 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adaptive and Scalable Compression of Multispectral Images using VVC
Jan 10, 2023

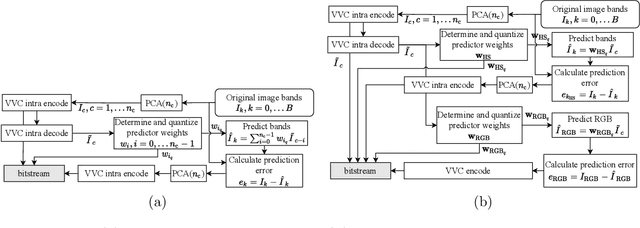
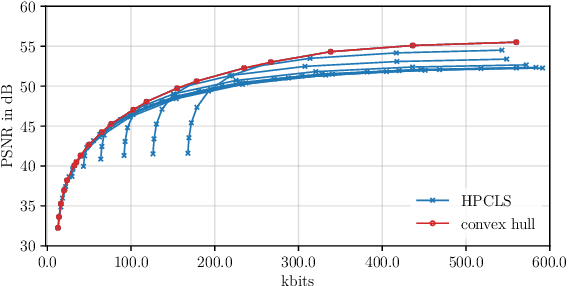
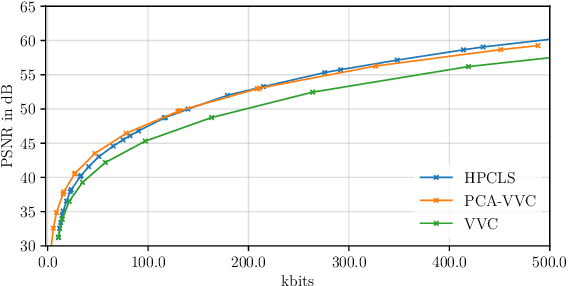
The VVC codec is applied to the task of multispectral image (MSI) compression using adaptive and scalable coding structures. In a 'plain' VVC approach, concepts from picture-to-picture temporal prediction are employed for decorrelation along the MSI's spectral dimension. The popular principle component analysis (PCA) for spectral decorrelation is further evaluated in combination with VVC intra-coding for spatial decorrelation. This approach is referred to as PCA-VVC. A novel adaptive MSI compression algorithm, named HPCLS, is introduced, that uses PCA and inter-prediction for spectral and VVC intra-coding for spatial decorrelation. Further, a novel adaptive scalable approach is proposed, that provides a separately decodable spectrally scaled preview of the MSI in the compressed file. Information contained in the preview is exploited in order to reduce the overall file size. All schemes are evaluated on images from the ARAD HS data set containing outdoor scenes with a high variety in brightness and color. We found that 'Plain' VVC is outperformed by both PCA-VVC and HPCLS. HPCLS shows advantageous rate-distortion (RD) behavior compared to PCA-VVC for reconstruction quality above 51dB PSNR. The performance of the scalable approach is compared to the combination of an independent RGB preview and one of HPCLS or PCA-VVC. The scalable approach shows significant benefit especially at higher preview qualities.
MMNet: Multi-modal Fusion with Mutual Learning Network for Fake News Detection
Dec 12, 2022
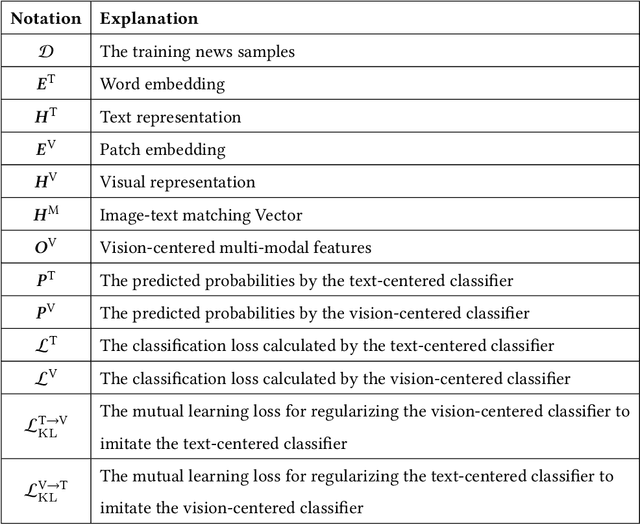
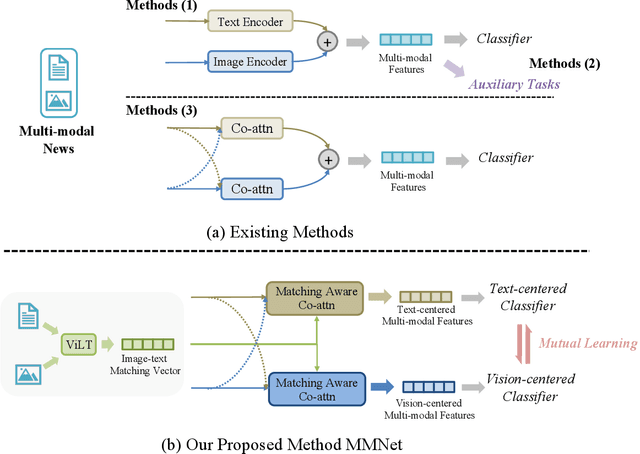
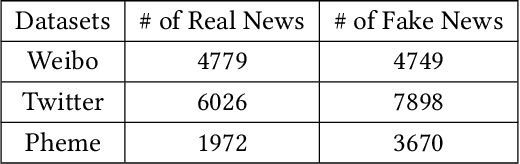
The rapid development of social media provides a hotbed for the dissemination of fake news, which misleads readers and causes negative effects on society. News usually involves texts and images to be more vivid. Consequently, multi-modal fake news detection has received wide attention. Prior efforts primarily conduct multi-modal fusion by simple concatenation or co-attention mechanism, leading to sub-optimal performance. In this paper, we propose a novel mutual learning network based model MMNet, which enhances the multi-modal fusion for fake news detection via mutual learning between text- and vision-centered views towards the same classification objective. Specifically, we design two detection modules respectively based on text- and vision-centered multi-modal fusion features, and enable the mutual learning of the two modules to facilitate the multi-modal fusion, considering the latent consistency between the two modules towards the same training objective. Moreover, we also consider the influence of the image-text matching degree on news authenticity judgement by designing an image-text matching aware co-attention mechanism for multi-modal fusion. Extensive experiments are conducted on three benchmark datasets and the results demonstrate that our proposed MMNet achieves superior performance in fake news detection.
Bringing the Algorithms to the Data -- Secure Distributed Medical Analytics using the Personal Health Train (PHT-meDIC)
Dec 07, 2022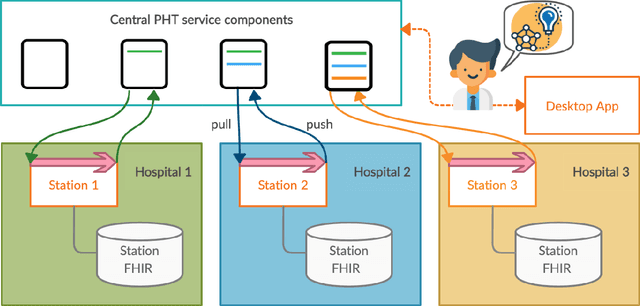
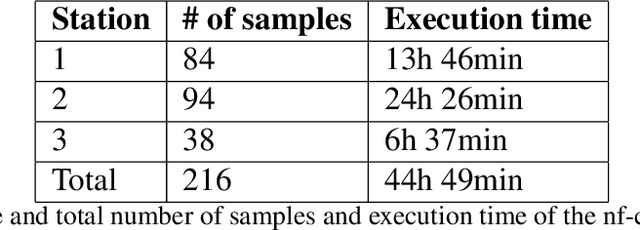
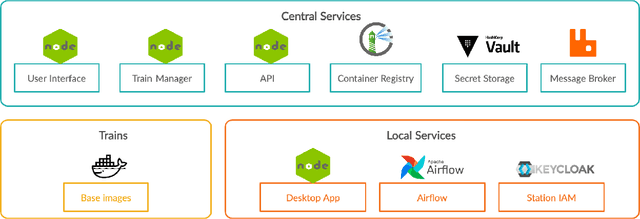
The need for data privacy and security -- enforced through increasingly strict data protection regulations -- renders the use of healthcare data for machine learning difficult. In particular, the transfer of data between different hospitals is often not permissible and thus cross-site pooling of data not an option. The Personal Health Train (PHT) paradigm proposed within the GO-FAIR initiative implements an 'algorithm to the data' paradigm that ensures that distributed data can be accessed for analysis without transferring any sensitive data. We present PHT-meDIC, a productively deployed open-source implementation of the PHT concept. Containerization allows us to easily deploy even complex data analysis pipelines (e.g, genomics, image analysis) across multiple sites in a secure and scalable manner. We discuss the underlying technological concepts, security models, and governance processes. The implementation has been successfully applied to distributed analyses of large-scale data, including applications of deep neural networks to medical image data.
Fine-tuned Generative Adversarial Network-based Model for Medical Images Super-Resolution
Nov 10, 2022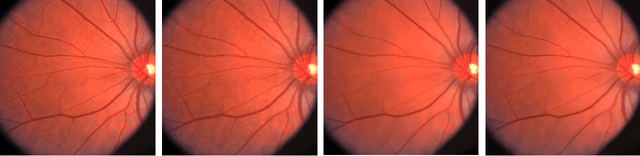
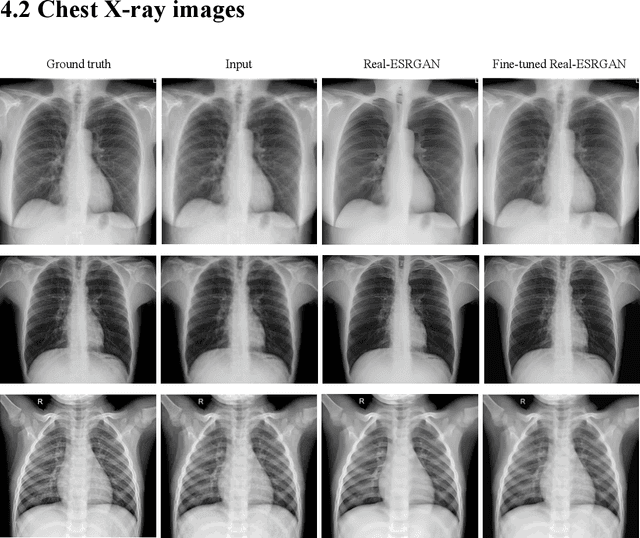
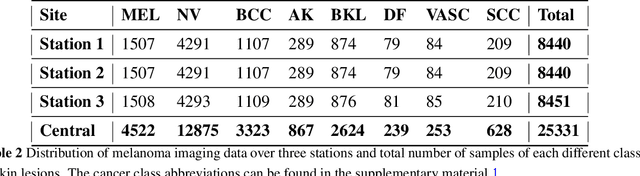
In medical image analysis, low-resolution images negatively affect the performance of medical image interpretation and may cause misdiagnosis. Single image super-resolution (SISR) methods can improve the resolution and quality of medical images. Currently, Generative Adversarial Networks (GAN) based super-resolution models have shown very good performance. Real-Enhanced Super-Resolution Generative Adversarial Network (Real-ESRGAN) is one of the practical GAN-based models which is widely used in the field of general image super-resolution. One of the challenges in medical image super-resolution is that, unlike natural images, medical images do not have high spatial resolution. To solve this problem, we can use transfer learning technique and fine-tune the model that has been trained on external datasets (often natural datasets). In our proposed approach, the pre-trained generator and discriminator networks of the Real-ESRGAN model are fine-tuned using medical image datasets. In this paper, we worked on chest X-ray and retinal images and used the STARE dataset of retinal images and Tuberculosis Chest X-rays (Shenzhen) dataset for fine-tuning. The proposed model produces more accurate and natural textures, and its outputs have better details and resolution compared to the original Real-ESRGAN outputs.
RIC-CNN: Rotation-Invariant Coordinate Convolutional Neural Network
Nov 21, 2022
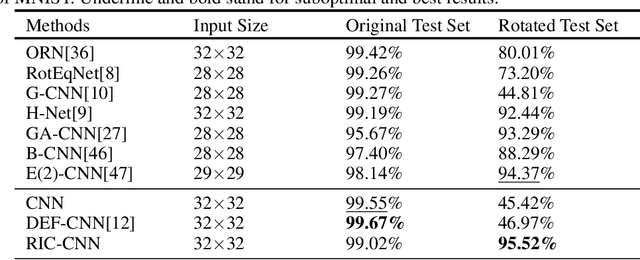
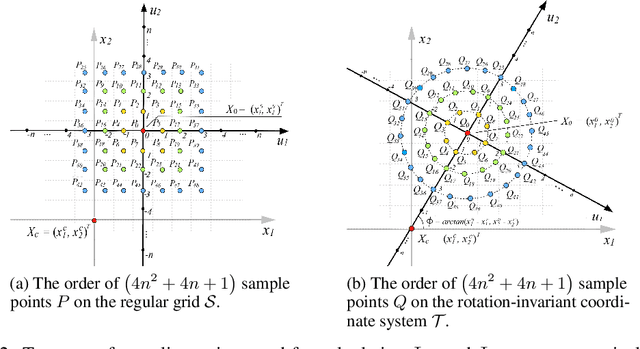
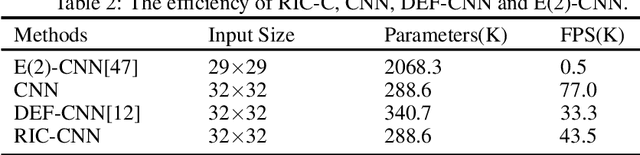
In recent years, convolutional neural network has shown good performance in many image processing and computer vision tasks. However, a standard CNN model is not invariant to image rotations. In fact, even slight rotation of an input image will seriously degrade its performance. This shortcoming precludes the use of CNN in some practical scenarios. Thus, in this paper, we focus on designing convolutional layer with good rotation invariance. Specifically, based on a simple rotation-invariant coordinate system, we propose a new convolutional operation, called Rotation-Invariant Coordinate Convolution (RIC-C). Without additional trainable parameters and data augmentation, RIC-C is naturally invariant to arbitrary rotations around the input center. Furthermore, we find the connection between RIC-C and deformable convolution, and propose a simple but efficient approach to implement RIC-C using Pytorch. By replacing all standard convolutional layers in a CNN with the corresponding RIC-C, a RIC-CNN can be derived. Using MNIST dataset, we first evaluate the rotation invariance of RIC-CNN and compare its performance with most of existing rotation-invariant CNN models. It can be observed that RIC-CNN achieves the state-of-the-art classification on the rotated test dataset of MNIST. Then, we deploy RIC-C to VGG, ResNet and DenseNet, and conduct the classification experiments on two real image datasets. Also, a shallow CNN and the corresponding RIC-CNN are trained to extract image patch descriptors, and we compare their performance in patch verification. These experimental results again show that RIC-C can be easily used as drop in replacement for standard convolutions, and greatly enhances the rotation invariance of CNN models designed for different applications.
SLAN: Self-Locator Aided Network for Cross-Modal Understanding
Nov 28, 2022
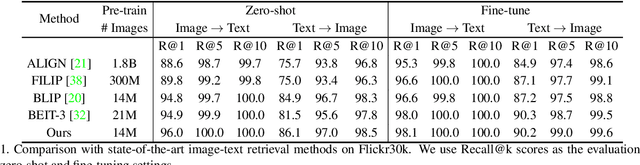
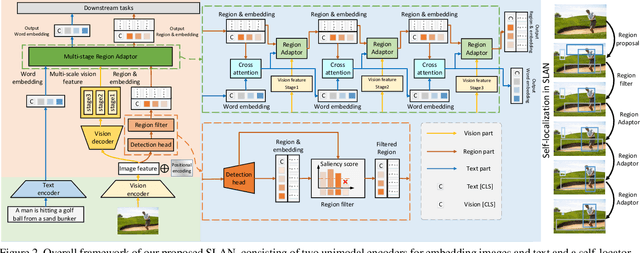
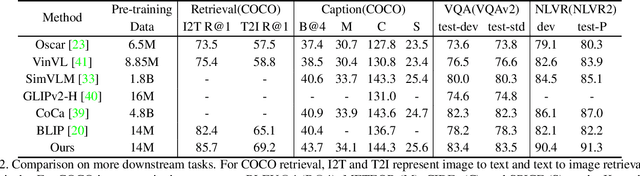
Learning fine-grained interplay between vision and language allows to a more accurate understanding for VisionLanguage tasks. However, it remains challenging to extract key image regions according to the texts for semantic alignments. Most existing works are either limited by textagnostic and redundant regions obtained with the frozen detectors, or failing to scale further due to its heavy reliance on scarce grounding (gold) data to pre-train detectors. To solve these problems, we propose Self-Locator Aided Network (SLAN) for cross-modal understanding tasks without any extra gold data. SLAN consists of a region filter and a region adaptor to localize regions of interest conditioned on different texts. By aggregating cross-modal information, the region filter selects key regions and the region adaptor updates their coordinates with text guidance. With detailed region-word alignments, SLAN can be easily generalized to many downstream tasks. It achieves fairly competitive results on five cross-modal understanding tasks (e.g., 85.7% and 69.2% on COCO image-to-text and text-to-image retrieval, surpassing previous SOTA methods). SLAN also demonstrates strong zero-shot and fine-tuned transferability to two localization tasks.
Dual Graphs of Polyhedral Decompositions for the Detection of Adversarial Attacks
Dec 02, 2022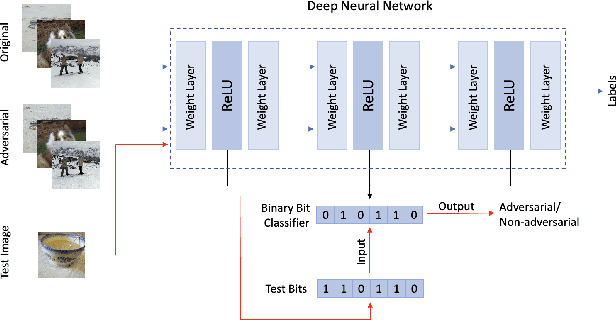
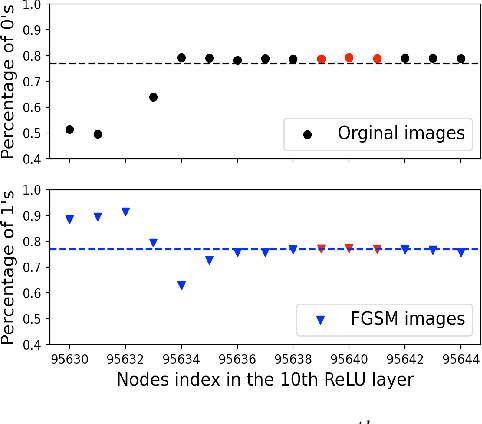
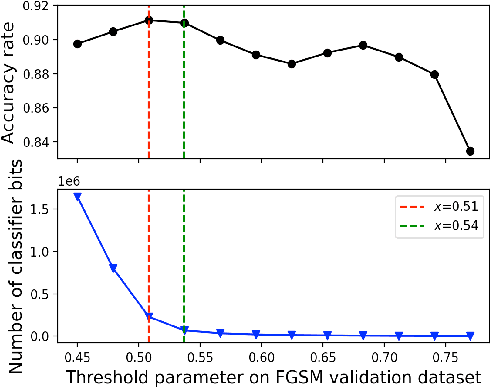
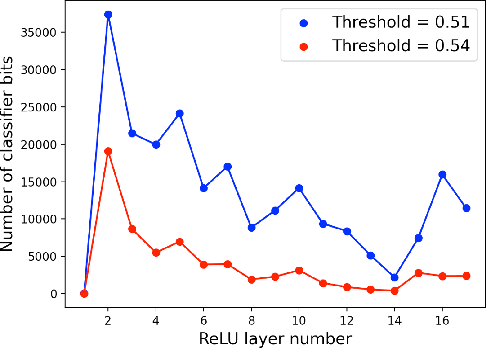
Previous work has shown that a neural network with the rectified linear unit (ReLU) activation function leads to a convex polyhedral decomposition of the input space. These decompositions can be represented by a dual graph with vertices corresponding to polyhedra and edges corresponding to polyhedra sharing a facet, which is a subgraph of a Hamming graph. This paper illustrates how one can utilize the dual graph to detect and analyze adversarial attacks in the context of digital images. When an image passes through a network containing ReLU nodes, the firing or non-firing at a node can be encoded as a bit ($1$ for ReLU activation, $0$ for ReLU non-activation). The sequence of all bit activations identifies the image with a bit vector, which identifies it with a polyhedron in the decomposition and, in turn, identifies it with a vertex in the dual graph. We identify ReLU bits that are discriminators between non-adversarial and adversarial images and examine how well collections of these discriminators can ensemble vote to build an adversarial image detector. Specifically, we examine the similarities and differences of ReLU bit vectors for adversarial images, and their non-adversarial counterparts, using a pre-trained ResNet-50 architecture. While this paper focuses on adversarial digital images, ResNet-50 architecture, and the ReLU activation function, our methods extend to other network architectures, activation functions, and types of datasets.
Pluralistic Image Completion with Probabilistic Mixture-of-Experts
May 18, 2022
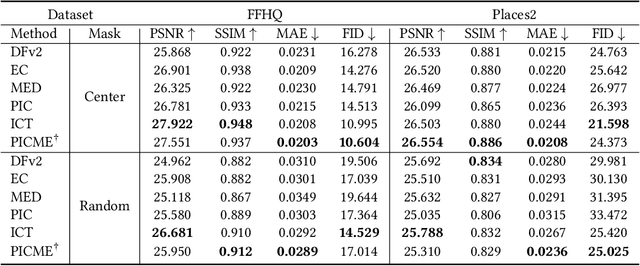

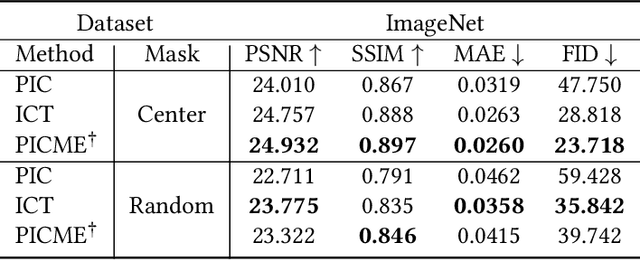
Pluralistic image completion focuses on generating both visually realistic and diverse results for image completion. Prior methods enjoy the empirical successes of this task. However, their used constraints for pluralistic image completion are argued to be not well interpretable and unsatisfactory from two aspects. First, the constraints for visual reality can be weakly correlated to the objective of image completion or even redundant. Second, the constraints for diversity are designed to be task-agnostic, which causes the constraints to not work well. In this paper, to address the issues, we propose an end-to-end probabilistic method. Specifically, we introduce a unified probabilistic graph model that represents the complex interactions in image completion. The entire procedure of image completion is then mathematically divided into several sub-procedures, which helps efficient enforcement of constraints. The sub-procedure directly related to pluralistic results is identified, where the interaction is established by a Gaussian mixture model (GMM). The inherent parameters of GMM are task-related, which are optimized adaptively during training, while the number of its primitives can control the diversity of results conveniently. We formally establish the effectiveness of our method and demonstrate it with comprehensive experiments.
Shared Coupling-bridge for Weakly Supervised Local Feature Learning
Dec 14, 2022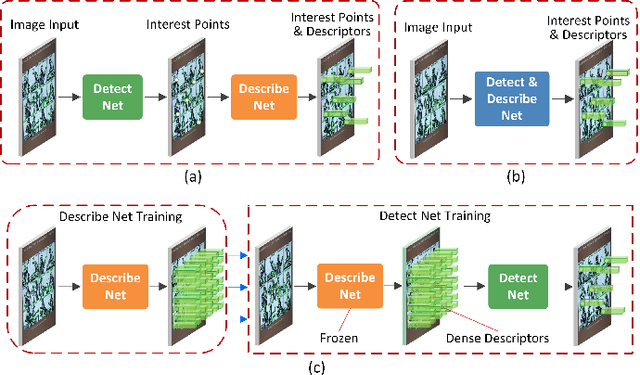


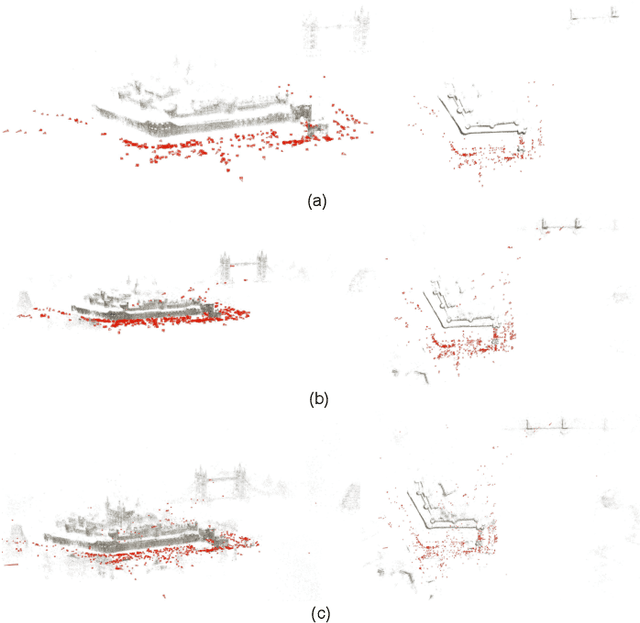
Sparse local feature extraction is usually believed to be of important significance in typical vision tasks such as simultaneous localization and mapping, image matching and 3D reconstruction. At present, it still has some deficiencies needing further improvement, mainly including the discrimination power of extracted local descriptors, the localization accuracy of detected keypoints, and the efficiency of local feature learning. This paper focuses on promoting the currently popular sparse local feature learning with camera pose supervision. Therefore, it pertinently proposes a Shared Coupling-bridge scheme with four light-weight yet effective improvements for weakly-supervised local feature (SCFeat) learning. It mainly contains: i) the \emph{Feature-Fusion-ResUNet Backbone} (F2R-Backbone) for local descriptors learning, ii) a shared coupling-bridge normalization to improve the decoupling training of description network and detection network, iii) an improved detection network with peakiness measurement to detect keypoints and iv) the fundamental matrix error as a reward factor to further optimize feature detection training. Extensive experiments prove that our SCFeat improvement is effective. It could often obtain a state-of-the-art performance on classic image matching and visual localization. In terms of 3D reconstruction, it could still achieve competitive results. For sharing and communication, our source codes are available at https://github.com/sunjiayuanro/SCFeat.git.
Radon-based Image Reconstruction for MPI using a continuously rotating FFL
Nov 22, 2022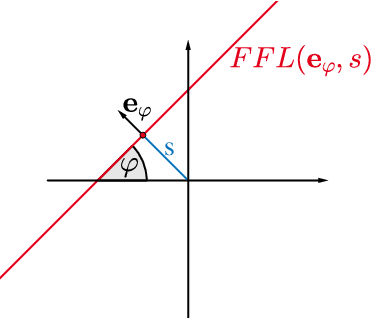
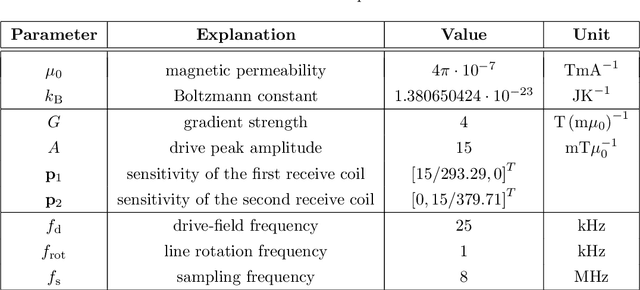
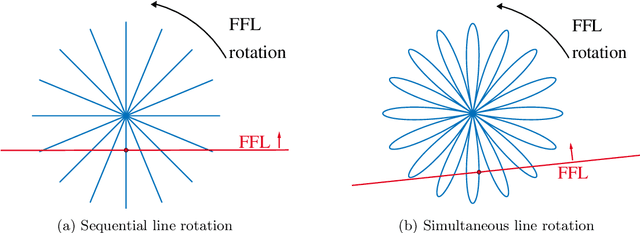

Magnetic particle imaging is a relatively new tracer-based medical imaging technique exploiting the non-linear magnetization response of magnetic nanoparticles to changing magnetic fields. If the data are generated by using a field-free line, the sampling geometry resembles the one in computerized tomography. Indeed, for an ideal field-free line rotating only in between measurements it was shown that the signal equation can be written as a convolution with the Radon transform of the particle concentration. In this work, we regard a continuously rotating field-free line and extend the forward operator accordingly. We obtain a similar result for the relation to the Radon data but with two additive terms resulting from the additional time-dependencies in the forward model. We jointly reconstruct particle concentration and corresponding Radon data by means of total variation regularization yielding promising results for synthetic data.