 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DiffusionInst: Diffusion Model for Instance Segmentation
Dec 07, 2022
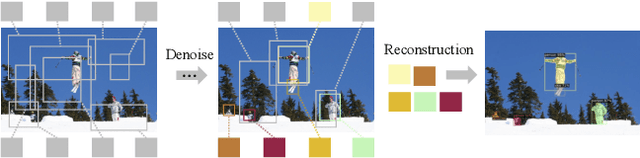
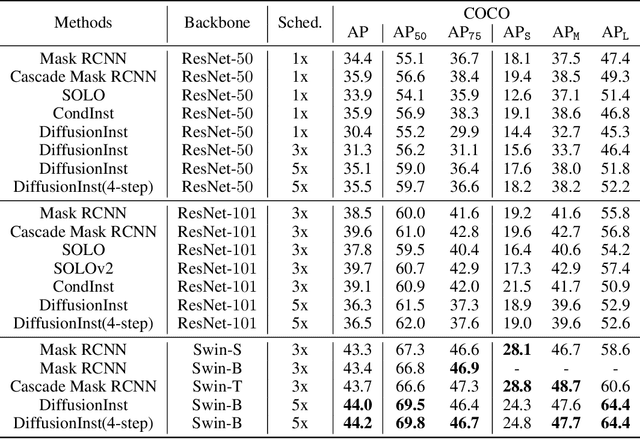
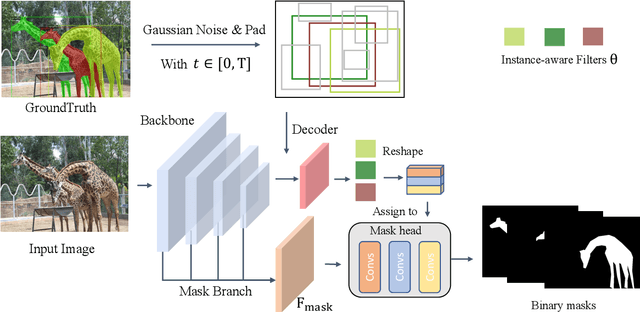
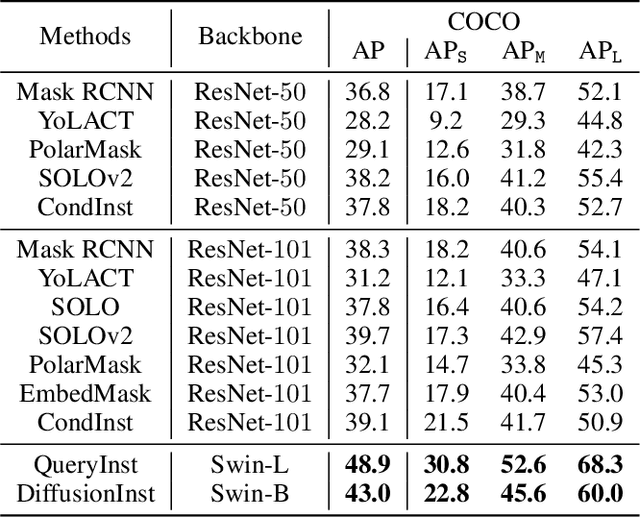
Recently, diffusion frameworks have achieved comparable performance with previous state-of-the-art image generation models. Researchers are curious about its variants in discriminative tasks because of its powerful noise-to-image denoising pipeline. This paper proposes DiffusionInst, a novel framework that represents instances as instance-aware filters and formulates instance segmentation as a noise-to-filter denoising process. The model is trained to reverse the noisy groundtruth without any inductive bias from RPN. During inference, it takes a randomly generated filter as input and outputs mask in one-step or multi-step denoising. Extensive experimental results on COCO and LVIS show that DiffusionInst achieves competitive performance compared to existing instance segmentation models. We hope our work could serve as a simple yet effective baseline, which could inspire designing more efficient diffusion frameworks for challenging discriminative tasks. Our code is available in https://github.com/chenhaoxing/DiffusionInst.
An Electromagnetic-Information-Theory Based Model for Efficient Characterization of MIMO Systems in Complex Space
Jan 13, 2023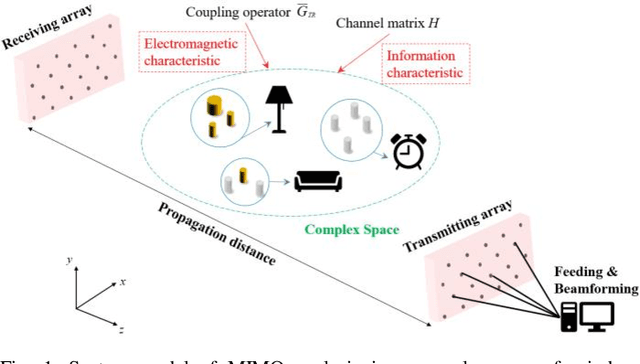
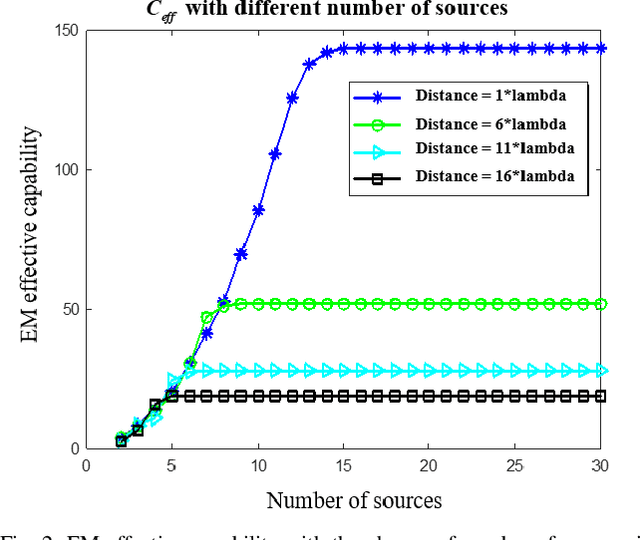
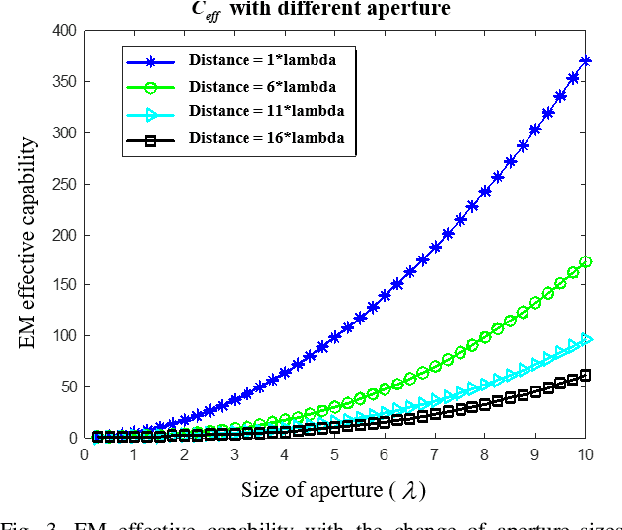
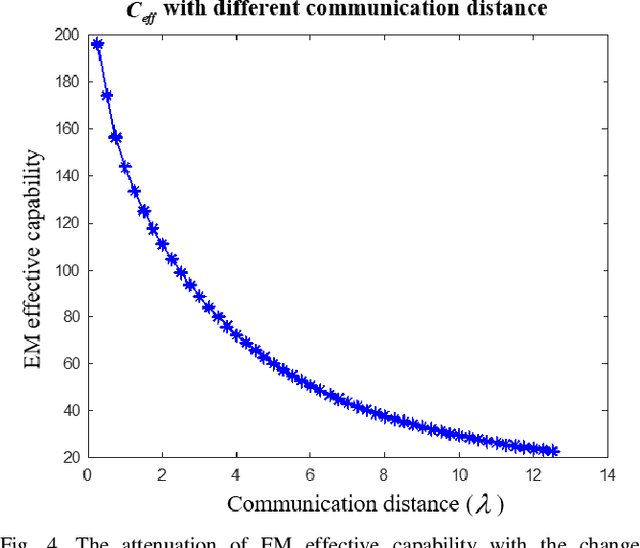
It is the pursuit of a multiple-input-multiple-output (MIMO) system to approach and even break the limit of channel capacity. However, it is always a big challenge to efficiently characterize the MIMO systems in complex space and get better propagation performance than the conventional MIMO systems considering only free space, which is important for guiding the power and phase allocation of antenna units. In this manuscript, an Electromagnetic-Information-Theory (EMIT) based model is developed for efficient characterization of MIMO systems in complex space. The group-T-matrix-based multiple scattering fast algorithm, the mode-decomposition-based characterization method, and their joint theoretical framework in complex space are discussed. Firstly, key informatics parameters in free electromagnetic space based on a dyadic Green's function are derived. Next, a novel group-T-matrix-based multiple scattering fast algorithm is developed to describe a representative inhomogeneous electromagnetic space. All the analytical results are validated by simulations. In addition, the complete form of the EMIT-based model is proposed to derive the informatics parameters frequently used in electromagnetic propagation, through integrating the mode analysis method with the dyadic Green's function matrix. Finally, as a proof-or-concept, microwave anechoic chamber measurements of a cylindrical array is performed, demonstrating the effectiveness of the EMIT-based model. Meanwhile, a case of image transmission with limited power is presented to illustrate how to use this EMIT-based model to guide the power and phase allocation of antenna units for real MIMO applications.
* 13 pages, 14 figures
Learning to Perceive in Deep Model-Free Reinforcement Learning
Jan 13, 2023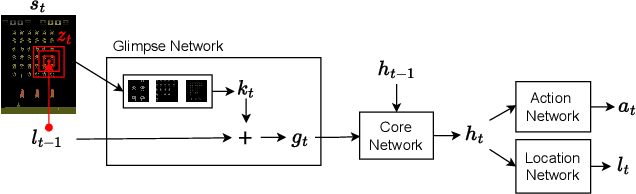

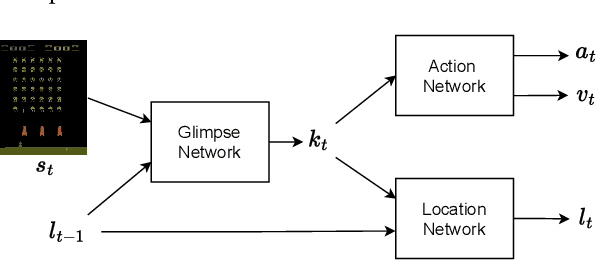
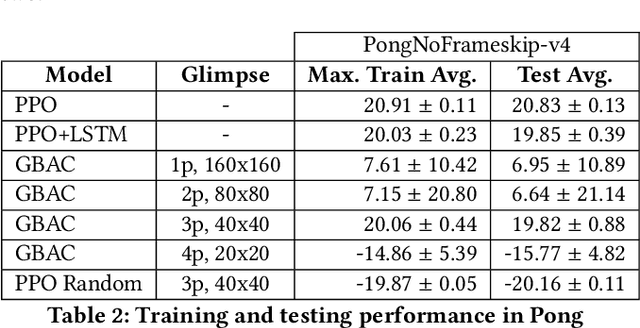
This work proposes a novel model-free Reinforcement Learning (RL) agent that is able to learn how to complete an unknown task having access to only a part of the input observation. We take inspiration from the concepts of visual attention and active perception that are characteristic of humans and tried to apply them to our agent, creating a hard attention mechanism. In this mechanism, the model decides first which region of the input image it should look at, and only after that it has access to the pixels of that region. Current RL agents do not follow this principle and we have not seen these mechanisms applied to the same purpose as this work. In our architecture, we adapt an existing model called recurrent attention model (RAM) and combine it with the proximal policy optimization (PPO) algorithm. We investigate whether a model with these characteristics is capable of achieving similar performance to state-of-the-art model-free RL agents that access the full input observation. This analysis is made in two Atari games, Pong and SpaceInvaders, which have a discrete action space, and in CarRacing, which has a continuous action space. Besides assessing its performance, we also analyze the movement of the attention of our model and compare it with what would be an example of the human behavior. Even with such visual limitation, we show that our model matches the performance of PPO+LSTM in two of the three games tested.
Explainable, Physics Aware, Trustworthy AI Paradigm Shift for Synthetic Aperture Radar
Jan 09, 2023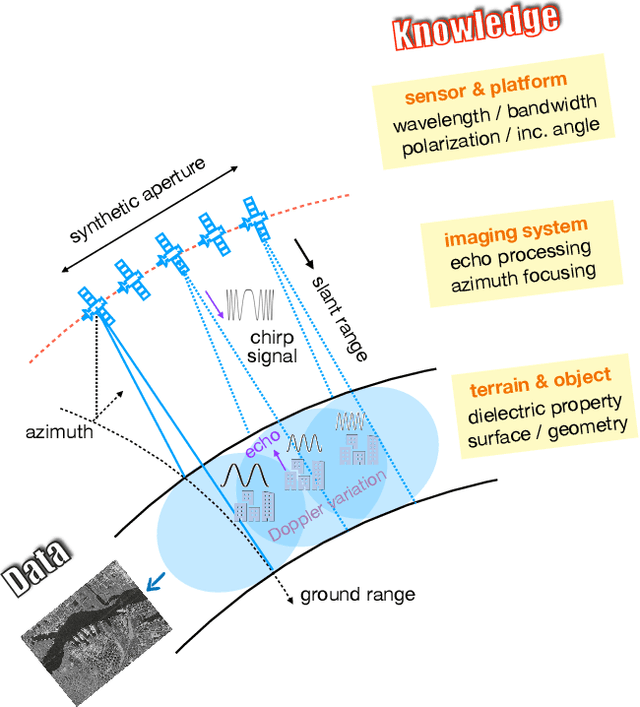
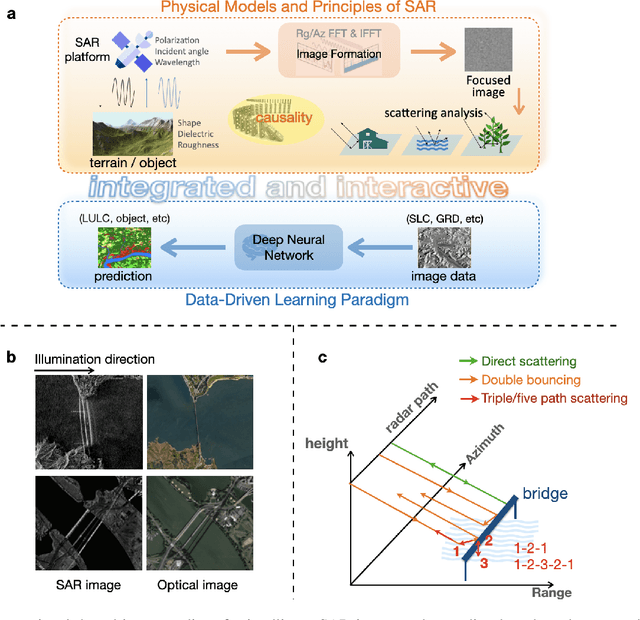
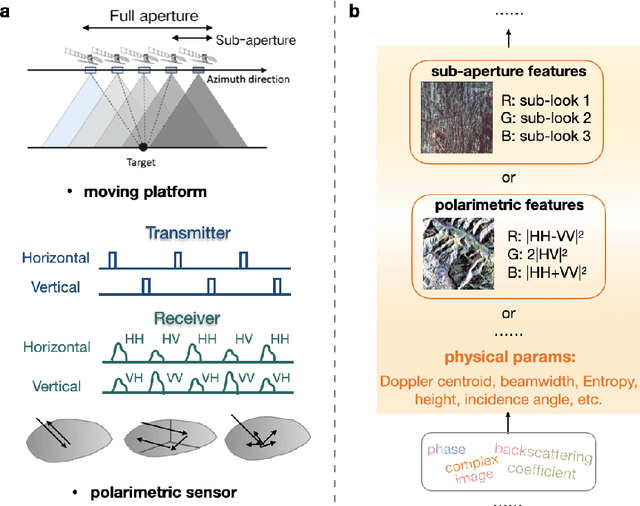
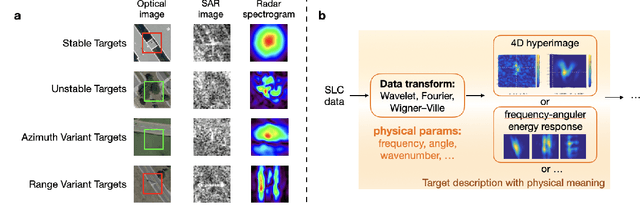
The recognition or understanding of the scenes observed with a SAR system requires a broader range of cues, beyond the spatial context. These encompass but are not limited to: imaging geometry, imaging mode, properties of the Fourier spectrum of the images or the behavior of the polarimetric signatures. In this paper, we propose a change of paradigm for explainability in data science for the case of Synthetic Aperture Radar (SAR) data to ground the explainable AI for SAR. It aims to use explainable data transformations based on well-established models to generate inputs for AI methods, to provide knowledgeable feedback for training process, and to learn or improve high-complexity unknown or un-formalized models from the data. At first, we introduce a representation of the SAR system with physical layers: i) instrument and platform, ii) imaging formation, iii) scattering signatures and objects, that can be integrated with an AI model for hybrid modeling. Successively, some illustrative examples are presented to demonstrate how to achieve hybrid modeling for SAR image understanding. The perspective of trustworthy model and supplementary explanations are discussed later. Finally, we draw the conclusion and we deem the proposed concept has applicability to the entire class of coherent imaging sensors and other computational imaging systems.
Towards Real-Time Panoptic Narrative Grounding by an End-to-End Grounding Network
Jan 09, 2023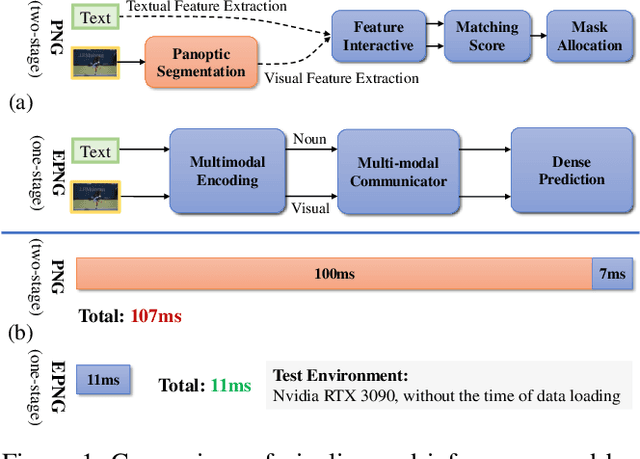

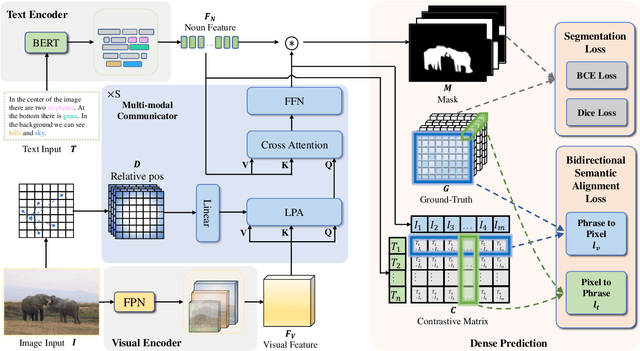
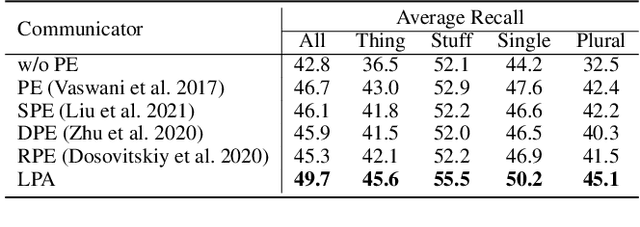
Panoptic Narrative Grounding (PNG) is an emerging cross-modal grounding task, which locates the target regions of an image corresponding to the text description. Existing approaches for PNG are mainly based on a two-stage paradigm, which is computationally expensive. In this paper, we propose a one-stage network for real-time PNG, termed End-to-End Panoptic Narrative Grounding network (EPNG), which directly generates masks for referents. Specifically, we propose two innovative designs, i.e., Locality-Perceptive Attention (LPA) and a bidirectional Semantic Alignment Loss (SAL), to properly handle the many-to-many relationship between textual expressions and visual objects. LPA embeds the local spatial priors into attention modeling, i.e., a pixel may belong to multiple masks at different scales, thereby improving segmentation. To help understand the complex semantic relationships, SAL proposes a bidirectional contrastive objective to regularize the semantic consistency inter modalities. Extensive experiments on the PNG benchmark dataset demonstrate the effectiveness and efficiency of our method. Compared to the single-stage baseline, our method achieves a significant improvement of up to 9.4% accuracy. More importantly, our EPNG is 10 times faster than the two-stage model. Meanwhile, the generalization ability of EPNG is also validated by zero-shot experiments on other grounding tasks.
Nearest Neighbor-Based Contrastive Learning for Hyperspectral and LiDAR Data Classification
Jan 09, 2023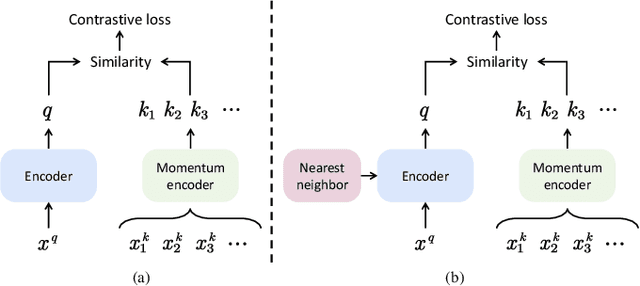
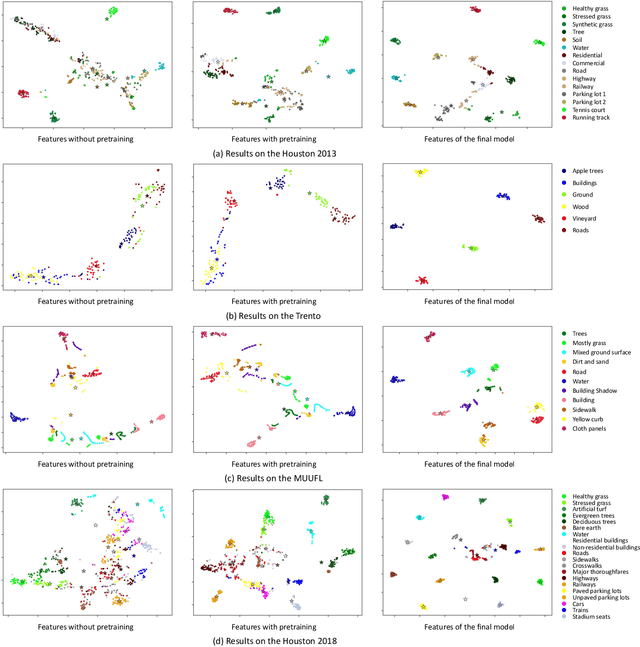
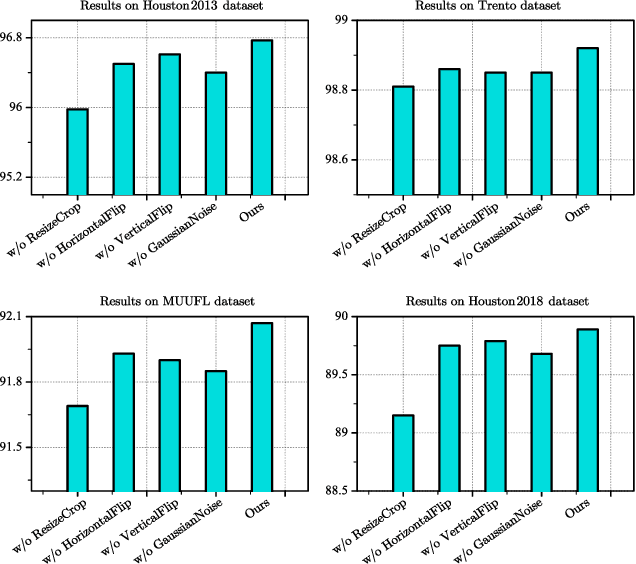
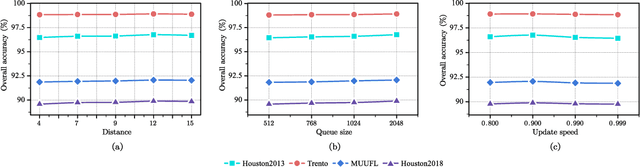
The joint hyperspectral image (HSI) and LiDAR data classification aims to interpret ground objects at more detailed and precise level. Although deep learning methods have shown remarkable success in the multisource data classification task, self-supervised learning has rarely been explored. It is commonly nontrivial to build a robust self-supervised learning model for multisource data classification, due to the fact that the semantic similarities of neighborhood regions are not exploited in existing contrastive learning framework. Furthermore, the heterogeneous gap induced by the inconsistent distribution of multisource data impedes the classification performance. To overcome these disadvantages, we propose a Nearest Neighbor-based Contrastive Learning Network (NNCNet), which takes full advantage of large amounts of unlabeled data to learn discriminative feature representations. Specifically, we propose a nearest neighbor-based data augmentation scheme to use enhanced semantic relationships among nearby regions. The intermodal semantic alignments can be captured more accurately. In addition, we design a bilinear attention module to exploit the second-order and even high-order feature interactions between the HSI and LiDAR data. Extensive experiments on four public datasets demonstrate the superiority of our NNCNet over state-of-the-art methods. The source codes are available at \url{https://github.com/summitgao/NNCNet}.
CM-MLP: Cascade Multi-scale MLP with Axial Context Relation Encoder for Edge Segmentation of Medical Image
Aug 23, 2022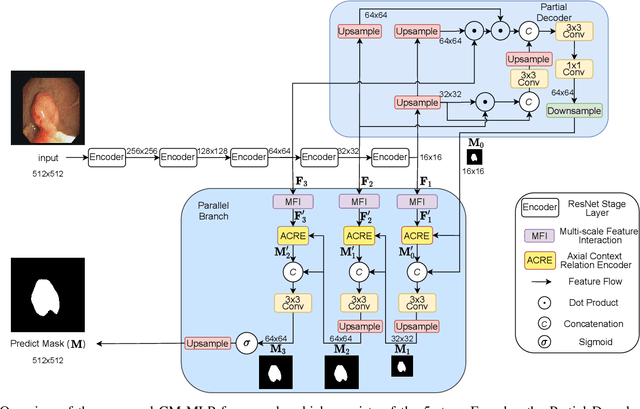
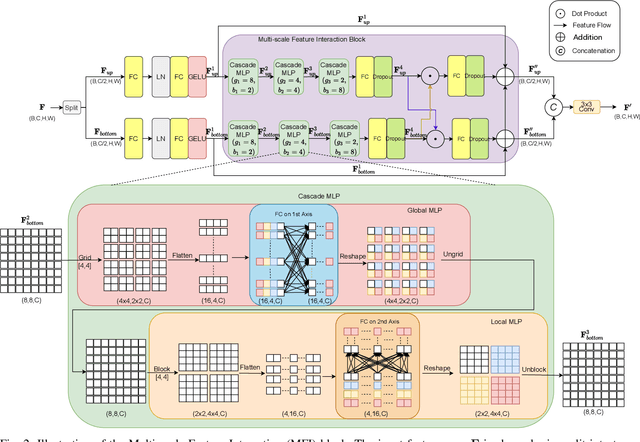
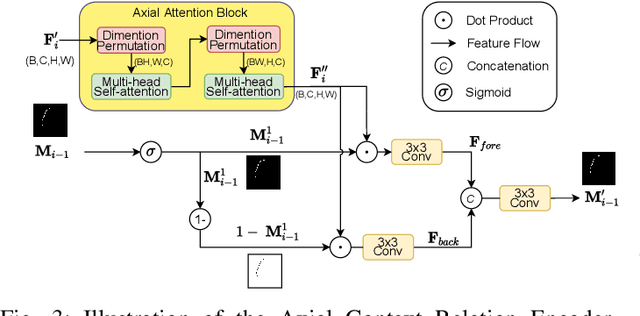
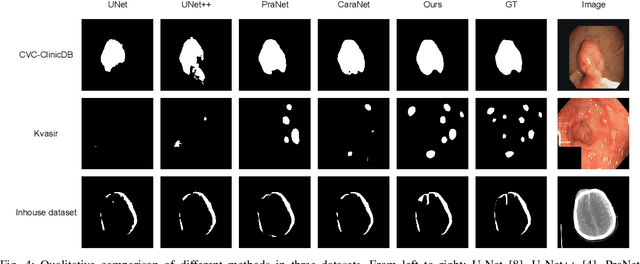
The convolutional-based methods provide good segmentation performance in the medical image segmentation task. However, those methods have the following challenges when dealing with the edges of the medical images: (1) Previous convolutional-based methods do not focus on the boundary relationship between foreground and background around the segmentation edge, which leads to the degradation of segmentation performance when the edge changes complexly. (2) The inductive bias of the convolutional layer cannot be adapted to complex edge changes and the aggregation of multiple-segmented areas, resulting in its performance improvement mostly limited to segmenting the body of segmented areas instead of the edge. To address these challenges, we propose the CM-MLP framework on MFI (Multi-scale Feature Interaction) block and ACRE (Axial Context Relation Encoder) block for accurate segmentation of the edge of medical image. In the MFI block, we propose the cascade multi-scale MLP (Cascade MLP) to process all local information from the deeper layers of the network simultaneously and utilize a cascade multi-scale mechanism to fuse discrete local information gradually. Then, the ACRE block is used to make the deep supervision focus on exploring the boundary relationship between foreground and background to modify the edge of the medical image. The segmentation accuracy (Dice) of our proposed CM-MLP framework reaches 96.96%, 96.76%, and 82.54% on three benchmark datasets: CVC-ClinicDB dataset, sub-Kvasir dataset, and our in-house dataset, respectively, which significantly outperform the state-of-the-art method. The source code and trained models will be available at https://github.com/ProgrammerHyy/CM-MLP.
CAT: Learning to Collaborate Channel and Spatial Attention from Multi-Information Fusion
Dec 13, 2022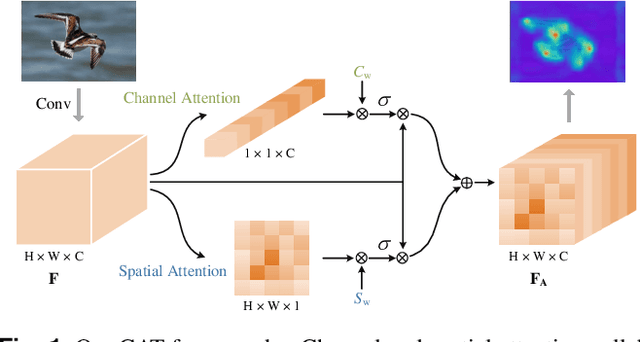
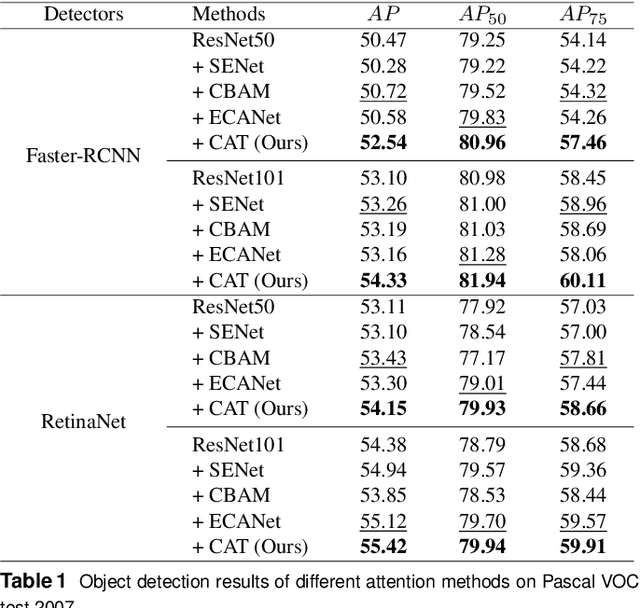
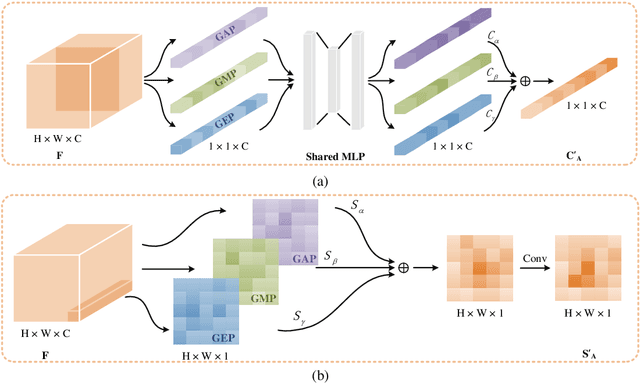
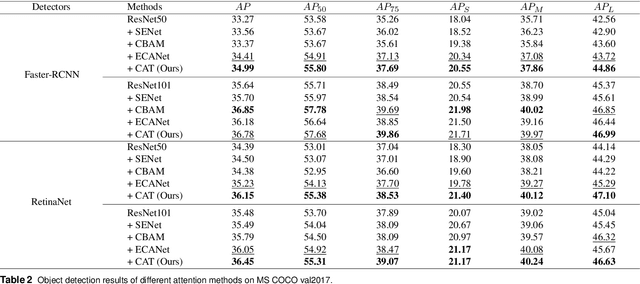
Channel and spatial attention mechanism has proven to provide an evident performance boost of deep convolution neural networks (CNNs). Most existing methods focus on one or run them parallel (series), neglecting the collaboration between the two attentions. In order to better establish the feature interaction between the two types of attention, we propose a plug-and-play attention module, which we term "CAT"-activating the Collaboration between spatial and channel Attentions based on learned Traits. Specifically, we represent traits as trainable coefficients (i.e., colla-factors) to adaptively combine contributions of different attention modules to fit different image hierarchies and tasks better. Moreover, we propose the global entropy pooling (GEP) apart from global average pooling (GAP) and global maximum pooling (GMP) operators, an effective component in suppressing noise signals by measuring the information disorder of feature maps. We introduce a three-way pooling operation into attention modules and apply the adaptive mechanism to fuse their outcomes. Extensive experiments on MS COCO, Pascal-VOC, Cifar-100, and ImageNet show that our CAT outperforms existing state-of-the-art attention mechanisms in object detection, instance segmentation, and image classification. The model and code will be released soon.
* 8 pages, 5 figures
DialogCC: Large-Scale Multi-Modal Dialogue Dataset
Dec 08, 2022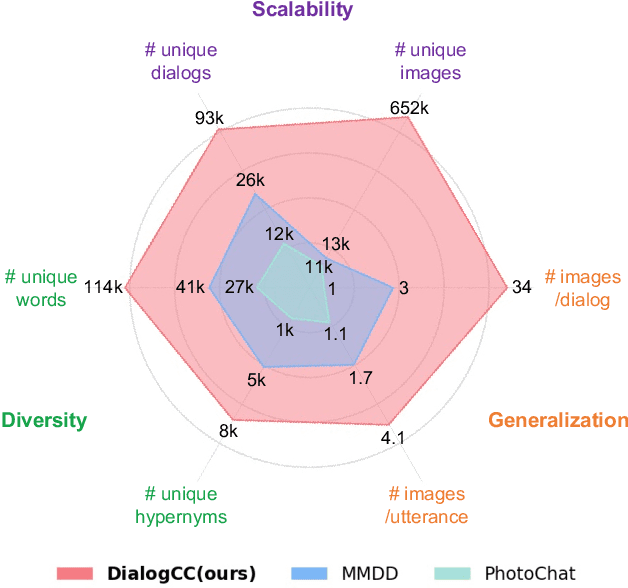
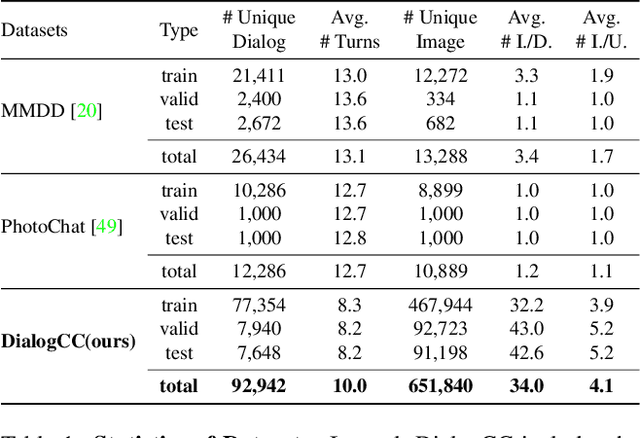
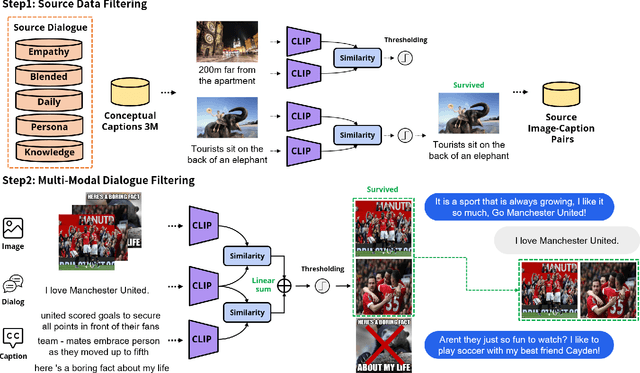
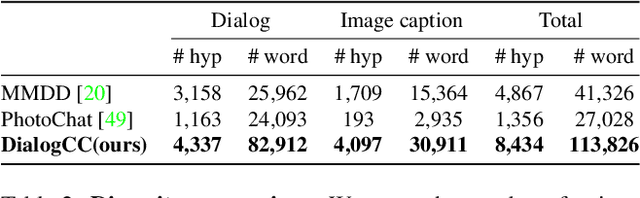
As sharing images in an instant message is a crucial factor, there has been active research on learning a image-text multi-modal dialogue model. However, training a well-generalized multi-modal dialogue model is challenging because existing multi-modal dialogue datasets contain a small number of data, limited topics, and a restricted variety of images per dialogue. In this paper, we present a multi-modal dialogue dataset creation pipeline that involves matching large-scale images to dialogues based on CLIP similarity. Using this automatic pipeline, we propose a large-scale multi-modal dialogue dataset, DialogCC, which covers diverse real-world topics and various images per dialogue. With extensive experiments, we demonstrate that training a multi-modal dialogue model with our dataset can improve generalization performance. Additionally, existing models trained with our dataset achieve state-of-the-art performance on image and text retrieval tasks. The source code and the dataset will be released after publication.
NRTR: Neuron Reconstruction with Transformer from 3D Optical Microscopy Images
Dec 08, 2022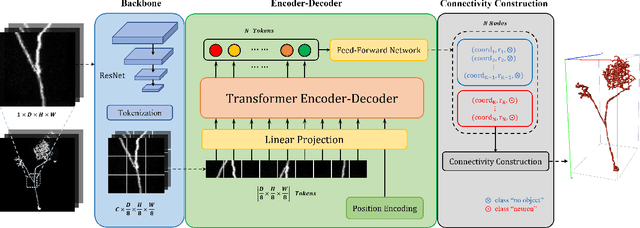
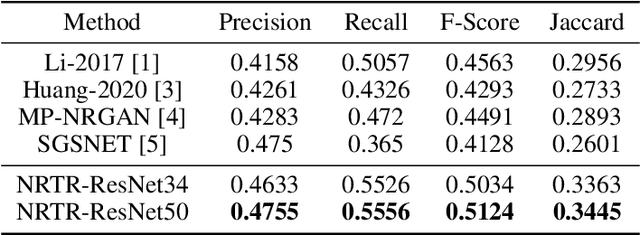
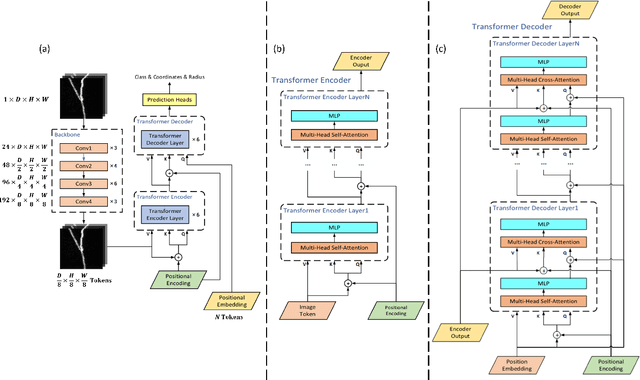
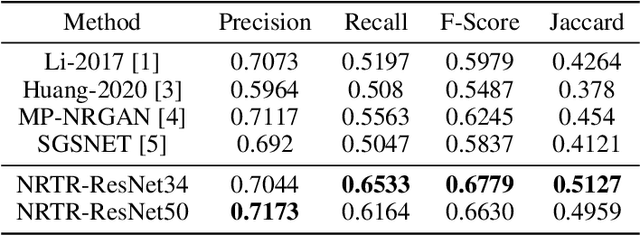
The neuron reconstruction from raw Optical Microscopy (OM) image stacks is the basis of neuroscience. Manual annotation and semi-automatic neuron tracing algorithms are time-consuming and inefficient. Existing deep learning neuron reconstruction methods, although demonstrating exemplary performance, greatly demand complex rule-based components. Therefore, a crucial challenge is designing an end-to-end neuron reconstruction method that makes the overall framework simpler and model training easier. We propose a Neuron Reconstruction Transformer (NRTR) that, discarding the complex rule-based components, views neuron reconstruction as a direct set-prediction problem. To the best of our knowledge, NRTR is the first image-to-set deep learning model for end-to-end neuron reconstruction. In experiments using the BigNeuron and VISoR-40 datasets, NRTR achieves excellent neuron reconstruction results for comprehensive benchmarks and outperforms competitive baselines. Results of extensive experiments indicate that NRTR is effective at showing that neuron reconstruction is viewed as a set-prediction problem, which makes end-to-end model training available.