 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DiffDreamer: Consistent Single-view Perpetual View Generation with Conditional Diffusion Models
Nov 22, 2022

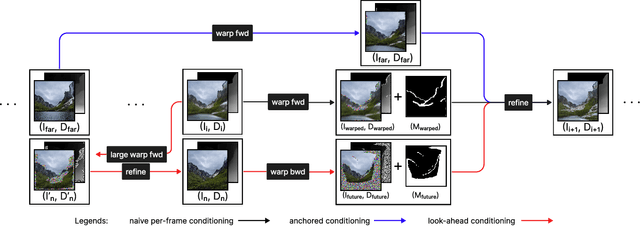
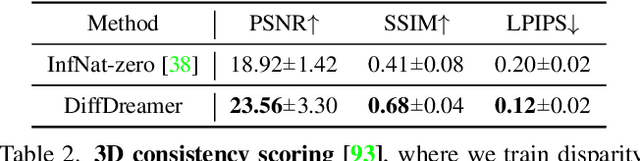

Perpetual view generation -- the task of generating long-range novel views by flying into a given image -- has been a novel yet promising task. We introduce DiffDreamer, an unsupervised framework capable of synthesizing novel views depicting a long camera trajectory while training solely on internet-collected images of nature scenes. We demonstrate that image-conditioned diffusion models can effectively perform long-range scene extrapolation while preserving both local and global consistency significantly better than prior GAN-based methods. Project page: https://primecai.github.io/diffdreamer .
DiffPose: Multi-hypothesis Human Pose Estimation using Diffusion models
Nov 29, 2022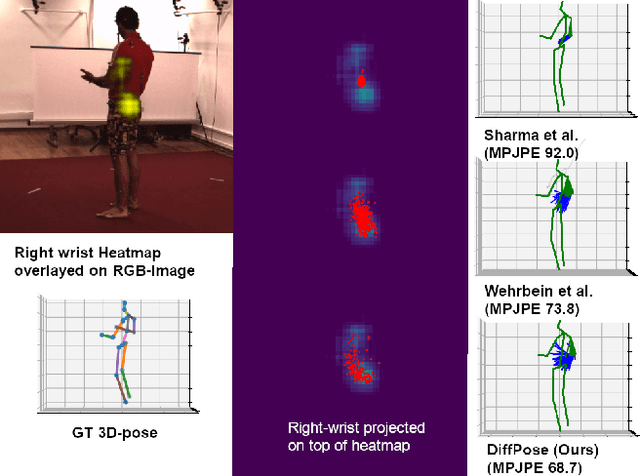
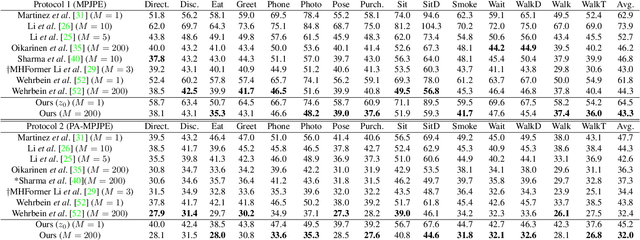
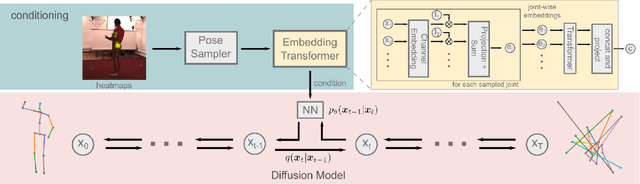

Traditionally, monocular 3D human pose estimation employs a machine learning model to predict the most likely 3D pose for a given input image. However, a single image can be highly ambiguous and induces multiple plausible solutions for the 2D-3D lifting step which results in overly confident 3D pose predictors. To this end, we propose \emph{DiffPose}, a conditional diffusion model, that predicts multiple hypotheses for a given input image. In comparison to similar approaches, our diffusion model is straightforward and avoids intensive hyperparameter tuning, complex network structures, mode collapse, and unstable training. Moreover, we tackle a problem of the common two-step approach that first estimates a distribution of 2D joint locations via joint-wise heatmaps and consecutively approximates them based on first- or second-moment statistics. Since such a simplification of the heatmaps removes valid information about possibly correct, though labeled unlikely, joint locations, we propose to represent the heatmaps as a set of 2D joint candidate samples. To extract information about the original distribution from these samples we introduce our \emph{embedding transformer} that conditions the diffusion model. Experimentally, we show that DiffPose slightly improves upon the state of the art for multi-hypothesis pose estimation for simple poses and outperforms it by a large margin for highly ambiguous poses.
Semantic Encoder Guided Generative Adversarial Face Ultra-Resolution Network
Nov 18, 2022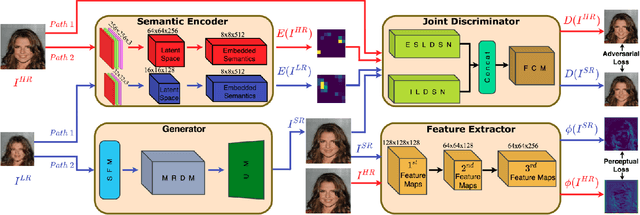
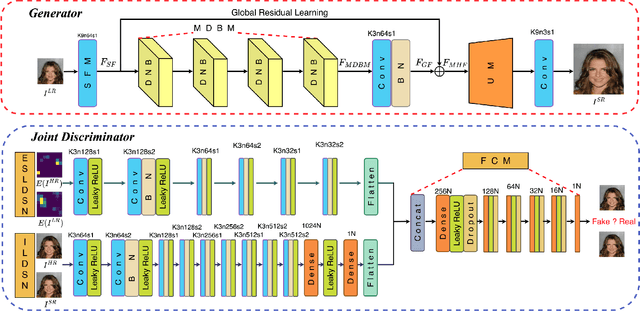
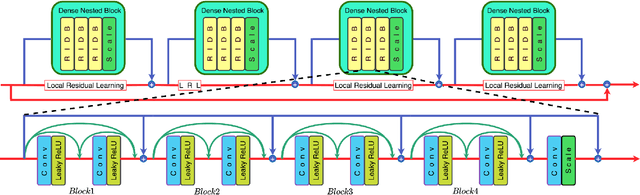

Face super-resolution is a domain-specific image super-resolution, which aims to generate High-Resolution (HR) face images from their Low-Resolution (LR) counterparts. In this paper, we propose a novel face super-resolution method, namely Semantic Encoder guided Generative Adversarial Face Ultra-Resolution Network (SEGA-FURN) to ultra-resolve an unaligned tiny LR face image to its HR counterpart with multiple ultra-upscaling factors (e.g., 4x and 8x). The proposed network is composed of a novel semantic encoder that has the ability to capture the embedded semantics to guide adversarial learning and a novel generator that uses a hierarchical architecture named Residual in Internal Dense Block (RIDB). Moreover, we propose a joint discriminator which discriminates both image data and embedded semantics. The joint discriminator learns the joint probability distribution of the image space and latent space. We also use a Relativistic average Least Squares loss (RaLS) as the adversarial loss to alleviate the gradient vanishing problem and enhance the stability of the training procedure. Extensive experiments on large face datasets have proved that the proposed method can achieve superior super-resolution results and significantly outperform other state-of-the-art methods in both qualitative and quantitative comparisons.
Relational Local Explanations
Dec 23, 2022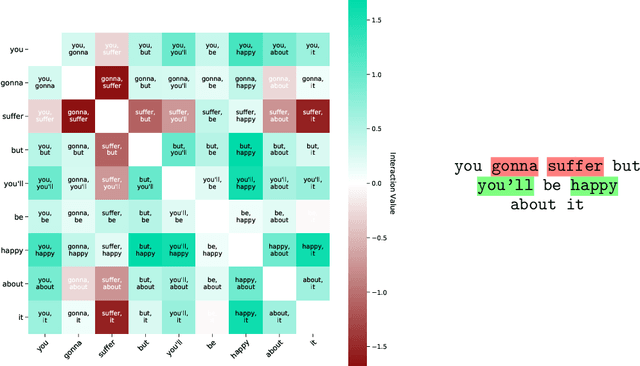

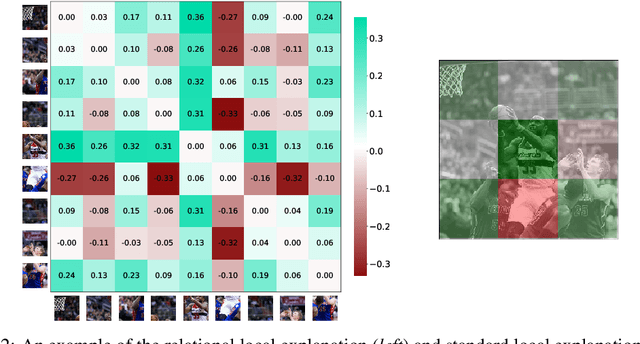
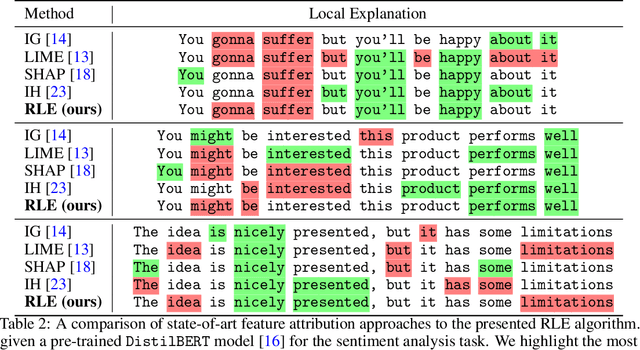
The majority of existing post-hoc explanation approaches for machine learning models produce independent per-variable feature attribution scores, ignoring a critical characteristic, such as the inter-variable relationship between features that naturally occurs in visual and textual data. In response, we develop a novel model-agnostic and permutation-based feature attribution algorithm based on the relational analysis between input variables. As a result, we are able to gain a broader insight into machine learning model decisions and data. This type of local explanation measures the effects of interrelationships between local features, which provides another critical aspect of explanations. Experimental evaluations of our framework using setups involving both image and text data modalities demonstrate its effectiveness and validity.
Contrastive Language-Vision AI Models Pretrained on Web-Scraped Multimodal Data Exhibit Sexual Objectification Bias
Dec 21, 2022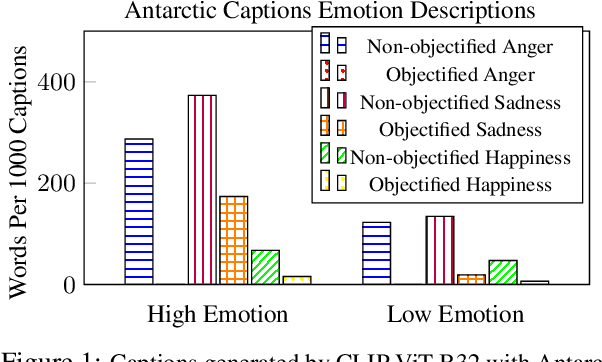
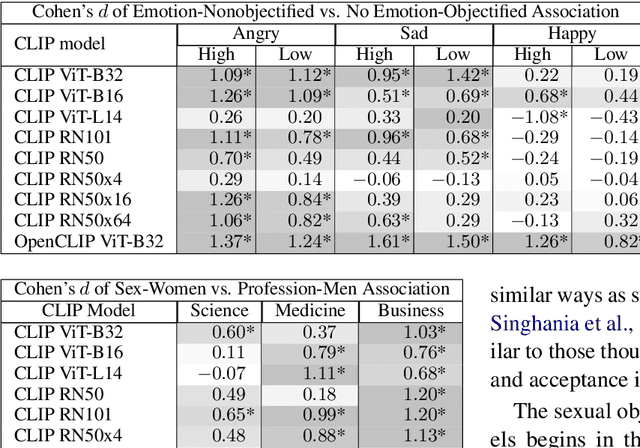
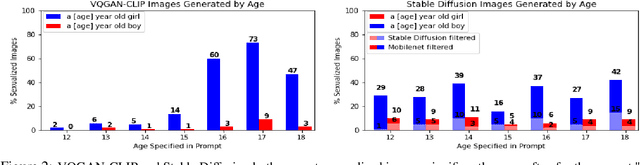
Nine language-vision AI models trained on web scrapes with the Contrastive Language-Image Pretraining (CLIP) objective are evaluated for evidence of a bias studied by psychologists: the sexual objectification of girls and women, which occurs when a person's human characteristics are disregarded and the person is treated as a body or a collection of body parts. A first experiment uses standardized images of women from the Sexual OBjectification and EMotion Database, and finds that, commensurate with prior research in psychology, human characteristics are disassociated from images of objectified women: the model's recognition of emotional state is mediated by whether the subject is fully or partially clothed. Embedding association tests (EATs) return significant effect sizes for both anger (d >.8) and sadness (d >.5). A second experiment measures the effect in a representative application: an automatic image captioner (Antarctic Captions) includes words denoting emotion less than 50% as often for images of partially clothed women than for images of fully clothed women. A third experiment finds that images of female professionals (scientists, doctors, executives) are likely to be associated with sexual descriptions relative to images of male professionals. A fourth experiment shows that a prompt of "a [age] year old girl" generates sexualized images (as determined by an NSFW classifier) up to 73% of the time for VQGAN-CLIP (age 17), and up to 40% of the time for Stable Diffusion (ages 14 and 18); the corresponding rate for boys never surpasses 9%. The evidence indicates that language-vision AI models trained on automatically collected web scrapes learn biases of sexual objectification, which propagate to downstream applications.
GPViT: A High Resolution Non-Hierarchical Vision Transformer with Group Propagation
Dec 13, 2022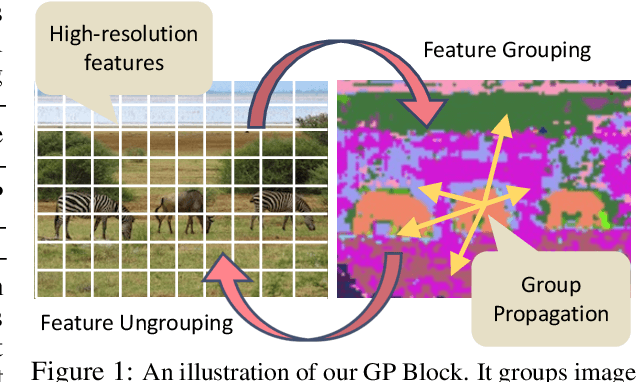
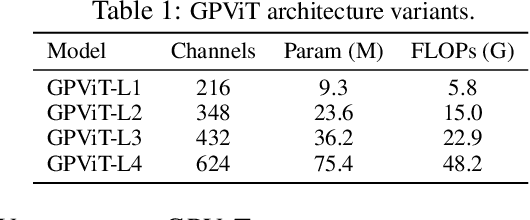
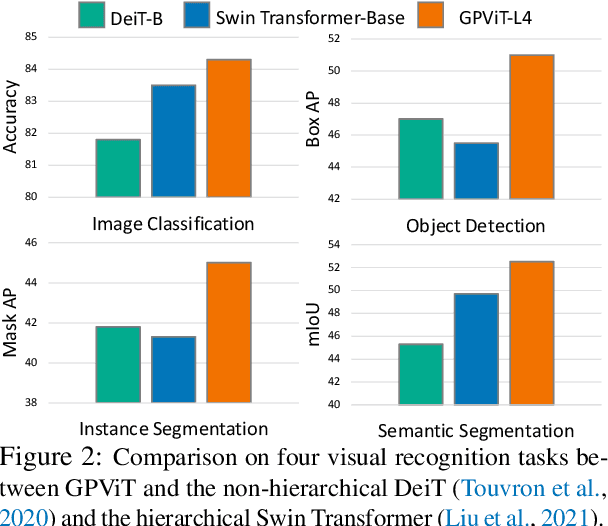
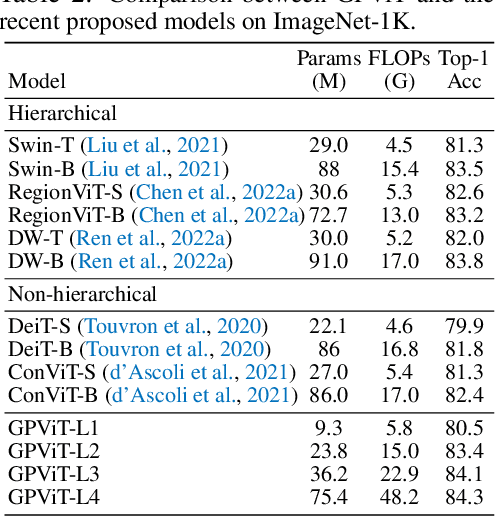
We present the Group Propagation Vision Transformer (GPViT): a novel nonhierarchical (i.e. non-pyramidal) transformer model designed for general visual recognition with high-resolution features. High-resolution features (or tokens) are a natural fit for tasks that involve perceiving fine-grained details such as detection and segmentation, but exchanging global information between these features is expensive in memory and computation because of the way self-attention scales. We provide a highly efficient alternative Group Propagation Block (GP Block) to exchange global information. In each GP Block, features are first grouped together by a fixed number of learnable group tokens; we then perform Group Propagation where global information is exchanged between the grouped features; finally, global information in the updated grouped features is returned back to the image features through a transformer decoder. We evaluate GPViT on a variety of visual recognition tasks including image classification, semantic segmentation, object detection, and instance segmentation. Our method achieves significant performance gains over previous works across all tasks, especially on tasks that require high-resolution outputs, for example, our GPViT-L3 outperforms Swin Transformer-B by 2.0 mIoU on ADE20K semantic segmentation with only half as many parameters. Code and pre-trained models are available at https://github.com/ChenhongyiYang/GPViT .
Structured 3D Features for Reconstructing Relightable and Animatable Avatars
Dec 13, 2022
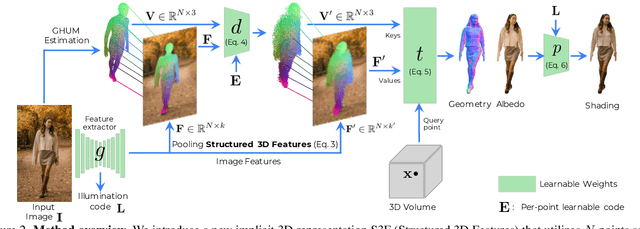
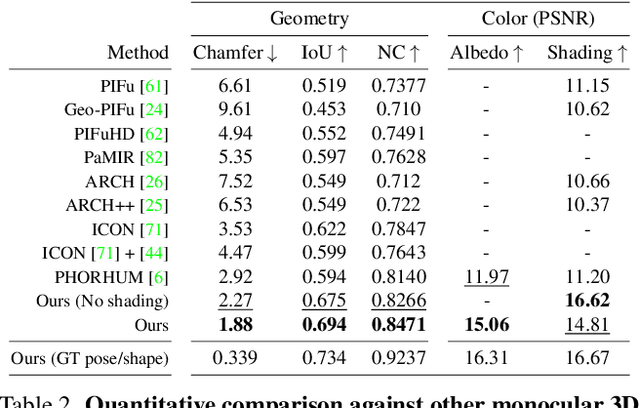
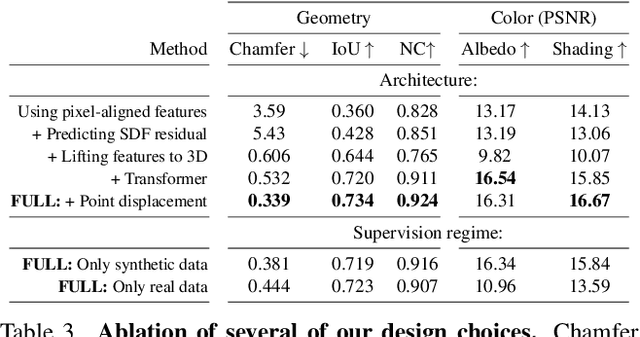
We introduce Structured 3D Features, a model based on a novel implicit 3D representation that pools pixel-aligned image features onto dense 3D points sampled from a parametric, statistical human mesh surface. The 3D points have associated semantics and can move freely in 3D space. This allows for optimal coverage of the person of interest, beyond just the body shape, which in turn, additionally helps modeling accessories, hair, and loose clothing. Owing to this, we present a complete 3D transformer-based attention framework which, given a single image of a person in an unconstrained pose, generates an animatable 3D reconstruction with albedo and illumination decomposition, as a result of a single end-to-end model, trained semi-supervised, and with no additional postprocessing. We show that our S3F model surpasses the previous state-of-the-art on various tasks, including monocular 3D reconstruction, as well as albedo and shading estimation. Moreover, we show that the proposed methodology allows novel view synthesis, relighting, and re-posing the reconstruction, and can naturally be extended to handle multiple input images (e.g. different views of a person, or the same view, in different poses, in video). Finally, we demonstrate the editing capabilities of our model for 3D virtual try-on applications.
Radon-based Image Reconstruction for MPI using a continuously rotating FFL
Nov 21, 2022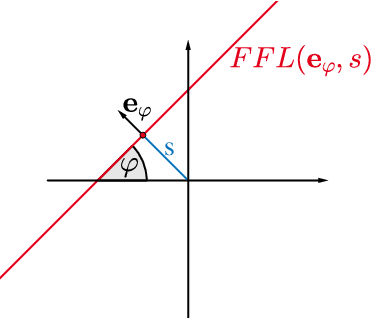
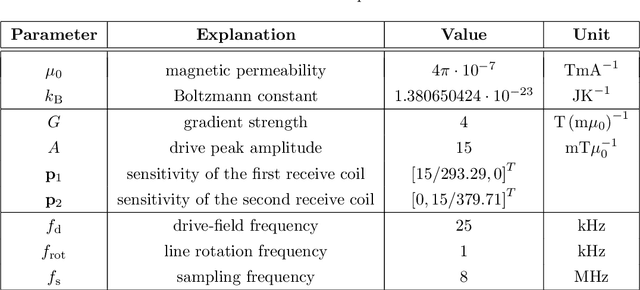
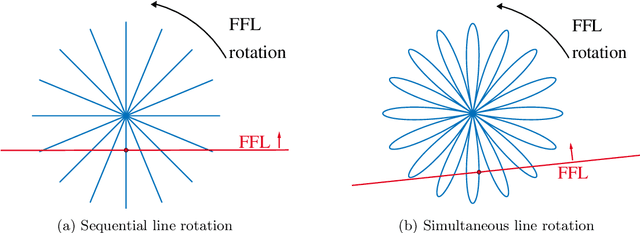

Magnetic particle imaging is a relatively new tracer-based medical imaging technique exploiting the non-linear magnetization response of magnetic nanoparticles to changing magnetic fields. If the data are generated by using a field-free line, the sampling geometry resembles the one in computerized tomography. Indeed, for an ideal field-free line rotating only in between measurements it was shown that the signal equation can be written as a convolution with the Radon transform of the particle concentration. In this work, we regard a continuously rotating field-free line and extend the forward operator accordingly. We obtain a similar result for the relation to the Radon data but with two additive terms resulting from the additional time-dependencies in the forward model. We jointly reconstruct particle concentration and corresponding Radon data by means of total variation regularization yielding promising results for synthetic data.
3D UX-Net: A Large Kernel Volumetric ConvNet Modernizing Hierarchical Transformer for Medical Image Segmentation
Oct 03, 2022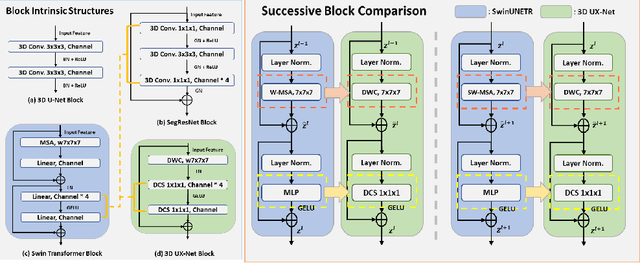
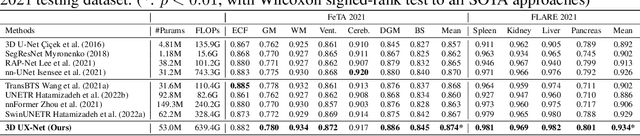
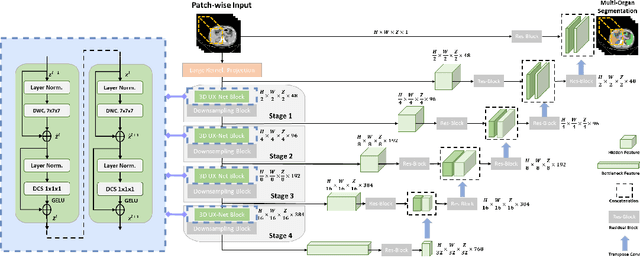
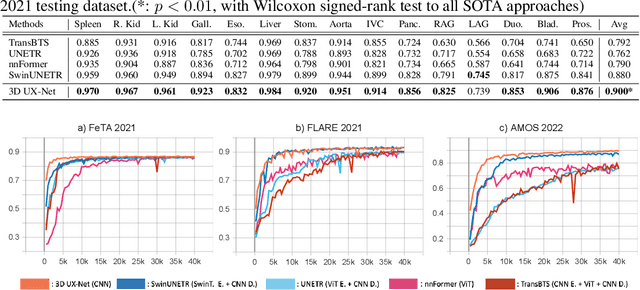
Vision transformers (ViTs) have quickly superseded convolutional networks (ConvNets) as the current state-of-the-art (SOTA) models for medical image segmentation. Hierarchical transformers (e.g., Swin Transformers) reintroduced several ConvNet priors and further enhanced the practical viability of adapting volumetric segmentation in 3D medical datasets. The effectiveness of hybrid approaches is largely credited to the large receptive field for non-local self-attention and the large number of model parameters. In this work, we propose a lightweight volumetric ConvNet, termed 3D UX-Net, which adapts the hierarchical transformer using ConvNet modules for robust volumetric segmentation. Specifically, we revisit volumetric depth-wise convolutions with large kernel size (e.g. starting from $7\times7\times7$) to enable the larger global receptive fields, inspired by Swin Transformer. We further substitute the multi-layer perceptron (MLP) in Swin Transformer blocks with pointwise depth convolutions and enhance model performances with fewer normalization and activation layers, thus reducing the number of model parameters. 3D UX-Net competes favorably with current SOTA transformers (e.g. SwinUNETR) using three challenging public datasets on volumetric brain and abdominal imaging: 1) MICCAI Challenge 2021 FLARE, 2) MICCAI Challenge 2021 FeTA, and 3) MICCAI Challenge 2022 AMOS. 3D UX-Net consistently outperforms SwinUNETR with improvement from 0.929 to 0.938 Dice (FLARE2021) and 0.867 to 0.874 Dice (Feta2021). We further evaluate the transfer learning capability of 3D UX-Net with AMOS2022 and demonstrates another improvement of $2.27\%$ Dice (from 0.880 to 0.900). The source code with our proposed model are available at https://github.com/MASILab/3DUX-Net.
On Learning the Structure of Clusters in Graphs
Dec 29, 2022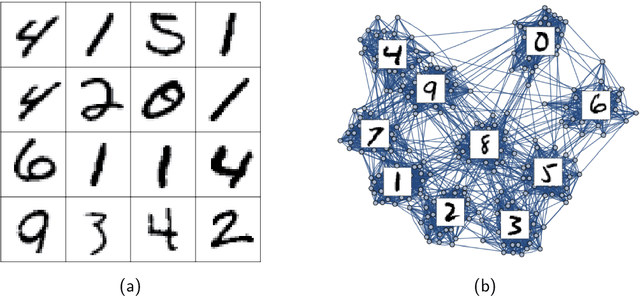

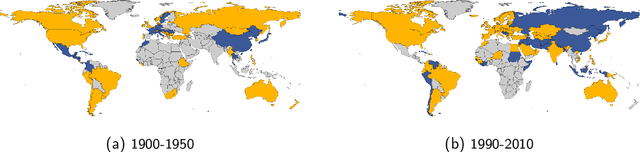
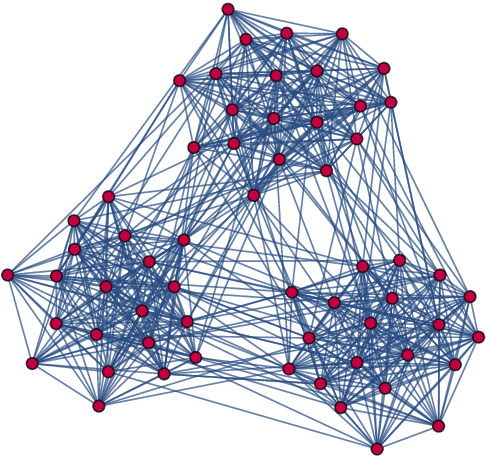
Graph clustering is a fundamental problem in unsupervised learning, with numerous applications in computer science and in analysing real-world data. In many real-world applications, we find that the clusters have a significant high-level structure. This is often overlooked in the design and analysis of graph clustering algorithms which make strong simplifying assumptions about the structure of the graph. This thesis addresses the natural question of whether the structure of clusters can be learned efficiently and describes four new algorithmic results for learning such structure in graphs and hypergraphs. All of the presented theoretical results are extensively evaluated on both synthetic and real-word datasets of different domains, including image classification and segmentation, migration networks, co-authorship networks, and natural language processing. These experimental results demonstrate that the newly developed algorithms are practical, effective, and immediately applicable for learning the structure of clusters in real-world data.