 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SwinDepth: Unsupervised Depth Estimation using Monocular Sequences via Swin Transformer and Densely Cascaded Network
Jan 17, 2023

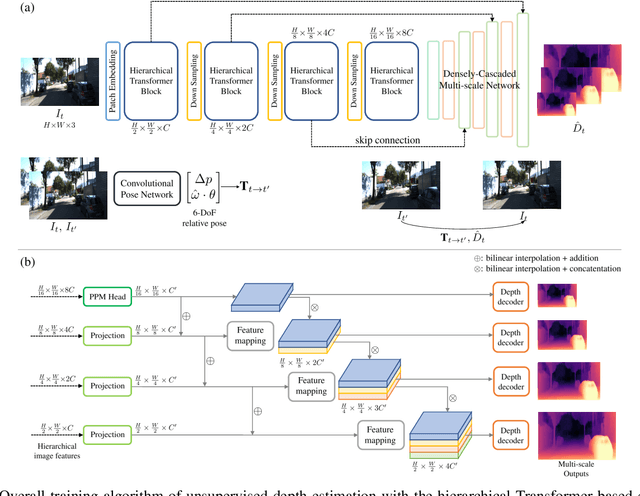
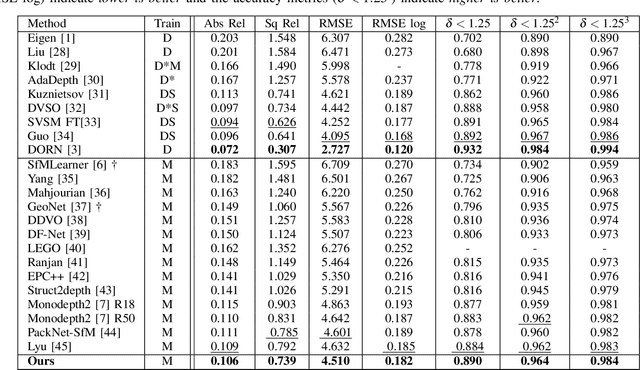
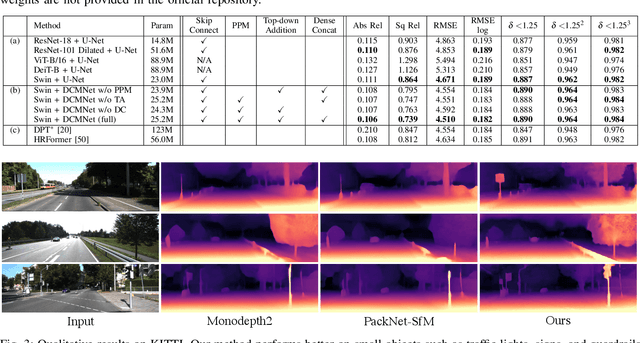
Monocular depth estimation plays a critical role in various computer vision and robotics applications such as localization, mapping, and 3D object detection. Recently, learning-based algorithms achieve huge success in depth estimation by training models with a large amount of data in a supervised manner. However, it is challenging to acquire dense ground truth depth labels for supervised training, and the unsupervised depth estimation using monocular sequences emerges as a promising alternative. Unfortunately, most studies on unsupervised depth estimation explore loss functions or occlusion masks, and there is little change in model architecture in that ConvNet-based encoder-decoder structure becomes a de-facto standard for depth estimation. In this paper, we employ a convolution-free Swin Transformer as an image feature extractor so that the network can capture both local geometric features and global semantic features for depth estimation. Also, we propose a Densely Cascaded Multi-scale Network (DCMNet) that connects every feature map directly with another from different scales via a top-down cascade pathway. This densely cascaded connectivity reinforces the interconnection between decoding layers and produces high-quality multi-scale depth outputs. The experiments on two different datasets, KITTI and Make3D, demonstrate that our proposed method outperforms existing state-of-the-art unsupervised algorithms.
Embodied Agents for Efficient Exploration and Smart Scene Description
Jan 17, 2023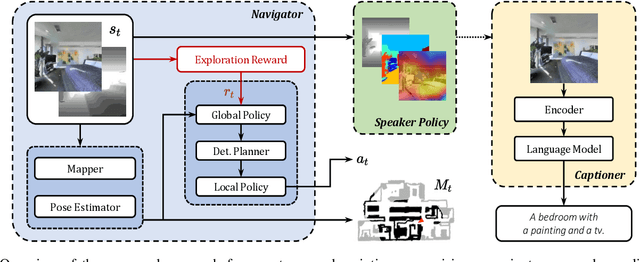



The development of embodied agents that can communicate with humans in natural language has gained increasing interest over the last years, as it facilitates the diffusion of robotic platforms in human-populated environments. As a step towards this objective, in this work, we tackle a setting for visual navigation in which an autonomous agent needs to explore and map an unseen indoor environment while portraying interesting scenes with natural language descriptions. To this end, we propose and evaluate an approach that combines recent advances in visual robotic exploration and image captioning on images generated through agent-environment interaction. Our approach can generate smart scene descriptions that maximize semantic knowledge of the environment and avoid repetitions. Further, such descriptions offer user-understandable insights into the robot's representation of the environment by highlighting the prominent objects and the correlation between them as encountered during the exploration. To quantitatively assess the performance of the proposed approach, we also devise a specific score that takes into account both exploration and description skills. The experiments carried out on both photorealistic simulated environments and real-world ones demonstrate that our approach can effectively describe the robot's point of view during exploration, improving the human-friendly interpretability of its observations.
Multimodal Video Adapter for Parameter Efficient Video Text Retrieval
Jan 19, 2023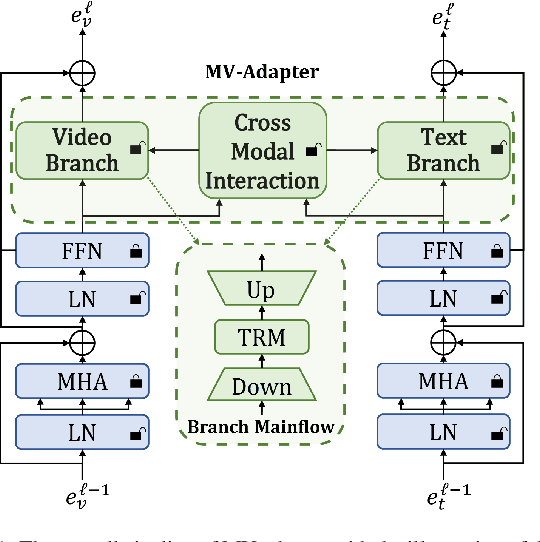
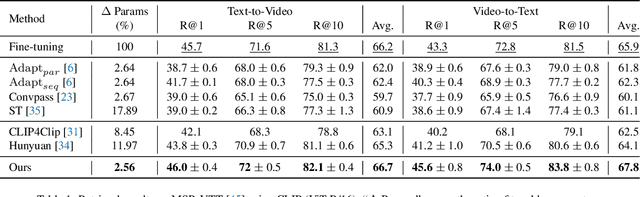
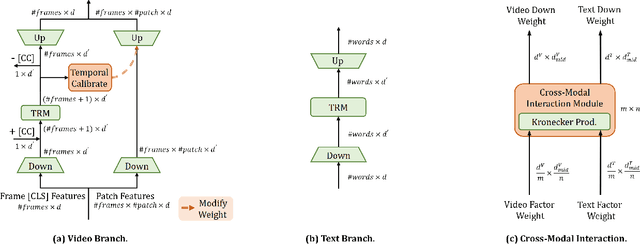
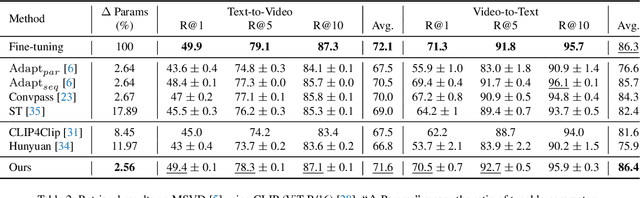
State-of-the-art video-text retrieval (VTR) methods usually fully fine-tune the pre-trained model (e.g. CLIP) on specific datasets, which may suffer from substantial storage costs in practical applications since a separate model per task needs to be stored. To overcome this issue, we present the premier work on performing parameter-efficient VTR from the pre-trained model, i.e., only a small number of parameters are tunable while freezing the backbone. Towards this goal, we propose a new method dubbed Multimodal Video Adapter (MV-Adapter) for efficiently transferring the knowledge in the pre-trained CLIP from image-text to video-text. Specifically, MV-Adapter adopts bottleneck structures in both video and text branches and introduces two novel components. The first is a Temporal Adaptation Module employed in the video branch to inject global and local temporal contexts. We also learn weights calibrations to adapt to the dynamic variations across frames. The second is a Cross-Modal Interaction Module that generates weights for video/text branches through a shared parameter space, for better aligning between modalities. Thanks to above innovations, MV-Adapter can achieve on-par or better performance than standard fine-tuning with negligible parameters overhead. Notably, on five widely used VTR benchmarks (MSR-VTT, MSVD, LSMDC, DiDemo, and ActivityNet), MV-Adapter consistently outperforms various competing methods in V2T/T2V tasks with large margins. Codes will be released.
Sampling Based On Natural Image Statistics Improves Local Surrogate Explainers
Aug 08, 2022


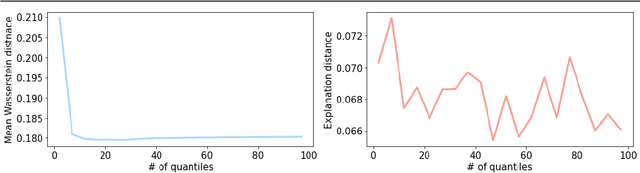
Many problems in computer vision have recently been tackled using models whose predictions cannot be easily interpreted, most commonly deep neural networks. Surrogate explainers are a popular post-hoc interpretability method to further understand how a model arrives at a particular prediction. By training a simple, more interpretable model to locally approximate the decision boundary of a non-interpretable system, we can estimate the relative importance of the input features on the prediction. Focusing on images, surrogate explainers, e.g., LIME, generate a local neighbourhood around a query image by sampling in an interpretable domain. However, these interpretable domains have traditionally been derived exclusively from the intrinsic features of the query image, not taking into consideration the manifold of the data the non-interpretable model has been exposed to in training (or more generally, the manifold of real images). This leads to suboptimal surrogates trained on potentially low probability images. We address this limitation by aligning the local neighbourhood on which the surrogate is trained with the original training data distribution, even when this distribution is not accessible. We propose two approaches to do so, namely (1) altering the method for sampling the local neighbourhood and (2) using perceptual metrics to convey some of the properties of the distribution of natural images.
FaIRCoP: Facial Image Retrieval using Contrastive Personalization
May 28, 2022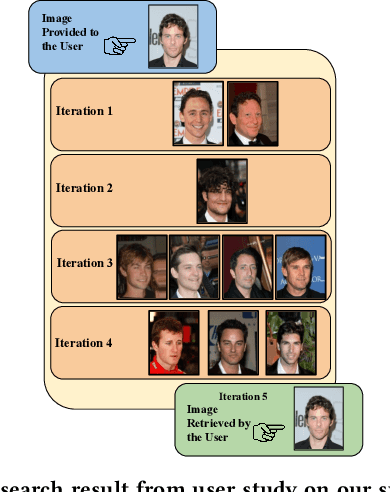
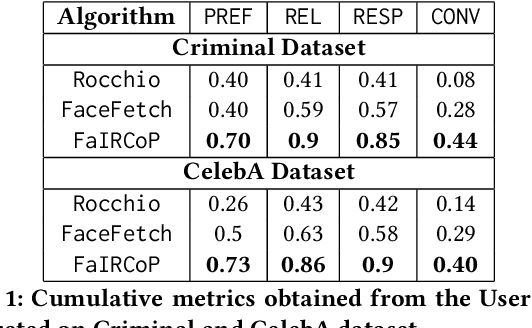

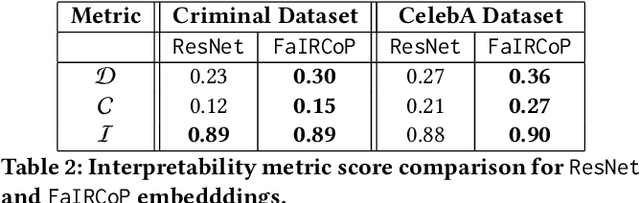
Retrieving facial images from attributes plays a vital role in various systems such as face recognition and suspect identification. Compared to other image retrieval tasks, facial image retrieval is more challenging due to the high subjectivity involved in describing a person's facial features. Existing methods do so by comparing specific characteristics from the user's mental image against the suggested images via high-level supervision such as using natural language. In contrast, we propose a method that uses a relatively simpler form of binary supervision by utilizing the user's feedback to label images as either similar or dissimilar to the target image. Such supervision enables us to exploit the contrastive learning paradigm for encapsulating each user's personalized notion of similarity. For this, we propose a novel loss function optimized online via user feedback. We validate the efficacy of our proposed approach using a carefully designed testbed to simulate user feedback and a large-scale user study. Our experiments demonstrate that our method iteratively improves personalization, leading to faster convergence and enhanced recommendation relevance, thereby, improving user satisfaction. Our proposed framework is also equipped with a user-friendly web interface with a real-time experience for facial image retrieval.
Attention-based Dynamic Subspace Learners for Medical Image Analysis
Jun 18, 2022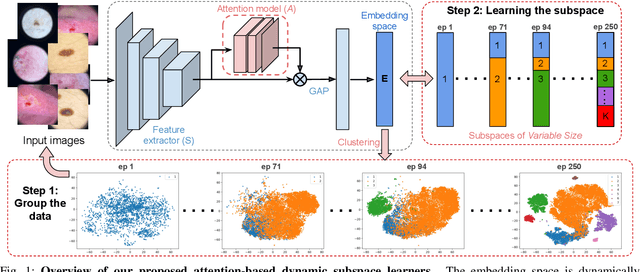
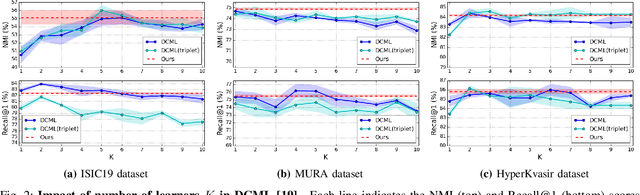
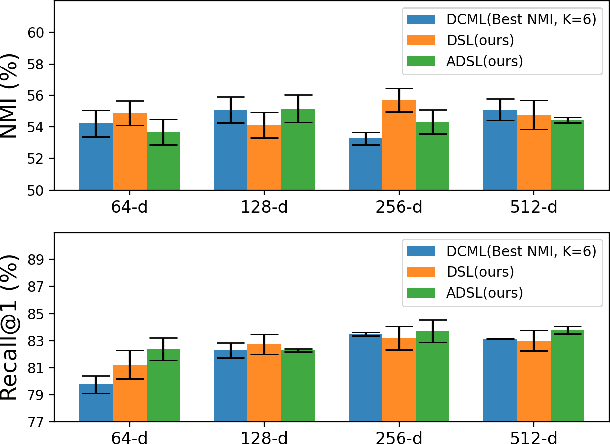
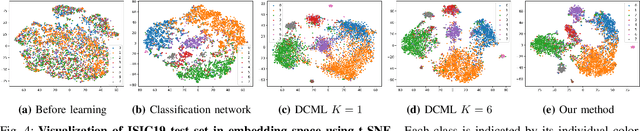
Learning similarity is a key aspect in medical image analysis, particularly in recommendation systems or in uncovering the interpretation of anatomical data in images. Most existing methods learn such similarities in the embedding space over image sets using a single metric learner. Images, however, have a variety of object attributes such as color, shape, or artifacts. Encoding such attributes using a single metric learner is inadequate and may fail to generalize. Instead, multiple learners could focus on separate aspects of these attributes in subspaces of an overarching embedding. This, however, implies the number of learners to be found empirically for each new dataset. This work, Dynamic Subspace Learners, proposes to dynamically exploit multiple learners by removing the need of knowing apriori the number of learners and aggregating new subspace learners during training. Furthermore, the visual interpretability of such subspace learning is enforced by integrating an attention module into our method. This integrated attention mechanism provides a visual insight of discriminative image features that contribute to the clustering of image sets and a visual explanation of the embedding features. The benefits of our attention-based dynamic subspace learners are evaluated in the application of image clustering, image retrieval, and weakly supervised segmentation. Our method achieves competitive results with the performances of multiple learners baselines and significantly outperforms the classification network in terms of clustering and retrieval scores on three different public benchmark datasets. Moreover, our attention maps offer a proxy-labels, which improves the segmentation accuracy up to 15% in Dice scores when compared to state-of-the-art interpretation techniques.
Semi-supervised Ranking for Object Image Blur Assessment
Jul 13, 2022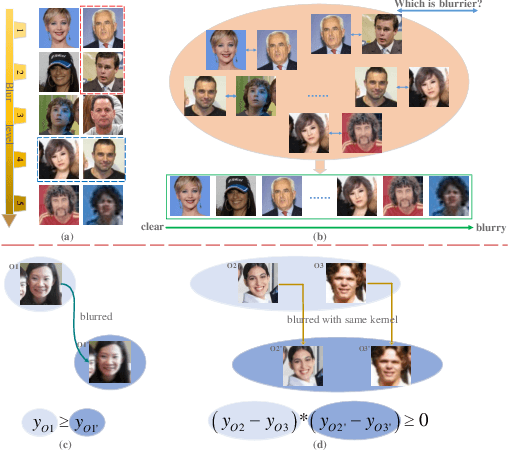
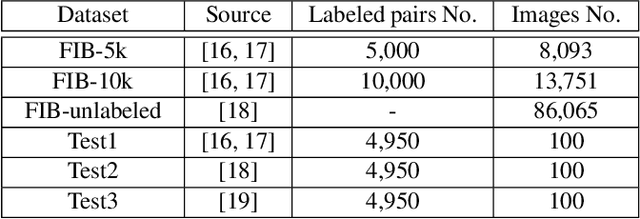
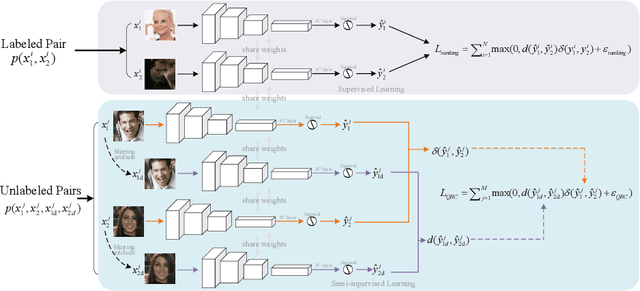
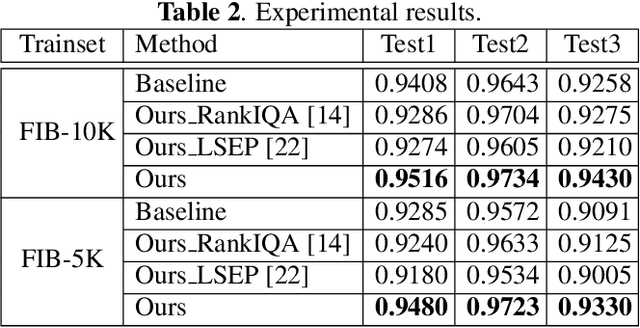
Assessing the blurriness of an object image is fundamentally important to improve the performance for object recognition and retrieval. The main challenge lies in the lack of abundant images with reliable labels and effective learning strategies. Current datasets are labeled with limited and confused quality levels. To overcome this limitation, we propose to label the rank relationships between pairwise images rather their quality levels, since it is much easier for humans to label, and establish a large-scale realistic face image blur assessment dataset with reliable labels. Based on this dataset, we propose a method to obtain the blur scores only with the pairwise rank labels as supervision. Moreover, to further improve the performance, we propose a self-supervised method based on quadruplet ranking consistency to leverage the unlabeled data more effectively. The supervised and self-supervised methods constitute a final semi-supervised learning framework, which can be trained end-to-end. Experimental results demonstrate the effectiveness of our method.
Structural Prior Guided Generative Adversarial Transformers for Low-Light Image Enhancement
Jul 16, 2022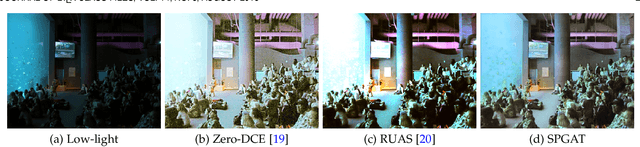
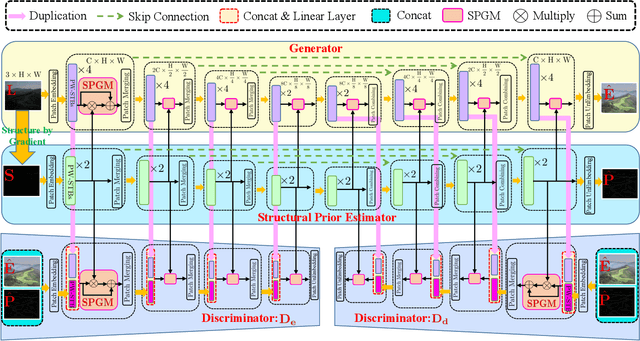


We propose an effective Structural Prior guided Generative Adversarial Transformer (SPGAT) to solve low-light image enhancement. Our SPGAT mainly contains a generator with two discriminators and a structural prior estimator (SPE). The generator is based on a U-shaped Transformer which is used to explore non-local information for better clear image restoration. The SPE is used to explore useful structures from images to guide the generator for better structural detail estimation. To generate more realistic images, we develop a new structural prior guided adversarial learning method by building the skip connections between the generator and discriminators so that the discriminators can better discriminate between real and fake features. Finally, we propose a parallel windows-based Swin Transformer block to aggregate different level hierarchical features for high-quality image restoration. Experimental results demonstrate that the proposed SPGAT performs favorably against recent state-of-the-art methods on both synthetic and real-world datasets.
A Neural-Network-Based Convex Regularizer for Image Reconstruction
Nov 22, 2022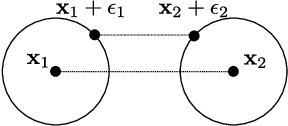
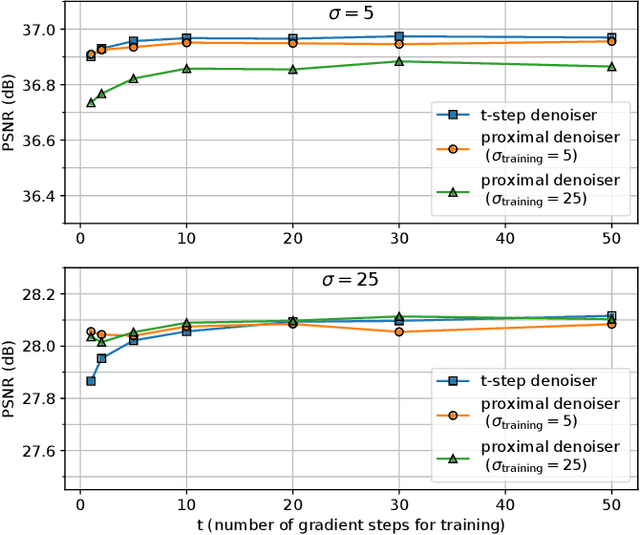
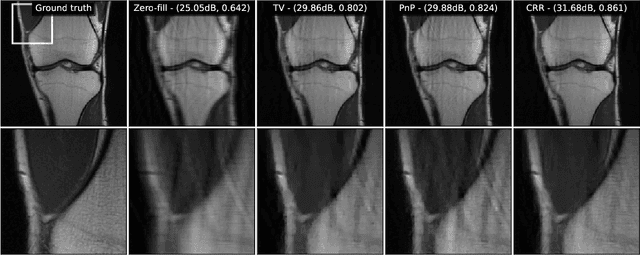
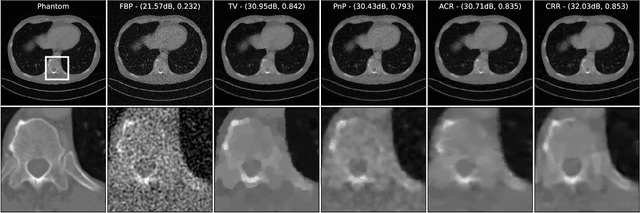
The emergence of deep-learning-based methods for solving inverse problems has enabled a significant increase in reconstruction quality. Unfortunately, these new methods often lack reliability and explainability, and there is a growing interest to address these shortcomings while retaining the performance. In this work, this problem is tackled by revisiting regularizers that are the sum of convex-ridge functions. The gradient of such regularizers is parametrized by a neural network that has a single hidden layer with increasing and learnable activation functions. This neural network is trained within a few minutes as a multi-step Gaussian denoiser. The numerical experiments for denoising, CT, and MRI reconstruction show improvements over methods that offer similar reliability guarantees.
Interactive Control over Temporal-consistency while Stylizing Video Streams
Jan 02, 2023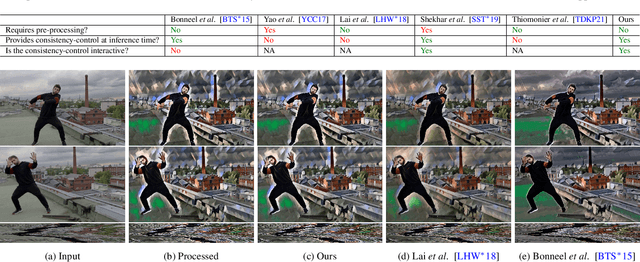
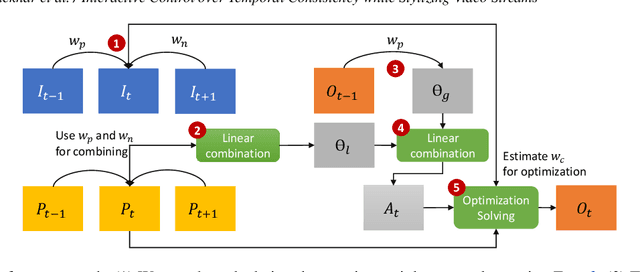
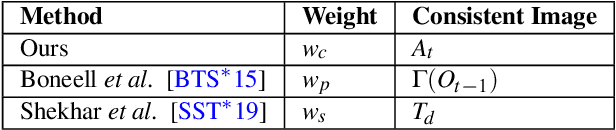
With the advent of Neural Style Transfer (NST), stylizing an image has become quite popular. A convenient way for extending stylization techniques to videos is by applying them on a per-frame basis. However, such per-frame application usually lacks temporal-consistency expressed by undesirable flickering artifacts. Most of the existing approaches for enforcing temporal-consistency suffers from one or more of the following drawbacks. They (1) are only suitable for a limited range of stylization techniques, (2) can only be applied in an offline fashion requiring the complete video as input, (3) cannot provide consistency for the task of stylization, or (4) do not provide interactive consistency-control. Note that existing consistent video-filtering approaches aim to completely remove flickering artifacts and thus do not respect any specific consistency-control aspect. For stylization tasks, however, consistency-control is an essential requirement where a certain amount of flickering can add to the artistic look and feel. Moreover, making this control interactive is paramount from a usability perspective. To achieve the above requirements, we propose an approach that can stylize video streams while providing interactive consistency-control. Apart from stylization, our approach also supports various other image processing filters. For achieving interactive performance, we develop a lite optical-flow network that operates at 80 Frames per second (FPS) on desktop systems with sufficient accuracy. We show that the final consistent video-output using our flow network is comparable to that being obtained using state-of-the-art optical-flow network. Further, we employ an adaptive combination of local and global consistent features and enable interactive selection between the two. By objective and subjective evaluation, we show that our method is superior to state-of-the-art approaches.