 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DeepVoxNet2: Yet another CNN framework
Nov 17, 2022
We know that both the CNN mapping function and the sampling scheme are of paramount importance for CNN-based image analysis. It is clear that both functions operate in the same space, with an image axis $\mathcal{I}$ and a feature axis $\mathcal{F}$. Remarkably, we found that no frameworks existed that unified the two and kept track of the spatial origin of the data automatically. Based on our own practical experience, we found the latter to often result in complex coding and pipelines that are difficult to exchange. This article introduces our framework for 1, 2 or 3D image classification or segmentation: DeepVoxNet2 (DVN2). This article serves as an interactive tutorial, and a pre-compiled version, including the outputs of the code blocks, can be found online in the public DVN2 repository. This tutorial uses data from the multimodal Brain Tumor Image Segmentation Benchmark (BRATS) of 2018 to show an example of a 3D segmentation pipeline.
Automated Quantification of Traffic Particulate Emissions via an Image Analysis Pipeline
Nov 24, 2022
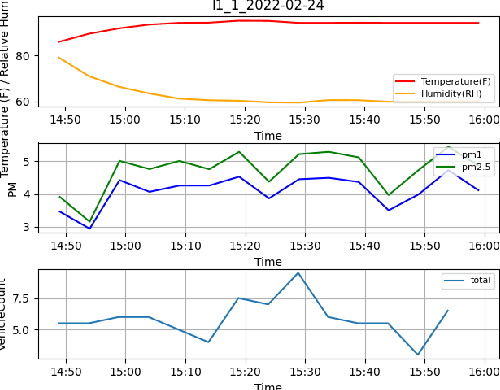
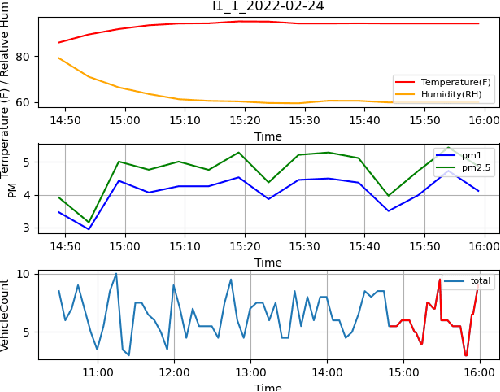
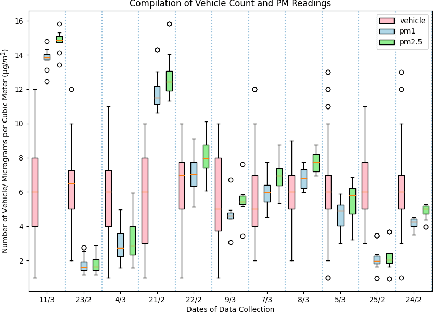
Traffic emissions are known to contribute significantly to air pollution around the world, especially in heavily urbanized cities such as Singapore. It has been previously shown that the particulate pollution along major roadways exhibit strong correlation with increased traffic during peak hours, and that reductions in traffic emissions can lead to better health outcomes. However, in many instances, obtaining proper counts of vehicular traffic remains manual and extremely laborious. This then restricts one's ability to carry out longitudinal monitoring for extended periods, for example, when trying to understand the efficacy of intervention measures such as new traffic regulations (e.g. car-pooling) or for computational modelling. Hence, in this study, we propose and implement an integrated machine learning pipeline that utilizes traffic images to obtain vehicular counts that can be easily integrated with other measurements to facilitate various studies. We verify the utility and accuracy of this pipeline on an open-source dataset of traffic images obtained for a location in Singapore and compare the obtained vehicular counts with collocated particulate measurement data obtained over a 2-week period in 2022. The roadside particulate emission is observed to correlate well with obtained vehicular counts with a correlation coefficient of 0.93, indicating that this method can indeed serve as a quick and effective correlate of particulate emissions.
Self-Supervised Clustering on Image-Subtracted Data with Deep-Embedded Self-Organizing Map
Sep 14, 2022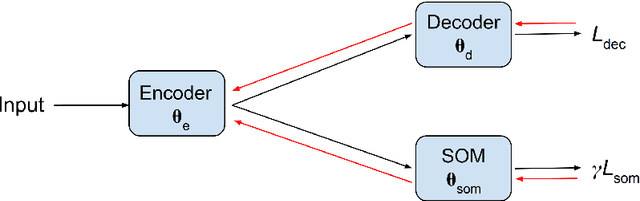

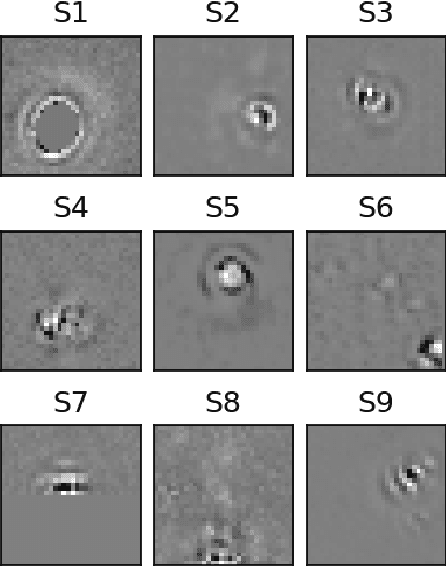

Developing an effective automatic classifier to separate genuine sources from artifacts is essential for transient follow-ups in wide-field optical surveys. The identification of transient detections from the subtraction artifacts after the image differencing process is a key step in such classifiers, known as real-bogus classification problem. We apply a self-supervised machine learning model, the deep-embedded self-organizing map (DESOM) to this "real-bogus" classification problem. DESOM combines an autoencoder and a self-organizing map to perform clustering in order to distinguish between real and bogus detections, based on their dimensionality-reduced representations. We use 32x32 normalized detection thumbnails as the input of DESOM. We demonstrate different model training approaches, and find that our best DESOM classifier shows a missed detection rate of 6.6% with a false positive rate of 1.5%. DESOM offers a more nuanced way to fine-tune the decision boundary identifying likely real detections when used in combination with other types of classifiers, for example built on neural networks or decision trees. We also discuss other potential usages of DESOM and its limitations.
An Electromagnetic-Information-Theory Based Model for Efficient Characterization of MIMO Systems in Complex Space
Jan 13, 2023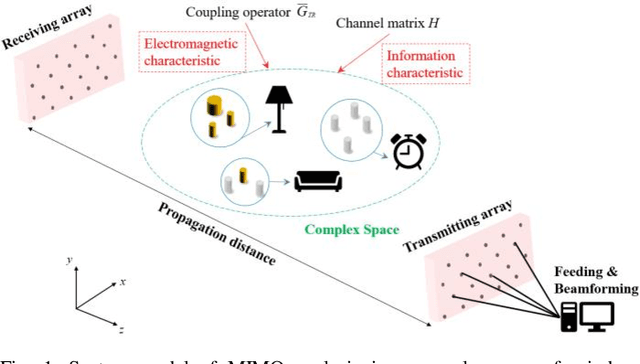
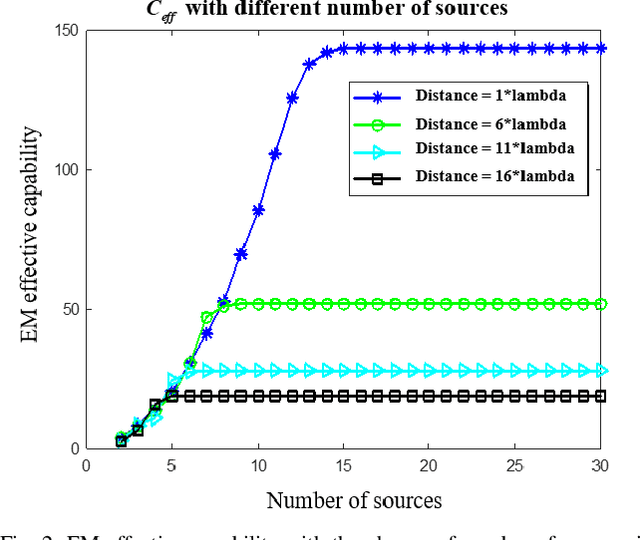
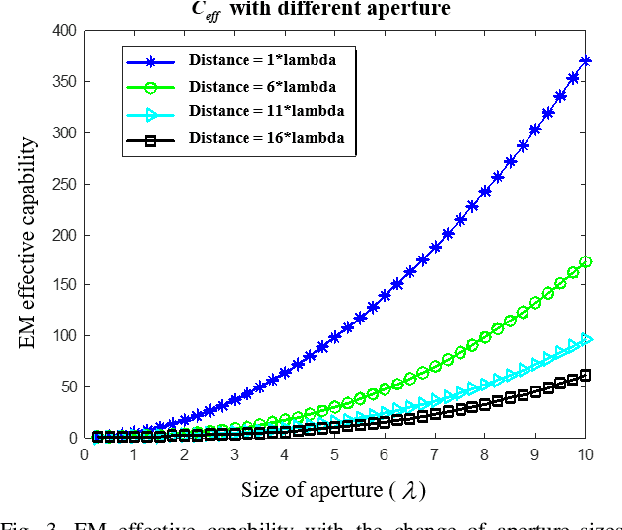
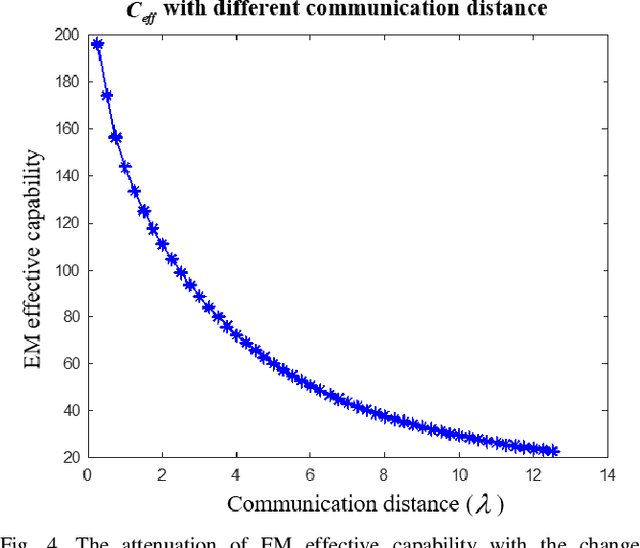
It is the pursuit of a multiple-input-multiple-output (MIMO) system to approach and even break the limit of channel capacity. However, it is always a big challenge to efficiently characterize the MIMO systems in complex space and get better propagation performance than the conventional MIMO systems considering only free space, which is important for guiding the power and phase allocation of antenna units. In this manuscript, an Electromagnetic-Information-Theory (EMIT) based model is developed for efficient characterization of MIMO systems in complex space. The group-T-matrix-based multiple scattering fast algorithm, the mode-decomposition-based characterization method, and their joint theoretical framework in complex space are discussed. Firstly, key informatics parameters in free electromagnetic space based on a dyadic Green's function are derived. Next, a novel group-T-matrix-based multiple scattering fast algorithm is developed to describe a representative inhomogeneous electromagnetic space. All the analytical results are validated by simulations. In addition, the complete form of the EMIT-based model is proposed to derive the informatics parameters frequently used in electromagnetic propagation, through integrating the mode analysis method with the dyadic Green's function matrix. Finally, as a proof-or-concept, microwave anechoic chamber measurements of a cylindrical array is performed, demonstrating the effectiveness of the EMIT-based model. Meanwhile, a case of image transmission with limited power is presented to illustrate how to use this EMIT-based model to guide the power and phase allocation of antenna units for real MIMO applications.
* 13 pages, 14 figures
Learning to Perceive in Deep Model-Free Reinforcement Learning
Jan 13, 2023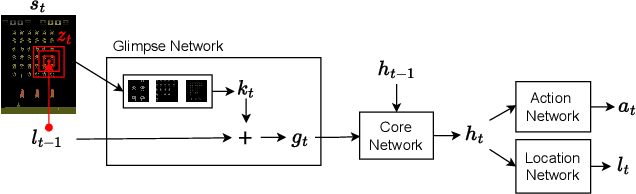

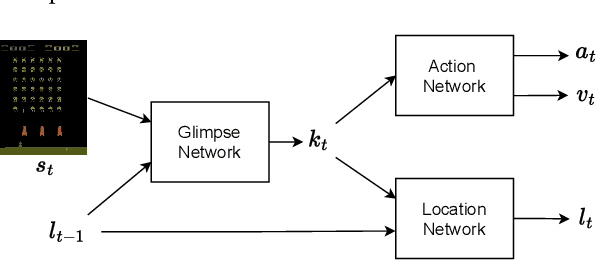
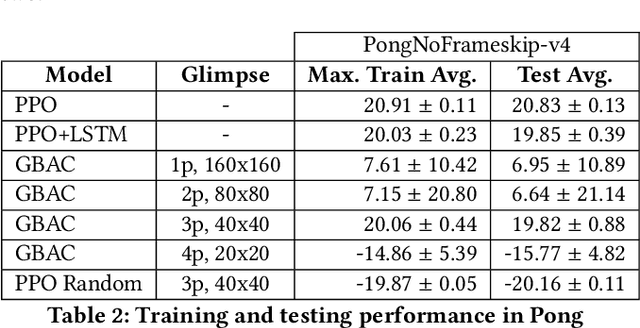
This work proposes a novel model-free Reinforcement Learning (RL) agent that is able to learn how to complete an unknown task having access to only a part of the input observation. We take inspiration from the concepts of visual attention and active perception that are characteristic of humans and tried to apply them to our agent, creating a hard attention mechanism. In this mechanism, the model decides first which region of the input image it should look at, and only after that it has access to the pixels of that region. Current RL agents do not follow this principle and we have not seen these mechanisms applied to the same purpose as this work. In our architecture, we adapt an existing model called recurrent attention model (RAM) and combine it with the proximal policy optimization (PPO) algorithm. We investigate whether a model with these characteristics is capable of achieving similar performance to state-of-the-art model-free RL agents that access the full input observation. This analysis is made in two Atari games, Pong and SpaceInvaders, which have a discrete action space, and in CarRacing, which has a continuous action space. Besides assessing its performance, we also analyze the movement of the attention of our model and compare it with what would be an example of the human behavior. Even with such visual limitation, we show that our model matches the performance of PPO+LSTM in two of the three games tested.
Image Harmonization with Region-wise Contrastive Learning
May 27, 2022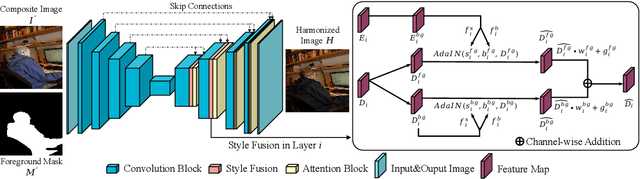
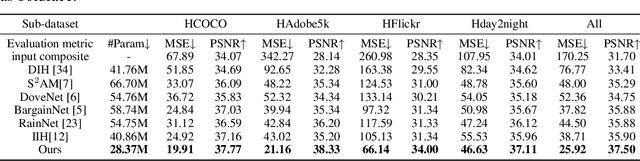
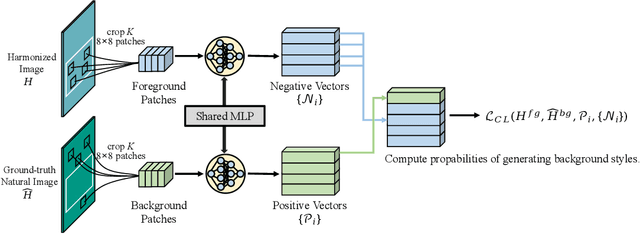
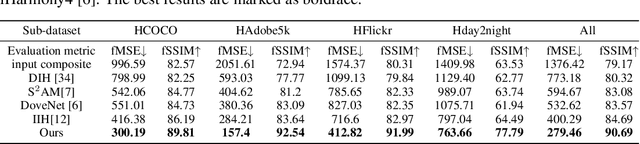
Image harmonization task aims at harmonizing different composite foreground regions according to specific background image. Previous methods would rather focus on improving the reconstruction ability of the generator by some internal enhancements such as attention, adaptive normalization and light adjustment, $etc.$. However, they pay less attention to discriminating the foreground and background appearance features within a restricted generator, which becomes a new challenge in image harmonization task. In this paper, we propose a novel image harmonization framework with external style fusion and region-wise contrastive learning scheme. For the external style fusion, we leverage the external background appearance from the encoder as the style reference to generate harmonized foreground in the decoder. This approach enhances the harmonization ability of the decoder by external background guidance. Moreover, for the contrastive learning scheme, we design a region-wise contrastive loss function for image harmonization task. Specifically, we first introduce a straight-forward samples generation method that selects negative samples from the output harmonized foreground region and selects positive samples from the ground-truth background region. Our method attempts to bring together corresponding positive and negative samples by maximizing the mutual information between the foreground and background styles, which desirably makes our harmonization network more robust to discriminate the foreground and background style features when harmonizing composite images. Extensive experiments on the benchmark datasets show that our method can achieve a clear improvement in harmonization quality and demonstrate the good generalization capability in real-scenario applications.
Edge-Based Self-Supervision for Semi-Supervised Few-Shot Microscopy Image Cell Segmentation
Aug 03, 2022
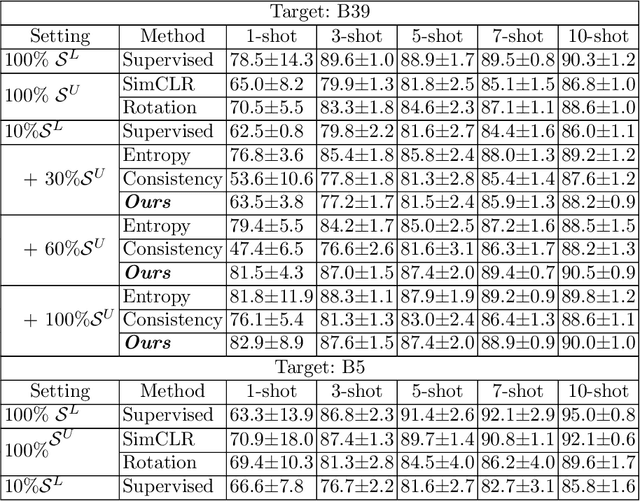

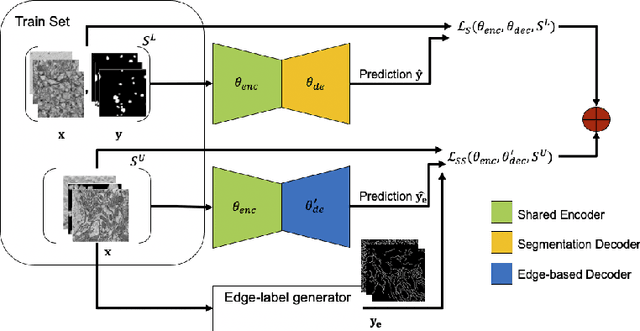
Deep neural networks currently deliver promising results for microscopy image cell segmentation, but they require large-scale labelled databases, which is a costly and time-consuming process. In this work, we relax the labelling requirement by combining self-supervised with semi-supervised learning. We propose the prediction of edge-based maps for self-supervising the training of the unlabelled images, which is combined with the supervised training of a small number of labelled images for learning the segmentation task. In our experiments, we evaluate on a few-shot microscopy image cell segmentation benchmark and show that only a small number of annotated images, e.g. 10% of the original training set, is enough for our approach to reach similar performance as with the fully annotated databases on 1- to 10-shots. Our code and trained models is made publicly available
Adversarial Attacks on Image Generation With Made-Up Words
Aug 04, 2022



Text-guided image generation models can be prompted to generate images using nonce words adversarially designed to robustly evoke specific visual concepts. Two approaches for such generation are introduced: macaronic prompting, which involves designing cryptic hybrid words by concatenating subword units from different languages; and evocative prompting, which involves designing nonce words whose broad morphological features are similar enough to that of existing words to trigger robust visual associations. The two methods can also be combined to generate images associated with more specific visual concepts. The implications of these techniques for the circumvention of existing approaches to content moderation, and particularly the generation of offensive or harmful images, are discussed.
Digital Image Processing Applied To Object Segmentation By Intensity And Motion
Aug 26, 2022The current technological development allows us to carry out tasks that some time ago were unthinkable if not impossible, digital image processing has been one of the major constants of development today, taking into account that its implementation dates from a short time ago, OpenCV [1] is a tool focused on machine vision, In this case implemented in an object-oriented programming platform based on Java language offered by the NetBeans development software, based on the above, a physical platform was proposed and implemented as a closed environment which through the development of an algorithm allowed detection and segmentation of objects by means of the RGB color model; In future works this algorithm will provide the information base for the autonomous robotic platform; this advance opens a wide spectrum for the development of applications and tools in the field of artificial vision.
Explainable, Physics Aware, Trustworthy AI Paradigm Shift for Synthetic Aperture Radar
Jan 09, 2023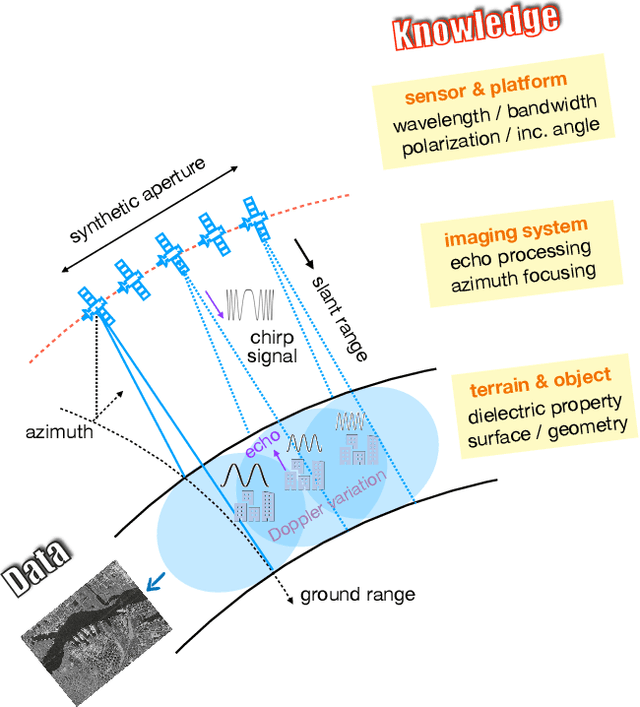
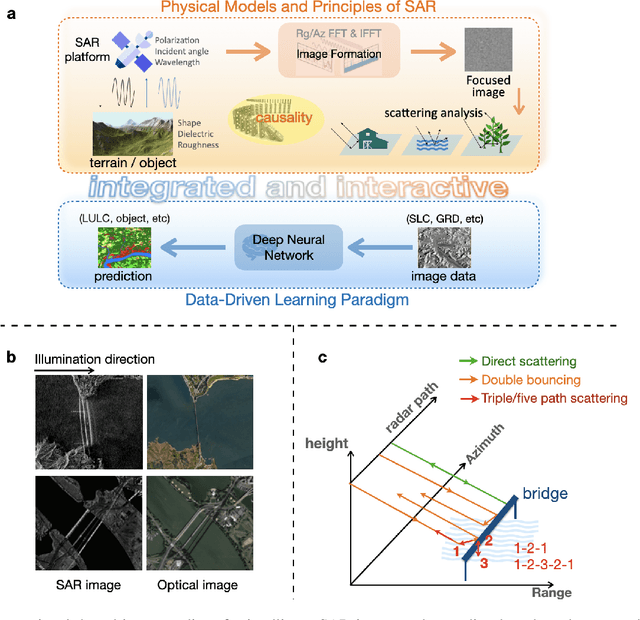
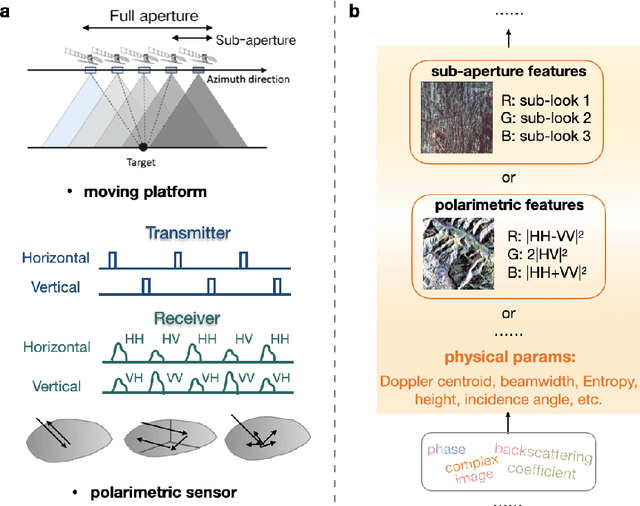
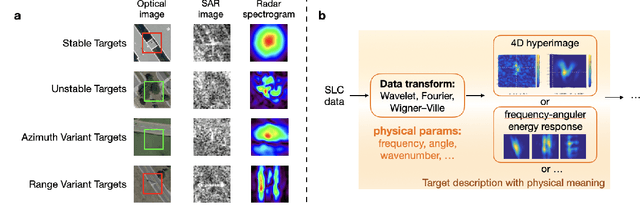
The recognition or understanding of the scenes observed with a SAR system requires a broader range of cues, beyond the spatial context. These encompass but are not limited to: imaging geometry, imaging mode, properties of the Fourier spectrum of the images or the behavior of the polarimetric signatures. In this paper, we propose a change of paradigm for explainability in data science for the case of Synthetic Aperture Radar (SAR) data to ground the explainable AI for SAR. It aims to use explainable data transformations based on well-established models to generate inputs for AI methods, to provide knowledgeable feedback for training process, and to learn or improve high-complexity unknown or un-formalized models from the data. At first, we introduce a representation of the SAR system with physical layers: i) instrument and platform, ii) imaging formation, iii) scattering signatures and objects, that can be integrated with an AI model for hybrid modeling. Successively, some illustrative examples are presented to demonstrate how to achieve hybrid modeling for SAR image understanding. The perspective of trustworthy model and supplementary explanations are discussed later. Finally, we draw the conclusion and we deem the proposed concept has applicability to the entire class of coherent imaging sensors and other computational imaging systems.