 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CAMixerSR: Only Details Need More "Attention"
Mar 15, 2024
To satisfy the rapidly increasing demands on the large image (2K-8K) super-resolution (SR), prevailing methods follow two independent tracks: 1) accelerate existing networks by content-aware routing, and 2) design better super-resolution networks via token mixer refining. Despite directness, they encounter unavoidable defects (e.g., inflexible route or non-discriminative processing) limiting further improvements of quality-complexity trade-off. To erase the drawbacks, we integrate these schemes by proposing a content-aware mixer (CAMixer), which assigns convolution for simple contexts and additional deformable window-attention for sparse textures. Specifically, the CAMixer uses a learnable predictor to generate multiple bootstraps, including offsets for windows warping, a mask for classifying windows, and convolutional attentions for endowing convolution with the dynamic property, which modulates attention to include more useful textures self-adaptively and improves the representation capability of convolution. We further introduce a global classification loss to improve the accuracy of predictors. By simply stacking CAMixers, we obtain CAMixerSR which achieves superior performance on large-image SR, lightweight SR, and omnidirectional-image SR.
FeatUp: A Model-Agnostic Framework for Features at Any Resolution
Mar 15, 2024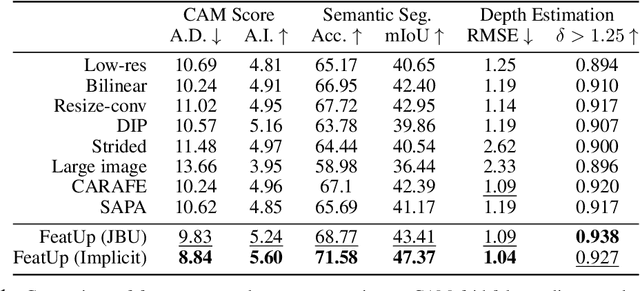
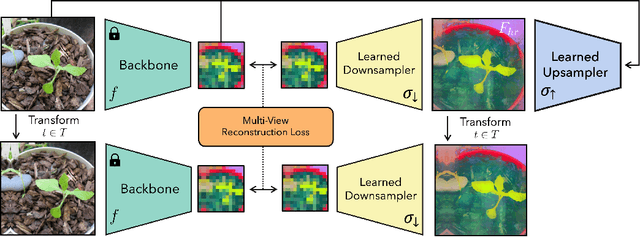
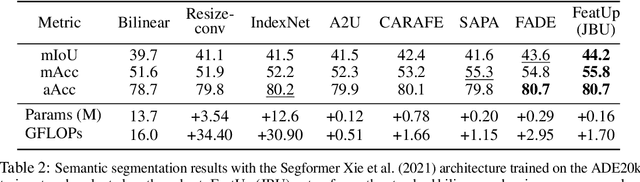

Deep features are a cornerstone of computer vision research, capturing image semantics and enabling the community to solve downstream tasks even in the zero- or few-shot regime. However, these features often lack the spatial resolution to directly perform dense prediction tasks like segmentation and depth prediction because models aggressively pool information over large areas. In this work, we introduce FeatUp, a task- and model-agnostic framework to restore lost spatial information in deep features. We introduce two variants of FeatUp: one that guides features with high-resolution signal in a single forward pass, and one that fits an implicit model to a single image to reconstruct features at any resolution. Both approaches use a multi-view consistency loss with deep analogies to NeRFs. Our features retain their original semantics and can be swapped into existing applications to yield resolution and performance gains even without re-training. We show that FeatUp significantly outperforms other feature upsampling and image super-resolution approaches in class activation map generation, transfer learning for segmentation and depth prediction, and end-to-end training for semantic segmentation.
Overcoming Distribution Shifts in Plug-and-Play Methods with Test-Time Training
Mar 15, 2024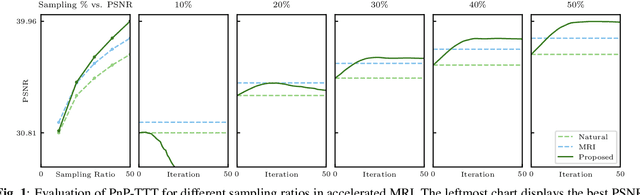
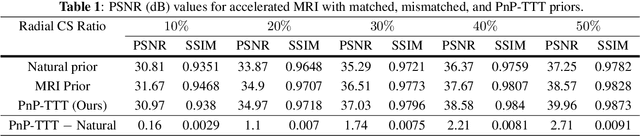
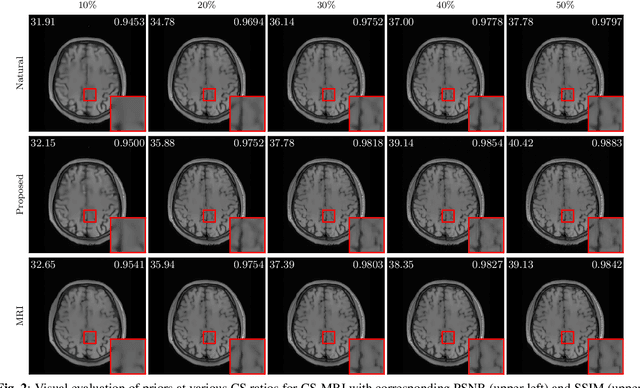
Plug-and-Play Priors (PnP) is a well-known class of methods for solving inverse problems in computational imaging. PnP methods combine physical forward models with learned prior models specified as image denoisers. A common issue with the learned models is that of a performance drop when there is a distribution shift between the training and testing data. Test-time training (TTT) was recently proposed as a general strategy for improving the performance of learned models when training and testing data come from different distributions. In this paper, we propose PnP-TTT as a new method for overcoming distribution shifts in PnP. PnP-TTT uses deep equilibrium learning (DEQ) for optimizing a self-supervised loss at the fixed points of PnP iterations. PnP-TTT can be directly applied on a single test sample to improve the generalization of PnP. We show through simulations that given a sufficient number of measurements, PnP-TTT enables the use of image priors trained on natural images for image reconstruction in magnetic resonance imaging (MRI).
Self and Mixed Supervision to Improve Training Labels for Multi-Class Medical Image Segmentation
Mar 06, 2024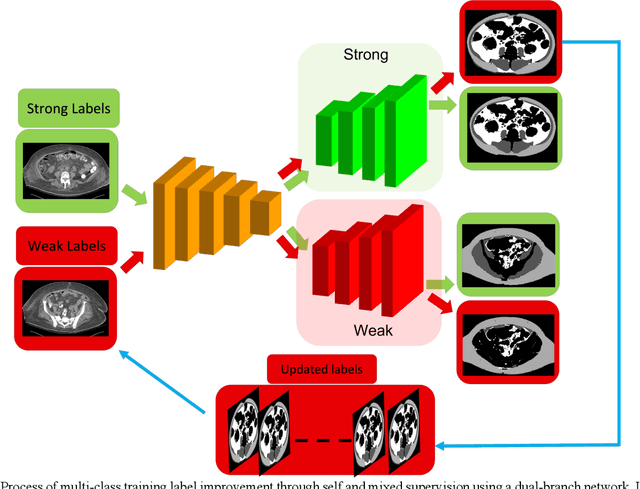
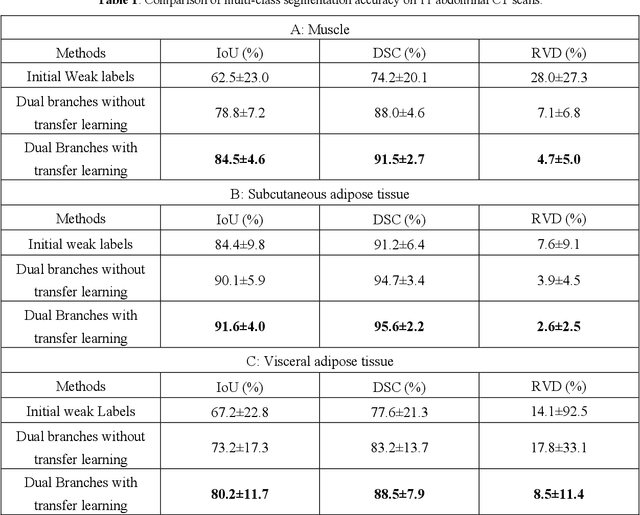
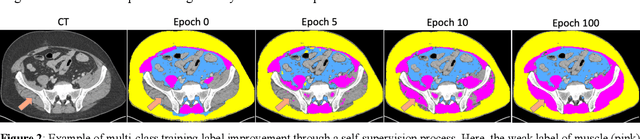
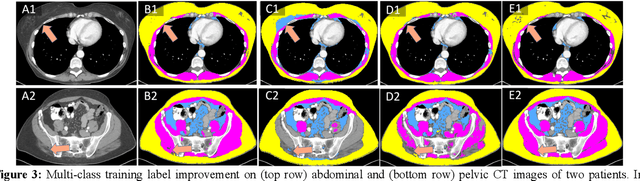
Accurate training labels are a key component for multi-class medical image segmentation. Their annotation is costly and time-consuming because it requires domain expertise. This work aims to develop a dual-branch network and automatically improve training labels for multi-class image segmentation. Transfer learning is used to train the network and improve inaccurate weak labels sequentially. The dual-branch network is first trained by weak labels alone to initialize model parameters. After the network is stabilized, the shared encoder is frozen, and strong and weak decoders are fine-tuned by strong and weak labels together. The accuracy of weak labels is iteratively improved in the fine-tuning process. The proposed method was applied to a three-class segmentation of muscle, subcutaneous and visceral adipose tissue on abdominal CT scans. Validation results on 11 patients showed that the accuracy of training labels was statistically significantly improved, with the Dice similarity coefficient of muscle, subcutaneous and visceral adipose tissue increased from 74.2% to 91.5%, 91.2% to 95.6%, and 77.6% to 88.5%, respectively (p<0.05). In comparison with our earlier method, the label accuracy was also significantly improved (p<0.05). These experimental results suggested that the combination of the dual-branch network and transfer learning is an efficient means to improve training labels for multi-class segmentation.
Region-aware Distribution Contrast: A Novel Approach to Multi-Task Partially Supervised Learning
Mar 15, 2024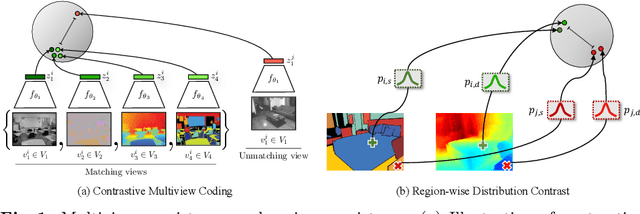
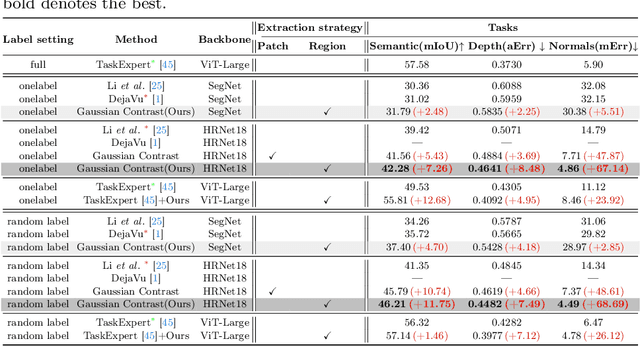
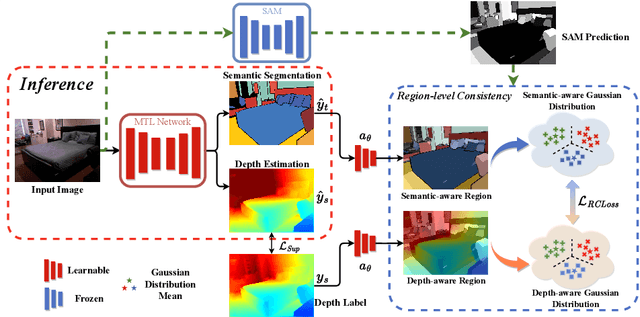

In this study, we address the intricate challenge of multi-task dense prediction, encompassing tasks such as semantic segmentation, depth estimation, and surface normal estimation, particularly when dealing with partially annotated data (MTPSL). The complexity arises from the absence of complete task labels for each training image. Given the inter-related nature of these pixel-wise dense tasks, our focus is on mining and capturing cross-task relationships. Existing solutions typically rely on learning global image representations for global cross-task image matching, imposing constraints that, unfortunately, sacrifice the finer structures within the images. Attempting local matching as a remedy faces hurdles due to the lack of precise region supervision, making local alignment a challenging endeavor. The introduction of Segment Anything Model (SAM) sheds light on addressing local alignment challenges by providing free and high-quality solutions for region detection. Leveraging SAM-detected regions, the subsequent challenge lies in aligning the representations within these regions. Diverging from conventional methods that directly learn a monolithic image representation, our proposal involves modeling region-wise representations using Gaussian Distributions. Aligning these distributions between corresponding regions from different tasks imparts higher flexibility and capacity to capture intra-region structures, accommodating a broader range of tasks. This innovative approach significantly enhances our ability to effectively capture cross-task relationships, resulting in improved overall performance in partially supervised multi-task dense prediction scenarios. Extensive experiments conducted on two widely used benchmarks underscore the superior effectiveness of our proposed method, showcasing state-of-the-art performance even when compared to fully supervised methods.
Towards Backward-Compatible Continual Learning of Image Compression
Feb 29, 2024This paper explores the possibility of extending the capability of pre-trained neural image compressors (e.g., adapting to new data or target bitrates) without breaking backward compatibility, the ability to decode bitstreams encoded by the original model. We refer to this problem as continual learning of image compression. Our initial findings show that baseline solutions, such as end-to-end fine-tuning, do not preserve the desired backward compatibility. To tackle this, we propose a knowledge replay training strategy that effectively addresses this issue. We also design a new model architecture that enables more effective continual learning than existing baselines. Experiments are conducted for two scenarios: data-incremental learning and rate-incremental learning. The main conclusion of this paper is that neural image compressors can be fine-tuned to achieve better performance (compared to their pre-trained version) on new data and rates without compromising backward compatibility. Our code is available at https://gitlab.com/viper-purdue/continual-compression
Diffusion Model-Based Image Editing: A Survey
Feb 27, 2024Denoising diffusion models have emerged as a powerful tool for various image generation and editing tasks, facilitating the synthesis of visual content in an unconditional or input-conditional manner. The core idea behind them is learning to reverse the process of gradually adding noise to images, allowing them to generate high-quality samples from a complex distribution. In this survey, we provide an exhaustive overview of existing methods using diffusion models for image editing, covering both theoretical and practical aspects in the field. We delve into a thorough analysis and categorization of these works from multiple perspectives, including learning strategies, user-input conditions, and the array of specific editing tasks that can be accomplished. In addition, we pay special attention to image inpainting and outpainting, and explore both earlier traditional context-driven and current multimodal conditional methods, offering a comprehensive analysis of their methodologies. To further evaluate the performance of text-guided image editing algorithms, we propose a systematic benchmark, EditEval, featuring an innovative metric, LMM Score. Finally, we address current limitations and envision some potential directions for future research. The accompanying repository is released at https://github.com/SiatMMLab/Awesome-Diffusion-Model-Based-Image-Editing-Methods.
HyenaPixel: Global Image Context with Convolutions
Feb 29, 2024In vision tasks, a larger effective receptive field (ERF) is associated with better performance. While attention natively supports global context, convolution requires multiple stacked layers and a hierarchical structure for large context. In this work, we extend Hyena, a convolution-based attention replacement, from causal sequences to the non-causal two-dimensional image space. We scale the Hyena convolution kernels beyond the feature map size up to 191$\times$191 to maximize the ERF while maintaining sub-quadratic complexity in the number of pixels. We integrate our two-dimensional Hyena, HyenaPixel, and bidirectional Hyena into the MetaFormer framework. For image categorization, HyenaPixel and bidirectional Hyena achieve a competitive ImageNet-1k top-1 accuracy of 83.0% and 83.5%, respectively, while outperforming other large-kernel networks. Combining HyenaPixel with attention further increases accuracy to 83.6%. We attribute the success of attention to the lack of spatial bias in later stages and support this finding with bidirectional Hyena.
TCIG: Two-Stage Controlled Image Generation with Quality Enhancement through Diffusion
Mar 02, 2024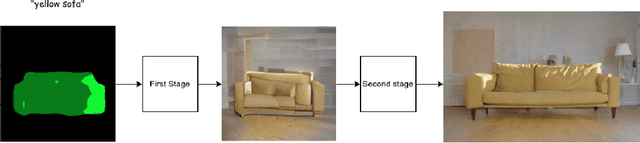



In recent years, significant progress has been made in the development of text-to-image generation models. However, these models still face limitations when it comes to achieving full controllability during the generation process. Often, specific training or the use of limited models is required, and even then, they have certain restrictions. To address these challenges, A two-stage method that effectively combines controllability and high quality in the generation of images is proposed. This approach leverages the expertise of pre-trained models to achieve precise control over the generated images, while also harnessing the power of diffusion models to achieve state-of-the-art quality. By separating controllability from high quality, This method achieves outstanding results. It is compatible with both latent and image space diffusion models, ensuring versatility and flexibility. Moreover, This approach consistently produces comparable outcomes to the current state-of-the-art methods in the field. Overall, This proposed method represents a significant advancement in text-to-image generation, enabling improved controllability without compromising on the quality of the generated images.
Relaxometry Guided Quantitative Cardiac Magnetic Resonance Image Reconstruction
Mar 01, 2024Deep learning-based methods have achieved prestigious performance for magnetic resonance imaging (MRI) reconstruction, enabling fast imaging for many clinical applications. Previous methods employ convolutional networks to learn the image prior as the regularization term. In quantitative MRI, the physical model of nuclear magnetic resonance relaxometry is known, providing additional prior knowledge for image reconstruction. However, traditional reconstruction networks are limited to learning the spatial domain prior knowledge, ignoring the relaxometry prior. Therefore, we propose a relaxometry-guided quantitative MRI reconstruction framework to learn the spatial prior from data and the relaxometry prior from MRI physics. Additionally, we also evaluated the performance of two popular reconstruction backbones, namely, recurrent variational networks (RVN) and variational networks (VN) with U- Net. Experiments demonstrate that the proposed method achieves highly promising results in quantitative MRI reconstruction.