 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Head-Free Lightweight Semantic Segmentation with Linear Transformer
Jan 11, 2023
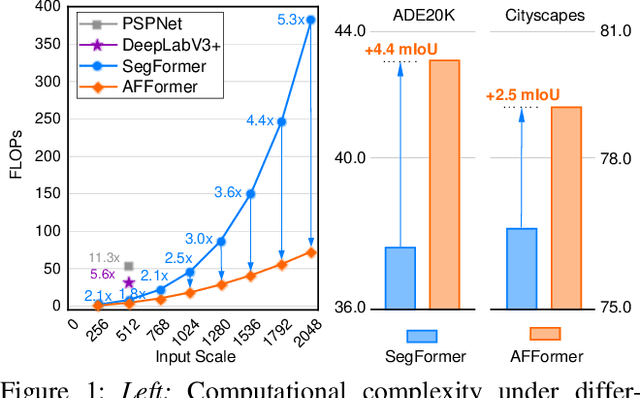
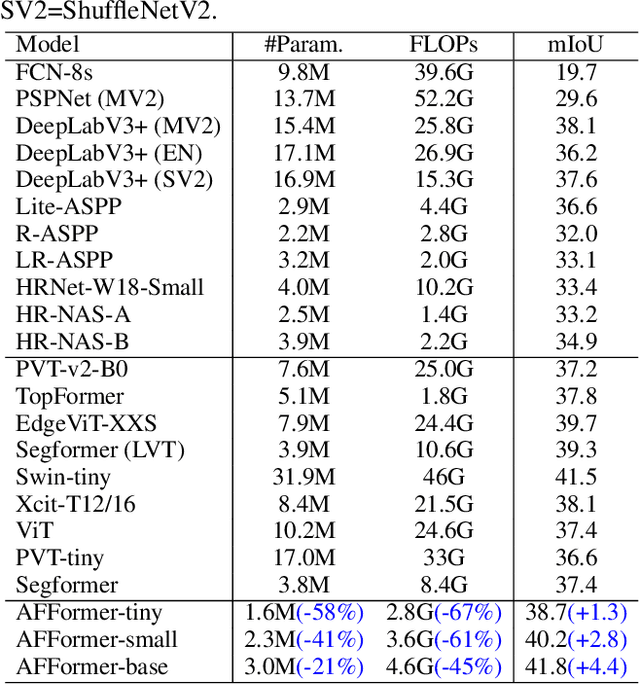
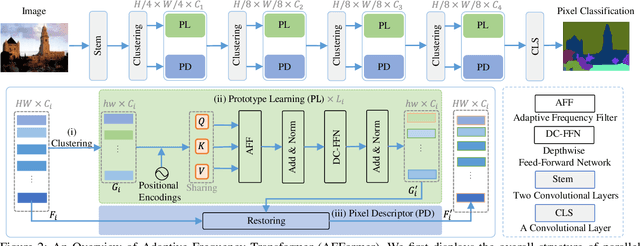

Existing semantic segmentation works have been mainly focused on designing effective decoders; however, the computational load introduced by the overall structure has long been ignored, which hinders their applications on resource-constrained hardwares. In this paper, we propose a head-free lightweight architecture specifically for semantic segmentation, named Adaptive Frequency Transformer. It adopts a parallel architecture to leverage prototype representations as specific learnable local descriptions which replaces the decoder and preserves the rich image semantics on high-resolution features. Although removing the decoder compresses most of the computation, the accuracy of the parallel structure is still limited by low computational resources. Therefore, we employ heterogeneous operators (CNN and Vision Transformer) for pixel embedding and prototype representations to further save computational costs. Moreover, it is very difficult to linearize the complexity of the vision Transformer from the perspective of spatial domain. Due to the fact that semantic segmentation is very sensitive to frequency information, we construct a lightweight prototype learning block with adaptive frequency filter of complexity $O(n)$ to replace standard self attention with $O(n^{2})$. Extensive experiments on widely adopted datasets demonstrate that our model achieves superior accuracy while retaining only 3M parameters. On the ADE20K dataset, our model achieves 41.8 mIoU and 4.6 GFLOPs, which is 4.4 mIoU higher than Segformer, with 45% less GFLOPs. On the Cityscapes dataset, our model achieves 78.7 mIoU and 34.4 GFLOPs, which is 2.5 mIoU higher than Segformer with 72.5% less GFLOPs. Code is available at https://github.com/dongbo811/AFFormer.
Active learning using adaptable task-based prioritisation
Dec 03, 2022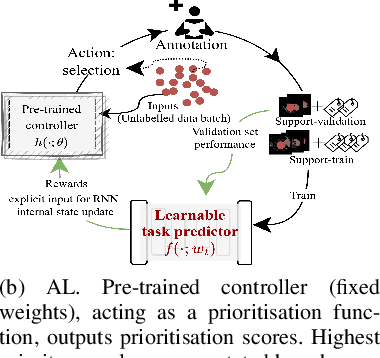
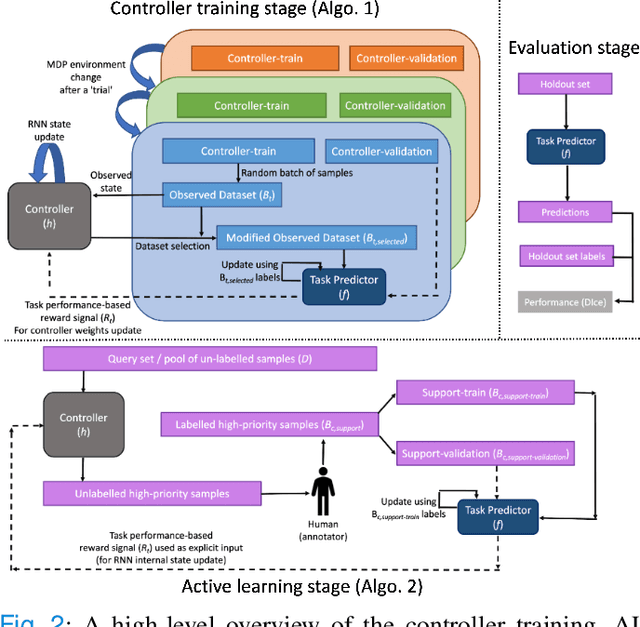
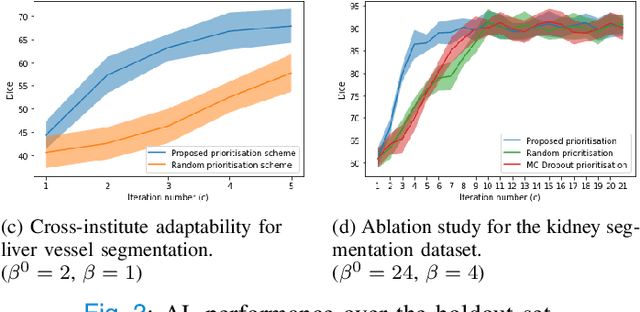
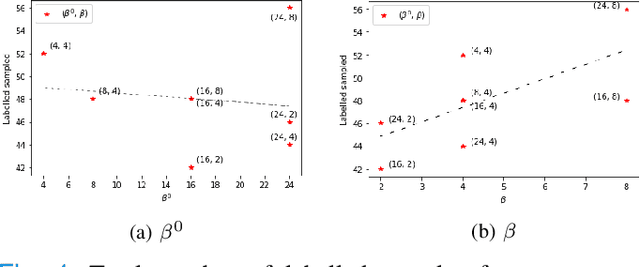
Supervised machine learning-based medical image computing applications necessitate expert label curation, while unlabelled image data might be relatively abundant. Active learning methods aim to prioritise a subset of available image data for expert annotation, for label-efficient model training. We develop a controller neural network that measures priority of images in a sequence of batches, as in batch-mode active learning, for multi-class segmentation tasks. The controller is optimised by rewarding positive task-specific performance gain, within a Markov decision process (MDP) environment that also optimises the task predictor. In this work, the task predictor is a segmentation network. A meta-reinforcement learning algorithm is proposed with multiple MDPs, such that the pre-trained controller can be adapted to a new MDP that contains data from different institutes and/or requires segmentation of different organs or structures within the abdomen. We present experimental results using multiple CT datasets from more than one thousand patients, with segmentation tasks of nine different abdominal organs, to demonstrate the efficacy of the learnt prioritisation controller function and its cross-institute and cross-organ adaptability. We show that the proposed adaptable prioritisation metric yields converging segmentation accuracy for the novel class of kidney, unseen in training, using between approximately 40\% to 60\% of labels otherwise required with other heuristic or random prioritisation metrics. For clinical datasets of limited size, the proposed adaptable prioritisation offers a performance improvement of 22.6\% and 10.2\% in Dice score, for tasks of kidney and liver vessel segmentation, respectively, compared to random prioritisation and alternative active sampling strategies.
Learning Feature Disentanglement and Dynamic Fusion for Recaptured Image Forensic
Jun 13, 2022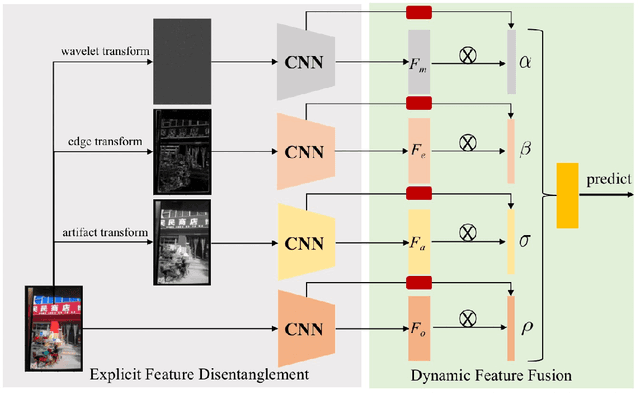
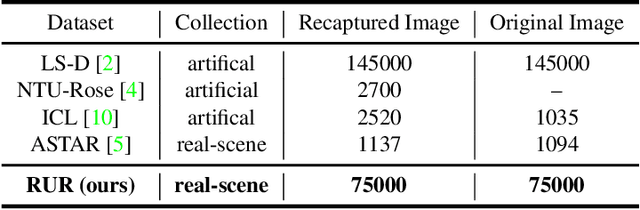
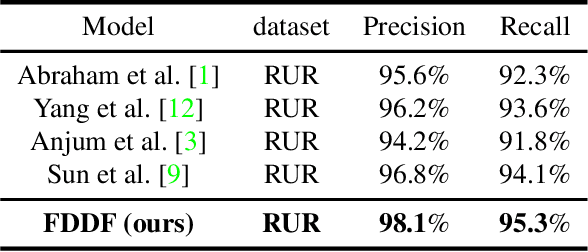
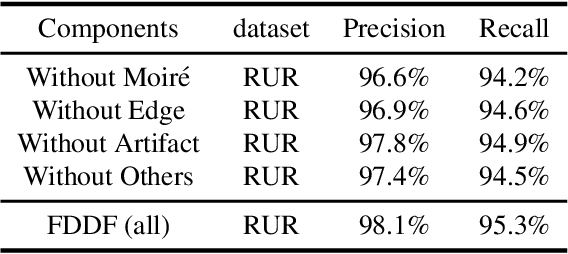
Image recapture seriously breaks the fairness of artificial intelligent (AI) systems, which deceives the system by recapturing others' images. Most of the existing recapture models can only address a single pattern of recapture (e.g., moire, edge, artifact, and others) based on the datasets with simulated recaptured images using fixed electronic devices. In this paper, we explicitly redefine image recapture forensic task as four patterns of image recapture recognition, i.e., moire recapture, edge recapture, artifact recapture, and other recapture. Meanwhile, we propose a novel Feature Disentanglement and Dynamic Fusion (FDDF) model to adaptively learn the most effective recapture feature representation for covering different recapture pattern recognition. Furthermore, we collect a large-scale Real-scene Universal Recapture (RUR) dataset containing various recapture patterns, which is about five times the number of previously published datasets. To the best of our knowledge, we are the first to propose a general model and a general real-scene large-scale dataset for recaptured image forensic. Extensive experiments show that our proposed FDDF can achieve state-of-the-art performance on the RUR dataset.
SparseFusion: Distilling View-conditioned Diffusion for 3D Reconstruction
Dec 04, 2022


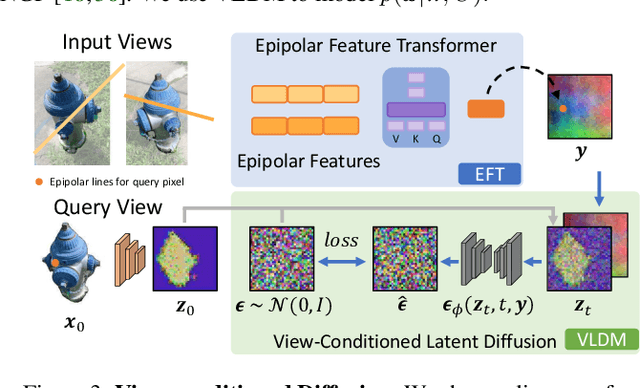
We propose SparseFusion, a sparse view 3D reconstruction approach that unifies recent advances in neural rendering and probabilistic image generation. Existing approaches typically build on neural rendering with re-projected features but fail to generate unseen regions or handle uncertainty under large viewpoint changes. Alternate methods treat this as a (probabilistic) 2D synthesis task, and while they can generate plausible 2D images, they do not infer a consistent underlying 3D. However, we find that this trade-off between 3D consistency and probabilistic image generation does not need to exist. In fact, we show that geometric consistency and generative inference can be complementary in a mode-seeking behavior. By distilling a 3D consistent scene representation from a view-conditioned latent diffusion model, we are able to recover a plausible 3D representation whose renderings are both accurate and realistic. We evaluate our approach across 51 categories in the CO3D dataset and show that it outperforms existing methods, in both distortion and perception metrics, for sparse-view novel view synthesis.
Rethinking Disparity: A Depth Range Free Multi-View Stereo Based on Disparity
Dec 04, 2022
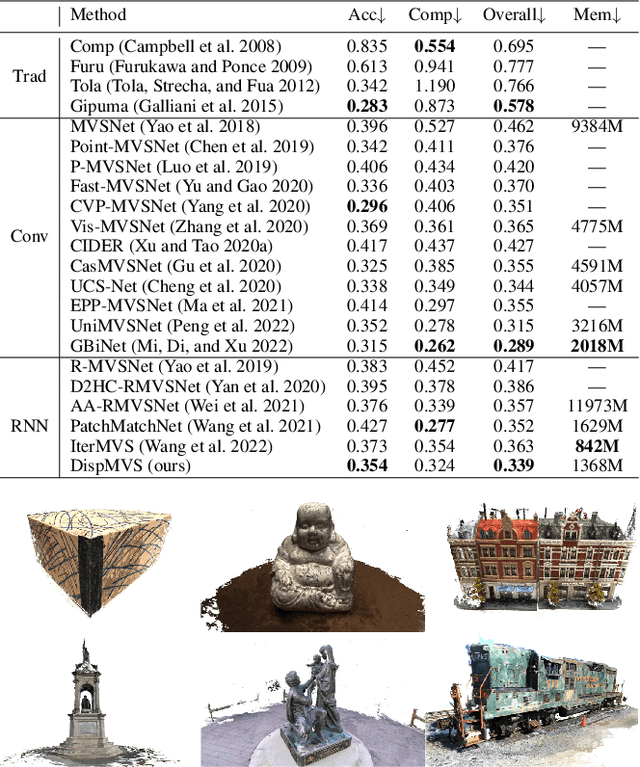
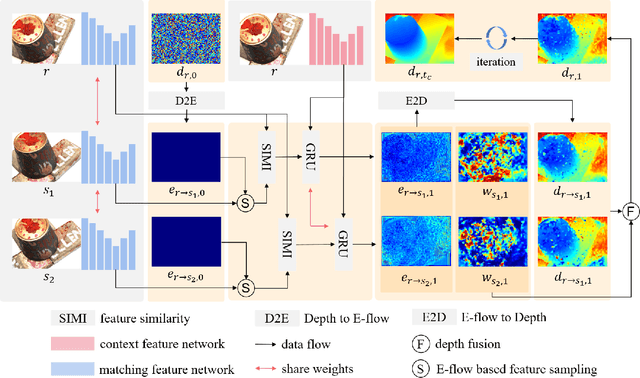
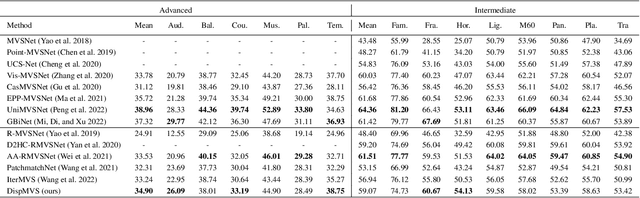
Existing learning-based multi-view stereo (MVS) methods rely on the depth range to build the 3D cost volume and may fail when the range is too large or unreliable. To address this problem, we propose a disparity-based MVS method based on the epipolar disparity flow (E-flow), called DispMVS, which infers the depth information from the pixel movement between two views. The core of DispMVS is to construct a 2D cost volume on the image plane along the epipolar line between each pair (between the reference image and several source images) for pixel matching and fuse uncountable depths triangulated from each pair by multi-view geometry to ensure multi-view consistency. To be robust, DispMVS starts from a randomly initialized depth map and iteratively refines the depth map with the help of the coarse-to-fine strategy. Experiments on DTUMVS and Tanks\&Temple datasets show that DispMVS is not sensitive to the depth range and achieves state-of-the-art results with lower GPU memory.
FFHQ-UV: Normalized Facial UV-Texture Dataset for 3D Face Reconstruction
Nov 25, 2022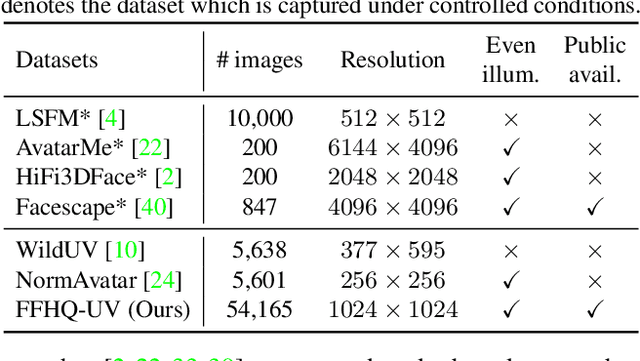

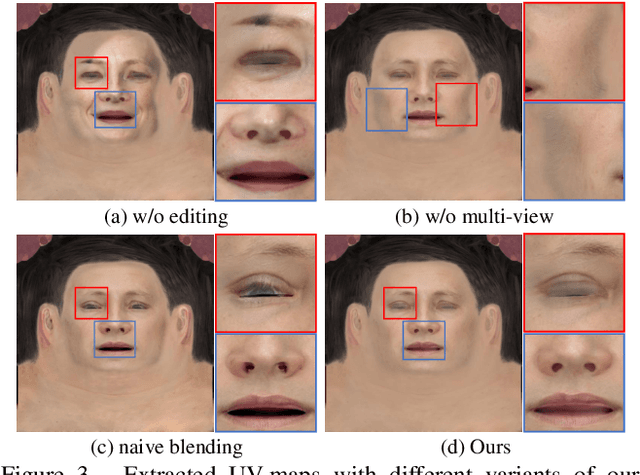

We present a large-scale facial UV-texture dataset that contains over 50,000 high-quality texture UV-maps with even illuminations, neutral expressions, and cleaned facial regions, which are desired characteristics for rendering realistic 3D face models under different lighting conditions. The dataset is derived from a large-scale face image dataset namely FFHQ, with the help of our fully automatic and robust UV-texture production pipeline. Our pipeline utilizes the recent advances in StyleGAN-based facial image editing approaches to generate multi-view normalized face images from single-image inputs. An elaborated UV-texture extraction, correction, and completion procedure is then applied to produce high-quality UV-maps from the normalized face images. Compared with existing UV-texture datasets, our dataset has more diverse and higher-quality texture maps. We further train a GAN-based texture decoder as the nonlinear texture basis for parametric fitting based 3D face reconstruction. Experiments show that our method improves the reconstruction accuracy over state-of-the-art approaches, and more importantly, produces high-quality texture maps that are ready for realistic renderings. The dataset, code, and pre-trained texture decoder are publicly available at https://github.com/csbhr/FFHQ-UV.
Masked Lip-Sync Prediction by Audio-Visual Contextual Exploitation in Transformers
Dec 09, 2022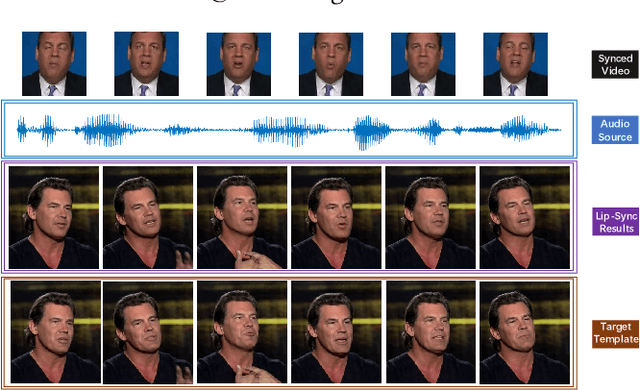
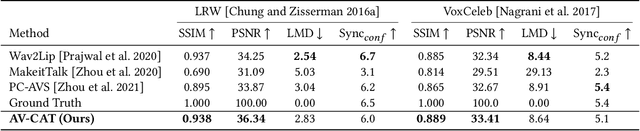
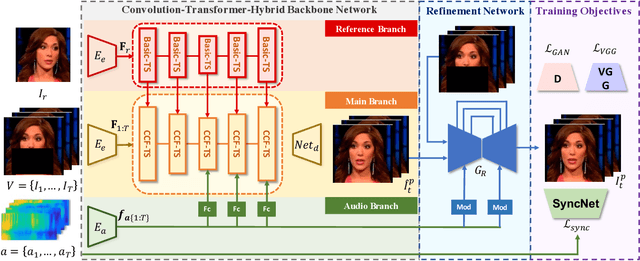
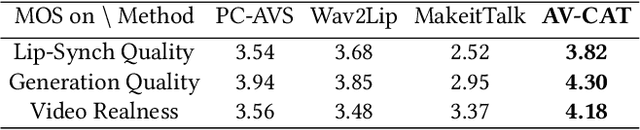
Previous studies have explored generating accurately lip-synced talking faces for arbitrary targets given audio conditions. However, most of them deform or generate the whole facial area, leading to non-realistic results. In this work, we delve into the formulation of altering only the mouth shapes of the target person. This requires masking a large percentage of the original image and seamlessly inpainting it with the aid of audio and reference frames. To this end, we propose the Audio-Visual Context-Aware Transformer (AV-CAT) framework, which produces accurate lip-sync with photo-realistic quality by predicting the masked mouth shapes. Our key insight is to exploit desired contextual information provided in audio and visual modalities thoroughly with delicately designed Transformers. Specifically, we propose a convolution-Transformer hybrid backbone and design an attention-based fusion strategy for filling the masked parts. It uniformly attends to the textural information on the unmasked regions and the reference frame. Then the semantic audio information is involved in enhancing the self-attention computation. Additionally, a refinement network with audio injection improves both image and lip-sync quality. Extensive experiments validate that our model can generate high-fidelity lip-synced results for arbitrary subjects.
AttEntropy: Segmenting Unknown Objects in Complex Scenes using the Spatial Attention Entropy of Semantic Segmentation Transformers
Dec 29, 2022
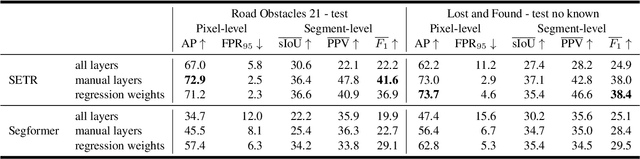
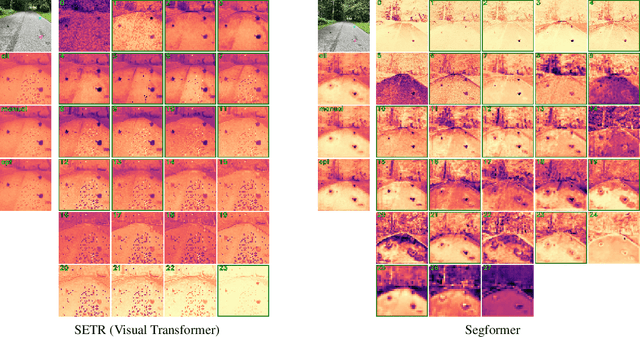
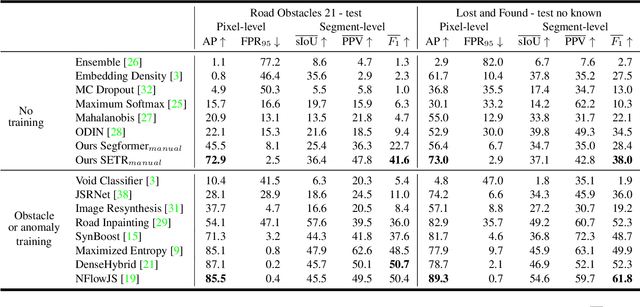
Vision transformers have emerged as powerful tools for many computer vision tasks. It has been shown that their features and class tokens can be used for salient object segmentation. However, the properties of segmentation transformers remain largely unstudied. In this work we conduct an in-depth study of the spatial attentions of different backbone layers of semantic segmentation transformers and uncover interesting properties. The spatial attentions of a patch intersecting with an object tend to concentrate within the object, whereas the attentions of larger, more uniform image areas rather follow a diffusive behavior. In other words, vision transformers trained to segment a fixed set of object classes generalize to objects well beyond this set. We exploit this by extracting heatmaps that can be used to segment unknown objects within diverse backgrounds, such as obstacles in traffic scenes. Our method is training-free and its computational overhead negligible. We use off-the-shelf transformers trained for street-scene segmentation to process other scene types.
Detection of out-of-distribution samples using binary neuron activation patterns
Dec 29, 2022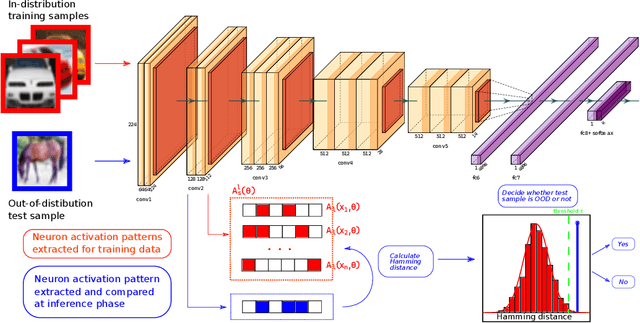
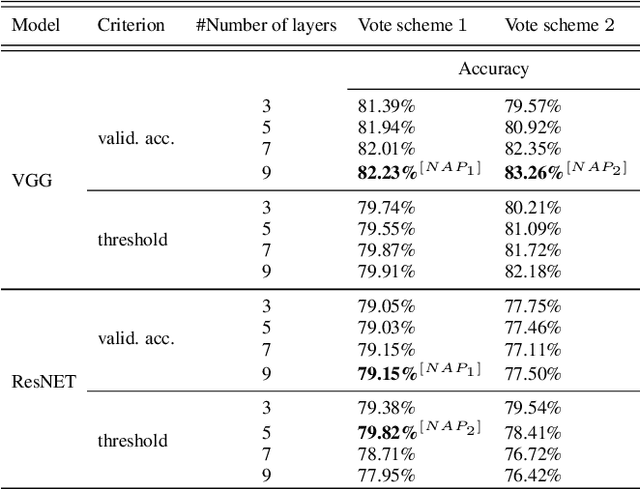
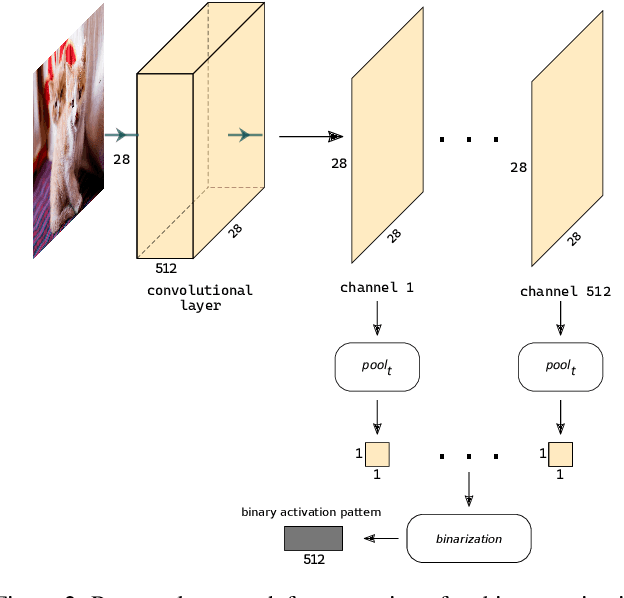
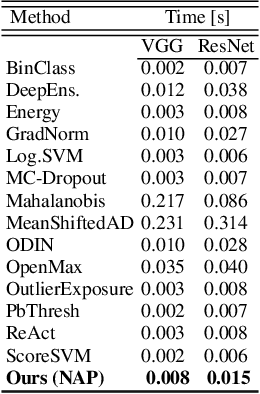
Deep neural networks (DNN) have outstanding performance in various applications. Despite numerous efforts of the research community, out-of-distribution (OOD) samples remain significant limitation of DNN classifiers. The ability to identify previously unseen inputs as novel is crucial in safety-critical applications such as self-driving cars, unmanned aerial vehicles and robots. Existing approaches to detect OOD samples treat a DNN as a black box and assess the confidence score of the output predictions. Unfortunately, this method frequently fails, because DNN are not trained to reduce their confidence for OOD inputs. In this work, we introduce a novel method for OOD detection. Our method is motivated by theoretical analysis of neuron activation patterns (NAP) in ReLU based architectures. The proposed method does not introduce high computational workload due to the binary representation of the activation patterns extracted from convolutional layers. The extensive empirical evaluation proves its high performance on various DNN architectures and seven image datasets. ion.
Learning Series-Parallel Lookup Tables for Efficient Image Super-Resolution
Jul 26, 2022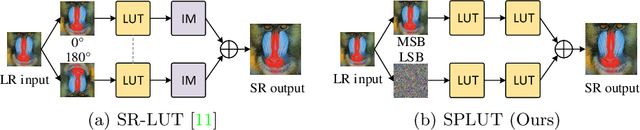
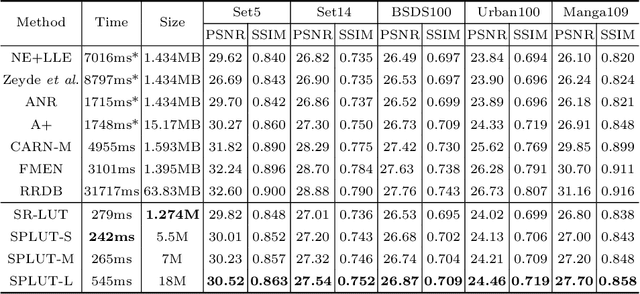
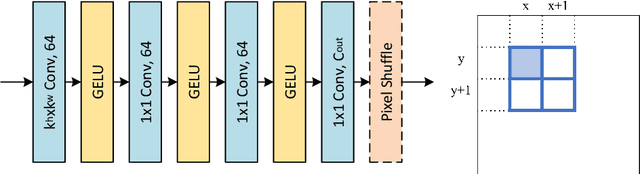
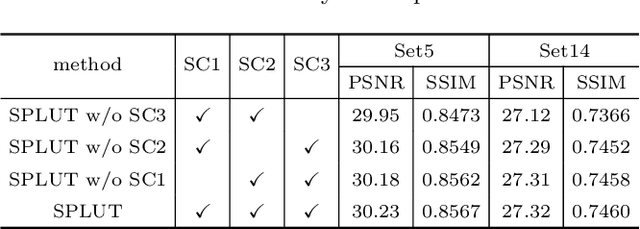
Lookup table (LUT) has shown its efficacy in low-level vision tasks due to the valuable characteristics of low computational cost and hardware independence. However, recent attempts to address the problem of single image super-resolution (SISR) with lookup tables are highly constrained by the small receptive field size. Besides, their frameworks of single-layer lookup tables limit the extension and generalization capacities of the model. In this paper, we propose a framework of series-parallel lookup tables (SPLUT) to alleviate the above issues and achieve efficient image super-resolution. On the one hand, we cascade multiple lookup tables to enlarge the receptive field of each extracted feature vector. On the other hand, we propose a parallel network which includes two branches of cascaded lookup tables which process different components of the input low-resolution images. By doing so, the two branches collaborate with each other and compensate for the precision loss of discretizing input pixels when establishing lookup tables. Compared to previous lookup table-based methods, our framework has stronger representation abilities with more flexible architectures. Furthermore, we no longer need interpolation methods which introduce redundant computations so that our method can achieve faster inference speed. Extensive experimental results on five popular benchmark datasets show that our method obtains superior SISR performance in a more efficient way. The code is available at https://github.com/zhjy2016/SPLUT.