 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Weakly-Supervised Stitching Network for Real-World Panoramic Image Generation
Sep 13, 2022
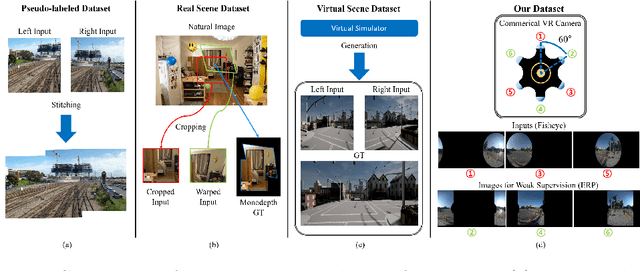
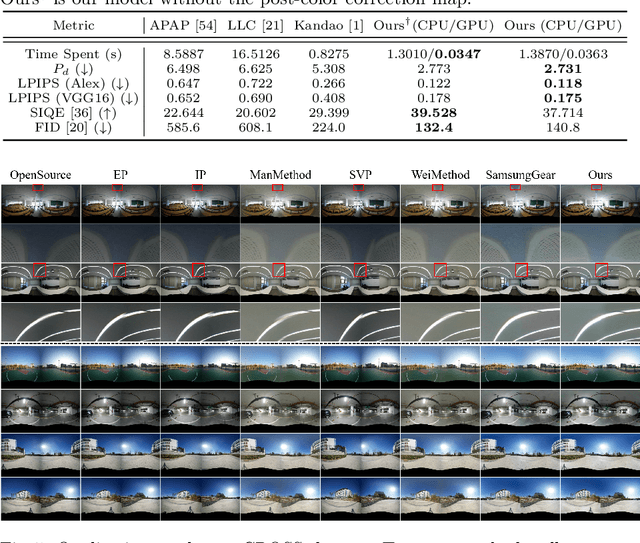
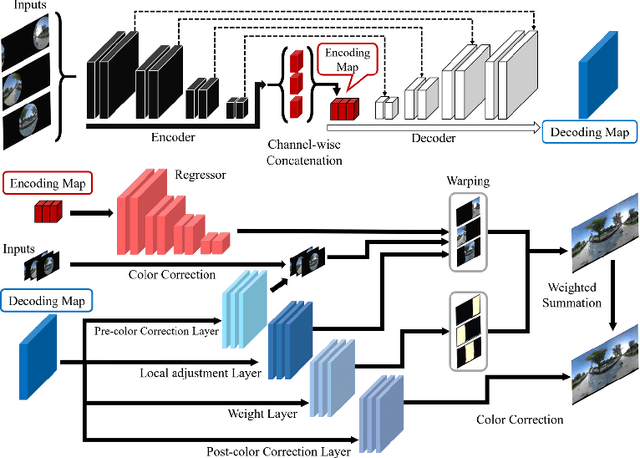

Recently, there has been growing attention on an end-to-end deep learning-based stitching model. However, the most challenging point in deep learning-based stitching is to obtain pairs of input images with a narrow field of view and ground truth images with a wide field of view captured from real-world scenes. To overcome this difficulty, we develop a weakly-supervised learning mechanism to train the stitching model without requiring genuine ground truth images. In addition, we propose a stitching model that takes multiple real-world fisheye images as inputs and creates a 360 output image in an equirectangular projection format. In particular, our model consists of color consistency corrections, warping, and blending, and is trained by perceptual and SSIM losses. The effectiveness of the proposed algorithm is verified on two real-world stitching datasets.
Time-lapse image classification using a diffractive neural network
Aug 23, 2022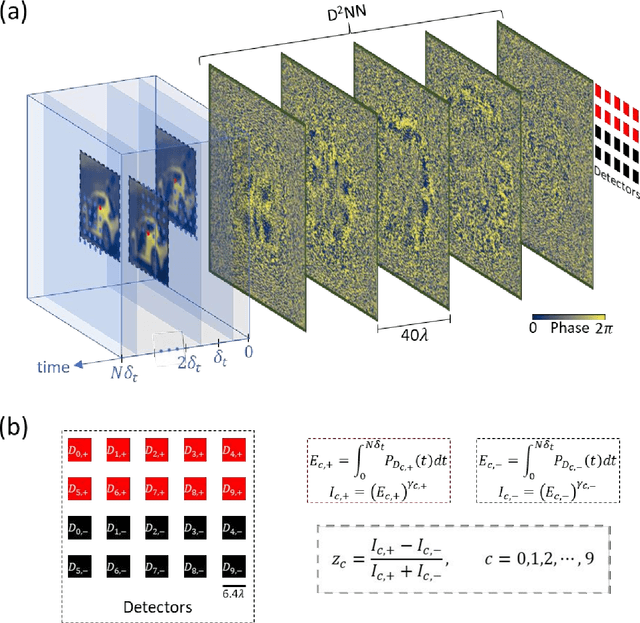
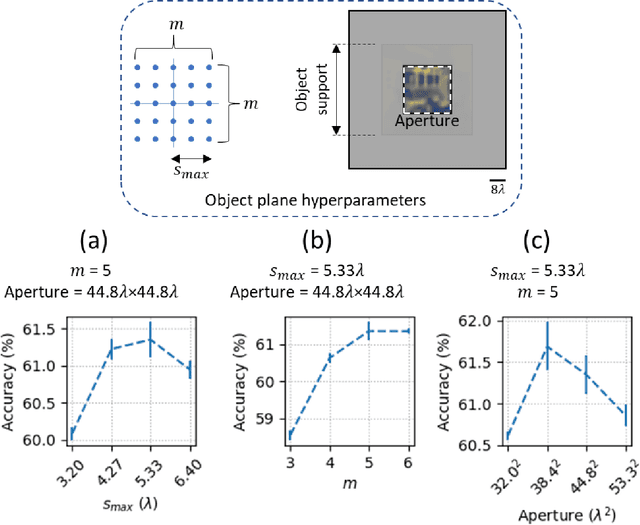
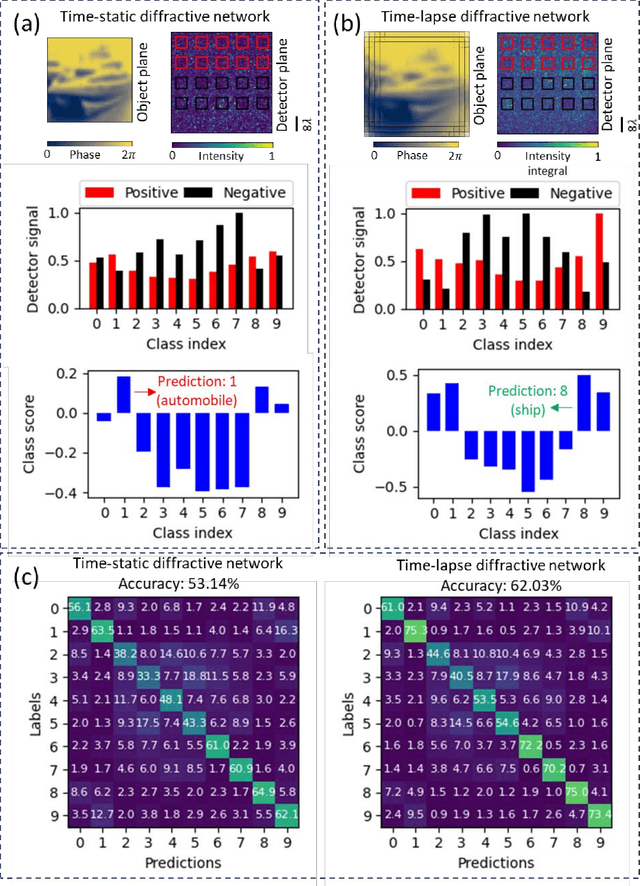
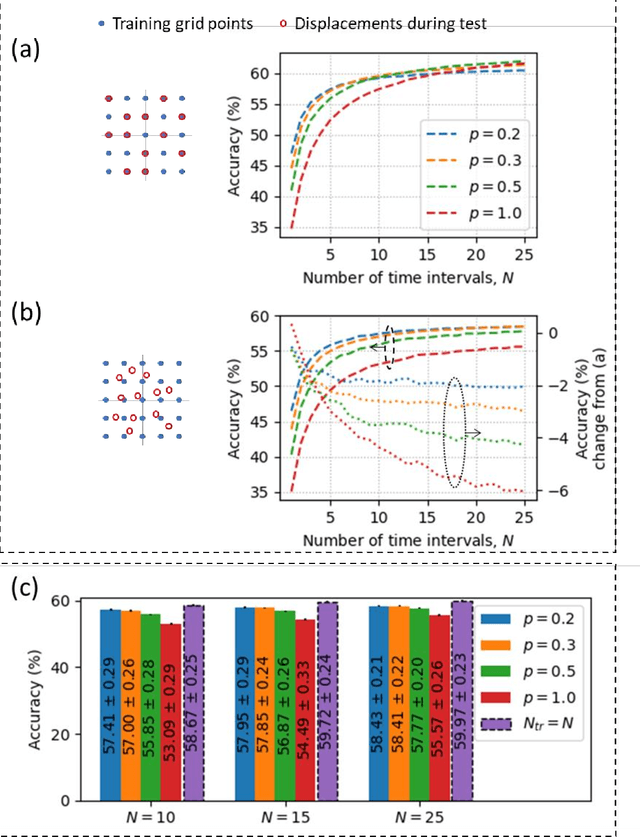
Diffractive deep neural networks (D2NNs) define an all-optical computing framework comprised of spatially engineered passive surfaces that collectively process optical input information by modulating the amplitude and/or the phase of the propagating light. Diffractive optical networks complete their computational tasks at the speed of light propagation through a thin diffractive volume, without any external computing power while exploiting the massive parallelism of optics. Diffractive networks were demonstrated to achieve all-optical classification of objects and perform universal linear transformations. Here we demonstrate, for the first time, a "time-lapse" image classification scheme using a diffractive network, significantly advancing its classification accuracy and generalization performance on complex input objects by using the lateral movements of the input objects and/or the diffractive network, relative to each other. In a different context, such relative movements of the objects and/or the camera are routinely being used for image super-resolution applications; inspired by their success, we designed a time-lapse diffractive network to benefit from the complementary information content created by controlled or random lateral shifts. We numerically explored the design space and performance limits of time-lapse diffractive networks, revealing a blind testing accuracy of 62.03% on the optical classification of objects from the CIFAR-10 dataset. This constitutes the highest inference accuracy achieved so far using a single diffractive network on the CIFAR-10 dataset. Time-lapse diffractive networks will be broadly useful for the spatio-temporal analysis of input signals using all-optical processors.
Multi-Target Landmark Detection with Incomplete Images via Reinforcement Learning and Shape Prior
Jan 13, 2023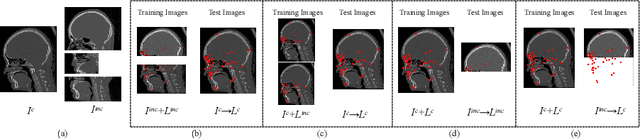
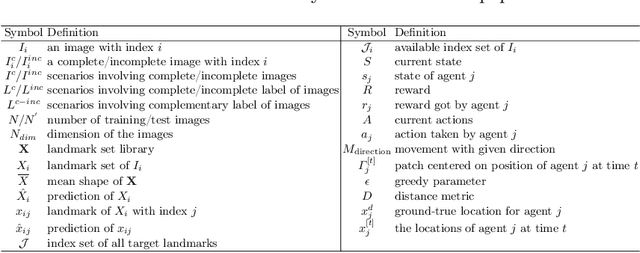

Medical images are generally acquired with limited field-of-view (FOV), which could lead to incomplete regions of interest (ROI), and thus impose a great challenge on medical image analysis. This is particularly evident for the learning-based multi-target landmark detection, where algorithms could be misleading to learn primarily the variation of background due to the varying FOV, failing the detection of targets. Based on learning a navigation policy, instead of predicting targets directly, reinforcement learning (RL)-based methods have the potential totackle this challenge in an efficient manner. Inspired by this, in this work we propose a multi-agent RL framework for simultaneous multi-target landmark detection. This framework is aimed to learn from incomplete or (and) complete images to form an implicit knowledge of global structure, which is consolidated during the training stage for the detection of targets from either complete or incomplete test images. To further explicitly exploit the global structural information from incomplete images, we propose to embed a shape model into the RL process. With this prior knowledge, the proposed RL model can not only localize dozens of targetssimultaneously, but also work effectively and robustly in the presence of incomplete images. We validated the applicability and efficacy of the proposed method on various multi-target detection tasks with incomplete images from practical clinics, using body dual-energy X-ray absorptiometry (DXA), cardiac MRI and head CT datasets. Results showed that our method could predict whole set of landmarks with incomplete training images up to 80% missing proportion (average distance error 2.29 cm on body DXA), and could detect unseen landmarks in regions with missing image information outside FOV of target images (average distance error 6.84 mm on 3D half-head CT).
SelectionConv: Convolutional Neural Networks for Non-rectilinear Image Data
Jul 18, 2022
Convolutional Neural Networks have revolutionized vision applications. There are image domains and representations, however, that cannot be handled by standard CNNs (e.g., spherical images, superpixels). Such data are usually processed using networks and algorithms specialized for each type. In this work, we show that it may not always be necessary to use specialized neural networks to operate on such spaces. Instead, we introduce a new structured graph convolution operator that can copy 2D convolution weights, transferring the capabilities of already trained traditional CNNs to our new graph network. This network can then operate on any data that can be represented as a positional graph. By converting non-rectilinear data to a graph, we can apply these convolutions on these irregular image domains without requiring training on large domain-specific datasets. Results of transferring pre-trained image networks for segmentation, stylization, and depth prediction are demonstrated for a variety of such data forms.
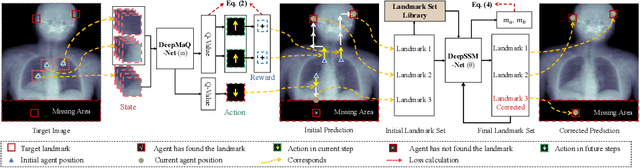
PADL: Language-Directed Physics-Based Character Control
Jan 31, 2023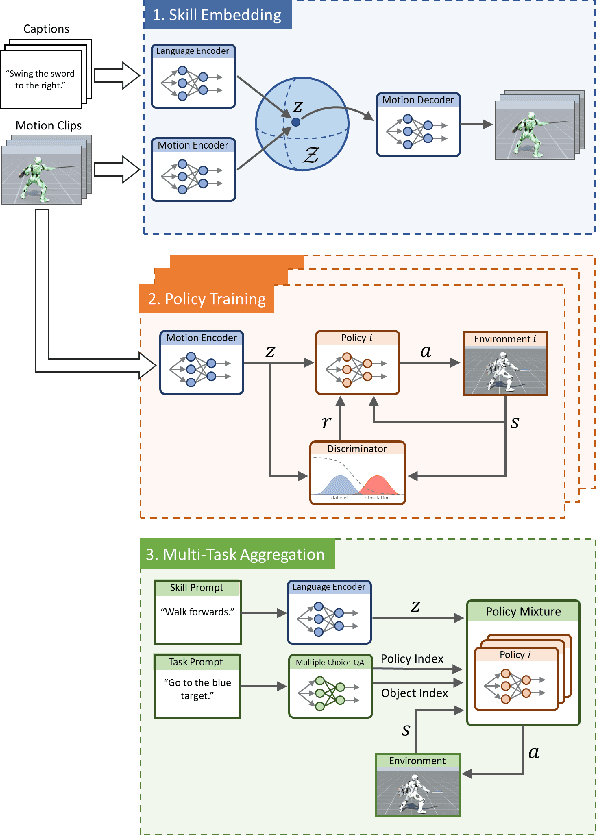

Developing systems that can synthesize natural and life-like motions for simulated characters has long been a focus for computer animation. But in order for these systems to be useful for downstream applications, they need not only produce high-quality motions, but must also provide an accessible and versatile interface through which users can direct a character's behaviors. Natural language provides a simple-to-use and expressive medium for specifying a user's intent. Recent breakthroughs in natural language processing (NLP) have demonstrated effective use of language-based interfaces for applications such as image generation and program synthesis. In this work, we present PADL, which leverages recent innovations in NLP in order to take steps towards developing language-directed controllers for physics-based character animation. PADL allows users to issue natural language commands for specifying both high-level tasks and low-level skills that a character should perform. We present an adversarial imitation learning approach for training policies to map high-level language commands to low-level controls that enable a character to perform the desired task and skill specified by a user's commands. Furthermore, we propose a multi-task aggregation method that leverages a language-based multiple-choice question-answering approach to determine high-level task objectives from language commands. We show that our framework can be applied to effectively direct a simulated humanoid character to perform a diverse array of complex motor skills.
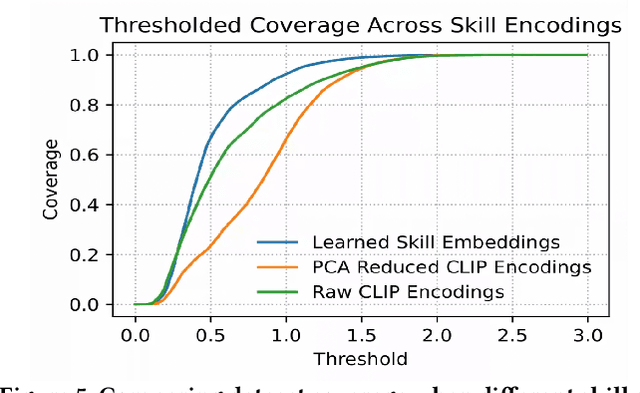
Learning Vision-based Robotic Manipulation Tasks Sequentially in Offline Reinforcement Learning Settings
Jan 31, 2023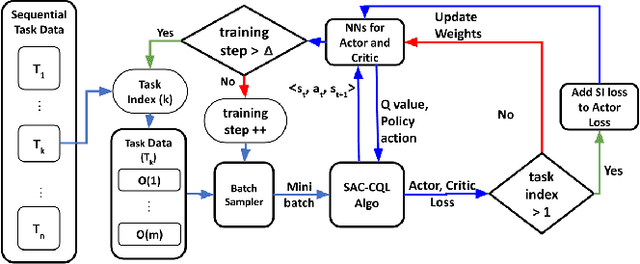
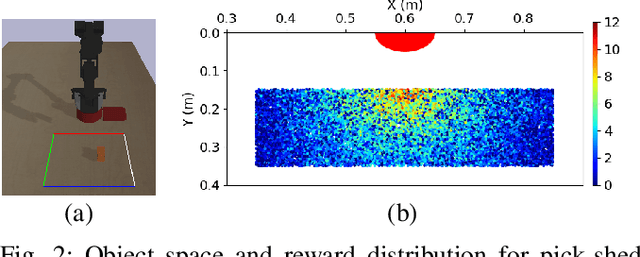
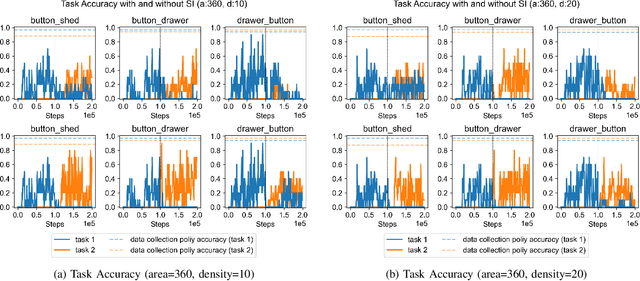
With the rise of deep reinforcement learning (RL) methods, many complex robotic manipulation tasks are being solved. However, harnessing the full power of deep learning requires large datasets. Online-RL does not suit itself readily into this paradigm due to costly and time-taking agent environment interaction. Therefore recently, many offline-RL algorithms have been proposed to learn robotic tasks. But mainly, all such methods focus on a single task or multi-task learning, which requires retraining every time we need to learn a new task. Continuously learning tasks without forgetting previous knowledge combined with the power of offline deep-RL would allow us to scale the number of tasks by keep adding them one-after-another. In this paper, we investigate the effectiveness of regularisation-based methods like synaptic intelligence for sequentially learning image-based robotic manipulation tasks in an offline-RL setup. We evaluate the performance of this combined framework against common challenges of sequential learning: catastrophic forgetting and forward knowledge transfer. We performed experiments with different task combinations to analyze the effect of task ordering. We also investigated the effect of the number of object configurations and density of robot trajectories. We found that learning tasks sequentially helps in the propagation of knowledge from previous tasks, thereby reducing the time required to learn a new task. Regularisation based approaches for continuous learning like the synaptic intelligence method although helps in mitigating catastrophic forgetting but has shown only limited transfer of knowledge from previous tasks.
NASiam: Efficient Representation Learning using Neural Architecture Search for Siamese Networks
Jan 31, 2023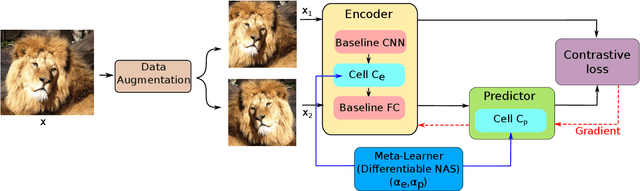
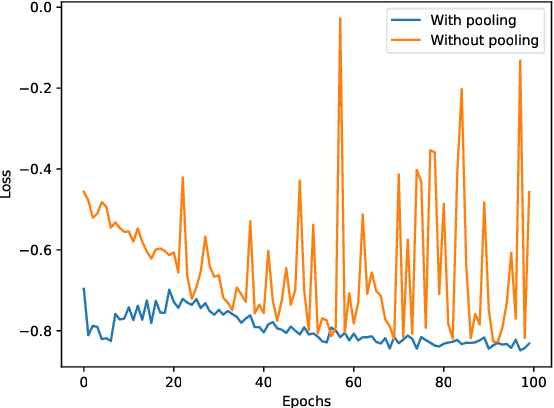
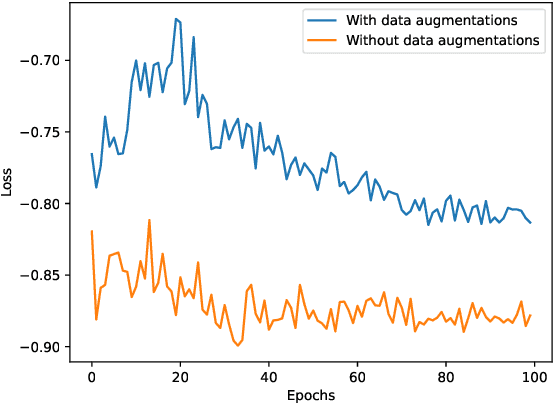
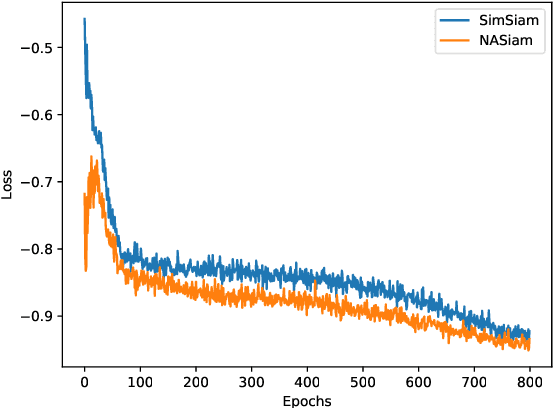
Siamese networks are one of the most trending methods to achieve self-supervised visual representation learning (SSL). Since hand labeling is costly, SSL can play a crucial part by allowing deep learning to train on large unlabeled datasets. Meanwhile, Neural Architecture Search (NAS) is becoming increasingly important as a technique to discover novel deep learning architectures. However, early NAS methods based on reinforcement learning or evolutionary algorithms suffered from ludicrous computational and memory costs. In contrast, differentiable NAS, a gradient-based approach, has the advantage of being much more efficient and has thus retained most of the attention in the past few years. In this article, we present NASiam, a novel approach that uses for the first time differentiable NAS to improve the multilayer perceptron projector and predictor (encoder/predictor pair) architectures inside siamese-networks-based contrastive learning frameworks (e.g., SimCLR, SimSiam, and MoCo) while preserving the simplicity of previous baselines. We crafted a search space designed explicitly for multilayer perceptrons, inside which we explored several alternatives to the standard ReLU activation function. We show that these new architectures allow ResNet backbone convolutional models to learn strong representations efficiently. NASiam reaches competitive performance in both small-scale (i.e., CIFAR-10/CIFAR-100) and large-scale (i.e., ImageNet) image classification datasets while costing only a few GPU hours. We discuss the composition of the NAS-discovered architectures and emit hypotheses on why they manage to prevent collapsing behavior. Our code is available at https://github.com/aheuillet/NASiam.
Sparse-based Domain Adaptation Network for OCTA Image Super-Resolution Reconstruction
Jul 25, 2022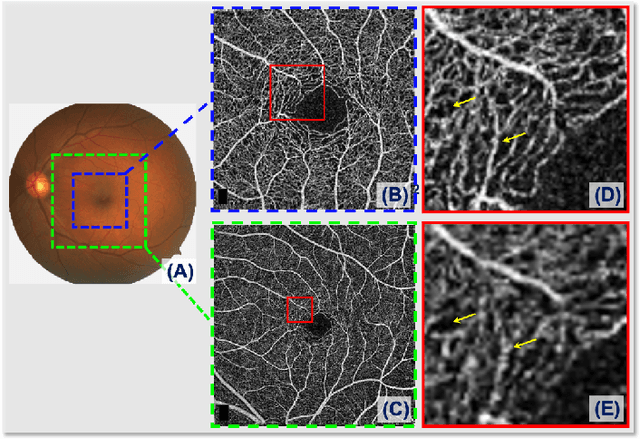
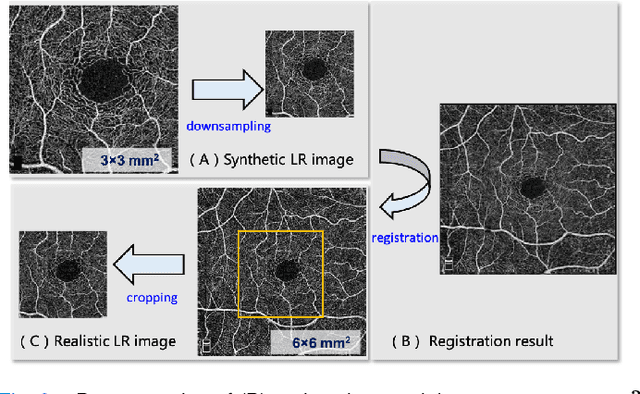
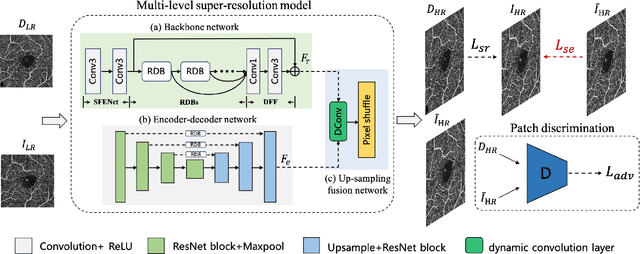
Retinal Optical Coherence Tomography Angiography (OCTA) with high-resolution is important for the quantification and analysis of retinal vasculature. However, the resolution of OCTA images is inversely proportional to the field of view at the same sampling frequency, which is not conducive to clinicians for analyzing larger vascular areas. In this paper, we propose a novel Sparse-based domain Adaptation Super-Resolution network (SASR) for the reconstruction of realistic 6x6 mm2/low-resolution (LR) OCTA images to high-resolution (HR) representations. To be more specific, we first perform a simple degradation of the 3x3 mm2/high-resolution (HR) image to obtain the synthetic LR image. An efficient registration method is then employed to register the synthetic LR with its corresponding 3x3 mm2 image region within the 6x6 mm2 image to obtain the cropped realistic LR image. We then propose a multi-level super-resolution model for the fully-supervised reconstruction of the synthetic data, guiding the reconstruction of the realistic LR images through a generative-adversarial strategy that allows the synthetic and realistic LR images to be unified in the feature domain. Finally, a novel sparse edge-aware loss is designed to dynamically optimize the vessel edge structure. Extensive experiments on two OCTA sets have shown that our method performs better than state-of-the-art super-resolution reconstruction methods. In addition, we have investigated the performance of the reconstruction results on retina structure segmentations, which further validate the effectiveness of our approach.
Using Atom-Like Local Image Features to Study Human Genetics and Neuroanatomy in Large Sets of 3D Medical Image Volumes
Aug 25, 2022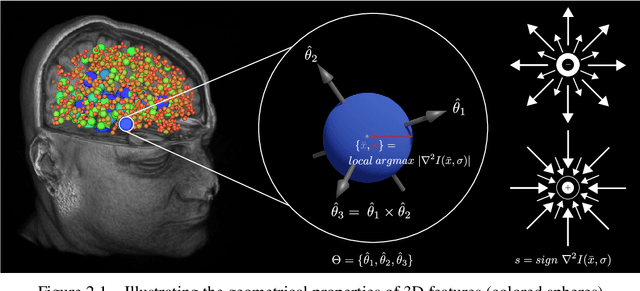
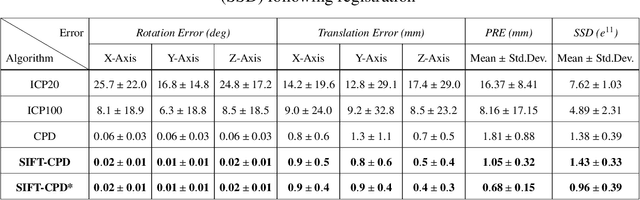
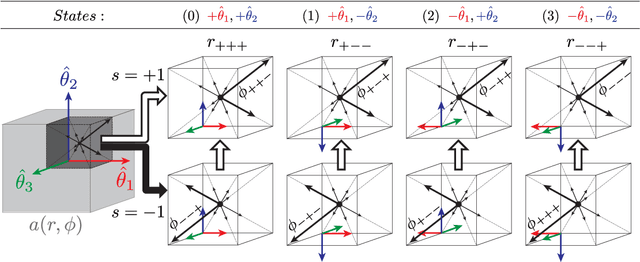
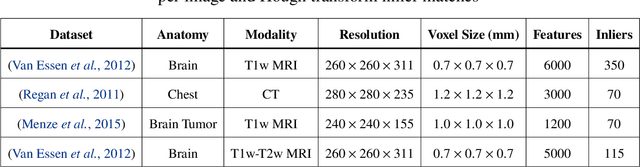
The contributions of this thesis stem from technology developed to analyse large sets of volumetric images in terms of atom-like features extracted in 3D image space, following SIFT algorithm in 2D image space. New feature properties are introduced including a binary feature sign, analogous to an electrical charge, and a discrete set of symmetric feature orientation states in 3D space. These new properties are leveraged to extend feature invariance to include the sign inversion and parity (SP) transform, analogous to the charge conjugation and parity (CP) transform between a particle and its antiparticle in quantum mechanics, thereby accounting for local intensity contrast inversion between imaging modalities and axis reflections due to shape symmetry. A novel exponential kernel is proposed to quantify the similarity of a pair of features extracted in different images from their properties including location, scale, orientation, sign and appearance. A novel measure entitled the soft Jaccard is proposed to quantify the similarity of a pair of feature sets based on their overlap or intersection-over-union, where a kernel establishes non-binary or soft equivalence between a pair of feature elements. The soft Jaccard may be used to identify pairs of feature sets extracted from the same individuals or families with high accuracy, and a simple distance threshold led to the surprising discovery of previously unknown individual and family labeling errors in major public neuroimage datasets. A new algorithm is proposed to register or spatially align a pair of feature sets, entitled SIFT Coherent Point Drift (SIFT-CPD), by identifying a transform that maximizes the soft Jaccard between a fixed feature set and a transformed set. SIFT-CPD achieves faster and more accurate registration than the original CPD algorithm based on feature location information alone, in a variety of challenging.
Perceptual Attacks of No-Reference Image Quality Models with Human-in-the-Loop
Oct 03, 2022


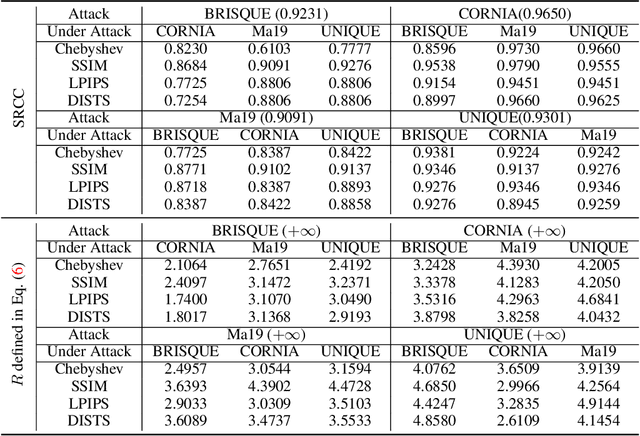
No-reference image quality assessment (NR-IQA) aims to quantify how humans perceive visual distortions of digital images without access to their undistorted references. NR-IQA models are extensively studied in computational vision, and are widely used for performance evaluation and perceptual optimization of man-made vision systems. Here we make one of the first attempts to examine the perceptual robustness of NR-IQA models. Under a Lagrangian formulation, we identify insightful connections of the proposed perceptual attack to previous beautiful ideas in computer vision and machine learning. We test one knowledge-driven and three data-driven NR-IQA methods under four full-reference IQA models (as approximations to human perception of just-noticeable differences). Through carefully designed psychophysical experiments, we find that all four NR-IQA models are vulnerable to the proposed perceptual attack. More interestingly, we observe that the generated counterexamples are not transferable, manifesting themselves as distinct design flows of respective NR-IQA methods.