 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
Aug 25, 2022

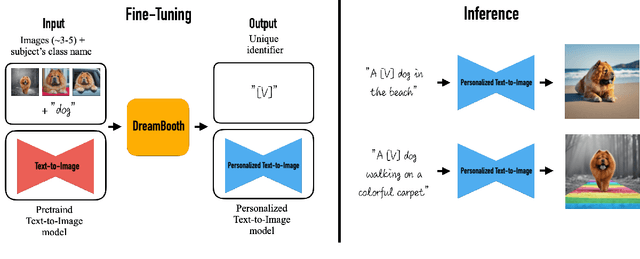
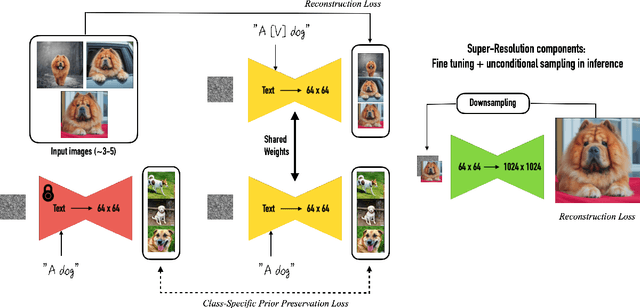

Large text-to-image models achieved a remarkable leap in the evolution of AI, enabling high-quality and diverse synthesis of images from a given text prompt. However, these models lack the ability to mimic the appearance of subjects in a given reference set and synthesize novel renditions of them in different contexts. In this work, we present a new approach for "personalization" of text-to-image diffusion models (specializing them to users' needs). Given as input just a few images of a subject, we fine-tune a pretrained text-to-image model (Imagen, although our method is not limited to a specific model) such that it learns to bind a unique identifier with that specific subject. Once the subject is embedded in the output domain of the model, the unique identifier can then be used to synthesize fully-novel photorealistic images of the subject contextualized in different scenes. By leveraging the semantic prior embedded in the model with a new autogenous class-specific prior preservation loss, our technique enables synthesizing the subject in diverse scenes, poses, views, and lighting conditions that do not appear in the reference images. We apply our technique to several previously-unassailable tasks, including subject recontextualization, text-guided view synthesis, appearance modification, and artistic rendering (all while preserving the subject's key features). Project page: https://dreambooth.github.io/
Equivariant Representations for Non-Free Group Actions
Jan 12, 2023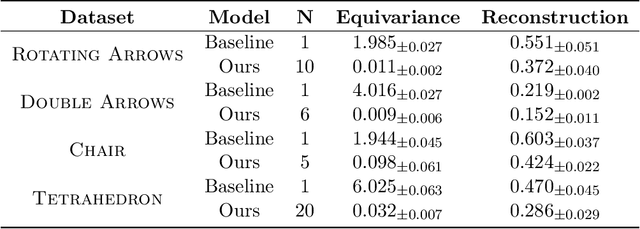

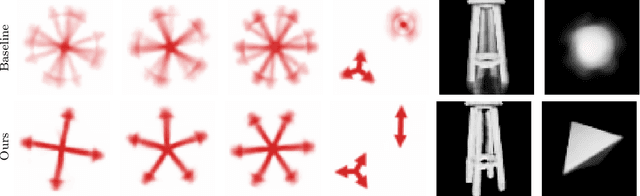
We introduce a method for learning representations that are equivariant with respect to general group actions over data. Differently from existing equivariant representation learners, our method is suitable for actions that are not free i.e., that stabilize data via nontrivial symmetries. Our method is grounded in the orbit-stabilizer theorem from group theory, which guarantees that an ideal learner infers an isomorphic representation. Finally, we provide an empirical investigation on image datasets with rotational symmetries and show that taking stabilizers into account improves the quality of the representations.
Image-to-Image MLP-mixer for Image Reconstruction
Feb 04, 2022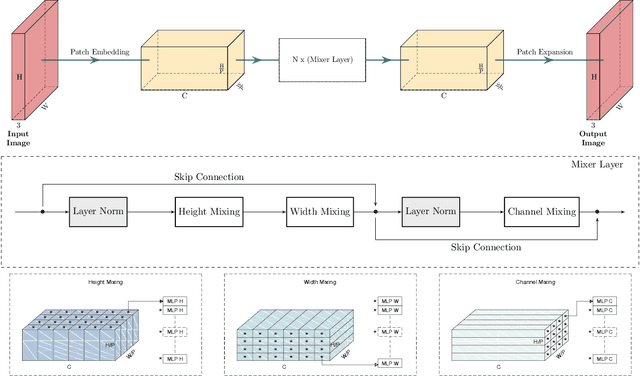
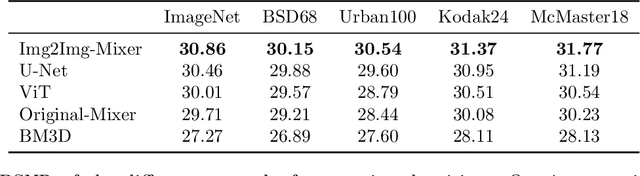
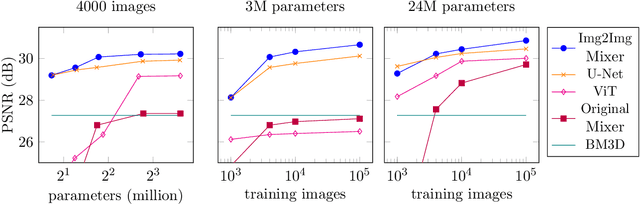

Neural networks are highly effective tools for image reconstruction problems such as denoising and compressive sensing. To date, neural networks for image reconstruction are almost exclusively convolutional. The most popular architecture is the U-Net, a convolutional network with a multi-resolution architecture. In this work, we show that a simple network based on the multi-layer perceptron (MLP)-mixer enables state-of-the art image reconstruction performance without convolutions and without a multi-resolution architecture, provided that the training set and the size of the network are moderately large. Similar to the original MLP-mixer, the image-to-image MLP-mixer is based exclusively on MLPs operating on linearly-transformed image patches. Contrary to the original MLP-mixer, we incorporate structure by retaining the relative positions of the image patches. This imposes an inductive bias towards natural images which enables the image-to-image MLP-mixer to learn to denoise images based on fewer examples than the original MLP-mixer. Moreover, the image-to-image MLP-mixer requires fewer parameters to achieve the same denoising performance than the U-Net and its parameters scale linearly in the image resolution instead of quadratically as for the original MLP-mixer. If trained on a moderate amount of examples for denoising, the image-to-image MLP-mixer outperforms the U-Net by a slight margin. It also outperforms the vision transformer tailored for image reconstruction and classical un-trained methods such as BM3D, making it a very effective tool for image reconstruction problems.
An Impartial Transformer for Story Visualization
Jan 09, 2023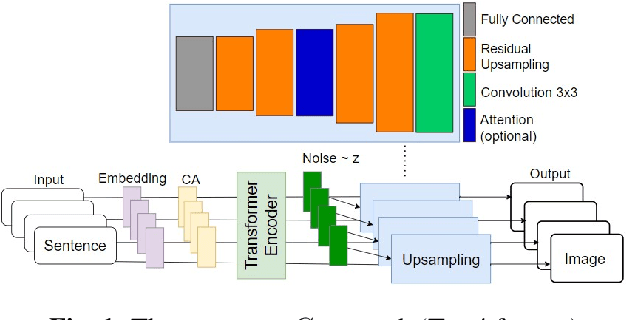
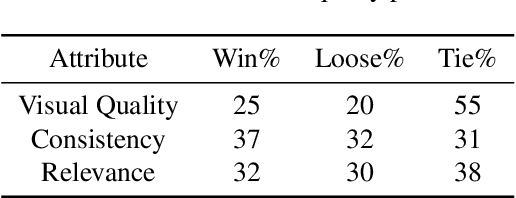
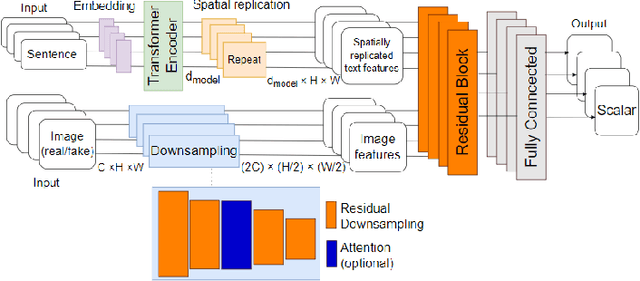
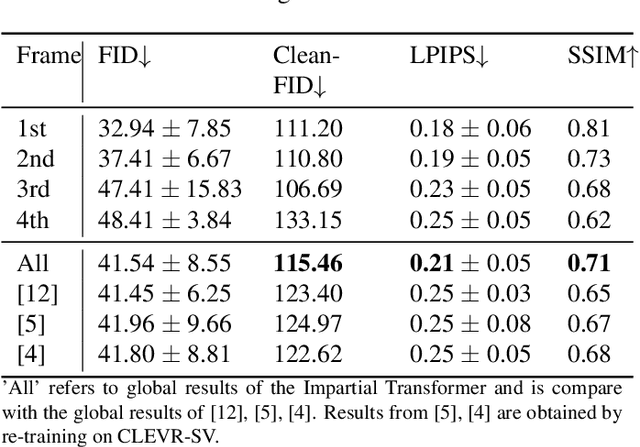
Story Visualization is an advanced task of computed vision that targets sequential image synthesis, where the generated samples need to be realistic, faithful to their conditioning and sequentially consistent. Our work proposes a novel architectural and training approach: the Impartial Transformer achieves both text-relevant plausible scenes and sequential consistency utilizing as few trainable parameters as possible. This enhancement is even able to handle synthesis of 'hard' samples with occluded objects, achieving improved evaluation metrics comparing to past approaches.
Classification of Luminal Subtypes in Full Mammogram Images Using Transfer Learning
Jan 23, 2023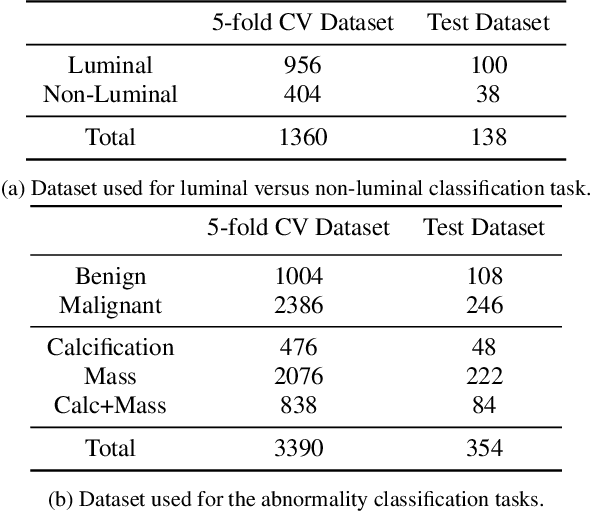
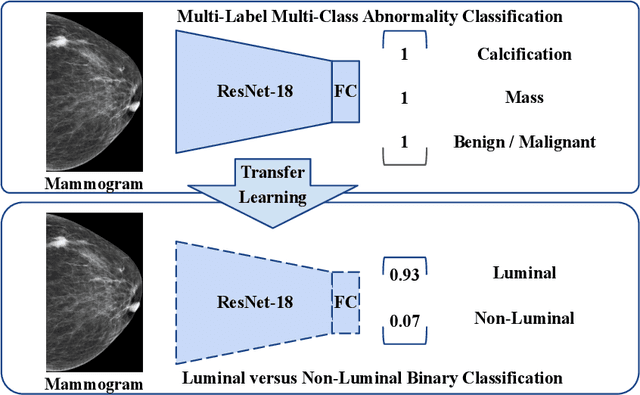
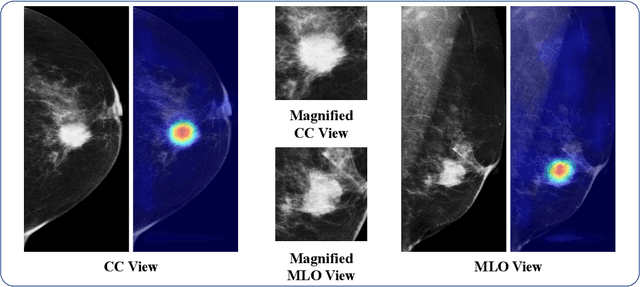
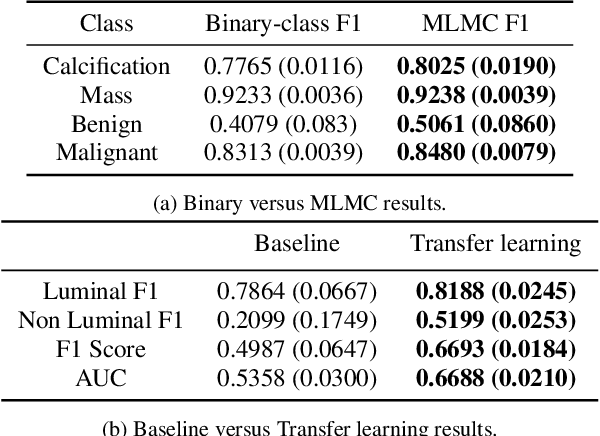
Automatic identification of patients with luminal and non-luminal subtypes during a routine mammography screening can support clinicians in streamlining breast cancer therapy planning. Recent machine learning techniques have shown promising results in molecular subtype classification in mammography; however, they are highly dependent on pixel-level annotations, handcrafted, and radiomic features. In this work, we provide initial insights into the luminal subtype classification in full mammogram images trained using only image-level labels. Transfer learning is applied from a breast abnormality classification task, to finetune a ResNet-18-based luminal versus non-luminal subtype classification task. We present and compare our results on the publicly available CMMD dataset and show that our approach significantly outperforms the baseline classifier by achieving a mean AUC score of 0.6688 and a mean F1 score of 0.6693 on the test dataset. The improvement over baseline is statistically significant, with a p-value of p<0.0001.
Artistic Curve Steganography Carried by Musical Audio
Jan 29, 2023
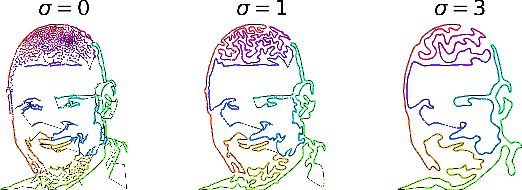
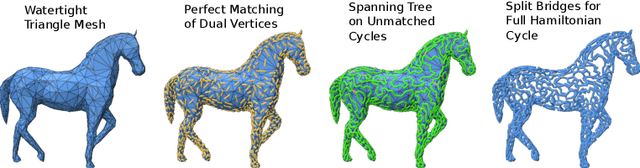
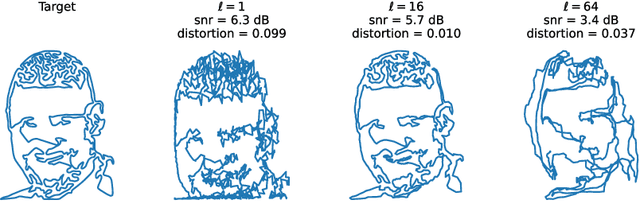
In this work, we create artistic closed loop curves that trace out images and 3D shapes, which we then hide in musical audio as a form of steganography. We use traveling salesperson art to create artistic plane loops to trace out image contours, and we use Hamiltonian cycles on triangle meshes to create artistic space loops that fill out 3D surfaces. Our embedding scheme is designed to faithfully preserve the geometry of these loops after lossy compression, while keeping their presence undetectable to the audio listener. To accomplish this, we hide each dimension of the curve in a different frequency, and we perturb a sliding window sum of the magnitude of that frequency to best match the target curve at that dimension, while hiding scale information in that frequency's phase. In the process, we exploit geometric properties of the curves to help to more effectively hide and recover them. Our scheme is simple and encoding happens efficiently with a nonnegative least squares framework, while decoding is trivial. We validate our technique quantitatively on large datasets of images and audio, and we show results of a crowd sourced listening test that validate that the hidden information is indeed unobtrusive.
Online Continual Learning via the Knowledge Invariant and Spread-out Properties
Feb 02, 2023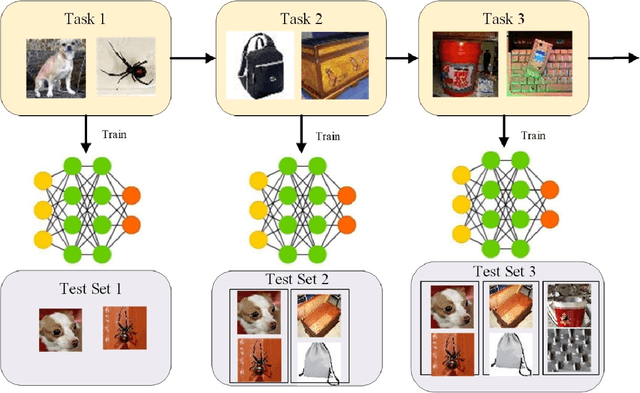
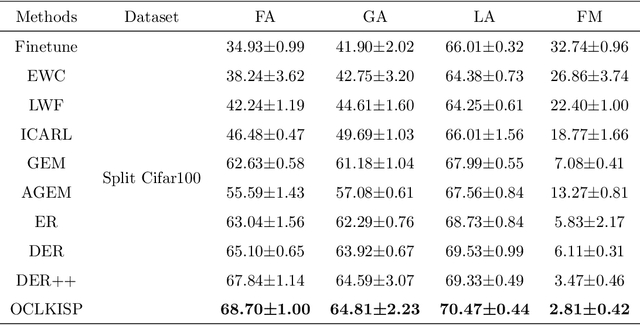
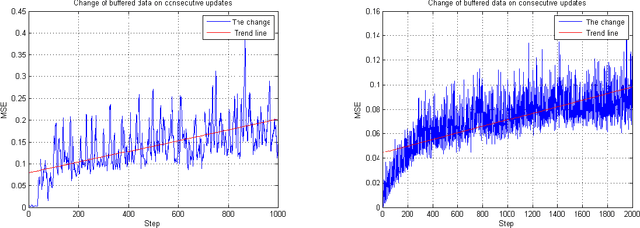
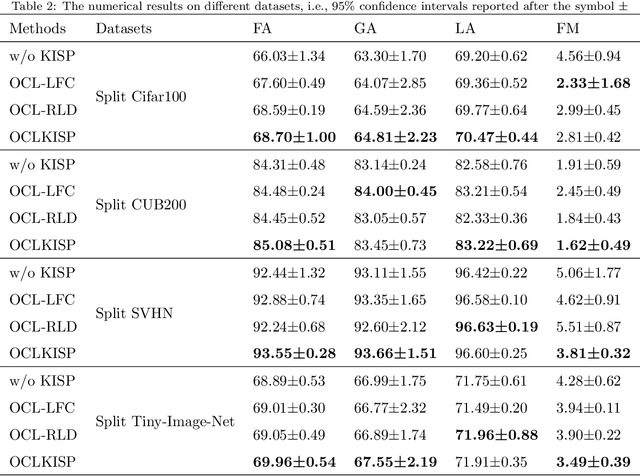
The goal of continual learning is to provide intelligent agents that are capable of learning continually a sequence of tasks using the knowledge obtained from previous tasks while performing well on prior tasks. However, a key challenge in this continual learning paradigm is catastrophic forgetting, namely adapting a model to new tasks often leads to severe performance degradation on prior tasks. Current memory-based approaches show their success in alleviating the catastrophic forgetting problem by replaying examples from past tasks when new tasks are learned. However, these methods are infeasible to transfer the structural knowledge from previous tasks i.e., similarities or dissimilarities between different instances. Furthermore, the learning bias between the current and prior tasks is also an urgent problem that should be solved. In this work, we propose a new method, named Online Continual Learning via the Knowledge Invariant and Spread-out Properties (OCLKISP), in which we constrain the evolution of the embedding features via Knowledge Invariant and Spread-out Properties (KISP). Thus, we can further transfer the inter-instance structural knowledge of previous tasks while alleviating the forgetting due to the learning bias. We empirically evaluate our proposed method on four popular benchmarks for continual learning: Split CIFAR 100, Split SVHN, Split CUB200 and Split Tiny-Image-Net. The experimental results show the efficacy of our proposed method compared to the state-of-the-art continual learning algorithms.
* 30 pages
Boosting 3D Object Detection via Object-Focused Image Fusion
Jul 21, 2022
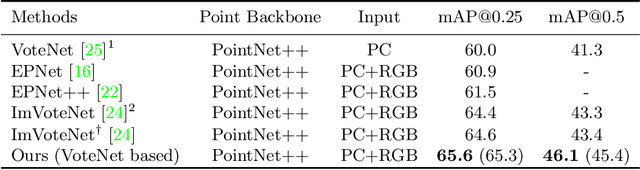

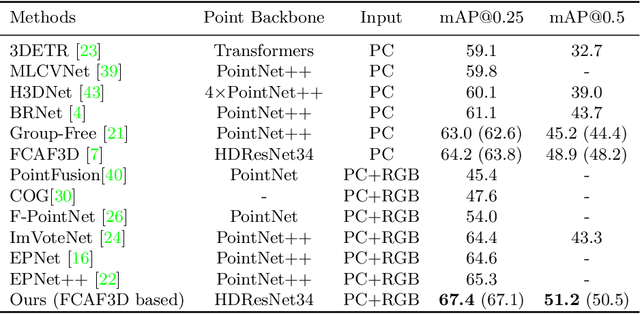
3D object detection has achieved remarkable progress by taking point clouds as the only input. However, point clouds often suffer from incomplete geometric structures and the lack of semantic information, which makes detectors hard to accurately classify detected objects. In this work, we focus on how to effectively utilize object-level information from images to boost the performance of point-based 3D detector. We present DeMF, a simple yet effective method to fuse image information into point features. Given a set of point features and image feature maps, DeMF adaptively aggregates image features by taking the projected 2D location of the 3D point as reference. We evaluate our method on the challenging SUN RGB-D dataset, improving state-of-the-art results by a large margin (+2.1 mAP@0.25 and +2.3mAP@0.5). Code is available at https://github.com/haoy945/DeMF.
Harmonizer: Learning to Perform White-Box Image and Video Harmonization
Jul 04, 2022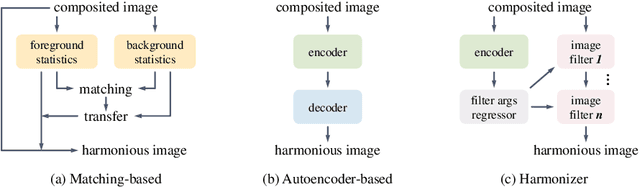
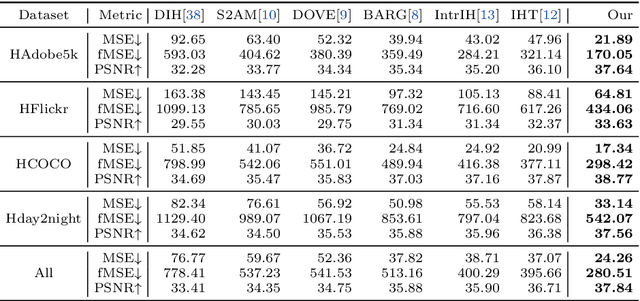
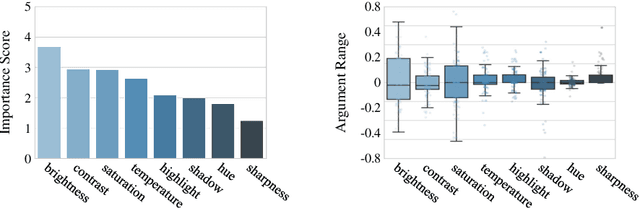
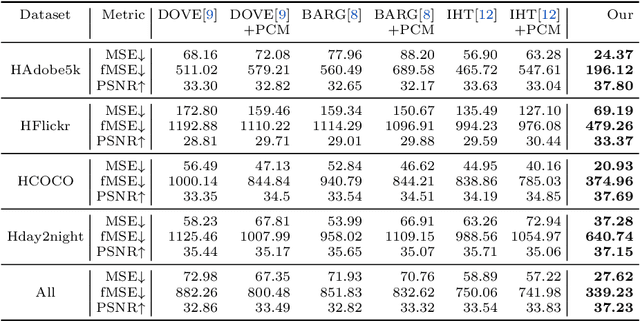
Recent works on image harmonization solve the problem as a pixel-wise image translation task via large autoencoders. They have unsatisfactory performances and slow inference speeds when dealing with high-resolution images. In this work, we observe that adjusting the input arguments of basic image filters, e.g., brightness and contrast, is sufficient for humans to produce realistic images from the composite ones. Hence, we frame image harmonization as an image-level regression problem to learn the arguments of the filters that humans use for the task. We present a Harmonizer framework for image harmonization. Unlike prior methods that are based on black-box autoencoders, Harmonizer contains a neural network for filter argument prediction and several white-box filters (based on the predicted arguments) for image harmonization. We also introduce a cascade regressor and a dynamic loss strategy for Harmonizer to learn filter arguments more stably and precisely. Since our network only outputs image-level arguments and the filters we used are efficient, Harmonizer is much lighter and faster than existing methods. Comprehensive experiments demonstrate that Harmonizer surpasses existing methods notably, especially with high-resolution inputs. Finally, we apply Harmonizer to video harmonization, which achieves consistent results across frames and 56 fps at 1080P resolution. Code and models are available at: https://github.com/ZHKKKe/Harmonizer.
Fine-Grained Hard Negative Mining: Generalizing Mitosis Detection with a Fifth of the MIDOG 2022 Dataset
Jan 03, 2023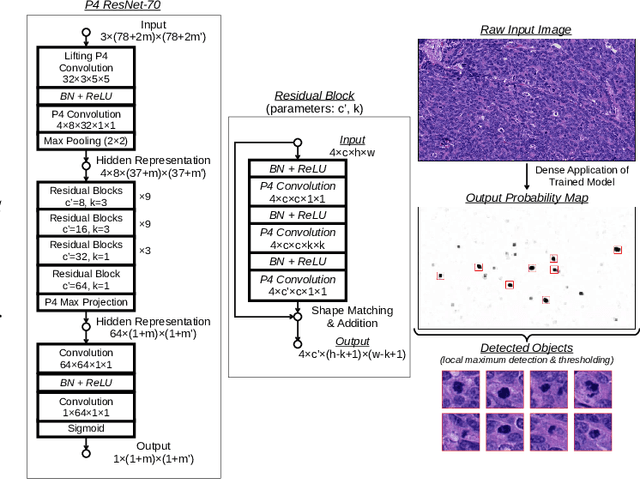
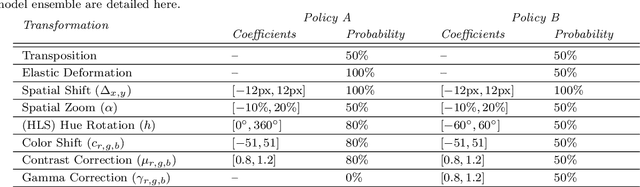
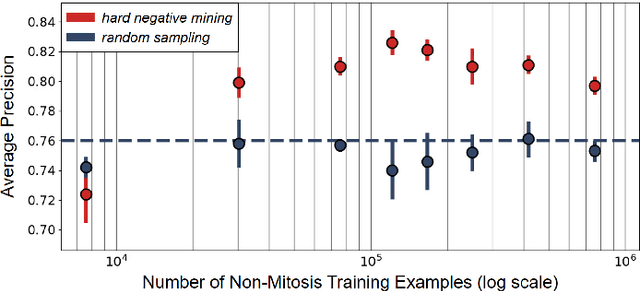
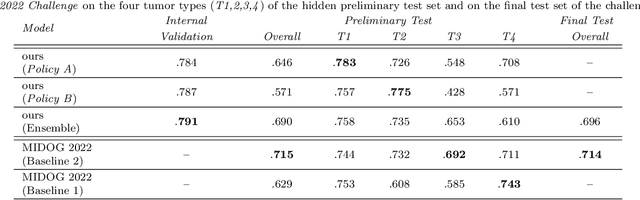
Making histopathology image classifiers robust to a wide range of real-world variability is a challenging task. Here, we describe a candidate deep learning solution for the Mitosis Domain Generalization Challenge 2022 (MIDOG) to address the problem of generalization for mitosis detection in images of hematoxylin-eosin-stained histology slides under high variability (scanner, tissue type and species variability). Our approach consists in training a rotation-invariant deep learning model using aggressive data augmentation with a training set enriched with hard negative examples and automatically selected negative examples from the unlabeled part of the challenge dataset. To optimize the performance of our models, we investigated a hard negative mining regime search procedure that lead us to train our best model using a subset of image patches representing 19.6% of our training partition of the challenge dataset. Our candidate model ensemble achieved a F1-score of .697 on the final test set after automated evaluation on the challenge platform, achieving the third best overall score in the MIDOG 2022 Challenge.