 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Nearest Neighbor-Based Contrastive Learning for Hyperspectral and LiDAR Data Classification
Jan 09, 2023
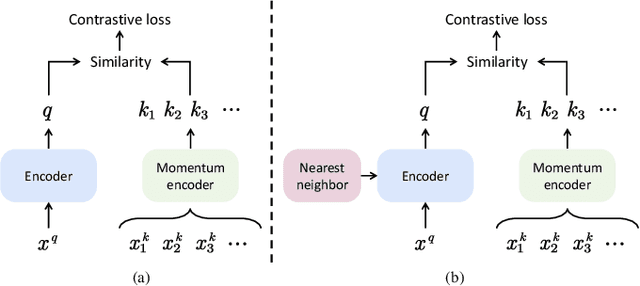
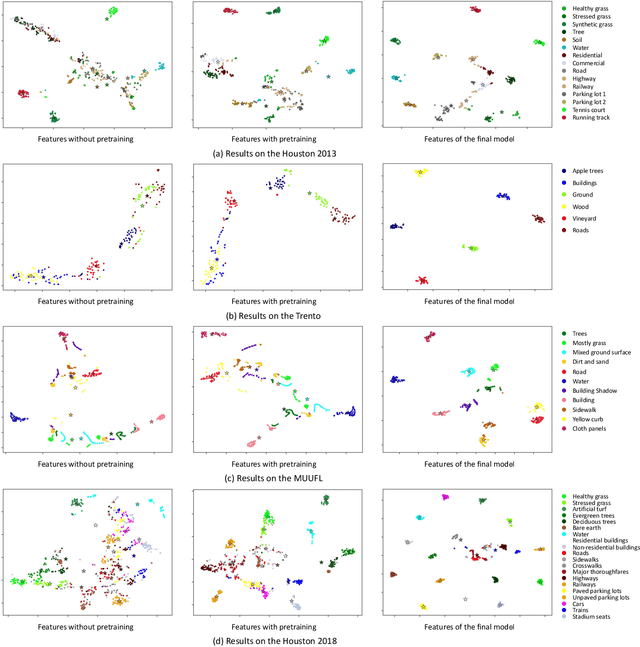
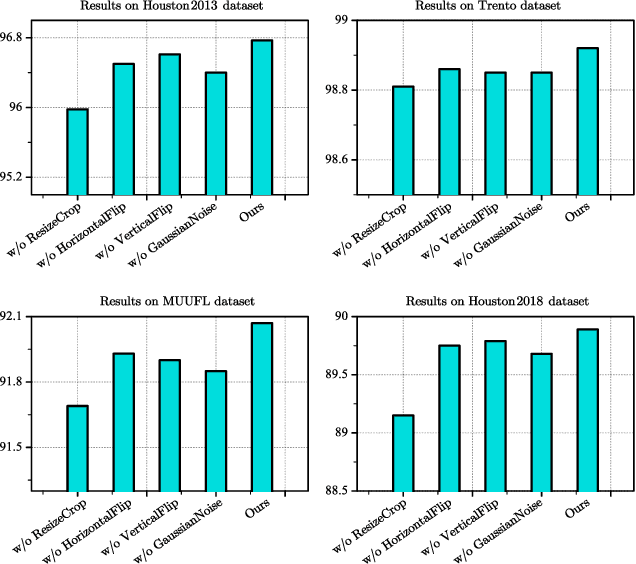
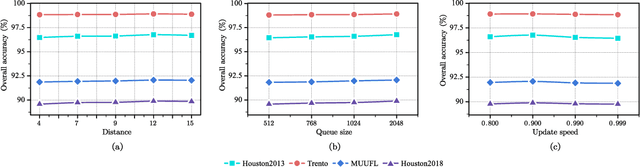
The joint hyperspectral image (HSI) and LiDAR data classification aims to interpret ground objects at more detailed and precise level. Although deep learning methods have shown remarkable success in the multisource data classification task, self-supervised learning has rarely been explored. It is commonly nontrivial to build a robust self-supervised learning model for multisource data classification, due to the fact that the semantic similarities of neighborhood regions are not exploited in existing contrastive learning framework. Furthermore, the heterogeneous gap induced by the inconsistent distribution of multisource data impedes the classification performance. To overcome these disadvantages, we propose a Nearest Neighbor-based Contrastive Learning Network (NNCNet), which takes full advantage of large amounts of unlabeled data to learn discriminative feature representations. Specifically, we propose a nearest neighbor-based data augmentation scheme to use enhanced semantic relationships among nearby regions. The intermodal semantic alignments can be captured more accurately. In addition, we design a bilinear attention module to exploit the second-order and even high-order feature interactions between the HSI and LiDAR data. Extensive experiments on four public datasets demonstrate the superiority of our NNCNet over state-of-the-art methods. The source codes are available at \url{https://github.com/summitgao/NNCNet}.
Explainable, Physics Aware, Trustworthy AI Paradigm Shift for Synthetic Aperture Radar
Jan 09, 2023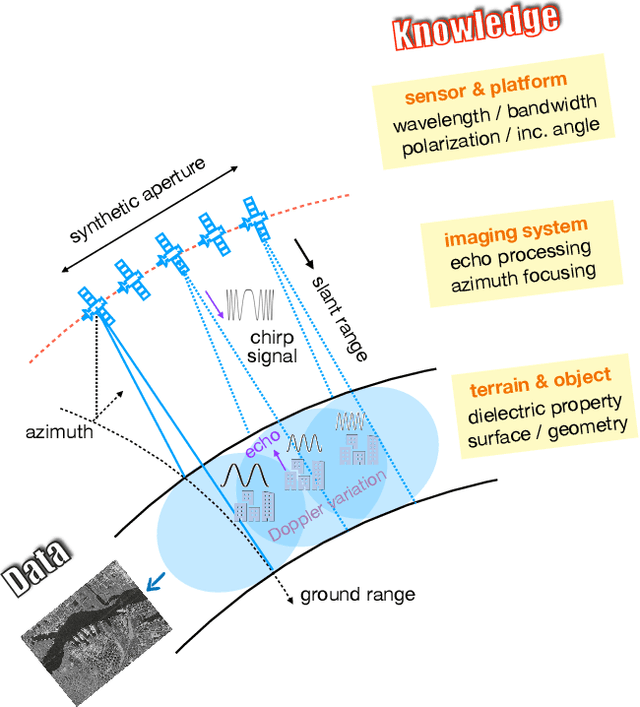
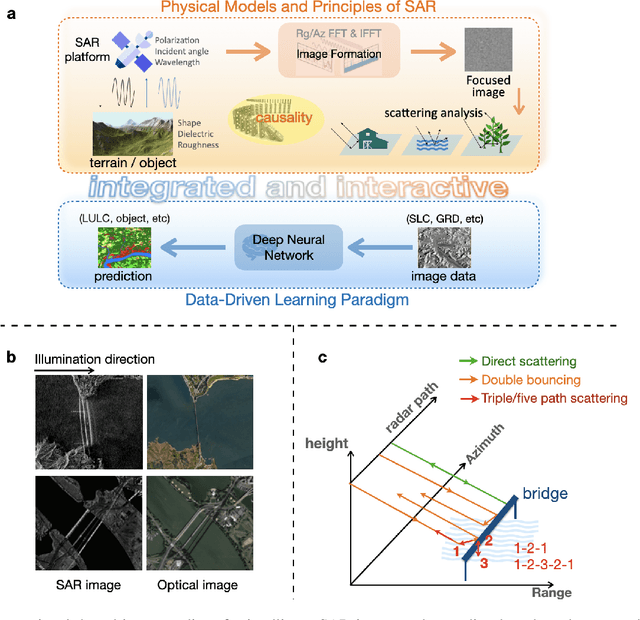
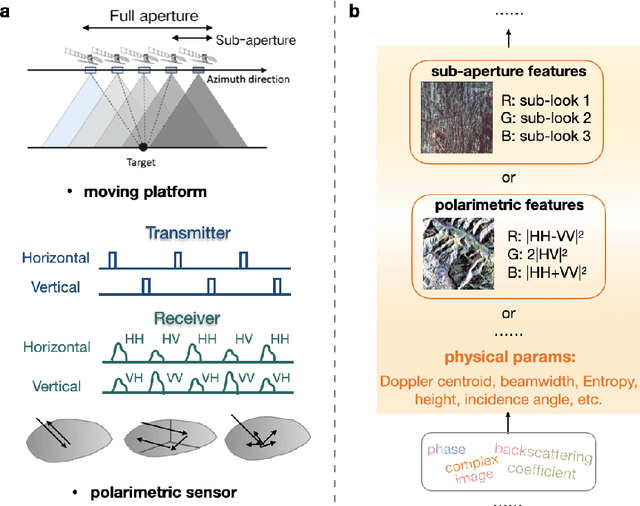
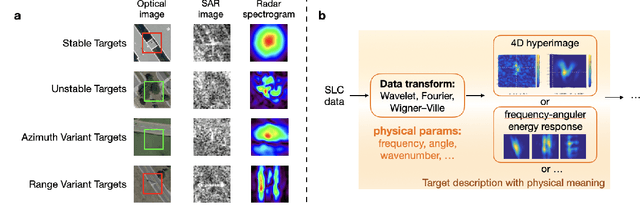
The recognition or understanding of the scenes observed with a SAR system requires a broader range of cues, beyond the spatial context. These encompass but are not limited to: imaging geometry, imaging mode, properties of the Fourier spectrum of the images or the behavior of the polarimetric signatures. In this paper, we propose a change of paradigm for explainability in data science for the case of Synthetic Aperture Radar (SAR) data to ground the explainable AI for SAR. It aims to use explainable data transformations based on well-established models to generate inputs for AI methods, to provide knowledgeable feedback for training process, and to learn or improve high-complexity unknown or un-formalized models from the data. At first, we introduce a representation of the SAR system with physical layers: i) instrument and platform, ii) imaging formation, iii) scattering signatures and objects, that can be integrated with an AI model for hybrid modeling. Successively, some illustrative examples are presented to demonstrate how to achieve hybrid modeling for SAR image understanding. The perspective of trustworthy model and supplementary explanations are discussed later. Finally, we draw the conclusion and we deem the proposed concept has applicability to the entire class of coherent imaging sensors and other computational imaging systems.
Robust Reflection Removal with Flash-only Cues in the Wild
Nov 05, 2022


We propose a simple yet effective reflection-free cue for robust reflection removal from a pair of flash and ambient (no-flash) images. The reflection-free cue exploits a flash-only image obtained by subtracting the ambient image from the corresponding flash image in raw data space. The flash-only image is equivalent to an image taken in a dark environment with only a flash on. This flash-only image is visually reflection-free and thus can provide robust cues to infer the reflection in the ambient image. Since the flash-only image usually has artifacts, we further propose a dedicated model that not only utilizes the reflection-free cue but also avoids introducing artifacts, which helps accurately estimate reflection and transmission. Our experiments on real-world images with various types of reflection demonstrate the effectiveness of our model with reflection-free flash-only cues: our model outperforms state-of-the-art reflection removal approaches by more than 5.23dB in PSNR. We extend our approach to handheld photography to address the misalignment between the flash and no-flash pair. With misaligned training data and the alignment module, our aligned model outperforms our previous version by more than 3.19dB in PSNR on a misaligned dataset. We also study using linear RGB images as training data. Our source code and dataset are publicly available at https://github.com/ChenyangLEI/flash-reflection-removal.
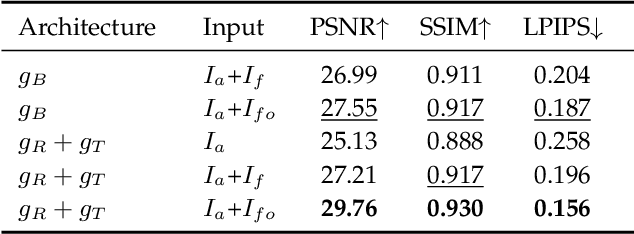
Towards Efficient and Scale-Robust Ultra-High-Definition Image Demoireing
Jul 20, 2022


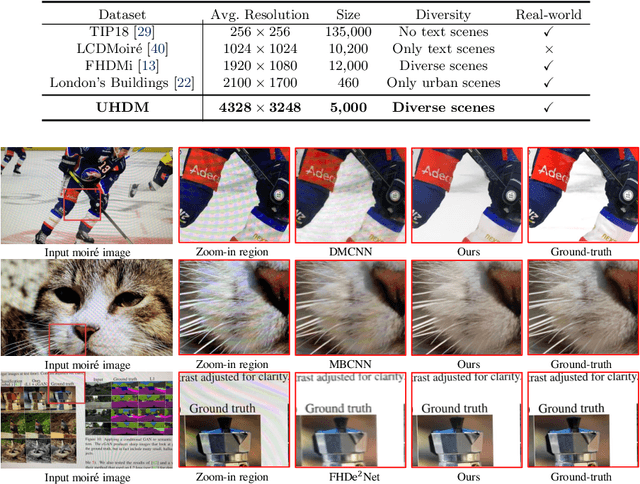
With the rapid development of mobile devices, modern widely-used mobile phones typically allow users to capture 4K resolution (i.e., ultra-high-definition) images. However, for image demoireing, a challenging task in low-level vision, existing works are generally carried out on low-resolution or synthetic images. Hence, the effectiveness of these methods on 4K resolution images is still unknown. In this paper, we explore moire pattern removal for ultra-high-definition images. To this end, we propose the first ultra-high-definition demoireing dataset (UHDM), which contains 5,000 real-world 4K resolution image pairs, and conduct a benchmark study on current state-of-the-art methods. Further, we present an efficient baseline model ESDNet for tackling 4K moire images, wherein we build a semantic-aligned scale-aware module to address the scale variation of moire patterns. Extensive experiments manifest the effectiveness of our approach, which outperforms state-of-the-art methods by a large margin while being much more lightweight. Code and dataset are available at https://xinyu-andy.github.io/uhdm-page.
Reinforcement Learning in Medical Image Analysis: Concepts, Applications, Challenges, and Future Directions
Jun 28, 2022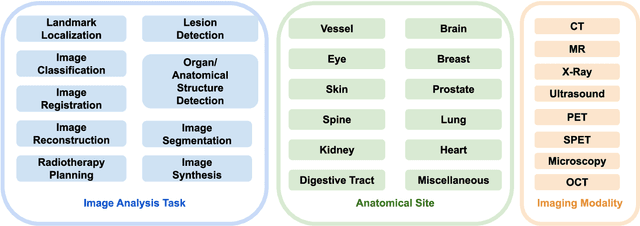
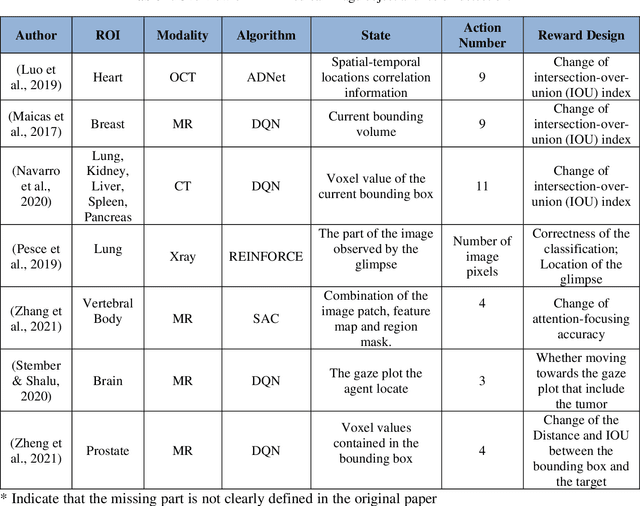
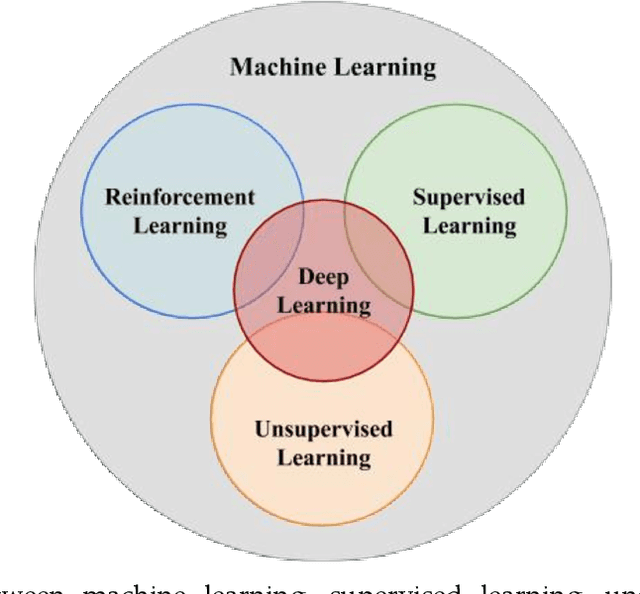
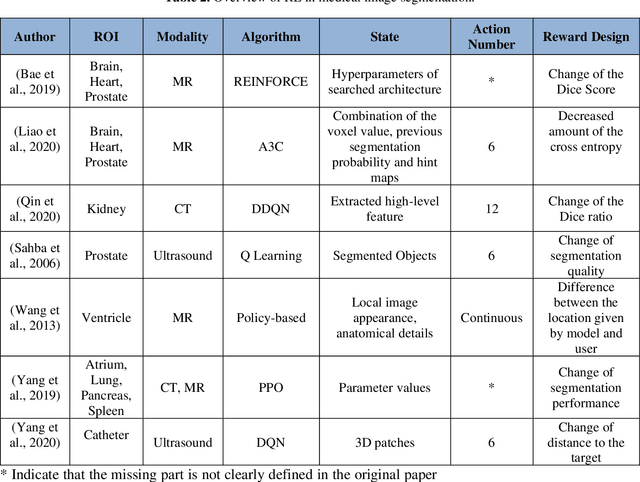
Motivation: Medical image analysis involves tasks to assist physicians in qualitative and quantitative analysis of lesions or anatomical structures, significantly improving the accuracy and reliability of diagnosis and prognosis. Traditionally, these tasks are finished by physicians or medical physicists and lead to two major problems: (i) low efficiency; (ii) biased by personal experience. In the past decade, many machine learning methods have been applied to accelerate and automate the image analysis process. Compared to the enormous deployments of supervised and unsupervised learning models, attempts to use reinforcement learning in medical image analysis are scarce. This review article could serve as the stepping-stone for related research. Significance: From our observation, though reinforcement learning has gradually gained momentum in recent years, many researchers in the medical analysis field find it hard to understand and deploy in clinics. One cause is lacking well-organized review articles targeting readers lacking professional computer science backgrounds. Rather than providing a comprehensive list of all reinforcement learning models in medical image analysis, this paper may help the readers to learn how to formulate and solve their medical image analysis research as reinforcement learning problems. Approach & Results: We selected published articles from Google Scholar and PubMed. Considering the scarcity of related articles, we also included some outstanding newest preprints. The papers are carefully reviewed and categorized according to the type of image analysis task. We first review the basic concepts and popular models of reinforcement learning. Then we explore the applications of reinforcement learning models in landmark detection. Finally, we conclude the article by discussing the reviewed reinforcement learning approaches' limitations and possible improvements.
Efficient Adaptive Ensembling for Image Classification
Jun 15, 2022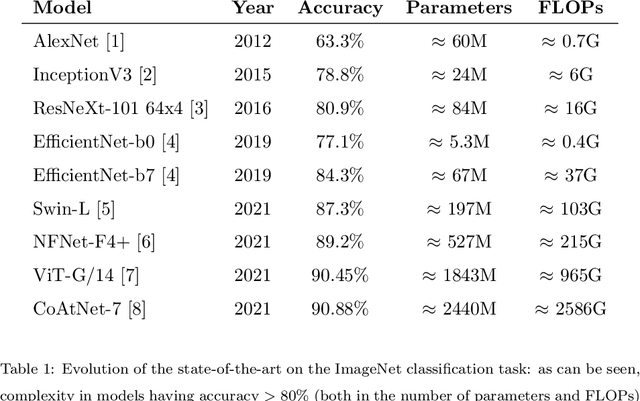
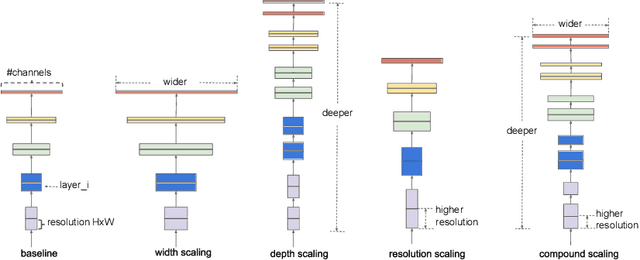
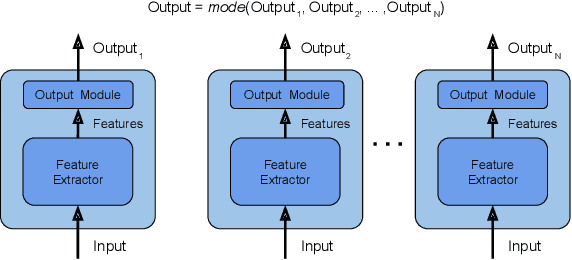
In recent times, except for sporadic cases, the trend in Computer Vision is to achieve minor improvements over considerable increases in complexity. To reverse this tendency, we propose a novel method to boost image classification performances without an increase in complexity. To this end, we revisited ensembling, a powerful approach, not often adequately used due to its nature of increased complexity and training time, making it viable by specific design choices. First, we trained end-to-end two EfficientNet-b0 models (known to be the architecture with the best overall accuracy/complexity trade-off in image classification) on disjoint subsets of data (i.e. bagging). Then, we made an efficient adaptive ensemble by performing fine-tuning of a trainable combination layer. In this way, we were able to outperform the state-of-the-art by an average of 0.5\% on the accuracy with restrained complexity both in terms of number of parameters (by 5-60 times), and FLoating point Operations Per Second (by 10-100 times) on several major benchmark datasets, fully embracing the green AI.
TAOTF: A Two-stage Approximately Orthogonal Training Framework in Deep Neural Networks
Dec 10, 2022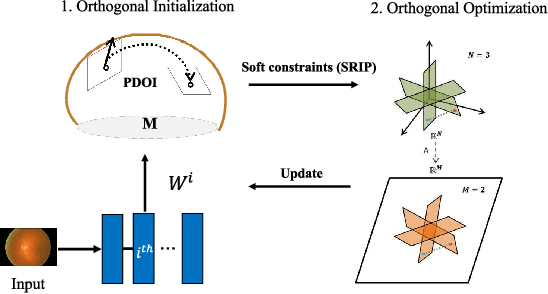
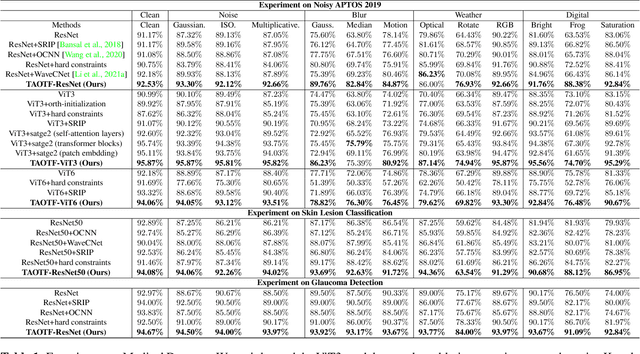
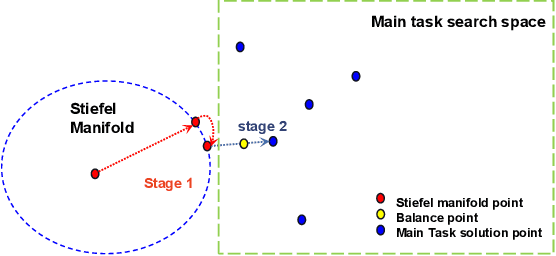
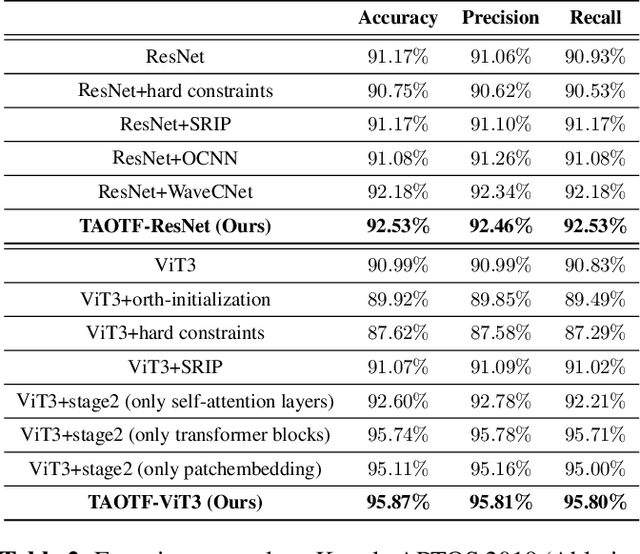
The orthogonality constraints, including the hard and soft ones, have been used to normalize the weight matrices of Deep Neural Network (DNN) models, especially the Convolutional Neural Network (CNN) and Vision Transformer (ViT), to reduce model parameter redundancy and improve training stability. However, the robustness to noisy data of these models with constraints is not always satisfactory. In this work, we propose a novel two-stage approximately orthogonal training framework (TAOTF) to find a trade-off between the orthogonal solution space and the main task solution space to solve this problem in noisy data scenarios. In the first stage, we propose a novel algorithm called polar decomposition-based orthogonal initialization (PDOI) to find a good initialization for the orthogonal optimization. In the second stage, unlike other existing methods, we apply soft orthogonal constraints for all layers of DNN model. We evaluate the proposed model-agnostic framework both on the natural image and medical image datasets, which show that our method achieves stable and superior performances to existing methods.
Fine-tuned Generative Adversarial Network-based Model for Medical Images Super-Resolution
Nov 10, 2022
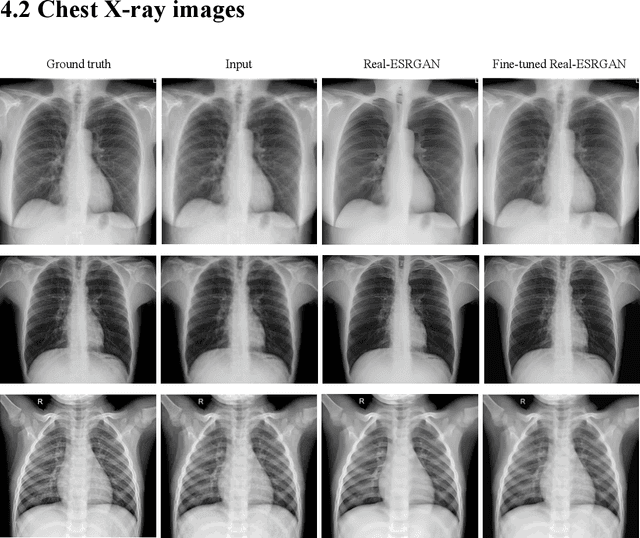
In medical image analysis, low-resolution images negatively affect the performance of medical image interpretation and may cause misdiagnosis. Single image super-resolution (SISR) methods can improve the resolution and quality of medical images. Currently, Generative Adversarial Networks (GAN) based super-resolution models have shown very good performance. Real-Enhanced Super-Resolution Generative Adversarial Network (Real-ESRGAN) is one of the practical GAN-based models which is widely used in the field of general image super-resolution. One of the challenges in medical image super-resolution is that, unlike natural images, medical images do not have high spatial resolution. To solve this problem, we can use transfer learning technique and fine-tune the model that has been trained on external datasets (often natural datasets). In our proposed approach, the pre-trained generator and discriminator networks of the Real-ESRGAN model are fine-tuned using medical image datasets. In this paper, we worked on chest X-ray and retinal images and used the STARE dataset of retinal images and Tuberculosis Chest X-rays (Shenzhen) dataset for fine-tuning. The proposed model produces more accurate and natural textures, and its outputs have better details and resolution compared to the original Real-ESRGAN outputs.
Studying inductive biases in image classification task
Oct 31, 2022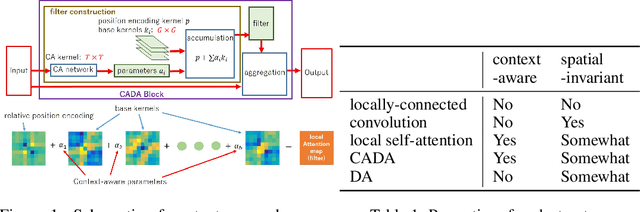

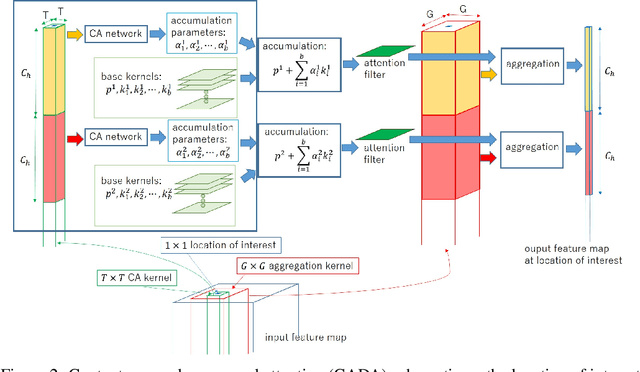
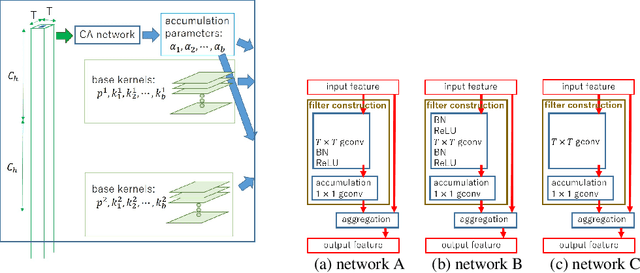
Recently, self-attention (SA) structures became popular in computer vision fields. They have locally independent filters and can use large kernels, which contradicts the previously popular convolutional neural networks (CNNs). CNNs success was attributed to the hard-coded inductive biases of locality and spatial invariance. However, recent studies have shown that inductive biases in CNNs are too restrictive. On the other hand, the relative position encodings, similar to depthwise (DW) convolution, are necessary for the local SA networks, which indicates that the SA structures are not entirely spatially variant. Hence, we would like to determine which part of inductive biases contributes to the success of the local SA structures. To do so, we introduced context-aware decomposed attention (CADA), which decomposes attention maps into multiple trainable base kernels and accumulates them using context-aware (CA) parameters. This way, we could identify the link between the CNNs and SA networks. We conducted ablation studies using the ResNet50 applied to the ImageNet classification task. DW convolution could have a large locality without increasing computational costs compared to CNNs, but the accuracy saturates with larger kernels. CADA follows this characteristic of locality. We showed that context awareness was the crucial property; however, large local information was not necessary to construct CA parameters. Even though no spatial invariance makes training difficult, more relaxed spatial invariance gave better accuracy than strict spatial invariance. Also, additional strong spatial invariance through relative position encoding was preferable. We extended these experiments to filters for downsampling and showed that locality bias is more critical for downsampling but can remove the strong locality bias using relaxed spatial invariance.
The Predictive Forward-Forward Algorithm
Jan 04, 2023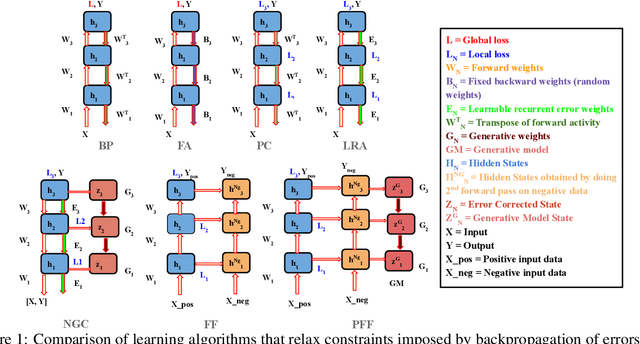
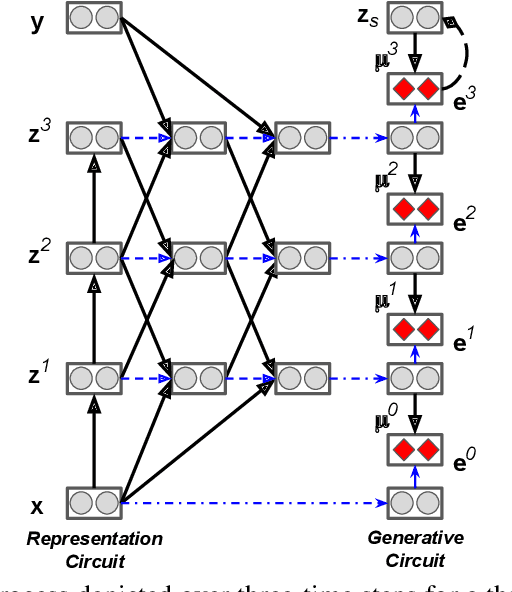
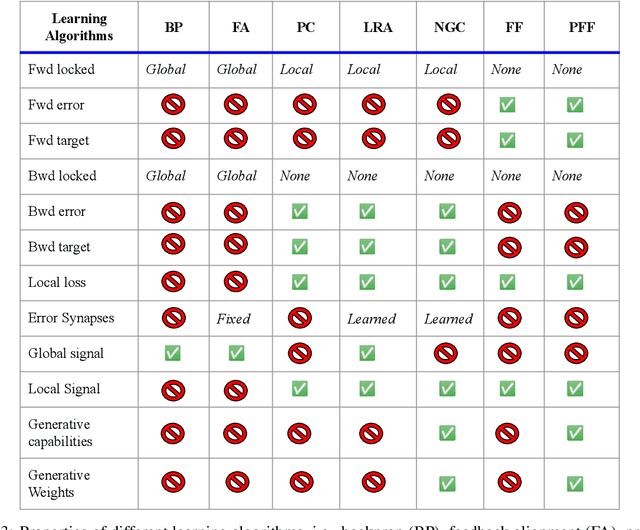

In this work, we propose a generalization of the forward-forward (FF) algorithm that we call the predictive forward-forward (PFF) algorithm. Specifically, we design a dynamic, recurrent neural system that learns a directed generative circuit jointly and simultaneously with a representation circuit, combining elements of predictive coding, an emerging and viable neurobiological process theory of cortical function, with the forward-forward adaptation scheme. Furthermore, PFF efficiently learns to propagate learning signals and updates synapses with forward passes only, eliminating some of the key structural and computational constraints imposed by a backprop-based scheme. Besides computational advantages, the PFF process could be further useful for understanding the learning mechanisms behind biological neurons that make use of local (and global) signals despite missing feedback connections. We run several experiments on image data and demonstrate that the PFF procedure works as well as backprop, offering a promising brain-inspired algorithm for classifying, reconstructing, and synthesizing data patterns. As a result, our approach presents further evidence of the promise afforded by backprop-alternative credit assignment algorithms within the context of brain-inspired computing.