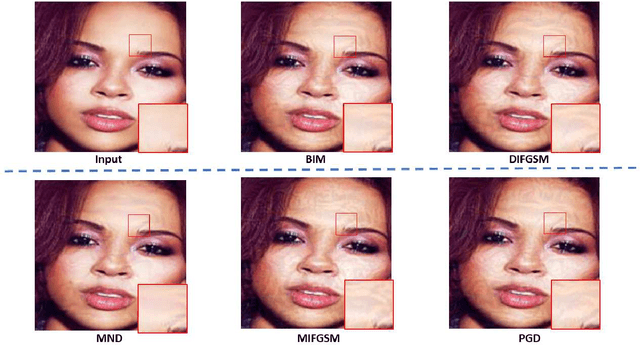
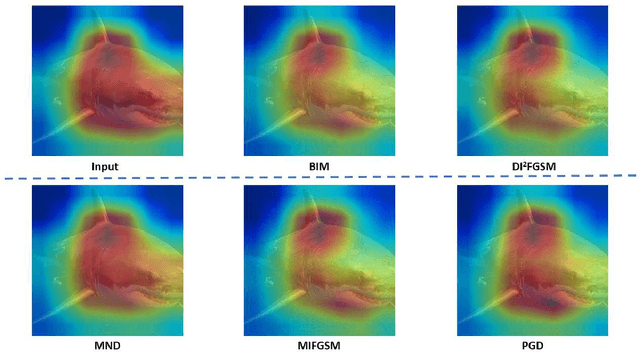

Deep learning models are found to be vulnerable to adversarial examples, as wrong predictions can be caused by small perturbation in input for deep learning models. Most of the existing works of adversarial image generation try to achieve attacks for most models, while few of them make efforts on guaranteeing the perceptual quality of the adversarial examples. High quality adversarial examples matter for many applications, especially for the privacy preserving. In this work, we develop a framework based on the Minimum Noticeable Difference (MND) concept to generate adversarial privacy preserving images that have minimum perceptual difference from the clean ones but are able to attack deep learning models. To achieve this, an adversarial loss is firstly proposed to make the deep learning models attacked by the adversarial images successfully. Then, a perceptual quality-preserving loss is developed by taking the magnitude of perturbation and perturbation-caused structural and gradient changes into account, which aims to preserve high perceptual quality for adversarial image generation. To the best of our knowledge, this is the first work on exploring quality-preserving adversarial image generation based on the MND concept for privacy preserving. To evaluate its performance in terms of perceptual quality, the deep models on image classification and face recognition are tested with the proposed method and several anchor methods in this work. Extensive experimental results demonstrate that the proposed MND framework is capable of generating adversarial images with remarkably improved performance metrics (e.g., PSNR, SSIM, and MOS) than that generated with the anchor methods.
Generative Modeling in Sinogram Domain for Sparse-view CT Reconstruction
Nov 25, 2022


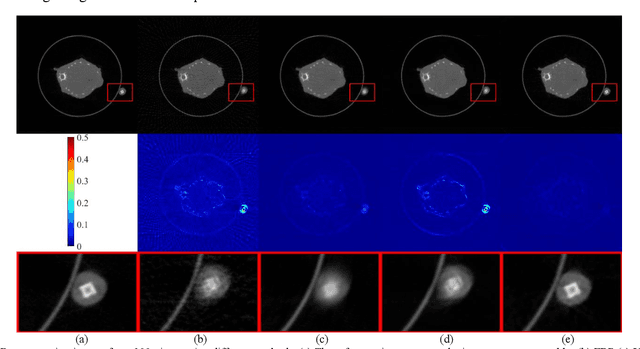
The radiation dose in computed tomography (CT) examinations is harmful for patients but can be significantly reduced by intuitively decreasing the number of projection views. Reducing projection views usually leads to severe aliasing artifacts in reconstructed images. Previous deep learning (DL) techniques with sparse-view data require sparse-view/full-view CT image pairs to train the network with supervised manners. When the number of projection view changes, the DL network should be retrained with updated sparse-view/full-view CT image pairs. To relieve this limitation, we present a fully unsupervised score-based generative model in sinogram domain for sparse-view CT reconstruction. Specifically, we first train a score-based generative model on full-view sinogram data and use multi-channel strategy to form highdimensional tensor as the network input to capture their prior distribution. Then, at the inference stage, the stochastic differential equation (SDE) solver and data-consistency step were performed iteratively to achieve fullview projection. Filtered back-projection (FBP) algorithm was used to achieve the final image reconstruction. Qualitative and quantitative studies were implemented to evaluate the presented method with several CT data. Experimental results demonstrated that our method achieved comparable or better performance than the supervised learning counterparts.
VeriX: Towards Verified Explainability of Deep Neural Networks
Dec 06, 2022
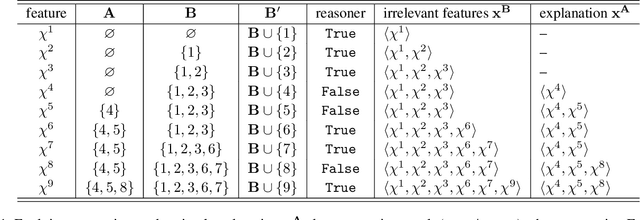
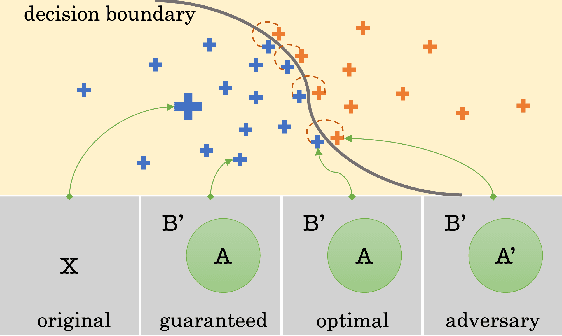
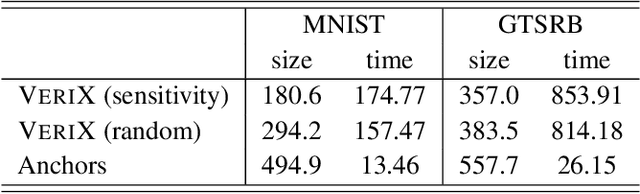
We present VeriX, a first step towards verified explainability of machine learning models in safety-critical applications. Specifically, our sound and optimal explanations can guarantee prediction invariance against bounded perturbations. We utilise constraint solving techniques together with feature sensitivity ranking to efficiently compute these explanations. We evaluate our approach on image recognition benchmarks and a real-world scenario of autonomous aircraft taxiing.