 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SImProv: Scalable Image Provenance Framework for Robust Content Attribution
Jun 28, 2022


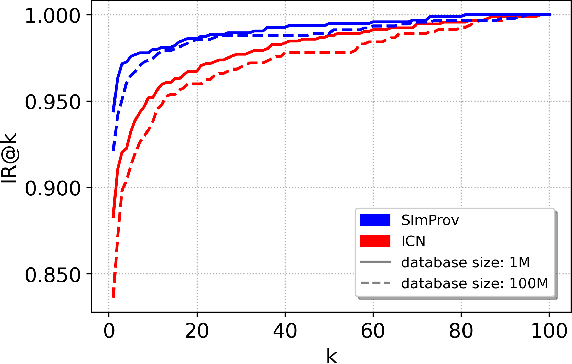

We present SImProv - a scalable image provenance framework to match a query image back to a trusted database of originals and identify possible manipulations on the query. SImProv consists of three stages: a scalable search stage for retrieving top-k most similar images; a re-ranking and near-duplicated detection stage for identifying the original among the candidates; and finally a manipulation detection and visualization stage for localizing regions within the query that may have been manipulated to differ from the original. SImProv is robust to benign image transformations that commonly occur during online redistribution, such as artifacts due to noise and recompression degradation, as well as out-of-place transformations due to image padding, warping, and changes in size and shape. Robustness towards out-of-place transformations is achieved via the end-to-end training of a differentiable warping module within the comparator architecture. We demonstrate effective retrieval and manipulation detection over a dataset of 100 million images.
Deep Diversity-Enhanced Feature Representation of Hyperspectral Images
Jan 15, 2023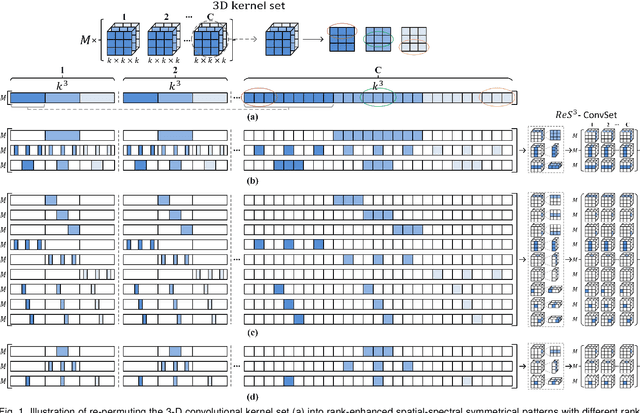
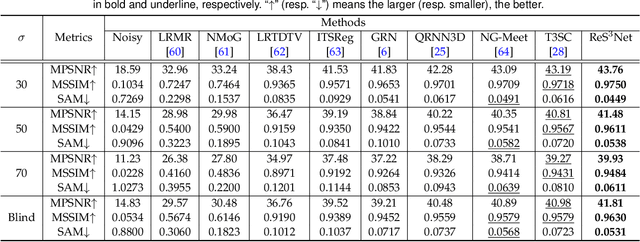
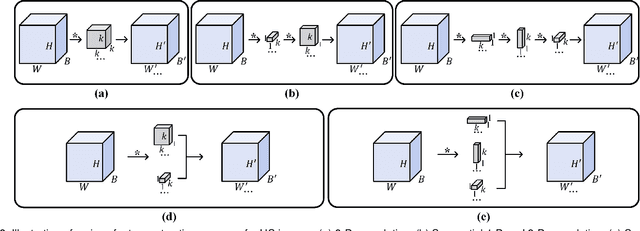
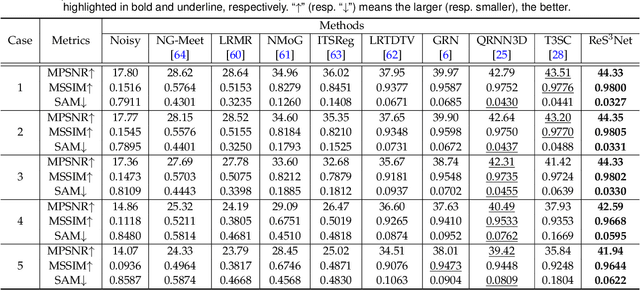
In this paper, we study the problem of embedding the high-dimensional spatio-spectral information of hyperspectral (HS) images efficiently and effectively, oriented by feature diversity. To be specific, based on the theoretical formulation that feature diversity is correlated with the rank of the unfolded kernel matrix, we rectify 3D convolution by modifying its topology to boost the rank upper-bound, yielding a rank-enhanced spatial-spectral symmetrical convolution set (ReS$^3$-ConvSet), which is able to not only learn diverse and powerful feature representations but also save network parameters. In addition, we also propose a novel diversity-aware regularization (DA-Reg) term, which acts directly on the feature maps to maximize the independence among elements. To demonstrate the superiority of the proposed ReS$^3$-ConvSet and DA-Reg, we apply them to various HS image processing and analysis tasks, including denoising, spatial super-resolution, and classification. Extensive experiments demonstrate that the proposed approaches outperform state-of-the-art methods to a significant extent both quantitatively and qualitatively. The code is publicly available at \url{https://github.com/jinnh/ReSSS-ConvSet}.
Supervised Attribute Information Removal and Reconstruction for Image Manipulation
Jul 13, 2022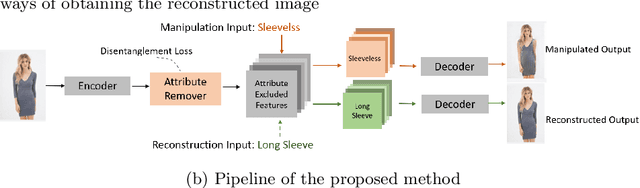
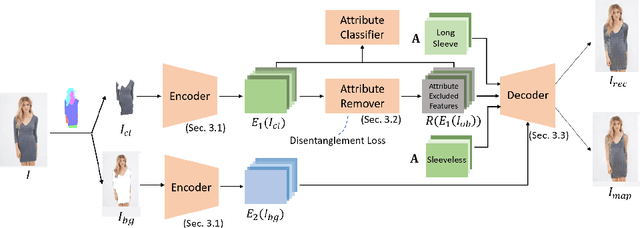
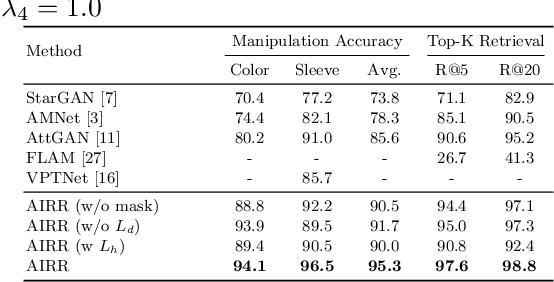
The goal of attribute manipulation is to control specified attribute(s) in given images. Prior work approaches this problem by learning disentangled representations for each attribute that enables it to manipulate the encoded source attributes to the target attributes. However, encoded attributes are often correlated with relevant image content. Thus, the source attribute information can often be hidden in the disentangled features, leading to unwanted image editing effects. In this paper, we propose an Attribute Information Removal and Reconstruction (AIRR) network that prevents such information hiding by learning how to remove the attribute information entirely, creating attribute excluded features, and then learns to directly inject the desired attributes in a reconstructed image. We evaluate our approach on four diverse datasets with a variety of attributes including DeepFashion Synthesis, DeepFashion Fine-grained Attribute, CelebA and CelebA-HQ, where our model improves attribute manipulation accuracy and top-k retrieval rate by 10% on average over prior work. A user study also reports that AIRR manipulated images are preferred over prior work in up to 76% of cases.
Coarse-to-fine Task-driven Inpainting for Geoscience Images
Nov 30, 2022

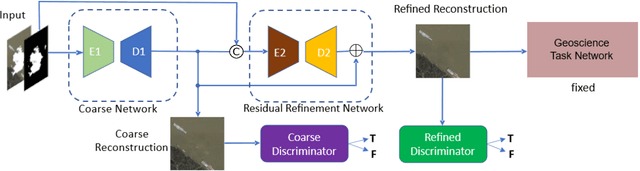
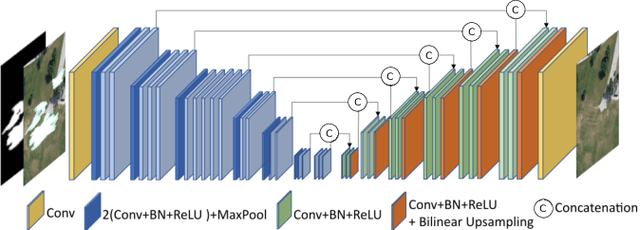
The processing and recognition of geoscience images have wide applications. Most of existing researches focus on understanding the high-quality geoscience images by assuming that all the images are clear. However, in many real-world cases, the geoscience images might contain occlusions during the image acquisition. This problem actually implies the image inpainting problem in computer vision and multimedia. To the best of our knowledge, all the existing image inpainting algorithms learn to repair the occluded regions for a better visualization quality, they are excellent for natural images but not good enough for geoscience images by ignoring the geoscience related tasks. This paper aims to repair the occluded regions for a better geoscience task performance with the advanced visualization quality simultaneously, without changing the current deployed deep learning based geoscience models. Because of the complex context of geoscience images, we propose a coarse-to-fine encoder-decoder network with coarse-to-fine adversarial context discriminators to reconstruct the occluded image regions. Due to the limited data of geoscience images, we use a MaskMix based data augmentation method to exploit more information from limited geoscience image data. The experimental results on three public geoscience datasets for remote sensing scene recognition, cross-view geolocation and semantic segmentation tasks respectively show the effectiveness and accuracy of the proposed method.
Unsupervised Linear and Iterative Combinations of Patches for Image Denoising
Dec 01, 2022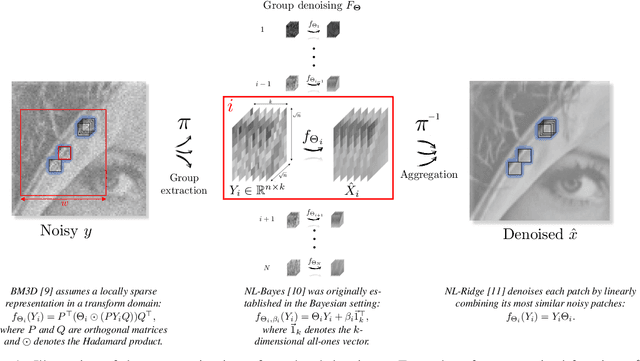
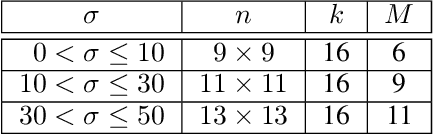
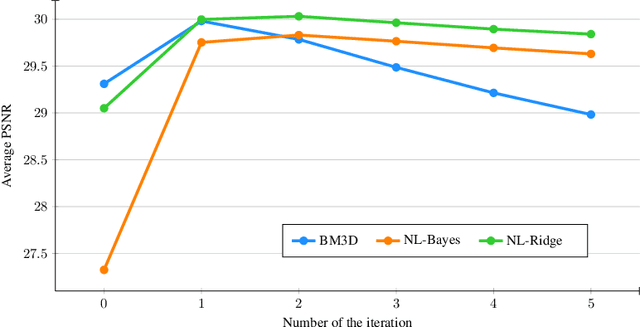
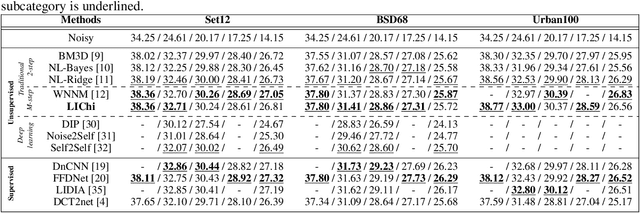
We introduce a parametric view of non-local two-step denoisers, for which BM3D is a major representative, where quadratic risk minimization is leveraged for unsupervised optimization. Within this paradigm, we propose to extend the underlying mathematical parametric formulation by iteration. This generalization can be expected to further improve the denoising performance, somehow curbed by the impracticality of repeating the second stage for all two-step denoisers. The resulting formulation involves estimating an even larger amount of parameters in a unsupervised manner which is all the more challenging. Focusing on the parameterized form of NL-Ridge, the simplest but also most efficient non-local two-step denoiser, we propose a progressive scheme to approximate the parameters minimizing the risk. In the end, the denoised images are made up of iterative linear combinations of patches. Experiments on artificially noisy images but also on real-world noisy images demonstrate that our method compares favorably with the very best unsupervised denoisers such as WNNM, outperforming the recent deep-learning-based approaches, while being much faster.
Two new parameters for the ordinal analysis of images
Dec 30, 2022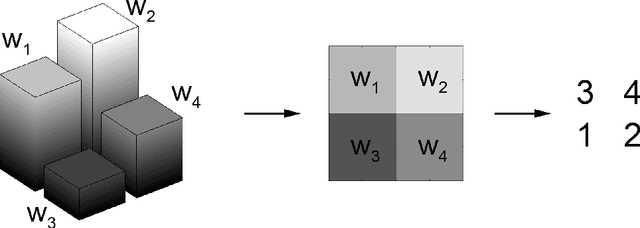
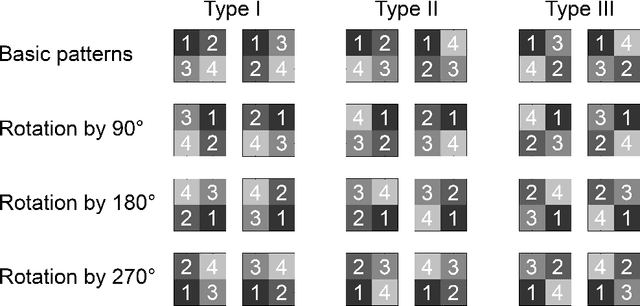
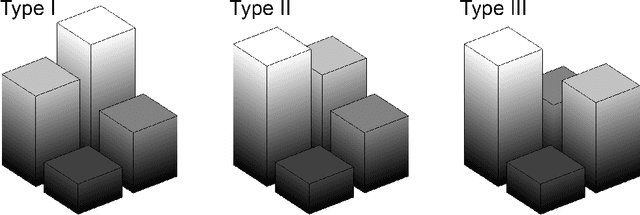
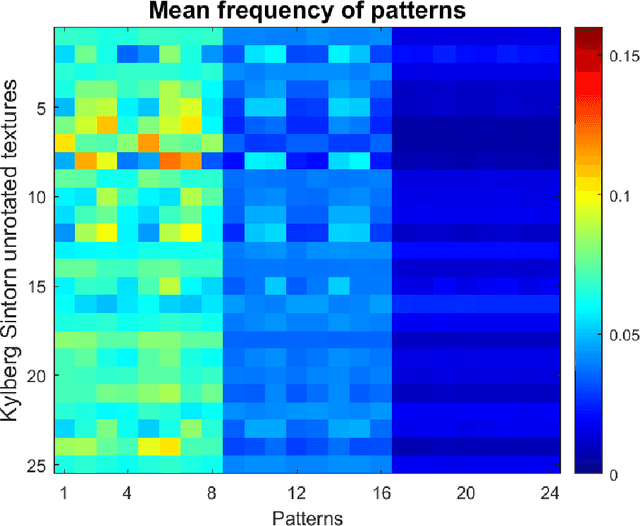
Local patterns play an important role in statistical physics as well as in image processing. Two-dimensional ordinal patterns were studied by Ribeiro et al. who determined permutation entropy and complexity in order to classify paintings and images of liquid crystals. Here we find that the 2 by 2 patterns of neighboring pixels come in three types. The statistics of these types, expressed by two parameters, contains the relevant information to describe and distinguish textures. The parameters are most stable and informative for isotropic structures.
A novel adversarial learning strategy for medical image classification
Jun 23, 2022
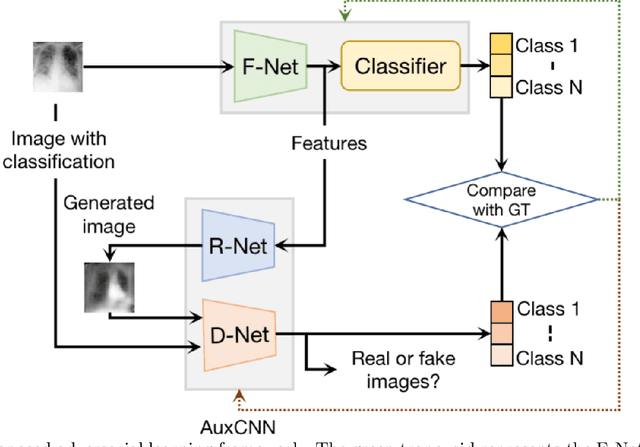
Deep learning (DL) techniques have been extensively utilized for medical image classification. Most DL-based classification networks are generally structured hierarchically and optimized through the minimization of a single loss function measured at the end of the networks. However, such a single loss design could potentially lead to optimization of one specific value of interest but fail to leverage informative features from intermediate layers that might benefit classification performance and reduce the risk of overfitting. Recently, auxiliary convolutional neural networks (AuxCNNs) have been employed on top of traditional classification networks to facilitate the training of intermediate layers to improve classification performance and robustness. In this study, we proposed an adversarial learning-based AuxCNN to support the training of deep neural networks for medical image classification. Two main innovations were adopted in our AuxCNN classification framework. First, the proposed AuxCNN architecture includes an image generator and an image discriminator for extracting more informative image features for medical image classification, motivated by the concept of generative adversarial network (GAN) and its impressive ability in approximating target data distribution. Second, a hybrid loss function is designed to guide the model training by incorporating different objectives of the classification network and AuxCNN to reduce overfitting. Comprehensive experimental studies demonstrated the superior classification performance of the proposed model. The effect of the network-related factors on classification performance was investigated.
Tracking the industrial growth of modern China with high-resolution panchromatic imagery: A sequential convolutional approach
Jan 23, 2023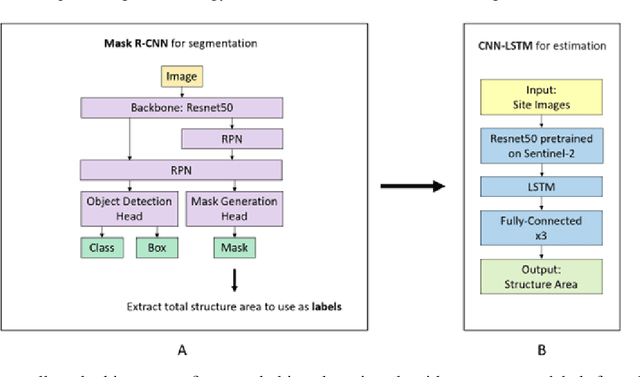
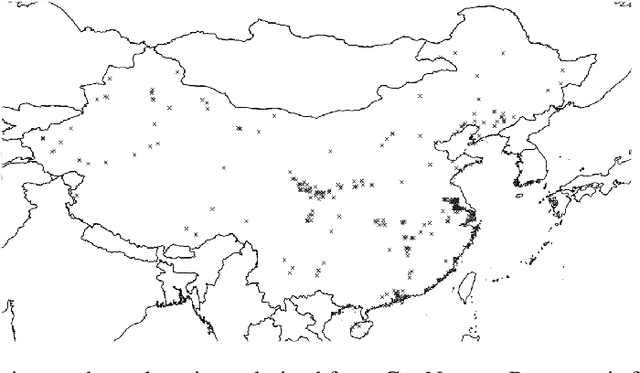

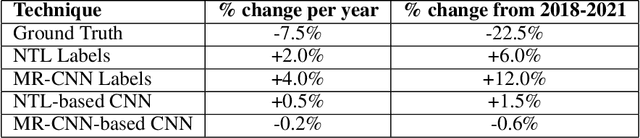
Due to insufficient or difficult to obtain data on development in inaccessible regions, remote sensing data is an important tool for interested stakeholders to collect information on economic growth. To date, no studies have utilized deep learning to estimate industrial growth at the level of individual sites. In this study, we harness high-resolution panchromatic imagery to estimate development over time at 419 industrial sites in the People's Republic of China using a multi-tier computer vision framework. We present two methods for approximating development: (1) structural area coverage estimated through a Mask R-CNN segmentation algorithm, and (2) imputing development directly with visible & infrared radiance from the Visible Infrared Imaging Radiometer Suite (VIIRS). Labels generated from these methods are comparatively evaluated and tested. On a dataset of 2,078 50 cm resolution images spanning 19 years, the results indicate that two dimensions of industrial development can be estimated using high-resolution daytime imagery, including (a) the total square meters of industrial development (average error of 0.021 $\textrm{km}^2$), and (b) the radiance of lights (average error of 9.8 $\mathrm{\frac{nW}{cm^{2}sr}}$). Trend analysis of the techniques reveal estimates from a Mask R-CNN-labeled CNN-LSTM track ground truth measurements most closely. The Mask R-CNN estimates positive growth at every site from the oldest image to the most recent, with an average change of 4,084 $\textrm{m}^2$.
Deep Bayesian Active-Learning-to-Rank for Endoscopic Image Data
Aug 05, 2022Automatic image-based disease severity estimation generally uses discrete (i.e., quantized) severity labels. Annotating discrete labels is often difficult due to the images with ambiguous severity. An easier alternative is to use relative annotation, which compares the severity level between image pairs. By using a learning-to-rank framework with relative annotation, we can train a neural network that estimates rank scores that are relative to severity levels. However, the relative annotation for all possible pairs is prohibitive, and therefore, appropriate sample pair selection is mandatory. This paper proposes a deep Bayesian active-learning-to-rank, which trains a Bayesian convolutional neural network while automatically selecting appropriate pairs for relative annotation. We confirmed the efficiency of the proposed method through experiments on endoscopic images of ulcerative colitis. In addition, we confirmed that our method is useful even with the severe class imbalance because of its ability to select samples from minor classes automatically.
U-Net vs Transformer: Is U-Net Outdated in Medical Image Registration?
Aug 13, 2022
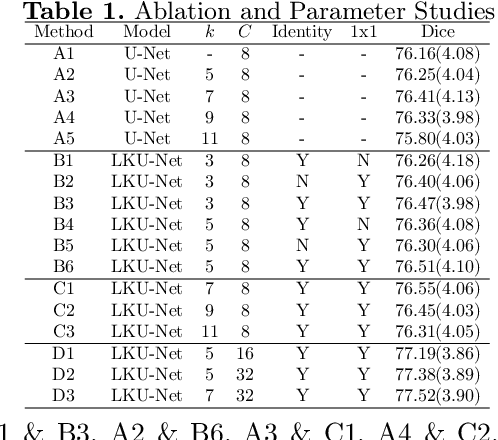
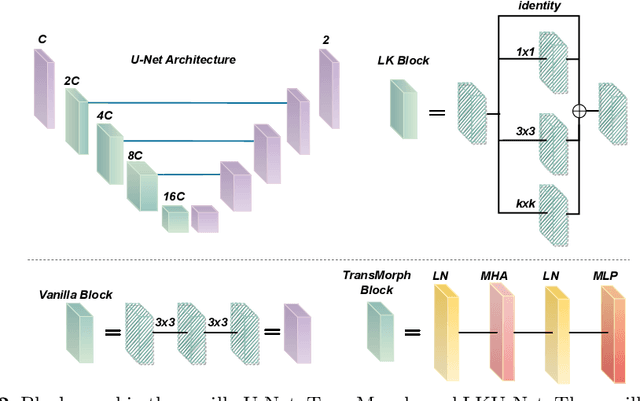
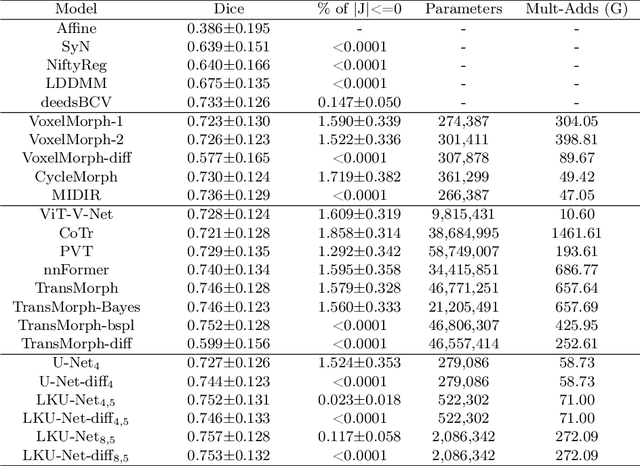
Due to their extreme long-range modeling capability, vision transformer-based networks have become increasingly popular in deformable image registration. We believe, however, that the receptive field of a 5-layer convolutional U-Net is sufficient to capture accurate deformations without needing long-range dependencies. The purpose of this study is therefore to investigate whether U-Net-based methods are outdated compared to modern transformer-based approaches when applied to medical image registration. For this, we propose a large kernel U-Net (LKU-Net) by embedding a parallel convolutional block to a vanilla U-Net in order to enhance the effective receptive field. On the public 3D IXI brain dataset for atlas-based registration, we show that the performance of the vanilla U-Net is already comparable with that of state-of-the-art transformer-based networks (such as TransMorph), and that the proposed LKU-Net outperforms TransMorph by using only 1.12% of its parameters and 10.8% of its mult-adds operations. We further evaluate LKU-Net on a MICCAI Learn2Reg 2021 challenge dataset for inter-subject registration, our LKU-Net also outperforms TransMorph on this dataset and ranks first on the public leaderboard as of the submission of this work. With only modest modifications to the vanilla U-Net, we show that U-Net can outperform transformer-based architectures on inter-subject and atlas-based 3D medical image registration. Code is available at https://github.com/xi-jia/LKU-Net.