 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DRKF: Distilled Rotated Kernel Fusion for Efficiently Boosting Rotation Invariance in Image Matching
Sep 22, 2022

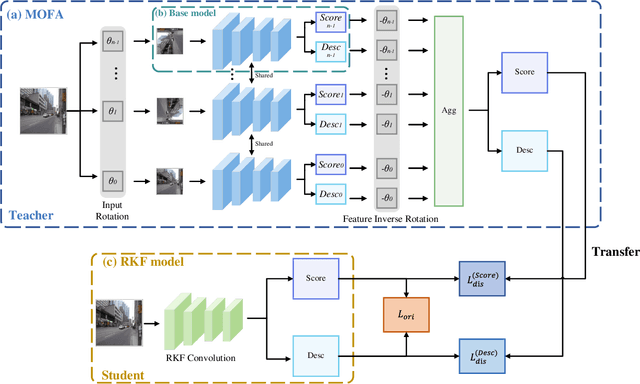
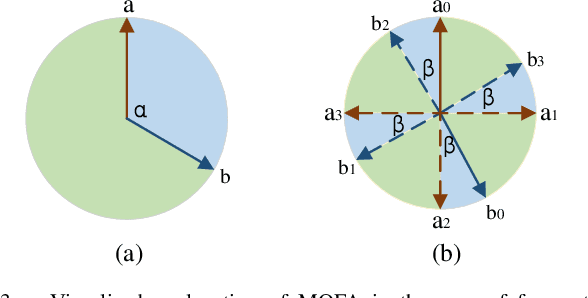
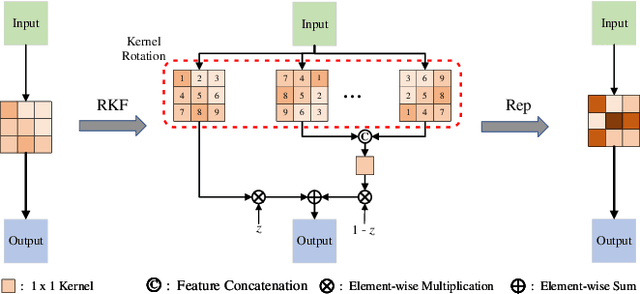
Most existing learning-based image matching pipelines are designed for better feature detectors and descriptors which are robust to repeated textures, viewpoint changes, etc., while little attention has been paid to rotation invariance. As a consequence, these approaches usually demonstrate inferior performance compared to the handcrafted algorithms in circumstances where a significant level of rotation exists in data, due to the lack of keypoint orientation prediction. To address the issue efficiently, an approach based on knowledge distillation is proposed for improving rotation robustness without extra computational costs. Specifically, based on the base model, we propose Multi-Oriented Feature Aggregation (MOFA), which is subsequently adopted as the teacher in the distillation pipeline. Moreover, Rotated Kernel Fusion (RKF) is applied to each convolution kernel of the student model to facilitate learning rotation-invariant features. Eventually, experiments show that our proposals can generalize successfully under various rotations without additional costs in the inference stage.
Coarse-to-fine Task-driven Inpainting for Geoscience Images
Nov 30, 2022

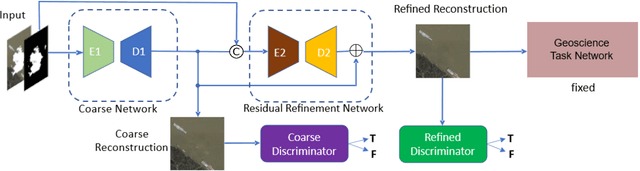
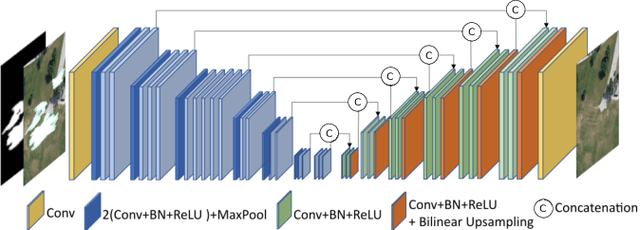
The processing and recognition of geoscience images have wide applications. Most of existing researches focus on understanding the high-quality geoscience images by assuming that all the images are clear. However, in many real-world cases, the geoscience images might contain occlusions during the image acquisition. This problem actually implies the image inpainting problem in computer vision and multimedia. To the best of our knowledge, all the existing image inpainting algorithms learn to repair the occluded regions for a better visualization quality, they are excellent for natural images but not good enough for geoscience images by ignoring the geoscience related tasks. This paper aims to repair the occluded regions for a better geoscience task performance with the advanced visualization quality simultaneously, without changing the current deployed deep learning based geoscience models. Because of the complex context of geoscience images, we propose a coarse-to-fine encoder-decoder network with coarse-to-fine adversarial context discriminators to reconstruct the occluded image regions. Due to the limited data of geoscience images, we use a MaskMix based data augmentation method to exploit more information from limited geoscience image data. The experimental results on three public geoscience datasets for remote sensing scene recognition, cross-view geolocation and semantic segmentation tasks respectively show the effectiveness and accuracy of the proposed method.
RE-Tagger: A light-weight Real-Estate Image Classifier
Jul 12, 2022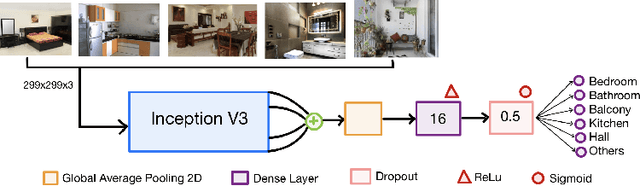

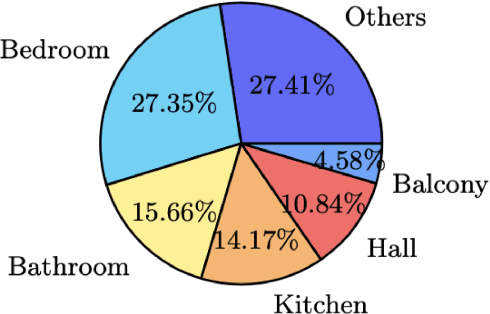

Real-estate image tagging is one of the essential use-cases to save efforts involved in manual annotation and enhance the user experience. This paper proposes an end-to-end pipeline (referred to as RE-Tagger) for the real-estate image classification problem. We present a two-stage transfer learning approach using custom InceptionV3 architecture to classify images into different categories (i.e., bedroom, bathroom, kitchen, balcony, hall, and others). Finally, we released the application as REST API hosted as a web application running on 2 cores machine with 2 GB RAM. The demo video is available here.
BAD-NeRF: Bundle Adjusted Deblur Neural Radiance Fields
Nov 23, 2022
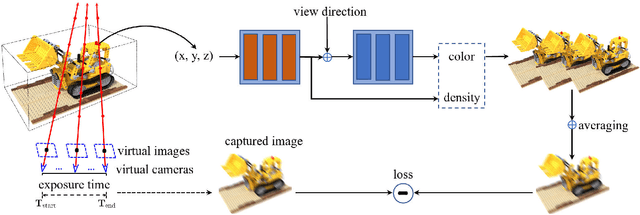
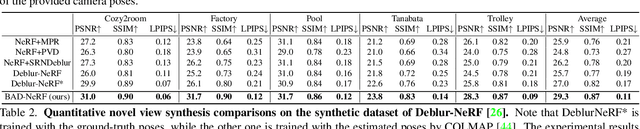
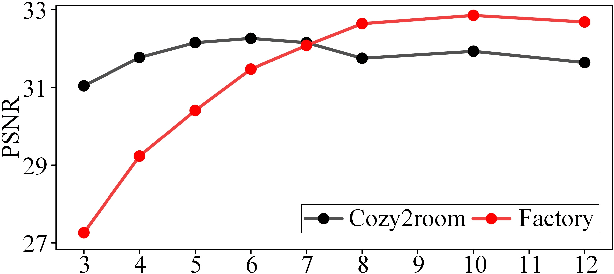
Neural Radiance Fields (NeRF) have received considerable attention recently, due to its impressive capability in photo-realistic 3D reconstruction and novel view synthesis, given a set of posed camera images. Earlier work usually assumes the input images are in good quality. However, image degradation (e.g. image motion blur in low-light conditions) can easily happen in real-world scenarios, which would further affect the rendering quality of NeRF. In this paper, we present a novel bundle adjusted deblur Neural Radiance Fields (BAD-NeRF), which can be robust to severe motion blurred images and inaccurate camera poses. Our approach models the physical image formation process of a motion blurred image, and jointly learns the parameters of NeRF and recovers the camera motion trajectories during exposure time. In experiments, we show that by directly modeling the real physical image formation process, BAD-NeRF achieves superior performance over prior works on both synthetic and real datasets.
Dense residual Transformer for image denoising
May 14, 2022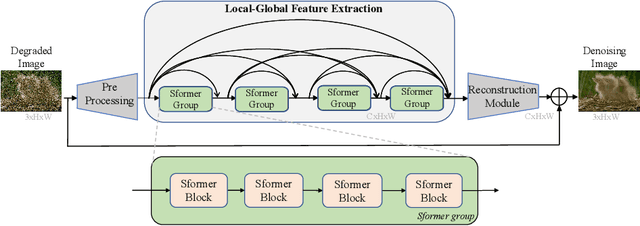
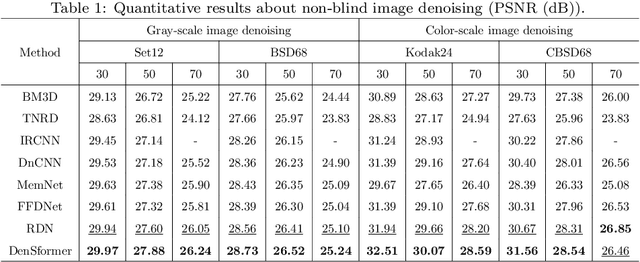
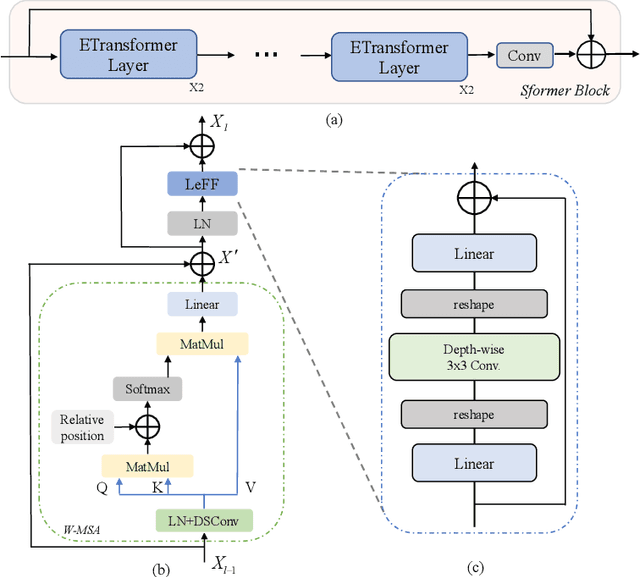
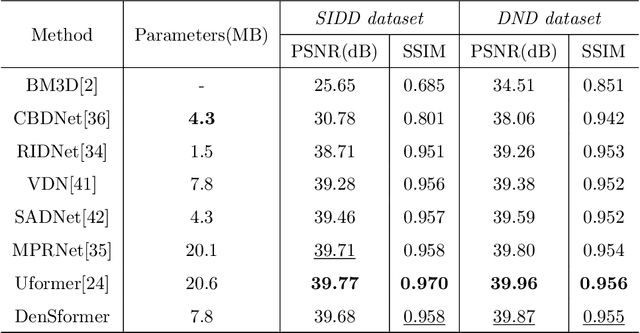
Image denoising is an important low-level computer vision task, which aims to reconstruct a noise-free and high-quality image from a noisy image. With the development of deep learning, convolutional neural network (CNN) has been gradually applied and achieved great success in image denoising, image compression, image enhancement, etc. Recently, Transformer has been a hot technique, which is widely used to tackle computer vision tasks. However, few Transformer-based methods have been proposed for low-level vision tasks. In this paper, we proposed an image denoising network structure based on Transformer, which is named DenSformer. DenSformer consists of three modules, including a preprocessing module, a local-global feature extraction module, and a reconstruction module. Specifically, the local-global feature extraction module consists of several Sformer groups, each of which has several ETransformer layers and a convolution layer, together with a residual connection. These Sformer groups are densely skip-connected to fuse the feature of different layers, and they jointly capture the local and global information from the given noisy images. We conduct our model on comprehensive experiments. Experimental results prove that our DenSformer achieves improvement compared to some state-of-the-art methods, both for the synthetic noise data and real noise data, in the objective and subjective evaluations.
Unsupervised Joint Image Transfer and Uncertainty Quantification using Patch Invariant Networks
Jul 09, 2022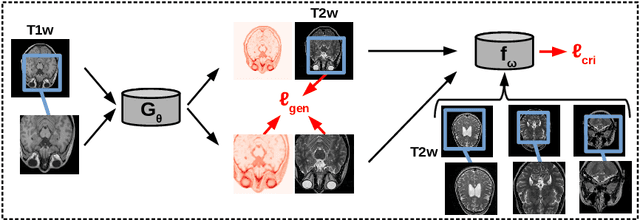
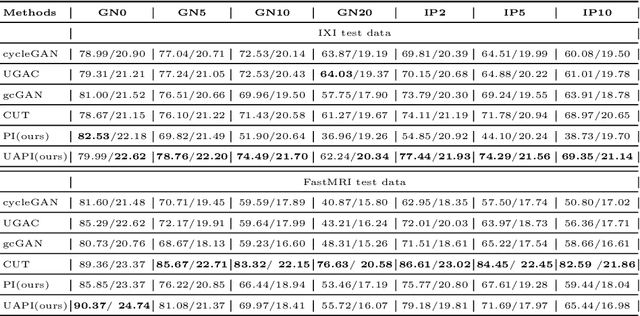
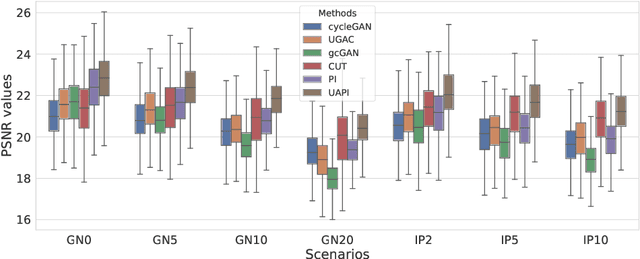
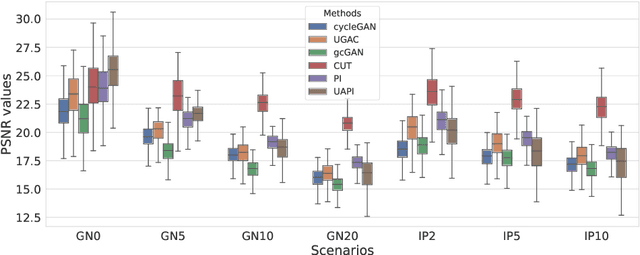
Unsupervised image transfer enables intra- and inter-modality transfer for medical applications where a large amount of paired training data is not abundant. To ensure a structure-preserving mapping from the input to the target domain, existing methods for unpaired medical image transfer are commonly based on cycle-consistency, causing additional computation resources and instability due to the learning of an inverse mapping. This paper presents a novel method for uni-directional domain mapping where no paired data is needed throughout the entire training process. A reasonable transfer is ensured by employing the GAN architecture and a novel generator loss based on patch invariance. To be more precise, generator outputs are evaluated and compared on different scales, which brings increased attention to high-frequency details as well as implicit data augmentation. This novel term also gives the opportunity to predict aleatoric uncertainty by modeling an input-dependent scale map for the patch residuals. The proposed method is comprehensively evaluated on three renowned medical databases. Superior accuracy on these datasets compared to four different state-of-the-art methods for unpaired image transfer suggests the great potential of this approach for uncertainty-aware medical image translation. Implementation of the proposed framework is released here: https://github.com/anger-man/unsupervised-image-transfer-and-uq.
GPTR: Gestalt-Perception Transformer for Diagram Object Detection
Dec 29, 2022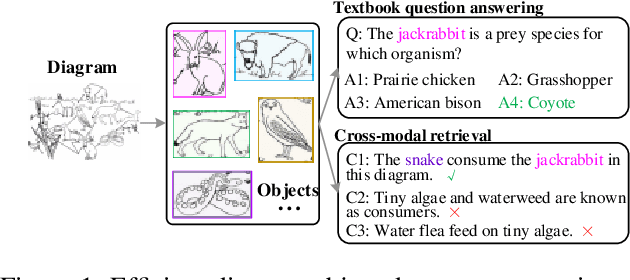
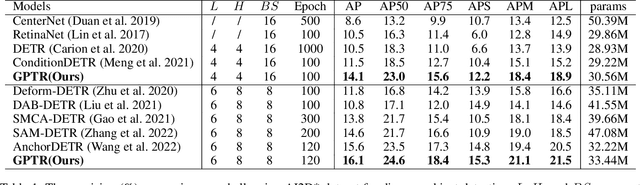
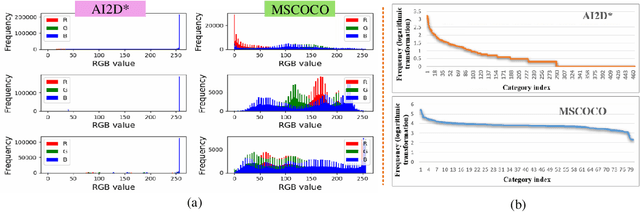
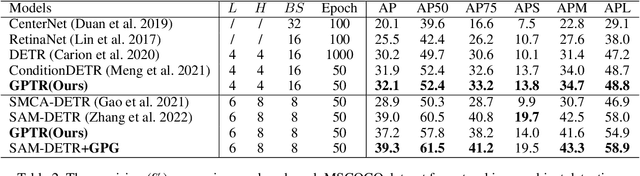
Diagram object detection is the key basis of practical applications such as textbook question answering. Because the diagram mainly consists of simple lines and color blocks, its visual features are sparser than those of natural images. In addition, diagrams usually express diverse knowledge, in which there are many low-frequency object categories in diagrams. These lead to the fact that traditional data-driven detection model is not suitable for diagrams. In this work, we propose a gestalt-perception transformer model for diagram object detection, which is based on an encoder-decoder architecture. Gestalt perception contains a series of laws to explain human perception, that the human visual system tends to perceive patches in an image that are similar, close or connected without abrupt directional changes as a perceptual whole object. Inspired by these thoughts, we build a gestalt-perception graph in transformer encoder, which is composed of diagram patches as nodes and the relationships between patches as edges. This graph aims to group these patches into objects via laws of similarity, proximity, and smoothness implied in these edges, so that the meaningful objects can be effectively detected. The experimental results demonstrate that the proposed GPTR achieves the best results in the diagram object detection task. Our model also obtains comparable results over the competitors in natural image object detection.
Layout-guided Indoor Panorama Inpainting with Plane-aware Normalization
Jan 13, 2023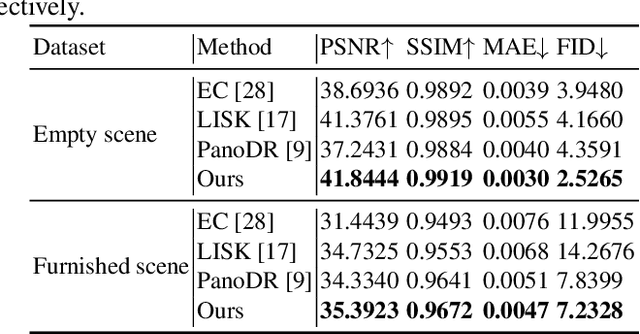

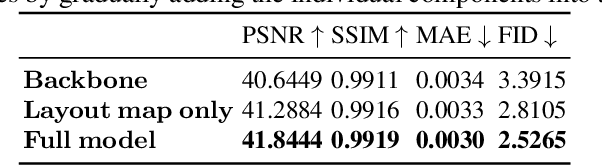
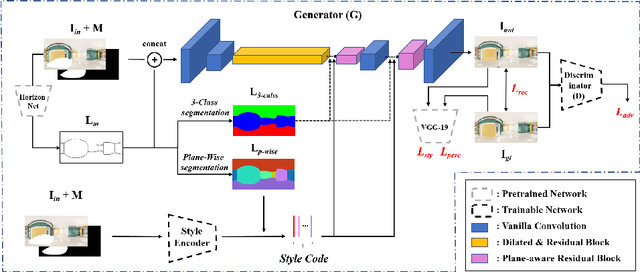
We present an end-to-end deep learning framework for indoor panoramic image inpainting. Although previous inpainting methods have shown impressive performance on natural perspective images, most fail to handle panoramic images, particularly indoor scenes, which usually contain complex structure and texture content. To achieve better inpainting quality, we propose to exploit both the global and local context of indoor panorama during the inpainting process. Specifically, we take the low-level layout edges estimated from the input panorama as a prior to guide the inpainting model for recovering the global indoor structure. A plane-aware normalization module is employed to embed plane-wise style features derived from the layout into the generator, encouraging local texture restoration from adjacent room structures (i.e., ceiling, floor, and walls). Experimental results show that our work outperforms the current state-of-the-art methods on a public panoramic dataset in both qualitative and quantitative evaluations. Our code is available at https://ericsujw.github.io/LGPN-net/
Multi-scale frequency separation network for image deblurring
Jun 01, 2022

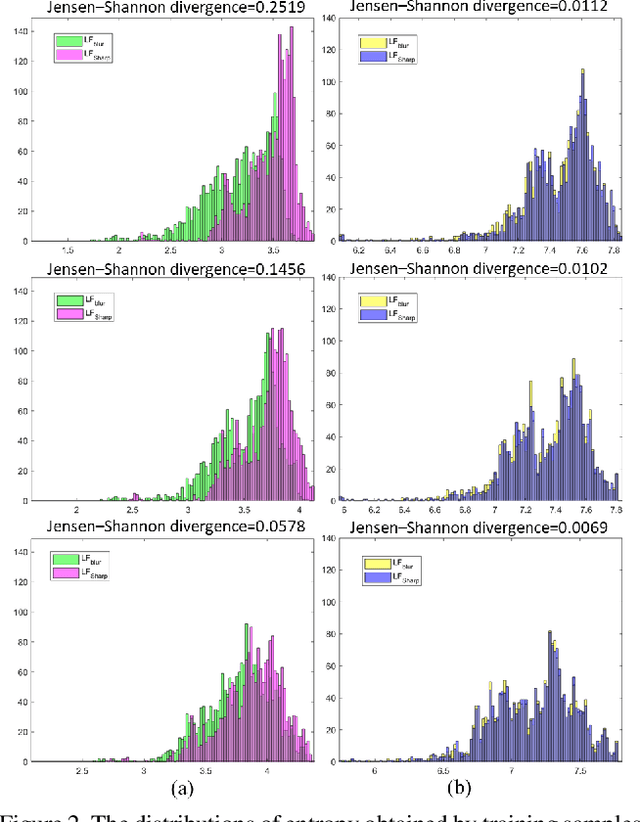
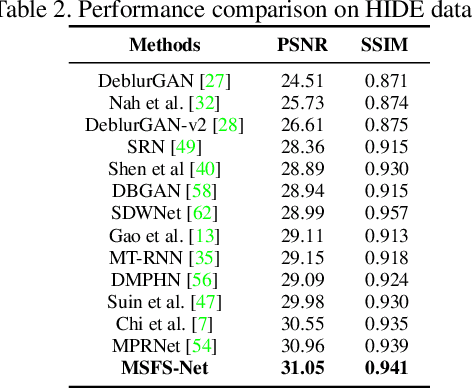
Image deblurring aims to restore the detailed texture information or structures from the blurry images, which has become an indispensable step in many computer-vision tasks. Although various methods have been proposed to deal with the image deblurring problem, most of them treated the blurry image as a whole and neglected the characteristics of different image frequencies. In this paper, we present a new method called multi-scale frequency separation network (MSFS-Net) for image deblurring. MSFS-Net introduces the frequency separation module (FSM) into an encoder-decoder network architecture to capture the low and high-frequency information of image at multiple scales. Then, a simple cycle-consistency strategy and a sophisticated contrastive learning module (CLM) are respectively designed to retain the low-frequency information and recover the high-frequency information during deblurring. At last, the features of different scales are fused by a cross-scale feature fusion module (CSFFM). Extensive experiments on benchmark datasets show that the proposed network achieves state-of-the-art performance.
Satellite image data downlink scheduling problem with family attribute: Model &Algorithm
Jul 04, 2022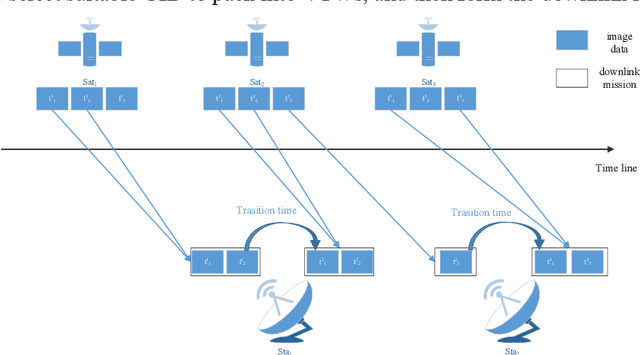

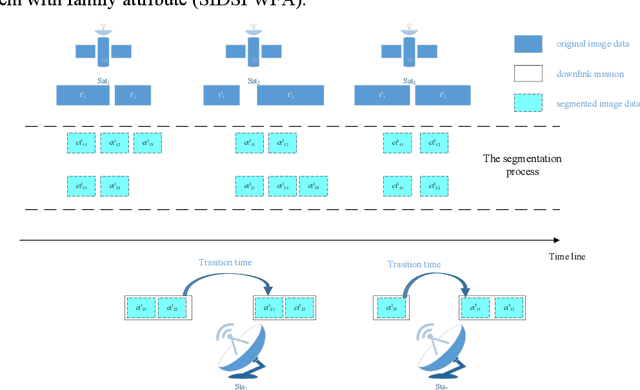
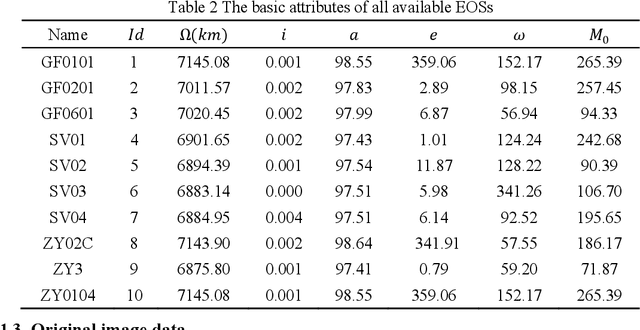
The asynchronous development between the observation capability and the transition capability results in that an original image data (OID) formed by one-time observation cannot be completely transmitted in one transmit chance between the EOS and GS (named as a visible time window, VTW). It needs to segment the OID to several segmented image data (SID) and then transmits them in several VTWs, which enriches the extension of satellite image data downlink scheduling problem (SIDSP). We define the novel SIDSP as satellite image data downlink scheduling problem with family attribute (SIDSPWFA), in which some big OID is segmented by a fast segmentation operator first, and all SID and other no-segmented OID is transmitted in the second step. Two optimization objectives, the image data transmission failure rate (FR) and the segmentation times (ST), are then designed to formalize SIDSPWFA as a bi-objective discrete optimization model. Furthermore, a bi-stage differential evolutionary algorithm(DE+NSGA-II) is developed holding several bi-stage operators. Extensive simulation instances show the efficiency of models, strategies, algorithms and operators is analyzed in detail.