 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Rate-Perception Optimized Preprocessing for Video Coding
Jan 25, 2023

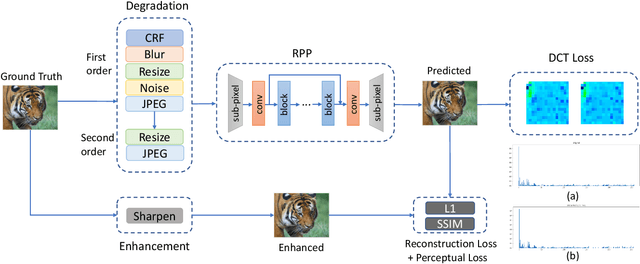

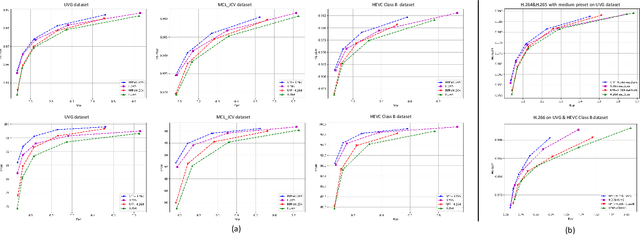
In the past decades, lots of progress have been done in the video compression field including traditional video codec and learning-based video codec. However, few studies focus on using preprocessing techniques to improve the rate-distortion performance. In this paper, we propose a rate-perception optimized preprocessing (RPP) method. We first introduce an adaptive Discrete Cosine Transform loss function which can save the bitrate and keep essential high frequency components as well. Furthermore, we also combine several state-of-the-art techniques from low-level vision fields into our approach, such as the high-order degradation model, efficient lightweight network design, and Image Quality Assessment model. By jointly using these powerful techniques, our RPP approach can achieve on average, 16.27% bitrate saving with different video encoders like AVC, HEVC, and VVC under multiple quality metrics. In the deployment stage, our RPP method is very simple and efficient which is not required any changes in the setting of video encoding, streaming, and decoding. Each input frame only needs to make a single pass through RPP before sending into video encoders. In addition, in our subjective visual quality test, 87% of users think videos with RPP are better or equal to videos by only using the codec to compress, while these videos with RPP save about 12% bitrate on average. Our RPP framework has been integrated into the production environment of our video transcoding services which serve millions of users every day.
vieCap4H-VLSP 2021: Vietnamese Image Captioning for Healthcare Domain using Swin Transformer and Attention-based LSTM
Sep 03, 2022
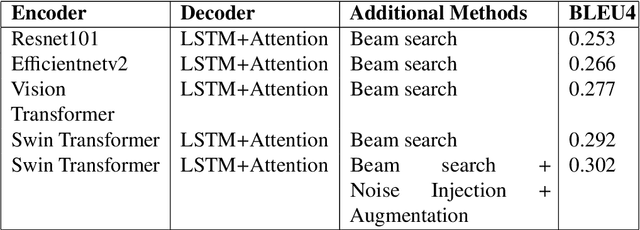
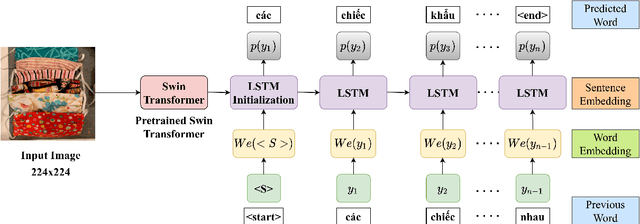

This study presents our approach on the automatic Vietnamese image captioning for healthcare domain in text processing tasks of Vietnamese Language and Speech Processing (VLSP) Challenge 2021, as shown in Figure 1. In recent years, image captioning often employs a convolutional neural network-based architecture as an encoder and a long short-term memory (LSTM) as a decoder to generate sentences. These models perform remarkably well in different datasets. Our proposed model also has an encoder and a decoder, but we instead use a Swin Transformer in the encoder, and a LSTM combined with an attention module in the decoder. The study presents our training experiments and techniques used during the competition. Our model achieves a BLEU4 score of 0.293 on the vietCap4H dataset, and the score is ranked the 3$^{rd}$ place on the private leaderboard. Our code can be found at \url{https://git.io/JDdJm}.
TinyMIM: An Empirical Study of Distilling MIM Pre-trained Models
Jan 03, 2023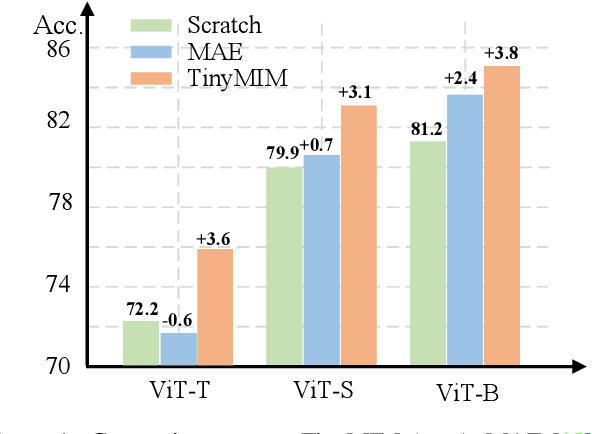
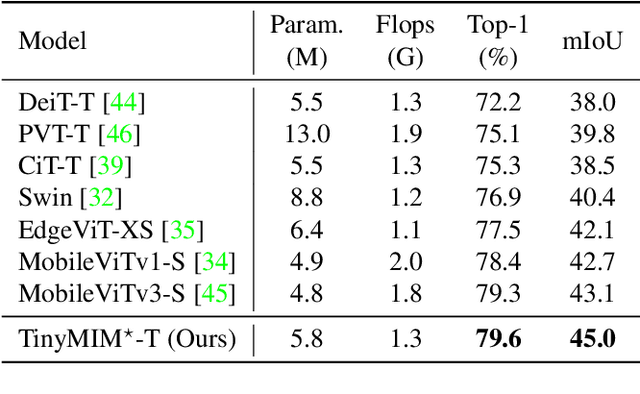
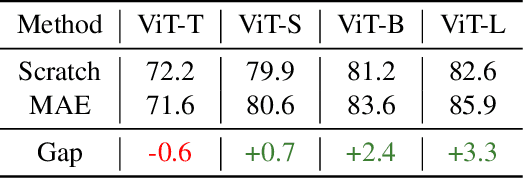
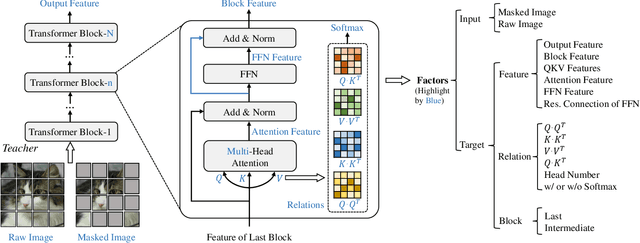
Masked image modeling (MIM) performs strongly in pre-training large vision Transformers (ViTs). However, small models that are critical for real-world applications cannot or only marginally benefit from this pre-training approach. In this paper, we explore distillation techniques to transfer the success of large MIM-based pre-trained models to smaller ones. We systematically study different options in the distillation framework, including distilling targets, losses, input, network regularization, sequential distillation, etc, revealing that: 1) Distilling token relations is more effective than CLS token- and feature-based distillation; 2) An intermediate layer of the teacher network as target perform better than that using the last layer when the depth of the student mismatches that of the teacher; 3) Weak regularization is preferred; etc. With these findings, we achieve significant fine-tuning accuracy improvements over the scratch MIM pre-training on ImageNet-1K classification, using all the ViT-Tiny, ViT-Small, and ViT-base models, with +4.2%/+2.4%/+1.4% gains, respectively. Our TinyMIM model of base size achieves 52.2 mIoU in AE20K semantic segmentation, which is +4.1 higher than the MAE baseline. Our TinyMIM model of tiny size achieves 79.6% top-1 accuracy on ImageNet-1K image classification, which sets a new record for small vision models of the same size and computation budget. This strong performance suggests an alternative way for developing small vision Transformer models, that is, by exploring better training methods rather than introducing inductive biases into architectures as in most previous works. Code is available at https://github.com/OliverRensu/TinyMIM.
FECANet: Boosting Few-Shot Semantic Segmentation with Feature-Enhanced Context-Aware Network
Jan 19, 2023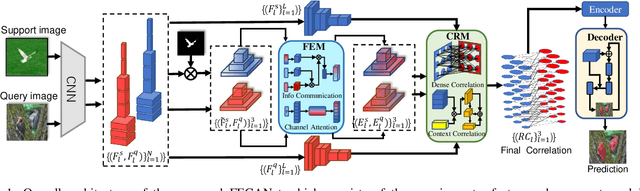
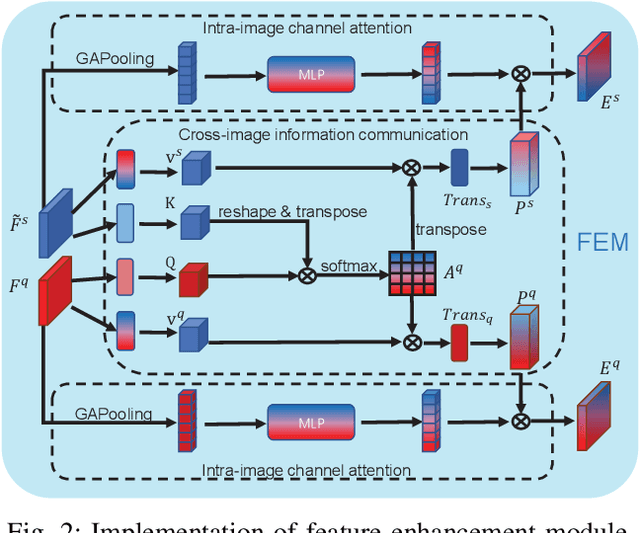
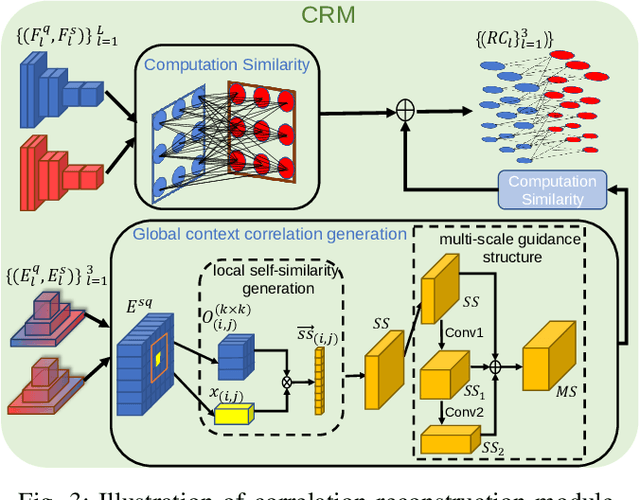

Few-shot semantic segmentation is the task of learning to locate each pixel of the novel class in the query image with only a few annotated support images. The current correlation-based methods construct pair-wise feature correlations to establish the many-to-many matching because the typical prototype-based approaches cannot learn fine-grained correspondence relations. However, the existing methods still suffer from the noise contained in naive correlations and the lack of context semantic information in correlations. To alleviate these problems mentioned above, we propose a Feature-Enhanced Context-Aware Network (FECANet). Specifically, a feature enhancement module is proposed to suppress the matching noise caused by inter-class local similarity and enhance the intra-class relevance in the naive correlation. In addition, we propose a novel correlation reconstruction module that encodes extra correspondence relations between foreground and background and multi-scale context semantic features, significantly boosting the encoder to capture a reliable matching pattern. Experiments on PASCAL-$5^i$ and COCO-$20^i$ datasets demonstrate that our proposed FECANet leads to remarkable improvement compared to previous state-of-the-arts, demonstrating its effectiveness.
TempSAL -- Uncovering Temporal Information for Deep Saliency Prediction
Jan 05, 2023


Deep saliency prediction algorithms complement the object recognition features, they typically rely on additional information, such as scene context, semantic relationships, gaze direction, and object dissimilarity. However, none of these models consider the temporal nature of gaze shifts during image observation. We introduce a novel saliency prediction model that learns to output saliency maps in sequential time intervals by exploiting human temporal attention patterns. Our approach locally modulates the saliency predictions by combining the learned temporal maps. Our experiments show that our method outperforms the state-of-the-art models, including a multi-duration saliency model, on the SALICON benchmark. Our code will be publicly available on GitHub.
RE-Tagger: A light-weight Real-Estate Image Classifier
Jul 12, 2022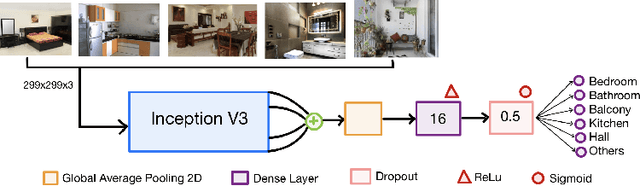

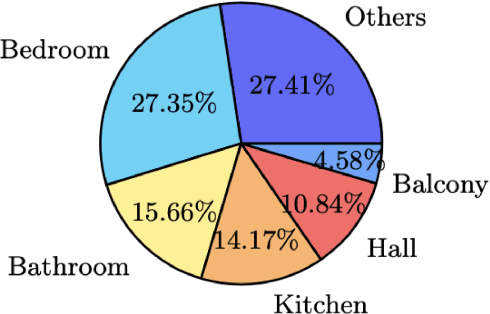

Real-estate image tagging is one of the essential use-cases to save efforts involved in manual annotation and enhance the user experience. This paper proposes an end-to-end pipeline (referred to as RE-Tagger) for the real-estate image classification problem. We present a two-stage transfer learning approach using custom InceptionV3 architecture to classify images into different categories (i.e., bedroom, bathroom, kitchen, balcony, hall, and others). Finally, we released the application as REST API hosted as a web application running on 2 cores machine with 2 GB RAM. The demo video is available here.
Improving Performance of Object Detection using the Mechanisms of Visual Recognition in Humans
Jan 23, 2023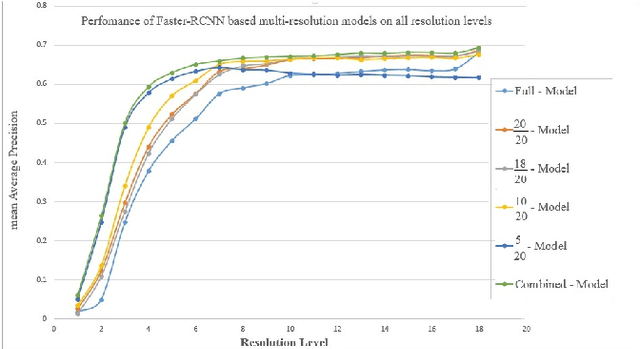
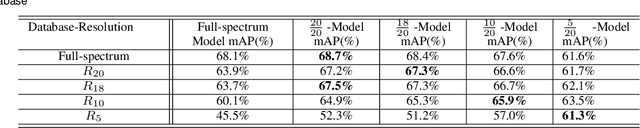

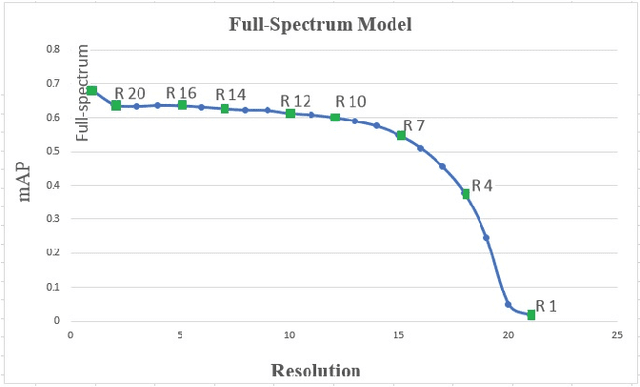
Object recognition systems are usually trained and evaluated on high resolution images. However, in real world applications, it is common that the images have low resolutions or have small sizes. In this study, we first track the performance of the state-of-the-art deep object recognition network, Faster- RCNN, as a function of image resolution. The results reveals negative effects of low resolution images on recognition performance. They also show that different spatial frequencies convey different information about the objects in recognition process. It means multi-resolution recognition system can provides better insight into optimal selection of features that results in better recognition of objects. This is similar to the mechanisms of the human visual systems that are able to implement multi-scale representation of a visual scene simultaneously. Then, we propose a multi-resolution object recognition framework rather than a single-resolution network. The proposed framework is evaluated on the PASCAL VOC2007 database. The experimental results show the performance of our adapted multi-resolution Faster-RCNN framework outperforms the single-resolution Faster-RCNN on input images with various resolutions with an increase in the mean Average Precision (mAP) of 9.14% across all resolutions and 1.2% on the full-spectrum images. Furthermore, the proposed model yields robustness of the performance over a wide range of spatial frequencies.
M-GenSeg: Domain Adaptation For Target Modality Tumor Segmentation With Annotation-Efficient Supervision
Dec 14, 2022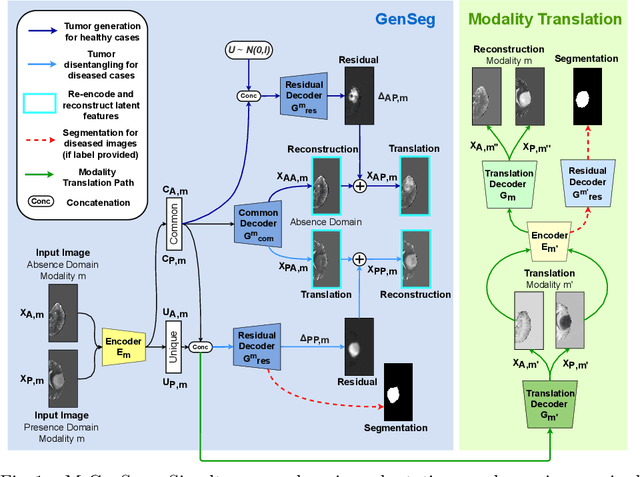
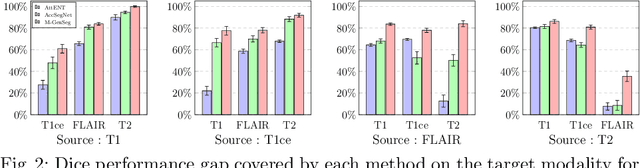
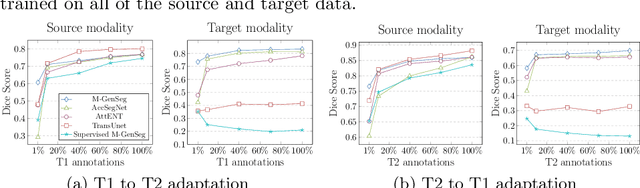
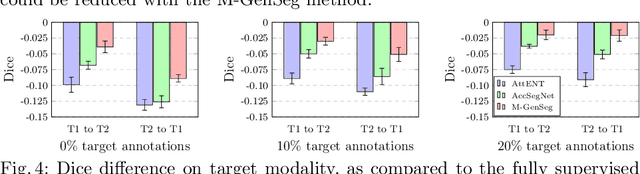
Automated medical image segmentation using deep neural networks typically requires substantial supervised training. However, these models fail to generalize well across different imaging modalities. This shortcoming, amplified by the limited availability of annotated data, has been hampering the deployment of such methods at a larger scale across modalities. To address these issues, we propose M-GenSeg, a new semi-supervised training strategy for accurate cross-modality tumor segmentation on unpaired bi-modal datasets. Based on image-level labels, a first unsupervised objective encourages the model to perform diseased to healthy translation by disentangling tumors from the background, which encompasses the segmentation task. Then, teaching the model to translate between image modalities enables the synthesis of target images from a source modality, thus leveraging the pixel-level annotations from the source modality to enforce generalization to the target modality images. We evaluated the performance on a brain tumor segmentation datasets composed of four different contrast sequences from the public BraTS 2020 challenge dataset. We report consistent improvement in Dice scores on both source and unannotated target modalities. On all twelve distinct domain adaptation experiments, the proposed model shows a clear improvement over state-of-the-art domain-adaptive baselines, with absolute Dice gains on the target modality reaching 0.15.
ExReg: Wide-range Photo Exposure Correction via a Multi-dimensional Regressor with Attention
Dec 14, 2022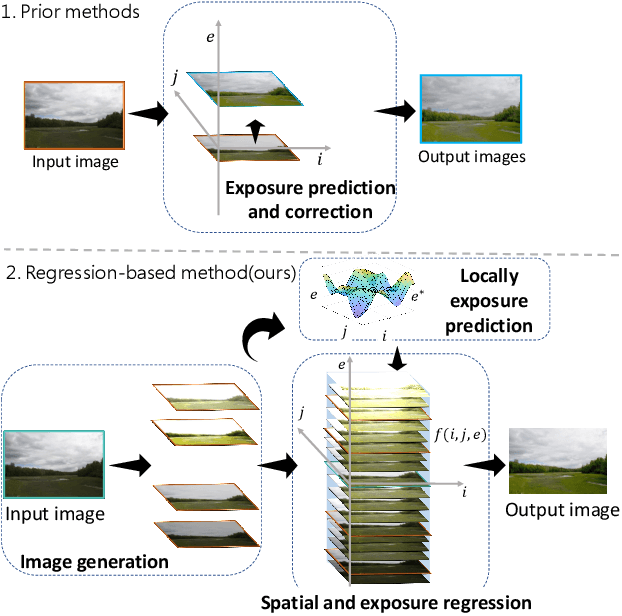
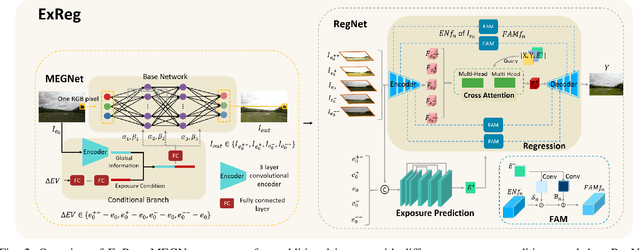
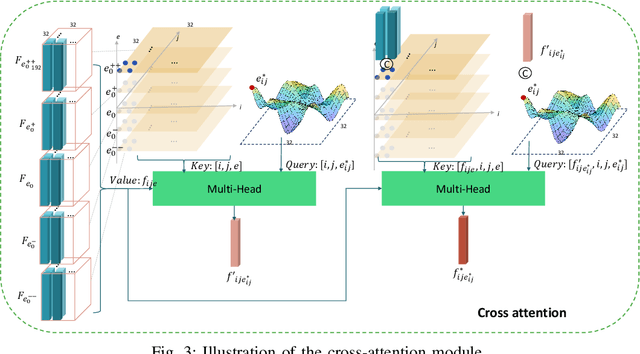

Photo exposure correction is widely investigated, but fewer studies focus on correcting under and over-exposed images simultaneously. Three issues remain open to handle and correct under and over-exposed images in a unified way. First, a locally-adaptive exposure adjustment may be more flexible instead of learning a global mapping. Second, it is an ill-posed problem to determine the suitable exposure values locally. Third, photos with the same content but different exposures may not reach consistent adjustment results. To this end, we proposed a novel exposure correction network, ExReg, to address the challenges by formulating exposure correction as a multi-dimensional regression process. Given an input image, a compact multi-exposure generation network is introduced to generate images with different exposure conditions for multi-dimensional regression and exposure correction in the next stage. An auxiliary module is designed to predict the region-wise exposure values, guiding the mainly proposed Encoder-Decoder ANP (Attentive Neural Processes) to regress the final corrected image. The experimental results show that ExReg can generate well-exposed results and outperform the SOTA method by 1.3dB in PSNR for extensive exposure problems. In addition, given the same image but under various exposure for testing, the corrected results are more visually consistent and physically accurate.
Dense residual Transformer for image denoising
May 14, 2022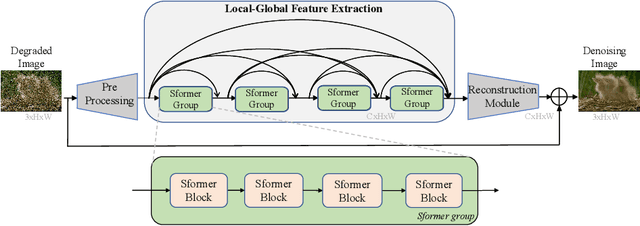
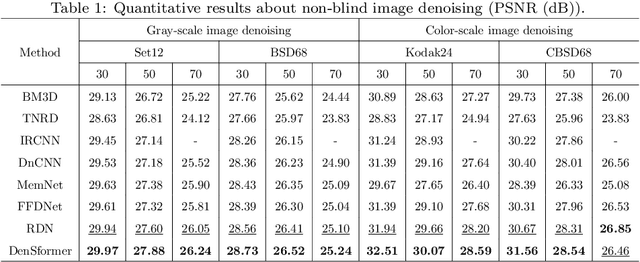
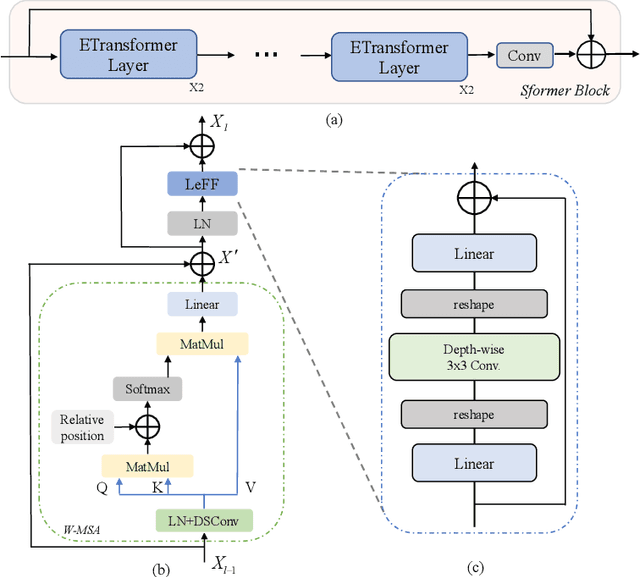
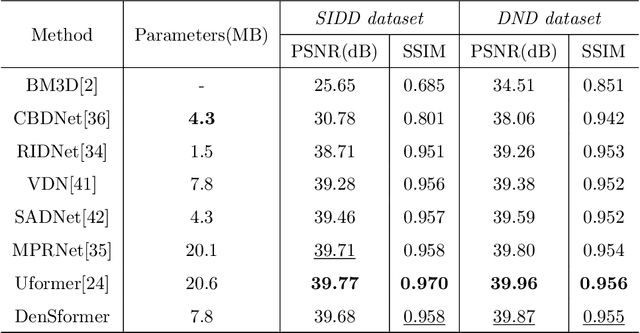
Image denoising is an important low-level computer vision task, which aims to reconstruct a noise-free and high-quality image from a noisy image. With the development of deep learning, convolutional neural network (CNN) has been gradually applied and achieved great success in image denoising, image compression, image enhancement, etc. Recently, Transformer has been a hot technique, which is widely used to tackle computer vision tasks. However, few Transformer-based methods have been proposed for low-level vision tasks. In this paper, we proposed an image denoising network structure based on Transformer, which is named DenSformer. DenSformer consists of three modules, including a preprocessing module, a local-global feature extraction module, and a reconstruction module. Specifically, the local-global feature extraction module consists of several Sformer groups, each of which has several ETransformer layers and a convolution layer, together with a residual connection. These Sformer groups are densely skip-connected to fuse the feature of different layers, and they jointly capture the local and global information from the given noisy images. We conduct our model on comprehensive experiments. Experimental results prove that our DenSformer achieves improvement compared to some state-of-the-art methods, both for the synthetic noise data and real noise data, in the objective and subjective evaluations.