 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MIRNF: Medical Image Registration via Neural Fields
Jun 07, 2022
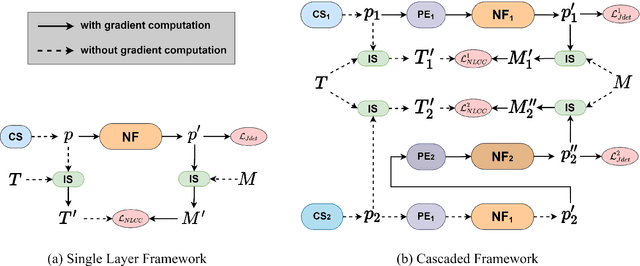
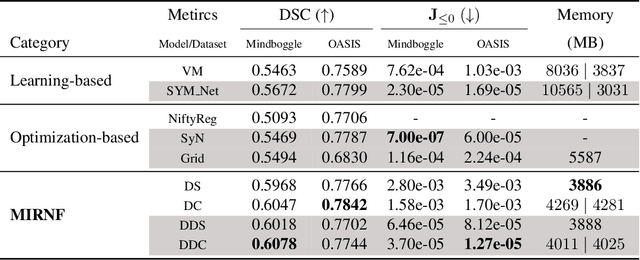
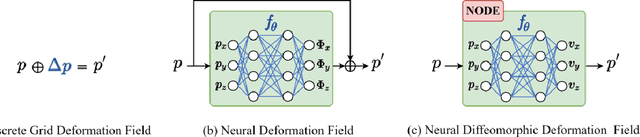
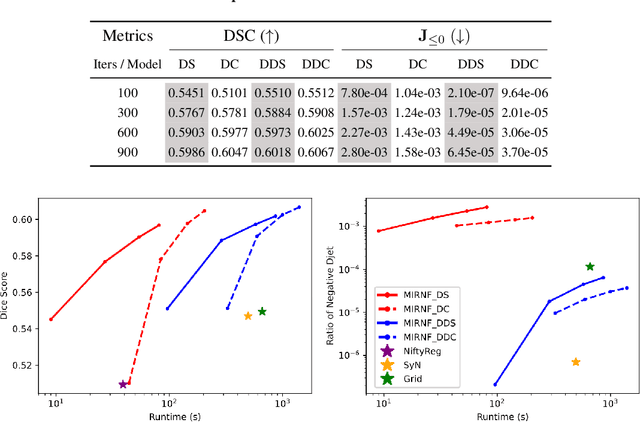
Image registration is widely used in medical image analysis to provide spatial correspondences between two images. Recently learning-based methods utilizing convolutional neural networks (CNNs) have been proposed for solving image registration problems. The learning-based methods tend to be much faster than traditional optimization-based methods, but the accuracy improvements gained from the complex CNN-based methods are modest. Here we introduce a new deep-neural net-based image registration framework, named \textbf{MIRNF}, which represents the correspondence mapping with a continuous function implemented via Neural Fields. MIRNF outputs either a deformation vector or velocity vector given a 3D coordinate as input. To ensure the mapping is diffeomorphic, the velocity vector output from MIRNF is integrated using the Neural ODE solver to derive the correspondences between two images. Furthermore, we propose a hybrid coordinate sampler along with a cascaded architecture to achieve the high-similarity mapping performance and low-distortion deformation fields. We conduct experiments on two 3D MR brain scan datasets, showing that our proposed framework provides state-of-art registration performance while maintaining comparable optimization time.
A Stochastic Proximal Polyak Step Size
Jan 12, 2023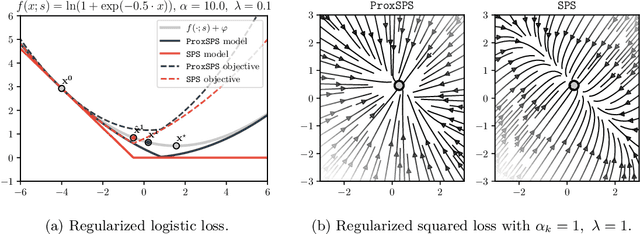
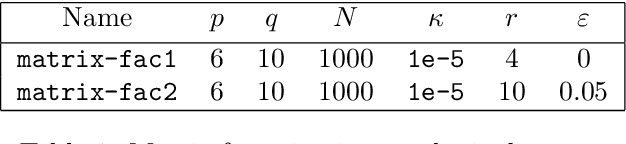
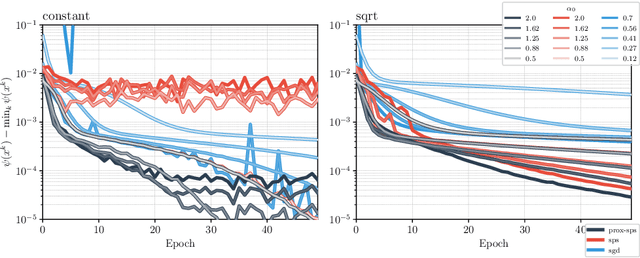
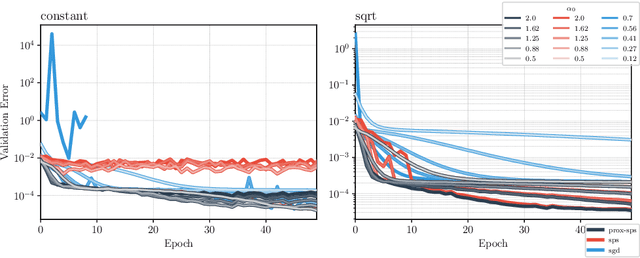
Recently, the stochastic Polyak step size (SPS) has emerged as a competitive adaptive step size scheme for stochastic gradient descent. Here we develop ProxSPS, a proximal variant of SPS that can handle regularization terms. Developing a proximal variant of SPS is particularly important, since SPS requires a lower bound of the objective function to work well. When the objective function is the sum of a loss and a regularizer, available estimates of a lower bound of the sum can be loose. In contrast, ProxSPS only requires a lower bound for the loss which is often readily available. As a consequence, we show that ProxSPS is easier to tune and more stable in the presence of regularization. Furthermore for image classification tasks, ProxSPS performs as well as AdamW with little to no tuning, and results in a network with smaller weight parameters. We also provide an extensive convergence analysis for ProxSPS that includes the non-smooth, smooth, weakly convex and strongly convex setting.
1st Place Solution for ECCV 2022 OOD-CV Challenge Object Detection Track
Jan 12, 2023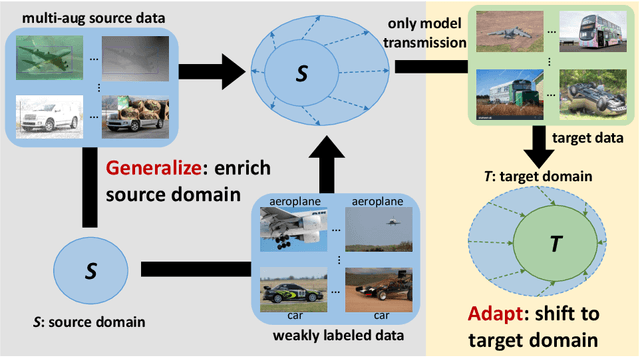

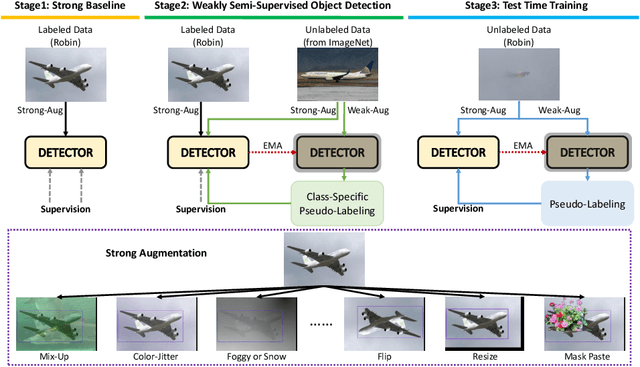
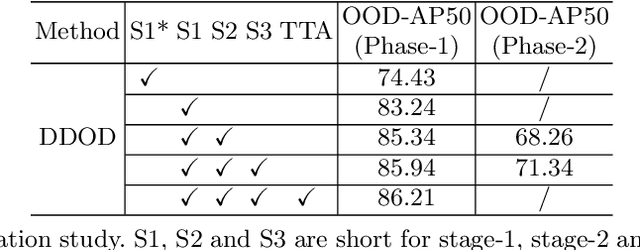
OOD-CV challenge is an out-of-distribution generalization task. To solve this problem in object detection track, we propose a simple yet effective Generalize-then-Adapt (G&A) framework, which is composed of a two-stage domain generalization part and a one-stage domain adaptation part. The domain generalization part is implemented by a Supervised Model Pretraining stage using source data for model warm-up and a Weakly Semi-Supervised Model Pretraining stage using both source data with box-level label and auxiliary data (ImageNet-1K) with image-level label for performance boosting. The domain adaptation part is implemented as a Source-Free Domain Adaptation paradigm, which only uses the pre-trained model and the unlabeled target data to further optimize in a self-supervised training manner. The proposed G&A framework help us achieve the first place on the object detection leaderboard of the OOD-CV challenge. Code will be released in https://github.com/hikvision-research/OOD-CV.
Improving mesh-based motion compensation by using edge adaptive graph-based compensated wavelet lifting for medical data sets
Jan 12, 2023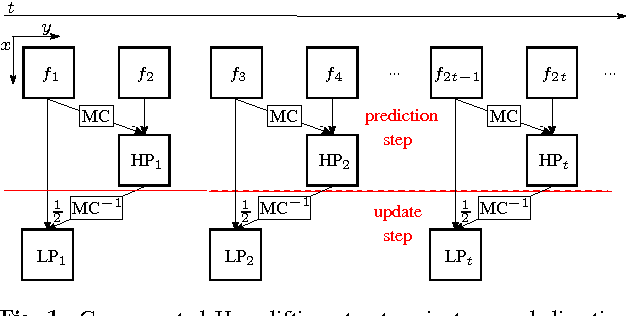

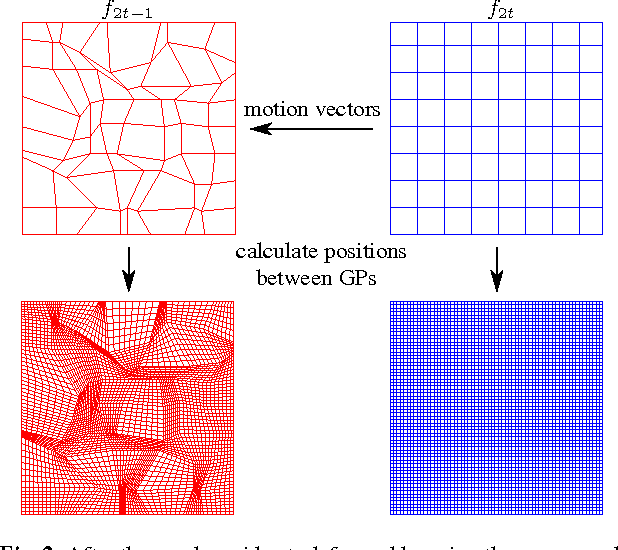
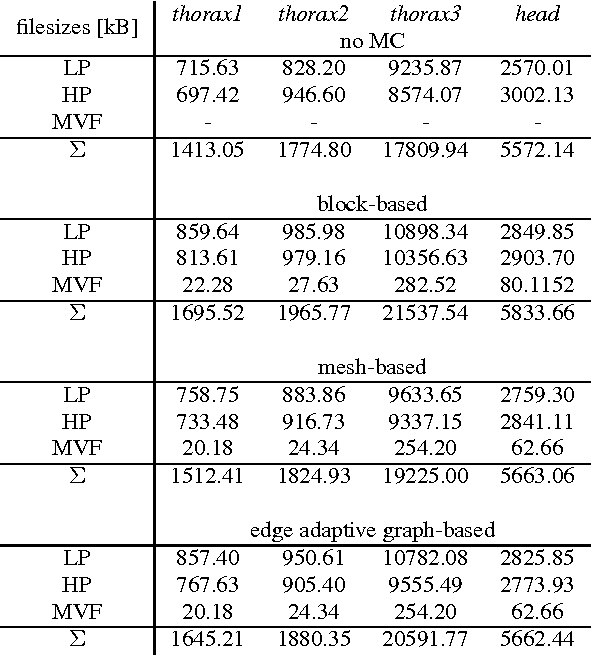
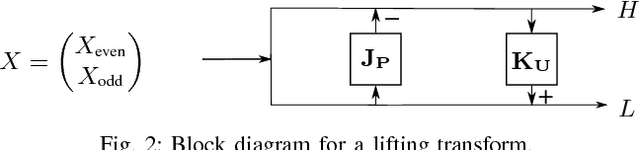
Medical applications like Computed Tomography (CT) or Magnetic Resonance Tomography (MRT) often require an efficient scalable representation of their huge output volumes in the further processing chain of medical routine. A downscaled version of such a signal can be obtained by using image and video coders based on wavelet transforms. The visual quality of the resulting lowpass band, which shall be used as a representative, can be improved by applying motion compensation methods during the transform. This paper presents a new approach of using the distorted edge lengths of a mesh-based compensated grid instead of the approximated intensity values of the underlying frame to perform a motion compensation. We will show that an edge adaptive graph-based compensation and its usage for compensated wavelet lifting improves the visual quality of the lowpass band by approximately 2.5 dB compared to the traditional mesh-based compensation, while the additional filesize required for coding the motion information doesn't change.
Graph-based compensated wavelet lifting for 3-D+t medical CT data
Jan 12, 2023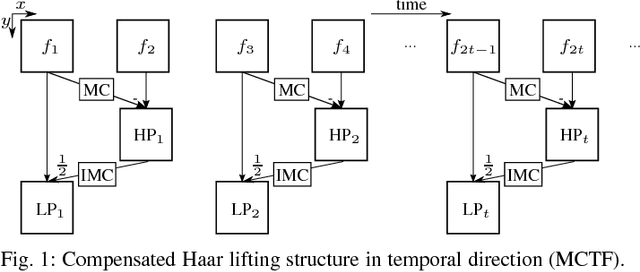
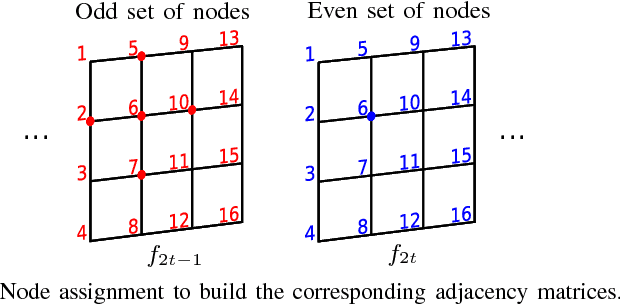
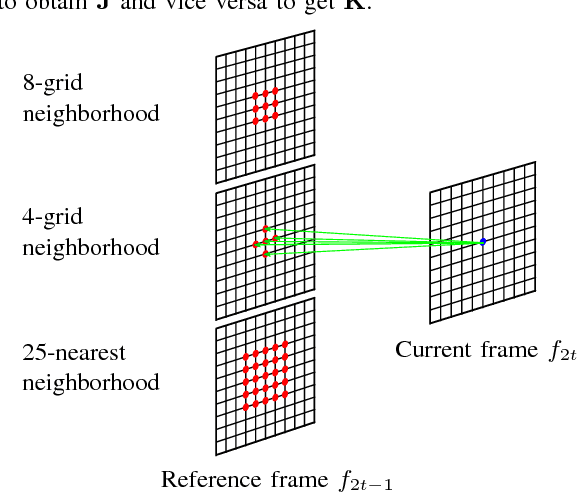
An efficient scalable data representation is an important task especially in the medical area, e.g. for volumes from Computed Tomography (CT) or Magnetic Resonance Tomography (MRT), when a downscaled version of the original signal is needed. Image and video coders based on wavelet transforms provide an adequate way to naturally achieve scalability. This paper presents a new approach for improving the visual quality of the lowpass band by using a novel graph-based method for motion compensation, which is an important step considering data compression. We compare different kinds of neighborhoods for graph construction and demonstrate that a higher amount of referenced nodes increases the quality of the lowpass band while the mean energy of the highpass band decreases. We show that for cardiac CT data the proposed method outperforms a traditional mesh-based approach of motion compensation by approximately 11 dB in terms of PSNR of the lowpass band. Also the mean energy of the highpass band decreases by around 30%.
Causal Triplet: An Open Challenge for Intervention-centric Causal Representation Learning
Jan 12, 2023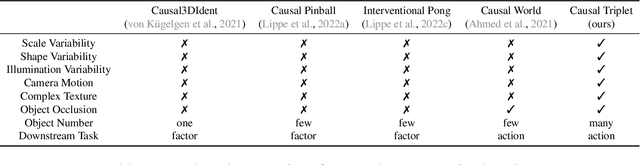
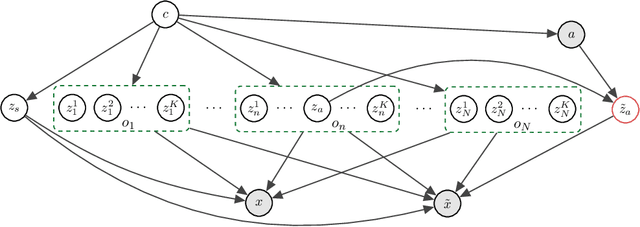


Recent years have seen a surge of interest in learning high-level causal representations from low-level image pairs under interventions. Yet, existing efforts are largely limited to simple synthetic settings that are far away from real-world problems. In this paper, we present Causal Triplet, a causal representation learning benchmark featuring not only visually more complex scenes, but also two crucial desiderata commonly overlooked in previous works: (i) an actionable counterfactual setting, where only certain object-level variables allow for counterfactual observations whereas others do not; (ii) an interventional downstream task with an emphasis on out-of-distribution robustness from the independent causal mechanisms principle. Through extensive experiments, we find that models built with the knowledge of disentangled or object-centric representations significantly outperform their distributed counterparts. However, recent causal representation learning methods still struggle to identify such latent structures, indicating substantial challenges and opportunities for future work. Our code and datasets will be available at https://sites.google.com/view/causaltriplet.
Unsupervised Superpixel Generation using Edge-Sparse Embedding
Nov 29, 2022
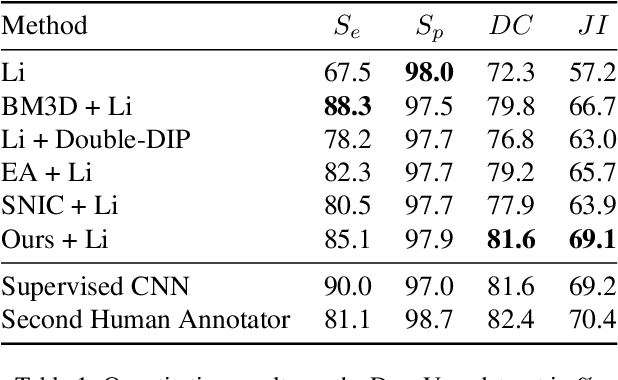
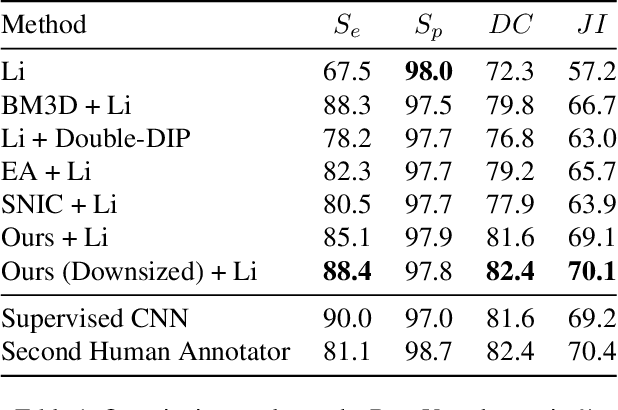
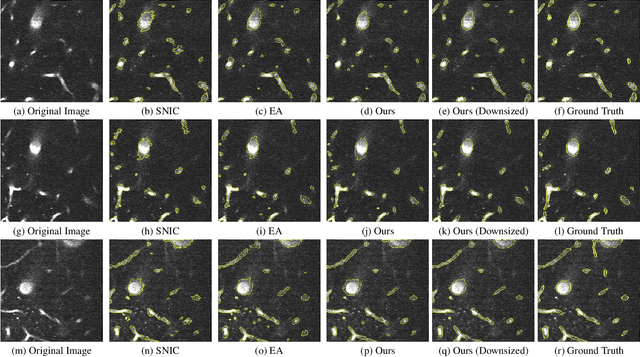
Partitioning an image into superpixels based on the similarity of pixels with respect to features such as colour or spatial location can significantly reduce data complexity and improve subsequent image processing tasks. Initial algorithms for unsupervised superpixel generation solely relied on local cues without prioritizing significant edges over arbitrary ones. On the other hand, more recent methods based on unsupervised deep learning either fail to properly address the trade-off between superpixel edge adherence and compactness or lack control over the generated number of superpixels. By using random images with strong spatial correlation as input, \ie, blurred noise images, in a non-convolutional image decoder we can reduce the expected number of contrasts and enforce smooth, connected edges in the reconstructed image. We generate edge-sparse pixel embeddings by encoding additional spatial information into the piece-wise smooth activation maps from the decoder's last hidden layer and use a standard clustering algorithm to extract high quality superpixels. Our proposed method reaches state-of-the-art performance on the BSDS500, PASCAL-Context and a microscopy dataset.
Taming a Generative Model
Nov 29, 2022
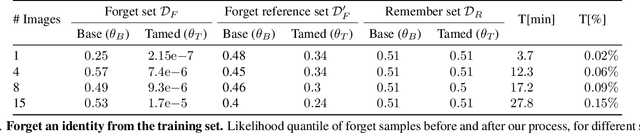
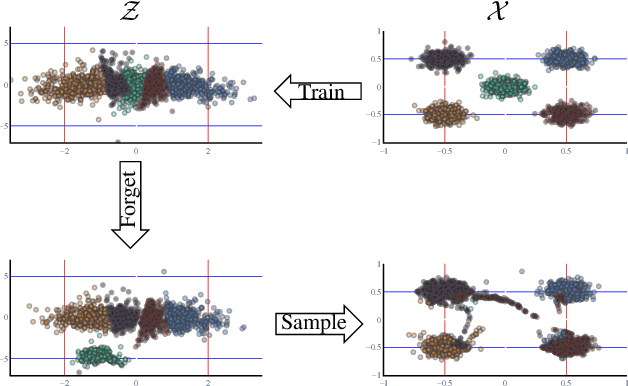
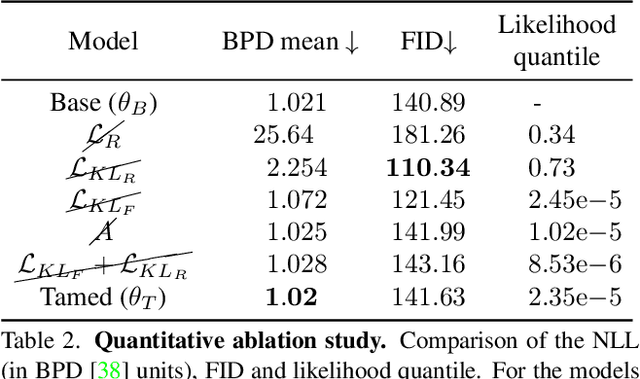
Generative models are becoming ever more powerful, being able to synthesize highly realistic images. We propose an algorithm for taming these models - changing the probability that the model will produce a specific image or image category. We consider generative models that are powered by normalizing flows, which allows us to reason about the exact generation probability likelihood for a given image. Our method is general purpose, and we exemplify it using models that generate human faces, a subdomain with many interesting privacy and bias considerations. Our method can be used in the context of privacy, e.g., removing a specific person from the output of a model, and also in the context of de-biasing by forcing a model to output specific image categories according to a given target distribution. Our method uses a fast fine-tuning process without retraining the model from scratch, achieving the goal in less than 1% of the time taken to initially train the generative model. We evaluate qualitatively and quantitatively, to examine the success of the taming process and output quality.
Traditional Classification Neural Networks are Good Generators: They are Competitive with DDPMs and GANs
Dec 08, 2022

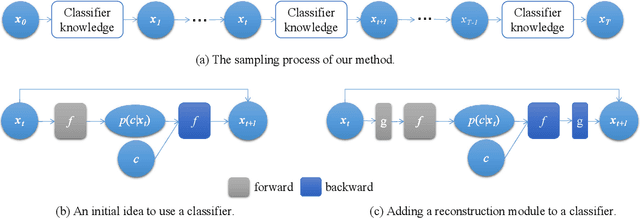
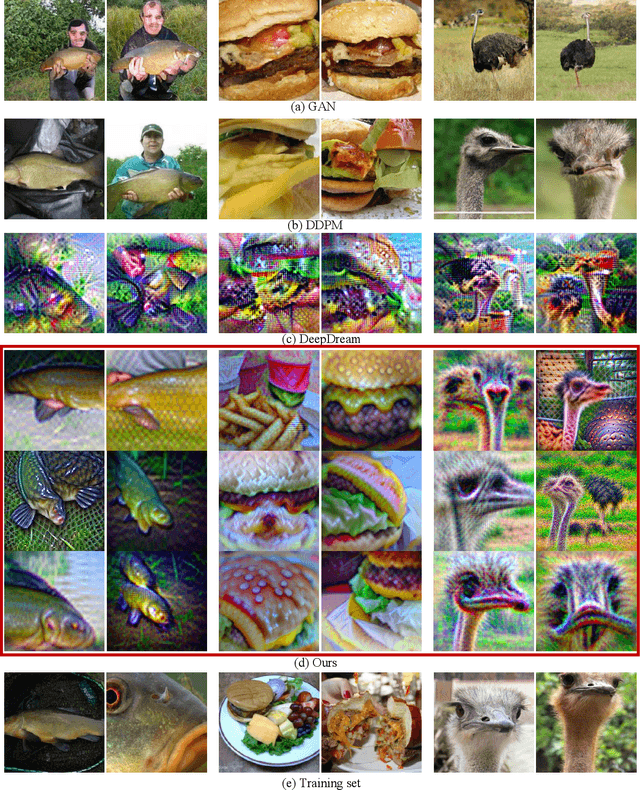
Classifiers and generators have long been separated. We break down this separation and showcase that conventional neural network classifiers can generate high-quality images of a large number of categories, being comparable to the state-of-the-art generative models (e.g., DDPMs and GANs). We achieve this by computing the partial derivative of the classification loss function with respect to the input to optimize the input to produce an image. Since it is widely known that directly optimizing the inputs is similar to targeted adversarial attacks incapable of generating human-meaningful images, we propose a mask-based stochastic reconstruction module to make the gradients semantic-aware to synthesize plausible images. We further propose a progressive-resolution technique to guarantee fidelity, which produces photorealistic images. Furthermore, we introduce a distance metric loss and a non-trivial distribution loss to ensure classification neural networks can synthesize diverse and high-fidelity images. Using traditional neural network classifiers, we can generate good-quality images of 256$\times$256 resolution on ImageNet. Intriguingly, our method is also applicable to text-to-image generation by regarding image-text foundation models as generalized classifiers. Proving that classifiers have learned the data distribution and are ready for image generation has far-reaching implications, for classifiers are much easier to train than generative models like DDPMs and GANs. We don't even need to train classification models because tons of public ones are available for download. Also, this holds great potential for the interpretability and robustness of classifiers. Project page is at \url{https://classifier-as-generator.github.io/}.
3D Inception-Based TransMorph: Pre- and Post-operative Multi-contrast MRI Registration in Brain Tumors
Dec 08, 2022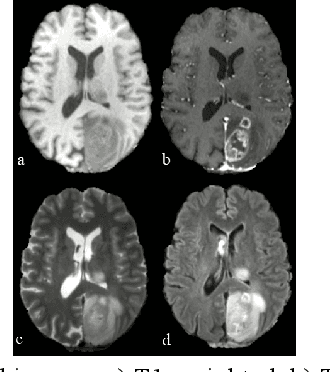
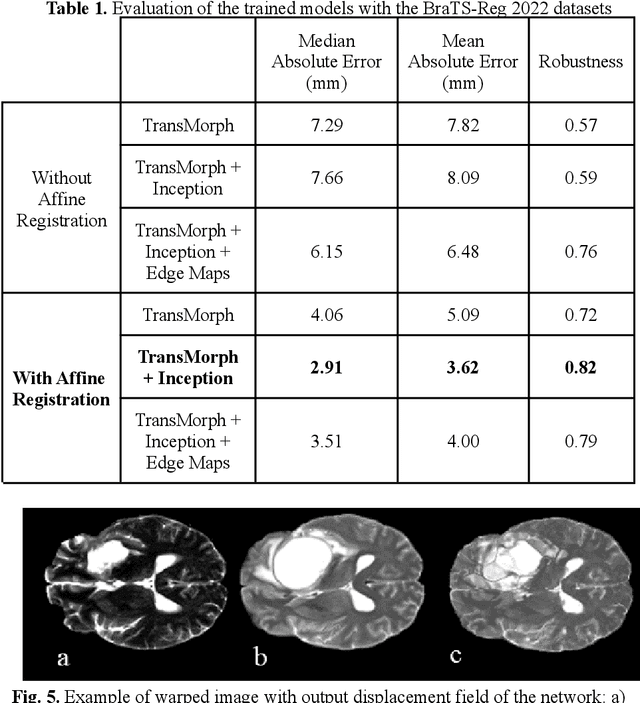
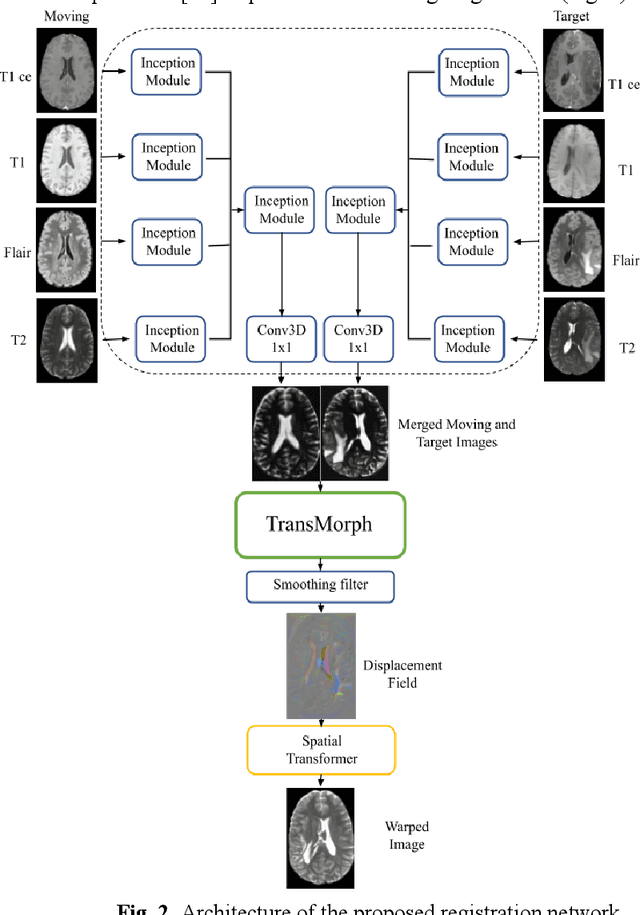
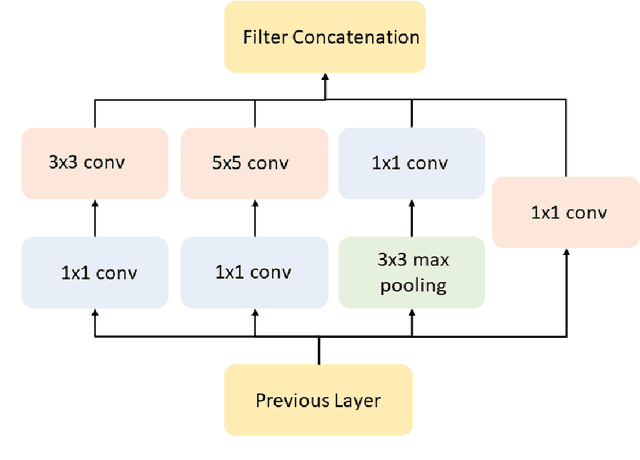
Deformable image registration is a key task in medical image analysis. The Brain Tumor Sequence Registration challenge (BraTS-Reg) aims at establishing correspondences between pre-operative and follow-up scans of the same patient diagnosed with an adult brain diffuse high-grade glioma and intends to address the challenging task of registering longitudinal data with major tissue appearance changes. In this work, we proposed a two-stage cascaded network based on the Inception and TransMorph models. The dataset for each patient was comprised of a native pre-contrast (T1), a contrast-enhanced T1-weighted (T1-CE), a T2-weighted (T2), and a Fluid Attenuated Inversion Recovery (FLAIR). The Inception model was used to fuse the 4 image modalities together and extract the most relevant information. Then, a variant of the TransMorph architecture was adapted to generate the displacement fields. The Loss function was composed of a standard image similarity measure, a diffusion regularizer, and an edge-map similarity measure added to overcome intensity dependence and reinforce correct boundary deformation. We observed that the addition of the Inception module substantially increased the performance of the network. Additionally, performing an initial affine registration before training the model showed improved accuracy in the landmark error measurements between pre and post-operative MRIs. We observed that our best model composed of the Inception and TransMorph architectures while using an initially affine registered dataset had the best performance with a median absolute error of 2.91 (initial error = 7.8). We achieved 6th place at the time of model submission in the final testing phase of the BraTS-Reg challenge.