 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RDD2022: A multi-national image dataset for automatic Road Damage Detection
Sep 18, 2022
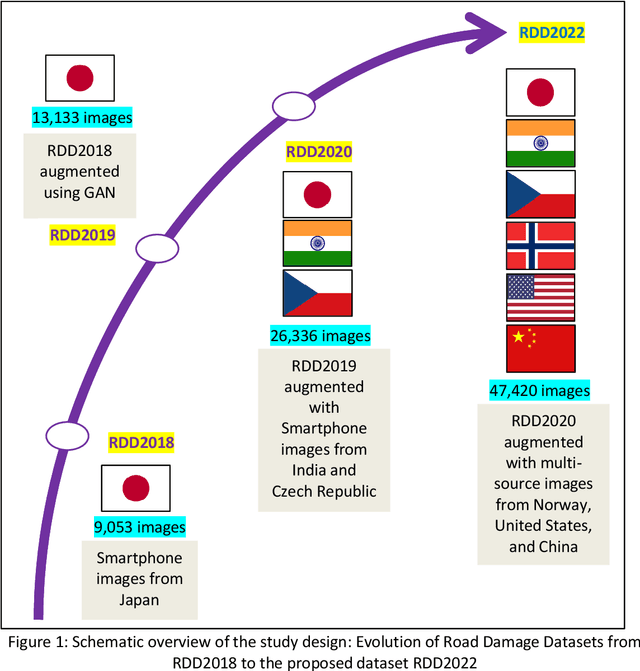
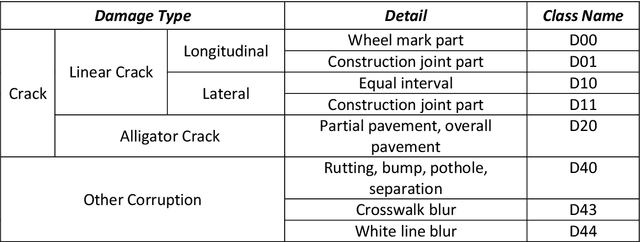
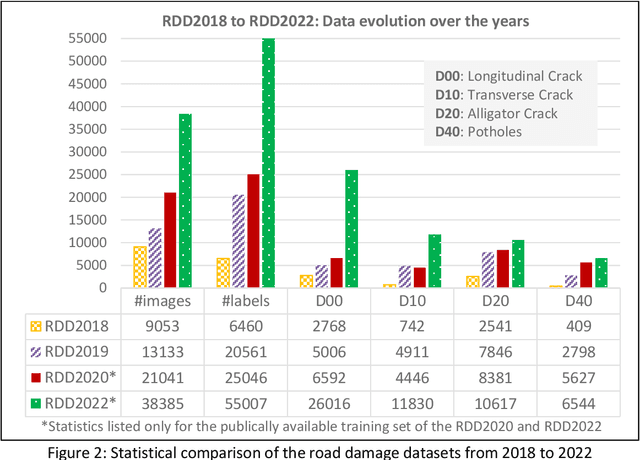
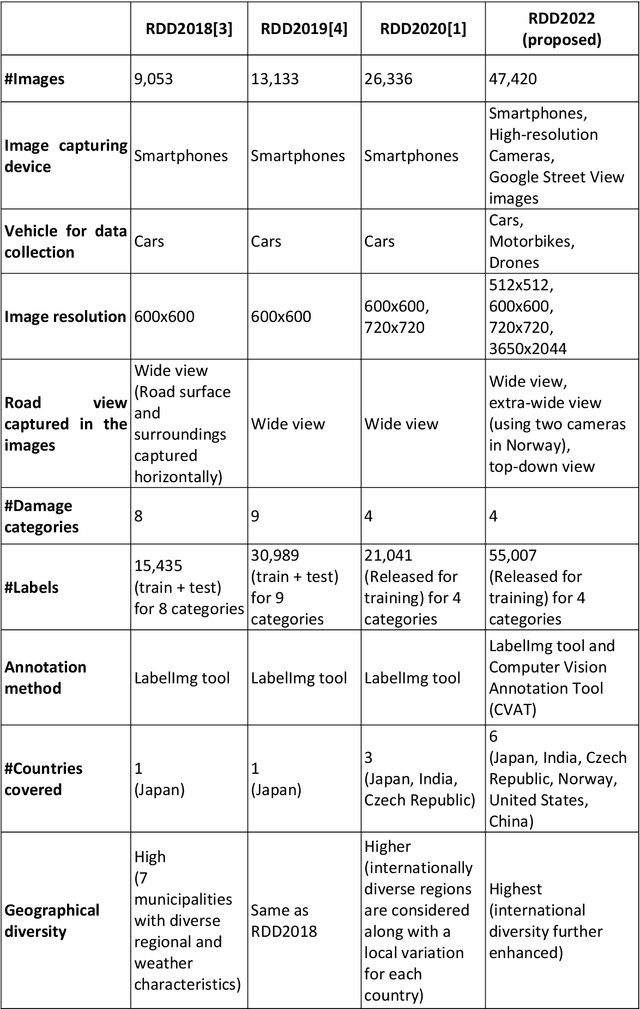
The data article describes the Road Damage Dataset, RDD2022, which comprises 47,420 road images from six countries, Japan, India, the Czech Republic, Norway, the United States, and China. The images have been annotated with more than 55,000 instances of road damage. Four types of road damage, namely longitudinal cracks, transverse cracks, alligator cracks, and potholes, are captured in the dataset. The annotated dataset is envisioned for developing deep learning-based methods to detect and classify road damage automatically. The dataset has been released as a part of the Crowd sensing-based Road Damage Detection Challenge (CRDDC2022). The challenge CRDDC2022 invites researchers from across the globe to propose solutions for automatic road damage detection in multiple countries. The municipalities and road agencies may utilize the RDD2022 dataset, and the models trained using RDD2022 for low-cost automatic monitoring of road conditions. Further, computer vision and machine learning researchers may use the dataset to benchmark the performance of different algorithms for other image-based applications of the same type (classification, object detection, etc.).
Learned Image Compression with Generalized Octave Convolution and Cross-Resolution Parameter Estimation
Sep 07, 2022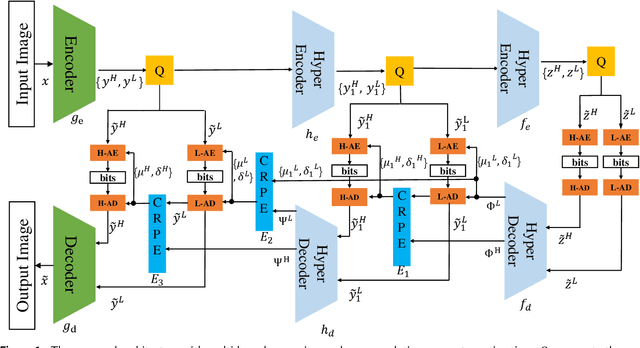

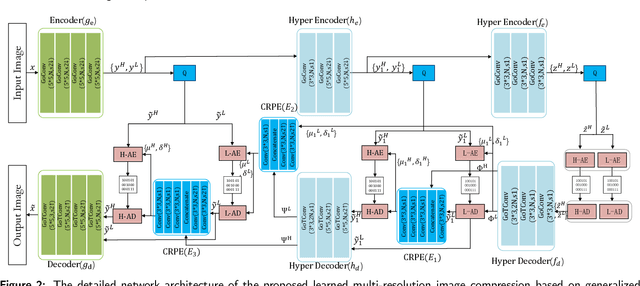
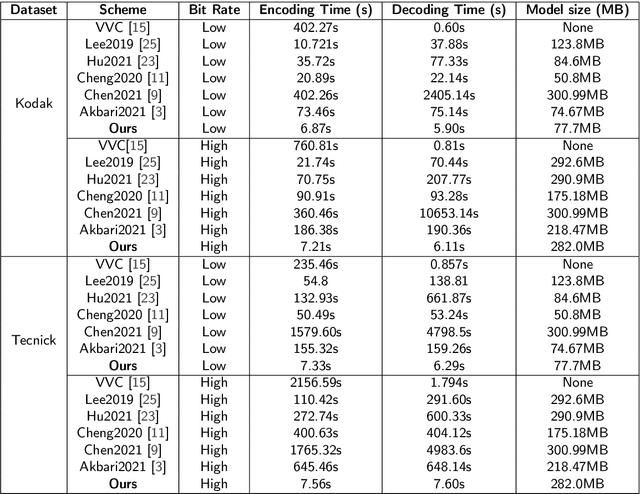
The application of the context-adaptive entropy model significantly improves the rate-distortion (R-D) performance, in which hyperpriors and autoregressive models are jointly utilized to effectively capture the spatial redundancy of the latent representations. However, the latent representations still contain some spatial correlations. In addition, these methods based on the context-adaptive entropy model cannot be accelerated in the decoding process by parallel computing devices, e.g. FPGA or GPU. To alleviate these limitations, we propose a learned multi-resolution image compression framework, which exploits the recently developed octave convolutions to factorize the latent representations into the high-resolution (HR) and low-resolution (LR) parts, similar to wavelet transform, which further improves the R-D performance. To speed up the decoding, our scheme does not use context-adaptive entropy model. Instead, we exploit an additional hyper layer including hyper encoder and hyper decoder to further remove the spatial redundancy of the latent representation. Moreover, the cross-resolution parameter estimation (CRPE) is introduced into the proposed framework to enhance the flow of information and further improve the rate-distortion performance. An additional information-fidelity loss is proposed to the total loss function to adjust the contribution of the LR part to the final bit stream. Experimental results show that our method separately reduces the decoding time by approximately 73.35 % and 93.44 % compared with that of state-of-the-art learned image compression methods, and the R-D performance is still better than H.266/VVC(4:2:0) and some learning-based methods on both PSNR and MS-SSIM metrics across a wide bit rates.
Learning Discriminative Representation via Metric Learning for Imbalanced Medical Image Classification
Jul 14, 2022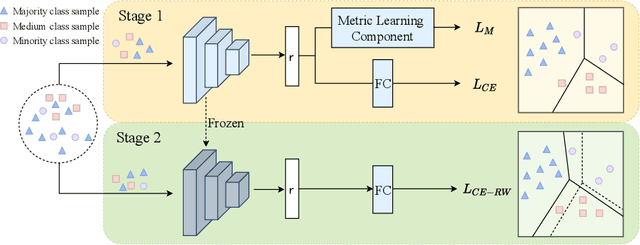

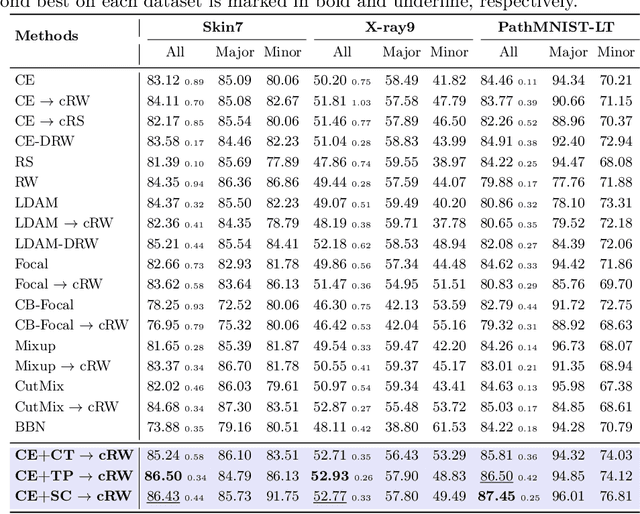
Data imbalance between common and rare diseases during model training often causes intelligent diagnosis systems to have biased predictions towards common diseases. The state-of-the-art approaches apply a two-stage learning framework to alleviate the class-imbalance issue, where the first stage focuses on training of a general feature extractor and the second stage focuses on fine-tuning the classifier head for class rebalancing. However, existing two-stage approaches do not consider the fine-grained property between different diseases, often causing the first stage less effective for medical image classification than for natural image classification tasks. In this study, we propose embedding metric learning into the first stage of the two-stage framework specially to help the feature extractor learn to extract more discriminative feature representations. Extensive experiments mainly on three medical image datasets show that the proposed approach consistently outperforms existing onestage and two-stage approaches, suggesting that metric learning can be used as an effective plug-in component in the two-stage framework for fine-grained class-imbalanced image classification tasks.
ESVIO: Event-based Stereo Visual Inertial Odometry
Dec 26, 2022
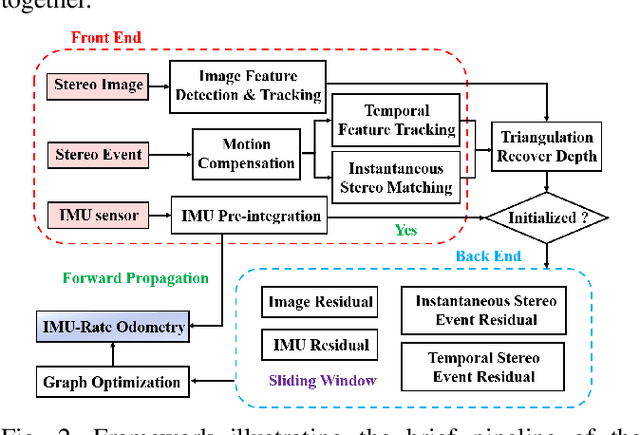
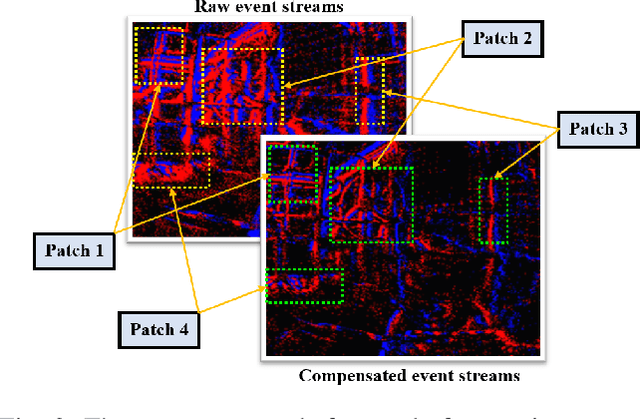
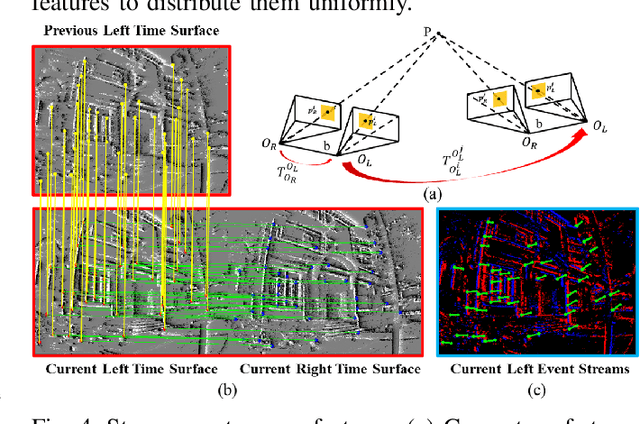
Event cameras that asynchronously output low-latency event streams provide great opportunities for state estimation under challenging situations. Despite event-based visual odometry having been extensively studied in recent years, most of them are based on monocular and few research on stereo event vision. In this paper, we present ESVIO, the first event-based stereo visual-inertial odometry, which leverages the complementary advantages of event streams, standard images and inertial measurements. Our proposed pipeline achieves temporal tracking and instantaneous matching between consecutive stereo event streams, thereby obtaining robust state estimation. In addition, the motion compensation method is designed to emphasize the edge of scenes by warping each event to reference moments with IMU and ESVIO back-end. We validate that both ESIO (purely event-based) and ESVIO (event with image-aided) have superior performance compared with other image-based and event-based baseline methods on public and self-collected datasets. Furthermore, we use our pipeline to perform onboard quadrotor flights under low-light environments. A real-world large-scale experiment is also conducted to demonstrate long-term effectiveness. We highlight that this work is a real-time, accurate system that is aimed at robust state estimation under challenging environments.
CLIP is Also an Efficient Segmenter: A Text-Driven Approach for Weakly Supervised Semantic Segmentation
Dec 20, 2022
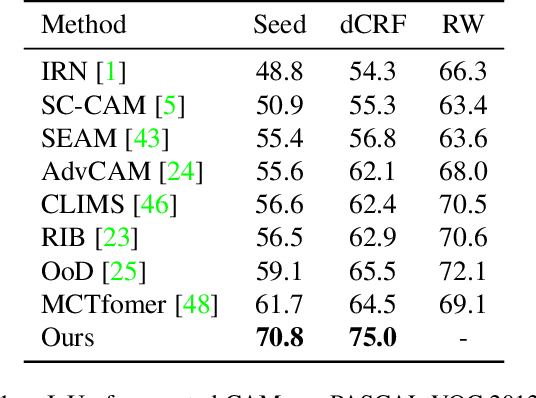
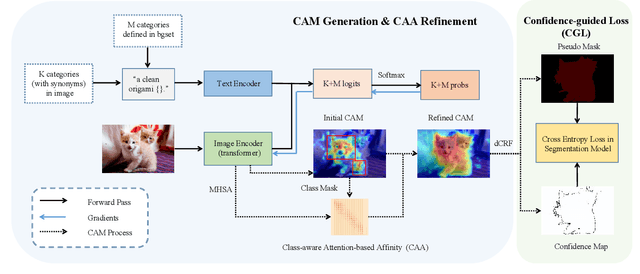
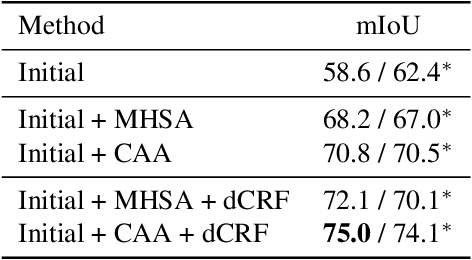
Weakly supervised semantic segmentation (WSSS) with image-level labels is a challenging task in computer vision. Mainstream approaches follow a multi-stage framework and suffer from high training costs. In this paper, we explore the potential of Contrastive Language-Image Pre-training models (CLIP) to localize different categories with only image-level labels and without any further training. To efficiently generate high-quality segmentation masks from CLIP, we propose a novel framework called CLIP-ES for WSSS. Our framework improves all three stages of WSSS with special designs for CLIP: 1) We introduce the softmax function into GradCAM and exploit the zero-shot ability of CLIP to suppress the confusion caused by non-target classes and backgrounds. Meanwhile, to take full advantage of CLIP, we re-explore text inputs under the WSSS setting and customize two text-driven strategies: sharpness-based prompt selection and synonym fusion. 2) To simplify the stage of CAM refinement, we propose a real-time class-aware attention-based affinity (CAA) module based on the inherent multi-head self-attention (MHSA) in CLIP-ViTs. 3) When training the final segmentation model with the masks generated by CLIP, we introduced a confidence-guided loss (CGL) to mitigate noise and focus on confident regions. Our proposed framework dramatically reduces the cost of training for WSSS and shows the capability of localizing objects in CLIP. Our CLIP-ES achieves SOTA performance on Pascal VOC 2012 and MS COCO 2014 while only taking 10% time of previous methods for the pseudo mask generation. Code is available at https://github.com/linyq2117/CLIP-ES.
Dynamic Grained Encoder for Vision Transformers
Jan 10, 2023
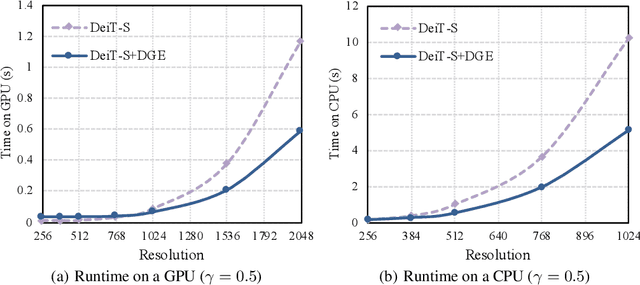
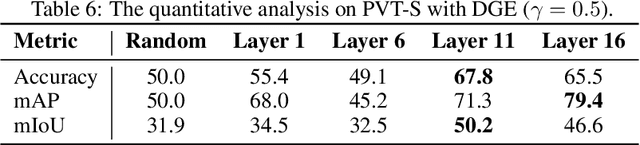
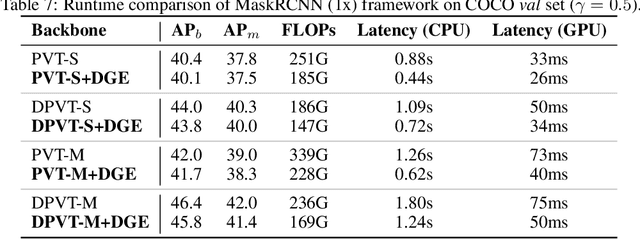
Transformers, the de-facto standard for language modeling, have been recently applied for vision tasks. This paper introduces sparse queries for vision transformers to exploit the intrinsic spatial redundancy of natural images and save computational costs. Specifically, we propose a Dynamic Grained Encoder for vision transformers, which can adaptively assign a suitable number of queries to each spatial region. Thus it achieves a fine-grained representation in discriminative regions while keeping high efficiency. Besides, the dynamic grained encoder is compatible with most vision transformer frameworks. Without bells and whistles, our encoder allows the state-of-the-art vision transformers to reduce computational complexity by 40%-60% while maintaining comparable performance on image classification. Extensive experiments on object detection and segmentation further demonstrate the generalizability of our approach. Code is available at https://github.com/StevenGrove/vtpack.
Deformer: Towards Displacement Field Learning for Unsupervised Medical Image Registration
Jul 07, 2022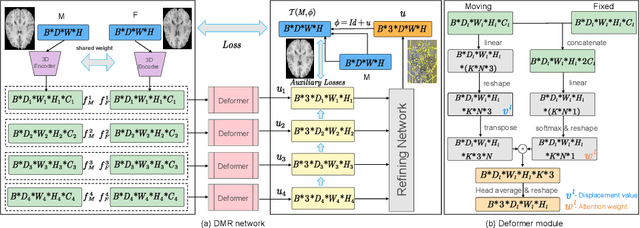
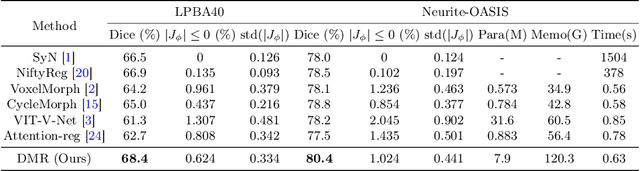
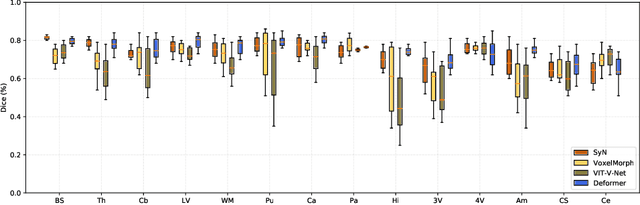
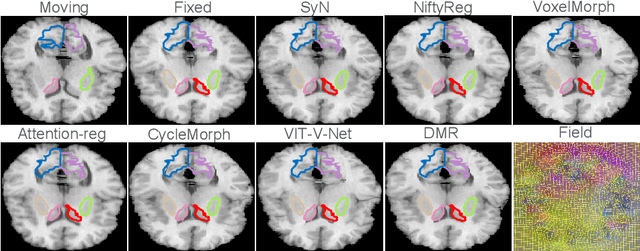
Recently, deep-learning-based approaches have been widely studied for deformable image registration task. However, most efforts directly map the composite image representation to spatial transformation through the convolutional neural network, ignoring its limited ability to capture spatial correspondence. On the other hand, Transformer can better characterize the spatial relationship with attention mechanism, its long-range dependency may be harmful to the registration task, where voxels with too large distances are unlikely to be corresponding pairs. In this study, we propose a novel Deformer module along with a multi-scale framework for the deformable image registration task. The Deformer module is designed to facilitate the mapping from image representation to spatial transformation by formulating the displacement vector prediction as the weighted summation of several bases. With the multi-scale framework to predict the displacement fields in a coarse-to-fine manner, superior performance can be achieved compared with traditional and learning-based approaches. Comprehensive experiments on two public datasets are conducted to demonstrate the effectiveness of the proposed Deformer module as well as the multi-scale framework.
On the Mathematics of Diffusion Models
Jan 25, 2023This paper attempts to present the stochastic differential equations of diffusion models in a manner that is accessible to a broad audience. The diffusion process is defined over a population density in R^d. Of particular interest is a population of images. In a diffusion model one first defines a diffusion process that takes a sample from the population and gradually adds noise until only noise remains. The fundamental idea is to sample from the population by a reverse-diffusion process mapping pure noise to a population sample. The diffusion process is defined independent of any ``interpretation'' but can be analyzed using the mathematics of variational auto-encoders (the ``VAE interpretation'') or the Fokker-Planck equation (the ``score-matching intgerpretation''). Both analyses yield reverse-diffusion methods involving the score function. The Fokker-Planck analysis yields a family of reverse-diffusion SDEs parameterized by any desired level of reverse-diffusion noise including zero (deterministic reverse-diffusion). The VAE analysis yields the reverse-diffusion SDE at the same noise level as the diffusion SDE. The VAE analysis also yields a useful expression for computing the population probabilities of a given point (image). This formula for the probability of a given point does not seem to follow naturally from the Fokker-Planck analysis. Much, but apparently not all, of the mathematics presented here can be found in the literature. Attributions are given at the end of the paper.
Rate-Perception Optimized Preprocessing for Video Coding
Jan 25, 2023
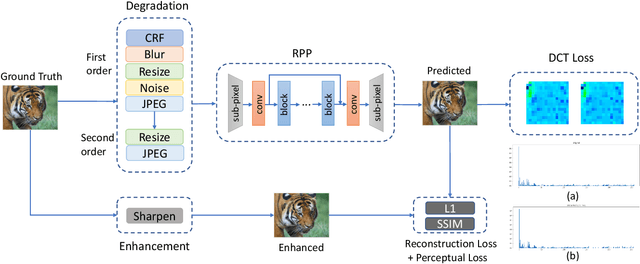

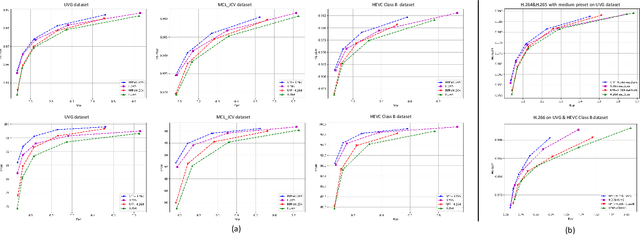
In the past decades, lots of progress have been done in the video compression field including traditional video codec and learning-based video codec. However, few studies focus on using preprocessing techniques to improve the rate-distortion performance. In this paper, we propose a rate-perception optimized preprocessing (RPP) method. We first introduce an adaptive Discrete Cosine Transform loss function which can save the bitrate and keep essential high frequency components as well. Furthermore, we also combine several state-of-the-art techniques from low-level vision fields into our approach, such as the high-order degradation model, efficient lightweight network design, and Image Quality Assessment model. By jointly using these powerful techniques, our RPP approach can achieve on average, 16.27% bitrate saving with different video encoders like AVC, HEVC, and VVC under multiple quality metrics. In the deployment stage, our RPP method is very simple and efficient which is not required any changes in the setting of video encoding, streaming, and decoding. Each input frame only needs to make a single pass through RPP before sending into video encoders. In addition, in our subjective visual quality test, 87% of users think videos with RPP are better or equal to videos by only using the codec to compress, while these videos with RPP save about 12% bitrate on average. Our RPP framework has been integrated into the production environment of our video transcoding services which serve millions of users every day.
The Brain-Inspired Decoder for Natural Visual Image Reconstruction
Jul 18, 2022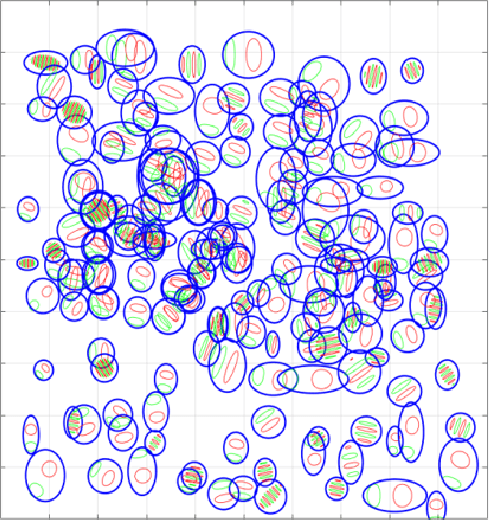
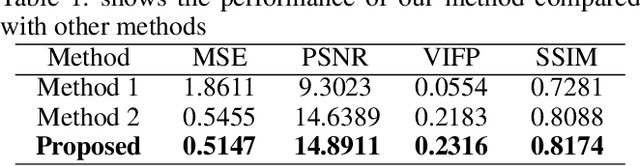

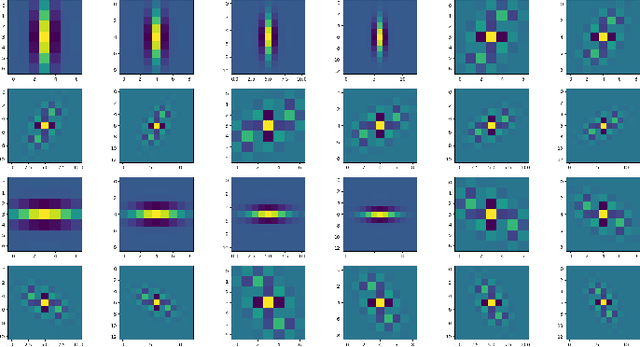
Decoding images from brain activity has been a challenge. Owing to the development of deep learning, there are available tools to solve this problem. The decoded image, which aims to map neural spike trains to low-level visual features and high-level semantic information space. Recently, there are a few studies of decoding from spike trains, however, these studies pay less attention to the foundations of neuroscience and there are few studies that merged receptive field into visual image reconstruction. In this paper, we propose a deep learning neural network architecture with biological properties to reconstruct visual image from spike trains. As far as we know, we implemented a method that integrated receptive field property matrix into loss function at the first time. Our model is an end-to-end decoder from neural spike trains to images. We not only merged Gabor filter into auto-encoder which used to generate images but also proposed a loss function with receptive field properties. We evaluated our decoder on two datasets which contain macaque primary visual cortex neural spikes and salamander retina ganglion cells (RGCs) spikes. Our results show that our method can effectively combine receptive field features to reconstruct images, providing a new approach to visual reconstruction based on neural information.