 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Spatiotemporal Diffusion Model with Paired Sampling for Accelerated Cardiac Cine MRI
Mar 13, 2024
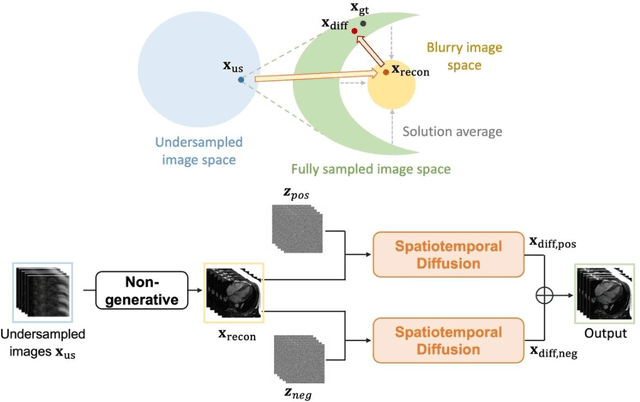
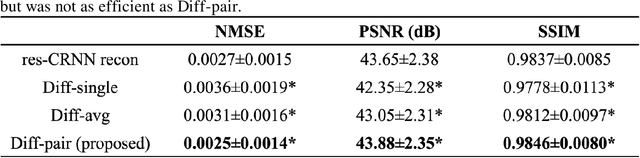
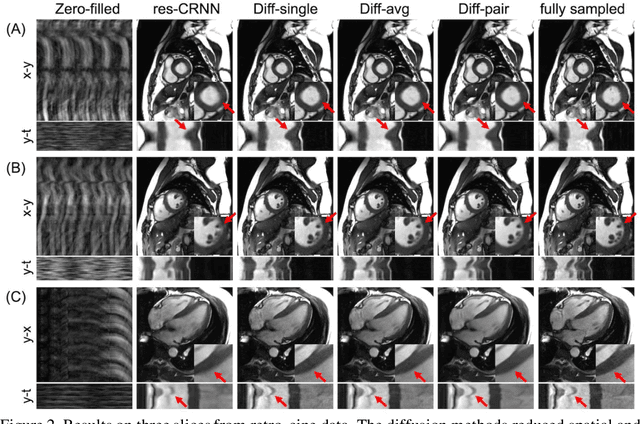
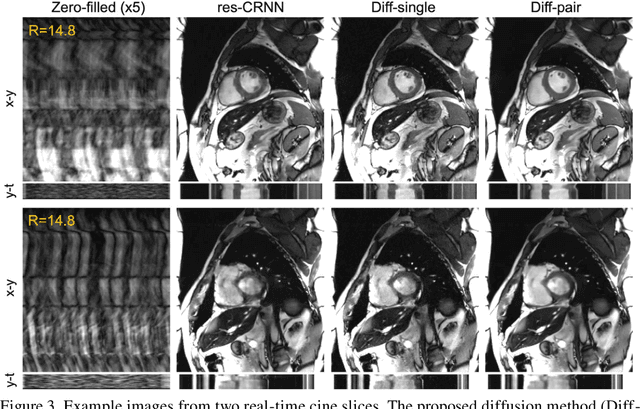
Current deep learning reconstruction for accelerated cardiac cine MRI suffers from spatial and temporal blurring. We aim to improve image sharpness and motion delineation for cine MRI under high undersampling rates. A spatiotemporal diffusion enhancement model conditional on an existing deep learning reconstruction along with a novel paired sampling strategy was developed. The diffusion model provided sharper tissue boundaries and clearer motion than the original reconstruction in experts evaluation on clinical data. The innovative paired sampling strategy substantially reduced artificial noises in the generative results.
Impact of Synthetic Images on Morphing Attack Detection Using a Siamese Network
Mar 14, 2024This paper evaluated the impact of synthetic images on Morphing Attack Detection (MAD) using a Siamese network with a semi-hard-loss function. Intra and cross-dataset evaluations were performed to measure synthetic image generalisation capabilities using a cross-dataset for evaluation. Three different pre-trained networks were used as feature extractors from traditional MobileNetV2, MobileNetV3 and EfficientNetB0. Our results show that MAD trained on EfficientNetB0 from FERET, FRGCv2, and FRLL can reach a lower error rate in comparison with SOTA. Conversely, worse performances were reached when the system was trained only with synthetic images. A mixed approach (synthetic + digital) database may help to improve MAD and reduce the error rate. This fact shows that we still need to keep going with our efforts to include synthetic images in the training process.
PyHySCO: GPU-Enabled Susceptibility Artifact Distortion Correction in Seconds
Mar 15, 2024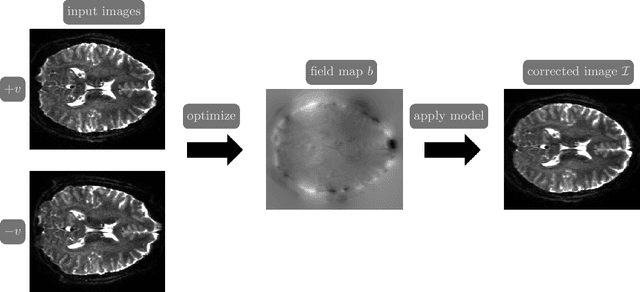

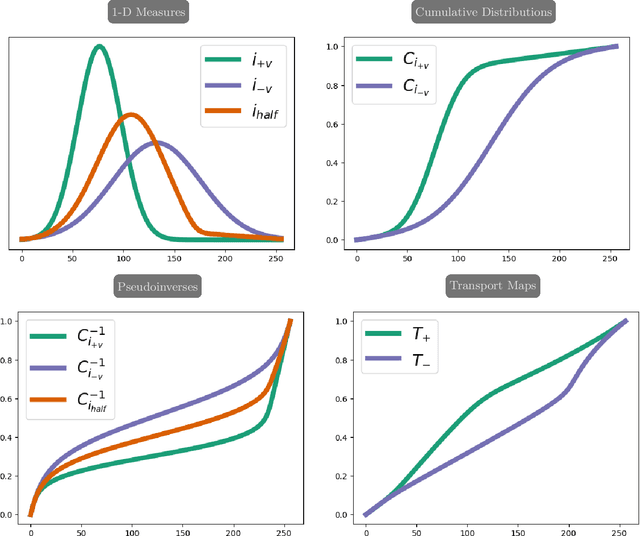
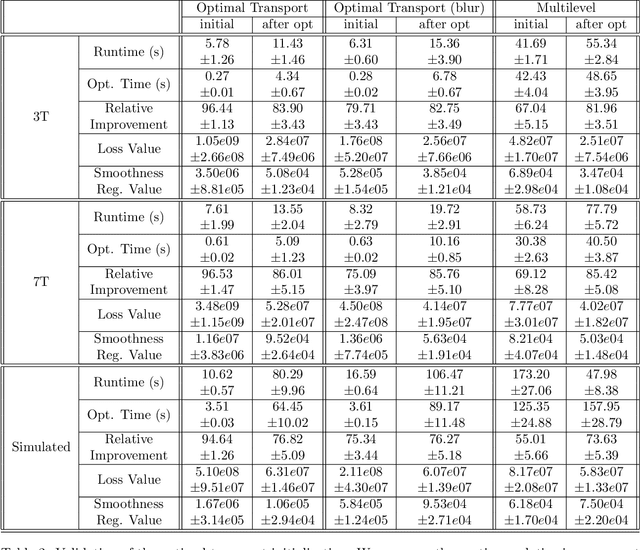
Over the past decade, reversed Gradient Polarity (RGP) methods have become a popular approach for correcting susceptibility artifacts in Echo-Planar Imaging (EPI). Although several post-processing tools for RGP are available, their implementations do not fully leverage recent hardware, algorithmic, and computational advances, leading to correction times of several minutes per image volume. To enable 3D RGP correction in seconds, we introduce PyHySCO, a user-friendly EPI distortion correction tool implemented in PyTorch that enables multi-threading and efficient use of graphics processing units (GPUs). PyHySCO uses a time-tested physical distortion model and mathematical formulation and is, therefore, reliable without training. An algorithmic improvement in PyHySCO is its novel initialization scheme that uses 1D optimal transport. PyHySCO is published under the GNU public license and can be used from the command line or its Python interface. Our extensive numerical validation using 3T and 7T data from the Human Connectome Project suggests that PyHySCO achieves accuracy comparable to that of leading RGP tools at a fraction of the cost. We also validate the new initialization scheme, compare different optimization algorithms, and test the algorithm on different hardware and arithmetic precision.
SparseFusion: Efficient Sparse Multi-Modal Fusion Framework for Long-Range 3D Perception
Mar 15, 2024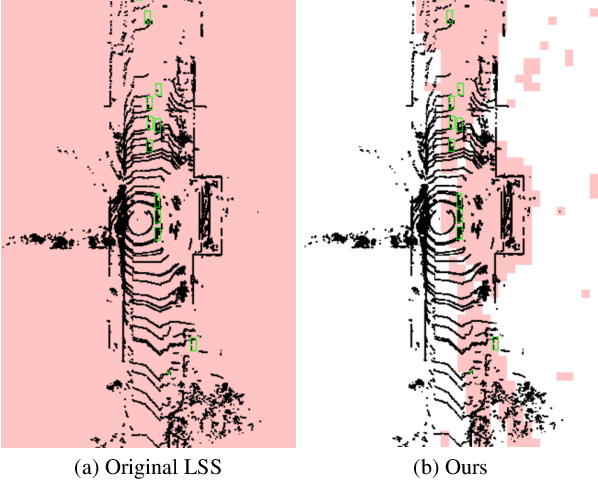

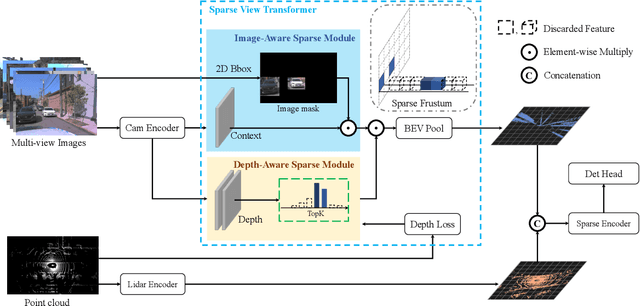
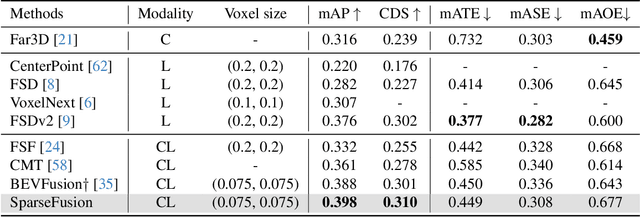
Multi-modal 3D object detection has exhibited significant progress in recent years. However, most existing methods can hardly scale to long-range scenarios due to their reliance on dense 3D features, which substantially escalate computational demands and memory usage. In this paper, we introduce SparseFusion, a novel multi-modal fusion framework fully built upon sparse 3D features to facilitate efficient long-range perception. The core of our method is the Sparse View Transformer module, which selectively lifts regions of interest in 2D image space into the unified 3D space. The proposed module introduces sparsity from both semantic and geometric aspects which only fill grids that foreground objects potentially reside in. Comprehensive experiments have verified the efficiency and effectiveness of our framework in long-range 3D perception. Remarkably, on the long-range Argoverse2 dataset, SparseFusion reduces memory footprint and accelerates the inference by about two times compared to dense detectors. It also achieves state-of-the-art performance with mAP of 41.2% and CDS of 32.1%. The versatility of SparseFusion is also validated in the temporal object detection task and 3D lane detection task. Codes will be released upon acceptance.
A Novel Framework for Multi-Person Temporal Gaze Following and Social Gaze Prediction
Mar 15, 2024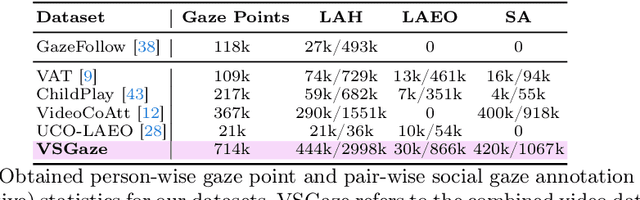
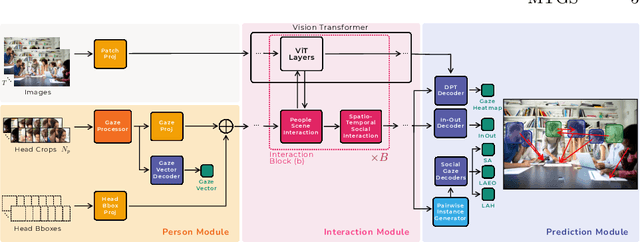
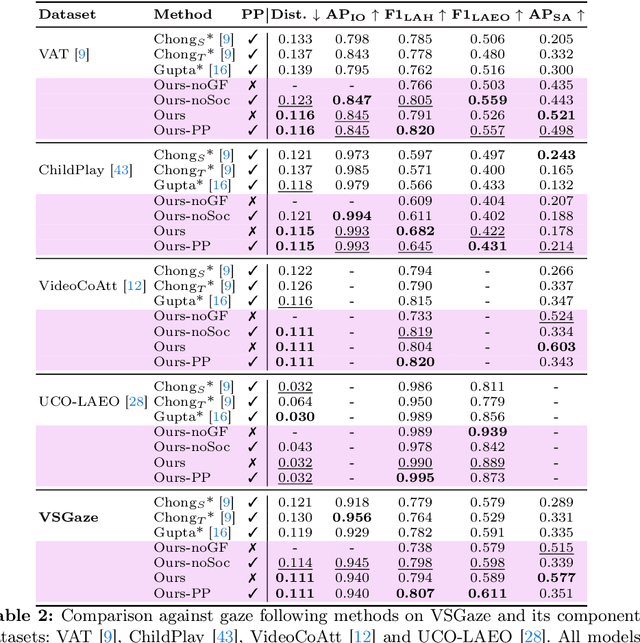
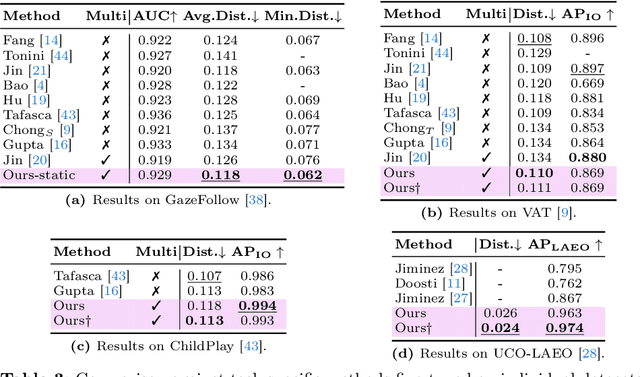
Gaze following and social gaze prediction are fundamental tasks providing insights into human communication behaviors, intent, and social interactions. Most previous approaches addressed these tasks separately, either by designing highly specialized social gaze models that do not generalize to other social gaze tasks or by considering social gaze inference as an ad-hoc post-processing of the gaze following task. Furthermore, the vast majority of gaze following approaches have proposed static models that can handle only one person at a time, therefore failing to take advantage of social interactions and temporal dynamics. In this paper, we address these limitations and introduce a novel framework to jointly predict the gaze target and social gaze label for all people in the scene. The framework comprises of: (i) a temporal, transformer-based architecture that, in addition to image tokens, handles person-specific tokens capturing the gaze information related to each individual; (ii) a new dataset, VSGaze, that unifies annotation types across multiple gaze following and social gaze datasets. We show that our model trained on VSGaze can address all tasks jointly, and achieves state-of-the-art results for multi-person gaze following and social gaze prediction.
An Active Contour Model Driven By the Hybrid Signed Pressure Function
Mar 12, 2024
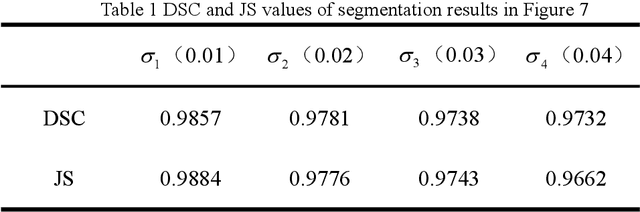
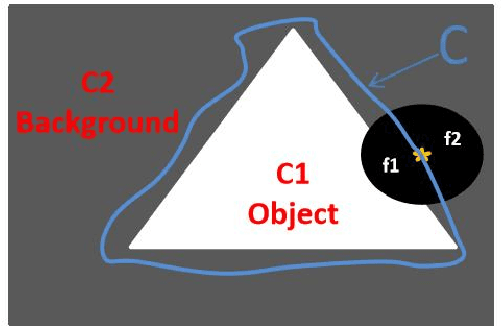
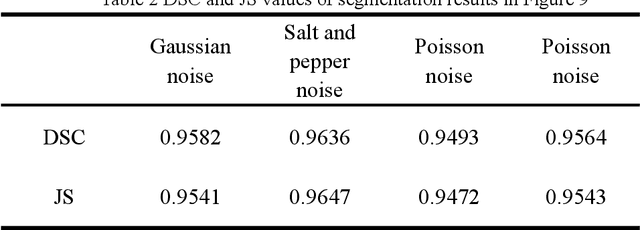
Due to the influence of imaging equipment and complex imaging environments, most images in daily life have features of intensity inhomogeneity and noise. Therefore, many scholars have designed many image segmentation algorithms to address these issues. Among them, the active contour model is one of the most effective image segmentation algorithms.This paper proposes an active contour model driven by the hybrid signed pressure function that combines global and local information construction. Firstly, a new global region-based signed pressure function is introduced by combining the average intensity of the inner and outer regions of the curve with the median intensity of the inner region of the evolution curve. Then, the paper uses the energy differences between the inner and outer regions of the curve in the local region to design the signed pressure function of the local term. Combine the two SPF function to obtain a new signed pressure function and get the evolution equation of the new model. Finally, experiments and numerical analysis show that the model has excellent segmentation performance for both intensity inhomogeneous images and noisy images.
Time-Efficient Light-Field Acquisition Using Coded Aperture and Events
Mar 12, 2024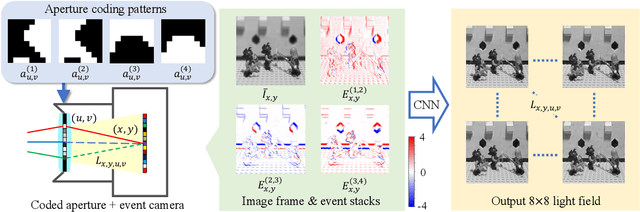
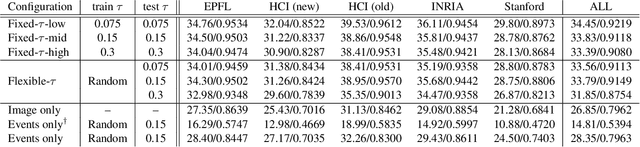
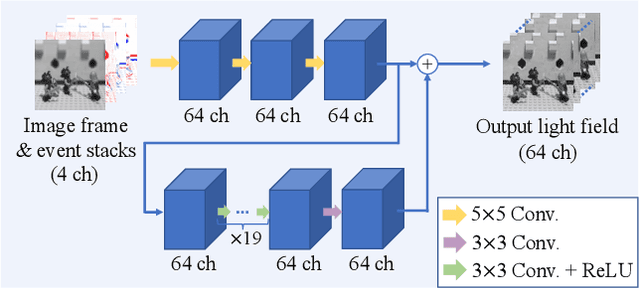
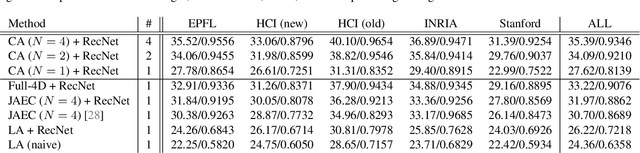
We propose a computational imaging method for time-efficient light-field acquisition that combines a coded aperture with an event-based camera. Different from the conventional coded-aperture imaging method, our method applies a sequence of coding patterns during a single exposure for an image frame. The parallax information, which is related to the differences in coding patterns, is recorded as events. The image frame and events, all of which are measured in a single exposure, are jointly used to computationally reconstruct a light field. We also designed an algorithm pipeline for our method that is end-to-end trainable on the basis of deep optics and compatible with real camera hardware. We experimentally showed that our method can achieve more accurate reconstruction than several other imaging methods with a single exposure. We also developed a hardware prototype with the potential to complete the measurement on the camera within 22 msec and demonstrated that light fields from real 3-D scenes can be obtained with convincing visual quality. Our software and supplementary video are available from our project website.
KEBench: A Benchmark on Knowledge Editing for Large Vision-Language Models
Mar 12, 2024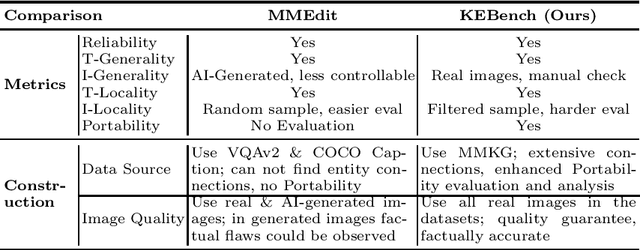

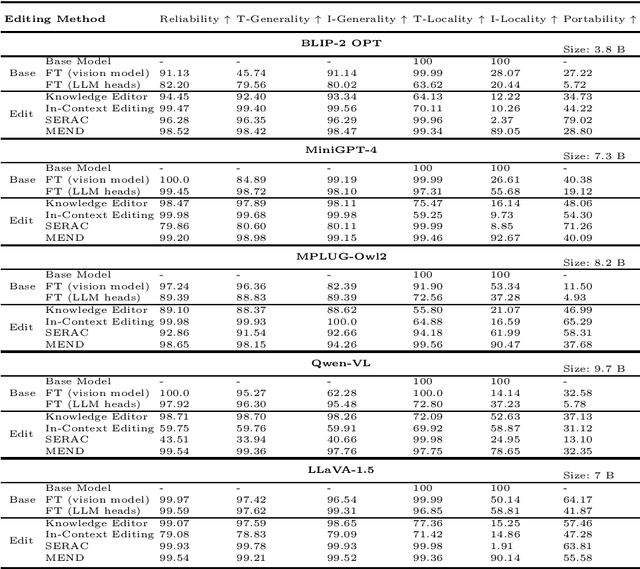
Currently, little research has been done on knowledge editing for Large Vision-Language Models (LVLMs). Editing LVLMs faces the challenge of effectively integrating diverse modalities (image and text) while ensuring coherent and contextually relevant modifications. An existing benchmark has three metrics (Reliability, Locality and Generality) to measure knowledge editing for LVLMs. However, the benchmark falls short in the quality of generated images used in evaluation and cannot assess whether models effectively utilize edited knowledge in relation to the associated content. We adopt different data collection methods to construct a new benchmark, $\textbf{KEBench}$, and extend new metric (Portability) for a comprehensive evaluation. Leveraging a multimodal knowledge graph, our image data exhibits clear directionality towards entities. This directional aspect can be further utilized to extract entity-related knowledge and form editing data. We conducted experiments of different editing methods on five LVLMs, and thoroughly analyze how these methods impact the models. The results reveal strengths and deficiencies of these methods and, hopefully, provide insights into potential avenues for future research.
MAP-Elites with Transverse Assessment for Multimodal Problems in Creative Domains
Mar 11, 2024The recent advances in language-based generative models have paved the way for the orchestration of multiple generators of different artefact types (text, image, audio, etc.) into one system. Presently, many open-source pre-trained models combine text with other modalities, thus enabling shared vector embeddings to be compared across different generators. Within this context we propose a novel approach to handle multimodal creative tasks using Quality Diversity evolution. Our contribution is a variation of the MAP-Elites algorithm, MAP-Elites with Transverse Assessment (MEliTA), which is tailored for multimodal creative tasks and leverages deep learned models that assess coherence across modalities. MEliTA decouples the artefacts' modalities and promotes cross-pollination between elites. As a test bed for this algorithm, we generate text descriptions and cover images for a hypothetical video game and assign each artefact a unique modality-specific behavioural characteristic. Results indicate that MEliTA can improve text-to-image mappings within the solution space, compared to a baseline MAP-Elites algorithm that strictly treats each image-text pair as one solution. Our approach represents a significant step forward in multimodal bottom-up orchestration and lays the groundwork for more complex systems coordinating multimodal creative agents in the future.
One Category One Prompt: Dataset Distillation using Diffusion Models
Mar 11, 2024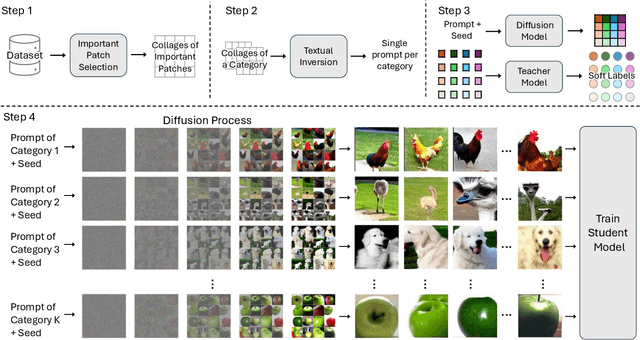
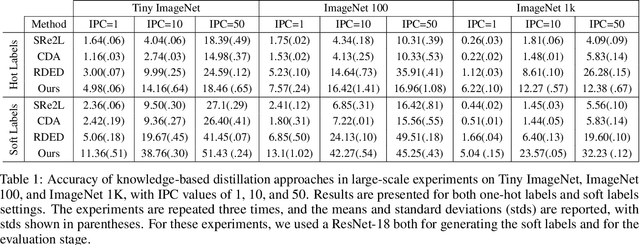
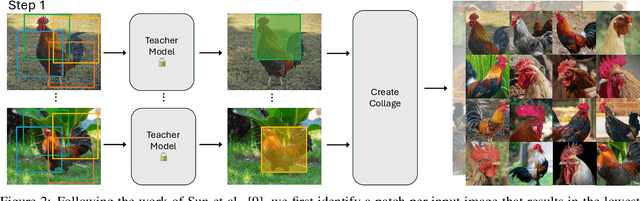
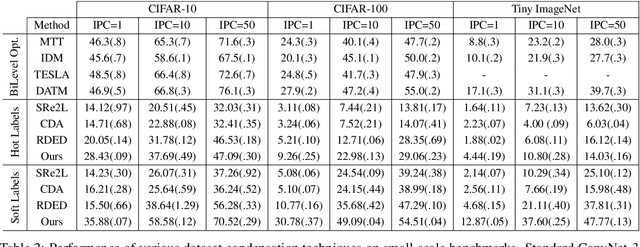
The extensive amounts of data required for training deep neural networks pose significant challenges on storage and transmission fronts. Dataset distillation has emerged as a promising technique to condense the information of massive datasets into a much smaller yet representative set of synthetic samples. However, traditional dataset distillation approaches often struggle to scale effectively with high-resolution images and more complex architectures due to the limitations in bi-level optimization. Recently, several works have proposed exploiting knowledge distillation with decoupled optimization schemes to scale up dataset distillation. Although these methods effectively address the scalability issue, they rely on extensive image augmentations requiring the storage of soft labels for augmented images. In this paper, we introduce Dataset Distillation using Diffusion Models (D3M) as a novel paradigm for dataset distillation, leveraging recent advancements in generative text-to-image foundation models. Our approach utilizes textual inversion, a technique for fine-tuning text-to-image generative models, to create concise and informative representations for large datasets. By employing these learned text prompts, we can efficiently store and infer new samples for introducing data variability within a fixed memory budget. We show the effectiveness of our method through extensive experiments across various computer vision benchmark datasets with different memory budgets.