 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
INFWIDE: Image and Feature Space Wiener Deconvolution Network for Non-blind Image Deblurring in Low-Light Conditions
Jul 17, 2022

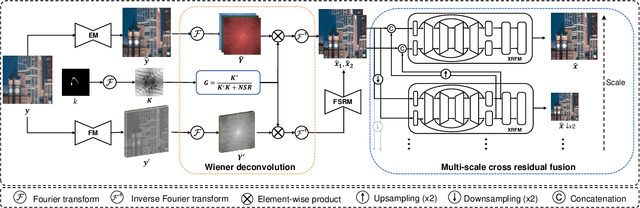
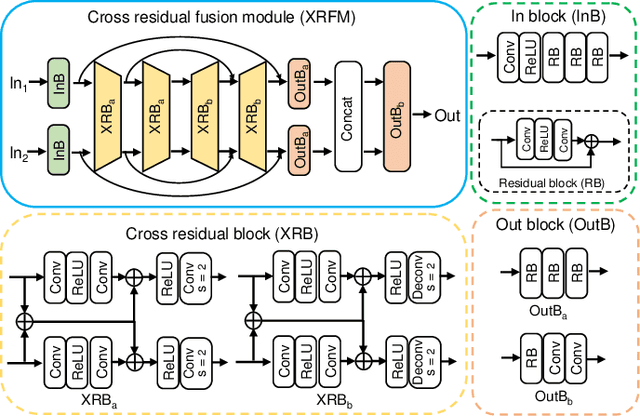

Under low-light environment, handheld photography suffers from severe camera shake under long exposure settings. Although existing deblurring algorithms have shown promising performance on well-exposed blurry images, they still cannot cope with low-light snapshots. Sophisticated noise and saturation regions are two dominating challenges in practical low-light deblurring. In this work, we propose a novel non-blind deblurring method dubbed image and feature space Wiener deconvolution network (INFWIDE) to tackle these problems systematically. In terms of algorithm design, INFWIDE proposes a two-branch architecture, which explicitly removes noise and hallucinates saturated regions in the image space and suppresses ringing artifacts in the feature space, and integrates the two complementary outputs with a subtle multi-scale fusion network for high quality night photograph deblurring. For effective network training, we design a set of loss functions integrating a forward imaging model and backward reconstruction to form a close-loop regularization to secure good convergence of the deep neural network. Further, to optimize INFWIDE's applicability in real low-light conditions, a physical-process-based low-light noise model is employed to synthesize realistic noisy night photographs for model training. Taking advantage of the traditional Wiener deconvolution algorithm's physically driven characteristics and arisen deep neural network's representation ability, INFWIDE can recover fine details while suppressing the unpleasant artifacts during deblurring. Extensive experiments on synthetic data and real data demonstrate the superior performance of the proposed approach.
Robust Deep Ensemble Method for Real-world Image Denoising
Jun 08, 2022

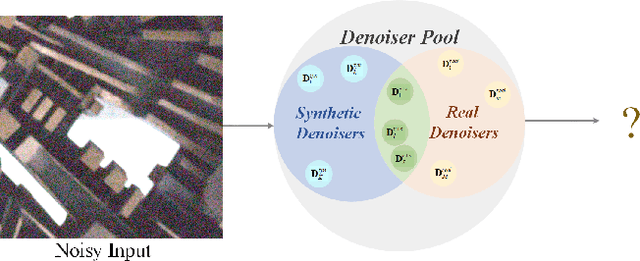
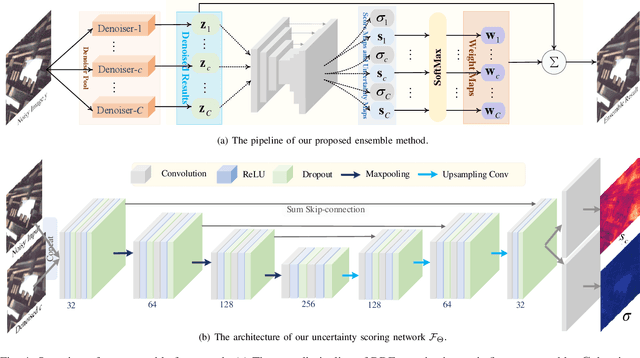
Recently, deep learning-based image denoising methods have achieved promising performance on test data with the same distribution as training set, where various denoising models based on synthetic or collected real-world training data have been learned. However, when handling real-world noisy images, the denoising performance is still limited. In this paper, we propose a simple yet effective Bayesian deep ensemble (BDE) method for real-world image denoising, where several representative deep denoisers pre-trained with various training data settings can be fused to improve robustness. The foundation of BDE is that real-world image noises are highly signal-dependent, and heterogeneous noises in a real-world noisy image can be separately handled by different denoisers. In particular, we take well-trained CBDNet, NBNet, HINet, Uformer and GMSNet into denoiser pool, and a U-Net is adopted to predict pixel-wise weighting maps to fuse these denoisers. Instead of solely learning pixel-wise weighting maps, Bayesian deep learning strategy is introduced to predict weighting uncertainty as well as weighting map, by which prediction variance can be modeled for improving robustness on real-world noisy images. Extensive experiments have shown that real-world noises can be better removed by fusing existing denoisers instead of training a big denoiser with expensive cost. On DND dataset, our BDE achieves +0.28~dB PSNR gain over the state-of-the-art denoising method. Moreover, we note that our BDE denoiser based on different Gaussian noise levels outperforms state-of-the-art CBDNet when applying to real-world noisy images. Furthermore, our BDE can be extended to other image restoration tasks, and achieves +0.30dB, +0.18dB and +0.12dB PSNR gains on benchmark datasets for image deblurring, image deraining and single image super-resolution, respectively.
Vision-Based Environmental Perception for Autonomous Driving
Dec 22, 2022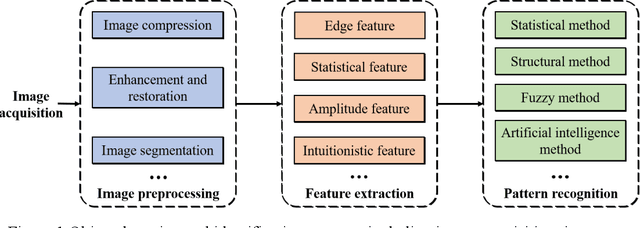
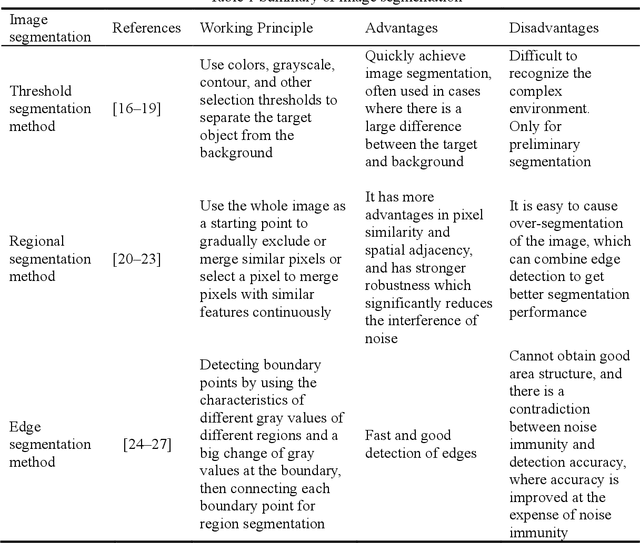

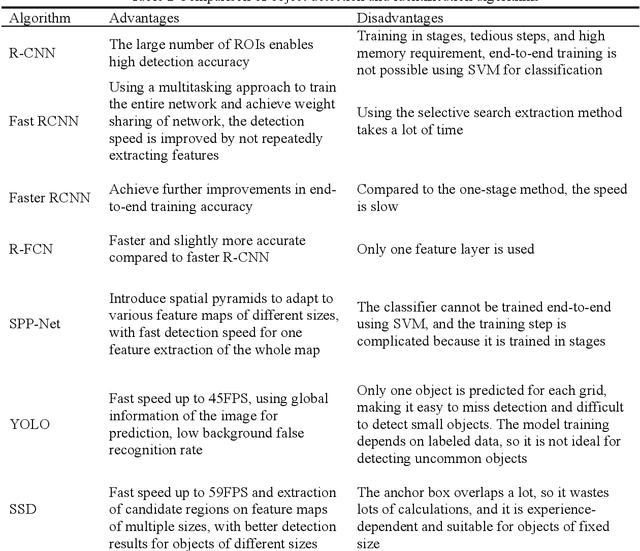
Visual perception plays an important role in autonomous driving. One of the primary tasks is object detection and identification. Since the vision sensor is rich in color and texture information, it can quickly and accurately identify various road information. The commonly used technique is based on extracting and calculating various features of the image. The recent development of deep learning-based method has better reliability and processing speed and has a greater advantage in recognizing complex elements. For depth estimation, vision sensor is also used for ranging due to their small size and low cost. Monocular camera uses image data from a single viewpoint as input to estimate object depth. In contrast, stereo vision is based on parallax and matching feature points of different views, and the application of deep learning also further improves the accuracy. In addition, Simultaneous Location and Mapping (SLAM) can establish a model of the road environment, thus helping the vehicle perceive the surrounding environment and complete the tasks. In this paper, we introduce and compare various methods of object detection and identification, then explain the development of depth estimation and compare various methods based on monocular, stereo, and RDBG sensors, next review and compare various methods of SLAM, and finally summarize the current problems and present the future development trends of vision technologies.
Line Drawing Guided Progressive Inpainting of Mural Damages
Nov 12, 2022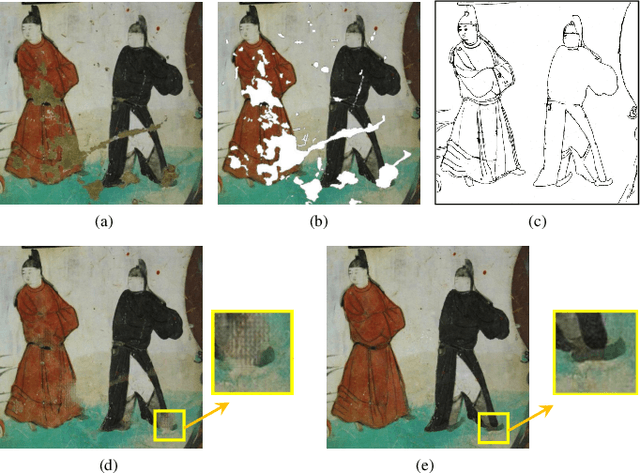

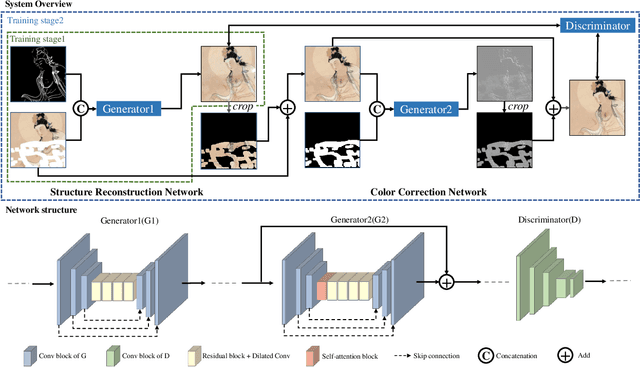

Mural image inpainting refers to repairing the damage or missing areas in a mural image to restore the visual appearance. Most existing image-inpainting methods tend to take a target image as the only input and directly repair the damage to generate a visually plausible result. These methods obtain high performance in restoration or completion of some specific objects, e.g., human face, fabric texture, and printed texts, etc., however, are not suitable for repairing murals with varied subjects, especially for murals with large damaged areas. Moreover, due to the discrete colors in paints, mural inpainting may suffer from apparent color bias as compared to natural image inpainting. To this end, in this paper, we propose a line drawing guided progressive mural inpainting method. It divides the inpainting process into two steps: structure reconstruction and color correction, executed by a structure reconstruction network (SRN) and a color correction network (CCN), respectively. In the structure reconstruction, line drawings are used by SRN as a guarantee for large-scale content authenticity and structural stability. In the color correction, CCN operates a local color adjustment for missing pixels which reduces the negative effects of color bias and edge jumping. The proposed approach is evaluated against the current state-of-the-art image inpainting methods. Qualitative and quantitative results demonstrate the superiority of the proposed method in mural image inpainting. The codes and data are available at {https://github.com/qinnzou/mural-image-inpainting}.
PoET: Pose Estimation Transformer for Single-View, Multi-Object 6D Pose Estimation
Nov 25, 2022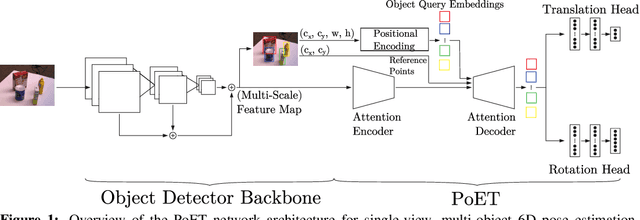
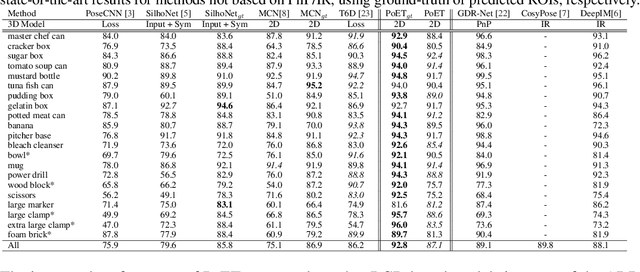

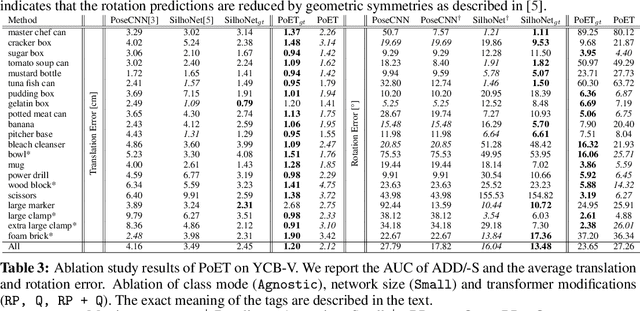
Accurate 6D object pose estimation is an important task for a variety of robotic applications such as grasping or localization. It is a challenging task due to object symmetries, clutter and occlusion, but it becomes more challenging when additional information, such as depth and 3D models, is not provided. We present a transformer-based approach that takes an RGB image as input and predicts a 6D pose for each object in the image. Besides the image, our network does not require any additional information such as depth maps or 3D object models. First, the image is passed through an object detector to generate feature maps and to detect objects. Then, the feature maps are fed into a transformer with the detected bounding boxes as additional information. Afterwards, the output object queries are processed by a separate translation and rotation head. We achieve state-of-the-art results for RGB-only approaches on the challenging YCB-V dataset. We illustrate the suitability of the resulting model as pose sensor for a 6-DoF state estimation task. Code is available at https://github.com/aau-cns/poet.
Deep Image Retrieval is not Robust to Label Noise
May 23, 2022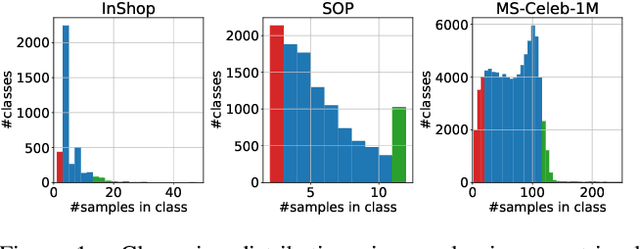
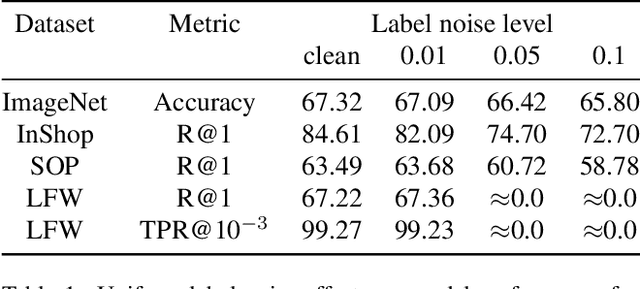
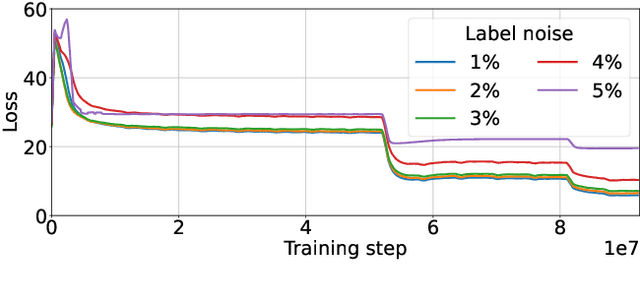
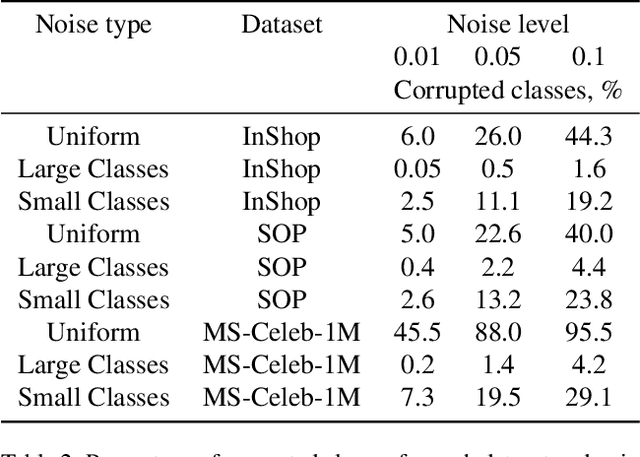
Large-scale datasets are essential for the success of deep learning in image retrieval. However, manual assessment errors and semi-supervised annotation techniques can lead to label noise even in popular datasets. As previous works primarily studied annotation quality in image classification tasks, it is still unclear how label noise affects deep learning approaches to image retrieval. In this work, we show that image retrieval methods are less robust to label noise than image classification ones. Furthermore, we, for the first time, investigate different types of label noise specific to image retrieval tasks and study their effect on model performance.
Adaptively-Realistic Image Generation from Stroke and Sketch with Diffusion Model
Sep 01, 2022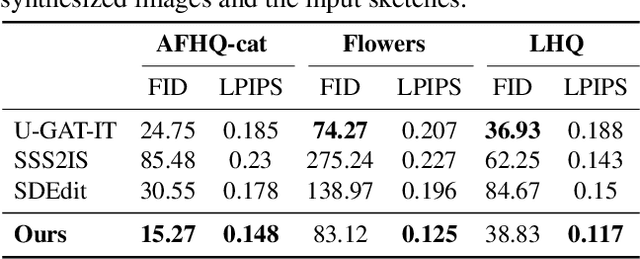
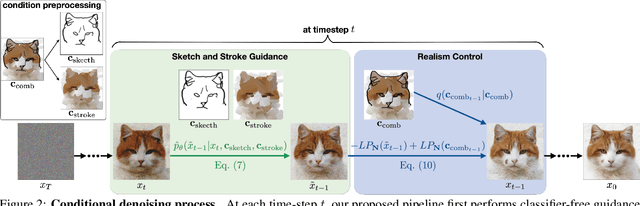

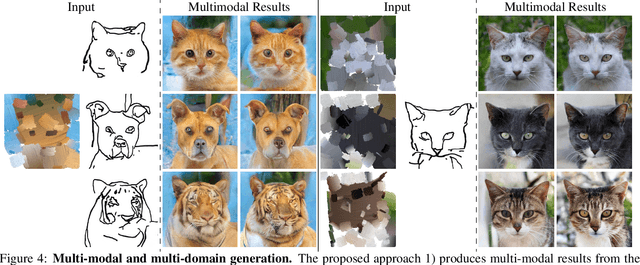
Generating images from hand-drawings is a crucial and fundamental task in content creation. The translation is difficult as there exist infinite possibilities and the different users usually expect different outcomes. Therefore, we propose a unified framework supporting a three-dimensional control over the image synthesis from sketches and strokes based on diffusion models. Users can not only decide the level of faithfulness to the input strokes and sketches, but also the degree of realism, as the user inputs are usually not consistent with the real images. Qualitative and quantitative experiments demonstrate that our framework achieves state-of-the-art performance while providing flexibility in generating customized images with control over shape, color, and realism. Moreover, our method unleashes applications such as editing on real images, generation with partial sketches and strokes, and multi-domain multi-modal synthesis.
GR-GAN: Gradual Refinement Text-to-image Generation
May 23, 2022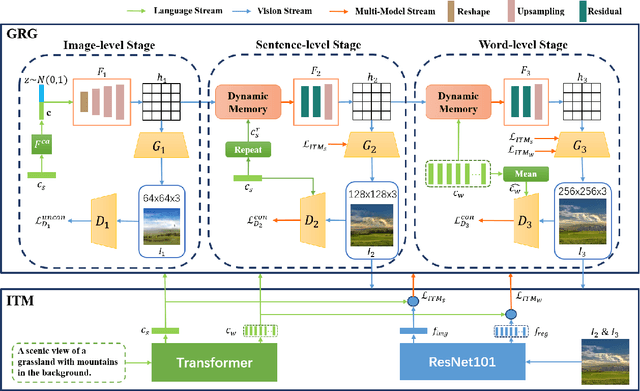
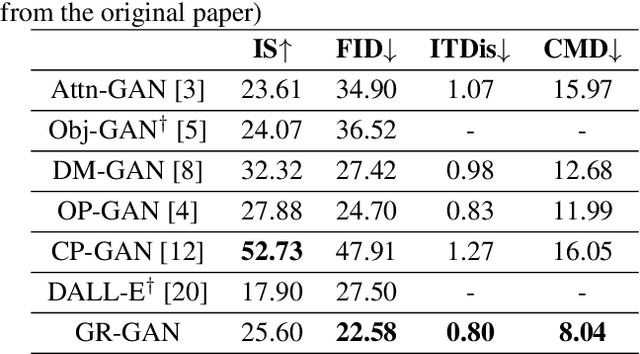

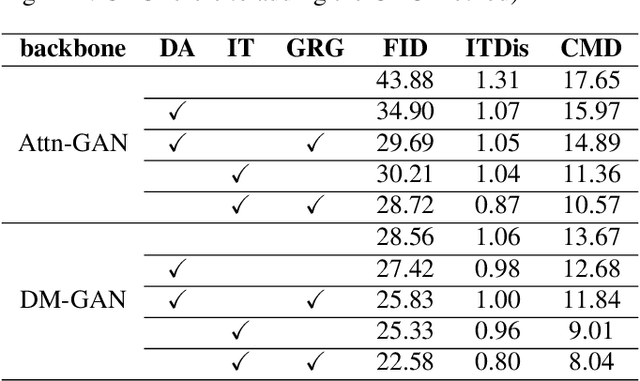
A good Text-to-Image model should not only generate high quality images, but also ensure the consistency between the text and the generated image. Previous models failed to simultaneously fix both sides well. This paper proposes a Gradual Refinement Generative Adversarial Network (GR-GAN) to alleviates the problem efficiently. A GRG module is designed to generate images from low resolution to high resolution with the corresponding text constraints from coarse granularity (sentence) to fine granularity (word) stage by stage, a ITM module is designed to provide image-text matching losses at both sentence-image level and word-region level for corresponding stages. We also introduce a new metric Cross-Model Distance (CMD) for simultaneously evaluating image quality and image-text consistency. Experimental results show GR-GAN significant outperform previous models, and achieve new state-of-the-art on both FID and CMD. A detailed analysis demonstrates the efficiency of different generation stages in GR-GAN.
Rethinking Implicit Neural Representations for Vision Learners
Nov 23, 2022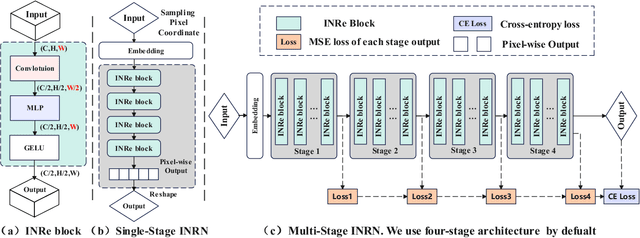
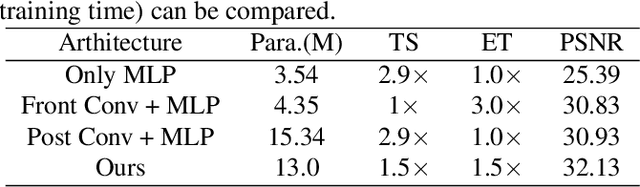
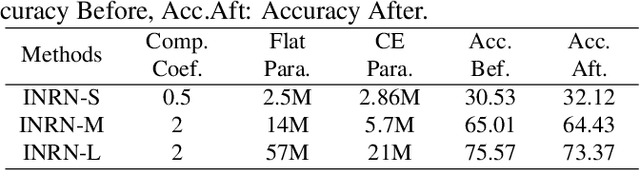

Implicit Neural Representations (INRs) are powerful to parameterize continuous signals in computer vision. However, almost all INRs methods are limited to low-level tasks, e.g., image/video compression, super-resolution, and image generation. The questions on how to explore INRs to high-level tasks and deep networks are still under-explored. Existing INRs methods suffer from two problems: 1) narrow theoretical definitions of INRs are inapplicable to high-level tasks; 2) lack of representation capabilities to deep networks. Motivated by the above facts, we reformulate the definitions of INRs from a novel perspective and propose an innovative Implicit Neural Representation Network (INRN), which is the first study of INRs to tackle both low-level and high-level tasks. Specifically, we present three key designs for basic blocks in INRN along with two different stacking ways and corresponding loss functions. Extensive experiments with analysis on both low-level tasks (image fitting) and high-level vision tasks (image classification, object detection, instance segmentation) demonstrate the effectiveness of the proposed method.
Measuring Annotator Agreement Generally across Complex Structured, Multi-object, and Free-text Annotation Tasks
Dec 15, 2022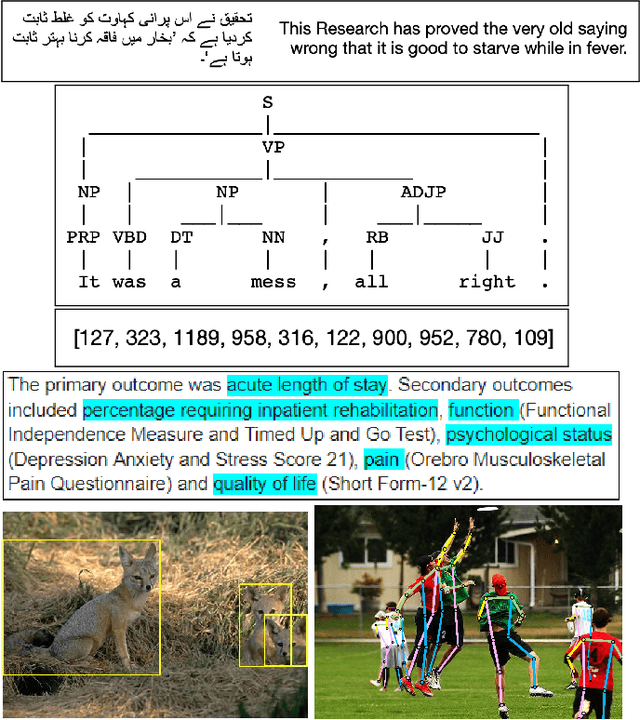
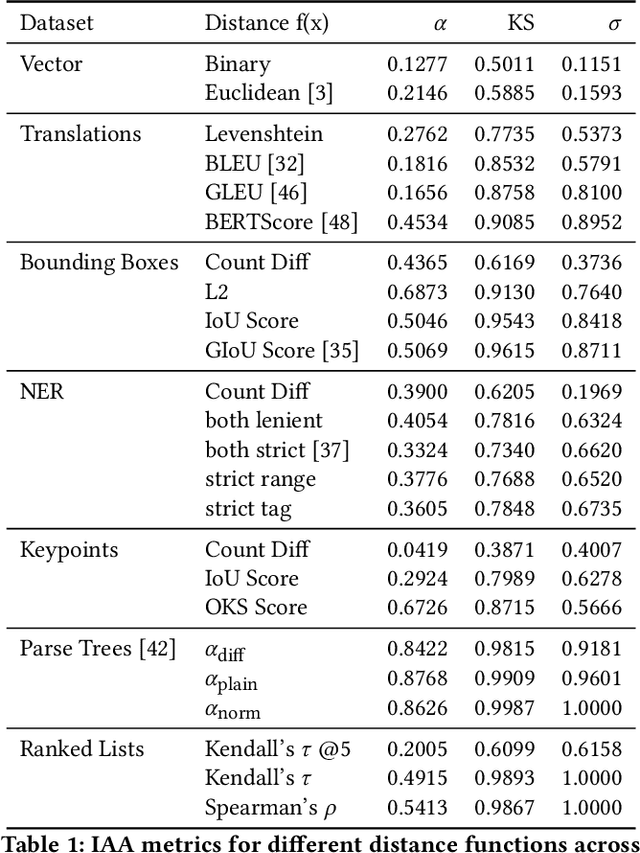
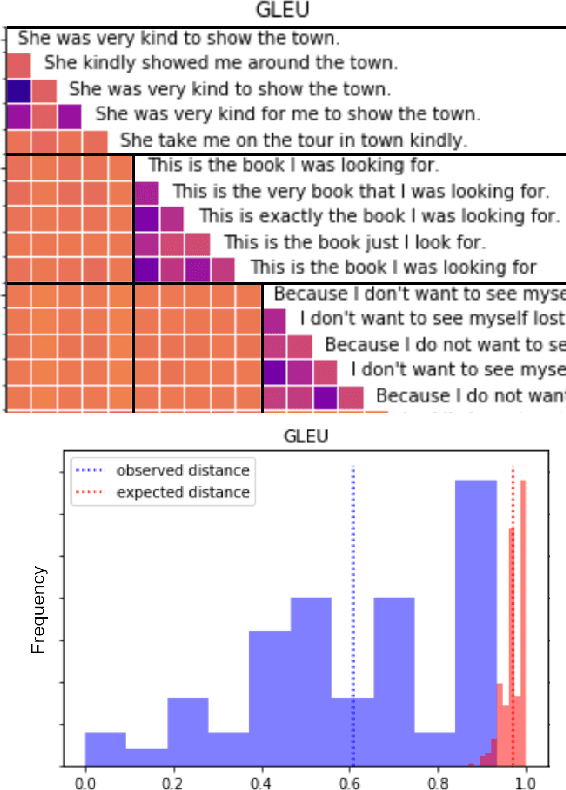
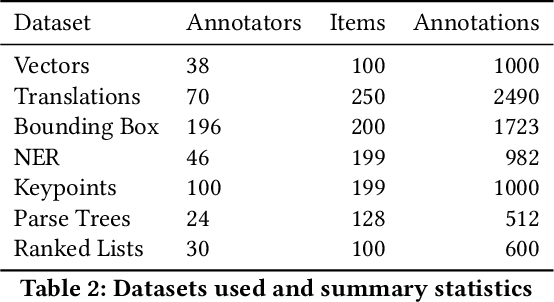
When annotators label data, a key metric for quality assurance is inter-annotator agreement (IAA): the extent to which annotators agree on their labels. Though many IAA measures exist for simple categorical and ordinal labeling tasks, relatively little work has considered more complex labeling tasks, such as structured, multi-object, and free-text annotations. Krippendorff's alpha, best known for use with simpler labeling tasks, does have a distance-based formulation with broader applicability, but little work has studied its efficacy and consistency across complex annotation tasks. We investigate the design and evaluation of IAA measures for complex annotation tasks, with evaluation spanning seven diverse tasks: image bounding boxes, image keypoints, text sequence tagging, ranked lists, free text translations, numeric vectors, and syntax trees. We identify the difficulty of interpretability and the complexity of choosing a distance function as key obstacles in applying Krippendorff's alpha generally across these tasks. We propose two novel, more interpretable measures, showing they yield more consistent IAA measures across tasks and annotation distance functions.