 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
UMFuse: Unified Multi View Fusion for Human Editing applications
Dec 01, 2022
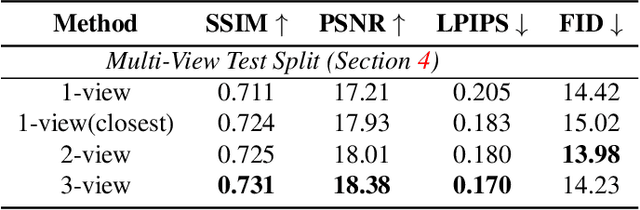
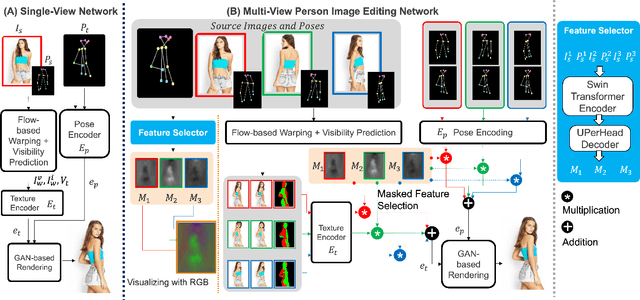
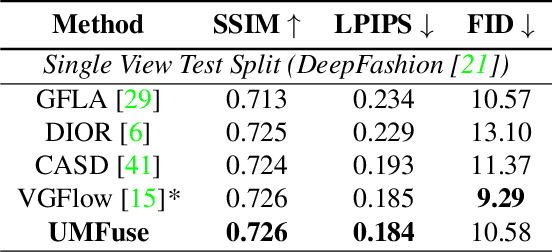
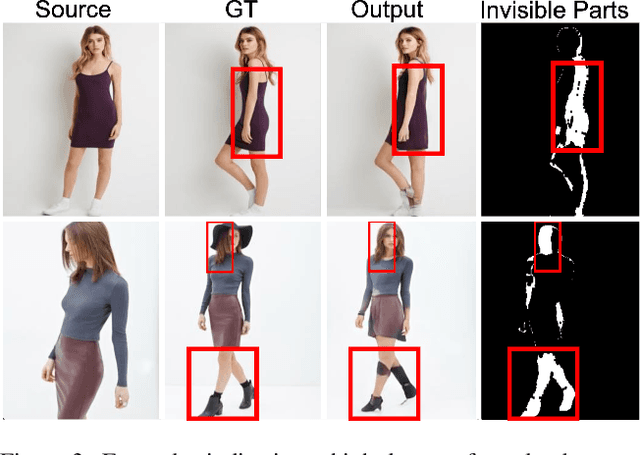
The vision community has explored numerous pose guided human editing methods due to their extensive practical applications. Most of these methods still use an image-to-image formulation in which a single image is given as input to produce an edited image as output. However, the problem is ill-defined in cases when the target pose is significantly different from the input pose. Existing methods then resort to in-painting or style transfer to handle occlusions and preserve content. In this paper, we explore the utilization of multiple views to minimize the issue of missing information and generate an accurate representation of the underlying human model. To fuse the knowledge from multiple viewpoints, we design a selector network that takes the pose keypoints and texture from images and generates an interpretable per-pixel selection map. After that, the encodings from a separate network (trained on a single image human reposing task) are merged in the latent space. This enables us to generate accurate, precise, and visually coherent images for different editing tasks. We show the application of our network on 2 newly proposed tasks - Multi-view human reposing, and Mix-and-match human image generation. Additionally, we study the limitations of single-view editing and scenarios in which multi-view provides a much better alternative.
Reverse engineering adversarial attacks with fingerprints from adversarial examples
Feb 01, 2023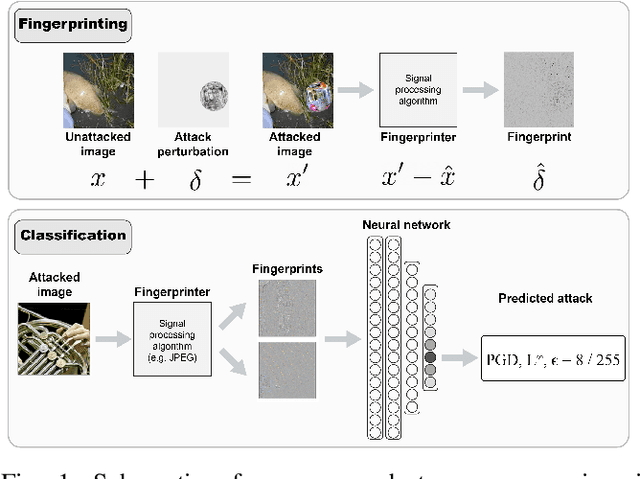
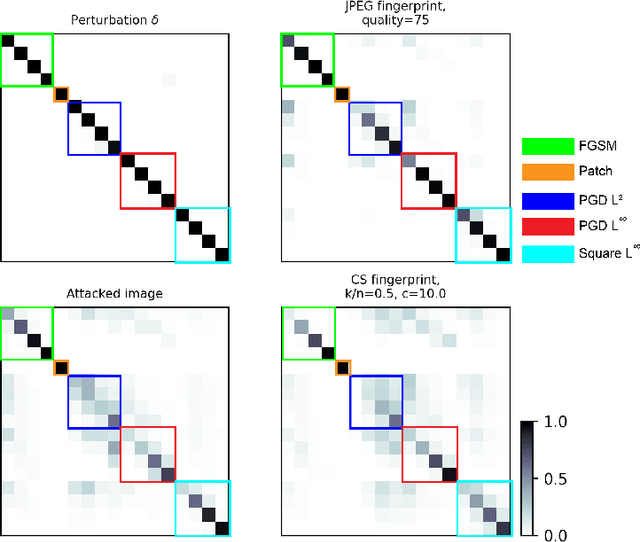
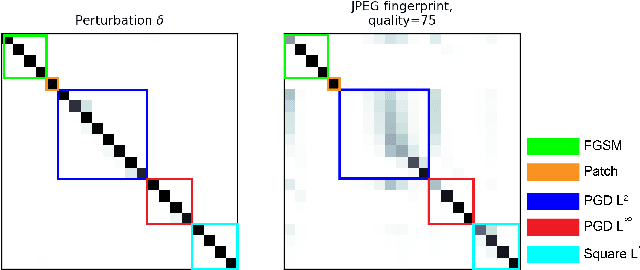
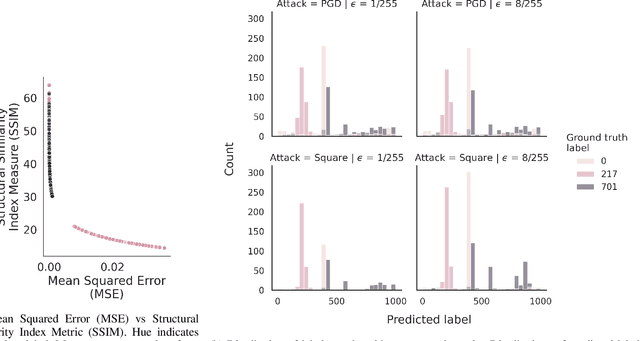
In spite of intense research efforts, deep neural networks remain vulnerable to adversarial examples: an input that forces the network to confidently produce incorrect outputs. Adversarial examples are typically generated by an attack algorithm that optimizes a perturbation added to a benign input. Many such algorithms have been developed. If it were possible to reverse engineer attack algorithms from adversarial examples, this could deter bad actors because of the possibility of attribution. Here we formulate reverse engineering as a supervised learning problem where the goal is to assign an adversarial example to a class that represents the algorithm and parameters used. To our knowledge it has not been previously shown whether this is even possible. We first test whether we can classify the perturbations added to images by attacks on undefended single-label image classification models. Taking a "fight fire with fire" approach, we leverage the sensitivity of deep neural networks to adversarial examples, training them to classify these perturbations. On a 17-class dataset (5 attacks, 4 bounded with 4 epsilon values each), we achieve an accuracy of 99.4% with a ResNet50 model trained on the perturbations. We then ask whether we can perform this task without access to the perturbations, obtaining an estimate of them with signal processing algorithms, an approach we call "fingerprinting". We find the JPEG algorithm serves as a simple yet effective fingerprinter (85.05% accuracy), providing a strong baseline for future work. We discuss how our approach can be extended to attack agnostic, learnable fingerprints, and to open-world scenarios with unknown attacks.
REPNP: Plug-and-Play with Deep Reinforcement Learning Prior for Robust Image Restoration
Jul 25, 2022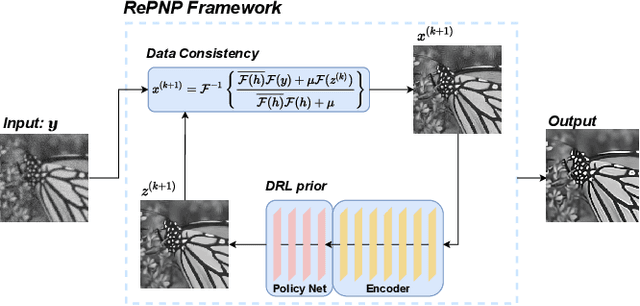
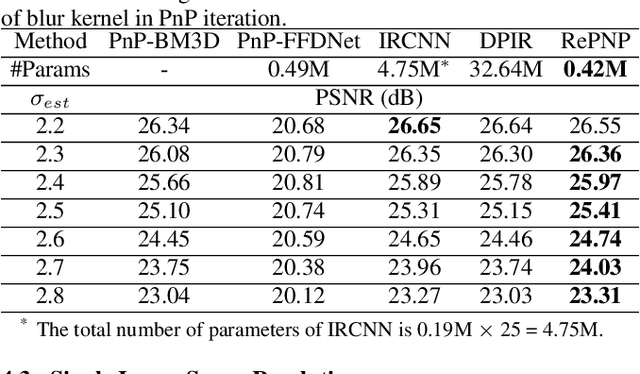
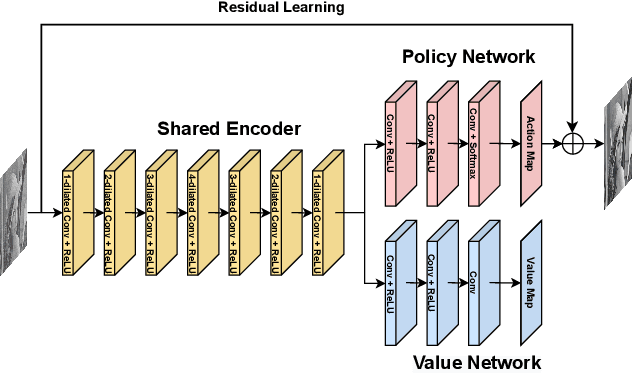
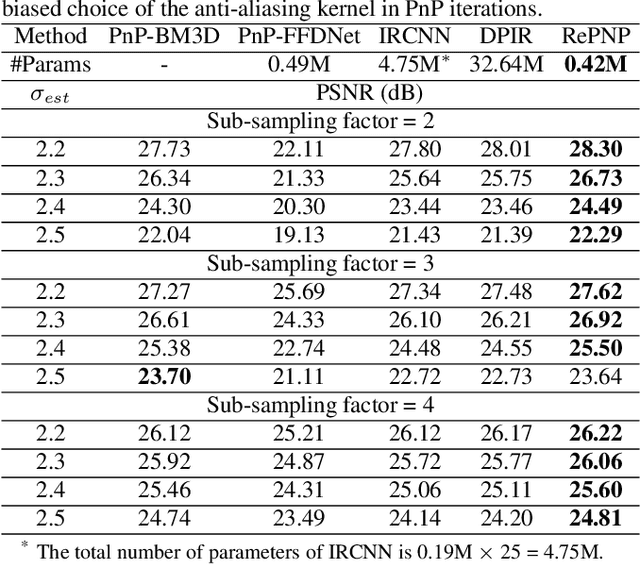
Image restoration schemes based on the pre-trained deep models have received great attention due to their unique flexibility for solving various inverse problems. In particular, the Plug-and-Play (PnP) framework is a popular and powerful tool that can integrate an off-the-shelf deep denoiser for different image restoration tasks with known observation models. However, obtaining the observation model that exactly matches the actual one can be challenging in practice. Thus, the PnP schemes with conventional deep denoisers may fail to generate satisfying results in some real-world image restoration tasks. We argue that the robustness of the PnP framework is largely limited by using the off-the-shelf deep denoisers that are trained by deterministic optimization. To this end, we propose a novel deep reinforcement learning (DRL) based PnP framework, dubbed RePNP, by leveraging a light-weight DRL-based denoiser for robust image restoration tasks. Experimental results demonstrate that the proposed RePNP is robust to the observation model used in the PnP scheme deviating from the actual one. Thus, RePNP can generate more reliable restoration results for image deblurring and super resolution tasks. Compared with several state-of-the-art deep image restoration baselines, RePNP achieves better results subjective to model deviation with fewer model parameters.
Discovering Bugs in Vision Models using Off-the-shelf Image Generation and Captioning
Aug 18, 2022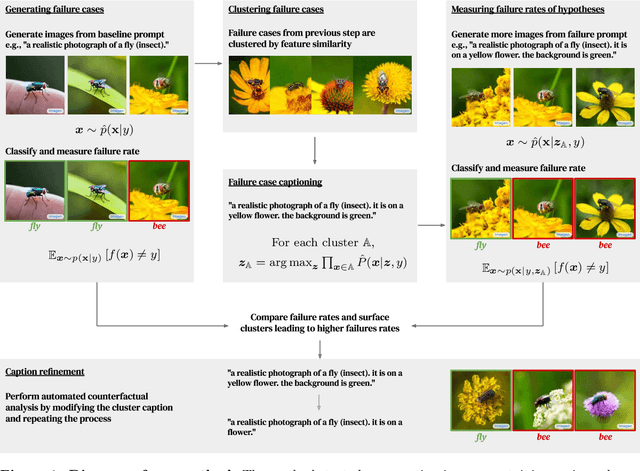



Automatically discovering failures in vision models under real-world settings remains an open challenge. This work demonstrates how off-the-shelf, large-scale, image-to-text and text-to-image models, trained on vast amounts of data, can be leveraged to automatically find such failures. In essence, a conditional text-to-image generative model is used to generate large amounts of synthetic, yet realistic, inputs given a ground-truth label. Misclassified inputs are clustered and a captioning model is used to describe each cluster. Each cluster's description is used in turn to generate more inputs and assess whether specific clusters induce more failures than expected. We use this pipeline to demonstrate that we can effectively interrogate classifiers trained on ImageNet to find specific failure cases and discover spurious correlations. We also show that we can scale the approach to generate adversarial datasets targeting specific classifier architectures. This work serves as a proof-of-concept demonstrating the utility of large-scale generative models to automatically discover bugs in vision models in an open-ended manner. We also describe a number of limitations and pitfalls related to this approach.
Point-E: A System for Generating 3D Point Clouds from Complex Prompts
Dec 16, 2022
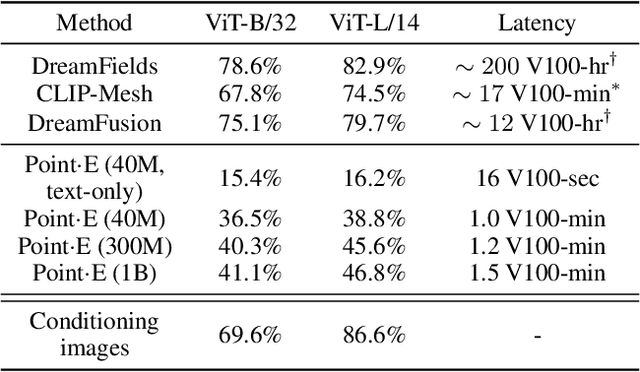

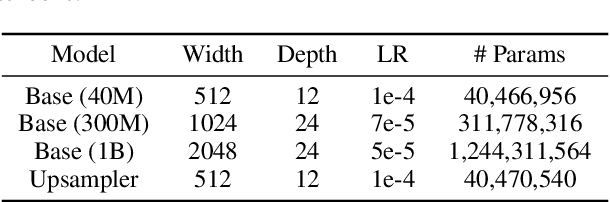
While recent work on text-conditional 3D object generation has shown promising results, the state-of-the-art methods typically require multiple GPU-hours to produce a single sample. This is in stark contrast to state-of-the-art generative image models, which produce samples in a number of seconds or minutes. In this paper, we explore an alternative method for 3D object generation which produces 3D models in only 1-2 minutes on a single GPU. Our method first generates a single synthetic view using a text-to-image diffusion model, and then produces a 3D point cloud using a second diffusion model which conditions on the generated image. While our method still falls short of the state-of-the-art in terms of sample quality, it is one to two orders of magnitude faster to sample from, offering a practical trade-off for some use cases. We release our pre-trained point cloud diffusion models, as well as evaluation code and models, at https://github.com/openai/point-e.
Zero-Shot Audio Classification using Image Embeddings
Jun 10, 2022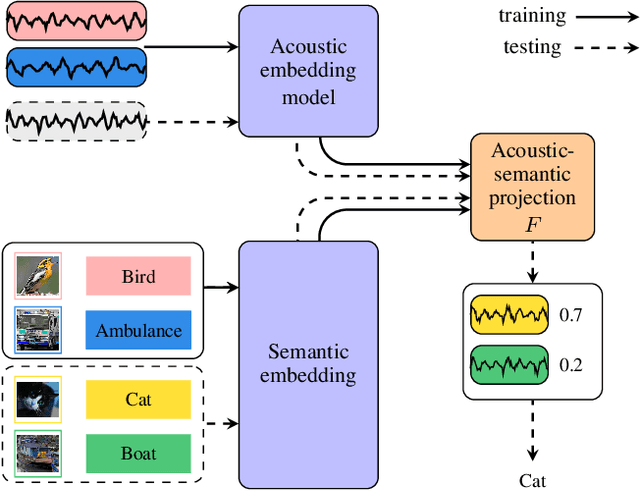
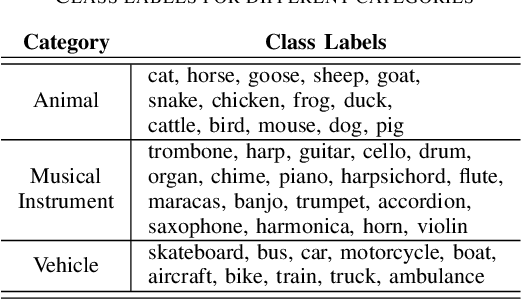
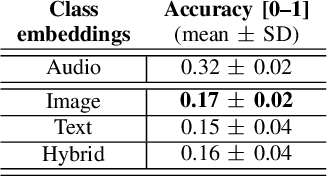
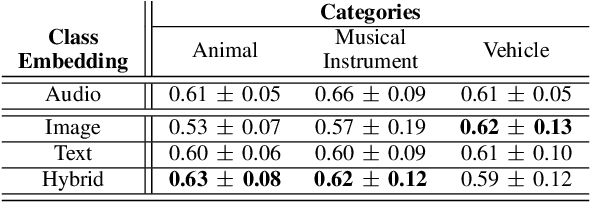
Supervised learning methods can solve the given problem in the presence of a large set of labeled data. However, the acquisition of a dataset covering all the target classes typically requires manual labeling which is expensive and time-consuming. Zero-shot learning models are capable of classifying the unseen concepts by utilizing their semantic information. The present study introduces image embeddings as side information on zero-shot audio classification by using a nonlinear acoustic-semantic projection. We extract the semantic image representations from the Open Images dataset and evaluate the performance of the models on an audio subset of AudioSet using semantic information in different domains; image, audio, and textual. We demonstrate that the image embeddings can be used as semantic information to perform zero-shot audio classification. The experimental results show that the image and textual embeddings display similar performance both individually and together. We additionally calculate the semantic acoustic embeddings from the test samples to provide an upper limit to the performance. The results show that the classification performance is highly sensitive to the semantic relation between test and training classes and textual and image embeddings can reach up to the semantic acoustic embeddings when the seen and unseen classes are semantically similar.
Poses of People in Art: A Data Set for Human Pose Estimation in Digital Art History
Jan 12, 2023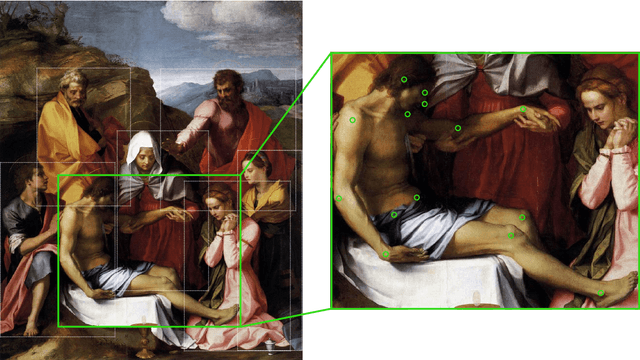

Throughout the history of art, the pose, as the holistic abstraction of the human body's expression, has proven to be a constant in numerous studies. However, due to the enormous amount of data that so far had to be processed by hand, its crucial role to the formulaic recapitulation of art-historical motifs since antiquity could only be highlighted selectively. This is true even for the now automated estimation of human poses, as domain-specific, sufficiently large data sets required for training computational models are either not publicly available or not indexed at a fine enough granularity. With the Poses of People in Art data set, we introduce the first openly licensed data set for estimating human poses in art and validating human pose estimators. It consists of 2,454 images from 22 art-historical depiction styles, including those that have increasingly turned away from lifelike representations of the body since the 19th century. A total of 10,749 human figures are precisely enclosed by rectangular bounding boxes, with a maximum of four per image labeled by up to 17 keypoints; among these are mainly joints such as elbows and knees. For machine learning purposes, the data set is divided into three subsets, training, validation, and testing, that follow the established JSON-based Microsoft COCO format, respectively. Each image annotation, in addition to mandatory fields, provides metadata from the art-historical online encyclopedia WikiArt. With this paper, we elaborate on the acquisition and constitution of the data set, address various application scenarios, and discuss prospects for a digitally supported art history. We show that the data set enables the investigation of body phenomena in art, whether at the level of individual figures, which can be captured in their subtleties, or entire figure constellations, whose position, distance, or proximity to one another is considered.
SUCRe: Leveraging Scene Structure for Underwater Color Restoration
Dec 18, 2022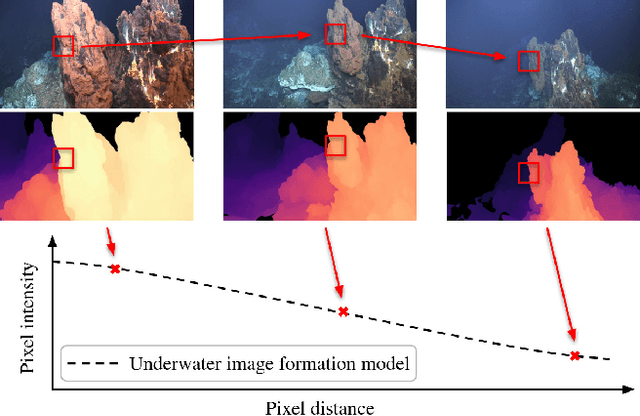

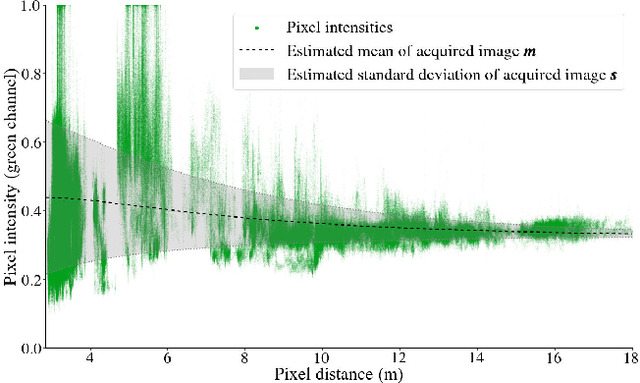
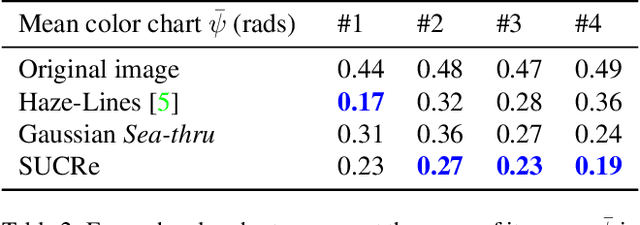
Underwater images are altered by the physical characteristics of the medium through which light rays pass before reaching the optical sensor. Scattering and strong wavelength-dependent absorption significantly modify the captured colors depending on the distance of observed elements to the image plane. In this paper, we aim to recover the original colors of the scene as if the water had no effect on them. We propose two novel methods that rely on different sets of inputs. The first assumes that pixel intensities in the restored image are normally distributed within each color channel, leading to an alternative optimization of the well-known \textit{Sea-thru} method which acts on single images and their distance maps. We additionally introduce SUCRe, a new method that further exploits the scene's 3D Structure for Underwater Color Restoration. By following points in multiple images and tracking their intensities at different distances to the sensor we constrain the optimization of the image formation model parameters. When compared to similar existing approaches, SUCRe provides clear improvements in a variety of scenarios ranging from natural light to deep-sea environments. The code for both approaches is publicly available at https://github.com/clementinboittiaux/sucre .
Identifying Spurious Correlations and Correcting them with an Explanation-based Learning
Dec 05, 2022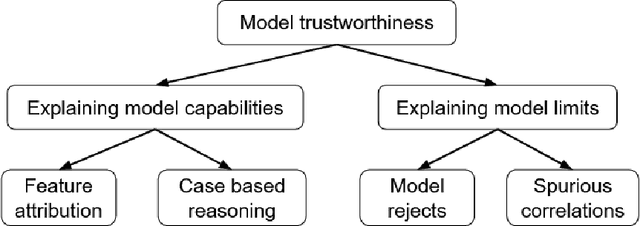
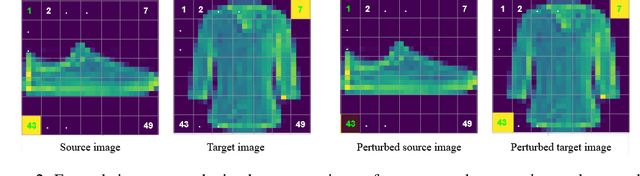
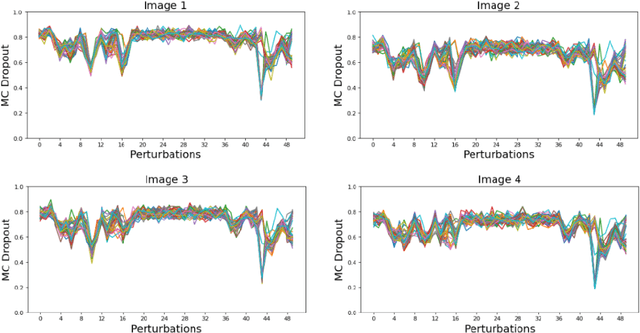
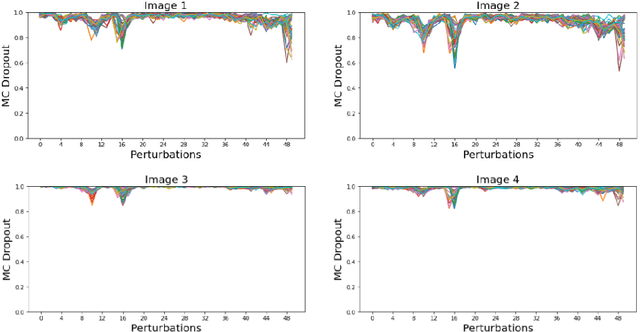
Identifying spurious correlations learned by a trained model is at the core of refining a trained model and building a trustworthy model. We present a simple method to identify spurious correlations that have been learned by a model trained for image classification problems. We apply image-level perturbations and monitor changes in certainties of predictions made using the trained model. We demonstrate this approach using an image classification dataset that contains images with synthetically generated spurious regions and show that the trained model was overdependent on spurious regions. Moreover, we remove the learned spurious correlations with an explanation based learning approach.
Which Pixel to Annotate: a Label-Efficient Nuclei Segmentation Framework
Dec 20, 2022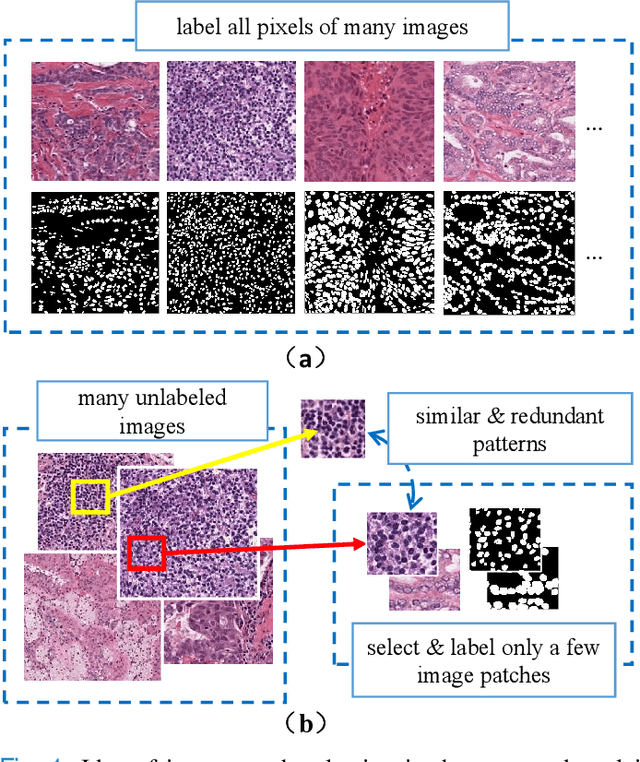
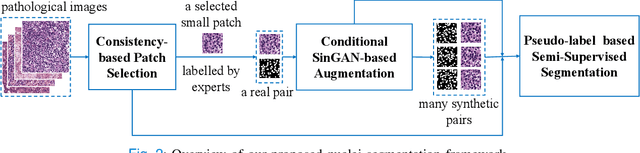
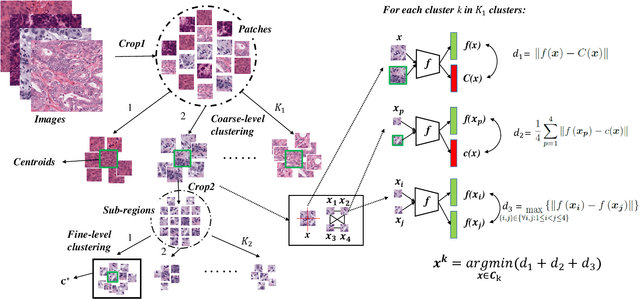
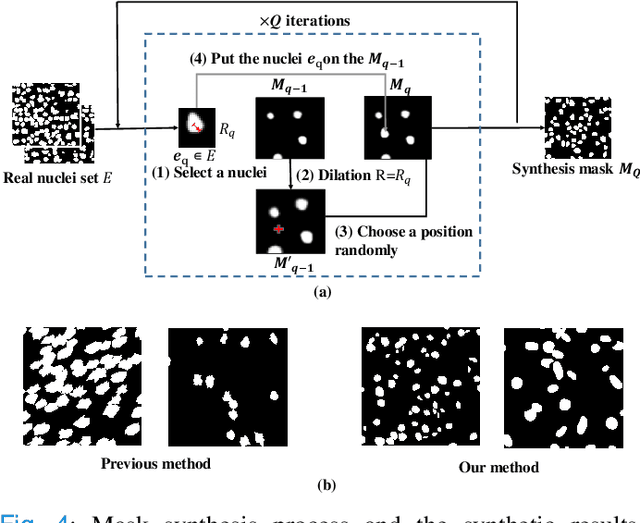
Recently deep neural networks, which require a large amount of annotated samples, have been widely applied in nuclei instance segmentation of H\&E stained pathology images. However, it is inefficient and unnecessary to label all pixels for a dataset of nuclei images which usually contain similar and redundant patterns. Although unsupervised and semi-supervised learning methods have been studied for nuclei segmentation, very few works have delved into the selective labeling of samples to reduce the workload of annotation. Thus, in this paper, we propose a novel full nuclei segmentation framework that chooses only a few image patches to be annotated, augments the training set from the selected samples, and achieves nuclei segmentation in a semi-supervised manner. In the proposed framework, we first develop a novel consistency-based patch selection method to determine which image patches are the most beneficial to the training. Then we introduce a conditional single-image GAN with a component-wise discriminator, to synthesize more training samples. Lastly, our proposed framework trains an existing segmentation model with the above augmented samples. The experimental results show that our proposed method could obtain the same-level performance as a fully-supervised baseline by annotating less than 5% pixels on some benchmarks.