 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Possible Converter to Denoise the Images of Exoplanet Candidates through Machine Learning Techniques
Jan 11, 2023
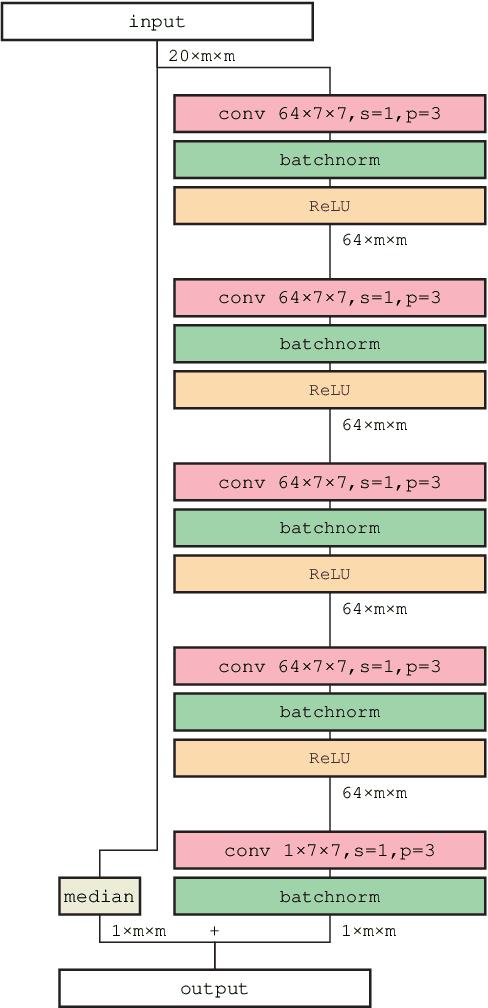

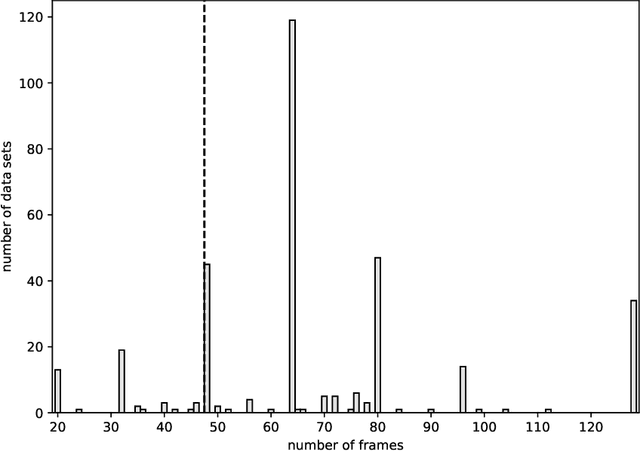
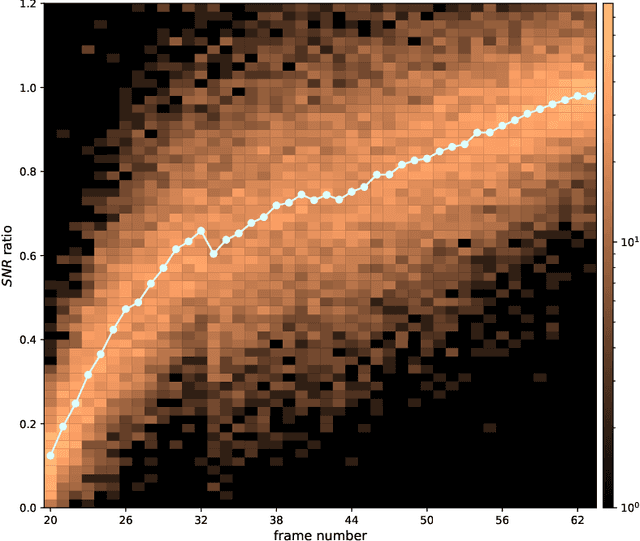
The method of direct imaging has detected many exoplanets and made important contribution to the field of planet formation. The standard method employs angular differential imaging (ADI) technique, and more ADI image frames could lead to the results with larger signal-to-noise-ratio (SNR). However, it would need precious observational time from large telescopes, which are always over-subscribed. We thus explore the possibility to generate a converter which can increase the SNR derived from a smaller number of ADI frames. The machine learning technique with two-dimension convolutional neural network (2D-CNN) is tested here. Several 2D-CNN models are trained and their performances of denoising are presented and compared. It is found that our proposed Modified five-layer Wide Inference Network with the Residual learning technique and Batch normalization (MWIN5-RB) can give the best result. We conclude that this MWIN5-RB can be employed as a converter for future observational data.
* 30 pages, 12 figures, 1 table, published by New Astronomy
Local Learning on Transformers via Feature Reconstruction
Dec 29, 2022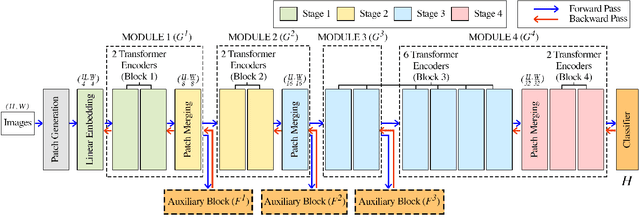

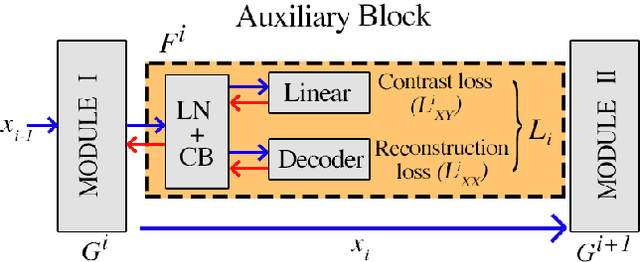
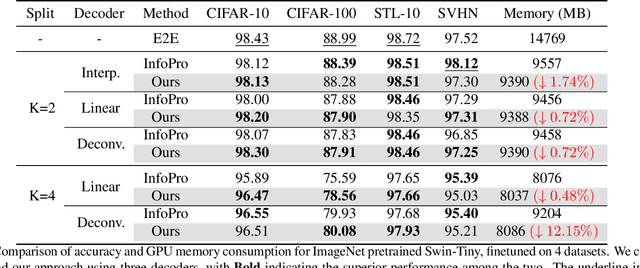
Transformers are becoming increasingly popular due to their superior performance over conventional convolutional neural networks(CNNs). However, transformers usually require a much larger amount of memory to train than CNNs, which prevents their application in many low resource settings. Local learning, which divides the network into several distinct modules and trains them individually, is a promising alternative to the end-to-end (E2E) training approach to reduce the amount of memory for training and to increase parallelism. This paper is the first to apply Local Learning on transformers for this purpose. The standard CNN-based local learning method, InfoPro [32], reconstructs the input images for each module in a CNN. However, reconstructing the entire image does not generalize well. In this paper, we propose a new mechanism for each local module, where instead of reconstructing the entire image, we reconstruct its input features, generated from previous modules. We evaluate our approach on 4 commonly used datasets and 3 commonly used decoder structures on Swin-Tiny. The experiments show that our approach outperforms InfoPro-Transformer, the InfoPro with Transfomer backbone we introduced, by at up to 0.58% on CIFAR-10, CIFAR-100, STL-10 and SVHN datasets, while using up to 12% less memory. Compared to the E2E approach, we require 36% less GPU memory when the network is divided into 2 modules and 45% less GPU memory when the network is divided into 4 modules.
Self-Supervised Geometry-Aware Encoder for Style-Based 3D GAN Inversion
Dec 15, 2022
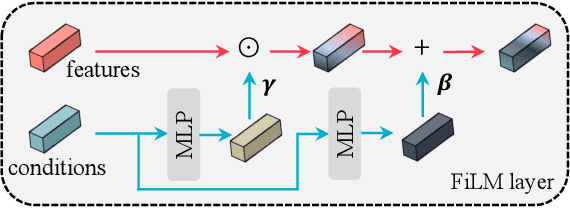

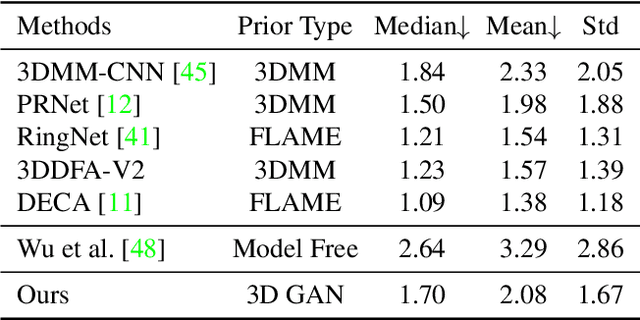
StyleGAN has achieved great progress in 2D face reconstruction and semantic editing via image inversion and latent editing. While studies over extending 2D StyleGAN to 3D faces have emerged, a corresponding generic 3D GAN inversion framework is still missing, limiting the applications of 3D face reconstruction and semantic editing. In this paper, we study the challenging problem of 3D GAN inversion where a latent code is predicted given a single face image to faithfully recover its 3D shapes and detailed textures. The problem is ill-posed: innumerable compositions of shape and texture could be rendered to the current image. Furthermore, with the limited capacity of a global latent code, 2D inversion methods cannot preserve faithful shape and texture at the same time when applied to 3D models. To solve this problem, we devise an effective self-training scheme to constrain the learning of inversion. The learning is done efficiently without any real-world 2D-3D training pairs but proxy samples generated from a 3D GAN. In addition, apart from a global latent code that captures the coarse shape and texture information, we augment the generation network with a local branch, where pixel-aligned features are added to faithfully reconstruct face details. We further consider a new pipeline to perform 3D view-consistent editing. Extensive experiments show that our method outperforms state-of-the-art inversion methods in both shape and texture reconstruction quality. Code and data will be released.
A Probabilistic Framework for Visual Localization in Ambiguous Scenes
Jan 05, 2023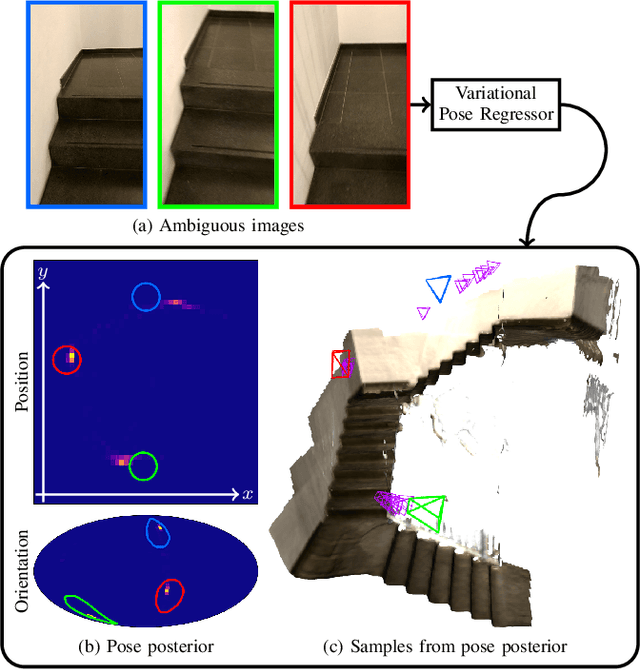
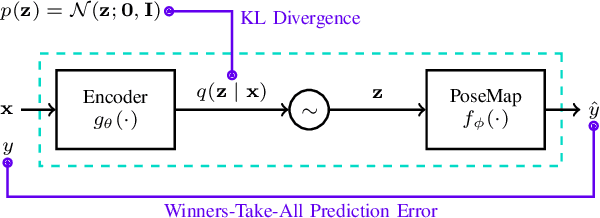


Visual localization allows autonomous robots to relocalize when losing track of their pose by matching their current observation with past ones. However, ambiguous scenes pose a challenge for such systems, as repetitive structures can be viewed from many distinct, equally likely camera poses, which means it is not sufficient to produce a single best pose hypothesis. In this work, we propose a probabilistic framework that for a given image predicts the arbitrarily shaped posterior distribution of its camera pose. We do this via a novel formulation of camera pose regression using variational inference, which allows sampling from the predicted distribution. Our method outperforms existing methods on localization in ambiguous scenes. Code and data will be released at https://github.com/efreidun/vapor.
BinImg2Vec: Augmenting Malware Binary Image Classification with Data2Vec
Sep 02, 2022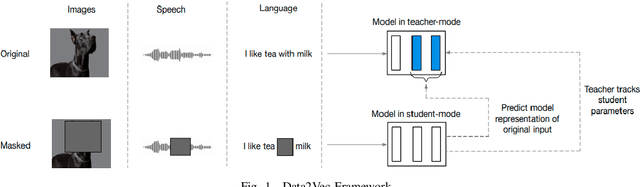

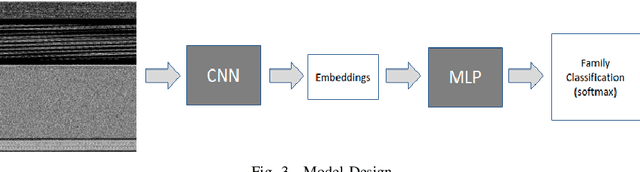
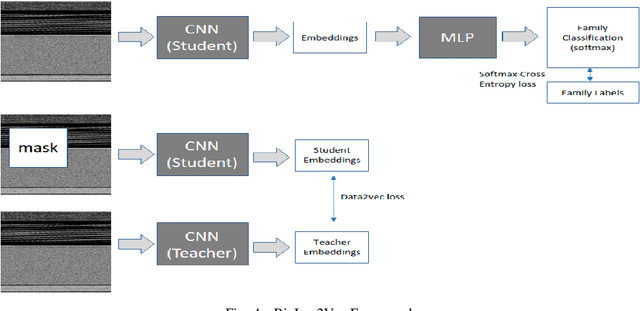
Rapid digitalisation spurred by the Covid-19 pandemic has resulted in more cyber crime. Malware-as-a-service is now a booming business for cyber criminals. With the surge in malware activities, it is vital for cyber defenders to understand more about the malware samples they have at hand as such information can greatly influence their next course of actions during a breach. Recently, researchers have shown how malware family classification can be done by first converting malware binaries into grayscale images and then passing them through neural networks for classification. However, most work focus on studying the impact of different neural network architectures on classification performance. In the last year, researchers have shown that augmenting supervised learning with self-supervised learning can improve performance. Even more recently, Data2Vec was proposed as a modality agnostic self-supervised framework to train neural networks. In this paper, we present BinImg2Vec, a framework of training malware binary image classifiers that incorporates both self-supervised learning and supervised learning to produce a model that consistently outperforms one trained only via supervised learning. We were able to achieve a 4% improvement in classification performance and a 0.5% reduction in performance variance over multiple runs. We also show how our framework produces embeddings that can be well clustered, facilitating model explanability.
Deep Learning-Based MR Image Re-parameterization
Jun 11, 2022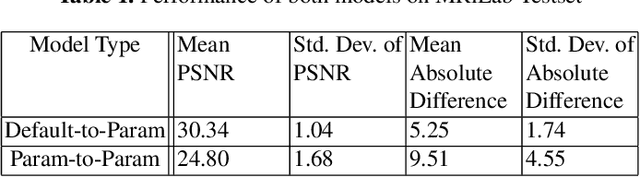
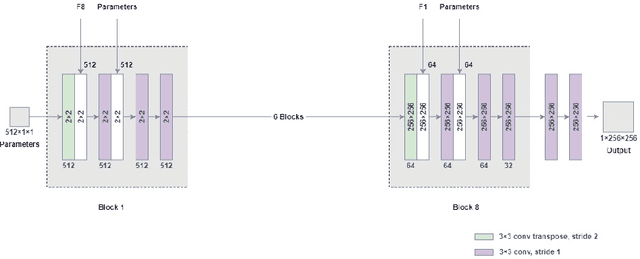
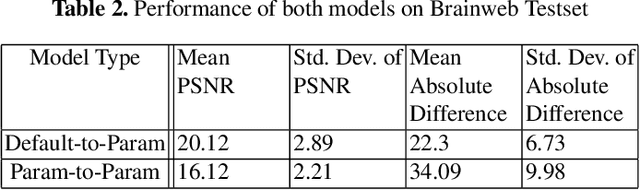
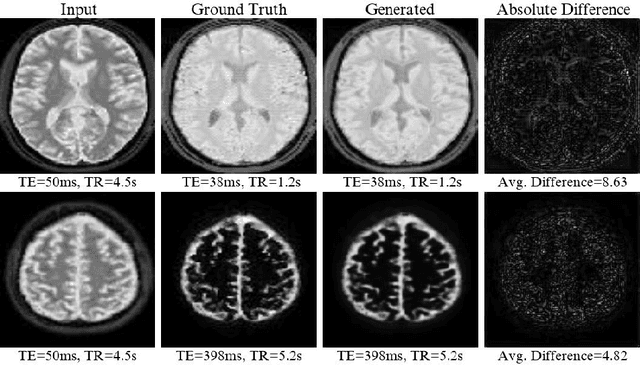
Magnetic resonance (MR) image re-parameterization refers to the process of generating via simulations of an MR image with a new set of MRI scanning parameters. Different parameter values generate distinct contrast between different tissues, helping identify pathologic tissue. Typically, more than one scan is required for diagnosis; however, acquiring repeated scans can be costly, time-consuming, and difficult for patients. Thus, using MR image re-parameterization to predict and estimate the contrast in these imaging scans can be an effective alternative. In this work, we propose a novel deep learning (DL) based convolutional model for MRI re-parameterization. Based on our preliminary results, DL-based techniques hold the potential to learn the non-linearities that govern the re-parameterization.
Asymmetric Cross-Scale Alignment for Text-Based Person Search
Nov 26, 2022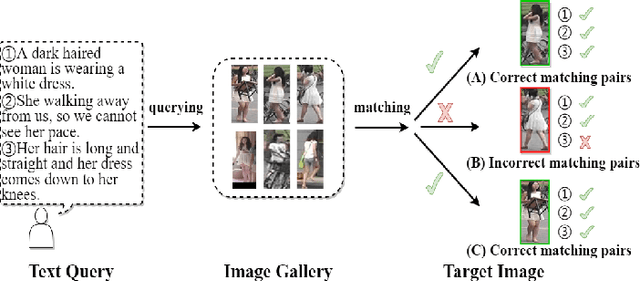
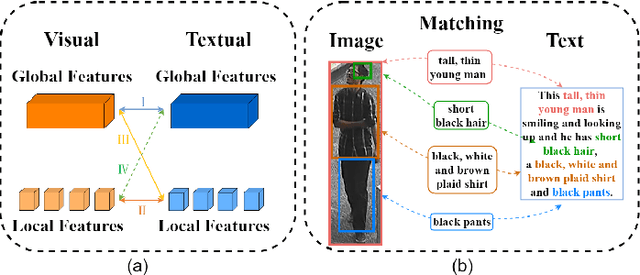
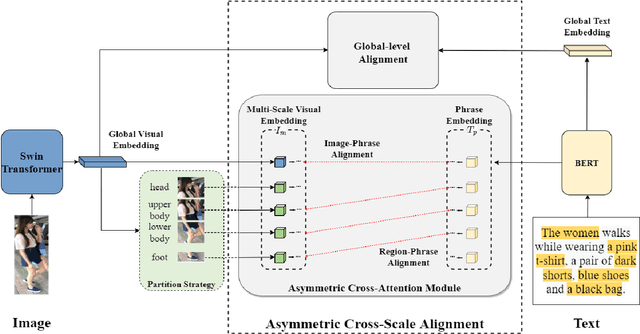
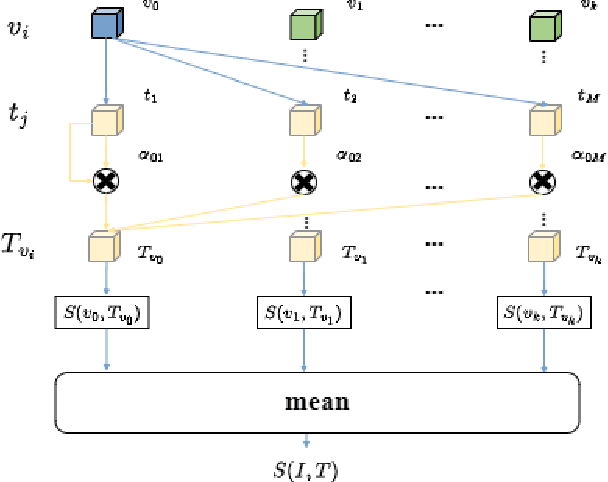
Text-based person search (TBPS) is of significant importance in intelligent surveillance, which aims to retrieve pedestrian images with high semantic relevance to a given text description. This retrieval task is characterized with both modal heterogeneity and fine-grained matching. To implement this task, one needs to extract multi-scale features from both image and text domains, and then perform the cross-modal alignment. However, most existing approaches only consider the alignment confined at their individual scales, e.g., an image-sentence or a region-phrase scale. Such a strategy adopts the presumable alignment in feature extraction, while overlooking the cross-scale alignment, e.g., image-phrase. In this paper, we present a transformer-based model to extract multi-scale representations, and perform Asymmetric Cross-Scale Alignment (ACSA) to precisely align the two modalities. Specifically, ACSA consists of a global-level alignment module and an asymmetric cross-attention module, where the former aligns an image and texts on a global scale, and the latter applies the cross-attention mechanism to dynamically align the cross-modal entities in region/image-phrase scales. Extensive experiments on two benchmark datasets CUHK-PEDES and RSTPReid demonstrate the effectiveness of our approach. Codes are available at \href{url}{https://github.com/mul-hjh/ACSA}.
Single-shot refractive index slice imaging using spectrally multiplexed optical transfer function reshaping
Jan 13, 2023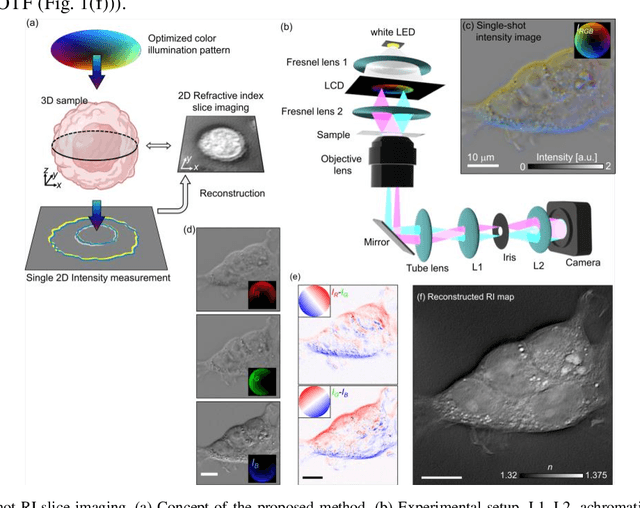
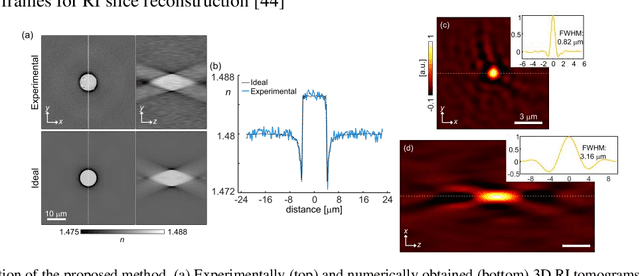
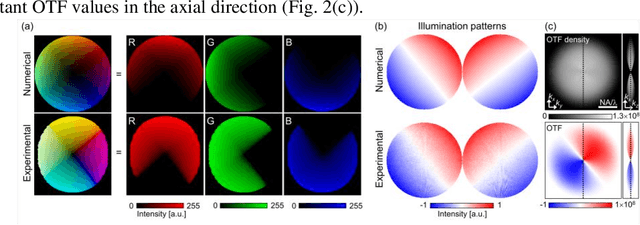
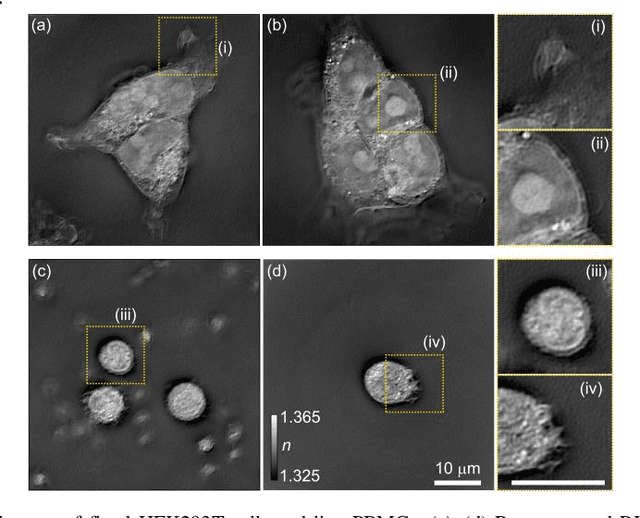
The refractive index (RI) of cells and tissues is crucial in pathophysiology as a noninvasive and quantitative imaging contrast. Although its measurements have been demonstrated using three-dimensional quantitative phase imaging methods, these methods often require bulky interferometric setups or multiple measurements, which limits the measurement sensitivity and speed. Here, we present a single-shot RI imaging method that visualizes the RI of the in-focus region of a sample. By exploiting spectral multiplexing and optical transfer function engineering, three color-coded intensity images of a sample with three optimized illuminations were simultaneously obtained in a single-shot measurement. The measured intensity images were then deconvoluted to obtain the RI image of the in-focus slice of the sample. As a proof of concept, a setup was built using Fresnel lenses and a liquid-crystal display. For validation purposes, we measured microspheres of known RI and cross-validated the results with simulated results. Various static and highly dynamic biological cells were imaged to demonstrate that the proposed method can conduct single-shot RI slice imaging of biological samples with subcellular resolution.
A Medical Image Fusion Method based on MDLatLRRv2
Jul 02, 2022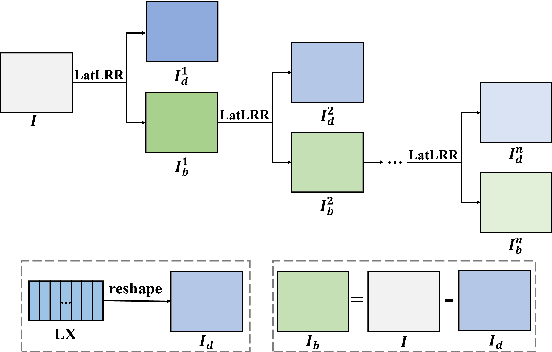
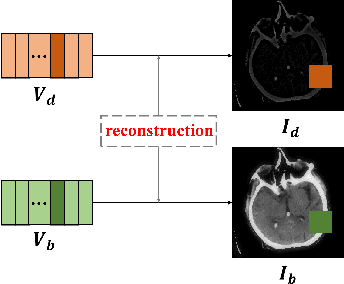
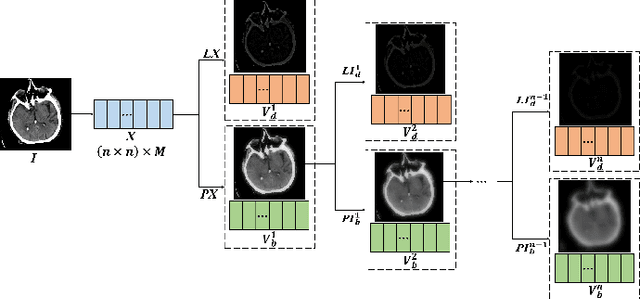
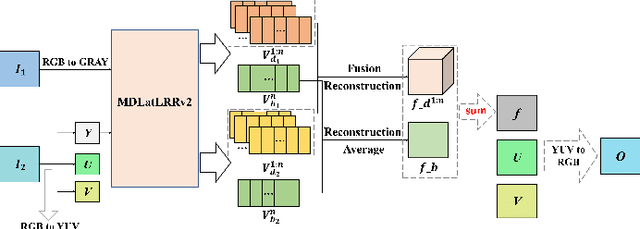
Since MDLatLRR only considers detailed parts (salient features) of input images extracted by latent low-rank representation (LatLRR), it doesn't use base parts (principal features) extracted by LatLRR effectively. Therefore, we proposed an improved multi-level decomposition method called MDLatLRRv2 which effectively analyzes and utilizes all the image features obtained by LatLRR. Then we apply MDLatLRRv2 to medical image fusion. The base parts are fused by average strategy and the detail parts are fused by nuclear-norm operation. The comparison with the existing methods demonstrates that the proposed method can achieve state-of-the-art fusion performance in objective and subjective assessment.
A domain-decomposed VAE method for Bayesian inverse problems
Jan 09, 2023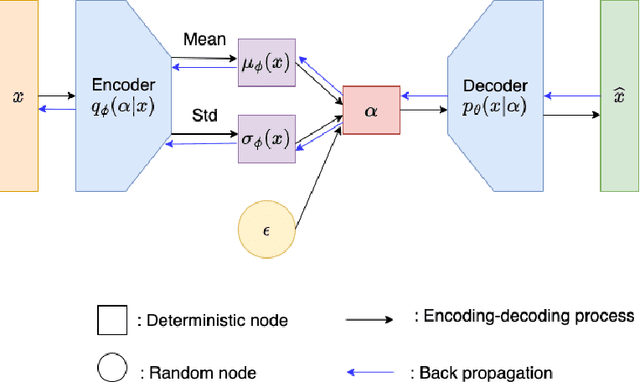
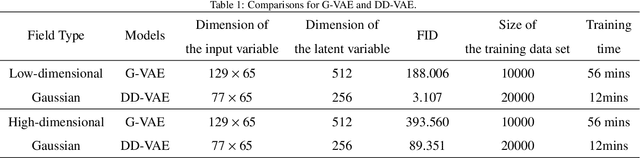
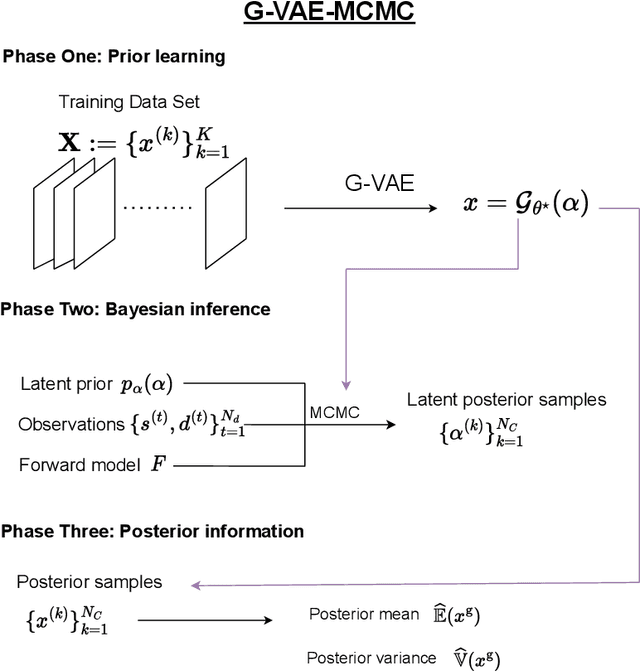

Bayesian inverse problems are often computationally challenging when the forward model is governed by complex partial differential equations (PDEs). This is typically caused by expensive forward model evaluations and high-dimensional parameterization of priors. This paper proposes a domain-decomposed variational auto-encoder Markov chain Monte Carlo (DD-VAE-MCMC) method to tackle these challenges simultaneously. Through partitioning the global physical domain into small subdomains, the proposed method first constructs local deterministic generative models based on local historical data, which provide efficient local prior representations. Gaussian process models with active learning address the domain decomposition interface conditions. Then inversions are conducted on each subdomain independently in parallel and in low-dimensional latent parameter spaces. The local inference solutions are post-processed through the Poisson image blending procedure to result in an efficient global inference result. Numerical examples are provided to demonstrate the performance of the proposed method.