 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Information Gain Sampling for Active Learning in Medical Image Classification
Aug 01, 2022
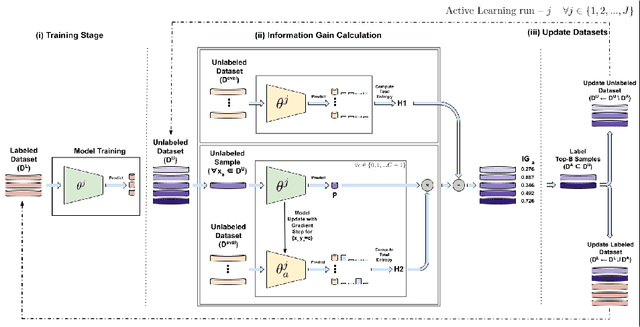
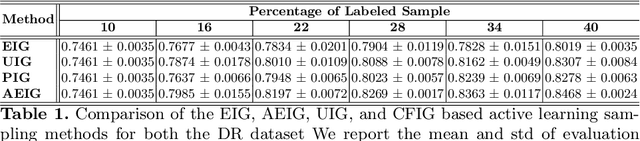
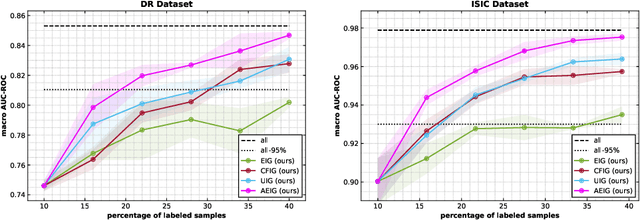
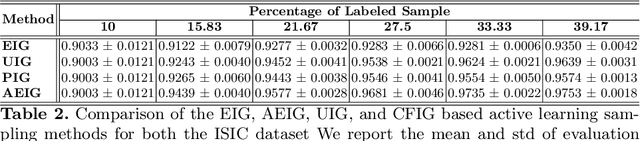
Large, annotated datasets are not widely available in medical image analysis due to the prohibitive time, costs, and challenges associated with labelling large datasets. Unlabelled datasets are easier to obtain, and in many contexts, it would be feasible for an expert to provide labels for a small subset of images. This work presents an information-theoretic active learning framework that guides the optimal selection of images from the unlabelled pool to be labeled based on maximizing the expected information gain (EIG) on an evaluation dataset. Experiments are performed on two different medical image classification datasets: multi-class diabetic retinopathy disease scale classification and multi-class skin lesion classification. Results indicate that by adapting EIG to account for class-imbalances, our proposed Adapted Expected Information Gain (AEIG) outperforms several popular baselines including the diversity based CoreSet and uncertainty based maximum entropy sampling. Specifically, AEIG achieves ~95% of overall performance with only 19% of the training data, while other active learning approaches require around 25%. We show that, by careful design choices, our model can be integrated into existing deep learning classifiers.
Component Segmentation of Engineering Drawings Using Graph Convolutional Networks
Dec 01, 2022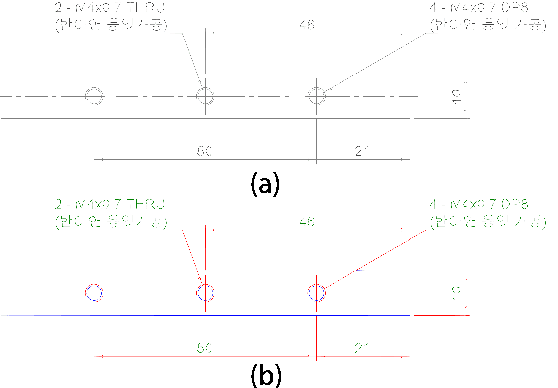

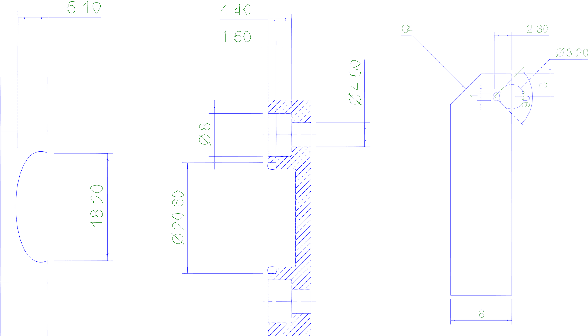
We present a data-driven framework to automate the vectorization and machine interpretation of 2D engineering part drawings. In industrial settings, most manufacturing engineers still rely on manual reads to identify the topological and manufacturing requirements from drawings submitted by designers. The interpretation process is laborious and time-consuming, which severely inhibits the efficiency of part quotation and manufacturing tasks. While recent advances in image-based computer vision methods have demonstrated great potential in interpreting natural images through semantic segmentation approaches, the application of such methods in parsing engineering technical drawings into semantically accurate components remains a significant challenge. The severe pixel sparsity in engineering drawings also restricts the effective featurization of image-based data-driven methods. To overcome these challenges, we propose a deep learning based framework that predicts the semantic type of each vectorized component. Taking a raster image as input, we vectorize all components through thinning, stroke tracing, and cubic bezier fitting. Then a graph of such components is generated based on the connectivity between the components. Finally, a graph convolutional neural network is trained on this graph data to identify the semantic type of each component. We test our framework in the context of semantic segmentation of text, dimension and, contour components in engineering drawings. Results show that our method yields the best performance compared to recent image, and graph-based segmentation methods.
Parameter-Efficient Image-to-Video Transfer Learning
Jun 27, 2022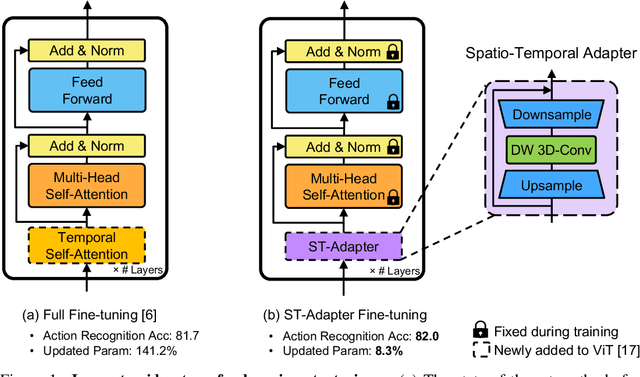
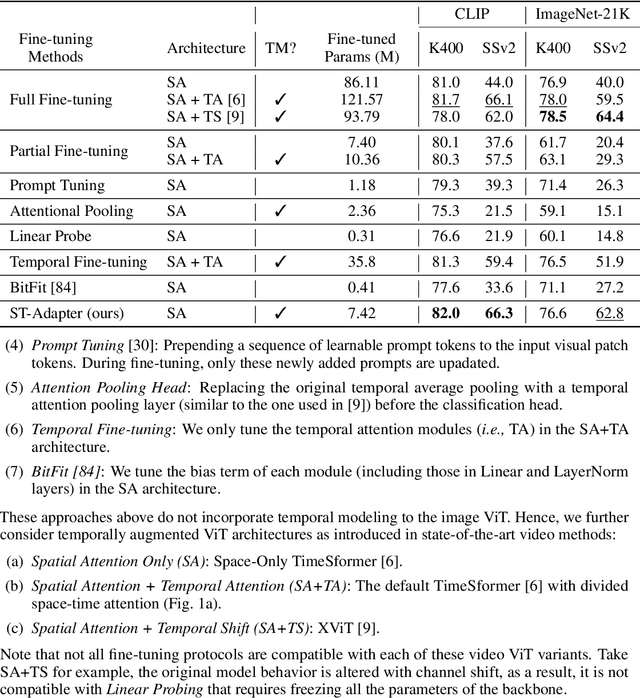
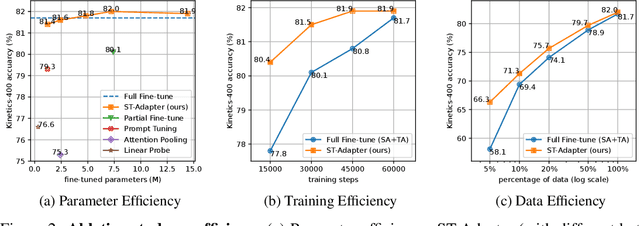
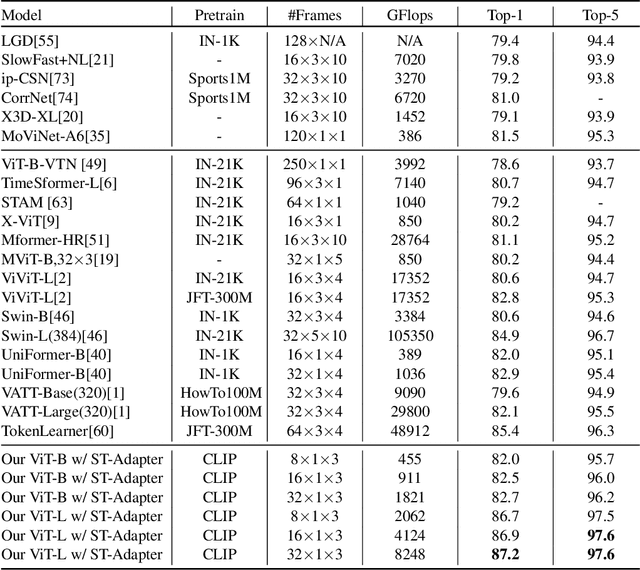
Capitalizing on large pre-trained models for various downstream tasks of interest have recently emerged with promising performance. Due to the ever-growing model size, the standard full fine-tuning based task adaptation strategy becomes prohibitively costly in terms of model training and storage. This has led to a new research direction in parameter-efficient transfer learning. However, existing attempts typically focus on downstream tasks from the same modality (e.g., image understanding) of the pre-trained model. This creates a limit because in some specific modalities, (e.g., video understanding) such a strong pre-trained model with sufficient knowledge is less or not available. In this work, we investigate such a novel cross-modality transfer learning setting, namely parameter-efficient image-to-video transfer learning. To solve this problem, we propose a new Spatio-Temporal Adapter (ST-Adapter) for parameter-efficient fine-tuning per video task. With a built-in spatio-temporal reasoning capability in a compact design, ST-Adapter enables a pre-trained image model without temporal knowledge to reason about dynamic video content at a small (~8%) per-task parameter cost, requiring approximately 20 times fewer updated parameters compared to previous work. Extensive experiments on video action recognition tasks show that our ST-Adapter can match or even outperform the strong full fine-tuning strategy and state-of-the-art video models, whilst enjoying the advantage of parameter efficiency.
Enhanced Fast Iterative Shrinkage Thresholding Algorithm For Linear Inverse Problem
Nov 28, 2022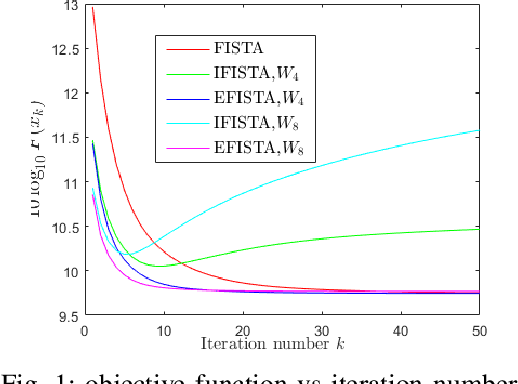
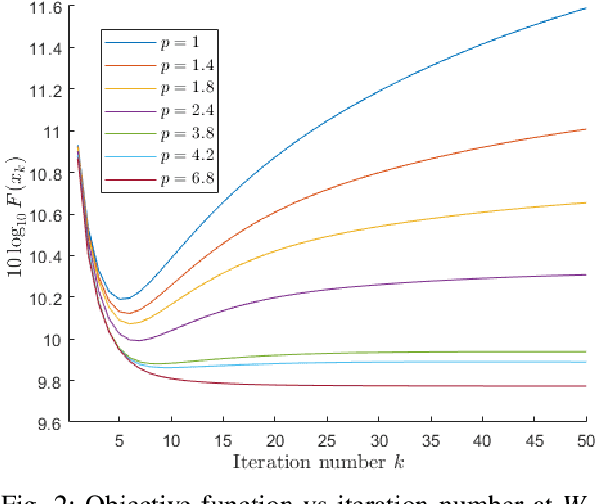
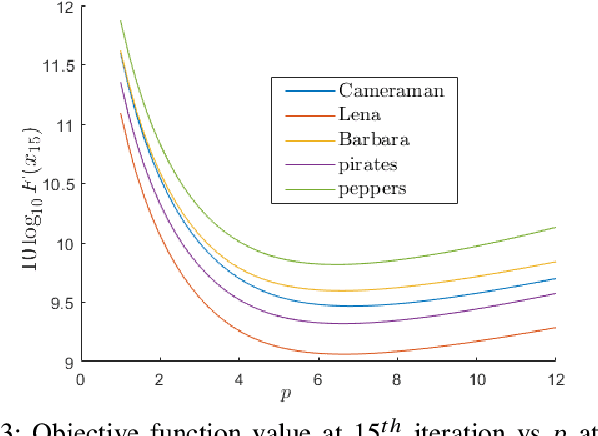

The linear inverse problem emerges from various real-world applications such as Image deblurring, inpainting, etc., which are still thrust research areas for image quality improvement. In this paper, we have introduced a new algorithm called the Enhanced fast iterative shrinkage thresholding algorithm (EFISTA) for linear inverse problems. This algorithm uses a weighted least square term and a scaled version of the regularization parameter to accelerate the objective function minimization. The image deblurring simulation results show that EFISTA has a superior execution speed, with an improved performance than its predecessors in terms of peak-signal-to-noise ratio (PSNR), particularly at a high noise level. With these motivating results, we can say that the proposed EFISTA can also be helpful for other linear inverse problems to improve the reconstruction speed and handle noise effectively.
On the Robustness of Normalizing Flows for Inverse Problems in Imaging
Dec 08, 2022

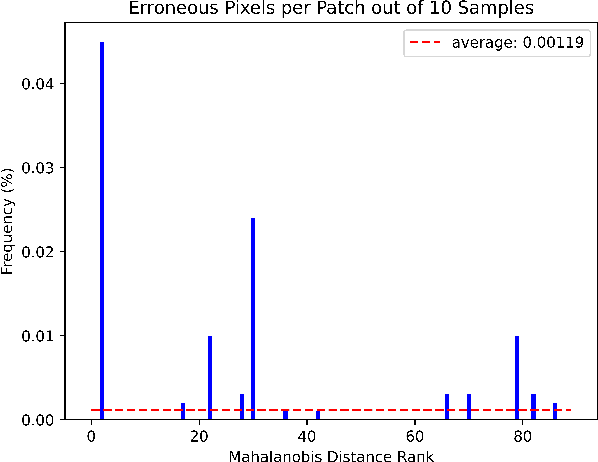

Conditional normalizing flows can generate diverse image samples for solving inverse problems. Most normalizing flows for inverse problems in imaging employ the conditional affine coupling layer that can generate diverse images quickly. However, unintended severe artifacts are occasionally observed in the output of them. In this work, we address this critical issue by investigating the origins of these artifacts and proposing the conditions to avoid them. First of all, we empirically and theoretically reveal that these problems are caused by ``exploding variance'' in the conditional affine coupling layer for certain out-of-distribution (OOD) conditional inputs. Then, we further validated that the probability of causing erroneous artifacts in pixels is highly correlated with a Mahalanobis distance-based OOD score for inverse problems in imaging. Lastly, based on our investigations, we propose a remark to avoid exploding variance and then based on it, we suggest a simple remedy that substitutes the affine coupling layers with the modified rational quadratic spline coupling layers in normalizing flows, to encourage the robustness of generated image samples. Our experimental results demonstrated that our suggested methods effectively suppressed critical artifacts occurring in normalizing flows for super-resolution space generation and low-light image enhancement without compromising performance.
Dimensionality-Varying Diffusion Process
Nov 29, 2022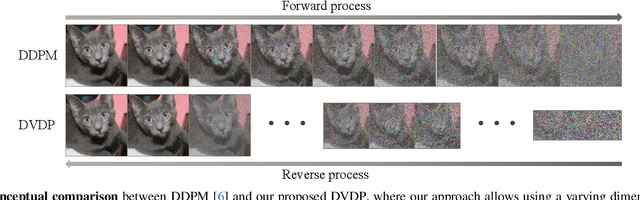
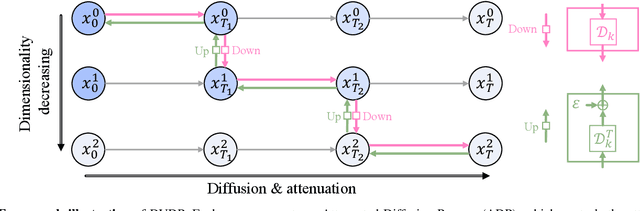
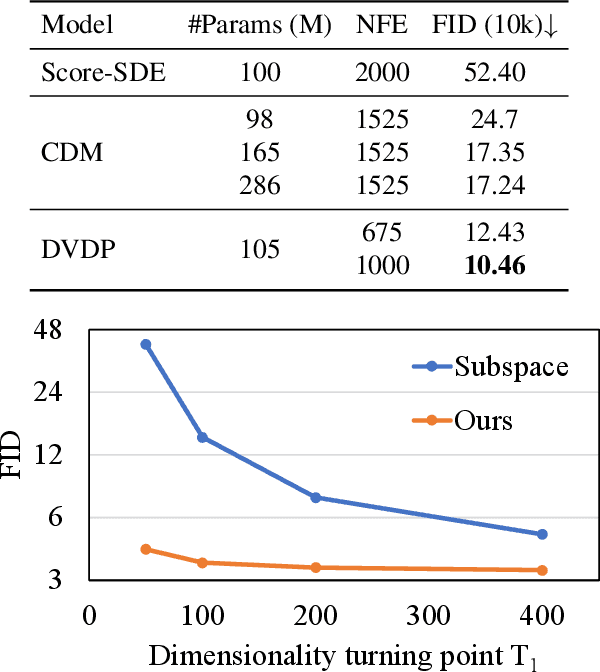

Diffusion models, which learn to reverse a signal destruction process to generate new data, typically require the signal at each step to have the same dimension. We argue that, considering the spatial redundancy in image signals, there is no need to maintain a high dimensionality in the evolution process, especially in the early generation phase. To this end, we make a theoretical generalization of the forward diffusion process via signal decomposition. Concretely, we manage to decompose an image into multiple orthogonal components and control the attenuation of each component when perturbing the image. That way, along with the noise strength increasing, we are able to diminish those inconsequential components and thus use a lower-dimensional signal to represent the source, barely losing information. Such a reformulation allows to vary dimensions in both training and inference of diffusion models. Extensive experiments on a range of datasets suggest that our approach substantially reduces the computational cost and achieves on-par or even better synthesis performance compared to baseline methods. We also show that our strategy facilitates high-resolution image synthesis and improves FID of diffusion model trained on FFHQ at $1024\times1024$ resolution from 52.40 to 10.46. Code and models will be made publicly available.
Flattening-Net: Deep Regular 2D Representation for 3D Point Cloud Analysis
Dec 17, 2022
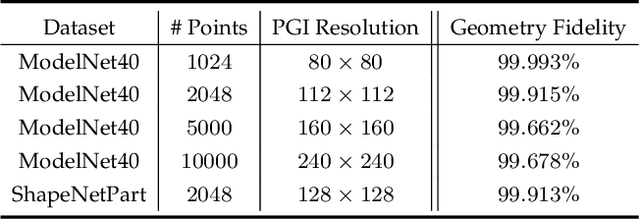
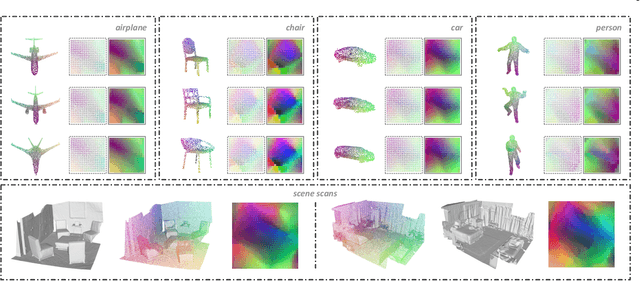
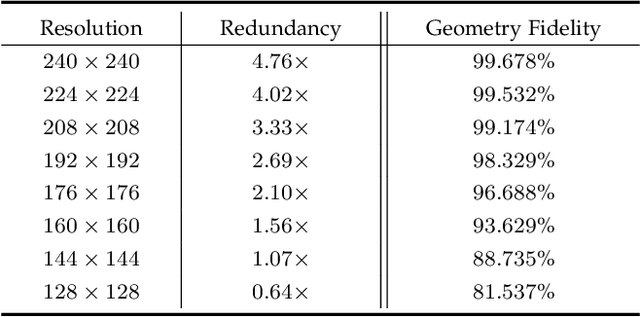
Point clouds are characterized by irregularity and unstructuredness, which pose challenges in efficient data exploitation and discriminative feature extraction. In this paper, we present an unsupervised deep neural architecture called Flattening-Net to represent irregular 3D point clouds of arbitrary geometry and topology as a completely regular 2D point geometry image (PGI) structure, in which coordinates of spatial points are captured in colors of image pixels. \mr{Intuitively, Flattening-Net implicitly approximates a locally smooth 3D-to-2D surface flattening process while effectively preserving neighborhood consistency.} \mr{As a generic representation modality, PGI inherently encodes the intrinsic property of the underlying manifold structure and facilitates surface-style point feature aggregation.} To demonstrate its potential, we construct a unified learning framework directly operating on PGIs to achieve \mr{diverse types of high-level and low-level} downstream applications driven by specific task networks, including classification, segmentation, reconstruction, and upsampling. Extensive experiments demonstrate that our methods perform favorably against the current state-of-the-art competitors. We will make the code and data publicly available at https://github.com/keeganhk/Flattening-Net.
Semi-supervised Ranking for Object Image Blur Assessment
Jul 13, 2022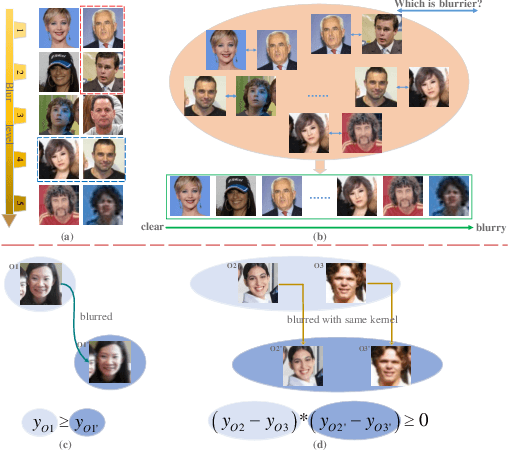
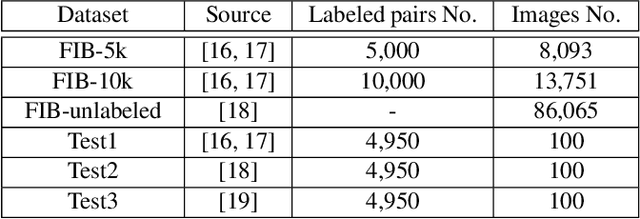
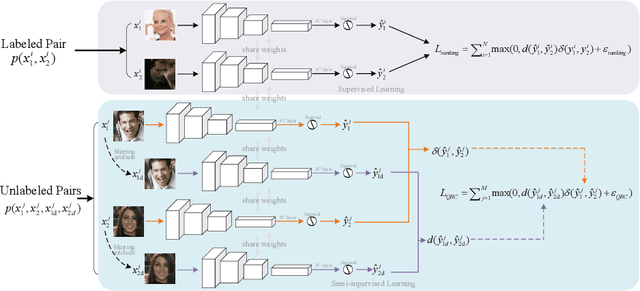
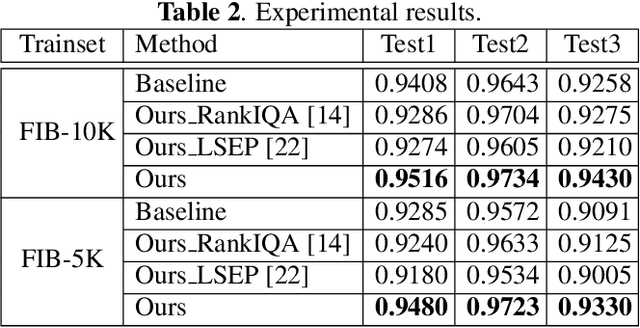
Assessing the blurriness of an object image is fundamentally important to improve the performance for object recognition and retrieval. The main challenge lies in the lack of abundant images with reliable labels and effective learning strategies. Current datasets are labeled with limited and confused quality levels. To overcome this limitation, we propose to label the rank relationships between pairwise images rather their quality levels, since it is much easier for humans to label, and establish a large-scale realistic face image blur assessment dataset with reliable labels. Based on this dataset, we propose a method to obtain the blur scores only with the pairwise rank labels as supervision. Moreover, to further improve the performance, we propose a self-supervised method based on quadruplet ranking consistency to leverage the unlabeled data more effectively. The supervised and self-supervised methods constitute a final semi-supervised learning framework, which can be trained end-to-end. Experimental results demonstrate the effectiveness of our method.
Intra-Instance VICReg: Bag of Self-Supervised Image Patch Embedding
Jun 17, 2022

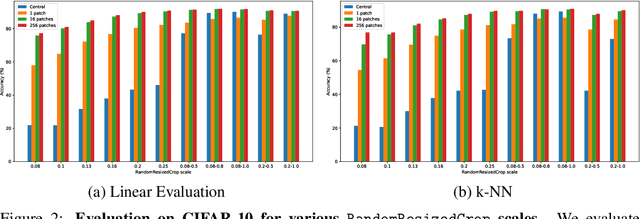

Recently, self-supervised learning (SSL) has achieved tremendous empirical advancements in learning image representation. However, our understanding and knowledge of the representation are still limited. This work shows that the success of the SOTA siamese-network-based SSL approaches is primarily based on learning a representation of image patches. Particularly, we show that when we learn a representation only for fixed-scale image patches and aggregate different patch representations linearly for an image (instance), it can achieve on par or even better results than the baseline methods on several benchmarks. Further, we show that the patch representation aggregation can also improve various SOTA baseline methods by a large margin. We also establish a formal connection between the SSL objective and the image patches co-occurrence statistics modeling, which supplements the prevailing invariance perspective. By visualizing the nearest neighbors of different image patches in the embedding space and projection space, we show that while the projection has more invariance, the embedding space tends to preserve more equivariance and locality. Finally, we propose a hypothesis for the future direction based on the discovery of this work.
NTIRE 2022 Challenge on Perceptual Image Quality Assessment
Jun 23, 2022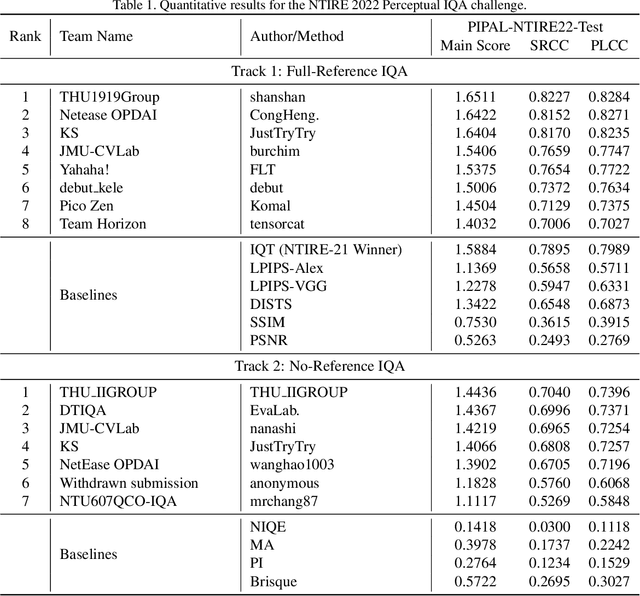
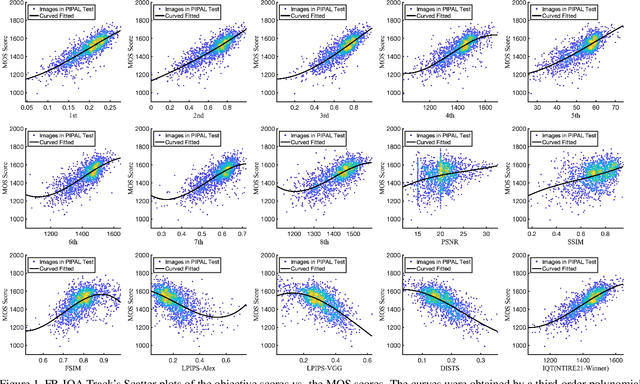
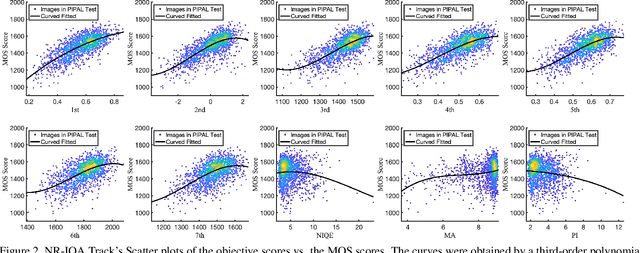
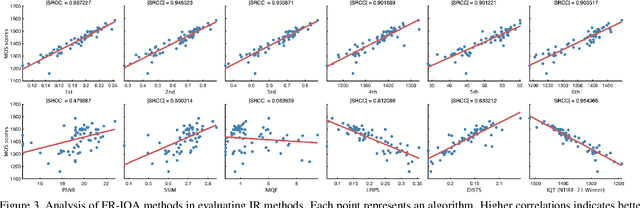
This paper reports on the NTIRE 2022 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2022. This challenge is held to address the emerging challenge of IQA by perceptual image processing algorithms. The output images of these algorithms have completely different characteristics from traditional distortions and are included in the PIPAL dataset used in this challenge. This challenge is divided into two tracks, a full-reference IQA track similar to the previous NTIRE IQA challenge and a new track that focuses on the no-reference IQA methods. The challenge has 192 and 179 registered participants for two tracks. In the final testing stage, 7 and 8 participating teams submitted their models and fact sheets. Almost all of them have achieved better results than existing IQA methods, and the winning method can demonstrate state-of-the-art performance.