 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A direct time-of-flight image sensor with in-pixel surface detection and dynamic vision
Sep 23, 2022
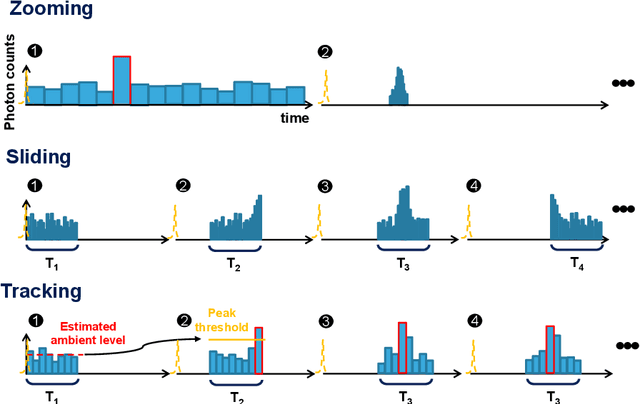
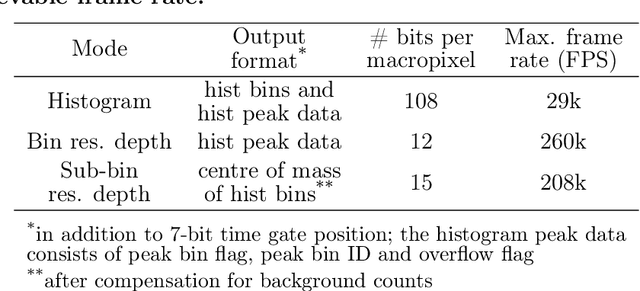
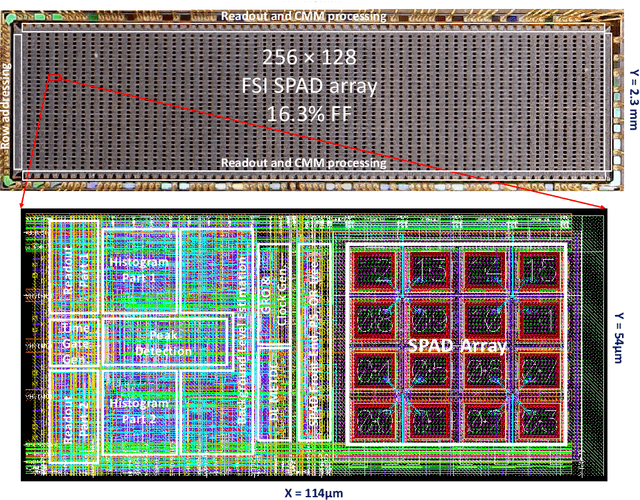
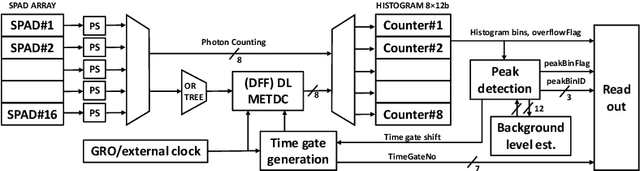
3D flash LIDAR is an alternative to the traditional scanning LIDAR systems, promising precise depth imaging in a compact form factor, and free of moving parts, for applications such as self-driving cars, robotics and augmented reality (AR). Typically implemented using single-photon, direct time-of-flight (dToF) receivers in image sensor format, the operation of the devices can be hindered by the large number of photon events needing to be processed and compressed in outdoor scenarios, limiting frame rates and scalability to larger arrays. We here present a 64x32 pixel (256x128 SPAD) dToF imager that overcomes these limitations by using pixels with embedded histogramming, which lock onto and track the return signal. This reduces the size of output data frames considerably, enabling maximum frame rates in the 10 kFPS range or 100 kFPS for direct depth readings. The sensor offers selective readout of pixels detecting surfaces, or those sensing motion, leading to reduced power consumption and off-chip processing requirements. We demonstrate the application of the sensor in mid-range LIDAR.
Hierarchical Average Precision Training for Pertinent Image Retrieval
Jul 05, 2022
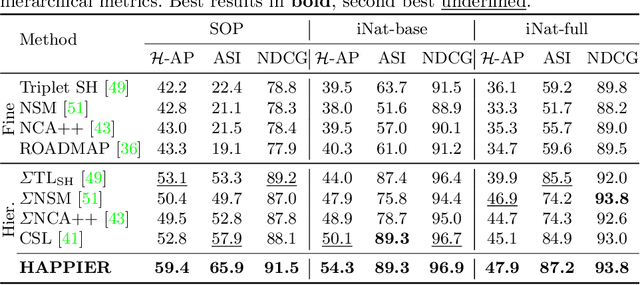
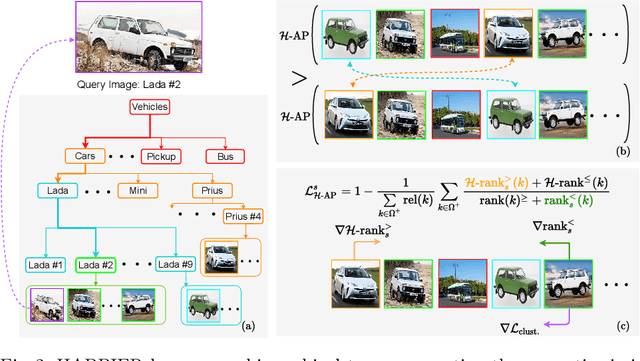
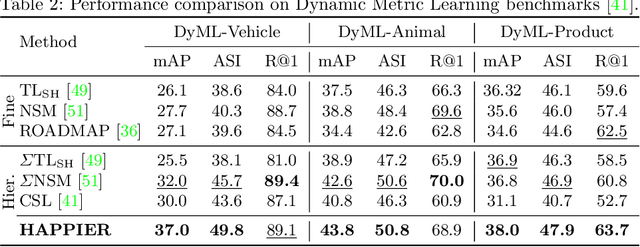
Image Retrieval is commonly evaluated with Average Precision (AP) or Recall@k. Yet, those metrics, are limited to binary labels and do not take into account errors' severity. This paper introduces a new hierarchical AP training method for pertinent image retrieval (HAP-PIER). HAPPIER is based on a new H-AP metric, which leverages a concept hierarchy to refine AP by integrating errors' importance and better evaluate rankings. To train deep models with H-AP, we carefully study the problem's structure and design a smooth lower bound surrogate combined with a clustering loss that ensures consistent ordering. Extensive experiments on 6 datasets show that HAPPIER significantly outperforms state-of-the-art methods for hierarchical retrieval, while being on par with the latest approaches when evaluating fine-grained ranking performances. Finally, we show that HAPPIER leads to better organization of the embedding space, and prevents most severe failure cases of non-hierarchical methods. Our code is publicly available at: https://github.com/elias-ramzi/HAPPIER.
Fighting Malicious Media Data: A Survey on Tampering Detection and Deepfake Detection
Dec 12, 2022


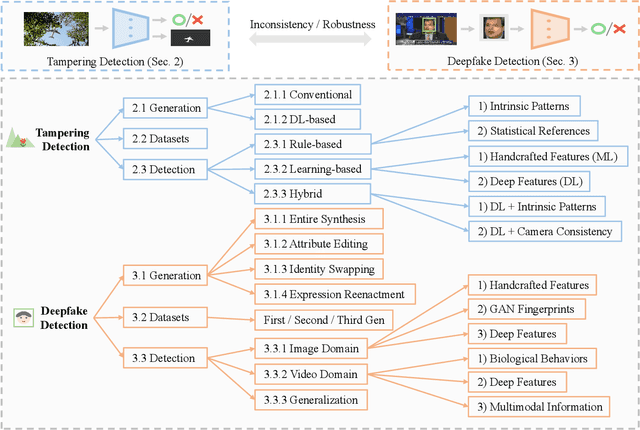
Online media data, in the forms of images and videos, are becoming mainstream communication channels. However, recent advances in deep learning, particularly deep generative models, open the doors for producing perceptually convincing images and videos at a low cost, which not only poses a serious threat to the trustworthiness of digital information but also has severe societal implications. This motivates a growing interest of research in media tampering detection, i.e., using deep learning techniques to examine whether media data have been maliciously manipulated. Depending on the content of the targeted images, media forgery could be divided into image tampering and Deepfake techniques. The former typically moves or erases the visual elements in ordinary images, while the latter manipulates the expressions and even the identity of human faces. Accordingly, the means of defense include image tampering detection and Deepfake detection, which share a wide variety of properties. In this paper, we provide a comprehensive review of the current media tampering detection approaches, and discuss the challenges and trends in this field for future research.
Learning the Relation between Similarity Loss and Clustering Loss in Self-Supervised Learning
Jan 08, 2023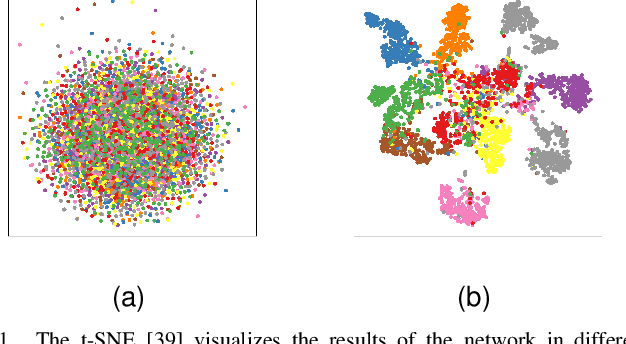
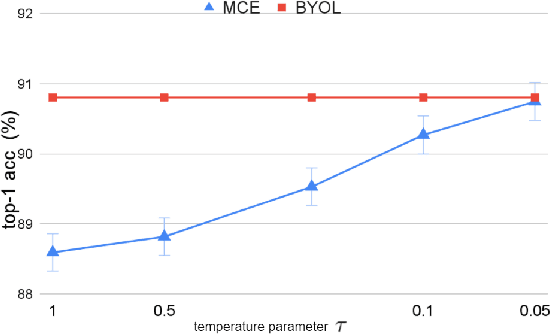
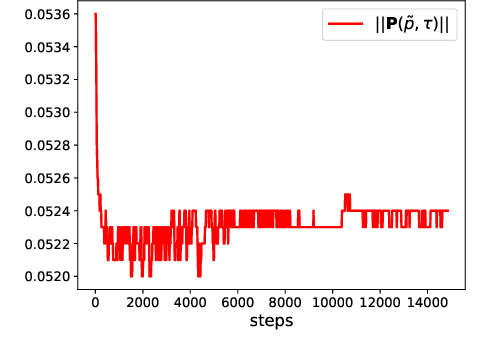
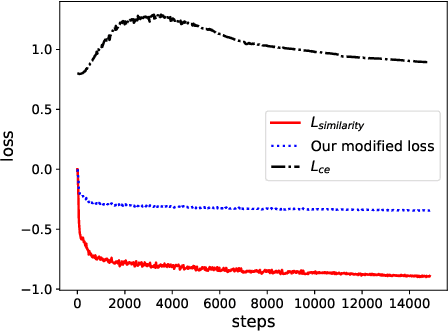
Self-supervised learning enables networks to learn discriminative features from massive data itself. Most state-of-the-art methods maximize the similarity between two augmentations of one image based on contrastive learning. By utilizing the consistency of two augmentations, the burden of manual annotations can be freed. Contrastive learning exploits instance-level information to learn robust features. However, the learned information is probably confined to different views of the same instance. In this paper, we attempt to leverage the similarity between two distinct images to boost representation in self-supervised learning. In contrast to instance-level information, the similarity between two distinct images may provide more useful information. Besides, we analyze the relation between similarity loss and feature-level cross-entropy loss. These two losses are essential for most deep learning methods. However, the relation between these two losses is not clear. Similarity loss helps obtain instance-level representation, while feature-level cross-entropy loss helps mine the similarity between two distinct images. We provide theoretical analyses and experiments to show that a suitable combination of these two losses can get state-of-the-art results.
CameraPose: Weakly-Supervised Monocular 3D Human Pose Estimation by Leveraging In-the-wild 2D Annotations
Jan 08, 2023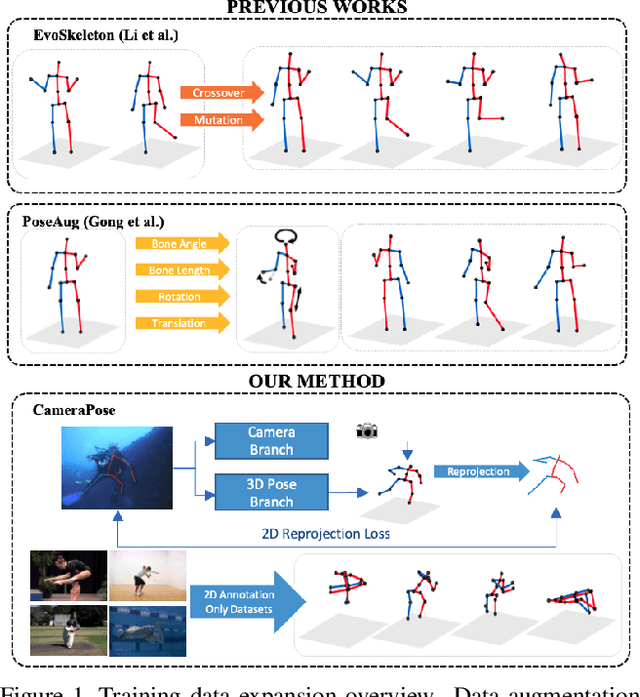
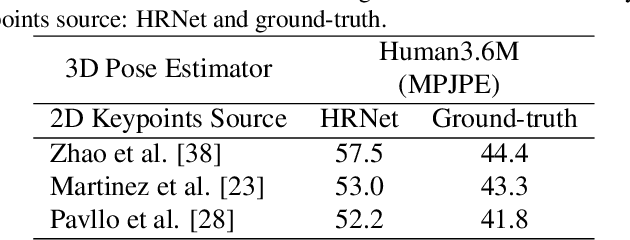
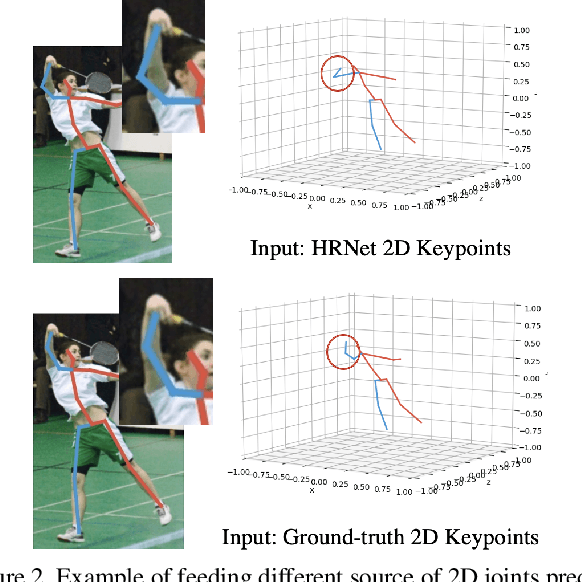

To improve the generalization of 3D human pose estimators, many existing deep learning based models focus on adding different augmentations to training poses. However, data augmentation techniques are limited to the "seen" pose combinations and hard to infer poses with rare "unseen" joint positions. To address this problem, we present CameraPose, a weakly-supervised framework for 3D human pose estimation from a single image, which can not only be applied on 2D-3D pose pairs but also on 2D alone annotations. By adding a camera parameter branch, any in-the-wild 2D annotations can be fed into our pipeline to boost the training diversity and the 3D poses can be implicitly learned by reprojecting back to 2D. Moreover, CameraPose introduces a refinement network module with confidence-guided loss to further improve the quality of noisy 2D keypoints extracted by 2D pose estimators. Experimental results demonstrate that the CameraPose brings in clear improvements on cross-scenario datasets. Notably, it outperforms the baseline method by 3mm on the most challenging dataset 3DPW. In addition, by combining our proposed refinement network module with existing 3D pose estimators, their performance can be improved in cross-scenario evaluation.
Advanced Data Augmentation Approaches: A Comprehensive Survey and Future directions
Jan 14, 2023
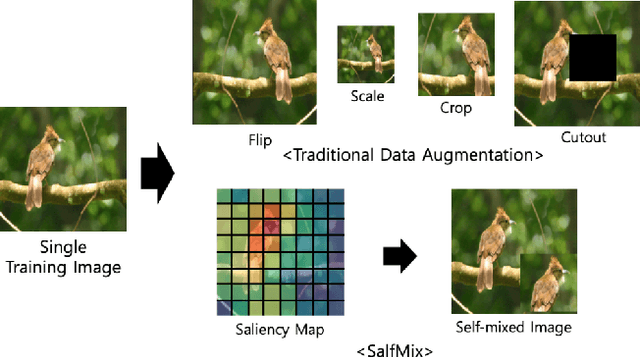


Deep learning (DL) algorithms have shown significant performance in various computer vision tasks. However, having limited labelled data lead to a network overfitting problem, where network performance is bad on unseen data as compared to training data. Consequently, it limits performance improvement. To cope with this problem, various techniques have been proposed such as dropout, normalization and advanced data augmentation. Among these, data augmentation, which aims to enlarge the dataset size by including sample diversity, has been a hot topic in recent times. In this article, we focus on advanced data augmentation techniques. we provide a background of data augmentation, a novel and comprehensive taxonomy of reviewed data augmentation techniques, and the strengths and weaknesses (wherever possible) of each technique. We also provide comprehensive results of the data augmentation effect on three popular computer vision tasks, such as image classification, object detection and semantic segmentation. For results reproducibility, we compiled available codes of all data augmentation techniques. Finally, we discuss the challenges and difficulties, and possible future direction for the research community. We believe, this survey provides several benefits i) readers will understand the data augmentation working mechanism to fix overfitting problems ii) results will save the searching time of the researcher for comparison purposes. iii) Codes of the mentioned data augmentation techniques are available at https://github.com/kmr2017/Advanced-Data-augmentation-codes iv) Future work will spark interest in research community.
Image Harmonization with Region-wise Contrastive Learning
May 27, 2022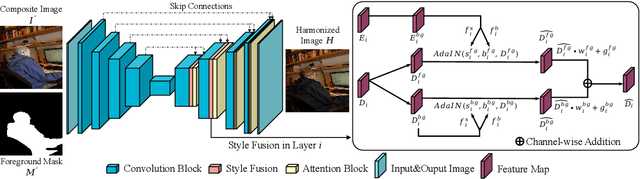
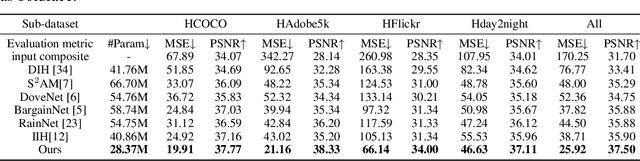
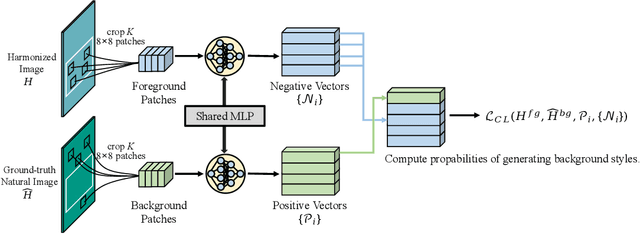
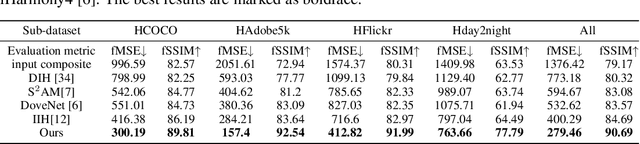
Image harmonization task aims at harmonizing different composite foreground regions according to specific background image. Previous methods would rather focus on improving the reconstruction ability of the generator by some internal enhancements such as attention, adaptive normalization and light adjustment, $etc.$. However, they pay less attention to discriminating the foreground and background appearance features within a restricted generator, which becomes a new challenge in image harmonization task. In this paper, we propose a novel image harmonization framework with external style fusion and region-wise contrastive learning scheme. For the external style fusion, we leverage the external background appearance from the encoder as the style reference to generate harmonized foreground in the decoder. This approach enhances the harmonization ability of the decoder by external background guidance. Moreover, for the contrastive learning scheme, we design a region-wise contrastive loss function for image harmonization task. Specifically, we first introduce a straight-forward samples generation method that selects negative samples from the output harmonized foreground region and selects positive samples from the ground-truth background region. Our method attempts to bring together corresponding positive and negative samples by maximizing the mutual information between the foreground and background styles, which desirably makes our harmonization network more robust to discriminate the foreground and background style features when harmonizing composite images. Extensive experiments on the benchmark datasets show that our method can achieve a clear improvement in harmonization quality and demonstrate the good generalization capability in real-scenario applications.
HashEncoding: Autoencoding with Multiscale Coordinate Hashing
Nov 29, 2022

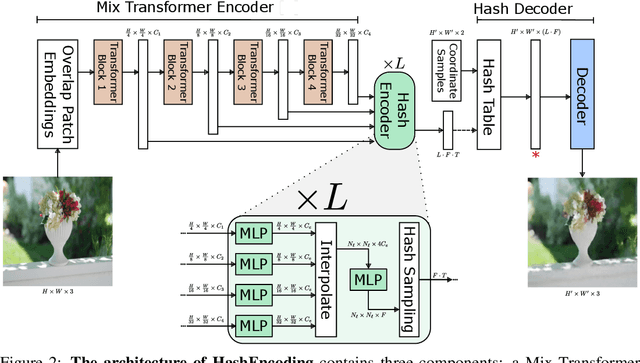

We present HashEncoding, a novel autoencoding architecture that leverages a non-parametric multiscale coordinate hash function to facilitate a per-pixel decoder without convolutions. By leveraging the space-folding behaviour of hashing functions, HashEncoding allows for an inherently multiscale embedding space that remains much smaller than the original image. As a result, the decoder requires very few parameters compared with decoders in traditional autoencoders, approaching a non-parametric reconstruction of the original image and allowing for greater generalizability. Finally, by allowing backpropagation directly to the coordinate space, we show that HashEncoding can be exploited for geometric tasks such as optical flow.
Uniformly Sampled Polar and Cylindrical Grid Approach for 2D, 3D Image Reconstruction using Algebraic Algorithm
Aug 27, 2022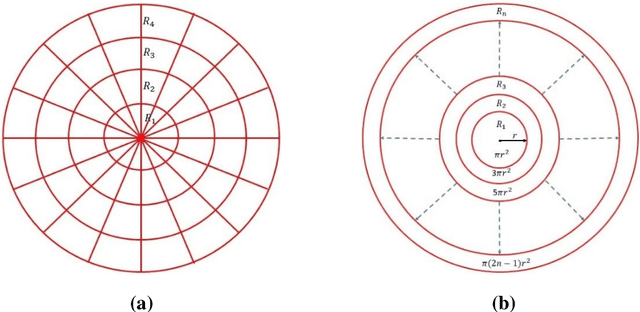

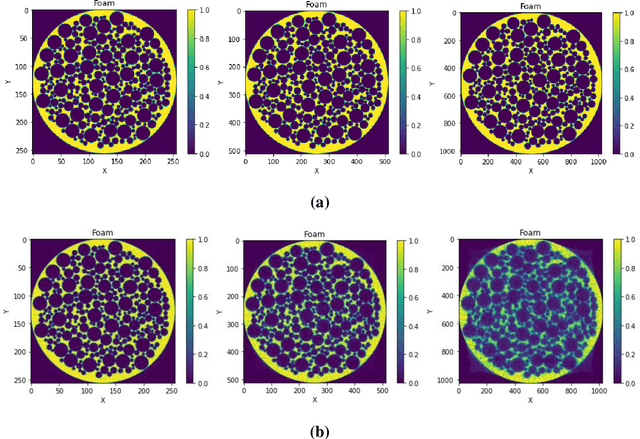
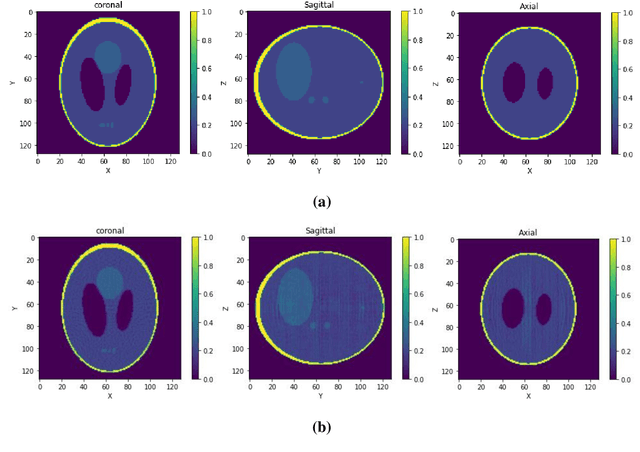
Image reconstruction by Algebraic Methods (AM) outperforms the transform methods in situations where the data collection procedure is constrained by time, space, and radiation dose. AM algorithms can also be applied for the cases where these constraints are not present but their high computational and storage requirement prohibit their actual breakthrough in such cases. In the present work, we propose a novel Uniformly Sampled Polar/Cylindrical Grid (USPG/USCG) discretization scheme to reduce the computational and storage burden of algebraic methods. The symmetries of USPG/USCG are utilized to speed up the calculations of the projection coefficients. In addition, we also offer an efficient approach for USPG to Cartesian Grid (CG) transformation for the visualization. The Multiplicative Algebraic Reconstruction Technique (MART) has been used to determine the field function of the suggested grids. Experimental projections data of a frog and Cu-Lump have been exercised to validate the proposed approach. A variety of image quality measures have been evaluated to check the accuracy of the reconstruction. Results indicate that the current strategies speed up (when compared to CG-based algorithms) the reconstruction process by a factor of 2.5 and reduce the memory requirement by the factor p, the number of projections used in the reconstruction.
Multi-Label Continual Learning using Augmented Graph Convolutional Network
Nov 27, 2022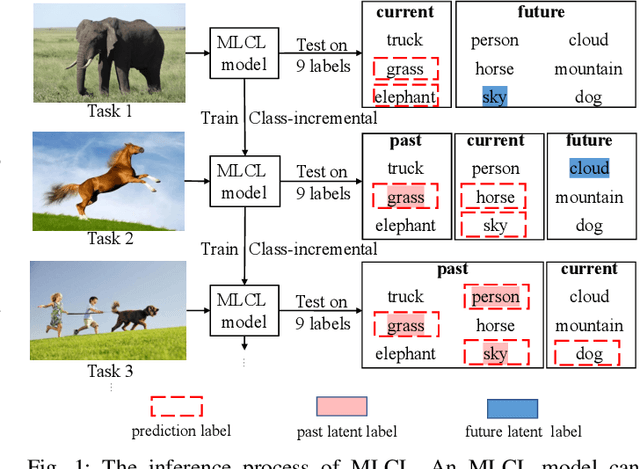
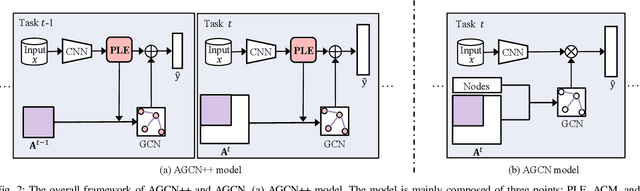
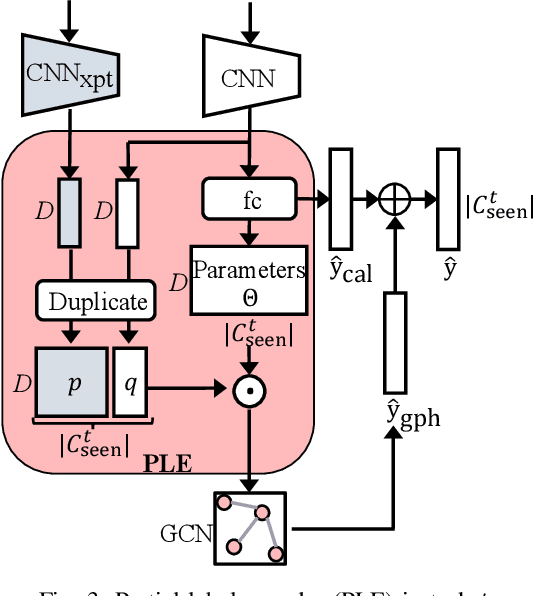
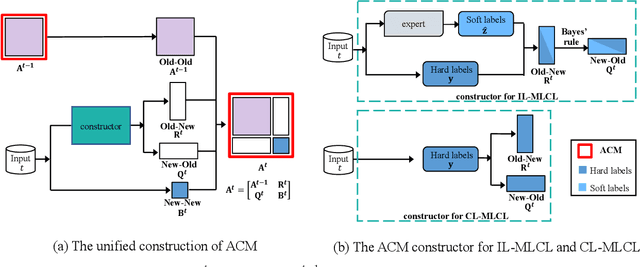
Multi-Label Continual Learning (MLCL) builds a class-incremental framework in a sequential multi-label image recognition data stream. The critical challenges of MLCL are the construction of label relationships on past-missing and future-missing partial labels of training data and the catastrophic forgetting on old classes, resulting in poor generalization. To solve the problems, the study proposes an Augmented Graph Convolutional Network (AGCN++) that can construct the cross-task label relationships in MLCL and sustain catastrophic forgetting. First, we build an Augmented Correlation Matrix (ACM) across all seen classes, where the intra-task relationships derive from the hard label statistics. In contrast, the inter-task relationships leverage hard and soft labels from data and a constructed expert network. Then, we propose a novel partial label encoder (PLE) for MLCL, which can extract dynamic class representation for each partial label image as graph nodes and help generate soft labels to create a more convincing ACM and suppress forgetting. Last, to suppress the forgetting of label dependencies across old tasks, we propose a relationship-preserving constrainter to construct label relationships. The inter-class topology can be augmented automatically, which also yields effective class representations. The proposed method is evaluated using two multi-label image benchmarks. The experimental results show that the proposed way is effective for MLCL image recognition and can build convincing correlations across tasks even if the labels of previous tasks are missing.