 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Foveated Thermal Computational Imaging in the Wild Using All-Silicon Meta-Optics
Dec 13, 2022
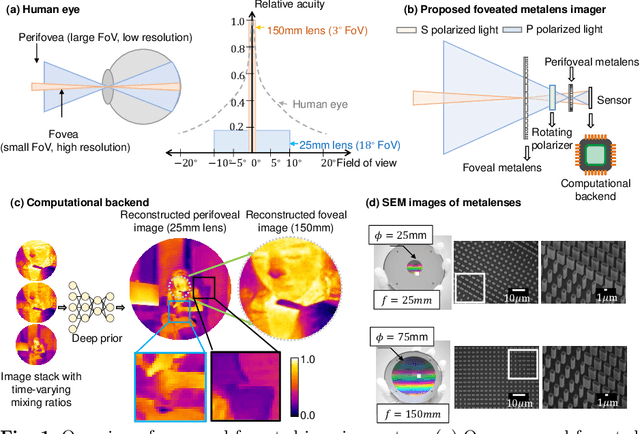
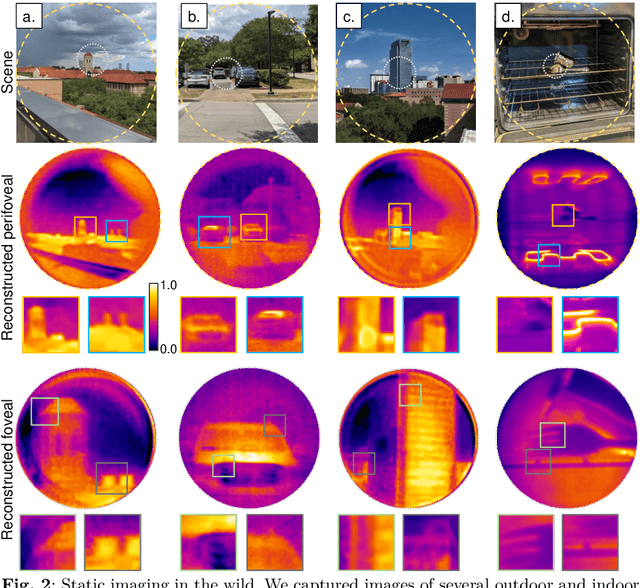
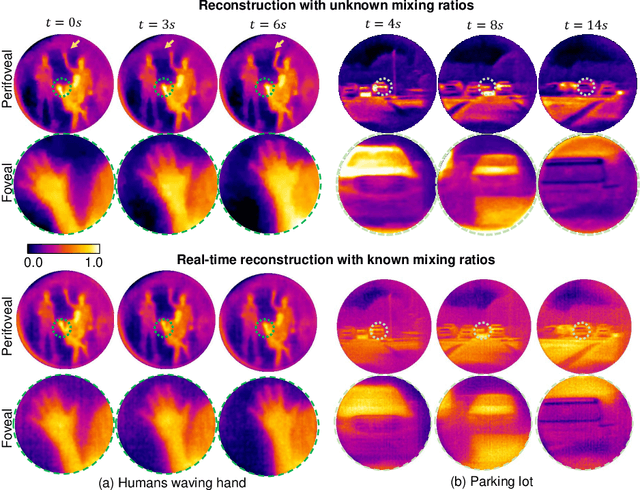
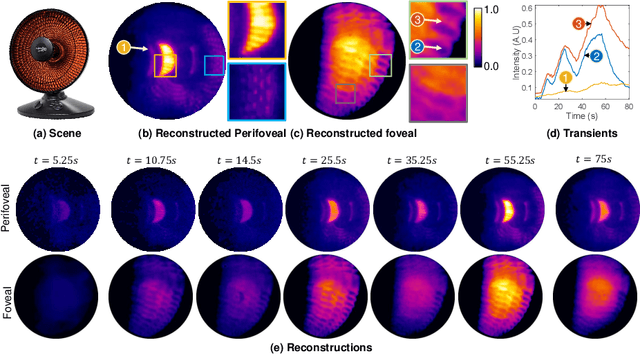
Foveated imaging provides a better tradeoff between situational awareness (field of view) and resolution and is critical in long-wavelength infrared regimes because of the size, weight, power, and cost of thermal sensors. We demonstrate computational foveated imaging by exploiting the ability of a meta-optical frontend to discriminate between different polarization states and a computational backend to reconstruct the captured image/video. The frontend is a three-element optic: the first element which we call the "foveal" element is a metalens that focuses s-polarized light at a distance of $f_1$ without affecting the p-polarized light; the second element which we call the "perifoveal" element is another metalens that focuses p-polarized light at a distance of $f_2$ without affecting the s-polarized light. The third element is a freely rotating polarizer that dynamically changes the mixing ratios between the two polarization states. Both the foveal element (focal length = 150mm; diameter = 75mm), and the perifoveal element (focal length = 25mm; diameter = 25mm) were fabricated as polarization-sensitive, all-silicon, meta surfaces resulting in a large-aperture, 1:6 foveal expansion, thermal imaging capability. A computational backend then utilizes a deep image prior to separate the resultant multiplexed image or video into a foveated image consisting of a high-resolution center and a lower-resolution large field of view context. We build a first-of-its-kind prototype system and demonstrate 12 frames per second real-time, thermal, foveated image, and video capture in the wild.
CLIP2GAN: Towards Bridging Text with the Latent Space of GANs
Nov 28, 2022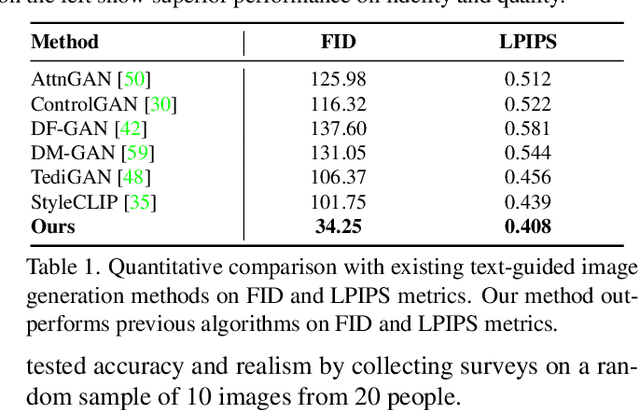
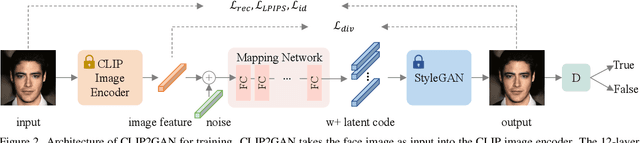
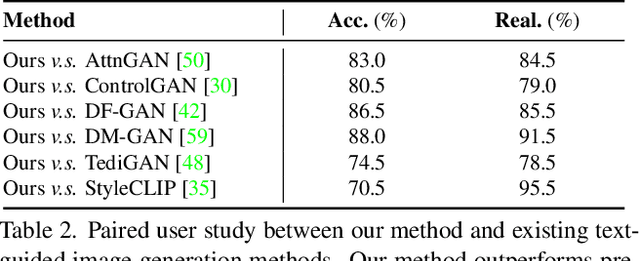
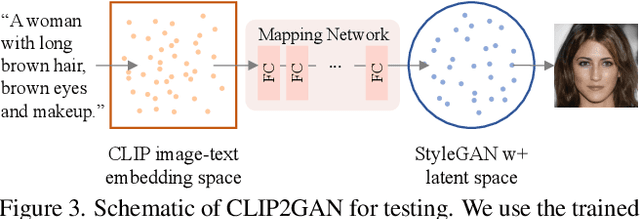
In this work, we are dedicated to text-guided image generation and propose a novel framework, i.e., CLIP2GAN, by leveraging CLIP model and StyleGAN. The key idea of our CLIP2GAN is to bridge the output feature embedding space of CLIP and the input latent space of StyleGAN, which is realized by introducing a mapping network. In the training stage, we encode an image with CLIP and map the output feature to a latent code, which is further used to reconstruct the image. In this way, the mapping network is optimized in a self-supervised learning way. In the inference stage, since CLIP can embed both image and text into a shared feature embedding space, we replace CLIP image encoder in the training architecture with CLIP text encoder, while keeping the following mapping network as well as StyleGAN model. As a result, we can flexibly input a text description to generate an image. Moreover, by simply adding mapped text features of an attribute to a mapped CLIP image feature, we can effectively edit the attribute to the image. Extensive experiments demonstrate the superior performance of our proposed CLIP2GAN compared to previous methods.
simple diffusion: End-to-end diffusion for high resolution images
Jan 26, 2023
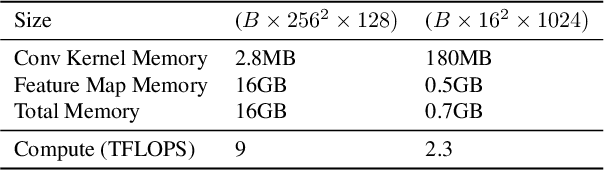

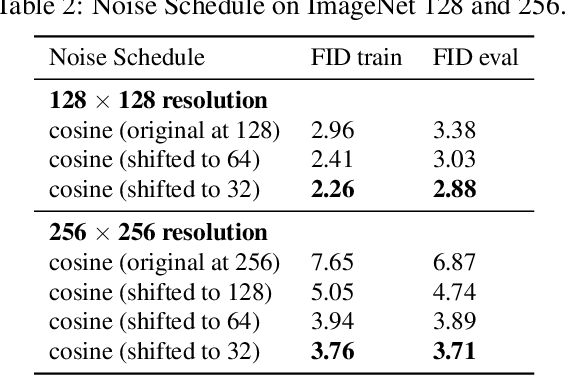
Currently, applying diffusion models in pixel space of high resolution images is difficult. Instead, existing approaches focus on diffusion in lower dimensional spaces (latent diffusion), or have multiple super-resolution levels of generation referred to as cascades. The downside is that these approaches add additional complexity to the diffusion framework. This paper aims to improve denoising diffusion for high resolution images while keeping the model as simple as possible. The paper is centered around the research question: How can one train a standard denoising diffusion models on high resolution images, and still obtain performance comparable to these alternate approaches? The four main findings are: 1) the noise schedule should be adjusted for high resolution images, 2) It is sufficient to scale only a particular part of the architecture, 3) dropout should be added at specific locations in the architecture, and 4) downsampling is an effective strategy to avoid high resolution feature maps. Combining these simple yet effective techniques, we achieve state-of-the-art on image generation among diffusion models without sampling modifiers on ImageNet.
A novel state connection strategy for quantum computing to represent and compress digital images
Dec 14, 2022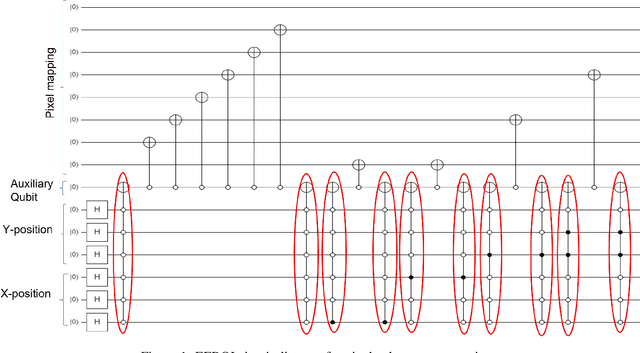
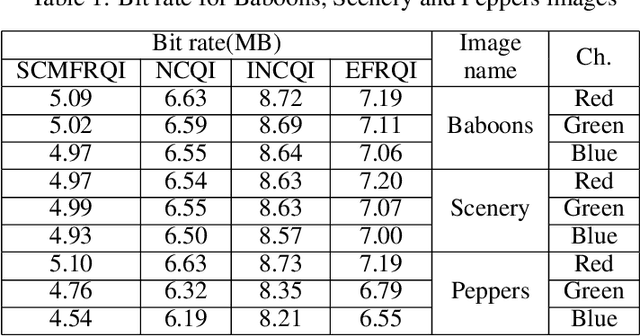
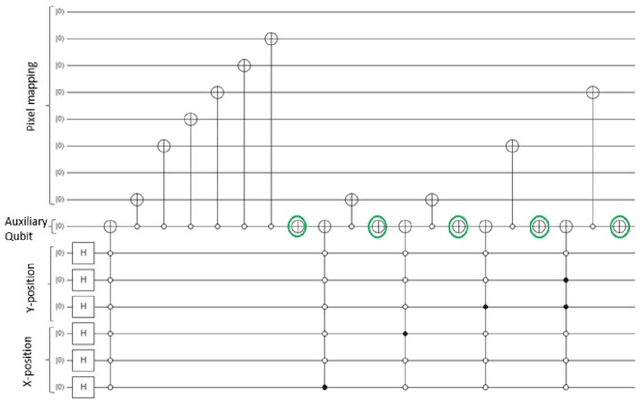
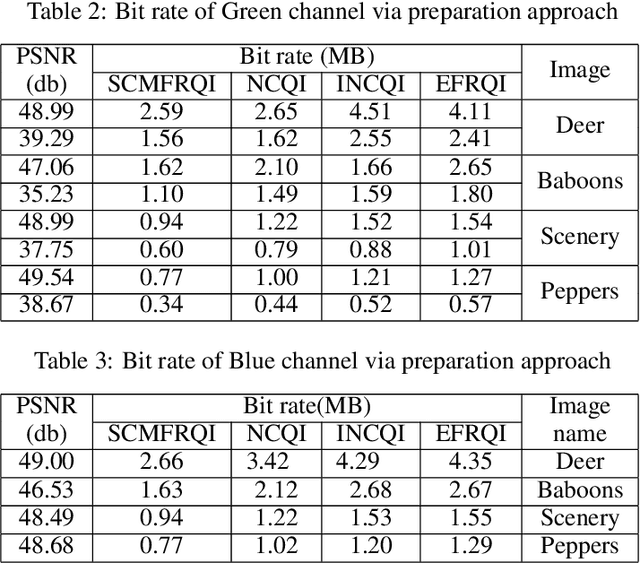
Quantum image processing draws a lot of attention due to faster data computation and storage compared to classical data processing systems. Converting classical image data into the quantum domain and state label preparation complexity is still a challenging issue. The existing techniques normally connect the pixel values and the state position directly. Recently, the EFRQI (efficient flexible representation of the quantum image) approach uses an auxiliary qubit that connects the pixel-representing qubits to the state position qubits via Toffoli gates to reduce state connection. Due to the twice use of Toffoli gates for each pixel connection still it requires a significant number of bits to connect each pixel value. In this paper, we propose a new SCMFRQI (state connection modification FRQI) approach for further reducing the required bits by modifying the state connection using a reset gate rather than repeating the use of the same Toffoli gate connection as a reset gate. Moreover, unlike other existing methods, we compress images using block-level for further reduction of required qubits. The experimental results confirm that the proposed method outperforms the existing methods in terms of both image representation and compression points of view.
Complementary consistency semi-supervised learning for 3D left atrial image segmentation
Oct 04, 2022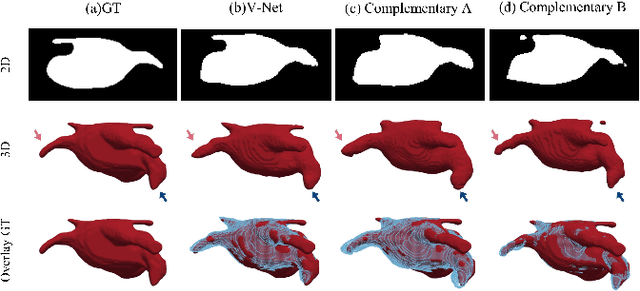
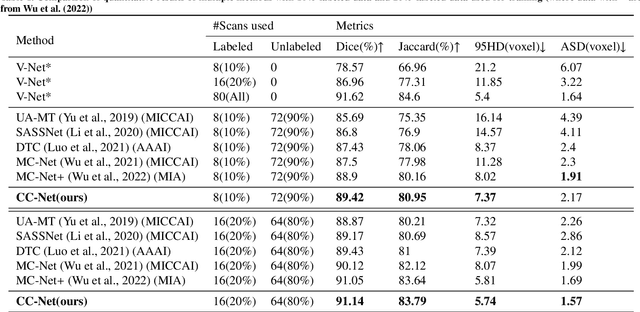
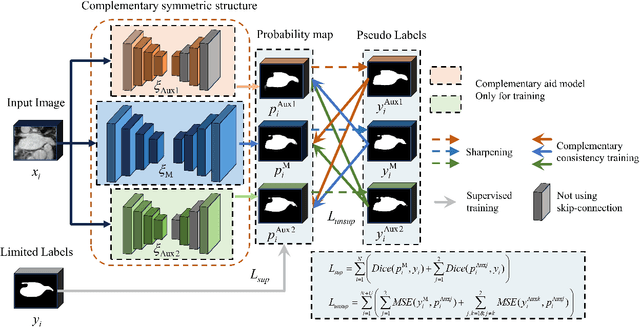
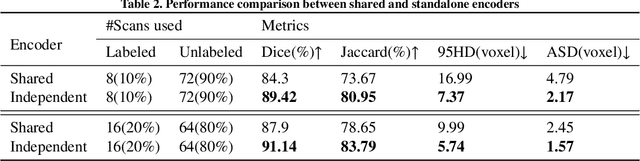
A network based on complementary consistency training (CC-Net) is proposed for semi-supervised left atrial image segmentation in this paper. From the perspective of complementary information, CC-Net effectively utilizes unlabeled data and resolves the problem that semi-supervised segmentation algorithms currently in use have a limited capacity to extract information from unlabeled data. A primary model and two complementary auxiliary models are part of the complementary symmetric structure of the CC-Net. A complementary consistency training is formed by the inter-model perturbation between the primary model and the auxiliary models. The main model is better able to concentrate on the ambiguous region due to the complementary information provided by the two auxiliary models. Additionally, forcing consistency between the primary model and the auxiliary models makes it easier to obtain decision boundaries with little uncertainty. CC-Net was validated in the benchmark dataset of 2018 left atrial segmentation challenge, reaching Dice of 89.42% with 10% labeled data training and 91.14% with 20% labeled data training. By comparing with current state-of-the-art algorithms, CC-Net has the best segmentation performance and robustness. Our code is publicly available at https://github.com/Cuthbert-Huang/CC-Net.
A review of schemes for fingerprint image quality computation
Jul 12, 2022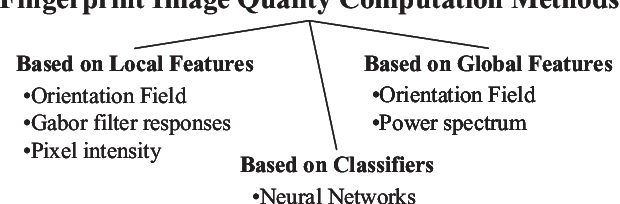

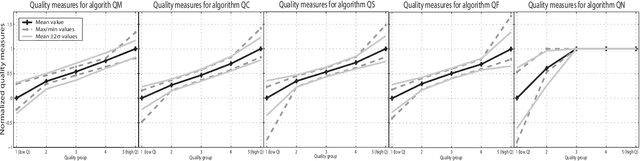
Fingerprint image quality affects heavily the performance of fingerprint recognition systems. This paper reviews existing approaches for fingerprint image quality computation. We also implement, test and compare a selection of them using the MCYT database including 9000 fingerprint images. Experimental results show that most of the algorithms behave similarly.
Bridging the Gap: Differentially Private Equivariant Deep Learning for Medical Image Analysis
Sep 09, 2022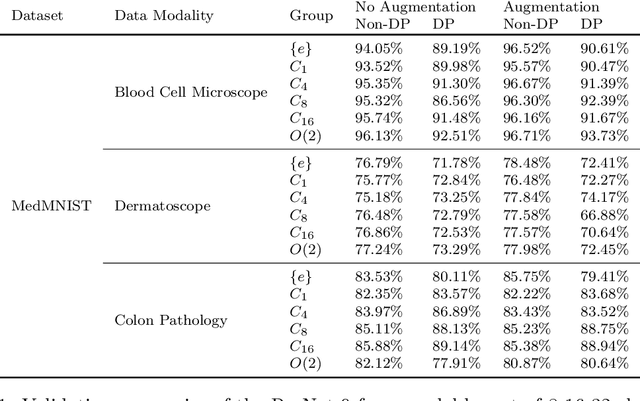
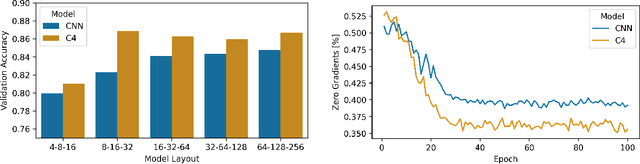
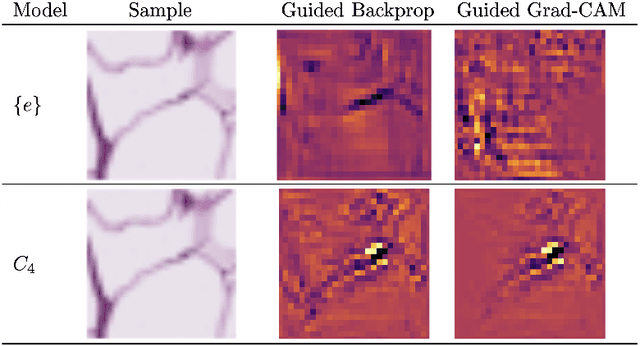
Machine learning with formal privacy-preserving techniques like Differential Privacy (DP) allows one to derive valuable insights from sensitive medical imaging data while promising to protect patient privacy, but it usually comes at a sharp privacy-utility trade-off. In this work, we propose to use steerable equivariant convolutional networks for medical image analysis with DP. Their improved feature quality and parameter efficiency yield remarkable accuracy gains, narrowing the privacy-utility gap.
Unsupervised Multi-Modal Medical Image Registration via Discriminator-Free Image-to-Image Translation
Apr 28, 2022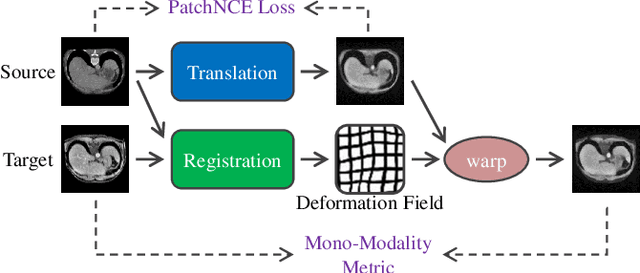
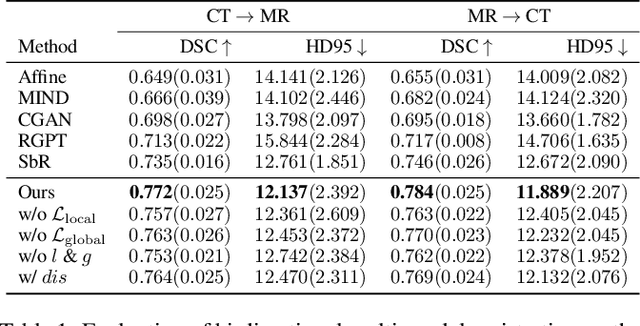
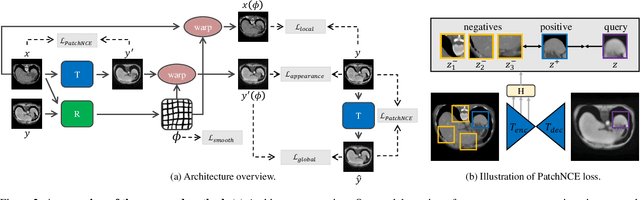
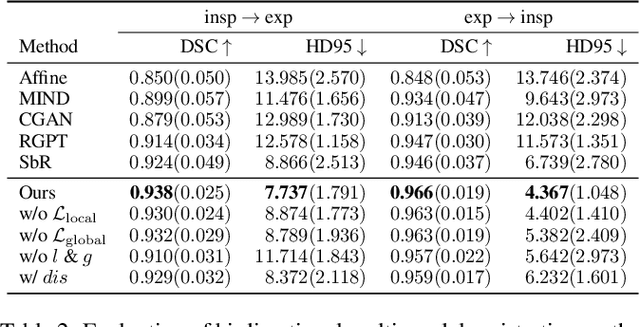
In clinical practice, well-aligned multi-modal images, such as Magnetic Resonance (MR) and Computed Tomography (CT), together can provide complementary information for image-guided therapies. Multi-modal image registration is essential for the accurate alignment of these multi-modal images. However, it remains a very challenging task due to complicated and unknown spatial correspondence between different modalities. In this paper, we propose a novel translation-based unsupervised deformable image registration approach to convert the multi-modal registration problem to a mono-modal one. Specifically, our approach incorporates a discriminator-free translation network to facilitate the training of the registration network and a patchwise contrastive loss to encourage the translation network to preserve object shapes. Furthermore, we propose to replace an adversarial loss, that is widely used in previous multi-modal image registration methods, with a pixel loss in order to integrate the output of translation into the target modality. This leads to an unsupervised method requiring no ground-truth deformation or pairs of aligned images for training. We evaluate four variants of our approach on the public Learn2Reg 2021 datasets \cite{hering2021learn2reg}. The experimental results demonstrate that the proposed architecture achieves state-of-the-art performance. Our code is available at https://github.com/heyblackC/DFMIR.
BinaryVQA: A Versatile Test Set to Evaluate the Out-of-Distribution Generalization of VQA Models
Jan 28, 2023
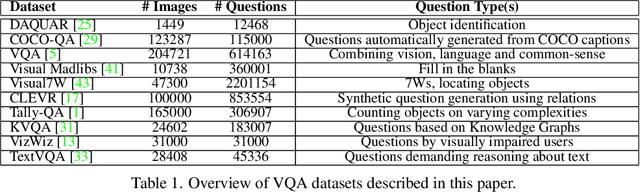

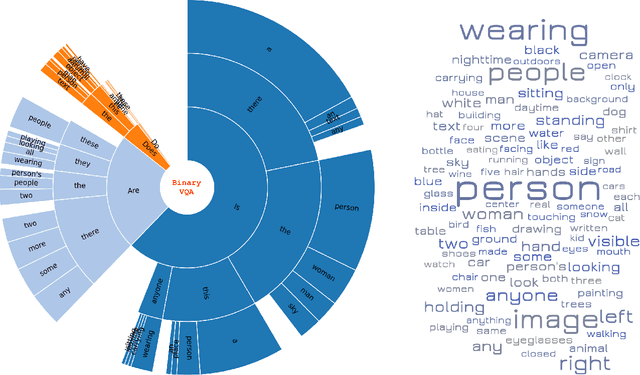
We introduce a new test set for visual question answering (VQA) called BinaryVQA to push the limits of VQA models. Our dataset includes 7,800 questions across 1,024 images and covers a wide variety of objects, topics, and concepts. For easy model evaluation, we only consider binary questions. Questions and answers are formulated and verified carefully and manually. Around 63% of the questions have positive answers. The median number of questions per image and question length are 7 and 5, respectively. The state of the art OFA model achieves 75% accuracy on BinaryVQA dataset, which is significantly lower than its performance on the VQA v2 test-dev dataset (94.7%). We also analyze the model behavior along several dimensions including: a) performance over different categories such as text, counting and gaze direction, b) model interpretability, c) the effect of question length on accuracy, d) bias of models towards positive answers and introduction of a new score called the ShuffleAcc, and e) sensitivity to spelling and grammar errors. Our investigation demonstrates the difficulty of our dataset and shows that it can challenge VQA models for next few years. Data and code are publicly available at: DATA and CODE.
MetaNO: How to Transfer Your Knowledge on Learning Hidden Physics
Jan 28, 2023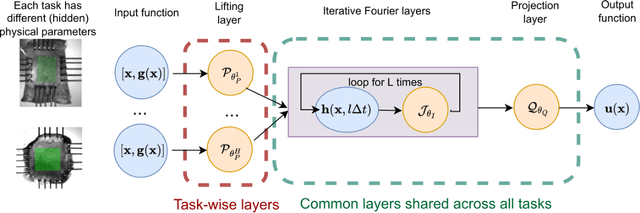
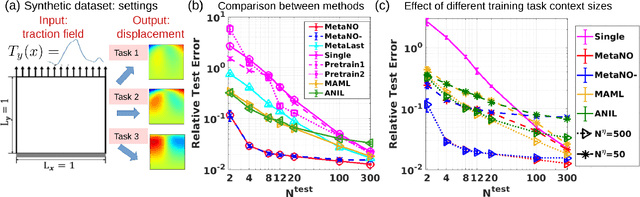
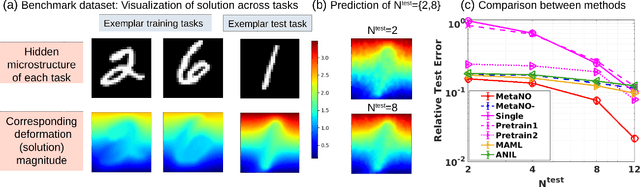
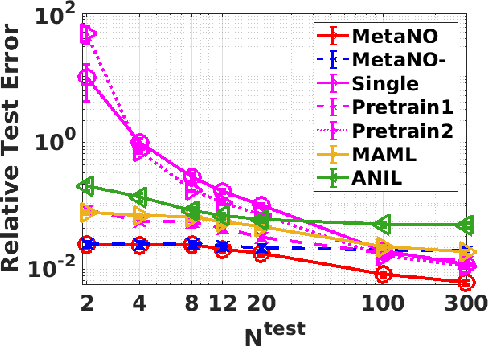
Gradient-based meta-learning methods have primarily been applied to classical machine learning tasks such as image classification. Recently, PDE-solving deep learning methods, such as neural operators, are starting to make an important impact on learning and predicting the response of a complex physical system directly from observational data. Since the data acquisition in this context is commonly challenging and costly, the call of utilization and transfer of existing knowledge to new and unseen physical systems is even more acute. Herein, we propose a novel meta-learning approach for neural operators, which can be seen as transferring the knowledge of solution operators between governing (unknown) PDEs with varying parameter fields. Our approach is a provably universal solution operator for multiple PDE solving tasks, with a key theoretical observation that underlying parameter fields can be captured in the first layer of neural operator models, in contrast to typical final-layer transfer in existing meta-learning methods. As applications, we demonstrate the efficacy of our proposed approach on PDE-based datasets and a real-world material modeling problem, illustrating that our method can handle complex and nonlinear physical response learning tasks while greatly improving the sampling efficiency in unseen tasks.