 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FRIH: Fine-grained Region-aware Image Harmonization
May 13, 2022


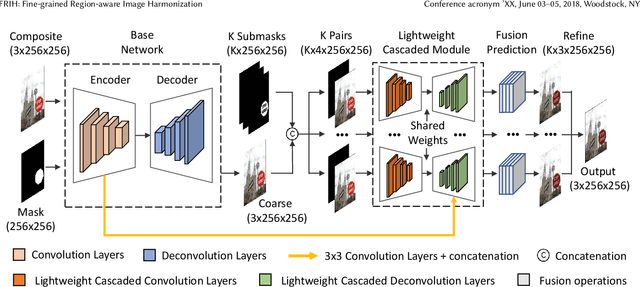
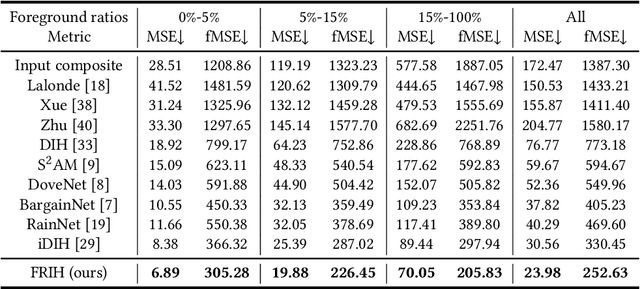
Image harmonization aims to generate a more realistic appearance of foreground and background for a composite image. Existing methods perform the same harmonization process for the whole foreground. However, the implanted foreground always contains different appearance patterns. All the existing solutions ignore the difference of each color block and losing some specific details. Therefore, we propose a novel global-local two stages framework for Fine-grained Region-aware Image Harmonization (FRIH), which is trained end-to-end. In the first stage, the whole input foreground mask is used to make a global coarse-grained harmonization. In the second stage, we adaptively cluster the input foreground mask into several submasks by the corresponding pixel RGB values in the composite image. Each submask and the coarsely adjusted image are concatenated respectively and fed into a lightweight cascaded module, adjusting the global harmonization performance according to the region-aware local feature. Moreover, we further designed a fusion prediction module by fusing features from all the cascaded decoder layers together to generate the final result, which could utilize the different degrees of harmonization results comprehensively. Without bells and whistles, our FRIH algorithm achieves the best performance on iHarmony4 dataset (PSNR is 38.19 dB) with a lightweight model. The parameters for our model are only 11.98 M, far below the existing methods.
Test-time Adaptation with Calibration of Medical Image Classification Nets for Label Distribution Shift
Jul 09, 2022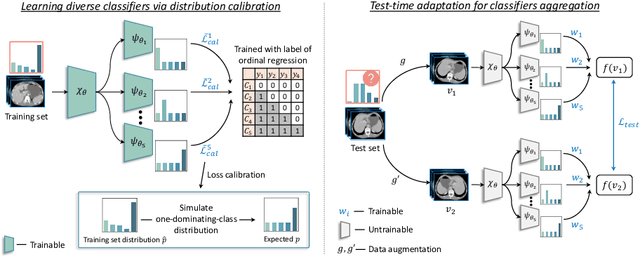
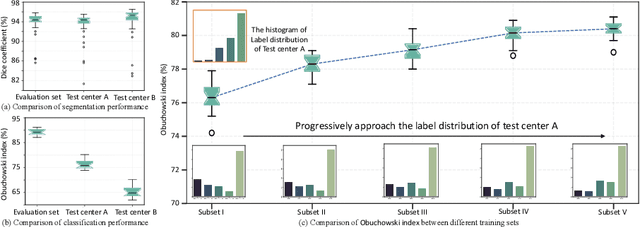
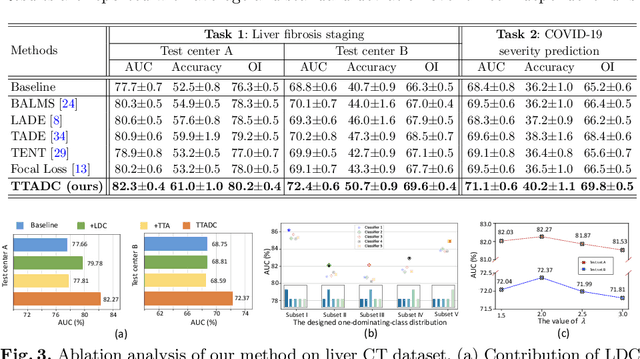
Class distribution plays an important role in learning deep classifiers. When the proportion of each class in the test set differs from the training set, the performance of classification nets usually degrades. Such a label distribution shift problem is common in medical diagnosis since the prevalence of disease vary over location and time. In this paper, we propose the first method to tackle label shift for medical image classification, which effectively adapt the model learned from a single training label distribution to arbitrary unknown test label distribution. Our approach innovates distribution calibration to learn multiple representative classifiers, which are capable of handling different one-dominating-class distributions. When given a test image, the diverse classifiers are dynamically aggregated via the consistency-driven test-time adaptation, to deal with the unknown test label distribution. We validate our method on two important medical image classification tasks including liver fibrosis staging and COVID-19 severity prediction. Our experiments clearly show the decreased model performance under label shift. With our method, model performance significantly improves on all the test datasets with different label shifts for both medical image diagnosis tasks.
PO-ELIC: Perception-Oriented Efficient Learned Image Coding
May 28, 2022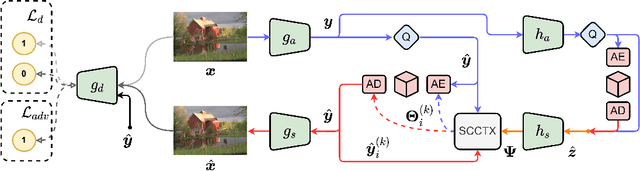


In the past years, learned image compression (LIC) has achieved remarkable performance. The recent LIC methods outperform VVC in both PSNR and MS-SSIM. However, the low bit-rate reconstructions of LIC suffer from artifacts such as blurring, color drifting and texture missing. Moreover, those varied artifacts make image quality metrics correlate badly with human perceptual quality. In this paper, we propose PO-ELIC, i.e., Perception-Oriented Efficient Learned Image Coding. To be specific, we adapt ELIC, one of the state-of-the-art LIC models, with adversarial training techniques. We apply a mixture of losses including hinge-form adversarial loss, Charbonnier loss, and style loss, to finetune the model towards better perceptual quality. Experimental results demonstrate that our method achieves comparable perceptual quality with HiFiC with much lower bitrate.
Unsupervised Echocardiography Registration through Patch-based MLPs and Transformers
Nov 21, 2022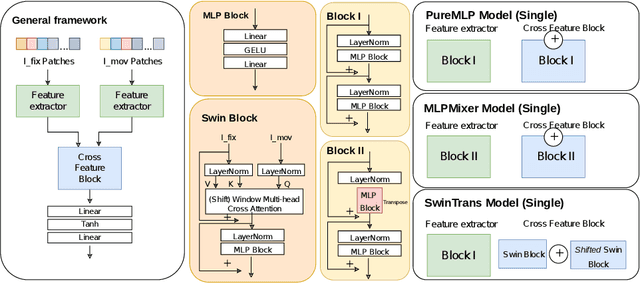
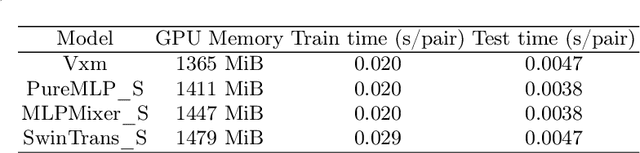
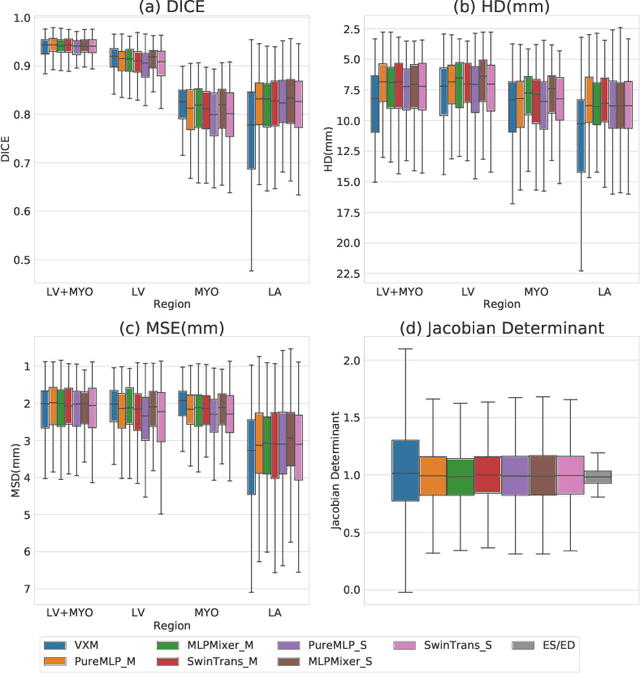
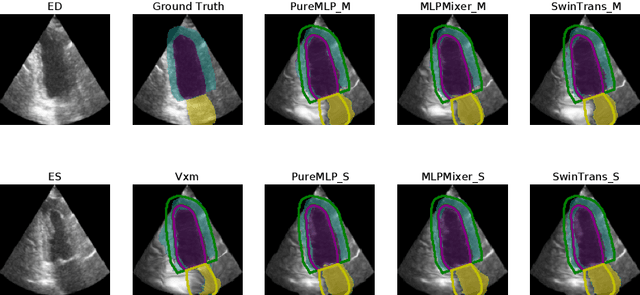
Image registration is an essential but challenging task in medical image computing, especially for echocardiography, where the anatomical structures are relatively noisy compared to other imaging modalities. Traditional (non-learning) registration approaches rely on the iterative optimization of a similarity metric which is usually costly in time complexity. In recent years, convolutional neural network (CNN) based image registration methods have shown good effectiveness. In the meantime, recent studies show that the attention-based model (e.g., Transformer) can bring superior performance in pattern recognition tasks. In contrast, whether the superior performance of the Transformer comes from the long-winded architecture or is attributed to the use of patches for dividing the inputs is unclear yet. This work introduces three patch-based frameworks for image registration using MLPs and transformers. We provide experiments on 2D-echocardiography registration to answer the former question partially and provide a benchmark solution. Our results on a large public 2D echocardiography dataset show that the patch-based MLP/Transformer model can be effectively used for unsupervised echocardiography registration. They demonstrate comparable and even better registration performance than a popular CNN registration model. In particular, patch-based models better preserve volume changes in terms of Jacobian determinants, thus generating robust registration fields with less unrealistic deformation. Our results demonstrate that patch-based learning methods, whether with attention or not, can perform high-performance unsupervised registration tasks with adequate time and space complexity. Our codes are available https://gitlab.inria.fr/epione/mlp\_transformer\_registration
RLIP: Relational Language-Image Pre-training for Human-Object Interaction Detection
Sep 05, 2022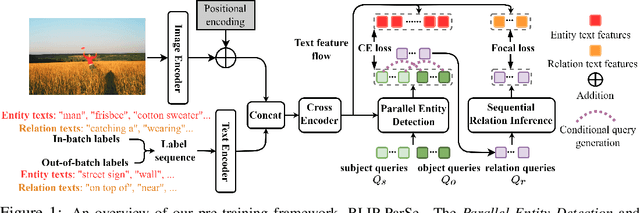
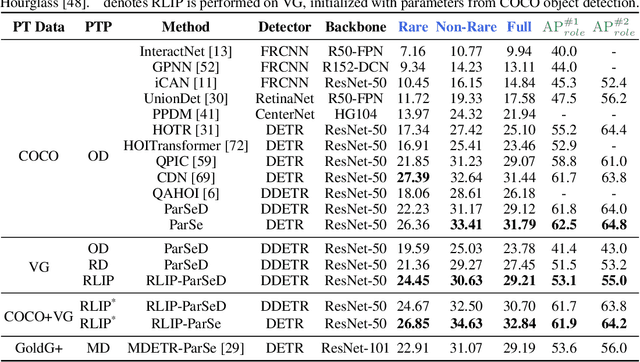
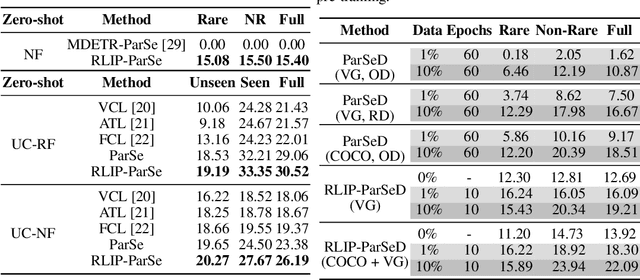

The task of Human-Object Interaction (HOI) detection targets fine-grained visual parsing of humans interacting with their environment, enabling a broad range of applications. Prior work has demonstrated the benefits of effective architecture design and integration of relevant cues for more accurate HOI detection. However, the design of an appropriate pre-training strategy for this task remains underexplored by existing approaches. To address this gap, we propose Relational Language-Image Pre-training (RLIP), a strategy for contrastive pre-training that leverages both entity and relation descriptions. To make effective use of such pre-training, we make three technical contributions: (1) a new Parallel entity detection and Sequential relation inference (ParSe) architecture that enables the use of both entity and relation descriptions during holistically optimized pre-training; (2) a synthetic data generation framework, Label Sequence Extension, that expands the scale of language data available within each minibatch; (3) mechanisms to account for ambiguity, Relation Quality Labels and Relation Pseudo-Labels, to mitigate the influence of ambiguous/noisy samples in the pre-training data. Through extensive experiments, we demonstrate the benefits of these contributions, collectively termed RLIP-ParSe, for improved zero-shot, few-shot and fine-tuning HOI detection performance as well as increased robustness to learning from noisy annotations. Code will be available at \url{https://github.com/JacobYuan7/RLIP}.
I2I: Image to Icosahedral Projection for $\mathrm{SO}(3)$ Object Reasoning from Single-View Images
Jul 18, 2022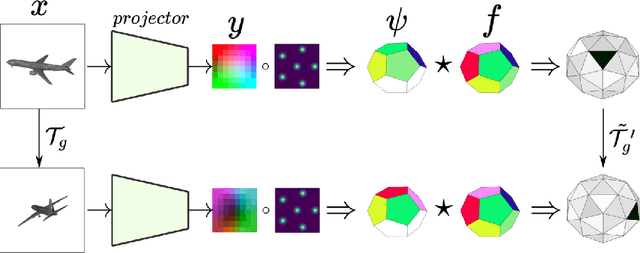
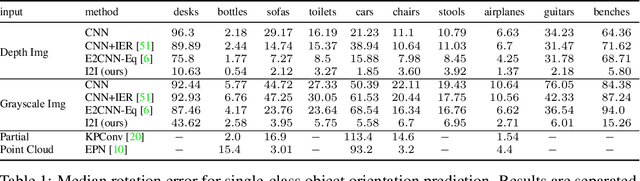
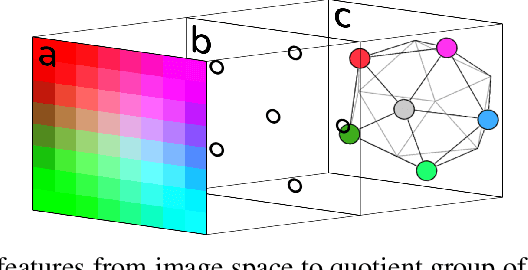
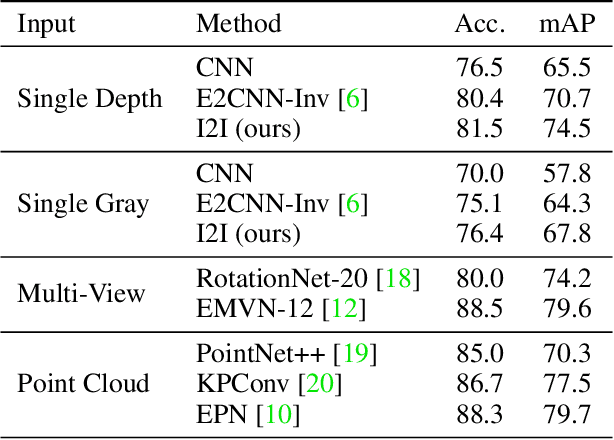
Reasoning about 3D objects based on 2D images is challenging due to large variations in appearance caused by viewing the object from different orientations. Ideally, our model would be invariant or equivariant to changes in object pose. Unfortunately, this is typically not possible with 2D image input because we do not have an a priori model of how the image would change under out-of-plane object rotations. The only $\mathrm{SO}(3)$-equivariant models that currently exist require point cloud input rather than 2D images. In this paper, we propose a novel model architecture based on icosahedral group convolution that reasons in $\mathrm{SO(3)}$ by projecting the input image onto an icosahedron. As a result of this projection, the model is approximately equivariant to rotation in $\mathrm{SO}(3)$. We apply this model to an object pose estimation task and find that it outperforms reasonable baselines.
AttEntropy: Segmenting Unknown Objects in Complex Scenes using the Spatial Attention Entropy of Semantic Segmentation Transformers
Dec 29, 2022
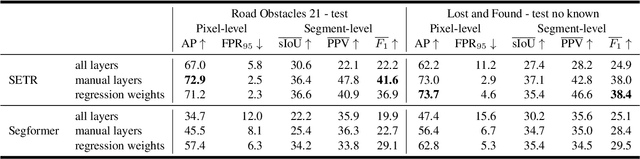
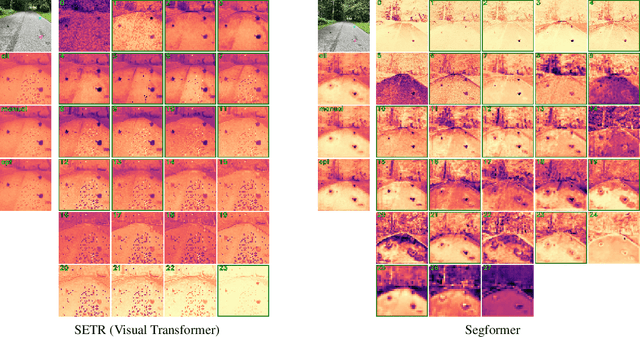
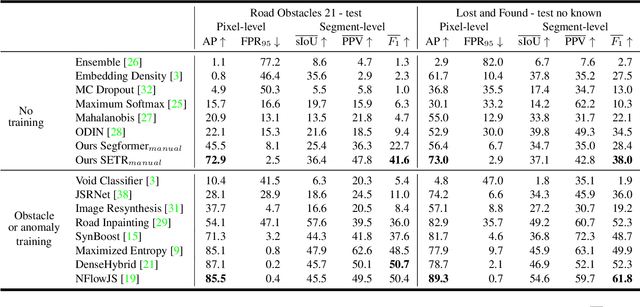
Vision transformers have emerged as powerful tools for many computer vision tasks. It has been shown that their features and class tokens can be used for salient object segmentation. However, the properties of segmentation transformers remain largely unstudied. In this work we conduct an in-depth study of the spatial attentions of different backbone layers of semantic segmentation transformers and uncover interesting properties. The spatial attentions of a patch intersecting with an object tend to concentrate within the object, whereas the attentions of larger, more uniform image areas rather follow a diffusive behavior. In other words, vision transformers trained to segment a fixed set of object classes generalize to objects well beyond this set. We exploit this by extracting heatmaps that can be used to segment unknown objects within diverse backgrounds, such as obstacles in traffic scenes. Our method is training-free and its computational overhead negligible. We use off-the-shelf transformers trained for street-scene segmentation to process other scene types.
Detection of out-of-distribution samples using binary neuron activation patterns
Dec 29, 2022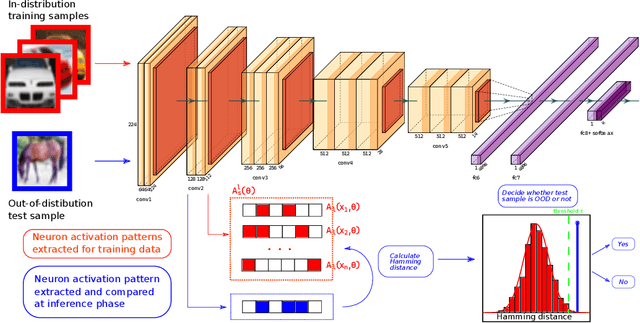
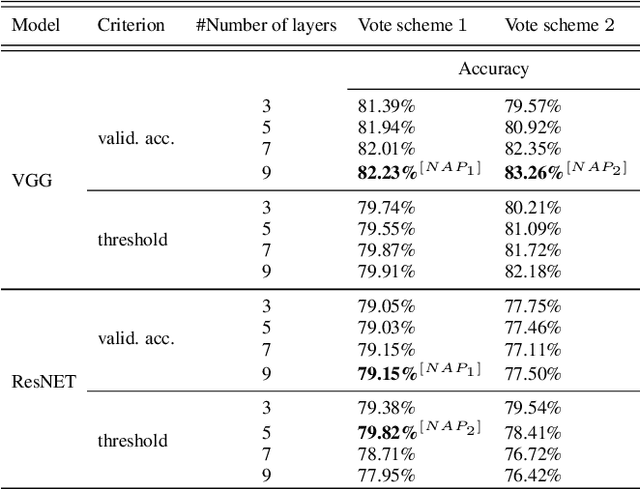
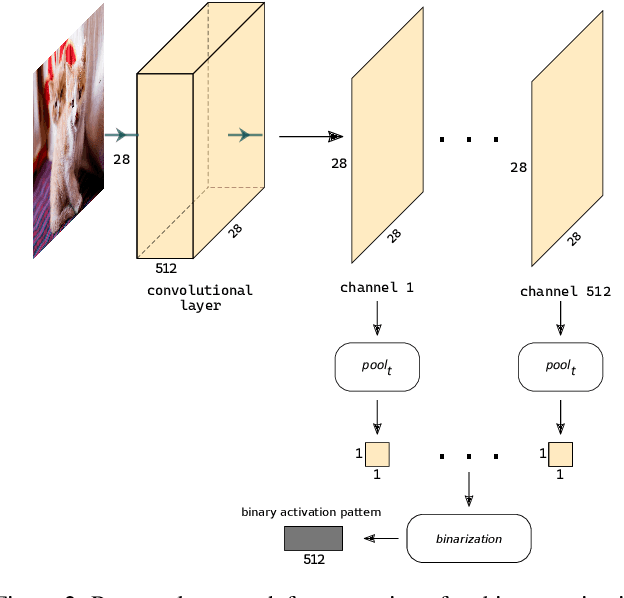
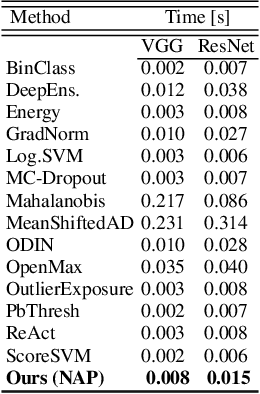
Deep neural networks (DNN) have outstanding performance in various applications. Despite numerous efforts of the research community, out-of-distribution (OOD) samples remain significant limitation of DNN classifiers. The ability to identify previously unseen inputs as novel is crucial in safety-critical applications such as self-driving cars, unmanned aerial vehicles and robots. Existing approaches to detect OOD samples treat a DNN as a black box and assess the confidence score of the output predictions. Unfortunately, this method frequently fails, because DNN are not trained to reduce their confidence for OOD inputs. In this work, we introduce a novel method for OOD detection. Our method is motivated by theoretical analysis of neuron activation patterns (NAP) in ReLU based architectures. The proposed method does not introduce high computational workload due to the binary representation of the activation patterns extracted from convolutional layers. The extensive empirical evaluation proves its high performance on various DNN architectures and seven image datasets. ion.
Optimizing illumination patterns for classical ghost imaging
Nov 07, 2022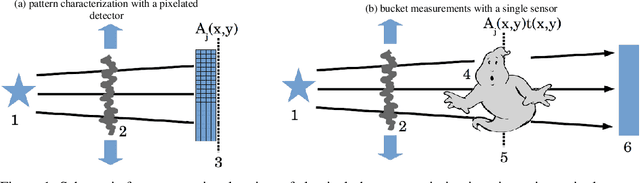



Classical ghost imaging is a new paradigm in imaging where the image of an object is not measured directly with a pixelated detector. Rather, the object is subject to a set of illumination patterns and the total interaction of the object, e.g., reflected or transmitted photons or particles, is measured for each pattern with a single-pixel or bucket detector. An image of the object is then computed through the correlation of each pattern and the corresponding bucket value. Assuming no prior knowledge of the object, the set of patterns used to compute the ghost image dictates the image quality. In the visible-light regime, programmable spatial light modulators can generate the illumination patterns. In many other regimes -- such as x rays, electrons, and neutrons -- no such dynamically configurable modulators exist, and patterns are commonly produced by employing a transversely-translated mask. In this paper we explore some of the properties of masks or speckle that should be considered to maximize ghost-image quality, given a certain experimental classical ghost-imaging setup employing a transversely-displaced but otherwise non-configurable mask.
Head-Free Lightweight Semantic Segmentation with Linear Transformer
Jan 11, 2023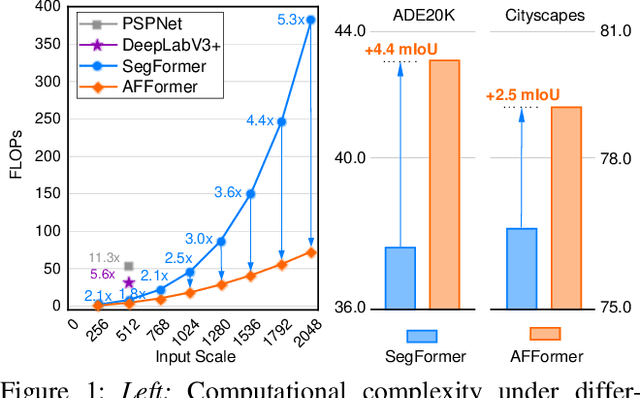
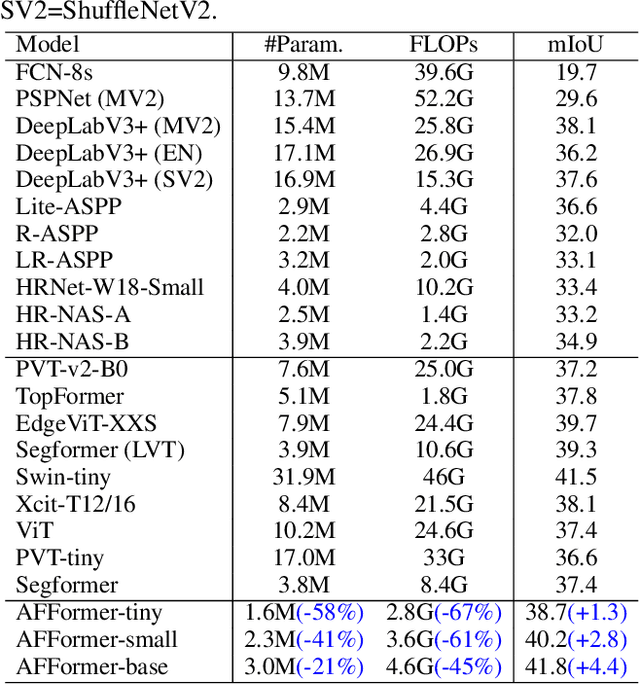
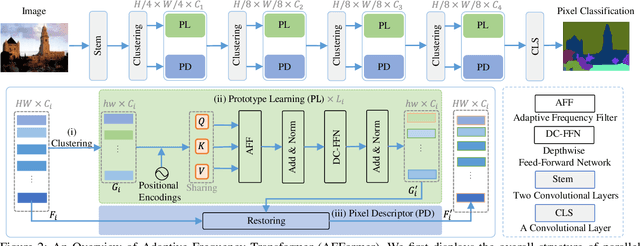

Existing semantic segmentation works have been mainly focused on designing effective decoders; however, the computational load introduced by the overall structure has long been ignored, which hinders their applications on resource-constrained hardwares. In this paper, we propose a head-free lightweight architecture specifically for semantic segmentation, named Adaptive Frequency Transformer. It adopts a parallel architecture to leverage prototype representations as specific learnable local descriptions which replaces the decoder and preserves the rich image semantics on high-resolution features. Although removing the decoder compresses most of the computation, the accuracy of the parallel structure is still limited by low computational resources. Therefore, we employ heterogeneous operators (CNN and Vision Transformer) for pixel embedding and prototype representations to further save computational costs. Moreover, it is very difficult to linearize the complexity of the vision Transformer from the perspective of spatial domain. Due to the fact that semantic segmentation is very sensitive to frequency information, we construct a lightweight prototype learning block with adaptive frequency filter of complexity $O(n)$ to replace standard self attention with $O(n^{2})$. Extensive experiments on widely adopted datasets demonstrate that our model achieves superior accuracy while retaining only 3M parameters. On the ADE20K dataset, our model achieves 41.8 mIoU and 4.6 GFLOPs, which is 4.4 mIoU higher than Segformer, with 45% less GFLOPs. On the Cityscapes dataset, our model achieves 78.7 mIoU and 34.4 GFLOPs, which is 2.5 mIoU higher than Segformer with 72.5% less GFLOPs. Code is available at https://github.com/dongbo811/AFFormer.