 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CAT: Learning to Collaborate Channel and Spatial Attention from Multi-Information Fusion
Dec 13, 2022
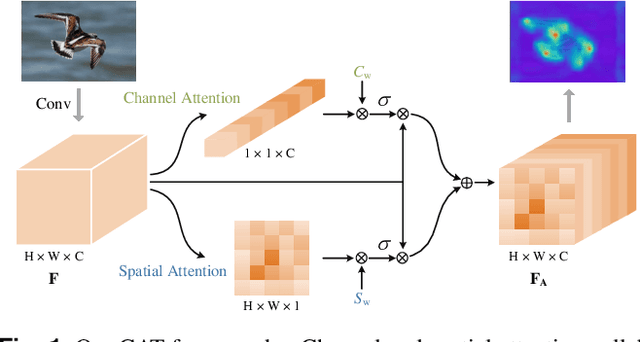
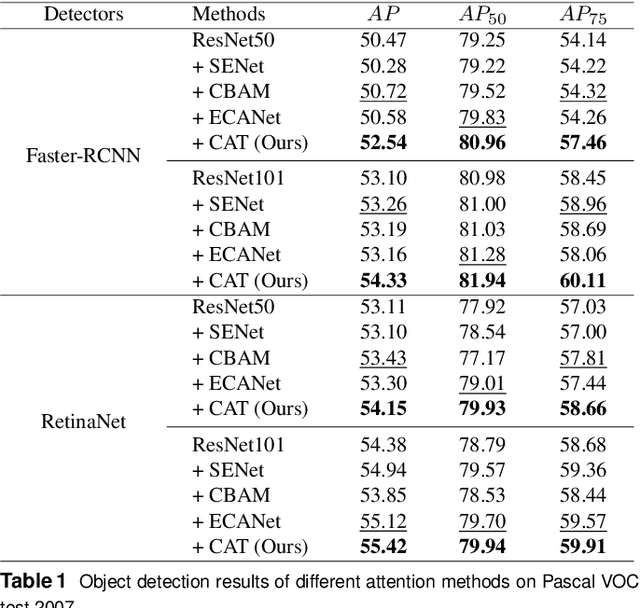
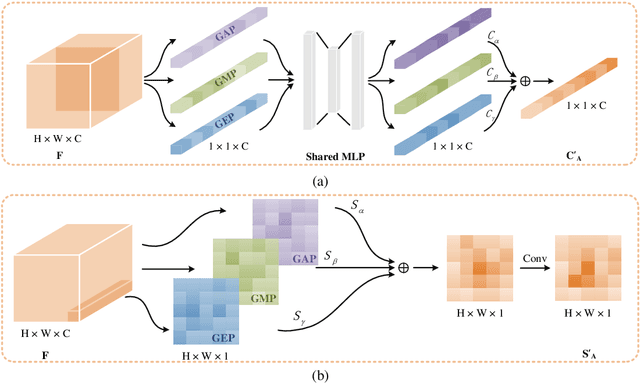
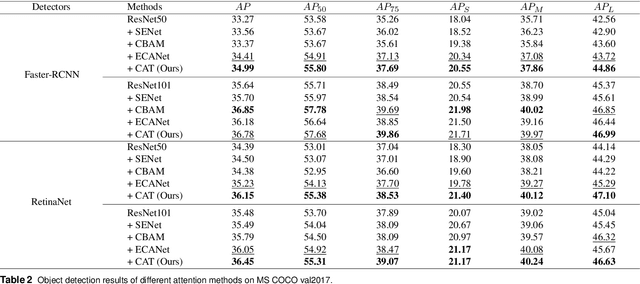
Channel and spatial attention mechanism has proven to provide an evident performance boost of deep convolution neural networks (CNNs). Most existing methods focus on one or run them parallel (series), neglecting the collaboration between the two attentions. In order to better establish the feature interaction between the two types of attention, we propose a plug-and-play attention module, which we term "CAT"-activating the Collaboration between spatial and channel Attentions based on learned Traits. Specifically, we represent traits as trainable coefficients (i.e., colla-factors) to adaptively combine contributions of different attention modules to fit different image hierarchies and tasks better. Moreover, we propose the global entropy pooling (GEP) apart from global average pooling (GAP) and global maximum pooling (GMP) operators, an effective component in suppressing noise signals by measuring the information disorder of feature maps. We introduce a three-way pooling operation into attention modules and apply the adaptive mechanism to fuse their outcomes. Extensive experiments on MS COCO, Pascal-VOC, Cifar-100, and ImageNet show that our CAT outperforms existing state-of-the-art attention mechanisms in object detection, instance segmentation, and image classification. The model and code will be released soon.
* 8 pages, 5 figures
I Can't Believe There's No Images! Learning Visual Tasks Using only Language Data
Dec 01, 2022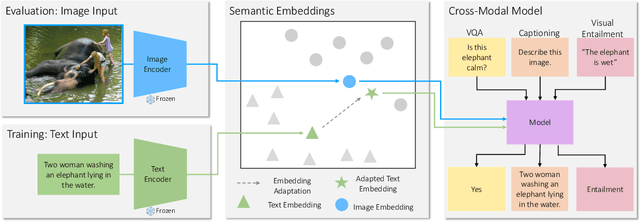
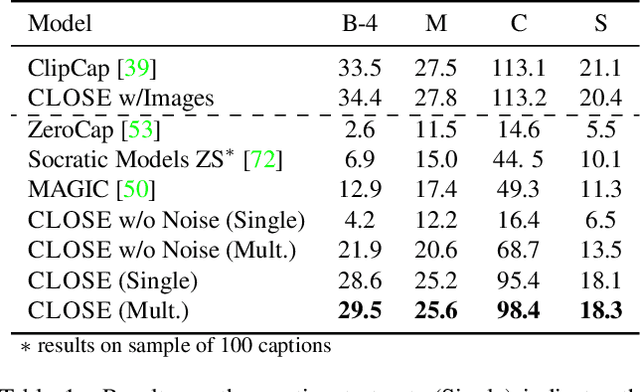

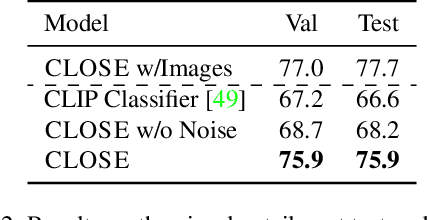
Many high-level skills that are required for computer vision tasks, such as parsing questions, comparing and contrasting semantics, and writing descriptions, are also required in other domains such as natural language processing. In this paper, we ask whether this makes it possible to learn those skills from text data and then use them to complete vision tasks without ever training on visual training data. Key to our approach is exploiting the joint embedding space of contrastively trained vision and language encoders. In practice, there can be systematic differences between embedding spaces for different modalities in contrastive models, and we analyze how these differences affect our approach and study a variety of strategies to mitigate this concern. We produce models using only text training data on three tasks: image captioning, visual entailment and visual question answering, and evaluate them on standard benchmarks using images. We find that this kind of transfer is possible and results in only a small drop in performance relative to models trained on images. We also showcase a variety of stylistic image captioning models that were trained using no image data and no human-curated language data, but instead text data from books, the web, or language models.
Efficient Adaptive Ensembling for Image Classification
Jun 15, 2022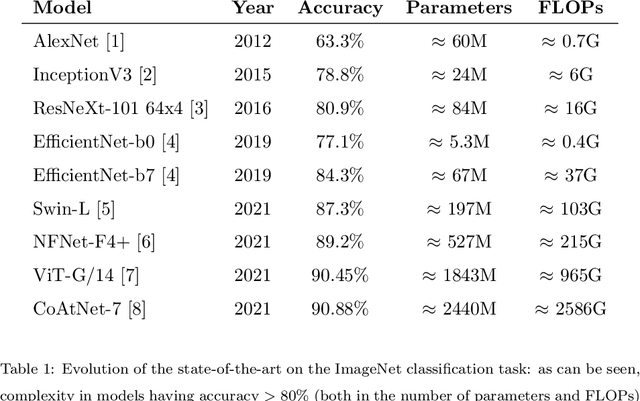
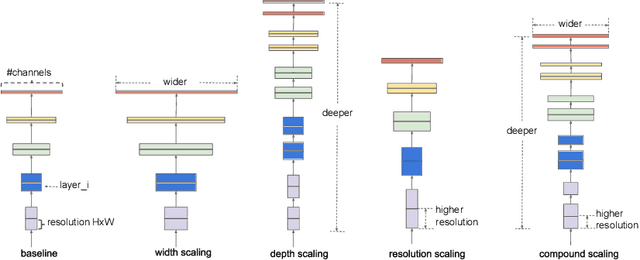
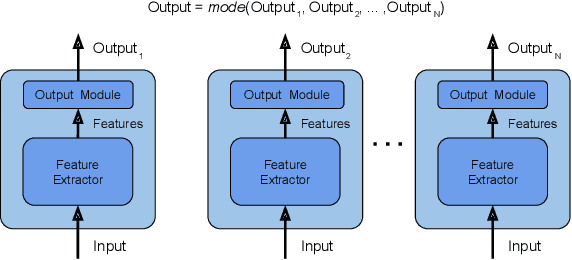
In recent times, except for sporadic cases, the trend in Computer Vision is to achieve minor improvements over considerable increases in complexity. To reverse this tendency, we propose a novel method to boost image classification performances without an increase in complexity. To this end, we revisited ensembling, a powerful approach, not often adequately used due to its nature of increased complexity and training time, making it viable by specific design choices. First, we trained end-to-end two EfficientNet-b0 models (known to be the architecture with the best overall accuracy/complexity trade-off in image classification) on disjoint subsets of data (i.e. bagging). Then, we made an efficient adaptive ensemble by performing fine-tuning of a trainable combination layer. In this way, we were able to outperform the state-of-the-art by an average of 0.5\% on the accuracy with restrained complexity both in terms of number of parameters (by 5-60 times), and FLoating point Operations Per Second (by 10-100 times) on several major benchmark datasets, fully embracing the green AI.
Reinforcement Learning in Medical Image Analysis: Concepts, Applications, Challenges, and Future Directions
Jun 28, 2022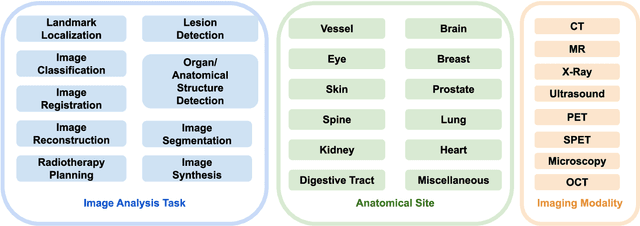
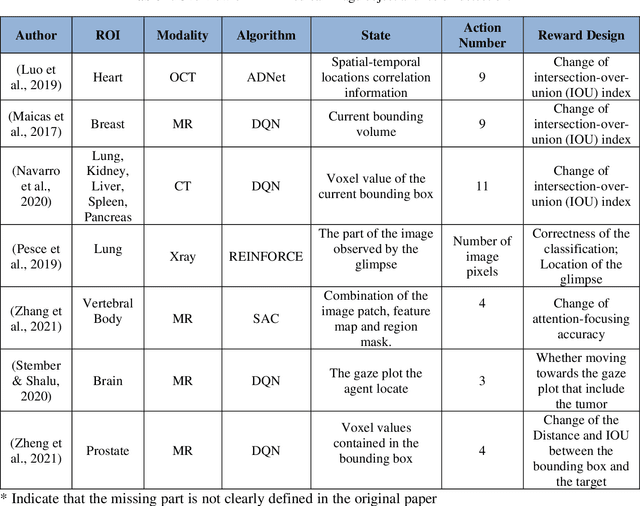
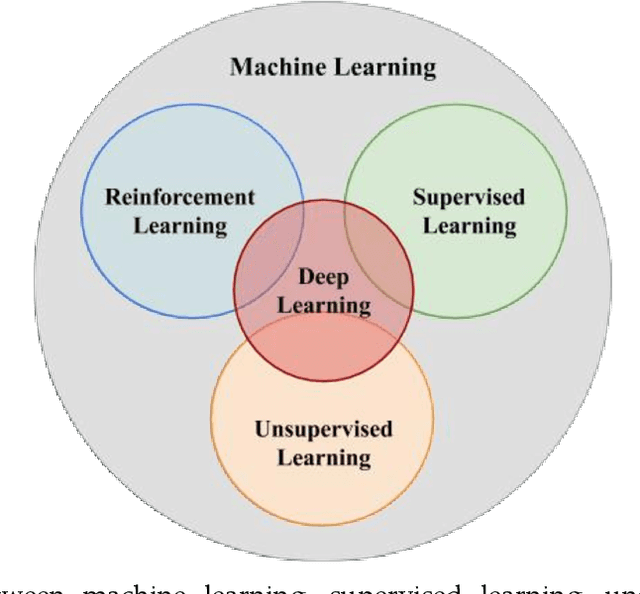
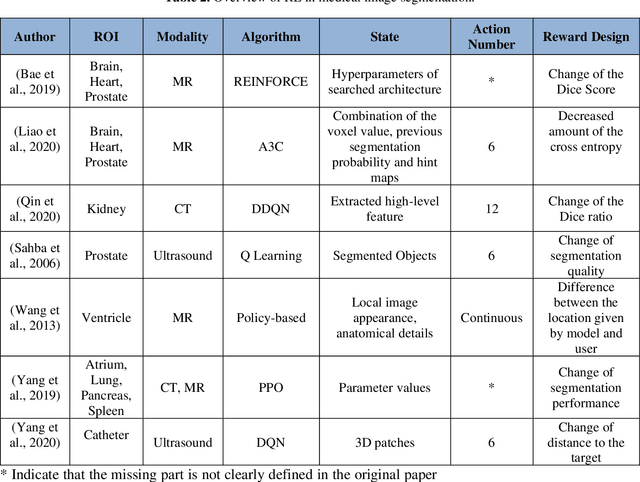
Motivation: Medical image analysis involves tasks to assist physicians in qualitative and quantitative analysis of lesions or anatomical structures, significantly improving the accuracy and reliability of diagnosis and prognosis. Traditionally, these tasks are finished by physicians or medical physicists and lead to two major problems: (i) low efficiency; (ii) biased by personal experience. In the past decade, many machine learning methods have been applied to accelerate and automate the image analysis process. Compared to the enormous deployments of supervised and unsupervised learning models, attempts to use reinforcement learning in medical image analysis are scarce. This review article could serve as the stepping-stone for related research. Significance: From our observation, though reinforcement learning has gradually gained momentum in recent years, many researchers in the medical analysis field find it hard to understand and deploy in clinics. One cause is lacking well-organized review articles targeting readers lacking professional computer science backgrounds. Rather than providing a comprehensive list of all reinforcement learning models in medical image analysis, this paper may help the readers to learn how to formulate and solve their medical image analysis research as reinforcement learning problems. Approach & Results: We selected published articles from Google Scholar and PubMed. Considering the scarcity of related articles, we also included some outstanding newest preprints. The papers are carefully reviewed and categorized according to the type of image analysis task. We first review the basic concepts and popular models of reinforcement learning. Then we explore the applications of reinforcement learning models in landmark detection. Finally, we conclude the article by discussing the reviewed reinforcement learning approaches' limitations and possible improvements.
CNN-Based Action Recognition and Pose Estimation for Classifying Animal Behavior from Videos: A Survey
Jan 15, 2023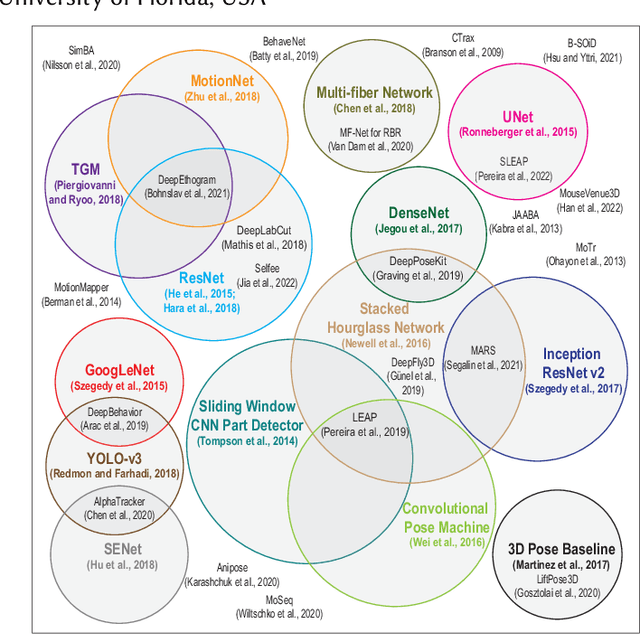
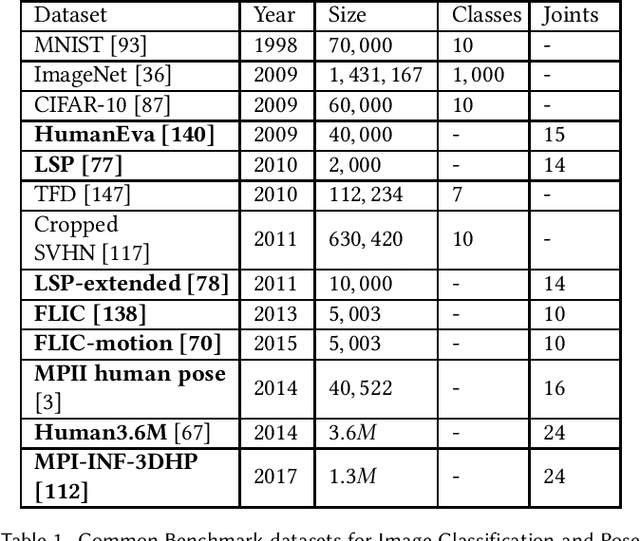

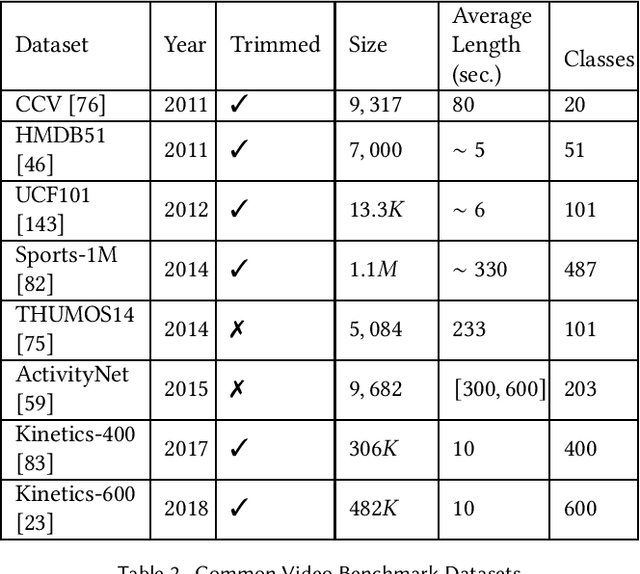
Classifying the behavior of humans or animals from videos is important in biomedical fields for understanding brain function and response to stimuli. Action recognition, classifying activities performed by one or more subjects in a trimmed video, forms the basis of many of these techniques. Deep learning models for human action recognition have progressed significantly over the last decade. Recently, there is an increased interest in research that incorporates deep learning-based action recognition for animal behavior classification. However, human action recognition methods are more developed. This survey presents an overview of human action recognition and pose estimation methods that are based on convolutional neural network (CNN) architectures and have been adapted for animal behavior classification in neuroscience. Pose estimation, estimating joint positions from an image frame, is included because it is often applied before classifying animal behavior. First, we provide foundational information on algorithms that learn spatiotemporal features through 2D, two-stream, and 3D CNNs. We explore motivating factors that determine optimizers, loss functions and training procedures, and compare their performance on benchmark datasets. Next, we review animal behavior frameworks that use or build upon these methods, organized by the level of supervision they require. Our discussion is uniquely focused on the technical evolution of the underlying CNN models and their architectural adaptations (which we illustrate), rather than their usability in a neuroscience lab. We conclude by discussing open research problems, and possible research directions. Our survey is designed to be a resource for researchers developing fully unsupervised animal behavior classification systems of which there are only a few examples in the literature.
Pluto's Surface Mapping using Unsupervised Learning from Near-Infrared Observations of LEISA/Ralph
Jan 15, 2023We map the surface of Pluto using an unsupervised machine learning technique using the near-infrared observations of the LEISA/Ralph instrument onboard NASA's New Horizons spacecraft. The principal component reduced Gaussian mixture model was implemented to investigate the geographic distribution of the surface units across the dwarf planet. We also present the likelihood of each surface unit at the image pixel level. Average I/F spectra of each unit were analyzed -- in terms of the position and strengths of absorption bands of abundant volatiles such as N${}_{2}$, CH${}_{4}$, and CO and nonvolatile H${}_{2}$O -- to connect the unit to surface composition, geology, and geographic location. The distribution of surface units shows a latitudinal pattern with distinct surface compositions of volatiles -- consistent with the existing literature. However, previous mapping efforts were based primarily on compositional analysis using spectral indices (indicators) or implementation of complex radiative transfer models, which need (prior) expert knowledge, label data, or optical constants of representative endmembers. We prove that an application of unsupervised learning in this instance renders a satisfactory result in mapping the spatial distribution of ice compositions without any prior information or label data. Thus, such an application is specifically advantageous for a planetary surface mapping when label data are poorly constrained or completely unknown, because an understanding of surface material distribution is vital for volatile transport modeling at the planetary scale. We emphasize that the unsupervised learning used in this study has wide applicability and can be expanded to other planetary bodies of the Solar System for mapping surface material distribution.
Identifying Spurious Correlations and Correcting them with an Explanation-based Learning
Nov 15, 2022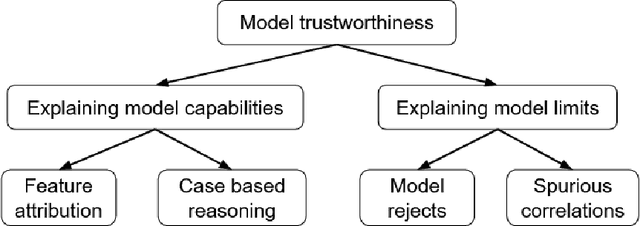
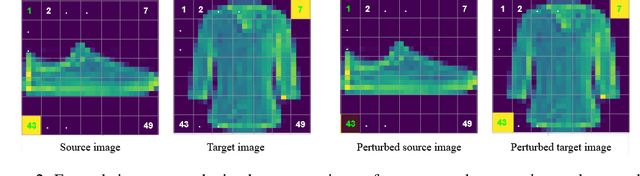
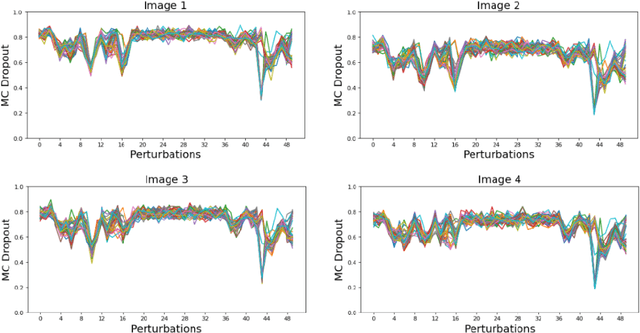
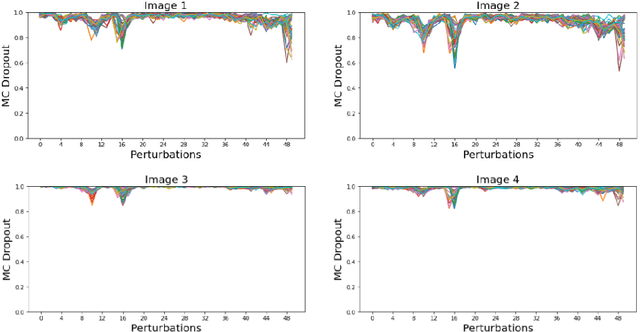
Identifying spurious correlations learned by a trained model is at the core of refining a trained model and building a trustworthy model. We present a simple method to identify spurious correlations that have been learned by a model trained for image classification problems. We apply image-level perturbations and monitor changes in certainties of predictions made using the trained model. We demonstrate this approach using an image classification dataset that contains images with synthetically generated spurious regions and show that the trained model was overdependent on spurious regions. Moreover, we remove the learned spurious correlations with an explanation based learning approach.
AtomVision: A machine vision library for atomistic images
Dec 05, 2022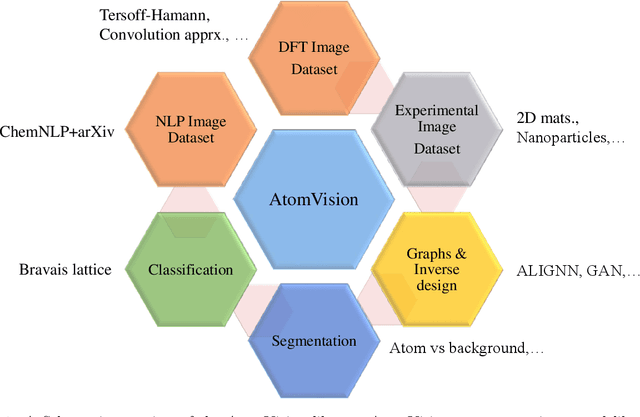
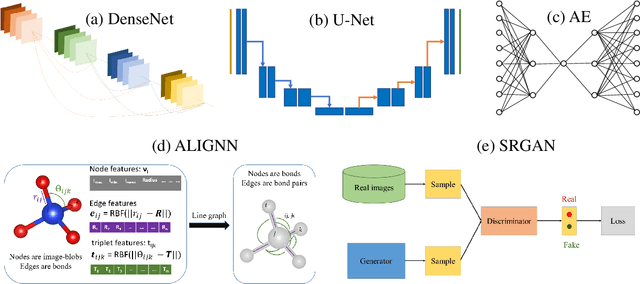
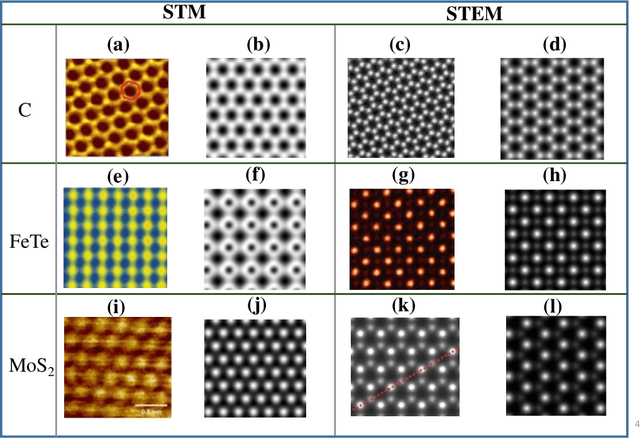
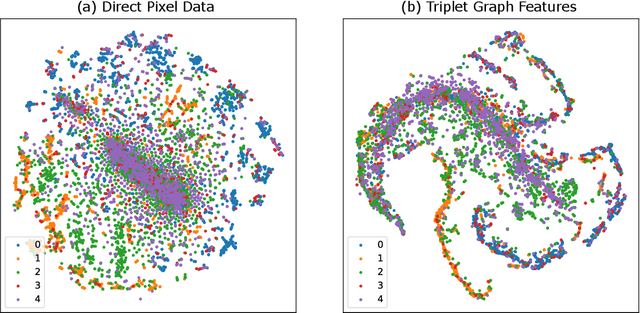
Computer vision techniques have immense potential for materials design applications. In this work, we introduce an integrated and general-purpose AtomVision library that can be used to generate, curate scanning tunneling microscopy (STM) and scanning transmission electron microscopy (STEM) datasets and apply machine learning techniques. To demonstrate the applicability of this library, we 1) generate and curate an atomistic image dataset of about 10000 materials, 2) develop and compare convolutional and graph neural network models to classify the Bravais lattices, 3) develop fully convolutional neural network using U-Net architecture to pixelwise classify atom vs background, 4) use generative adversarial network for super-resolution, 5) curate a natural language processing based image dataset using open-access arXiv dataset, and 6) integrate the computational framework with experimental microscopy tools. AtomVision library is available at https://github.com/usnistgov/atomvision.
Traditional Classification Neural Networks are Good Generators: They are Competitive with DDPMs and GANs
Nov 27, 2022

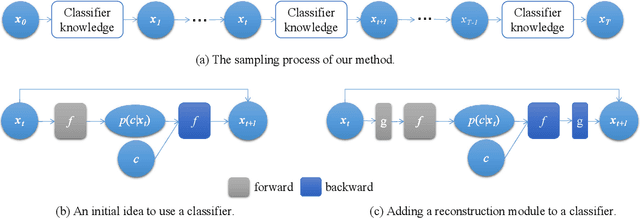
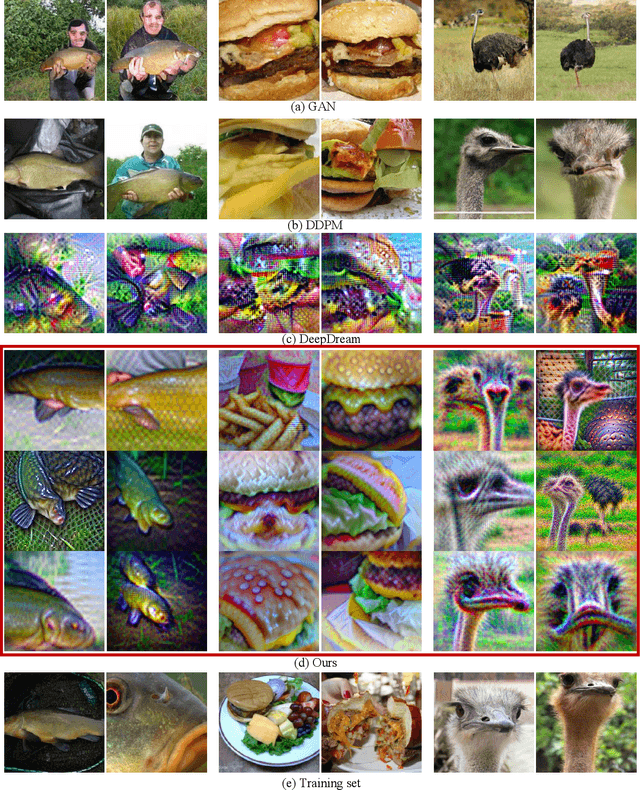
Classifiers and generators have long been separated. We break down this separation and showcase that conventional neural network classifiers can generate high-quality images of a large number of categories, being comparable to the state-of-the-art generative models (e.g., DDPMs and GANs). We achieve this by computing the partial derivative of the classification loss function with respect to the input to optimize the input to produce an image. Since it is widely known that directly optimizing the inputs is similar to targeted adversarial attacks incapable of generating human-meaningful images, we propose a mask-based stochastic reconstruction module to make the gradients semantic-aware to synthesize plausible images. We further propose a progressive-resolution technique to guarantee fidelity, which produces photorealistic images. Furthermore, we introduce a distance metric loss and a non-trivial distribution loss to ensure classification neural networks can synthesize diverse and high-fidelity images. Using traditional neural network classifiers, we can generate good-quality images of 256$\times$256 resolution on ImageNet. Intriguingly, our method is also applicable to text-to-image generation by regarding image-text foundation models as generalized classifiers. Proving that classifiers have learned the data distribution and are ready for image generation has far-reaching implications, for classifiers are much easier to train than generative models like DDPMs and GANs. We don't even need to train classification models because tons of public ones are available for download. Also, this holds great potential for the interpretability and robustness of classifiers.
Robust Reflection Removal with Flash-only Cues in the Wild
Nov 05, 2022


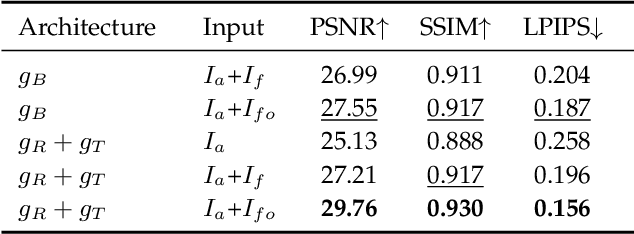
We propose a simple yet effective reflection-free cue for robust reflection removal from a pair of flash and ambient (no-flash) images. The reflection-free cue exploits a flash-only image obtained by subtracting the ambient image from the corresponding flash image in raw data space. The flash-only image is equivalent to an image taken in a dark environment with only a flash on. This flash-only image is visually reflection-free and thus can provide robust cues to infer the reflection in the ambient image. Since the flash-only image usually has artifacts, we further propose a dedicated model that not only utilizes the reflection-free cue but also avoids introducing artifacts, which helps accurately estimate reflection and transmission. Our experiments on real-world images with various types of reflection demonstrate the effectiveness of our model with reflection-free flash-only cues: our model outperforms state-of-the-art reflection removal approaches by more than 5.23dB in PSNR. We extend our approach to handheld photography to address the misalignment between the flash and no-flash pair. With misaligned training data and the alignment module, our aligned model outperforms our previous version by more than 3.19dB in PSNR on a misaligned dataset. We also study using linear RGB images as training data. Our source code and dataset are publicly available at https://github.com/ChenyangLEI/flash-reflection-removal.