 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Series-Parallel Lookup Tables for Efficient Image Super-Resolution
Jul 26, 2022
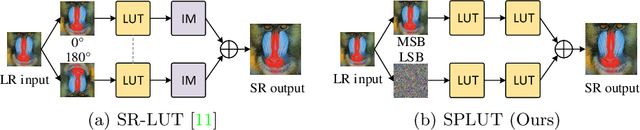
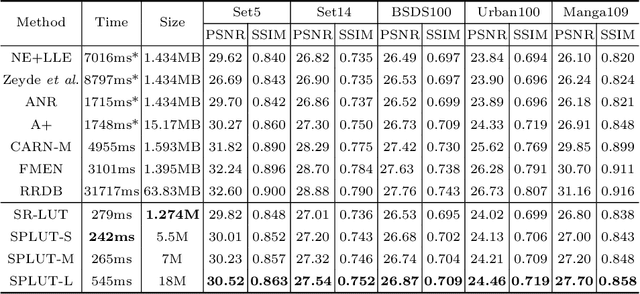
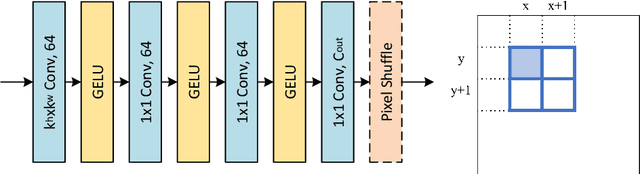
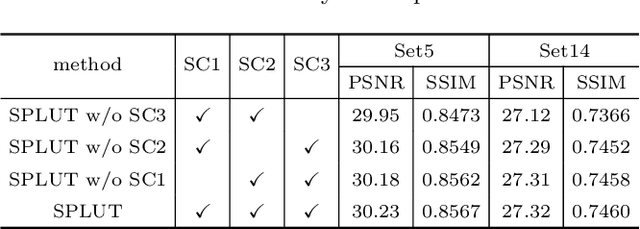
Lookup table (LUT) has shown its efficacy in low-level vision tasks due to the valuable characteristics of low computational cost and hardware independence. However, recent attempts to address the problem of single image super-resolution (SISR) with lookup tables are highly constrained by the small receptive field size. Besides, their frameworks of single-layer lookup tables limit the extension and generalization capacities of the model. In this paper, we propose a framework of series-parallel lookup tables (SPLUT) to alleviate the above issues and achieve efficient image super-resolution. On the one hand, we cascade multiple lookup tables to enlarge the receptive field of each extracted feature vector. On the other hand, we propose a parallel network which includes two branches of cascaded lookup tables which process different components of the input low-resolution images. By doing so, the two branches collaborate with each other and compensate for the precision loss of discretizing input pixels when establishing lookup tables. Compared to previous lookup table-based methods, our framework has stronger representation abilities with more flexible architectures. Furthermore, we no longer need interpolation methods which introduce redundant computations so that our method can achieve faster inference speed. Extensive experimental results on five popular benchmark datasets show that our method obtains superior SISR performance in a more efficient way. The code is available at https://github.com/zhjy2016/SPLUT.
Guided Depth Super-Resolution by Deep Anisotropic Diffusion
Nov 21, 2022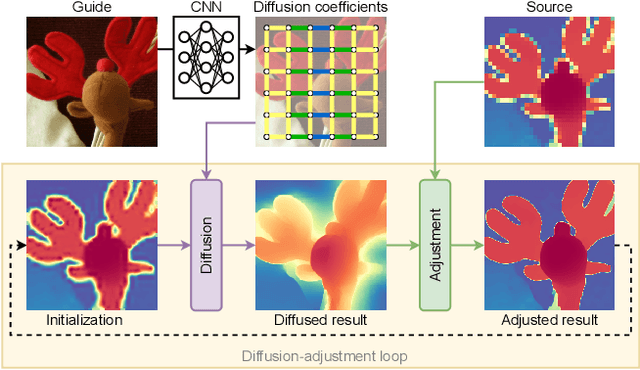
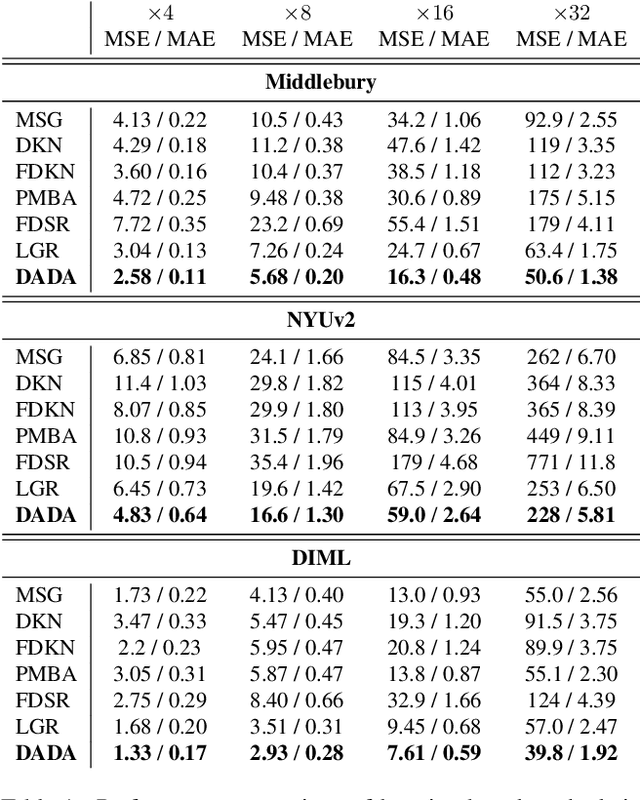
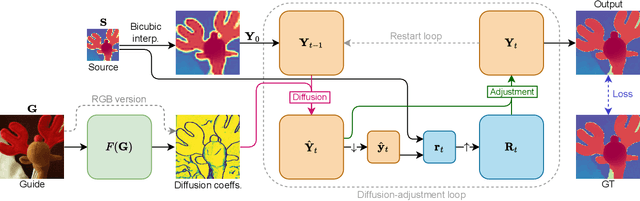
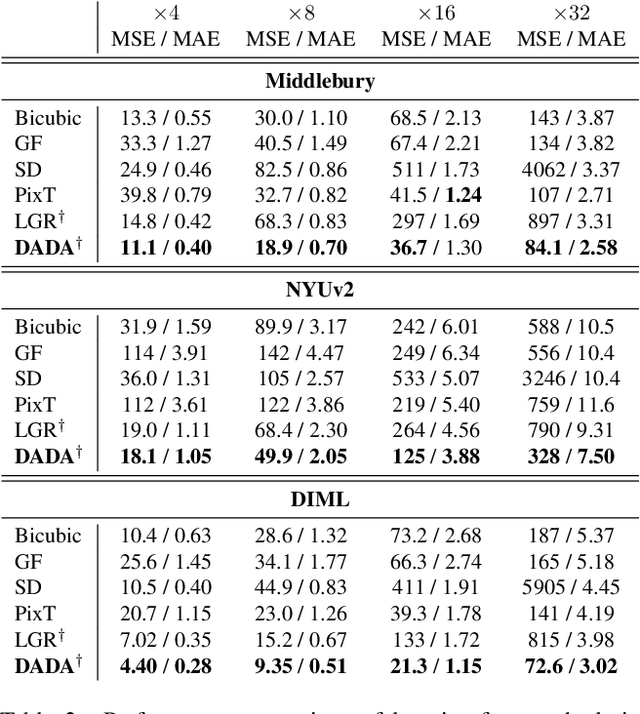
Performing super-resolution of a depth image using the guidance from an RGB image is a problem that concerns several fields, such as robotics, medical imaging, and remote sensing. While deep learning methods have achieved good results in this problem, recent work highlighted the value of combining modern methods with more formal frameworks. In this work, we propose a novel approach which combines guided anisotropic diffusion with a deep convolutional network and advances the state of the art for guided depth super-resolution. The edge transferring/enhancing properties of the diffusion are boosted by the contextual reasoning capabilities of modern networks, and a strict adjustment step guarantees perfect adherence to the source image. We achieve unprecedented results in three commonly used benchmarks for guided depth super-resolution. The performance gain compared to other methods is the largest at larger scales, such as x32 scaling. Code for the proposed method will be made available to promote reproducibility of our results.
Pixel-by-pixel Mean Opinion Score (pMOS) for No-Reference Image Quality Assessment
Jun 14, 2022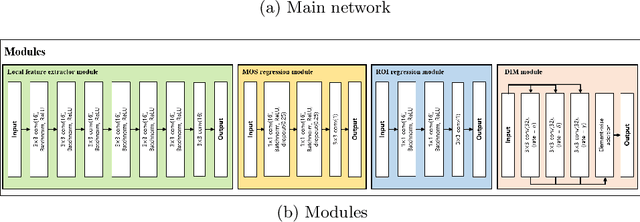
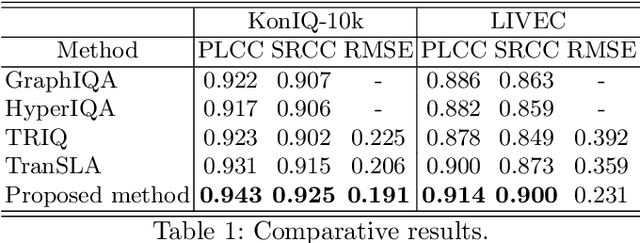
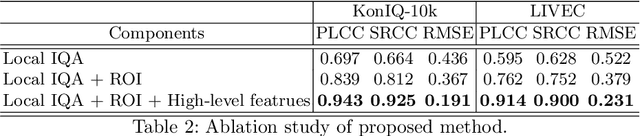
Deep-learning based techniques have contributed to the remarkable progress in the field of automatic image quality assessment (IQA). Existing IQA methods are designed to measure the quality of an image in terms of Mean Opinion Score (MOS) at the image-level (i.e. the whole image) or at the patch-level (dividing the image into multiple units and measuring quality of each patch). Some applications may require assessing the quality at the pixel-level (i.e. MOS value for each pixel), however, this is not possible in case of existing techniques as the spatial information is lost owing to their network structures. This paper proposes an IQA algorithm that can measure the MOS at the pixel-level, in addition to the image-level MOS. The proposed algorithm consists of three core parts, namely: i) Local IQA; ii) Region of Interest (ROI) prediction; iii) High-level feature embedding. The Local IQA part outputs the MOS at the pixel-level, or pixel-by-pixel MOS - we term it 'pMOS'. The ROI prediction part outputs weights that characterize the relative importance of region when calculating the image-level IQA. The high-level feature embedding part extracts high-level image features which are then embedded into the Local IQA part. In other words, the proposed algorithm yields three outputs: the pMOS which represents MOS for each pixel, the weights from the ROI indicating the relative importance of region, and finally the image-level MOS that is obtained by the weighted sum of pMOS and ROI values. The image-level MOS thus obtained by utilizing pMOS and ROI weights shows superior performance compared to the existing popular IQA techniques. In addition, visualization results indicate that predicted pMOS and ROI outputs are reasonably aligned with the general principles of the human visual system (HVS).
Hyperbolic Image Segmentation
Mar 11, 2022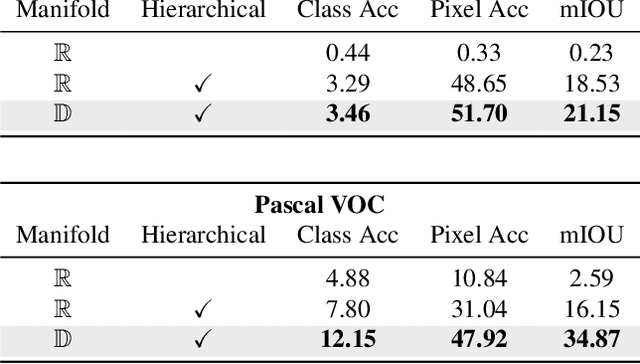

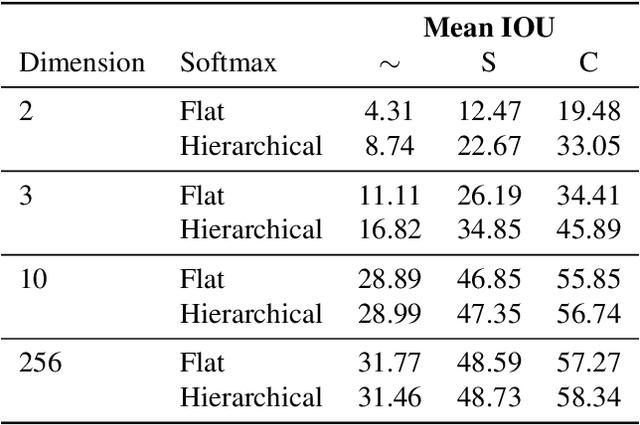
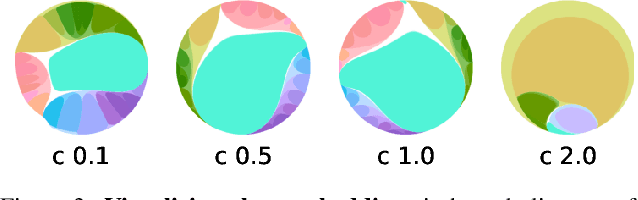
For image segmentation, the current standard is to perform pixel-level optimization and inference in Euclidean output embedding spaces through linear hyperplanes. In this work, we show that hyperbolic manifolds provide a valuable alternative for image segmentation and propose a tractable formulation of hierarchical pixel-level classification in hyperbolic space. Hyperbolic Image Segmentation opens up new possibilities and practical benefits for segmentation, such as uncertainty estimation and boundary information for free, zero-label generalization, and increased performance in low-dimensional output embeddings.
Implementation of fast ICA using memristor crossbar arrays for blind image source separations
Aug 07, 2022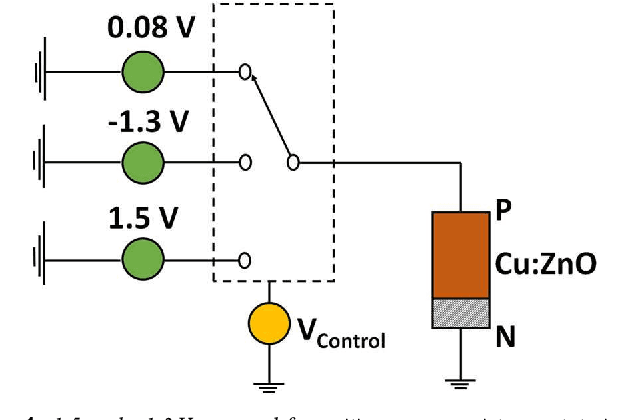
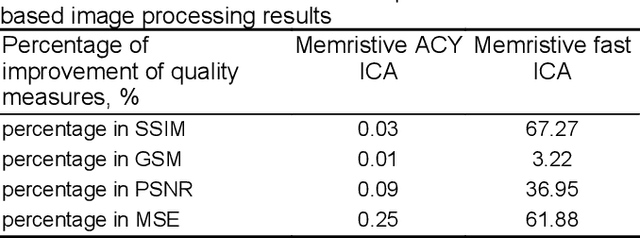
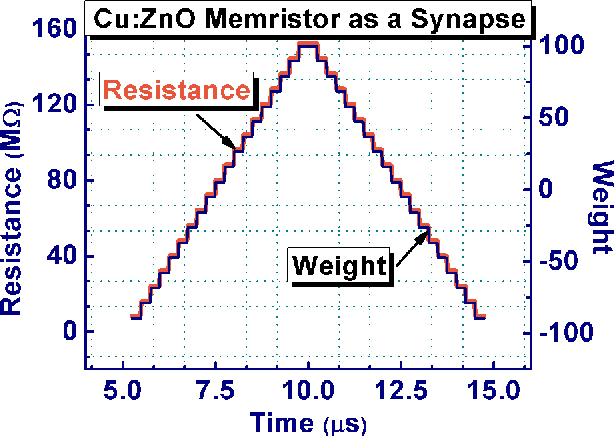
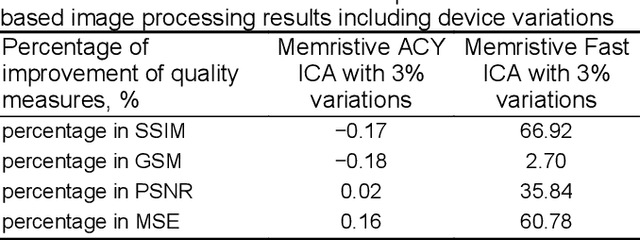
Independent component analysis is an unsupervised learning approach for computing the independent components (ICs) from the multivariate signals or data matrix. The ICs are evaluated based on the multiplication of the weight matrix with the multivariate data matrix. This study proposes a novel memristor crossbar array for the implementation of both ACY ICA and Fast ICA for blind source separation. The data input was applied in the form of pulse width modulated voltages to the crossbar array and the weight of the implemented neural network is stored in the memristor. The output charges from the memristor columns are used to calculate the weight update, which is executed through the voltages kept higher than the memristor Set/Reset voltages. In order to demonstrate its potential application, the proposed memristor crossbar arrays based fast ICA architecture is employed for image source separation problem. The experimental results demonstrate that the proposed approach is very effective to separate image sources, and also the contrast of the images are improved with an improvement factor in terms of percentage of structural similarity as 67.27% when compared with the software-based implementation of conventional ACY ICA and Fast ICA algorithms.
Why Capsule Neural Networks Do Not Scale: Challenging the Dynamic Parse-Tree Assumption
Jan 04, 2023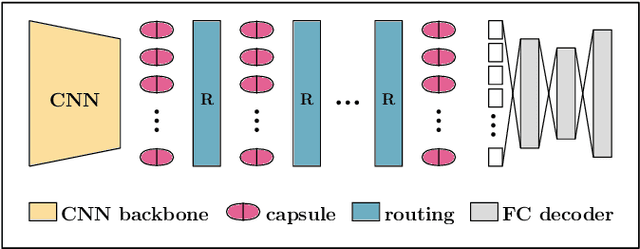
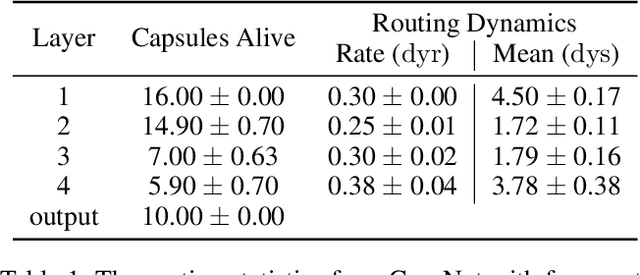
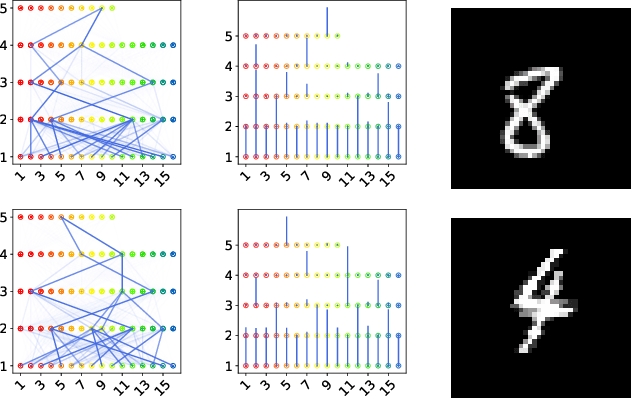
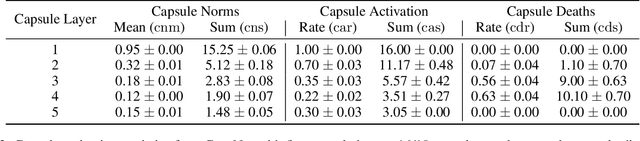
Capsule neural networks replace simple, scalar-valued neurons with vector-valued capsules. They are motivated by the pattern recognition system in the human brain, where complex objects are decomposed into a hierarchy of simpler object parts. Such a hierarchy is referred to as a parse-tree. Conceptually, capsule neural networks have been defined to realize such parse-trees. The capsule neural network (CapsNet), by Sabour, Frosst, and Hinton, is the first actual implementation of the conceptual idea of capsule neural networks. CapsNets achieved state-of-the-art performance on simple image recognition tasks with fewer parameters and greater robustness to affine transformations than comparable approaches. This sparked extensive follow-up research. However, despite major efforts, no work was able to scale the CapsNet architecture to more reasonable-sized datasets. Here, we provide a reason for this failure and argue that it is most likely not possible to scale CapsNets beyond toy examples. In particular, we show that the concept of a parse-tree, the main idea behind capsule neuronal networks, is not present in CapsNets. We also show theoretically and experimentally that CapsNets suffer from a vanishing gradient problem that results in the starvation of many capsules during training.
MessageNet: Message Classification using Natural Language Processing and Meta-data
Jan 04, 2023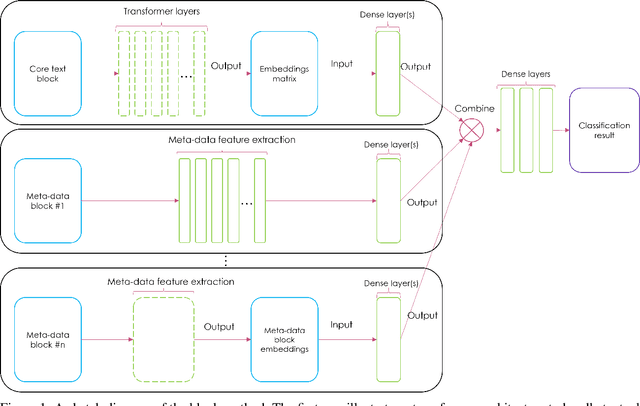
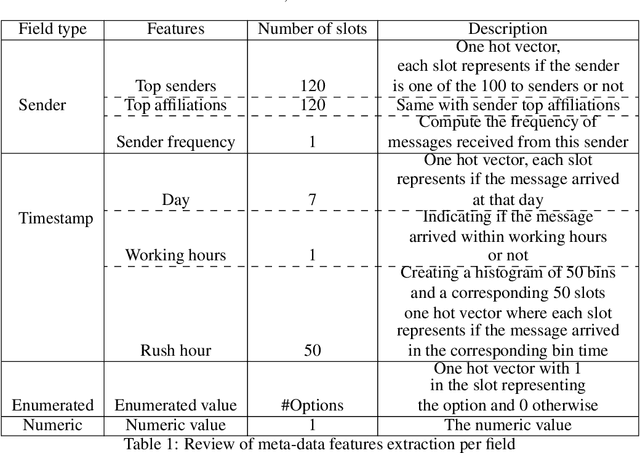
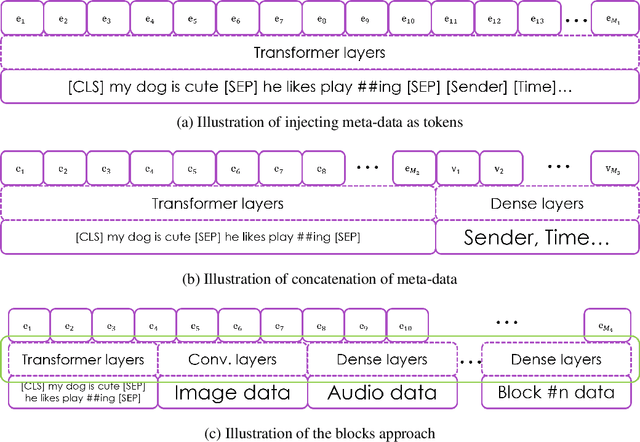
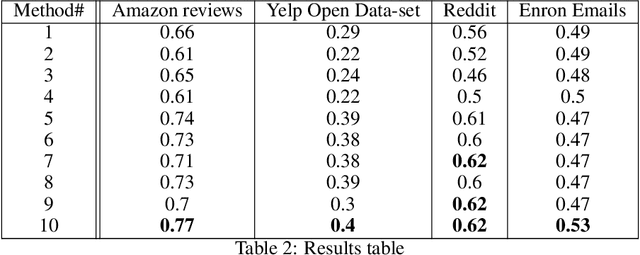
In this paper we propose a new Deep Learning (DL) approach for message classification. Our method is based on the state-of-the-art Natural Language Processing (NLP) building blocks, combined with a novel technique for infusing the meta-data input that is typically available in messages such as the sender information, timestamps, attached image, audio, affiliations, and more. As we demonstrate throughout the paper, going beyond the mere text by leveraging all available channels in the message, could yield an improved representation and higher classification accuracy. To achieve message representation, each type of input is processed in a dedicated block in the neural network architecture that is suitable for the data type. Such an implementation enables training all blocks together simultaneously, and forming cross channels features in the network. We show in the Experiments Section that in some cases, message's meta-data holds an additional information that cannot be extracted just from the text, and when using this information we achieve better performance. Furthermore, we demonstrate that our multi-modality block approach outperforms other approaches for injecting the meta data to the the text classifier.
ORCa: Glossy Objects as Radiance Field Cameras
Dec 12, 2022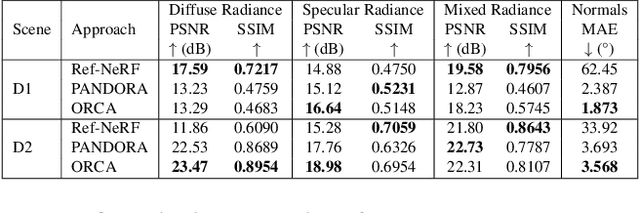
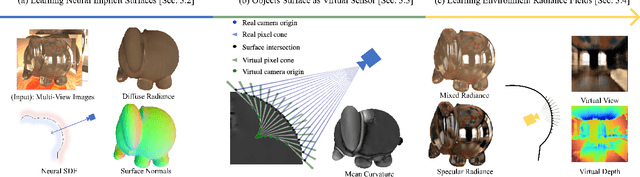
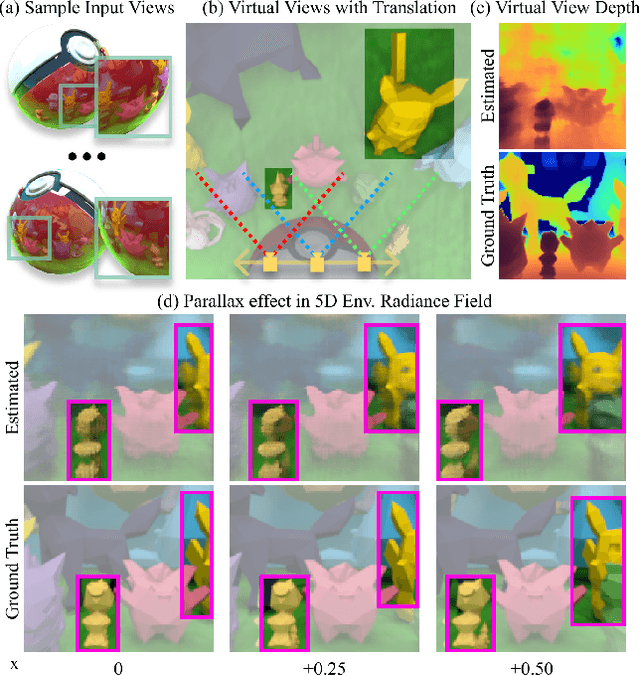
Reflections on glossy objects contain valuable and hidden information about the surrounding environment. By converting these objects into cameras, we can unlock exciting applications, including imaging beyond the camera's field-of-view and from seemingly impossible vantage points, e.g. from reflections on the human eye. However, this task is challenging because reflections depend jointly on object geometry, material properties, the 3D environment, and the observer viewing direction. Our approach converts glossy objects with unknown geometry into radiance-field cameras to image the world from the object's perspective. Our key insight is to convert the object surface into a virtual sensor that captures cast reflections as a 2D projection of the 5D environment radiance field visible to the object. We show that recovering the environment radiance fields enables depth and radiance estimation from the object to its surroundings in addition to beyond field-of-view novel-view synthesis, i.e. rendering of novel views that are only directly-visible to the glossy object present in the scene, but not the observer. Moreover, using the radiance field we can image around occluders caused by close-by objects in the scene. Our method is trained end-to-end on multi-view images of the object and jointly estimates object geometry, diffuse radiance, and the 5D environment radiance field.
Unsupervised Contrastive Learning of Image Representations from Ultrasound Videos with Hard Negative Mining
Jul 26, 2022
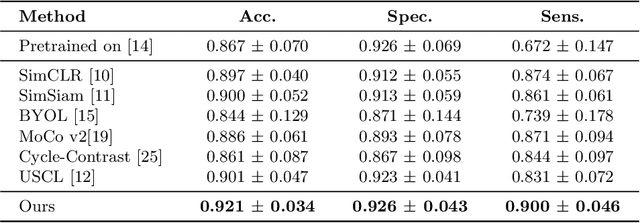
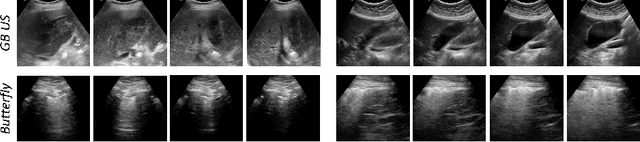
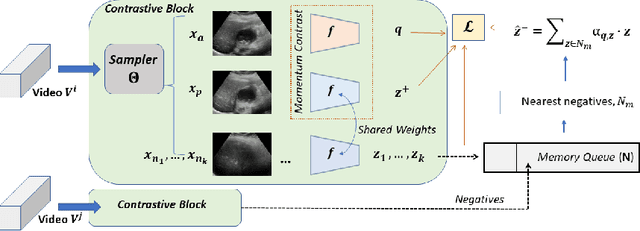
Rich temporal information and variations in viewpoints make video data an attractive choice for learning image representations using unsupervised contrastive learning (UCL) techniques. State-of-the-art (SOTA) contrastive learning techniques consider frames within a video as positives in the embedding space, whereas the frames from other videos are considered negatives. We observe that unlike multiple views of an object in natural scene videos, an Ultrasound (US) video captures different 2D slices of an organ. Hence, there is almost no similarity between the temporally distant frames of even the same US video. In this paper we propose to instead utilize such frames as hard negatives. We advocate mining both intra-video and cross-video negatives in a hardness-sensitive negative mining curriculum in a UCL framework to learn rich image representations. We deploy our framework to learn the representations of Gallbladder (GB) malignancy from US videos. We also construct the first large-scale US video dataset containing 64 videos and 15,800 frames for learning GB representations. We show that the standard ResNet50 backbone trained with our framework improves the accuracy of models pretrained with SOTA UCL techniques as well as supervised pretrained models on ImageNet for the GB malignancy detection task by 2-6%. We further validate the generalizability of our method on a publicly available lung US image dataset of COVID-19 pathologies and show an improvement of 1.5% compared to SOTA. Source code, dataset, and models are available at https://gbc-iitd.github.io/usucl.
Preprocessing Enhanced Image Compression for Machine Vision
Jun 12, 2022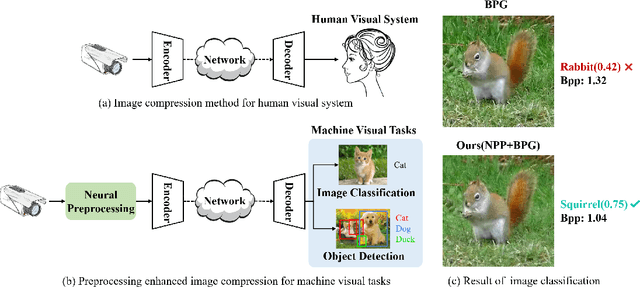
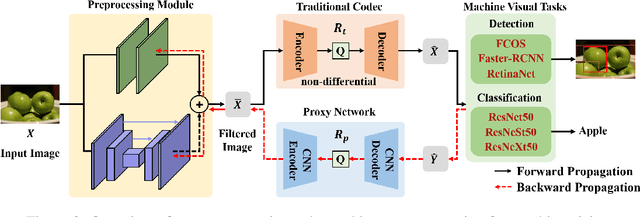
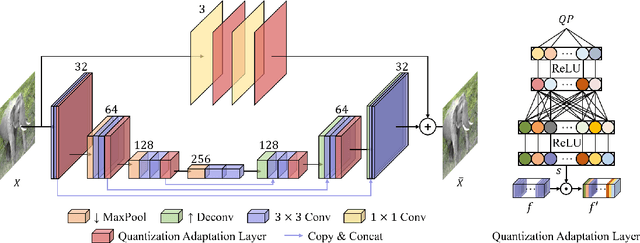
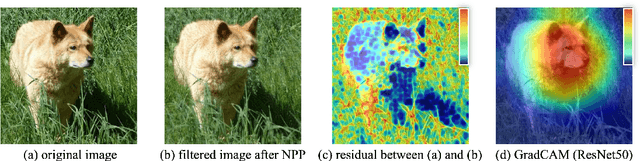
Recently, more and more images are compressed and sent to the back-end devices for the machine analysis tasks~(\textit{e.g.,} object detection) instead of being purely watched by humans. However, most traditional or learned image codecs are designed to minimize the distortion of the human visual system without considering the increased demand from machine vision systems. In this work, we propose a preprocessing enhanced image compression method for machine vision tasks to address this challenge. Instead of relying on the learned image codecs for end-to-end optimization, our framework is built upon the traditional non-differential codecs, which means it is standard compatible and can be easily deployed in practical applications. Specifically, we propose a neural preprocessing module before the encoder to maintain the useful semantic information for the downstream tasks and suppress the irrelevant information for bitrate saving. Furthermore, our neural preprocessing module is quantization adaptive and can be used in different compression ratios. More importantly, to jointly optimize the preprocessing module with the downstream machine vision tasks, we introduce the proxy network for the traditional non-differential codecs in the back-propagation stage. We provide extensive experiments by evaluating our compression method for two representative downstream tasks with different backbone networks. Experimental results show our method achieves a better trade-off between the coding bitrate and the performance of the downstream machine vision tasks by saving about 20% bitrate.