 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Radon-based Image Reconstruction for MPI using a continuously rotating FFL
Nov 21, 2022
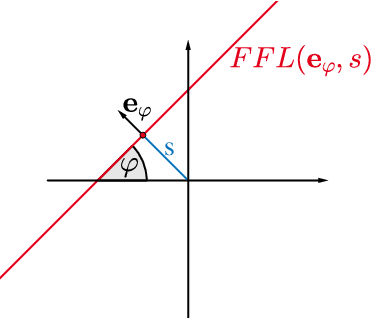
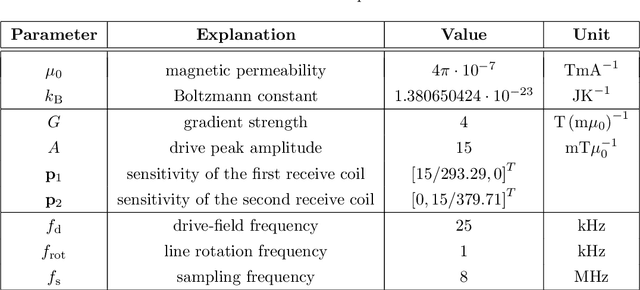
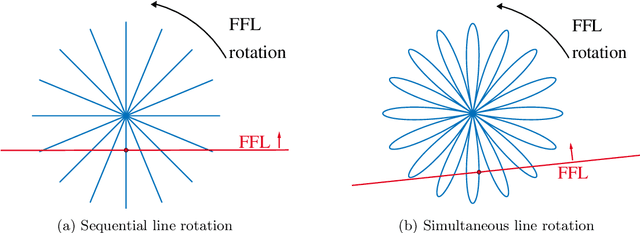

Magnetic particle imaging is a relatively new tracer-based medical imaging technique exploiting the non-linear magnetization response of magnetic nanoparticles to changing magnetic fields. If the data are generated by using a field-free line, the sampling geometry resembles the one in computerized tomography. Indeed, for an ideal field-free line rotating only in between measurements it was shown that the signal equation can be written as a convolution with the Radon transform of the particle concentration. In this work, we regard a continuously rotating field-free line and extend the forward operator accordingly. We obtain a similar result for the relation to the Radon data but with two additive terms resulting from the additional time-dependencies in the forward model. We jointly reconstruct particle concentration and corresponding Radon data by means of total variation regularization yielding promising results for synthetic data.
iBoot: Image-bootstrapped Self-Supervised Video Representation Learning
Jun 16, 2022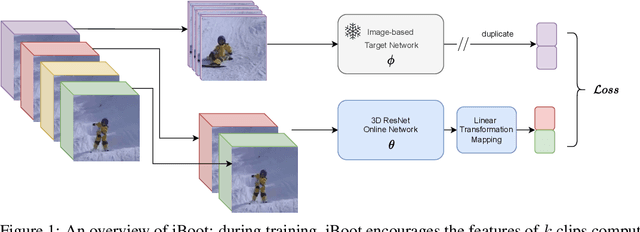



Learning visual representations through self-supervision is an extremely challenging task as the network needs to sieve relevant patterns from spurious distractors without the active guidance provided by supervision. This is achieved through heavy data augmentation, large-scale datasets and prohibitive amounts of compute. Video self-supervised learning (SSL) suffers from added challenges: video datasets are typically not as large as image datasets, compute is an order of magnitude larger, and the amount of spurious patterns the optimizer has to sieve through is multiplied several fold. Thus, directly learning self-supervised representations from video data might result in sub-optimal performance. To address this, we propose to utilize a strong image-based model, pre-trained with self- or language supervision, in a video representation learning framework, enabling the model to learn strong spatial and temporal information without relying on the video labeled data. To this end, we modify the typical video-based SSL design and objective to encourage the video encoder to \textit{subsume} the semantic content of an image-based model trained on a general domain. The proposed algorithm is shown to learn much more efficiently (i.e. in less epochs and with a smaller batch) and results in a new state-of-the-art performance on standard downstream tasks among single-modality SSL methods.
Towards Ground Truth for Single Image Deraining
Jun 22, 2022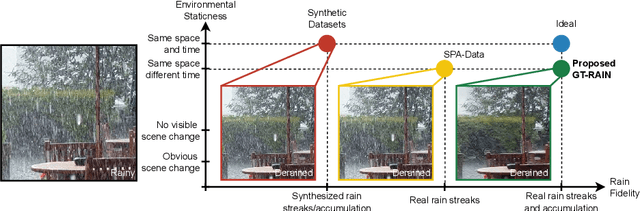
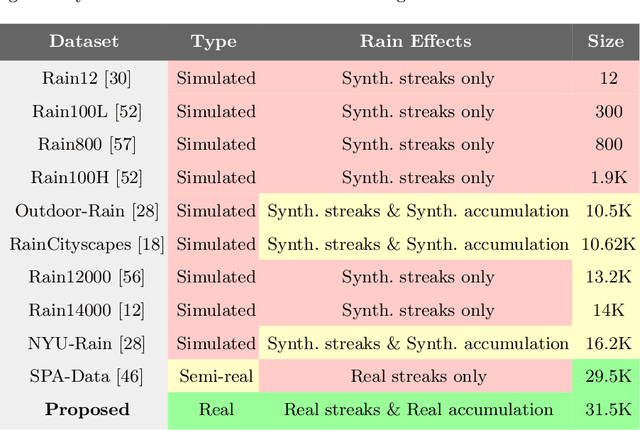
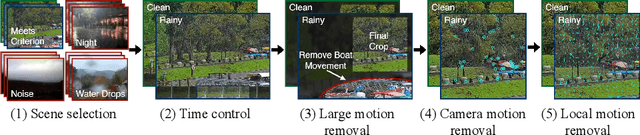

We propose a large-scale dataset of real-world rainy and clean image pairs and a method to remove degradations, induced by rain streaks and rain accumulation, from the image. As there exists no real-world dataset for deraining, current state-of-the-art methods rely on synthetic data and thus are limited by the sim2real domain gap; moreover, rigorous evaluation remains a challenge due to the absence of a real paired dataset. We fill this gap by collecting the first real paired deraining dataset through meticulous control of non-rain variations. Our dataset enables paired training and quantitative evaluation for diverse real-world rain phenomena (e.g. rain streaks and rain accumulation). To learn a representation invariant to rain phenomena, we propose a deep neural network that reconstructs the underlying scene by minimizing a rain-invariant loss between rainy and clean images. Extensive experiments demonstrate that the proposed dataset benefits existing derainers, and our model can outperform the state-of-the-art deraining methods on real rainy images under various conditions.
D2HNet: Joint Denoising and Deblurring with Hierarchical Network for Robust Night Image Restoration
Jul 14, 2022
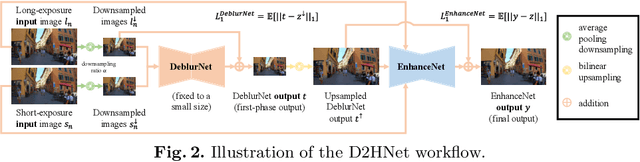
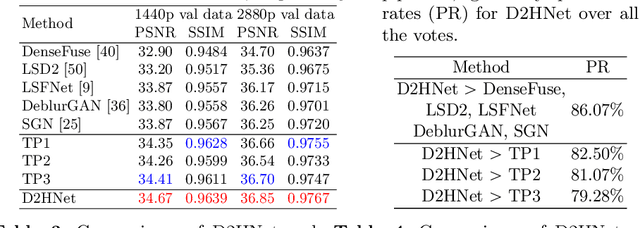
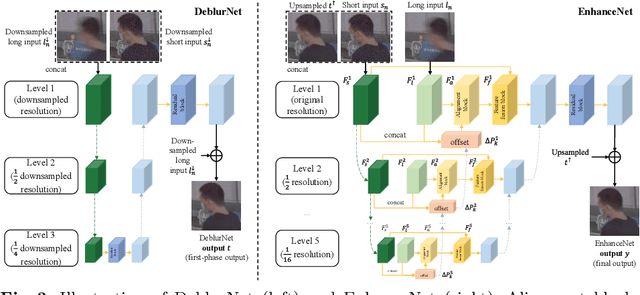
Night imaging with modern smartphone cameras is troublesome due to low photon count and unavoidable noise in the imaging system. Directly adjusting exposure time and ISO ratings cannot obtain sharp and noise-free images at the same time in low-light conditions. Though many methods have been proposed to enhance noisy or blurry night images, their performances on real-world night photos are still unsatisfactory due to two main reasons: 1) Limited information in a single image and 2) Domain gap between synthetic training images and real-world photos (e.g., differences in blur area and resolution). To exploit the information from successive long- and short-exposure images, we propose a learning-based pipeline to fuse them. A D2HNet framework is developed to recover a high-quality image by deblurring and enhancing a long-exposure image under the guidance of a short-exposure image. To shrink the domain gap, we leverage a two-phase DeblurNet-EnhanceNet architecture, which performs accurate blur removal on a fixed low resolution so that it is able to handle large ranges of blur in different resolution inputs. In addition, we synthesize a D2-Dataset from HD videos and experiment on it. The results on the validation set and real photos demonstrate our methods achieve better visual quality and state-of-the-art quantitative scores. The D2HNet codes and D2-Dataset can be found at https://github.com/zhaoyuzhi/D2HNet.
Relational Local Explanations
Dec 23, 2022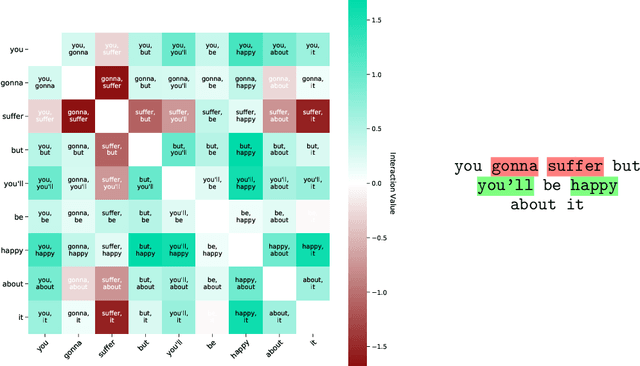

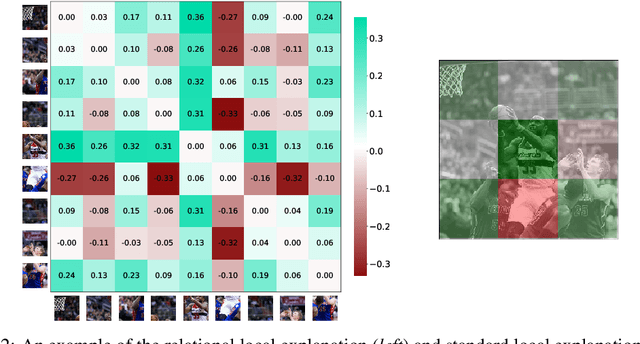
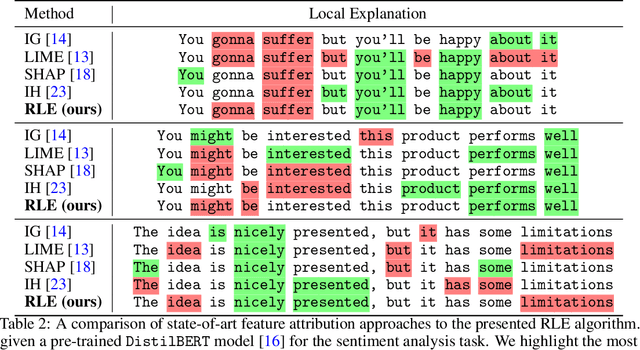
The majority of existing post-hoc explanation approaches for machine learning models produce independent per-variable feature attribution scores, ignoring a critical characteristic, such as the inter-variable relationship between features that naturally occurs in visual and textual data. In response, we develop a novel model-agnostic and permutation-based feature attribution algorithm based on the relational analysis between input variables. As a result, we are able to gain a broader insight into machine learning model decisions and data. This type of local explanation measures the effects of interrelationships between local features, which provides another critical aspect of explanations. Experimental evaluations of our framework using setups involving both image and text data modalities demonstrate its effectiveness and validity.
Contrastive Language-Vision AI Models Pretrained on Web-Scraped Multimodal Data Exhibit Sexual Objectification Bias
Dec 21, 2022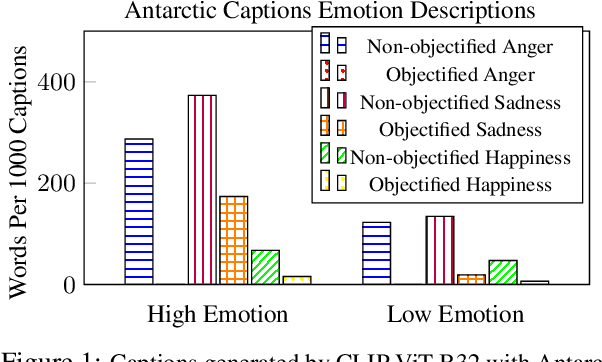
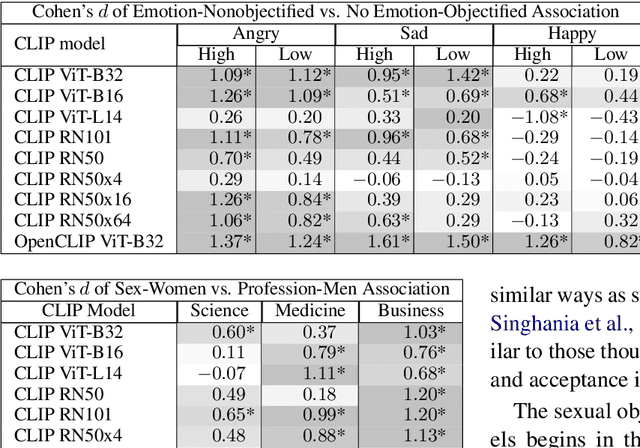
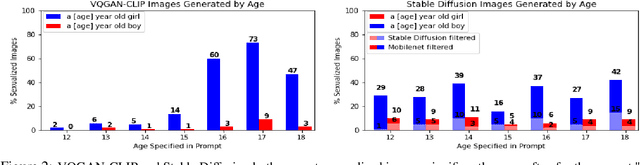
Nine language-vision AI models trained on web scrapes with the Contrastive Language-Image Pretraining (CLIP) objective are evaluated for evidence of a bias studied by psychologists: the sexual objectification of girls and women, which occurs when a person's human characteristics are disregarded and the person is treated as a body or a collection of body parts. A first experiment uses standardized images of women from the Sexual OBjectification and EMotion Database, and finds that, commensurate with prior research in psychology, human characteristics are disassociated from images of objectified women: the model's recognition of emotional state is mediated by whether the subject is fully or partially clothed. Embedding association tests (EATs) return significant effect sizes for both anger (d >.8) and sadness (d >.5). A second experiment measures the effect in a representative application: an automatic image captioner (Antarctic Captions) includes words denoting emotion less than 50% as often for images of partially clothed women than for images of fully clothed women. A third experiment finds that images of female professionals (scientists, doctors, executives) are likely to be associated with sexual descriptions relative to images of male professionals. A fourth experiment shows that a prompt of "a [age] year old girl" generates sexualized images (as determined by an NSFW classifier) up to 73% of the time for VQGAN-CLIP (age 17), and up to 40% of the time for Stable Diffusion (ages 14 and 18); the corresponding rate for boys never surpasses 9%. The evidence indicates that language-vision AI models trained on automatically collected web scrapes learn biases of sexual objectification, which propagate to downstream applications.
Structured Vision-Language Pretraining for Computational Cooking
Dec 08, 2022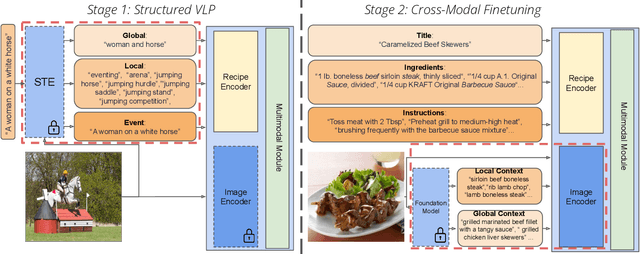
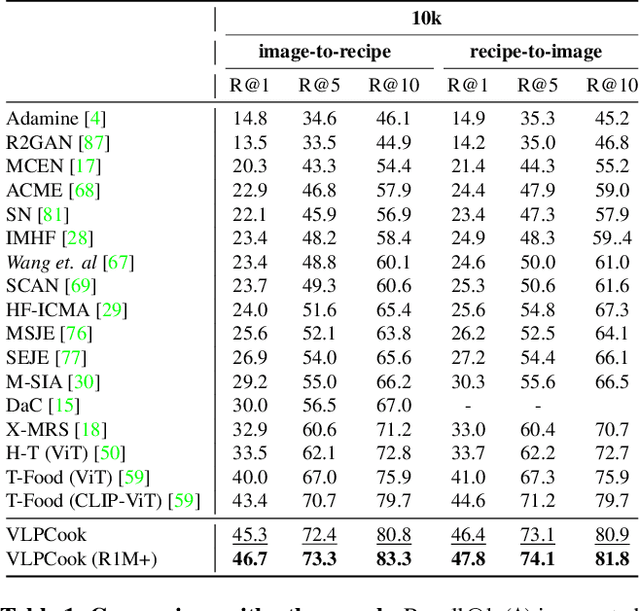
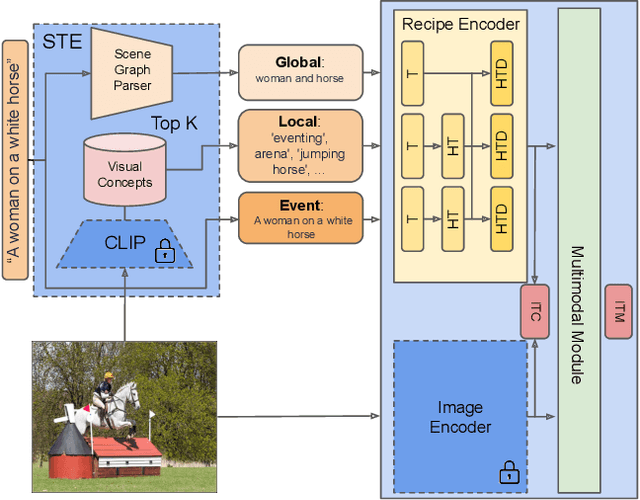
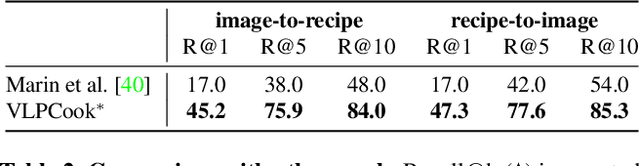
Vision-Language Pretraining (VLP) and Foundation models have been the go-to recipe for achieving SoTA performance on general benchmarks. However, leveraging these powerful techniques for more complex vision-language tasks, such as cooking applications, with more structured input data, is still little investigated. In this work, we propose to leverage these techniques for structured-text based computational cuisine tasks. Our strategy, dubbed VLPCook (Structured Vision-Language Pretraining for Computational Cooking), first transforms existing image-text pairs to image and structured-text pairs. This allows to pretrain our VLPCook model using VLP objectives adapted to the strutured data of the resulting datasets, then finetuning it on downstream computational cooking tasks. During finetuning, we also enrich the visual encoder, leveraging pretrained foundation models (e.g. CLIP) to provide local and global textual context. VLPCook outperforms current SoTA by a significant margin (+3.3 Recall@1 absolute improvement) on the task of Cross-Modal Food Retrieval on the large Recipe1M dataset. Finally, we conduct further experiments on VLP to validate their importance, especially on the Recipe1M+ dataset. The code will be made publicly available.
The Differentiable Lens: Compound Lens Search over Glass Surfaces and Materials for Object Detection
Dec 08, 2022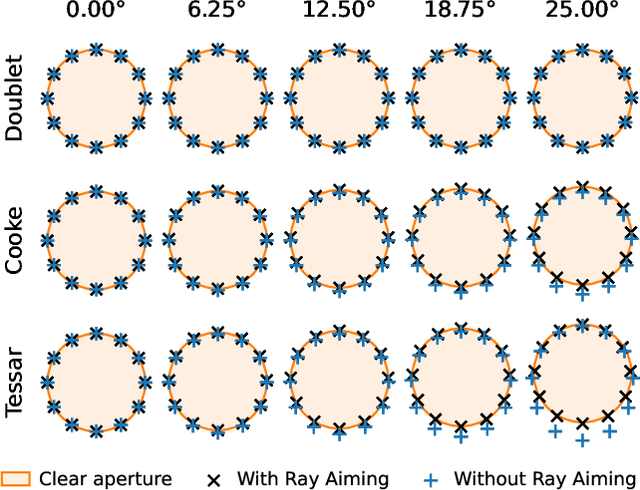
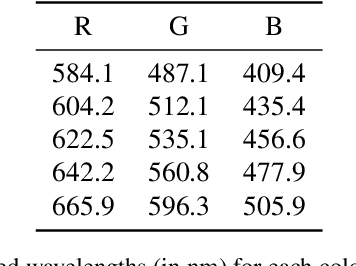

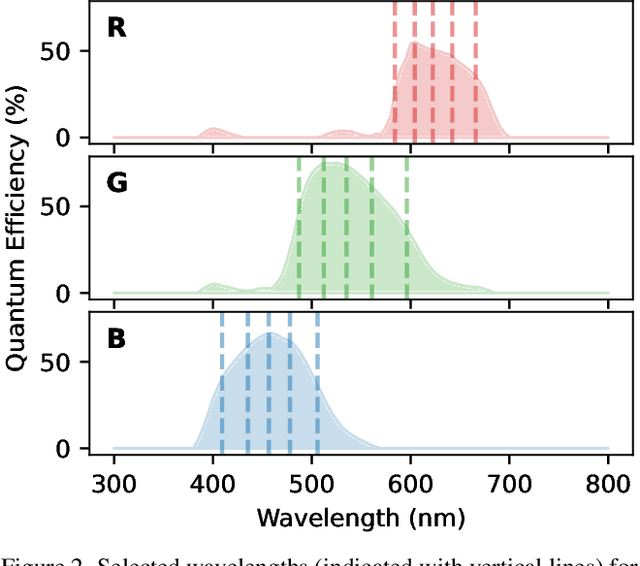
Most camera lens systems are designed in isolation, separately from downstream computer vision methods. Recently, joint optimization approaches that design lenses alongside other components of the image acquisition and processing pipeline -- notably, downstream neural networks -- have achieved improved imaging quality or better performance on vision tasks. However, these existing methods optimize only a subset of lens parameters and cannot optimize glass materials given their categorical nature. In this work, we develop a differentiable spherical lens simulation model that accurately captures geometrical aberrations. We propose an optimization strategy to address the challenges of lens design -- notorious for non-convex loss function landscapes and many manufacturing constraints -- that are exacerbated in joint optimization tasks. Specifically, we introduce quantized continuous glass variables to facilitate the optimization and selection of glass materials in an end-to-end design context, and couple this with carefully designed constraints to support manufacturability. In automotive object detection, we show improved detection performance over existing designs even when simplifying designs to two- or three-element lenses, despite significantly degrading the image quality. Code and optical designs will be made publicly available.
Data-aware customization of activation functions reduces neural network error
Jan 16, 2023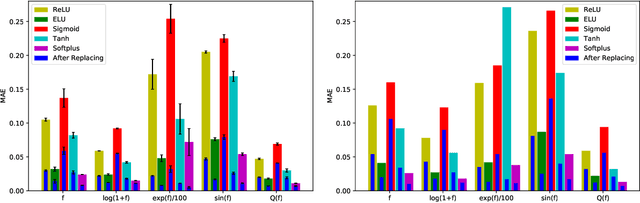
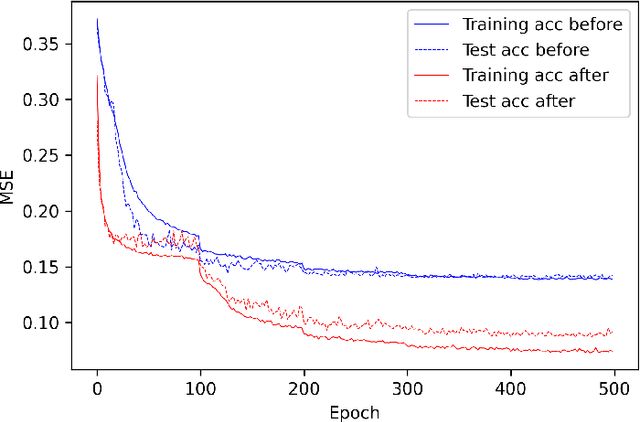
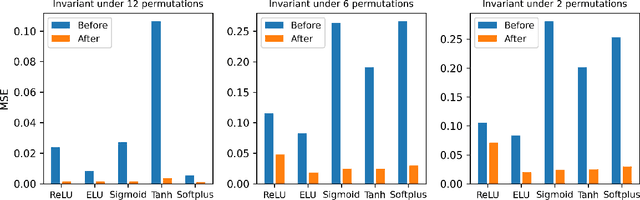
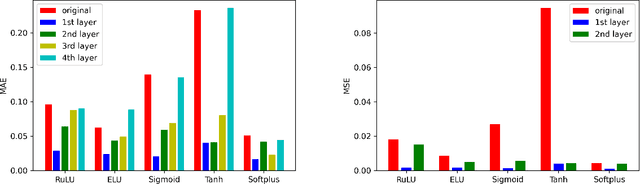
Activation functions play critical roles in neural networks, yet current off-the-shelf neural networks pay little attention to the specific choice of activation functions used. Here we show that data-aware customization of activation functions can result in striking reductions in neural network error. We first give a simple linear algebraic explanation of the role of activation functions in neural networks; then, through connection with the Diaconis-Shahshahani Approximation Theorem, we propose a set of criteria for good activation functions. As a case study, we consider regression tasks with a partially exchangeable target function, \emph{i.e.} $f(u,v,w)=f(v,u,w)$ for $u,v\in \mathbb{R}^d$ and $w\in \mathbb{R}^k$, and prove that for such a target function, using an even activation function in at least one of the layers guarantees that the prediction preserves partial exchangeability for best performance. Since even activation functions are seldom used in practice, we designed the ``seagull'' even activation function $\log(1+x^2)$ according to our criteria. Empirical testing on over two dozen 9-25 dimensional examples with different local smoothness, curvature, and degree of exchangeability revealed that a simple substitution with the ``seagull'' activation function in an already-refined neural network can lead to an order-of-magnitude reduction in error. This improvement was most pronounced when the activation function substitution was applied to the layer in which the exchangeable variables are connected for the first time. While the improvement is greatest for low-dimensional data, experiments on the CIFAR10 image classification dataset showed that use of ``seagull'' can reduce error even for high-dimensional cases. These results collectively highlight the potential of customizing activation functions as a general approach to improve neural network performance.
AADG: Automatic Augmentation for Domain Generalization on Retinal Image Segmentation
Jul 27, 2022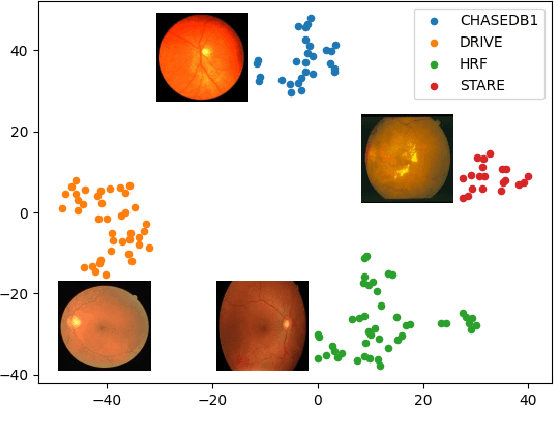
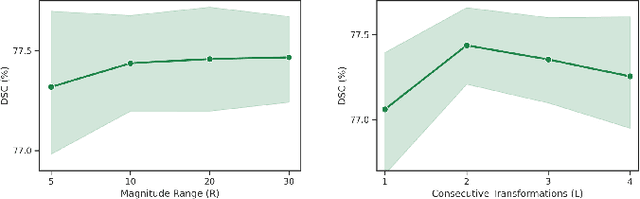
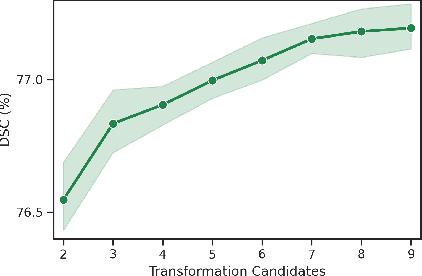
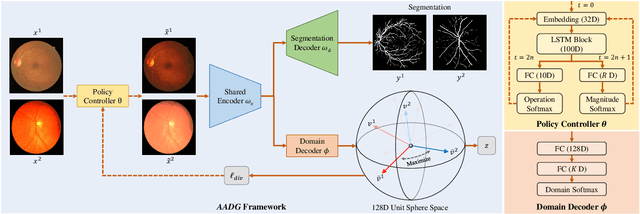
Convolutional neural networks have been widely applied to medical image segmentation and have achieved considerable performance. However, the performance may be significantly affected by the domain gap between training data (source domain) and testing data (target domain). To address this issue, we propose a data manipulation based domain generalization method, called Automated Augmentation for Domain Generalization (AADG). Our AADG framework can effectively sample data augmentation policies that generate novel domains and diversify the training set from an appropriate search space. Specifically, we introduce a novel proxy task maximizing the diversity among multiple augmented novel domains as measured by the Sinkhorn distance in a unit sphere space, making automated augmentation tractable. Adversarial training and deep reinforcement learning are employed to efficiently search the objectives. Quantitative and qualitative experiments on 11 publicly-accessible fundus image datasets (four for retinal vessel segmentation, four for optic disc and cup (OD/OC) segmentation and three for retinal lesion segmentation) are comprehensively performed. Two OCTA datasets for retinal vasculature segmentation are further involved to validate cross-modality generalization. Our proposed AADG exhibits state-of-the-art generalization performance and outperforms existing approaches by considerable margins on retinal vessel, OD/OC and lesion segmentation tasks. The learned policies are empirically validated to be model-agnostic and can transfer well to other models. The source code is available at https://github.com/CRazorback/AADG.