 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Attentive Mask CLIP
Dec 16, 2022
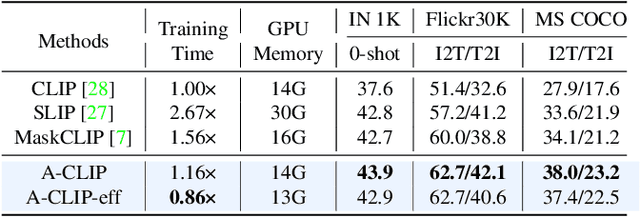
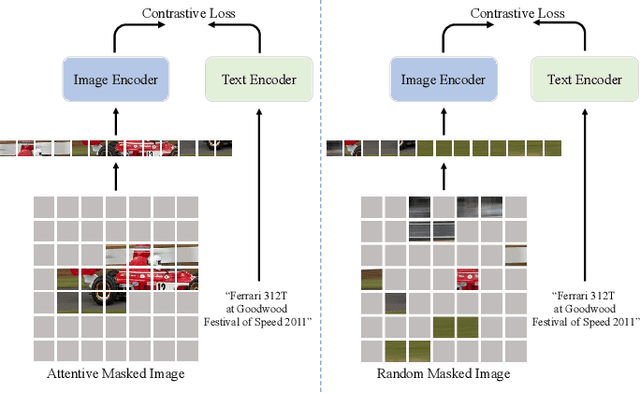
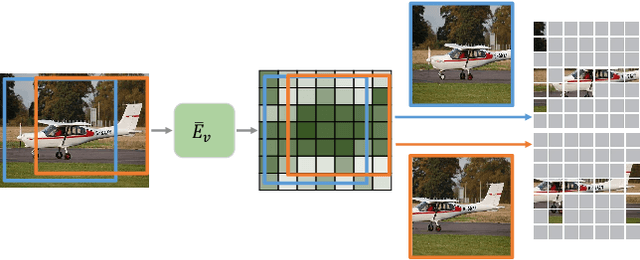
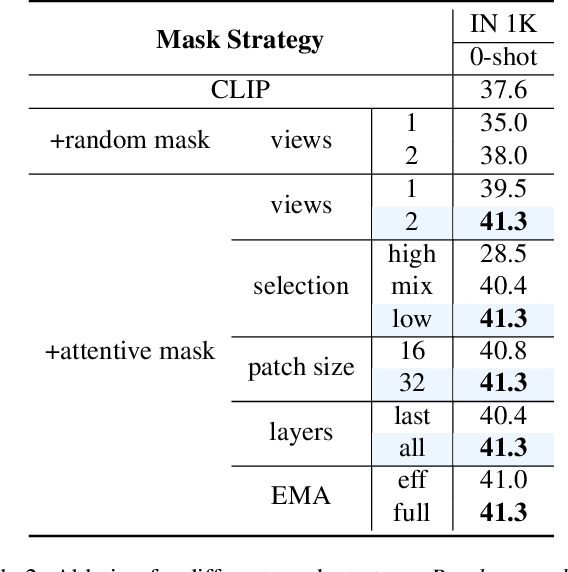
Image token removal is an efficient augmentation strategy for reducing the cost of computing image features. However, this efficient augmentation strategy has been found to adversely affect the accuracy of CLIP-based training. We hypothesize that removing a large portion of image tokens may improperly discard the semantic content associated with a given text description, thus constituting an incorrect pairing target in CLIP training. To address this issue, we propose an attentive token removal approach for CLIP training, which retains tokens with a high semantic correlation to the text description. The correlation scores are computed in an online fashion using the EMA version of the visual encoder. Our experiments show that the proposed attentive masking approach performs better than the previous method of random token removal for CLIP training. The approach also makes it efficient to apply multiple augmentation views to the image, as well as introducing instance contrastive learning tasks between these views into the CLIP framework. Compared to other CLIP improvements that combine different pre-training targets such as SLIP and MaskCLIP, our method is not only more effective, but also much more efficient. Specifically, using ViT-B and YFCC-15M dataset, our approach achieves $43.9\%$ top-1 accuracy on ImageNet-1K zero-shot classification, as well as $62.7/42.1$ and $38.0/23.2$ I2T/T2I retrieval accuracy on Flickr30K and MS COCO, which are $+1.1\%$, $+5.5/+0.9$, and $+4.4/+1.3$ higher than the SLIP method, while being $2.30\times$ faster. An efficient version of our approach running $1.16\times$ faster than the plain CLIP model achieves significant gains of $+5.3\%$, $+11.3/+8.0$, and $+9.5/+4.9$ on these benchmarks.
SALVE: Self-supervised Adaptive Low-light Video Enhancement
Dec 22, 2022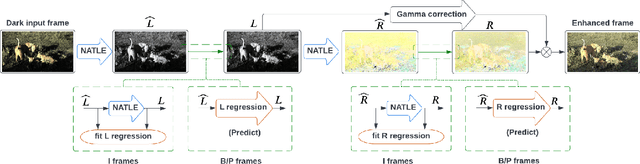
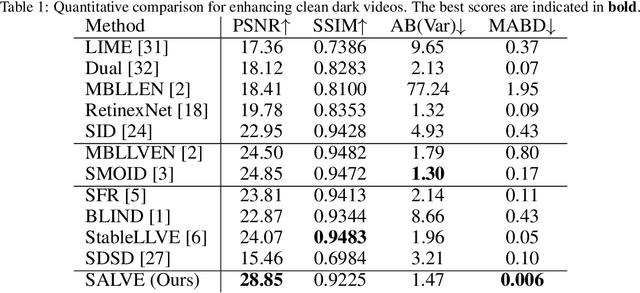

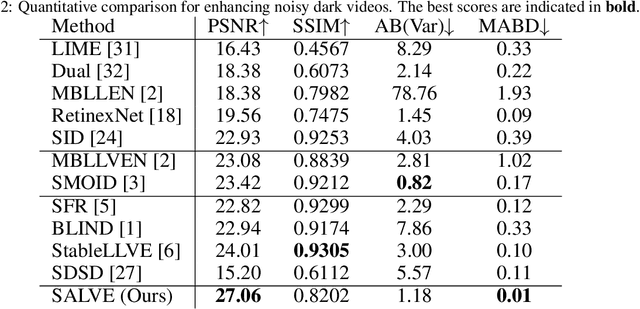
A self-supervised adaptive low-light video enhancement (SALVE) method is proposed in this work. SALVE first conducts an effective Retinex-based low-light image enhancement on a few key frames of an input low-light video. Next, it learns mappings from the low- to enhanced-light frames via Ridge regression. Finally, it uses these mappings to enhance the remaining frames in the input video. SALVE is a hybrid method that combines components from a traditional Retinex-based image enhancement method and a learning-based method. The former component leads to a robust solution which is easily adaptive to new real-world environments. The latter component offers a fast, computationally inexpensive and temporally consistent solution. We conduct extensive experiments to show the superior performance of SALVE. Our user study shows that 87% of participants prefer SALVE over prior work.
Monocular 3D Object Detection using Multi-Stage Approaches with Attention and Slicing aided hyper inference
Dec 22, 2022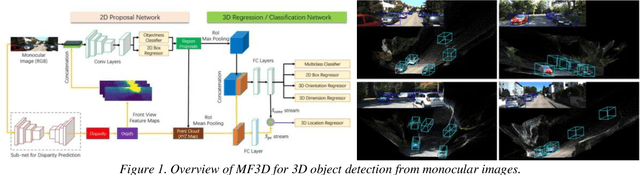
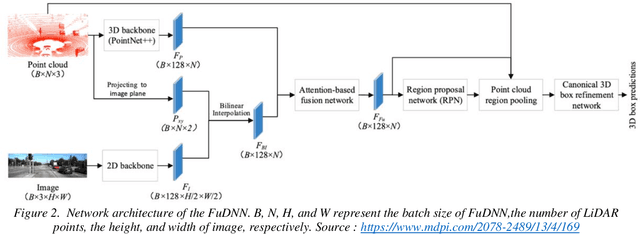
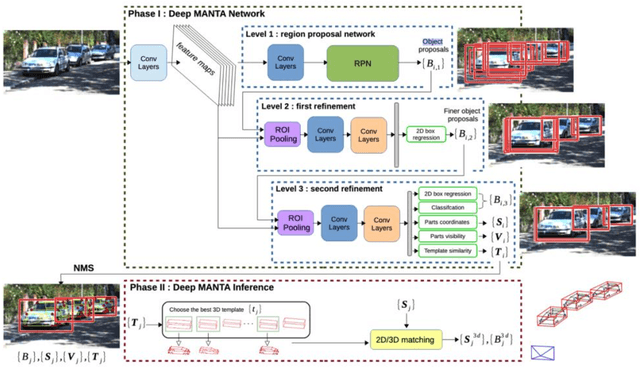
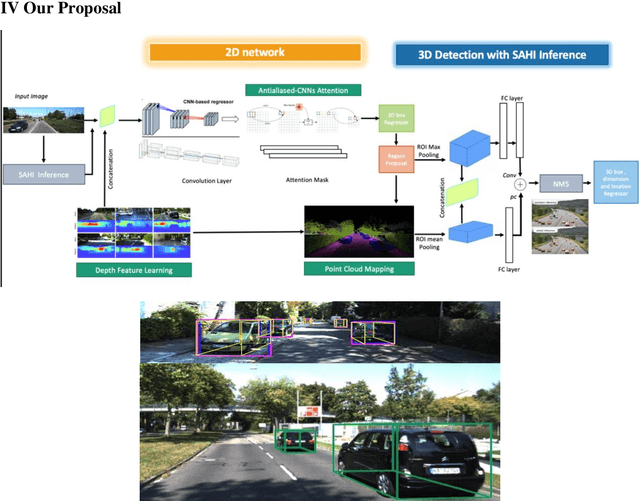
3D object detection is vital as it would enable us to capture objects' sizes, orientation, and position in the world. As a result, we would be able to use this 3D detection in real-world applications such as Augmented Reality (AR), self-driving cars, and robotics which perceive the world the same way we do as humans. Monocular 3D Object Detection is the task to draw 3D bounding box around objects in a single 2D RGB image. It is localization task but without any extra information like depth or other sensors or multiple images. Monocular 3D object detection is an important yet challenging task. Beyond the significant progress in image-based 2D object detection, 3D understanding of real-world objects is an open challenge that has not been explored extensively thus far. In addition to the most closely related studies.
Seafloor-Invariant Caustics Removal from Underwater Imagery
Dec 20, 2022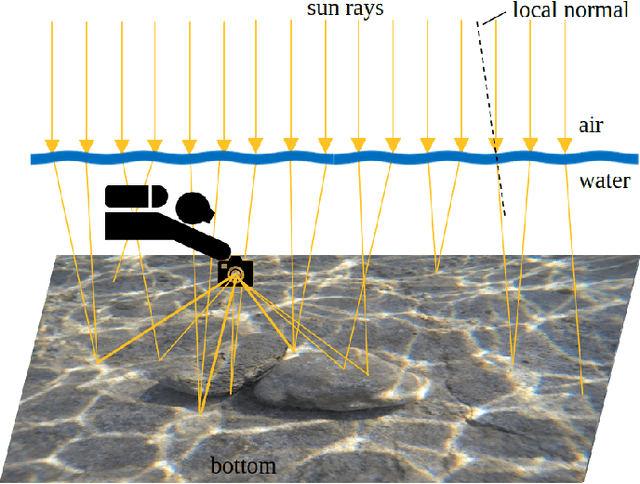


Mapping the seafloor with underwater imaging cameras is of significant importance for various applications including marine engineering, geology, geomorphology, archaeology and biology. For shallow waters, among the underwater imaging challenges, caustics i.e., the complex physical phenomena resulting from the projection of light rays being refracted by the wavy surface, is likely the most crucial one. Caustics is the main factor during underwater imaging campaigns that massively degrade image quality and affect severely any 2D mosaicking or 3D reconstruction of the seabed. In this work, we propose a novel method for correcting the radiometric effects of caustics on shallow underwater imagery. Contrary to the state-of-the-art, the developed method can handle seabed and riverbed of any anaglyph, correcting the images using real pixel information, thus, improving image matching and 3D reconstruction processes. In particular, the developed method employs deep learning architectures in order to classify image pixels to "non-caustics" and "caustics". Then, exploits the 3D geometry of the scene to achieve a pixel-wise correction, by transferring appropriate color values between the overlapping underwater images. Moreover, to fill the current gap, we have collected, annotated and structured a real-world caustic dataset, namely R-CAUSTIC, which is openly available. Overall, based on the experimental results and validation the developed methodology is quite promising in both detecting caustics and reconstructing their intensity.
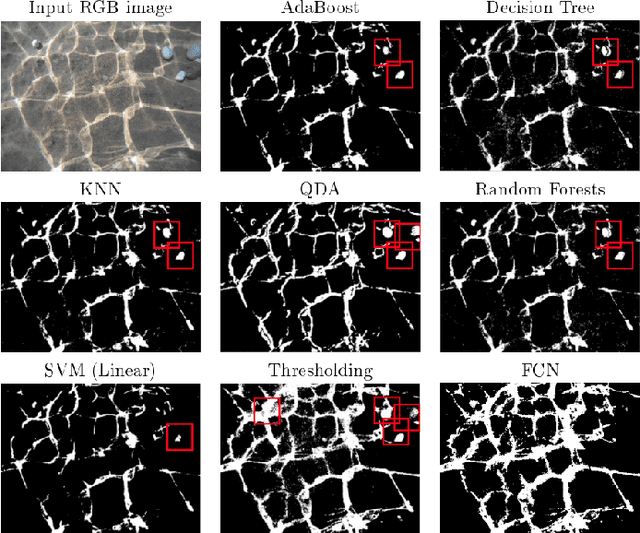
DeepCut: Unsupervised Segmentation using Graph Neural Networks Clustering
Dec 18, 2022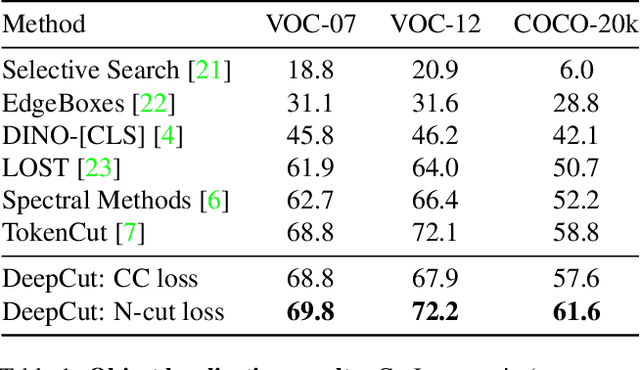
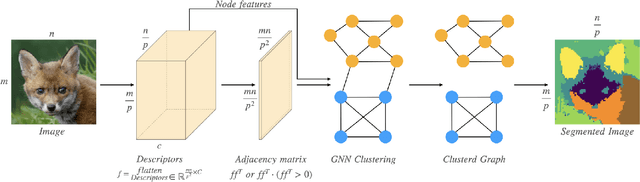
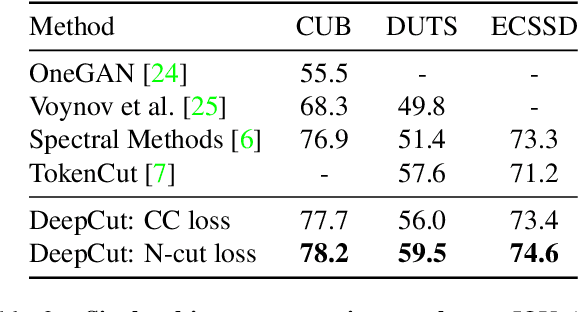

Image segmentation is a fundamental task in computer vision. Data annotation for training supervised methods can be labor-intensive, motivating unsupervised methods. Some existing approaches extract deep features from pre-trained networks and build a graph to apply classical clustering methods (e.g., $k$-means and normalized-cuts) as a post-processing stage. These techniques reduce the high-dimensional information encoded in the features to pair-wise scalar affinities. In this work, we replace classical clustering algorithms with a lightweight Graph Neural Network (GNN) trained to achieve the same clustering objective function. However, in contrast to existing approaches, we feed the GNN not only the pair-wise affinities between local image features but also the raw features themselves. Maintaining this connection between the raw feature and the clustering goal allows to perform part semantic segmentation implicitly, without requiring additional post-processing steps. We demonstrate how classical clustering objectives can be formulated as self-supervised loss functions for training our image segmentation GNN. Additionally, we use the Correlation-Clustering (CC) objective to perform clustering without defining the number of clusters ($k$-less clustering). We apply the proposed method for object localization, segmentation, and semantic part segmentation tasks, surpassing state-of-the-art performance on multiple benchmarks.
[Work in progress] Scalable, out-of-the box segmentation of individual particles from mineral samples acquired with micro CT
Jan 30, 2023![Figure 1 for [Work in progress] Scalable, out-of-the box segmentation of individual particles from mineral samples acquired with micro CT](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Fdad1e0aecebde7831ba14d9096a9e0a14de30b07%2F3-Figure1-1.png&w=640&q=75)
![Figure 2 for [Work in progress] Scalable, out-of-the box segmentation of individual particles from mineral samples acquired with micro CT](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Fdad1e0aecebde7831ba14d9096a9e0a14de30b07%2F8-Table1-1.png&w=640&q=75)
![Figure 3 for [Work in progress] Scalable, out-of-the box segmentation of individual particles from mineral samples acquired with micro CT](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Fdad1e0aecebde7831ba14d9096a9e0a14de30b07%2F4-Figure2-1.png&w=640&q=75)
![Figure 4 for [Work in progress] Scalable, out-of-the box segmentation of individual particles from mineral samples acquired with micro CT](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Fdad1e0aecebde7831ba14d9096a9e0a14de30b07%2F8-Table2-1.png&w=640&q=75)
Minerals are indispensable for a functioning modern society. Yet, their supply is limited causing a need for optimizing their exploration and extraction both from ores and recyclable materials. Typically, these processes must be meticulously adapted to the precise properties of the processed particles, requiring an extensive characterization of their shapes, appearances as well as the overall material composition. Current approaches perform this analysis based on bulk segmentation and characterization of particles, and rely on rudimentary postprocessing techniques to separate touching particles. However, due to their inability to reliably perform this separation as well as the need to retrain or reconfigure most methods for each new image, these approaches leave untapped potential to be leveraged. Here, we propose an instance segmentation method that is able to extract individual particles from large micro CT images taken from mineral samples embedded in an epoxy matrix. Our approach is based on the powerful nnU-Net framework, introduces a particle size normalization, makes use of a border-core representation to enable instance segmentation and is trained with a large dataset containing particles of numerous different materials and minerals. We demonstrate that our approach can be applied out-of-the box to a large variety of particle types, including materials and appearances that have not been part of the training set. Thus, no further manual annotations and retraining are required when applying the method to new mineral samples, enabling substantially higher scalability of experiments than existing methods. Our code and dataset are made publicly available.
Flattening Surface Based On Using Contour Estimating Subdivision Surface
Dec 27, 2022

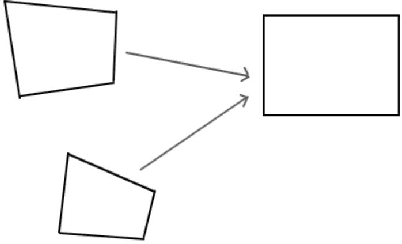

In the process of projecting the surface of a three-dimensional object onto a two-dimensional surface, due to the perspective distortion, the image on the surface of the object will have different degrees of distortion according to the level of the surface curvature. This paper presents an imprecise method for flattening this type of distortion on the surface of a regularly curved body. The main idea of this method is to roughly estimate the gridded surface subdivision that can be used to describe the surface of the three-dimensional object through the contour curve of the two-dimensional image of the object. Then, take each grid block with different sizes and shapes inversely transformed into a rectangle with exactly the same shape and size. Finally, each of the same rectangles is splicing and recombining in turn to obtain a roughly flat rectangle. This paper will introduce and show the specific process and results of using this method to solve the problem of bending page flattening, then demonstrate the feasibility and limitations of this method.
A novel adversarial learning strategy for medical image classification
Jun 26, 2022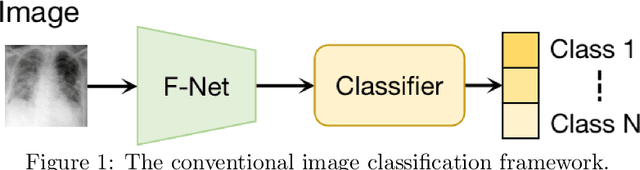
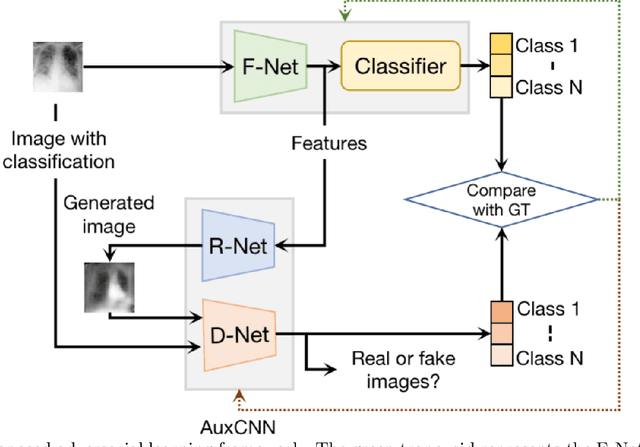
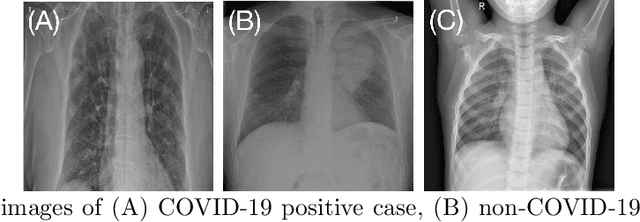
Deep learning (DL) techniques have been extensively utilized for medical image classification. Most DL-based classification networks are generally structured hierarchically and optimized through the minimization of a single loss function measured at the end of the networks. However, such a single loss design could potentially lead to optimization of one specific value of interest but fail to leverage informative features from intermediate layers that might benefit classification performance and reduce the risk of overfitting. Recently, auxiliary convolutional neural networks (AuxCNNs) have been employed on top of traditional classification networks to facilitate the training of intermediate layers to improve classification performance and robustness. In this study, we proposed an adversarial learning-based AuxCNN to support the training of deep neural networks for medical image classification. Two main innovations were adopted in our AuxCNN classification framework. First, the proposed AuxCNN architecture includes an image generator and an image discriminator for extracting more informative image features for medical image classification, motivated by the concept of generative adversarial network (GAN) and its impressive ability in approximating target data distribution. Second, a hybrid loss function is designed to guide the model training by incorporating different objectives of the classification network and AuxCNN to reduce overfitting. Comprehensive experimental studies demonstrated the superior classification performance of the proposed model. The effect of the network-related factors on classification performance was investigated.
Identity masking effectiveness and gesture recognition: Effects of eye enhancement in seeing through the mask
Jan 20, 2023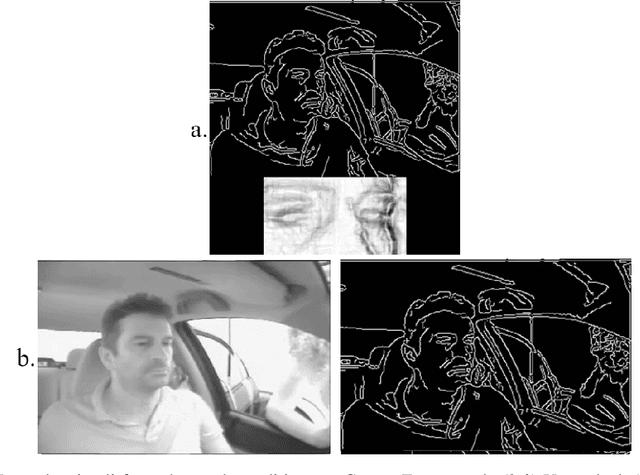

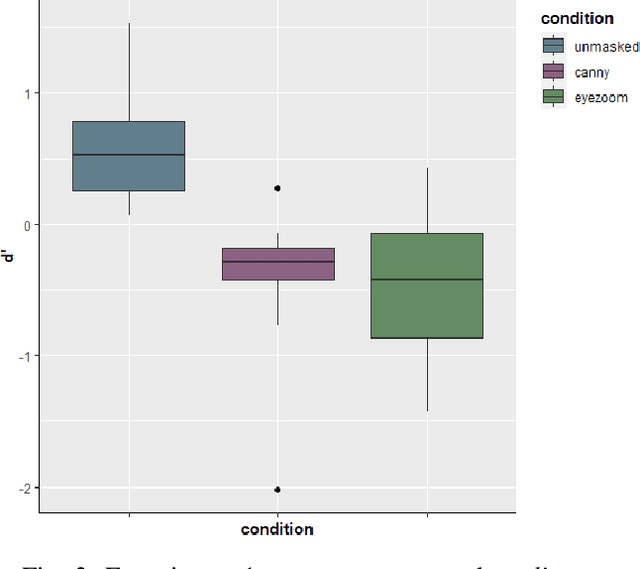
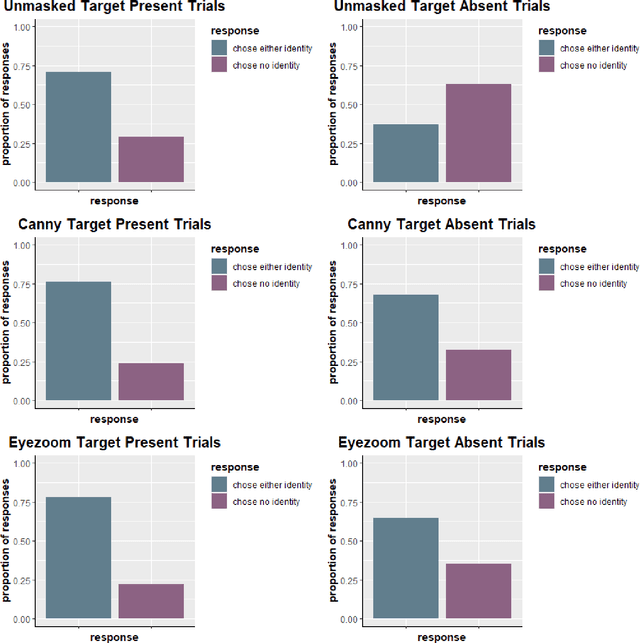
Face identity masking algorithms developed in recent years aim to protect the privacy of people in video recordings. These algorithms are designed to interfere with identification, while preserving information about facial actions. An important challenge is to preserve subtle actions in the eye region, while obscuring the salient identity cues from the eyes. We evaluated the effectiveness of identity-masking algorithms based on Canny filters, applied with and without eye enhancement, for interfering with identification and preserving facial actions. In Experiments 1 and 2, we tested human participants' ability to match the facial identity of a driver in a low resolution video to a high resolution facial image. Results showed that both masking methods impaired identification, and that eye enhancement did not alter the effectiveness of the Canny filter mask. In Experiment 3, we tested action preservation and found that neither method interfered significantly with driver action perception. We conclude that relatively simple, filter-based masking algorithms, which are suitable for application to low quality video, can be used in privacy protection without compromising action perception.
Octuplet Loss: Make Face Recognition Robust to Image Resolution
Jul 14, 2022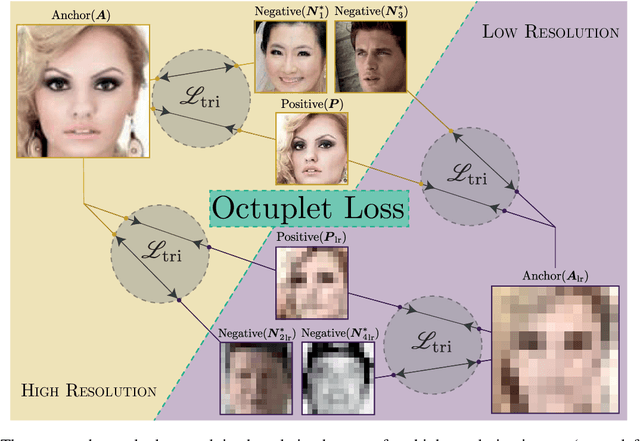
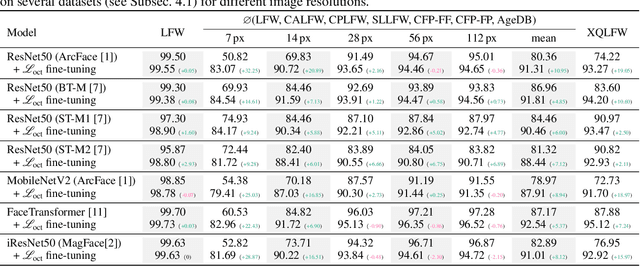
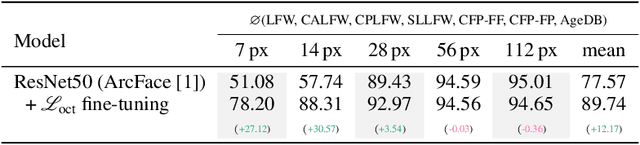
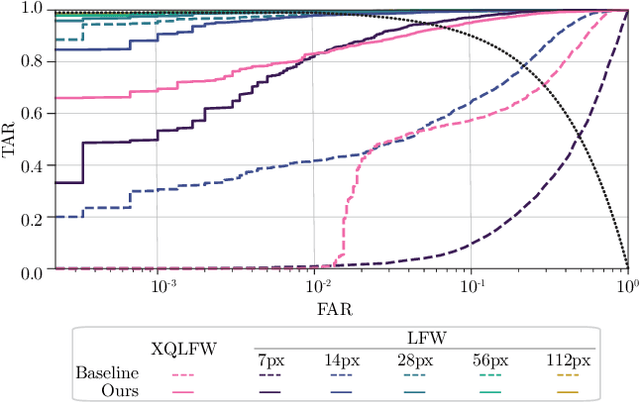
Image resolution, or in general, image quality, plays an essential role in the performance of today's face recognition systems. To address this problem, we propose a novel combination of the popular triplet loss to improve robustness against image resolution via fine-tuning of existing face recognition models. With octuplet loss, we leverage the relationship between high-resolution images and their synthetically down-sampled variants jointly with their identity labels. Fine-tuning several state-of-the-art approaches with our method proves that we can significantly boost performance for cross-resolution (high-to-low resolution) face verification on various datasets without meaningfully exacerbating the performance on high-to-high resolution images. Our method applied on the FaceTransformer network achieves 95.12% face verification accuracy on the challenging XQLFW dataset while reaching 99.73% on the LFW database. Moreover, the low-to-low face verification accuracy benefits from our method. We release our code to allow seamless integration of the octuplet loss into existing frameworks.