 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SEVEN: Pruning Transformer Model by Reserving Sentinels
Mar 19, 2024
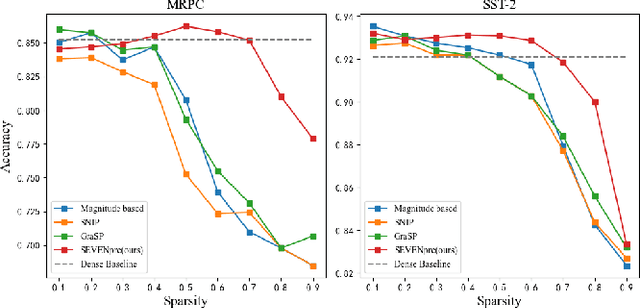
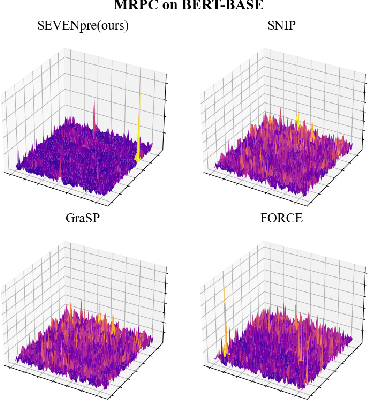
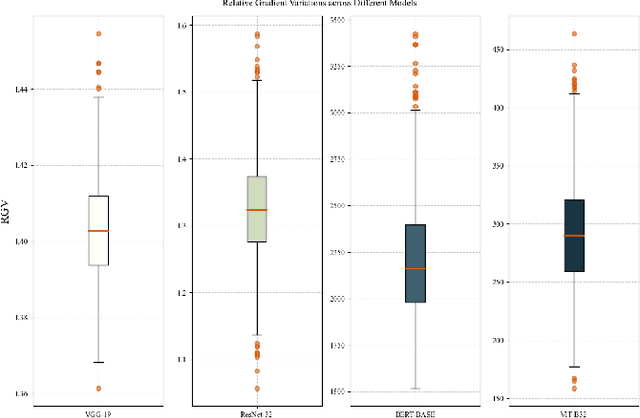
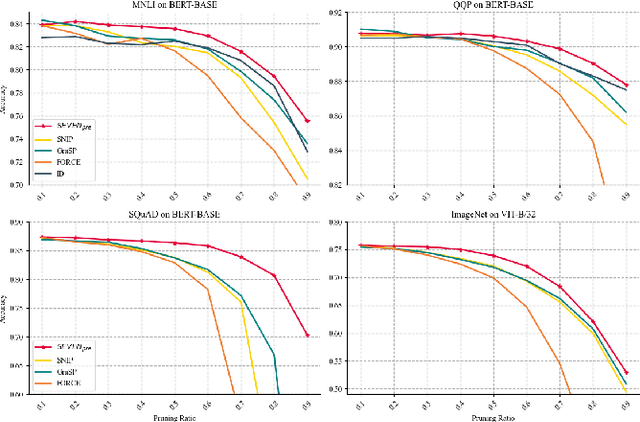
Large-scale Transformer models (TM) have demonstrated outstanding performance across various tasks. However, their considerable parameter size restricts their applicability, particularly on mobile devices. Due to the dynamic and intricate nature of gradients on TM compared to Convolutional Neural Networks, commonly used pruning methods tend to retain weights with larger gradient noise. This results in pruned models that are sensitive to sparsity and datasets, exhibiting suboptimal performance. Symbolic Descent (SD) is a general approach for training and fine-tuning TM. In this paper, we attempt to describe the noisy batch gradient sequences on TM through the cumulative process of SD. We utilize this design to dynamically assess the importance scores of weights.SEVEN is introduced by us, which particularly favors weights with consistently high sensitivity, i.e., weights with small gradient noise. These weights are tended to be preserved by SEVEN. Extensive experiments on various TM in natural language, question-answering, and image classification domains are conducted to validate the effectiveness of SEVEN. The results demonstrate significant improvements of SEVEN in multiple pruning scenarios and across different sparsity levels. Additionally, SEVEN exhibits robust performance under various fine-tuning strategies. The code is publicly available at https://github.com/xiaojinying/SEVEN.
Better Call SAL: Towards Learning to Segment Anything in Lidar
Mar 19, 2024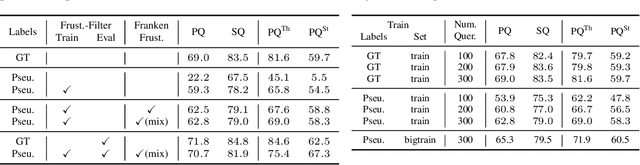
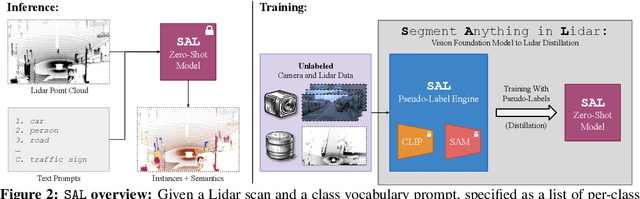
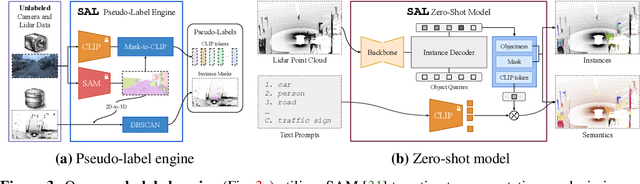

We propose $\texttt{SAL}$ ($\texttt{S}$egment $\texttt{A}$nything in $\texttt{L}$idar) method consisting of a text-promptable zero-shot model for segmenting and classifying any object in Lidar, and a pseudo-labeling engine that facilitates model training without manual supervision. While the established paradigm for $\textit{Lidar Panoptic Segmentation}$ (LPS) relies on manual supervision for a handful of object classes defined a priori, we utilize 2D vision foundation models to generate 3D supervision "for free". Our pseudo-labels consist of instance masks and corresponding CLIP tokens, which we lift to Lidar using calibrated multi-modal data. By training our model on these labels, we distill the 2D foundation models into our Lidar $\texttt{SAL}$ model. Even without manual labels, our model achieves $91\%$ in terms of class-agnostic segmentation and $44\%$ in terms of zero-shot LPS of the fully supervised state-of-the-art. Furthermore, we outperform several baselines that do not distill but only lift image features to 3D. More importantly, we demonstrate that $\texttt{SAL}$ supports arbitrary class prompts, can be easily extended to new datasets, and shows significant potential to improve with increasing amounts of self-labeled data.
Exploring Facial Expression Recognition through Semi-Supervised Pretraining and Temporal Modeling
Mar 19, 2024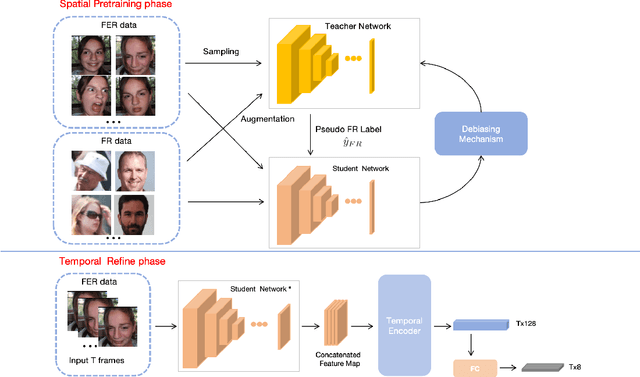

Facial Expression Recognition (FER) plays a crucial role in computer vision and finds extensive applications across various fields. This paper aims to present our approach for the upcoming 6th Affective Behavior Analysis in-the-Wild (ABAW) competition, scheduled to be held at CVPR2024. In the facial expression recognition task, The limited size of the FER dataset poses a challenge to the expression recognition model's generalization ability, resulting in subpar recognition performance. To address this problem, we employ a semi-supervised learning technique to generate expression category pseudo-labels for unlabeled face data. At the same time, we uniformly sampled the labeled facial expression samples and implemented a debiased feedback learning strategy to address the problem of category imbalance in the dataset and the possible data bias in semi-supervised learning. Moreover, to further compensate for the limitation and bias of features obtained only from static images, we introduced a Temporal Encoder to learn and capture temporal relationships between neighbouring expression image features. In the 6th ABAW competition, our method achieved outstanding results on the official validation set, a result that fully confirms the effectiveness and competitiveness of our proposed method.
Video Editing via Factorized Diffusion Distillation
Mar 14, 2024
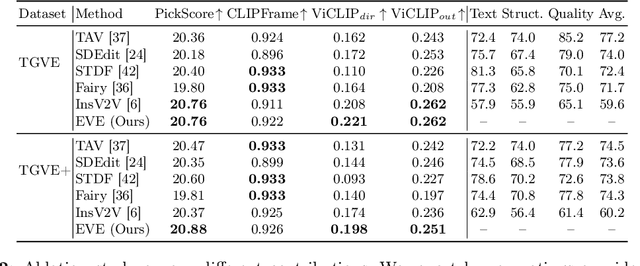
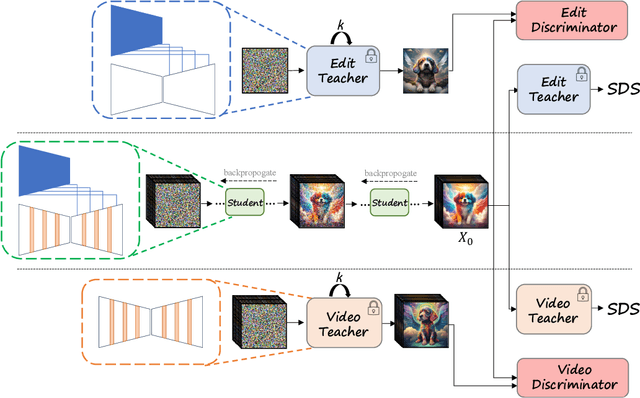
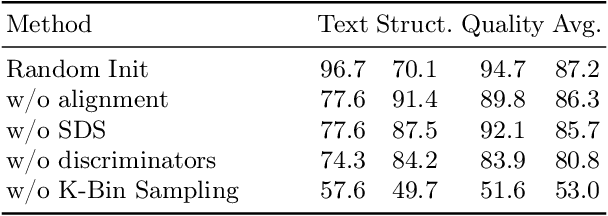
We introduce Emu Video Edit (EVE), a model that establishes a new state-of-the art in video editing without relying on any supervised video editing data. To develop EVE we separately train an image editing adapter and a video generation adapter, and attach both to the same text-to-image model. Then, to align the adapters towards video editing we introduce a new unsupervised distillation procedure, Factorized Diffusion Distillation. This procedure distills knowledge from one or more teachers simultaneously, without any supervised data. We utilize this procedure to teach EVE to edit videos by jointly distilling knowledge to (i) precisely edit each individual frame from the image editing adapter, and (ii) ensure temporal consistency among the edited frames using the video generation adapter. Finally, to demonstrate the potential of our approach in unlocking other capabilities, we align additional combinations of adapters
BraSyn 2023 challenge: Missing MRI synthesis and the effect of different learning objectives
Mar 12, 2024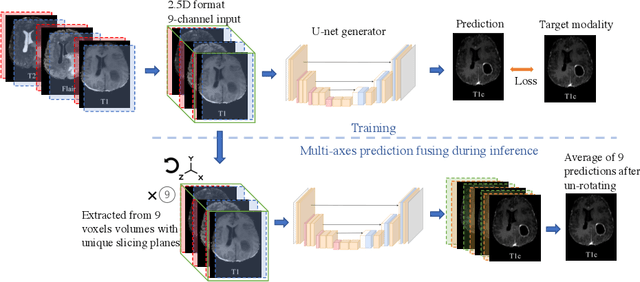
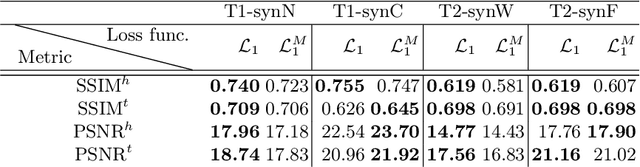
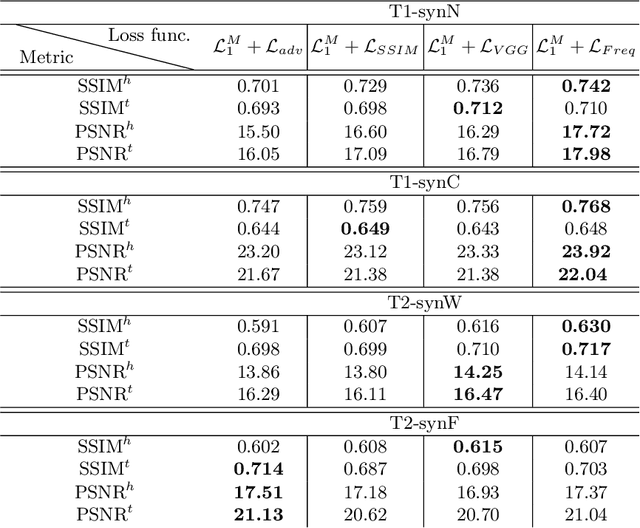
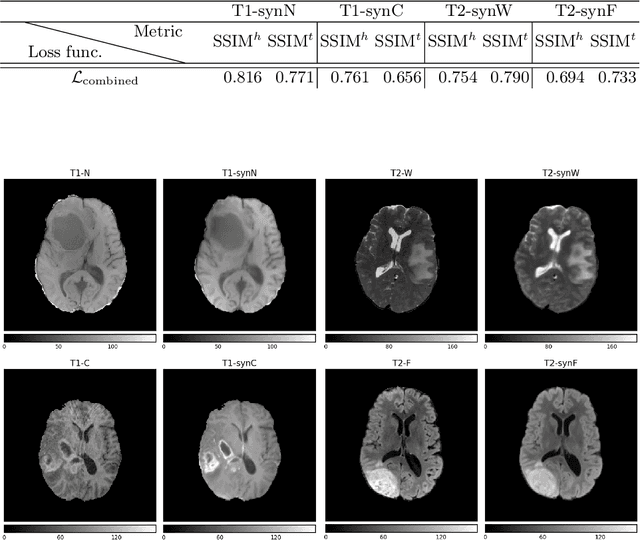
This work is addressing the Brain Magnetic Resonance Image Synthesis for Tumor Segmentation (BraSyn) challenge which was hosted as part of the Brain Tumor Segmentation challenge (BraTS) 2023. In this challenge researchers are invited to work on synthesizing a missing magnetic resonance image sequence given other available sequences to facilitate tumor segmentation pipelines trained on complete sets of image sequences. This problem can be addressed using deep learning in the framework of paired images-to-image translation. In this work, we proposed to investigate the effectiveness of a commonly-used deep learning framework such as Pix2Pix trained under supervision of different image-quality loss functions. Our results indicate that using different loss functions significantly affects the synthesis quality. We systematically study the impact of different loss functions in the multi-sequence MR image synthesis setting of the BraSyn challenge. Furthermore, we show how image synthesis performance can be optimized by beneficially combining different learning objectives.
Modeling the Label Distributions for Weakly-Supervised Semantic Segmentation
Mar 20, 2024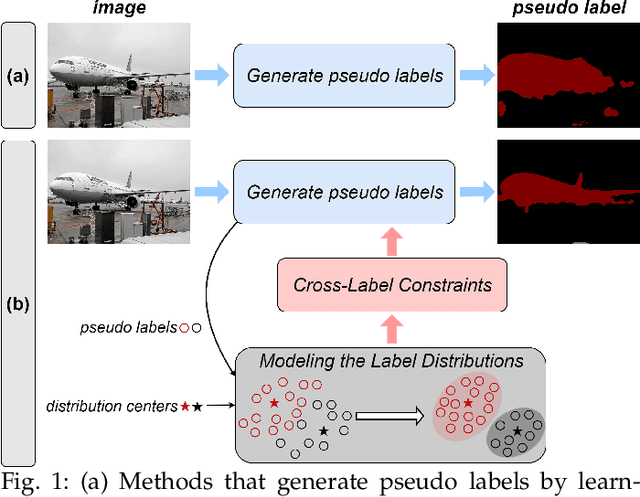
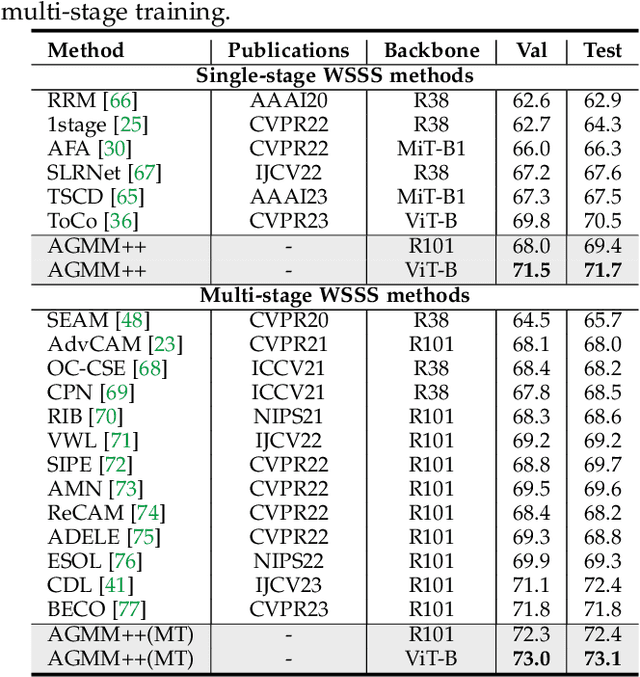
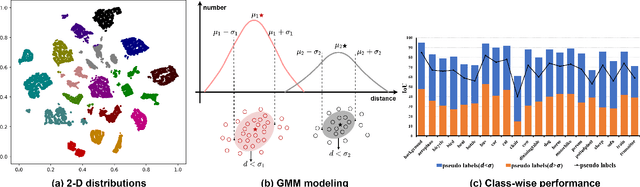
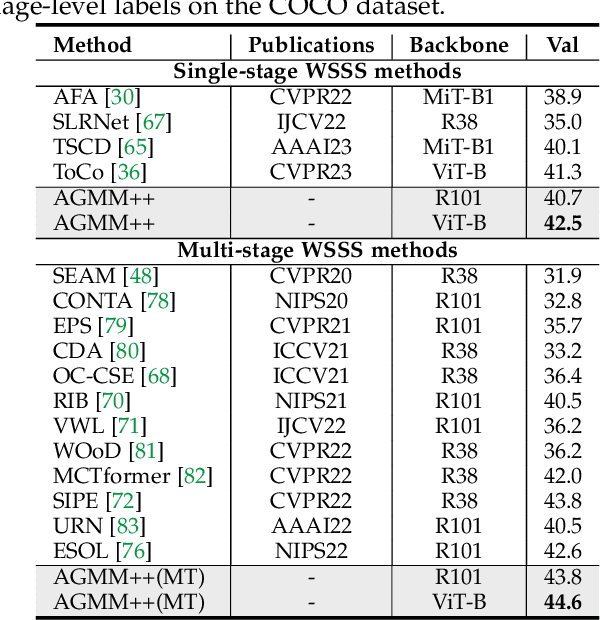
Weakly-Supervised Semantic Segmentation (WSSS) aims to train segmentation models by weak labels, which is receiving significant attention due to its low annotation cost. Existing approaches focus on generating pseudo labels for supervision while largely ignoring to leverage the inherent semantic correlation among different pseudo labels. We observe that pseudo-labeled pixels that are close to each other in the feature space are more likely to share the same class, and those closer to the distribution centers tend to have higher confidence. Motivated by this, we propose to model the underlying label distributions and employ cross-label constraints to generate more accurate pseudo labels. In this paper, we develop a unified WSSS framework named Adaptive Gaussian Mixtures Model, which leverages a GMM to model the label distributions. Specifically, we calculate the feature distribution centers of pseudo-labeled pixels and build the GMM by measuring the distance between the centers and each pseudo-labeled pixel. Then, we introduce an Online Expectation-Maximization (OEM) algorithm and a novel maximization loss to optimize the GMM adaptively, aiming to learn more discriminative decision boundaries between different class-wise Gaussian mixtures. Based on the label distributions, we leverage the GMM to generate high-quality pseudo labels for more reliable supervision. Our framework is capable of solving different forms of weak labels: image-level labels, points, scribbles, blocks, and bounding-boxes. Extensive experiments on PASCAL, COCO, Cityscapes, and ADE20K datasets demonstrate that our framework can effectively provide more reliable supervision and outperform the state-of-the-art methods under all settings. Code will be available at https://github.com/Luffy03/AGMM-SASS.
Region-Adaptive Transform with Segmentation Prior for Image Compression
Mar 01, 2024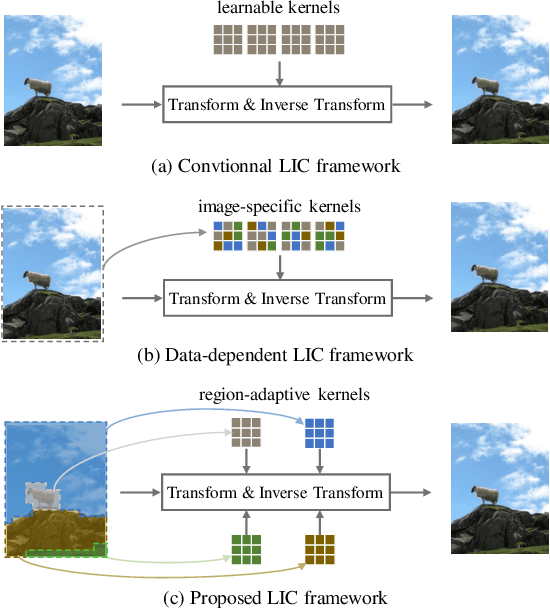
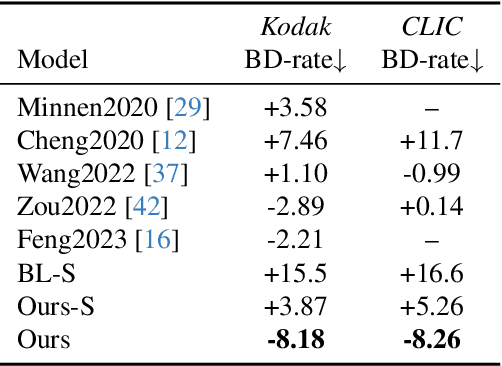
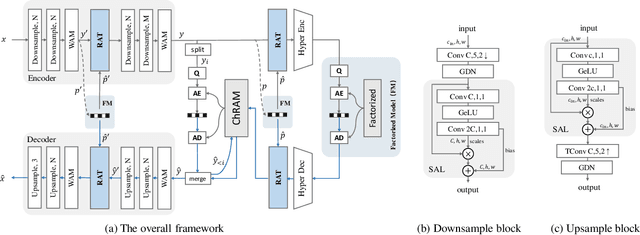
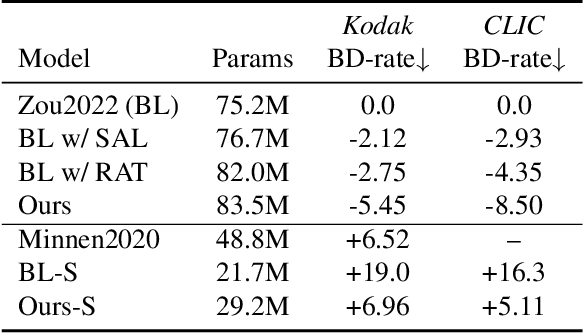
Learned Image Compression (LIC) has shown remarkable progress in recent years. Existing works commonly employ CNN-based or self-attention-based modules as transform methods for compression. However, there is no prior research on neural transform that focuses on specific regions. In response, we introduce the class-agnostic segmentation masks (i.e. semantic masks without category labels) for extracting region-adaptive contextual information. Our proposed module, Region-Adaptive Transform, applies adaptive convolutions on different regions guided by the masks. Additionally, we introduce a plug-and-play module named Scale Affine Layer to incorporate rich contexts from various regions. While there have been prior image compression efforts that involve segmentation masks as additional intermediate inputs, our approach differs significantly from them. Our advantages lie in that, to avoid extra bitrate overhead, we treat these masks as privilege information, which is accessible during the model training stage but not required during the inference phase. To the best of our knowledge, we are the first to employ class-agnostic masks as privilege information and achieve superior performance in pixel-fidelity metrics, such as Peak Signal to Noise Ratio (PSNR). The experimental results demonstrate our improvement compared to previously well-performing methods, with about 8.2% bitrate saving compared to VTM-17.0. The code will be released at https://github.com/GityuxiLiu/Region-Adaptive-Transform-with-Segmentation-Prior-for-Image-Compression.
InTeX: Interactive Text-to-texture Synthesis via Unified Depth-aware Inpainting
Mar 18, 2024
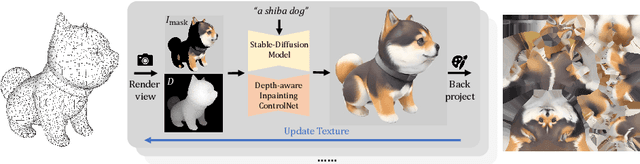


Text-to-texture synthesis has become a new frontier in 3D content creation thanks to the recent advances in text-to-image models. Existing methods primarily adopt a combination of pretrained depth-aware diffusion and inpainting models, yet they exhibit shortcomings such as 3D inconsistency and limited controllability. To address these challenges, we introduce InteX, a novel framework for interactive text-to-texture synthesis. 1) InteX includes a user-friendly interface that facilitates interaction and control throughout the synthesis process, enabling region-specific repainting and precise texture editing. 2) Additionally, we develop a unified depth-aware inpainting model that integrates depth information with inpainting cues, effectively mitigating 3D inconsistencies and improving generation speed. Through extensive experiments, our framework has proven to be both practical and effective in text-to-texture synthesis, paving the way for high-quality 3D content creation.
End-To-End Underwater Video Enhancement: Dataset and Model
Mar 18, 2024
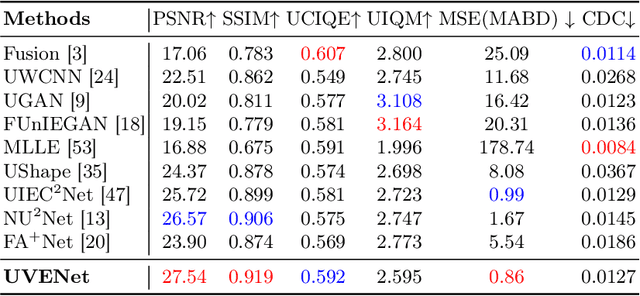
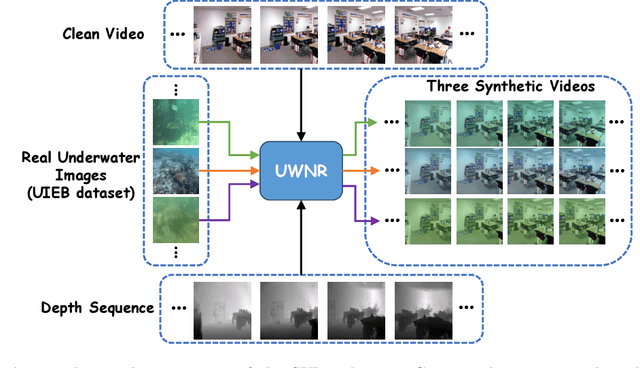
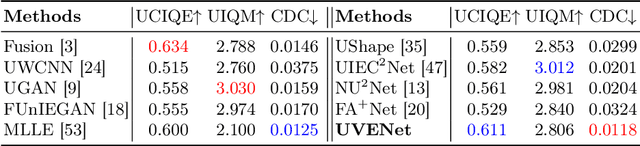
Underwater video enhancement (UVE) aims to improve the visibility and frame quality of underwater videos, which has significant implications for marine research and exploration. However, existing methods primarily focus on developing image enhancement algorithms to enhance each frame independently. There is a lack of supervised datasets and models specifically tailored for UVE tasks. To fill this gap, we construct the Synthetic Underwater Video Enhancement (SUVE) dataset, comprising 840 diverse underwater-style videos paired with ground-truth reference videos. Based on this dataset, we train a novel underwater video enhancement model, UVENet, which utilizes inter-frame relationships to achieve better enhancement performance. Through extensive experiments on both synthetic and real underwater videos, we demonstrate the effectiveness of our approach. This study represents the first comprehensive exploration of UVE to our knowledge. The code is available at https://anonymous.4open.science/r/UVENet.
VIGFace: Virtual Identity Generation Model for Face Image Synthesis
Mar 13, 2024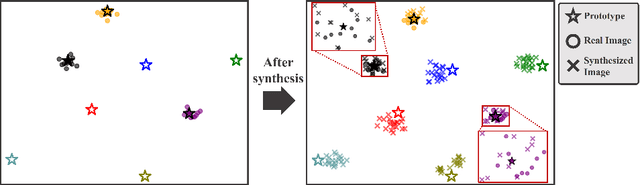

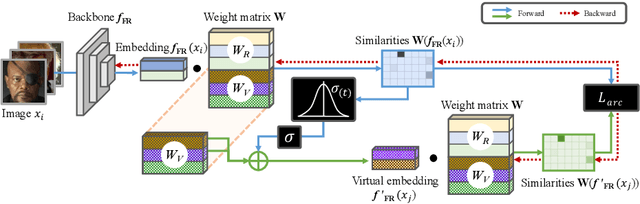
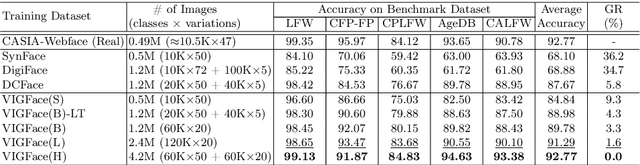
Deep learning-based face recognition continues to face challenges due to its reliance on huge datasets obtained from web crawling, which can be costly to gather and raise significant real-world privacy concerns. To address this issue, we propose VIGFace, a novel framework capable of generating synthetic facial images. Initially, we train the face recognition model using a real face dataset and create a feature space for both real and virtual IDs where virtual prototypes are orthogonal to other prototypes. Subsequently, we generate synthetic images by using the diffusion model based on the feature space. Our proposed framework provides two significant benefits. Firstly, it allows for creating virtual facial images without concerns about portrait rights, guaranteeing that the generated virtual face images are clearly differentiated from existing individuals. Secondly, it serves as an effective augmentation method by incorporating real existing images. Further experiments demonstrate the efficacy of our framework, achieving state-of-the-art results from both perspectives without any external data.