 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fast Hierarchical Deep Unfolding Network for Image Compressed Sensing
Aug 03, 2022
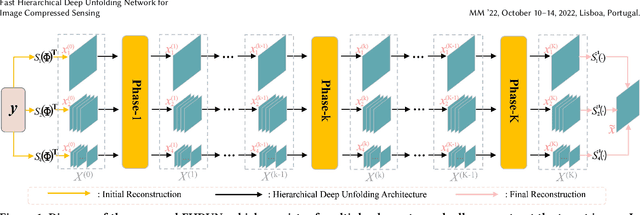
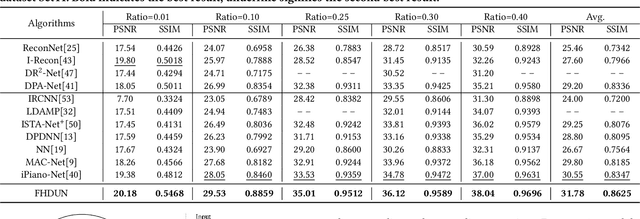
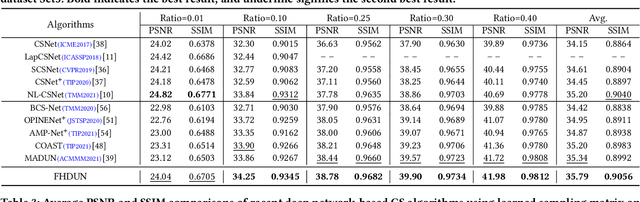
By integrating certain optimization solvers with deep neural network, deep unfolding network (DUN) has attracted much attention in recent years for image compressed sensing (CS). However, there still exist several issues in existing DUNs: 1) For each iteration, a simple stacked convolutional network is usually adopted, which apparently limits the expressiveness of these models. 2) Once the training is completed, most hyperparameters of existing DUNs are fixed for any input content, which significantly weakens their adaptability. In this paper, by unfolding the Fast Iterative Shrinkage-Thresholding Algorithm (FISTA), a novel fast hierarchical DUN, dubbed FHDUN, is proposed for image compressed sensing, in which a well-designed hierarchical unfolding architecture is developed to cooperatively explore richer contextual prior information in multi-scale spaces. To further enhance the adaptability, series of hyperparametric generation networks are developed in our framework to dynamically produce the corresponding optimal hyperparameters according to the input content. Furthermore, due to the accelerated policy in FISTA, the newly embedded acceleration module makes the proposed FHDUN save more than 50% of the iterative loops against recent DUNs. Extensive CS experiments manifest that the proposed FHDUN outperforms existing state-of-the-art CS methods, while maintaining fewer iterations.
Satellite image data downlink scheduling problem with family attribute: Model &Algorithm
Jul 04, 2022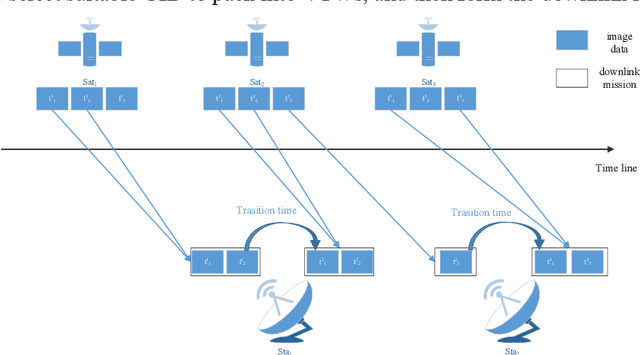

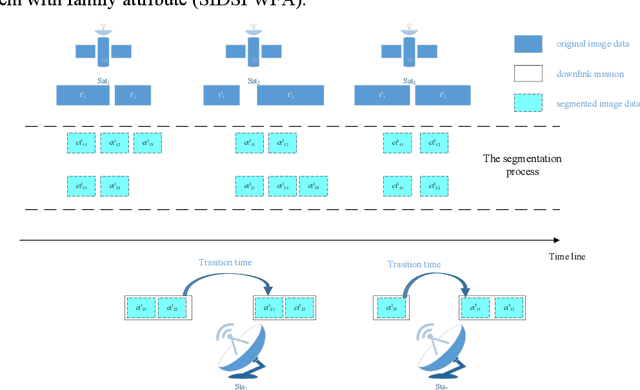
The asynchronous development between the observation capability and the transition capability results in that an original image data (OID) formed by one-time observation cannot be completely transmitted in one transmit chance between the EOS and GS (named as a visible time window, VTW). It needs to segment the OID to several segmented image data (SID) and then transmits them in several VTWs, which enriches the extension of satellite image data downlink scheduling problem (SIDSP). We define the novel SIDSP as satellite image data downlink scheduling problem with family attribute (SIDSPWFA), in which some big OID is segmented by a fast segmentation operator first, and all SID and other no-segmented OID is transmitted in the second step. Two optimization objectives, the image data transmission failure rate (FR) and the segmentation times (ST), are then designed to formalize SIDSPWFA as a bi-objective discrete optimization model. Furthermore, a bi-stage differential evolutionary algorithm(DE+NSGA-II) is developed holding several bi-stage operators. Extensive simulation instances show the efficiency of models, strategies, algorithms and operators is analyzed in detail.
Collaborative Semantic Communication at the Edge
Jan 10, 2023
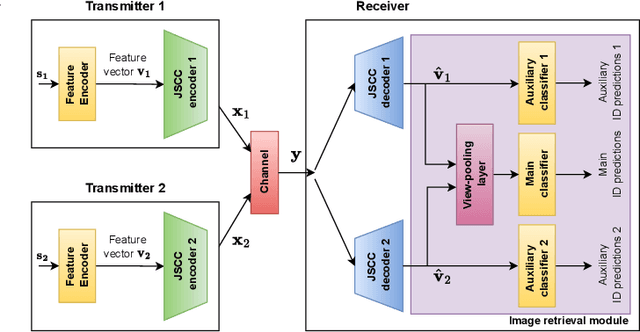
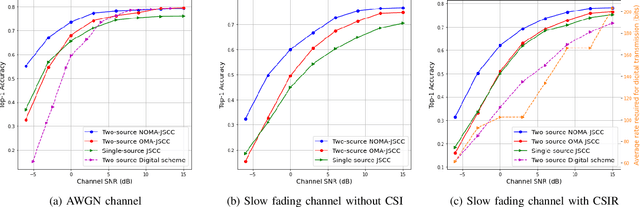
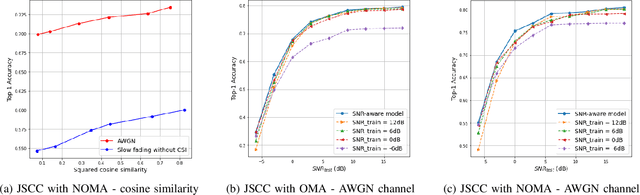
We study the collaborative image retrieval problem at the wireless edge, where multiple edge devices capture images of the same object from different angles and locations, which are then used jointly to retrieve similar images at the edge server over a shared multiple access channel (MAC). We propose two novel deep learning-based joint source and channel coding (JSCC) schemes for the task over both additive white Gaussian noise (AWGN) and Rayleigh slow fading channels, with the aim of maximizing the retrieval accuracy under a total bandwidth constraint. The proposed schemes are evaluated on a wide range of channel signal-to-noise ratios (SNRs), and shown to outperform the single-device JSCC and the separation-based multiple-access benchmarks. We also propose two novel SNR-aware JSCC schemes with attention modules to improve the performance in the case of channel mismatch between training and test instances.
An Event-based Algorithm for Simultaneous 6-DOF Camera Pose Tracking and Mapping
Jan 10, 2023
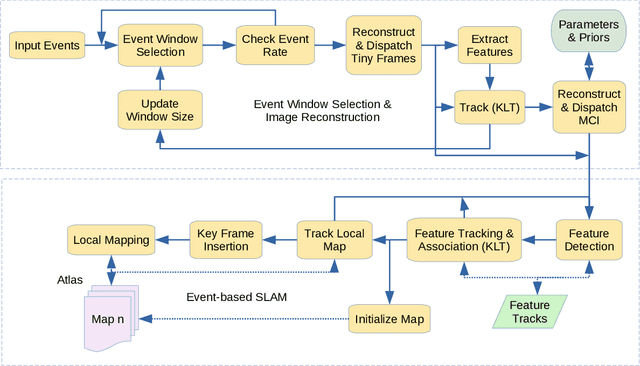
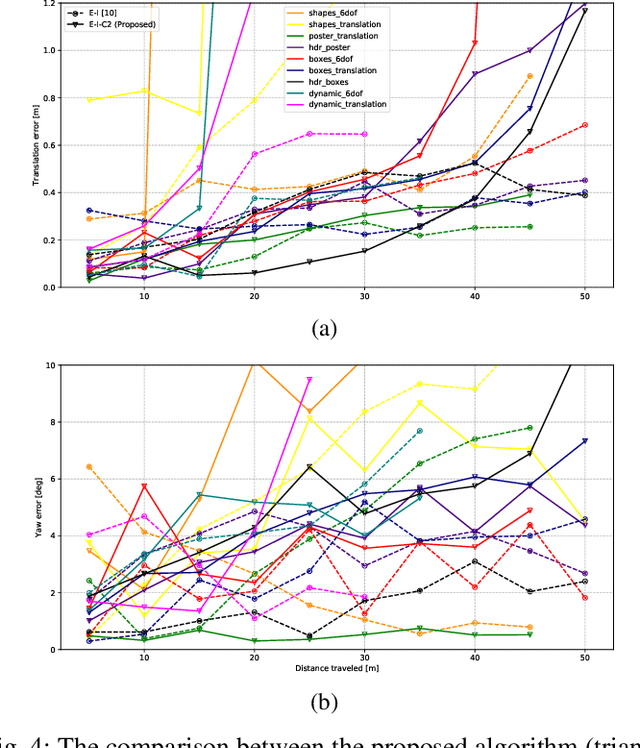
Compared to regular cameras, Dynamic Vision Sensors or Event Cameras can output compact visual data based on a change in the intensity in each pixel location asynchronously. In this paper, we study the application of current image-based SLAM techniques to these novel sensors. To this end, the information in adaptively selected event windows is processed to form motion-compensated images. These images are then used to reconstruct the scene and estimate the 6-DOF pose of the camera. We also propose an inertial version of the event-only pipeline to assess its capabilities. We compare the results of different configurations of the proposed algorithm against the ground truth for sequences of two publicly available event datasets. We also compare the results of the proposed event-inertial pipeline with the state-of-the-art and show it can produce comparable or more accurate results provided the map estimate is reliable.
ROBUSfT: Robust Real-Time Shape-from-Template, a C++ Library
Jan 10, 2023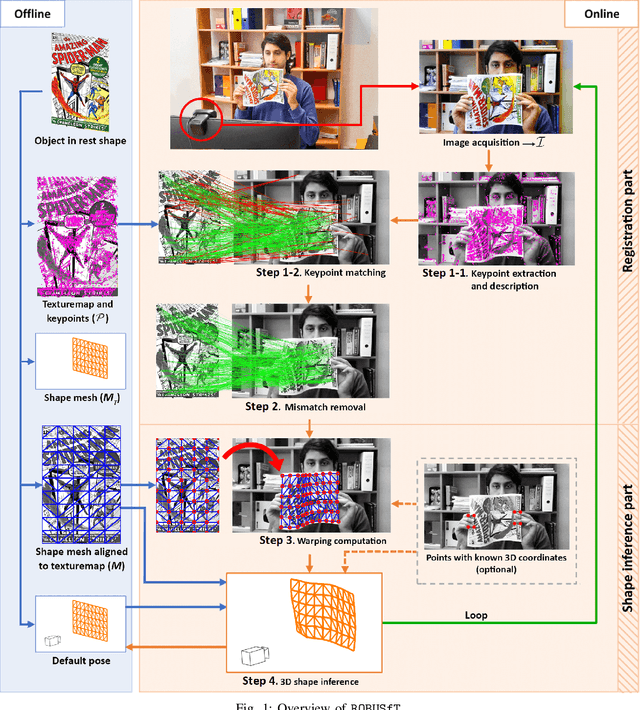
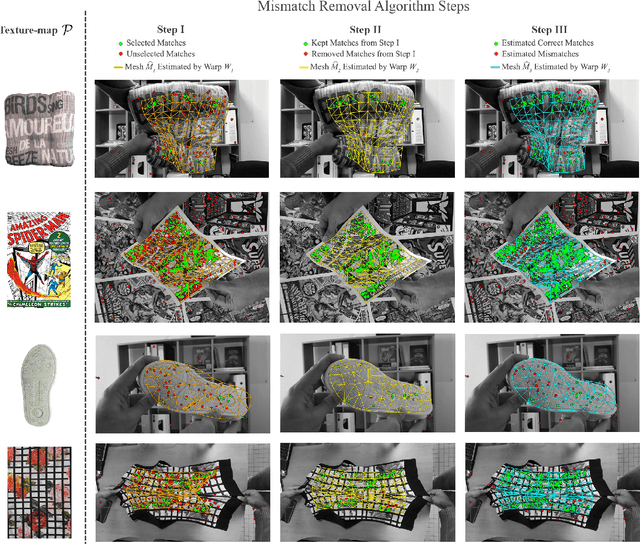
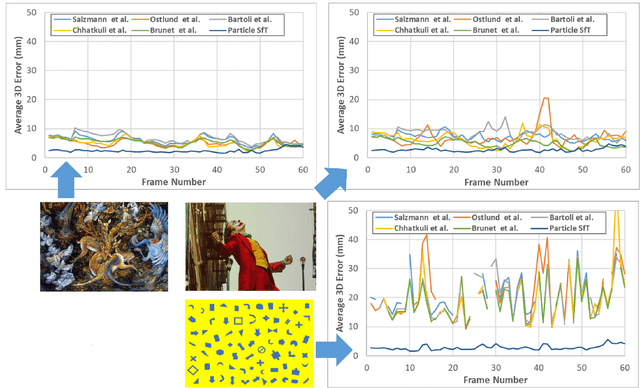
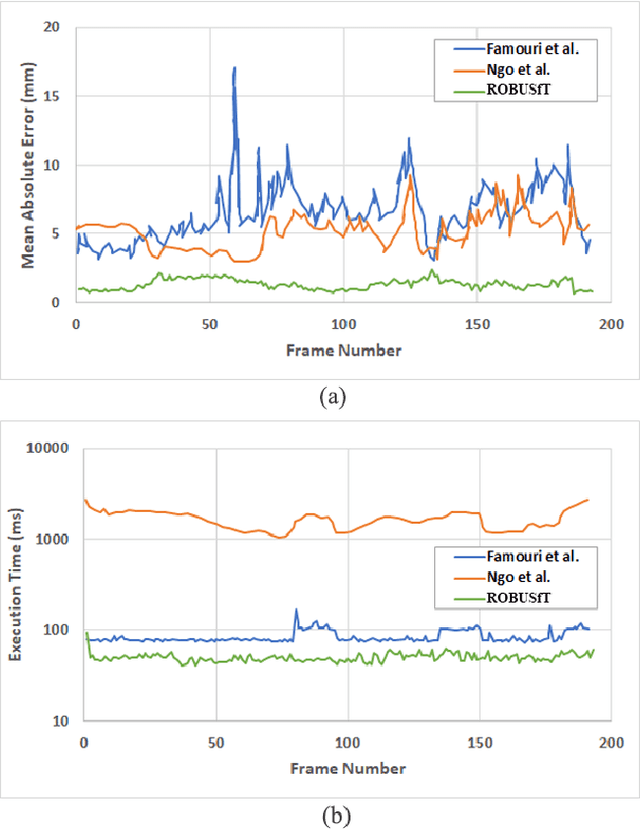
Tracking the 3D shape of a deforming object using only monocular 2D vision is a challenging problem. This is because one should (i) infer the 3D shape from a 2D image, which is a severely underconstrained problem, and (ii) implement the whole solution pipeline in real-time. The pipeline typically requires feature detection and matching, mismatch filtering, 3D shape inference and feature tracking algorithms. We propose ROBUSfT, a conventional pipeline based on a template containing the object's rest shape, texturemap and deformation law. ROBUSfT is ready-to-use, wide-baseline, capable of handling large deformations, fast up to 30 fps, free of training, and robust against partial occlusions and discontinuity in video frames. It outperforms the state-of-the-art methods in challenging datasets. ROBUSfT is implemented as a publicly available C++ library and we provide a tutorial on how to use it in https://github.com/mrshetab/ROBUSfT
Dense residual Transformer for image denoising
May 14, 2022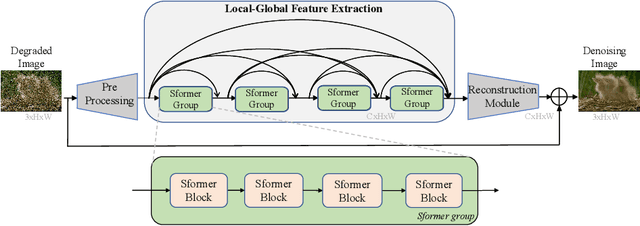
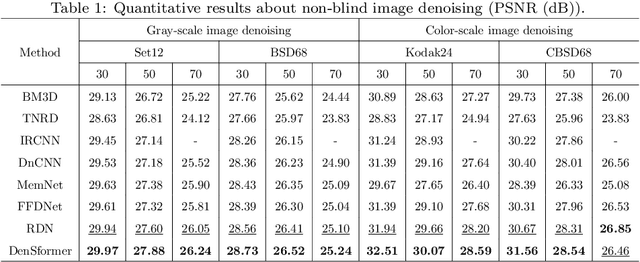
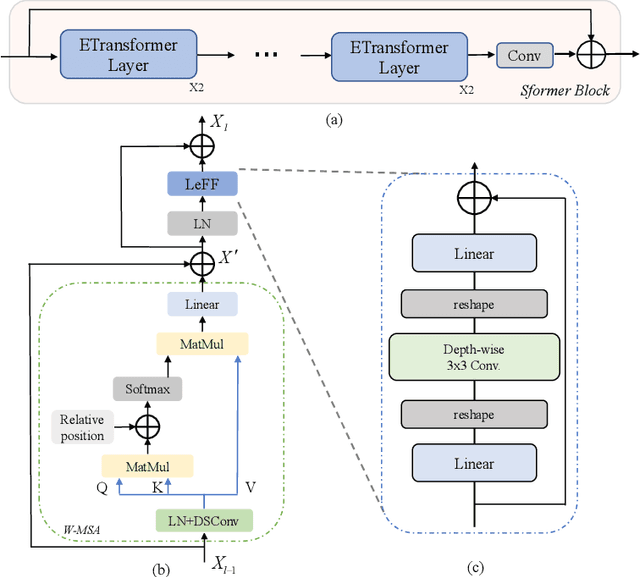
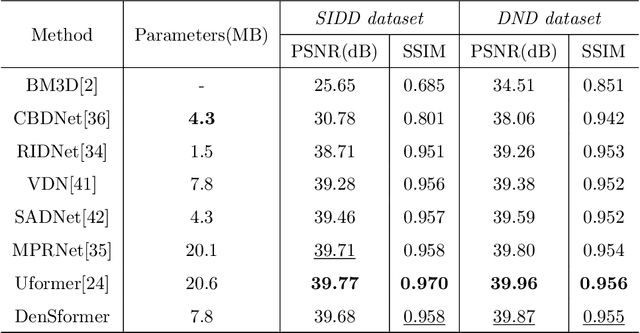
Image denoising is an important low-level computer vision task, which aims to reconstruct a noise-free and high-quality image from a noisy image. With the development of deep learning, convolutional neural network (CNN) has been gradually applied and achieved great success in image denoising, image compression, image enhancement, etc. Recently, Transformer has been a hot technique, which is widely used to tackle computer vision tasks. However, few Transformer-based methods have been proposed for low-level vision tasks. In this paper, we proposed an image denoising network structure based on Transformer, which is named DenSformer. DenSformer consists of three modules, including a preprocessing module, a local-global feature extraction module, and a reconstruction module. Specifically, the local-global feature extraction module consists of several Sformer groups, each of which has several ETransformer layers and a convolution layer, together with a residual connection. These Sformer groups are densely skip-connected to fuse the feature of different layers, and they jointly capture the local and global information from the given noisy images. We conduct our model on comprehensive experiments. Experimental results prove that our DenSformer achieves improvement compared to some state-of-the-art methods, both for the synthetic noise data and real noise data, in the objective and subjective evaluations.
Disentangling 3D Attributes from a Single 2D Image: Human Pose, Shape and Garment
Aug 05, 2022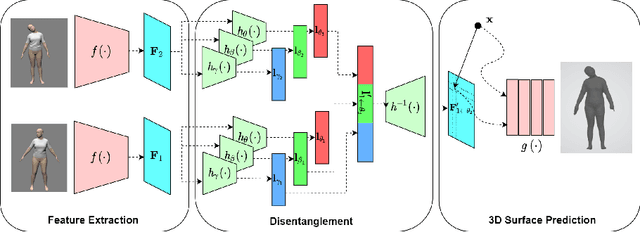

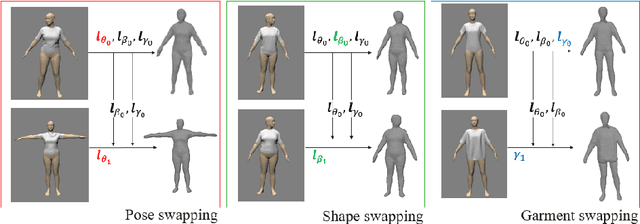
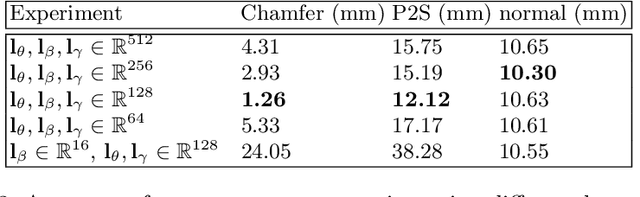
For visual manipulation tasks, we aim to represent image content with semantically meaningful features. However, learning implicit representations from images often lacks interpretability, especially when attributes are intertwined. We focus on the challenging task of extracting disentangled 3D attributes only from 2D image data. Specifically, we focus on human appearance and learn implicit pose, shape and garment representations of dressed humans from RGB images. Our method learns an embedding with disentangled latent representations of these three image properties and enables meaningful re-assembling of features and property control through a 2D-to-3D encoder-decoder structure. The 3D model is inferred solely from the feature map in the learned embedding space. To the best of our knowledge, our method is the first to achieve cross-domain disentanglement for this highly under-constrained problem. We qualitatively and quantitatively demonstrate our framework's ability to transfer pose, shape, and garments in 3D reconstruction on virtual data and show how an implicit shape loss can benefit the model's ability to recover fine-grained reconstruction details.
Unsupervised Superpixel Generation using Edge-Sparse Embedding
Nov 29, 2022
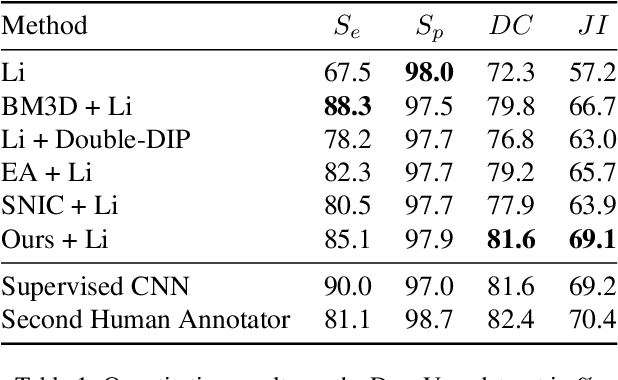
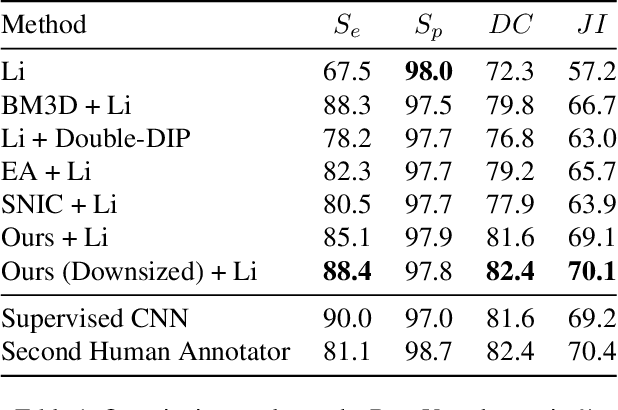
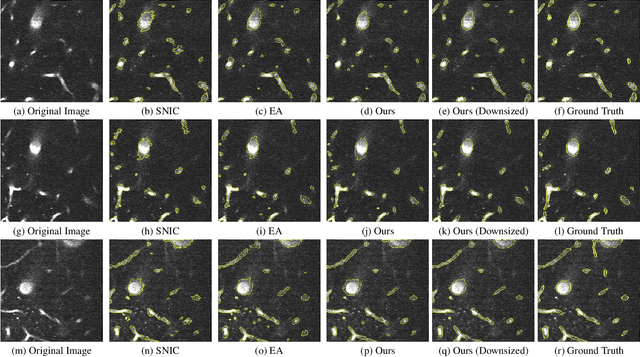
Partitioning an image into superpixels based on the similarity of pixels with respect to features such as colour or spatial location can significantly reduce data complexity and improve subsequent image processing tasks. Initial algorithms for unsupervised superpixel generation solely relied on local cues without prioritizing significant edges over arbitrary ones. On the other hand, more recent methods based on unsupervised deep learning either fail to properly address the trade-off between superpixel edge adherence and compactness or lack control over the generated number of superpixels. By using random images with strong spatial correlation as input, \ie, blurred noise images, in a non-convolutional image decoder we can reduce the expected number of contrasts and enforce smooth, connected edges in the reconstructed image. We generate edge-sparse pixel embeddings by encoding additional spatial information into the piece-wise smooth activation maps from the decoder's last hidden layer and use a standard clustering algorithm to extract high quality superpixels. Our proposed method reaches state-of-the-art performance on the BSDS500, PASCAL-Context and a microscopy dataset.
Taming a Generative Model
Nov 29, 2022
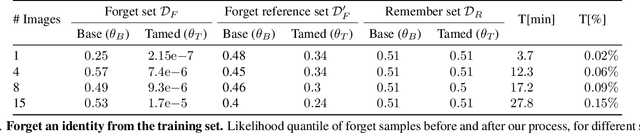
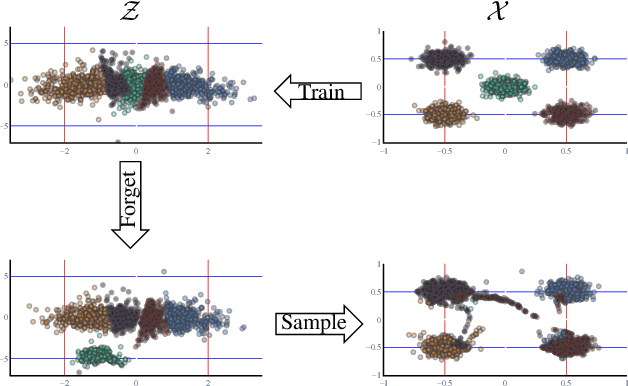
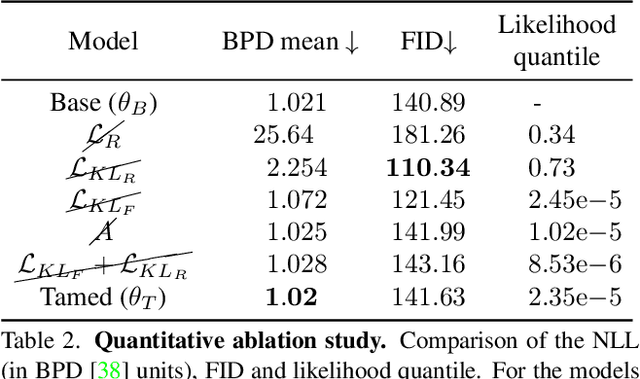
Generative models are becoming ever more powerful, being able to synthesize highly realistic images. We propose an algorithm for taming these models - changing the probability that the model will produce a specific image or image category. We consider generative models that are powered by normalizing flows, which allows us to reason about the exact generation probability likelihood for a given image. Our method is general purpose, and we exemplify it using models that generate human faces, a subdomain with many interesting privacy and bias considerations. Our method can be used in the context of privacy, e.g., removing a specific person from the output of a model, and also in the context of de-biasing by forcing a model to output specific image categories according to a given target distribution. Our method uses a fast fine-tuning process without retraining the model from scratch, achieving the goal in less than 1% of the time taken to initially train the generative model. We evaluate qualitatively and quantitatively, to examine the success of the taming process and output quality.
EndoBoost: a plug-and-play module for false positive suppression during computer-aided polyp detection in real-world colonoscopy (with dataset)
Dec 23, 2022
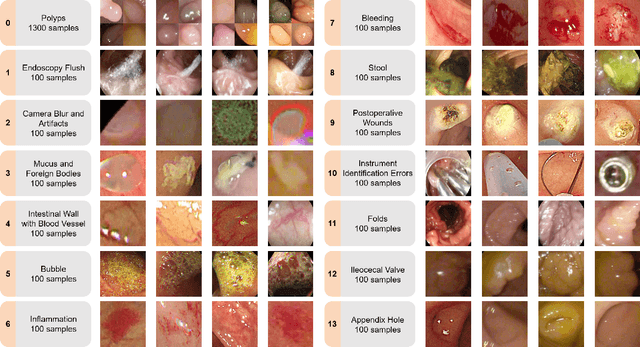
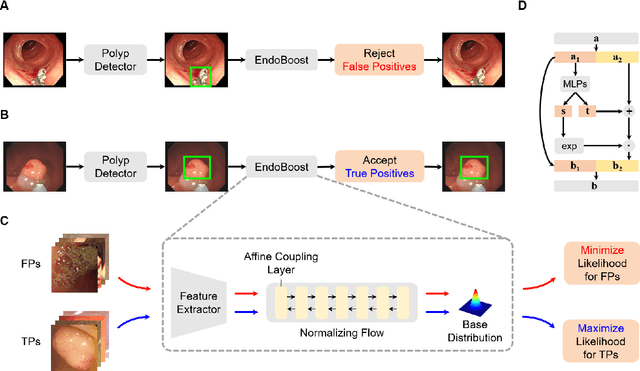
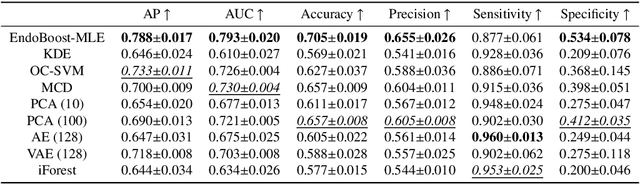
The advance of computer-aided detection systems using deep learning opened a new scope in endoscopic image analysis. However, the learning-based models developed on closed datasets are susceptible to unknown anomalies in complex clinical environments. In particular, the high false positive rate of polyp detection remains a major challenge in clinical practice. In this work, we release the FPPD-13 dataset, which provides a taxonomy and real-world cases of typical false positives during computer-aided polyp detection in real-world colonoscopy. We further propose a post-hoc module EndoBoost, which can be plugged into generic polyp detection models to filter out false positive predictions. This is realized by generative learning of the polyp manifold with normalizing flows and rejecting false positives through density estimation. Compared to supervised classification, this anomaly detection paradigm achieves better data efficiency and robustness in open-world settings. Extensive experiments demonstrate a promising false positive suppression in both retrospective and prospective validation. In addition, the released dataset can be used to perform 'stress' tests on established detection systems and encourages further research toward robust and reliable computer-aided endoscopic image analysis. The dataset and code will be publicly available at http://endoboost.miccai.cloud.