 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semi-Supervised Domain Generalization for Cardiac Magnetic Resonance Image Segmentation with High Quality Pseudo Labels
Sep 30, 2022
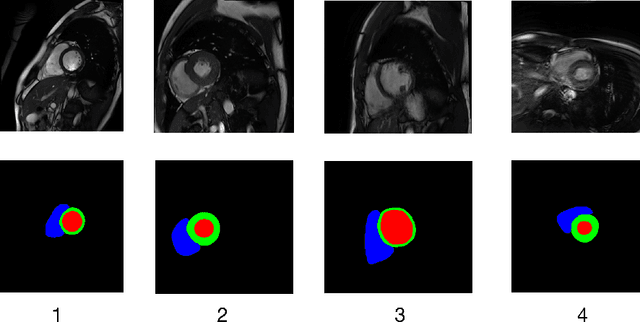

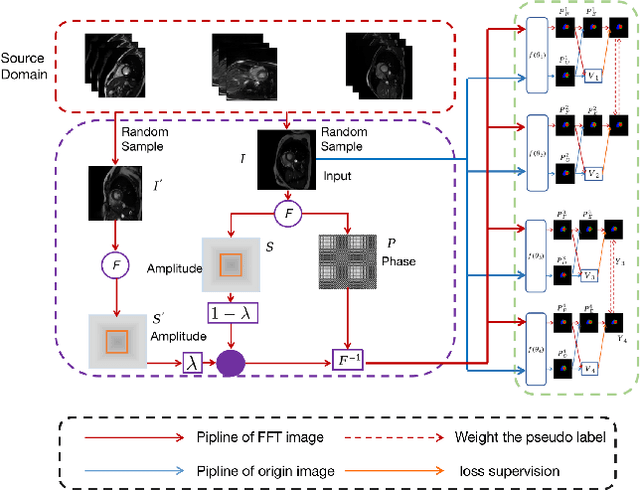
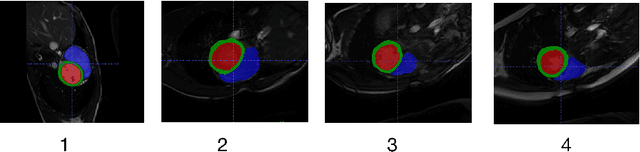
Developing a deep learning method for medical segmentation tasks heavily relies on a large amount of labeled data. However, the annotations require professional knowledge and are limited in number. Recently, semi-supervised learning has demonstrated great potential in medical segmentation tasks. Most existing methods related to cardiac magnetic resonance images only focus on regular images with similar domains and high image quality. A semi-supervised domain generalization method was developed in [2], which enhances the quality of pseudo labels on varied datasets. In this paper, we follow the strategy in [2] and present a domain generalization method for semi-supervised medical segmentation. Our main goal is to improve the quality of pseudo labels under extreme MRI Analysis with various domains. We perform Fourier transformation on input images to learn low-level statistics and cross-domain information. Then we feed the augmented images as input to the double cross pseudo supervision networks to calculate the variance among pseudo labels. We evaluate our method on the CMRxMotion dataset [1]. With only partially labeled data and without domain labels, our approach consistently generates accurate segmentation results of cardiac magnetic resonance images with different respiratory motions. Code will be available after the conference.
Rethinking Implicit Neural Representations for Vision Learners
Nov 23, 2022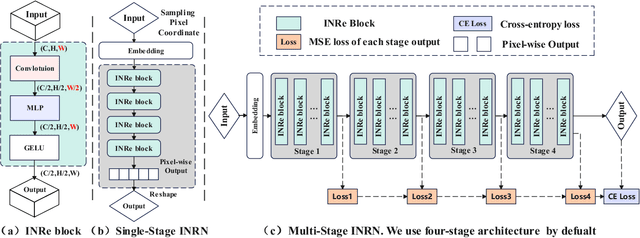
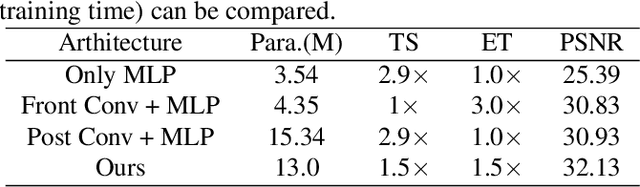
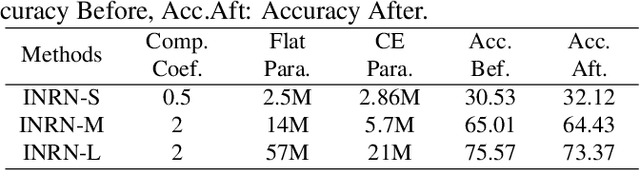

Implicit Neural Representations (INRs) are powerful to parameterize continuous signals in computer vision. However, almost all INRs methods are limited to low-level tasks, e.g., image/video compression, super-resolution, and image generation. The questions on how to explore INRs to high-level tasks and deep networks are still under-explored. Existing INRs methods suffer from two problems: 1) narrow theoretical definitions of INRs are inapplicable to high-level tasks; 2) lack of representation capabilities to deep networks. Motivated by the above facts, we reformulate the definitions of INRs from a novel perspective and propose an innovative Implicit Neural Representation Network (INRN), which is the first study of INRs to tackle both low-level and high-level tasks. Specifically, we present three key designs for basic blocks in INRN along with two different stacking ways and corresponding loss functions. Extensive experiments with analysis on both low-level tasks (image fitting) and high-level vision tasks (image classification, object detection, instance segmentation) demonstrate the effectiveness of the proposed method.
Siamese Image Modeling for Self-Supervised Vision Representation Learning
Jun 02, 2022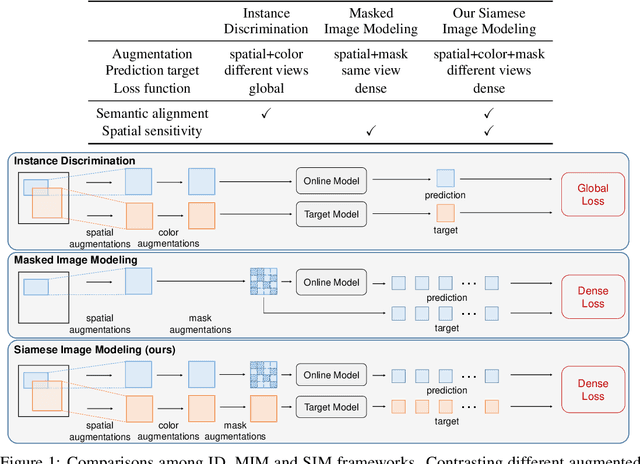
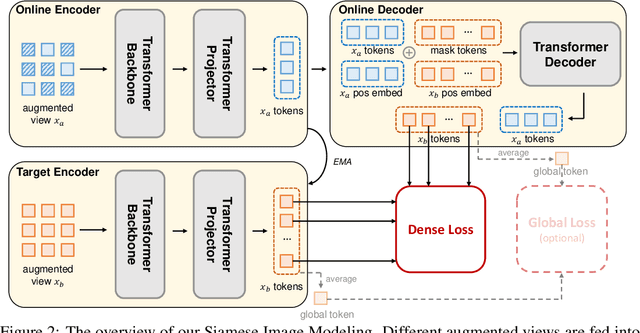
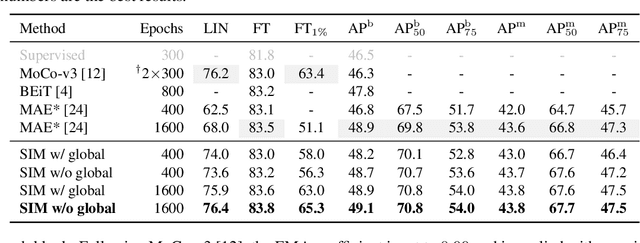
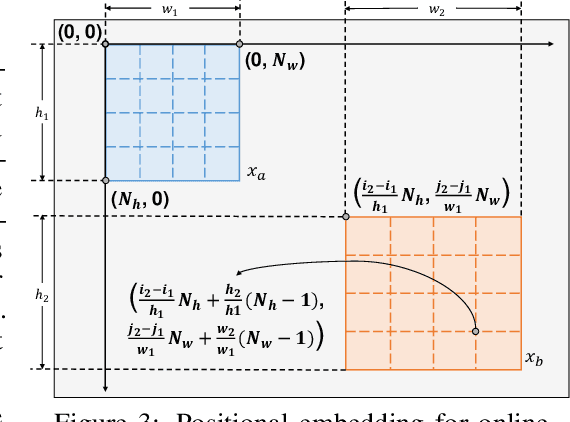
Self-supervised learning (SSL) has delivered superior performance on a variety of downstream vision tasks. Two main-stream SSL frameworks have been proposed, i.e., Instance Discrimination (ID) and Masked Image Modeling (MIM). ID pulls together the representations of different views from the same image, while avoiding feature collapse. It does well on linear probing but is inferior in detection performance. On the other hand, MIM reconstructs the original content given a masked image. It excels at dense prediction but fails to perform well on linear probing. Their distinctions are caused by neglecting the representation requirements of either semantic alignment or spatial sensitivity. Specifically, we observe that (1) semantic alignment demands semantically similar views to be projected into nearby representation, which can be achieved by contrasting different views with strong augmentations; (2) spatial sensitivity requires to model the local structure within an image. Predicting dense representations with masked image is therefore beneficial because it models the conditional distribution of image content. Driven by these analysis, we propose Siamese Image Modeling (SIM), which predicts the dense representations of an augmented view, based on another masked view from the same image but with different augmentations. Our method uses a Siamese network with two branches. The online branch encodes the first view, and predicts the second view's representation according to the relative positions between these two views. The target branch produces the target by encoding the second view. In this way, we are able to achieve comparable linear probing and dense prediction performances with ID and MIM, respectively. We also demonstrate that decent linear probing result can be obtained without a global loss. Code shall be released.
Squeeze flow of micro-droplets: convolutional neural network with trainable and tunable refinement
Nov 16, 2022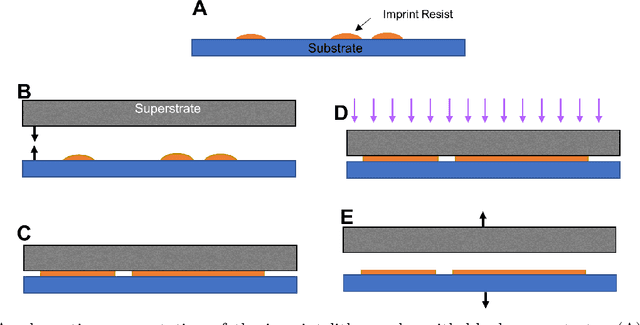
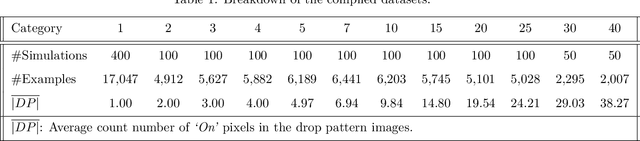
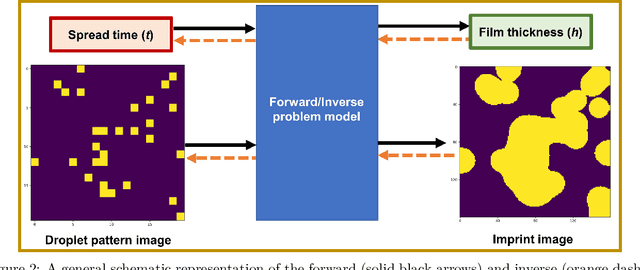
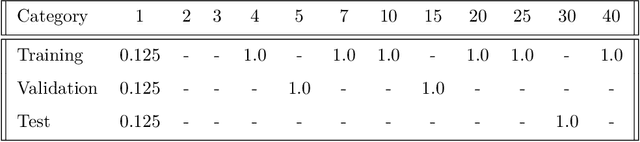
We propose a platform based on neural networks to solve the image-to-image translation problem in the context of squeeze flow of micro-droplets. In the first part of this paper, we present the governing partial differential equations to lay out the underlying physics of the problem. We also discuss our developed Python package, sqflow, which can potentially serve as free, flexible, and scalable standardized benchmarks in the fields of machine learning and computer vision. In the second part of this paper, we introduce a residual convolutional neural network to solve the corresponding inverse problem: to translate a high-resolution (HR) imprint image with a specific liquid film thickness to a low-resolution (LR) droplet pattern image capable of producing the given imprint image for an appropriate spread time of droplets. We propose a neural network architecture that learns to systematically tune the refinement level of its residual convolutional blocks by using the function approximators that are trained to map a given input parameter (film thickness) to an appropriate refinement level indicator. We use multiple stacks of convolutional layers the output of which is translated according to the refinement level indicators provided by the directly-connected function approximators. Together with a non-linear activation function, such a translation mechanism enables the HR imprint image to be refined sequentially in multiple steps until the target LR droplet pattern image is revealed. The proposed platform can be potentially applied to data compression and data encryption. The developed package and datasets are publicly available on GitHub at https://github.com/sqflow/sqflow.
Auto-outlier Fusion Technique for Chest X-ray classification with Multi-head Attention Mechanism
Nov 15, 2022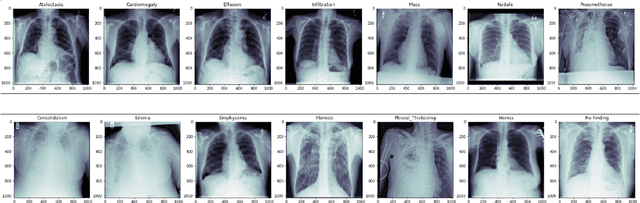
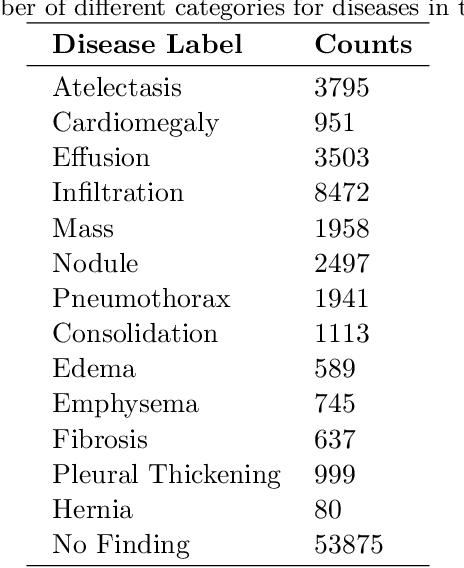
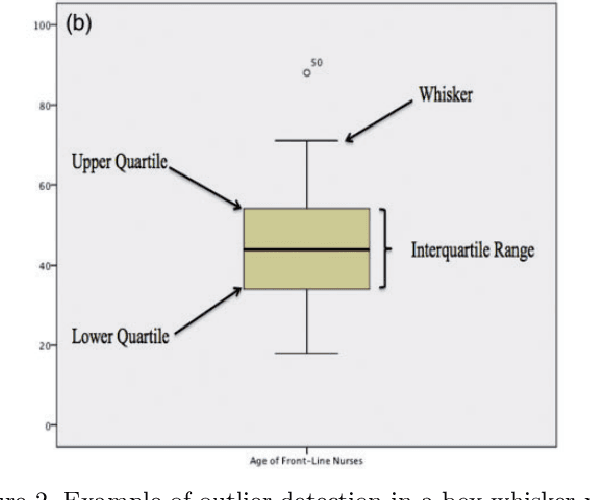
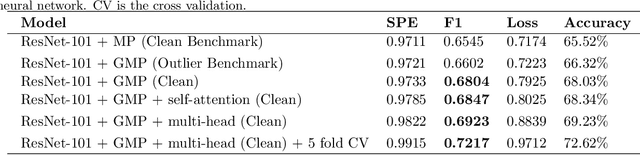
A chest X-ray is one of the most widely available radiological examinations for diagnosing and detecting various lung illnesses. The National Institutes of Health (NIH) provides an extensive database, ChestX-ray8 and ChestXray14, to help establish a deep learning community for analysing and predicting lung diseases. ChestX-ray14 consists of 112,120 frontal-view X-ray images of 30,805 distinct patients with text-mined fourteen disease image labels, where each image has multiple labels and has been utilised in numerous research in the past. To our current knowledge, no previous study has investigated outliers and multi-label impact for a single X-ray image during the preprocessing stage. The effect of outliers is mitigated in this paper by our proposed auto-outlier fusion technique. The image label is regenerated by concentrating on a particular factor in one image. The final cleaned dataset will be used to compare the mechanisms of multi-head self-attention and multi-head attention with generalised max-pooling.
Multi-scale Attentive Image De-raining Networks via Neural Architecture Search
Jul 02, 2022



Multi-scale architectures and attention modules have shown effectiveness in many deep learning-based image de-raining methods. However, manually designing and integrating these two components into a neural network requires a bulk of labor and extensive expertise. In this article, a high-performance multi-scale attentive neural architecture search (MANAS) framework is technically developed for image deraining. The proposed method formulates a new multi-scale attention search space with multiple flexible modules that are favorite to the image de-raining task. Under the search space, multi-scale attentive cells are built, which are further used to construct a powerful image de-raining network. The internal multiscale attentive architecture of the de-raining network is searched automatically through a gradient-based search algorithm, which avoids the daunting procedure of the manual design to some extent. Moreover, in order to obtain a robust image de-raining model, a practical and effective multi-to-one training strategy is also presented to allow the de-raining network to get sufficient background information from multiple rainy images with the same background scene, and meanwhile, multiple loss functions including external loss, internal loss, architecture regularization loss, and model complexity loss are jointly optimized to achieve robust de-raining performance and controllable model complexity. Extensive experimental results on both synthetic and realistic rainy images, as well as the down-stream vision applications (i.e., objection detection and segmentation) consistently demonstrate the superiority of our proposed method.
Three-dimensional tomographic imaging of the magnetization vector field using Fourier transform holography
Dec 20, 2022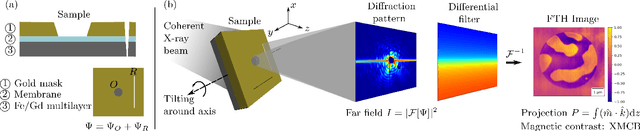

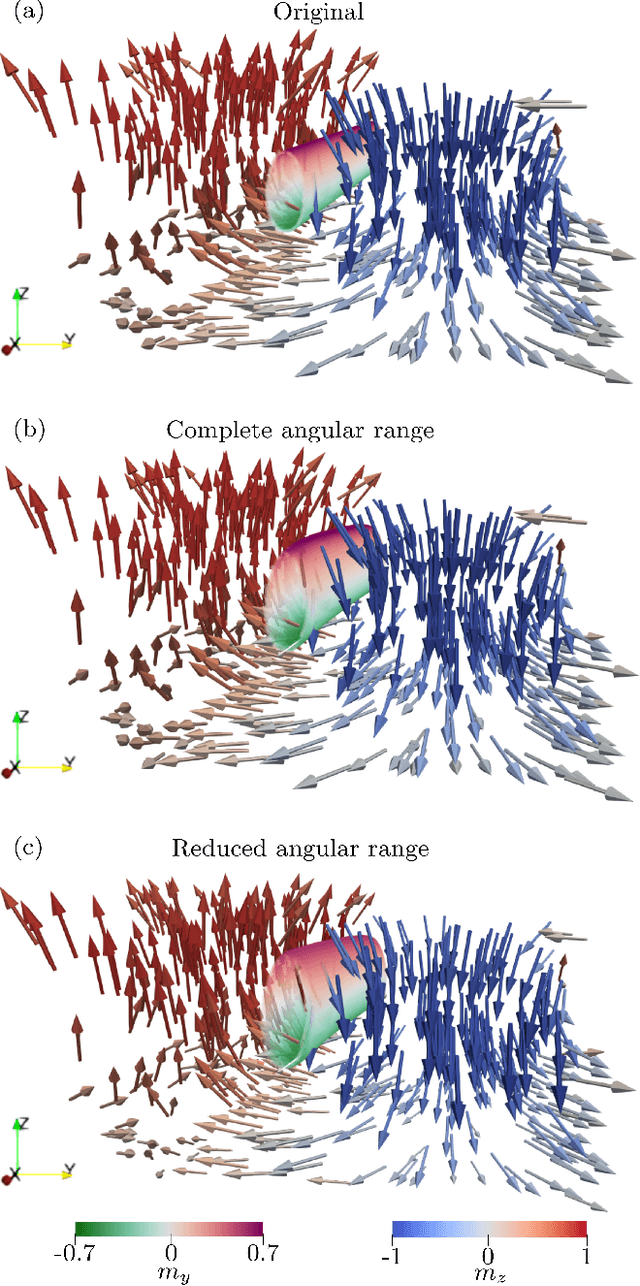
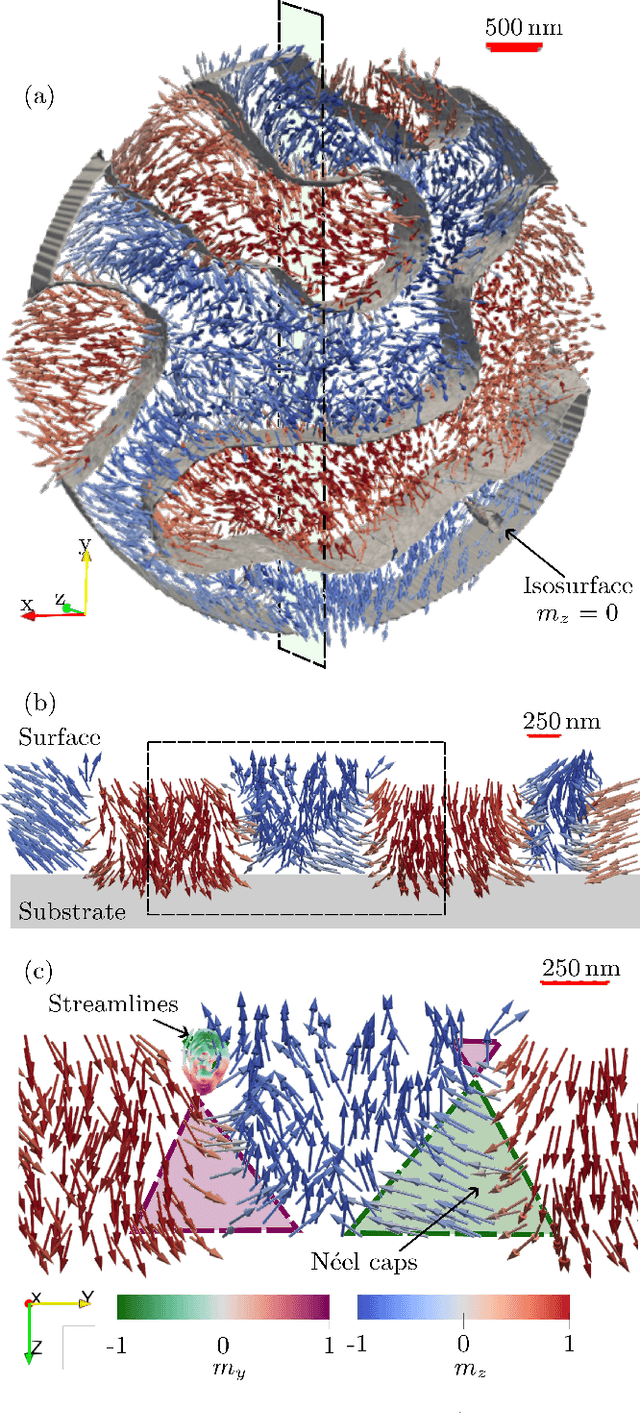
In recent years, interest in expanding from 2D to 3D systems has grown in the magnetism community, from exploring new geometries to broadening the knowledge on the magnetic textures present in thick samples, and with this arise the need for new characterization techniques, in particular tomographic imaging. Here, we present a new tomographic technique based on Fourier transform holography, a lensless imaging technique that uses a known reference in the sample to retrieve the object of interest from its diffraction pattern in one single step of calculation, overcoming the phase problem inherent to reciprocal-space-based techniques. Moreover, by exploiting the phase contrast instead of the absorption contrast, thicker samples can be investigated. We obtain a 3D full-vectorial image of a 800 nm-thick extended Fe/Gd multilayer in a 5$\mu$m-diameter circular field of view with a resolution of approximately 80 nm. The 3D image reveals worm-like domains with magnetization pointing mostly out of plane near the surface of the sample but that falls in-plane near the substrate. Since the FTH setup is fairly simple, it allows modifying the sample environment. Therefore, this technique could enable in particular a 3D view of the magnetic configuration's response to an external magnetic field.
StyleDomain: Analysis of StyleSpace for Domain Adaptation of StyleGAN
Dec 20, 2022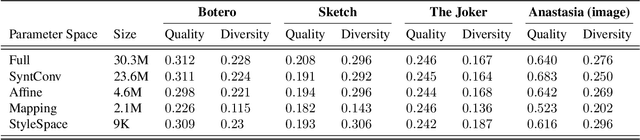
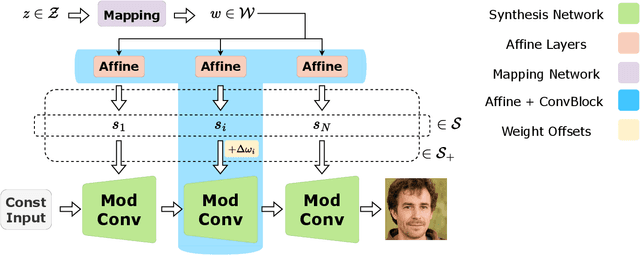
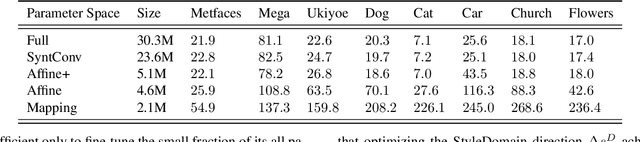

Domain adaptation of GANs is a problem of fine-tuning the state-of-the-art GAN models (e.g. StyleGAN) pretrained on a large dataset to a specific domain with few samples (e.g. painting faces, sketches, etc.). While there are a great number of methods that tackle this problem in different ways there are still many important questions that remain unanswered. In this paper, we provide a systematic and in-depth analysis of the domain adaptation problem of GANs, focusing on the StyleGAN model. First, we perform a detailed exploration of the most important parts of StyleGAN that are responsible for adapting the generator to a new domain depending on the similarity between the source and target domains. In particular, we show that affine layers of StyleGAN can be sufficient for fine-tuning to similar domains. Second, inspired by these findings, we investigate StyleSpace to utilize it for domain adaptation. We show that there exist directions in the StyleSpace that can adapt StyleGAN to new domains. Further, we examine these directions and discover their many surprising properties. Finally, we leverage our analysis and findings to deliver practical improvements and applications in such standard tasks as image-to-image translation and cross-domain morphing.
RangeAugment: Efficient Online Augmentation with Range Learning
Dec 20, 2022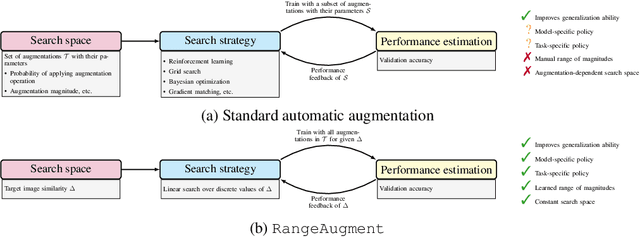
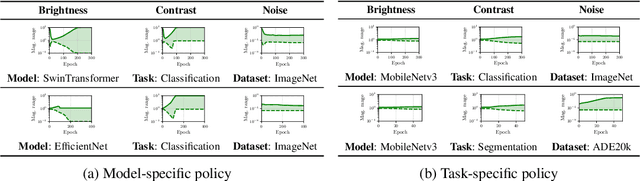

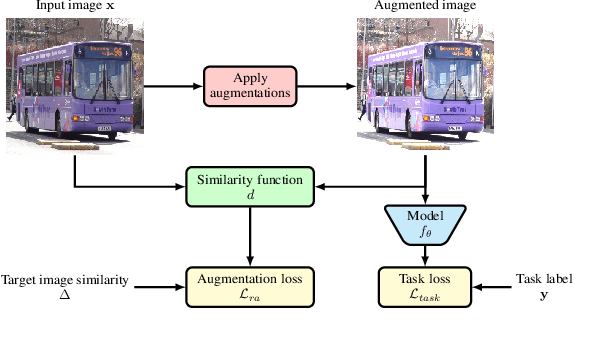
State-of-the-art automatic augmentation methods (e.g., AutoAugment and RandAugment) for visual recognition tasks diversify training data using a large set of augmentation operations. The range of magnitudes of many augmentation operations (e.g., brightness and contrast) is continuous. Therefore, to make search computationally tractable, these methods use fixed and manually-defined magnitude ranges for each operation, which may lead to sub-optimal policies. To answer the open question on the importance of magnitude ranges for each augmentation operation, we introduce RangeAugment that allows us to efficiently learn the range of magnitudes for individual as well as composite augmentation operations. RangeAugment uses an auxiliary loss based on image similarity as a measure to control the range of magnitudes of augmentation operations. As a result, RangeAugment has a single scalar parameter for search, image similarity, which we simply optimize via linear search. RangeAugment integrates seamlessly with any model and learns model- and task-specific augmentation policies. With extensive experiments on the ImageNet dataset across different networks, we show that RangeAugment achieves competitive performance to state-of-the-art automatic augmentation methods with 4-5 times fewer augmentation operations. Experimental results on semantic segmentation, object detection, foundation models, and knowledge distillation further shows RangeAugment's effectiveness.
Fast Text-Conditional Discrete Denoising on Vector-Quantized Latent Spaces
Nov 14, 2022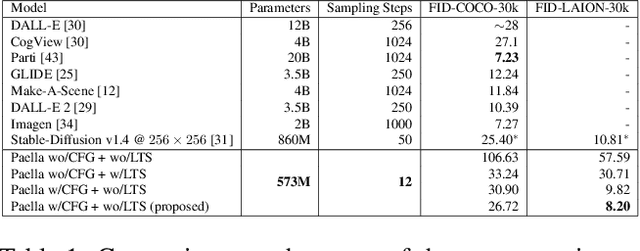
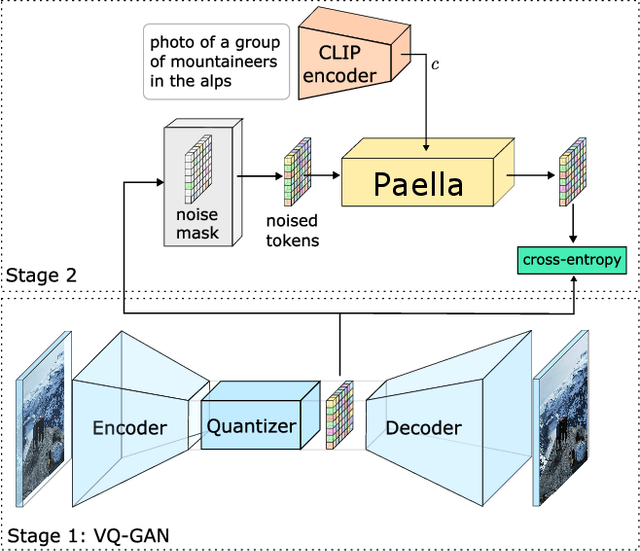
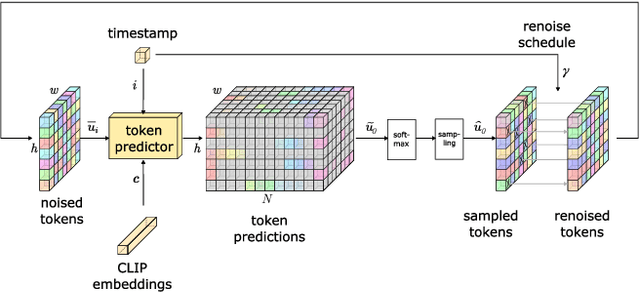
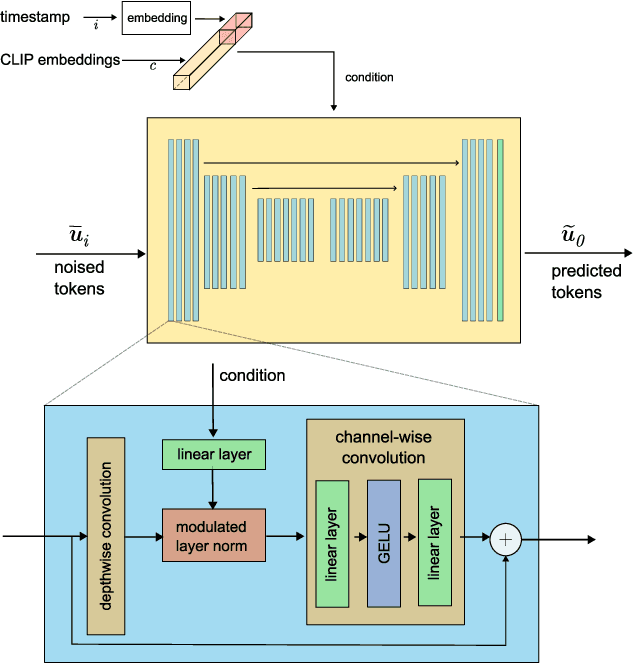
Conditional text-to-image generation has seen countless recent improvements in terms of quality, diversity and fidelity. Nevertheless, most state-of-the-art models require numerous inference steps to produce faithful generations, resulting in performance bottlenecks for end-user applications. In this paper we introduce Paella, a novel text-to-image model requiring less than 10 steps to sample high-fidelity images, using a speed-optimized architecture allowing to sample a single image in less than 500 ms, while having 573M parameters. The model operates on a compressed & quantized latent space, it is conditioned on CLIP embeddings and uses an improved sampling function over previous works. Aside from text-conditional image generation, our model is able to do latent space interpolation and image manipulations such as inpainting, outpainting, and structural editing. We release all of our code and pretrained models at https://github.com/dome272/Paella