 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Information-Theoretic Approach to Transferability in Task Transfer Learning
Dec 20, 2022
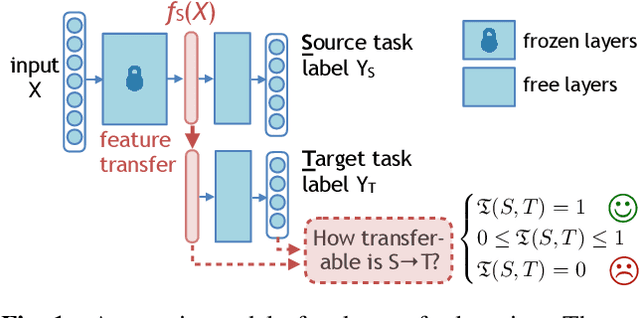
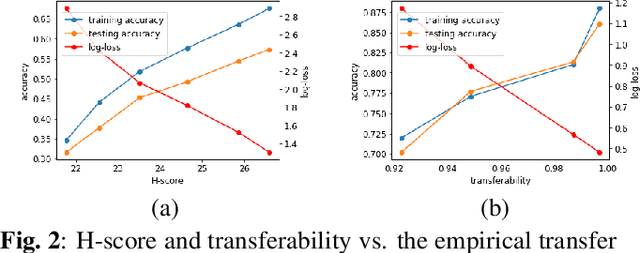
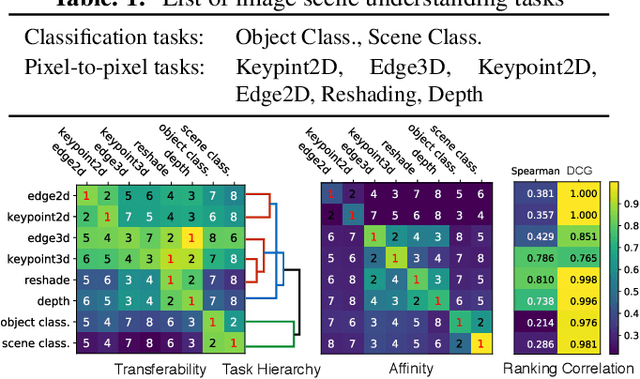
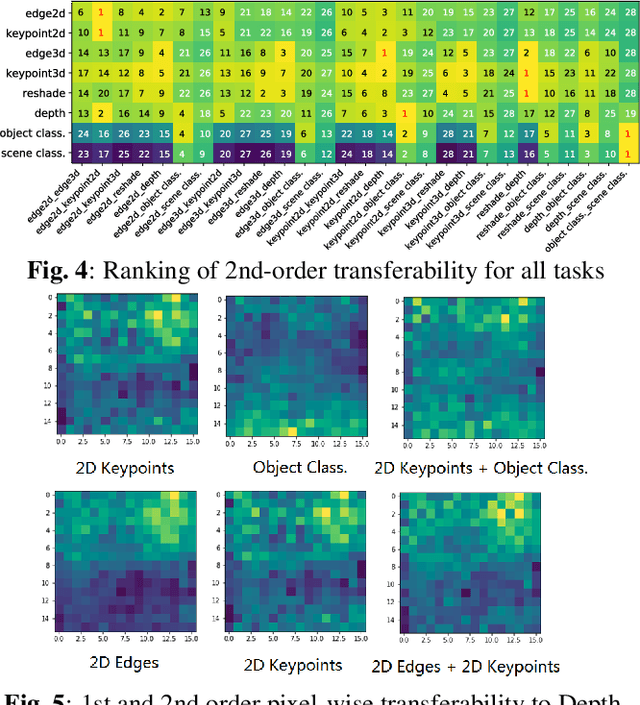
Task transfer learning is a popular technique in image processing applications that uses pre-trained models to reduce the supervision cost of related tasks. An important question is to determine task transferability, i.e. given a common input domain, estimating to what extent representations learned from a source task can help in learning a target task. Typically, transferability is either measured experimentally or inferred through task relatedness, which is often defined without a clear operational meaning. In this paper, we present a novel metric, H-score, an easily-computable evaluation function that estimates the performance of transferred representations from one task to another in classification problems using statistical and information theoretic principles. Experiments on real image data show that our metric is not only consistent with the empirical transferability measurement, but also useful to practitioners in applications such as source model selection and task transfer curriculum learning.
BuyTheDips: PathLoss for improved topology-preserving deep learning-based image segmentation
Jul 23, 2022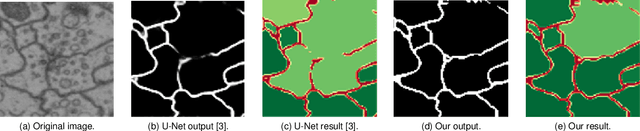
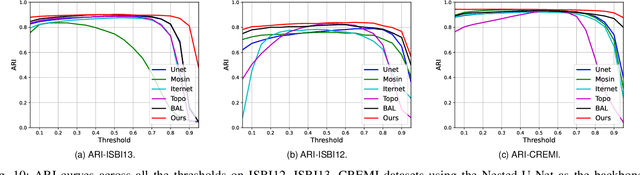
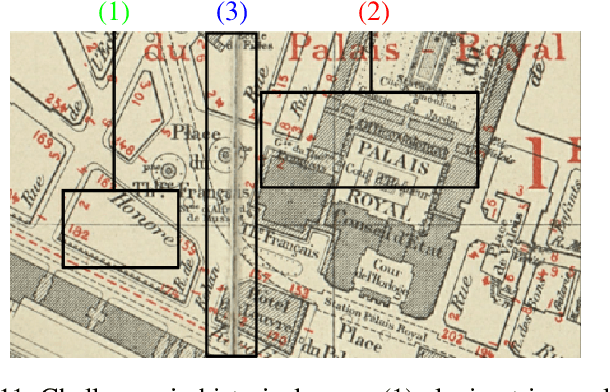
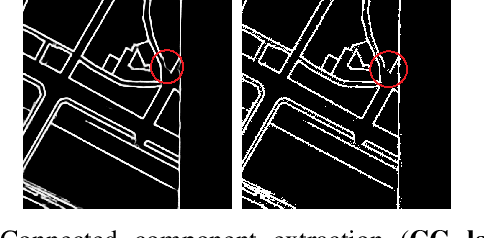
Capturing the global topology of an image is essential for proposing an accurate segmentation of its domain. However, most of existing segmentation methods do not preserve the initial topology of the given input, which is detrimental for numerous downstream object-based tasks. This is all the more true for deep learning models which most work at local scales. In this paper, we propose a new topology-preserving deep image segmentation method which relies on a new leakage loss: the Pathloss. Our method is an extension of the BALoss [1], in which we want to improve the leakage detection for better recovering the closeness property of the image segmentation. This loss allows us to correctly localize and fix the critical points (a leakage in the boundaries) that could occur in the predictions, and is based on a shortest-path search algorithm. This way, loss minimization enforces connectivity only where it is necessary and finally provides a good localization of the boundaries of the objects in the image. Moreover, according to our research, our Pathloss learns to preserve stronger elongated structure compared to methods without using topology-preserving loss. Training with our topological loss function, our method outperforms state-of-the-art topology-aware methods on two representative datasets of different natures: Electron Microscopy and Historical Map.
SGDraw: Scene Graph Drawing Interface Using Object-Oriented Representation
Nov 30, 2022
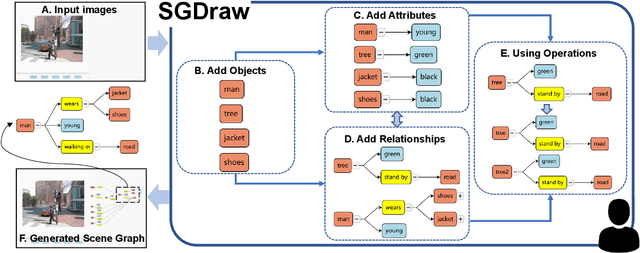
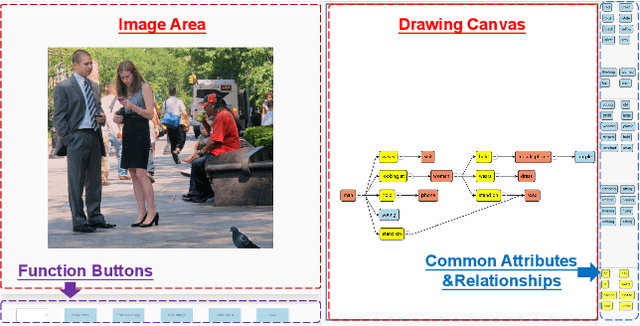
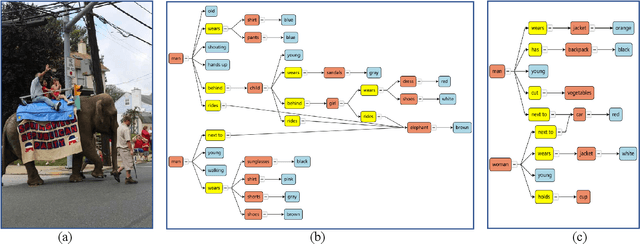
Scene understanding is an essential and challenging task in computer vision. To provide the visually fundamental graphical structure of an image, the scene graph has received increased attention due to its powerful semantic representation. However, it is difficult to draw a proper scene graph for image retrieval, image generation, and multi-modal applications. The conventional scene graph annotation interface is not easy to use in image annotations, and the automatic scene graph generation approaches using deep neural networks are prone to generate redundant content while disregarding details. In this work, we propose SGDraw, a scene graph drawing interface using object-oriented scene graph representation to help users draw and edit scene graphs interactively. For the proposed object-oriented representation, we consider the objects, attributes, and relationships of objects as a structural unit. SGDraw provides a web-based scene graph annotation and generation tool for scene understanding applications. To verify the effectiveness of the proposed interface, we conducted a comparison study with the conventional tool and the user experience study. The results show that SGDraw can help generate scene graphs with richer details and describe the images more accurately than traditional bounding box annotations. We believe the proposed SGDraw can be useful in various vision tasks, such as image retrieval and generation.
Adaptive adversarial training method for improving multi-scale GAN based on generalization bound theory
Nov 30, 2022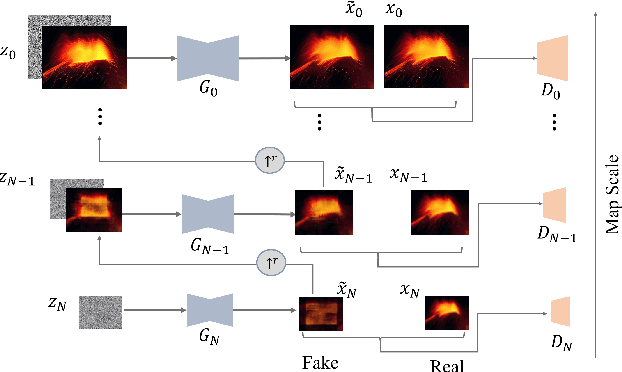

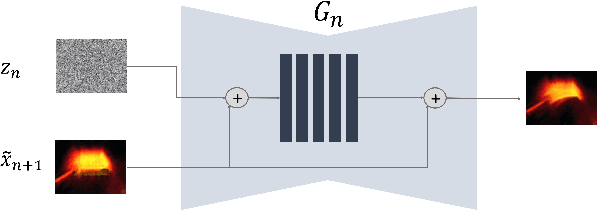

In recent years, multi-scale generative adversarial networks (GANs) have been proposed to build generalized image processing models based on single sample. Constraining on the sample size, multi-scale GANs have much difficulty converging to the global optimum, which ultimately leads to limitations in their capabilities. In this paper, we pioneered the introduction of PAC-Bayes generalized bound theory into the training analysis of specific models under different adversarial training methods, which can obtain a non-vacuous upper bound on the generalization error for the specified multi-scale GAN structure. Based on the drastic changes we found of the generalization error bound under different adversarial attacks and different training states, we proposed an adaptive training method which can greatly improve the image manipulation ability of multi-scale GANs. The final experimental results show that our adaptive training method in this paper has greatly contributed to the improvement of the quality of the images generated by multi-scale GANs on several image manipulation tasks. In particular, for the image super-resolution restoration task, the multi-scale GAN model trained by the proposed method achieves a 100% reduction in natural image quality evaluator (NIQE) and a 60% reduction in root mean squared error (RMSE), which is better than many models trained on large-scale datasets.
ESVIO: Event-based Stereo Visual Inertial Odometry
Dec 26, 2022
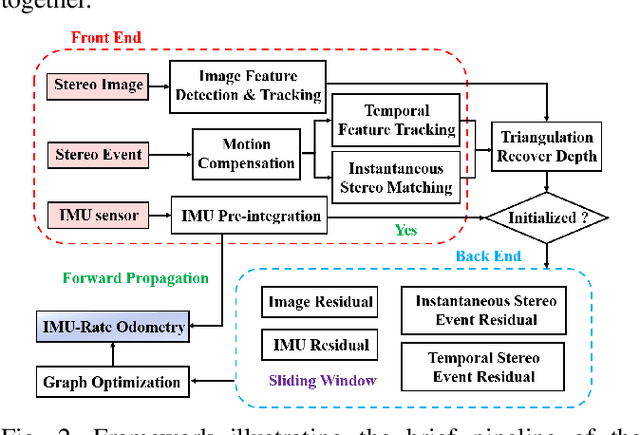
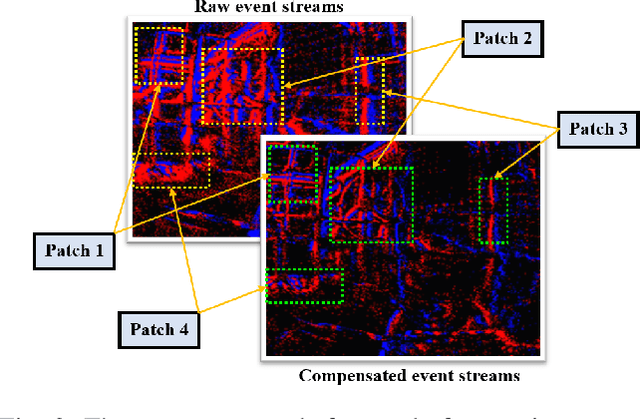
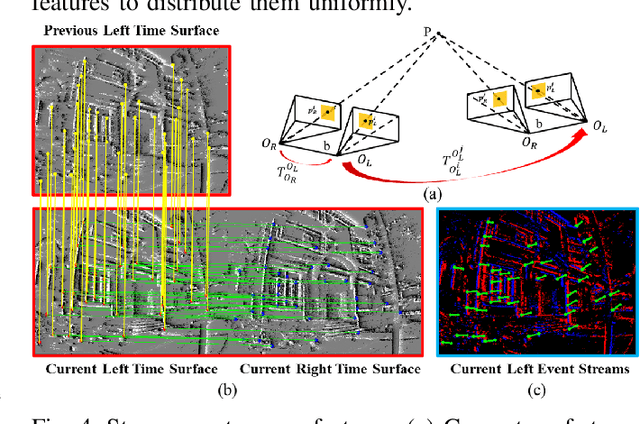
Event cameras that asynchronously output low-latency event streams provide great opportunities for state estimation under challenging situations. Despite event-based visual odometry having been extensively studied in recent years, most of them are based on monocular and few research on stereo event vision. In this paper, we present ESVIO, the first event-based stereo visual-inertial odometry, which leverages the complementary advantages of event streams, standard images and inertial measurements. Our proposed pipeline achieves temporal tracking and instantaneous matching between consecutive stereo event streams, thereby obtaining robust state estimation. In addition, the motion compensation method is designed to emphasize the edge of scenes by warping each event to reference moments with IMU and ESVIO back-end. We validate that both ESIO (purely event-based) and ESVIO (event with image-aided) have superior performance compared with other image-based and event-based baseline methods on public and self-collected datasets. Furthermore, we use our pipeline to perform onboard quadrotor flights under low-light environments. A real-world large-scale experiment is also conducted to demonstrate long-term effectiveness. We highlight that this work is a real-time, accurate system that is aimed at robust state estimation under challenging environments.
TempSAL -- Uncovering Temporal Information for Deep Saliency Prediction
Jan 05, 2023


Deep saliency prediction algorithms complement the object recognition features, they typically rely on additional information, such as scene context, semantic relationships, gaze direction, and object dissimilarity. However, none of these models consider the temporal nature of gaze shifts during image observation. We introduce a novel saliency prediction model that learns to output saliency maps in sequential time intervals by exploiting human temporal attention patterns. Our approach locally modulates the saliency predictions by combining the learned temporal maps. Our experiments show that our method outperforms the state-of-the-art models, including a multi-duration saliency model, on the SALICON benchmark. Our code will be publicly available on GitHub.
TinyMIM: An Empirical Study of Distilling MIM Pre-trained Models
Jan 03, 2023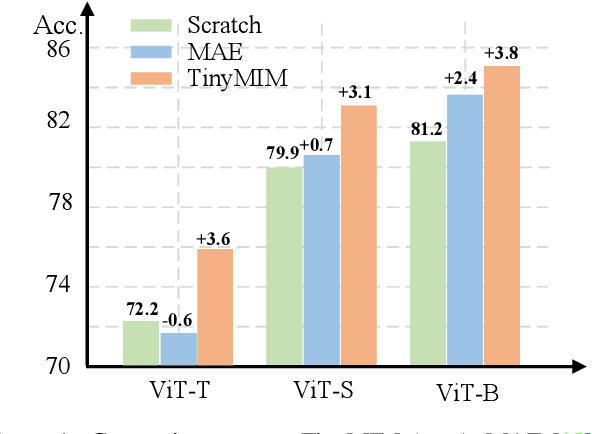
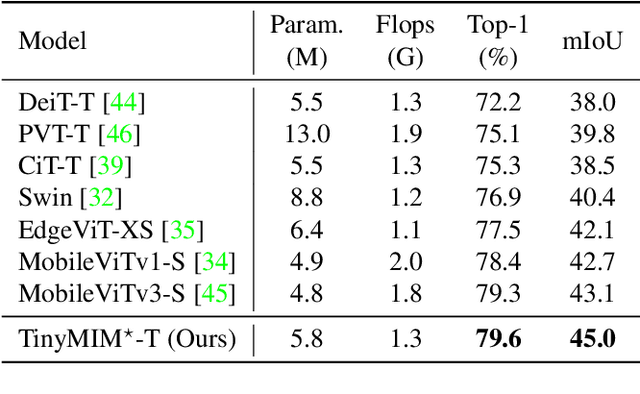
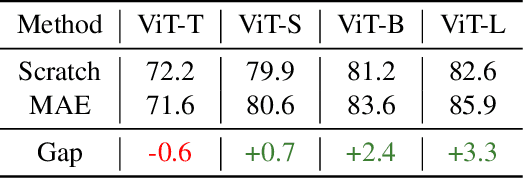
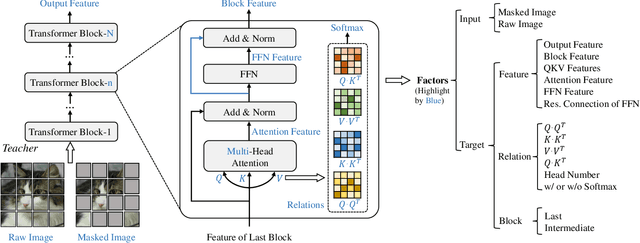
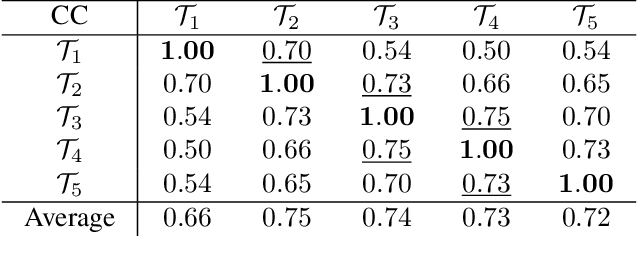
Masked image modeling (MIM) performs strongly in pre-training large vision Transformers (ViTs). However, small models that are critical for real-world applications cannot or only marginally benefit from this pre-training approach. In this paper, we explore distillation techniques to transfer the success of large MIM-based pre-trained models to smaller ones. We systematically study different options in the distillation framework, including distilling targets, losses, input, network regularization, sequential distillation, etc, revealing that: 1) Distilling token relations is more effective than CLS token- and feature-based distillation; 2) An intermediate layer of the teacher network as target perform better than that using the last layer when the depth of the student mismatches that of the teacher; 3) Weak regularization is preferred; etc. With these findings, we achieve significant fine-tuning accuracy improvements over the scratch MIM pre-training on ImageNet-1K classification, using all the ViT-Tiny, ViT-Small, and ViT-base models, with +4.2%/+2.4%/+1.4% gains, respectively. Our TinyMIM model of base size achieves 52.2 mIoU in AE20K semantic segmentation, which is +4.1 higher than the MAE baseline. Our TinyMIM model of tiny size achieves 79.6% top-1 accuracy on ImageNet-1K image classification, which sets a new record for small vision models of the same size and computation budget. This strong performance suggests an alternative way for developing small vision Transformer models, that is, by exploring better training methods rather than introducing inductive biases into architectures as in most previous works. Code is available at https://github.com/OliverRensu/TinyMIM.
Learning Dense Visual Descriptors using Image Augmentations for Robot Manipulation Tasks
Sep 12, 2022

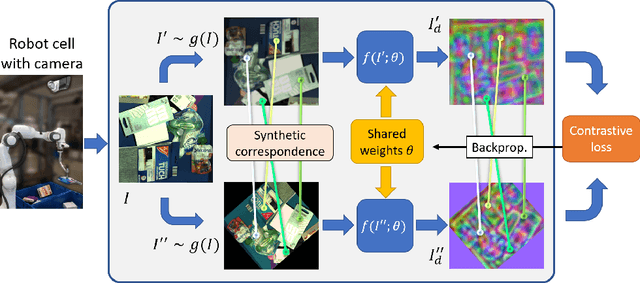

We propose a self-supervised training approach for learning view-invariant dense visual descriptors using image augmentations. Unlike existing works, which often require complex datasets, such as registered RGBD sequences, we train on an unordered set of RGB images. This allows for learning from a single camera view, e.g., in an existing robotic cell with a fix-mounted camera. We create synthetic views and dense pixel correspondences using data augmentations. We find our descriptors are competitive to the existing methods, despite the simpler data recording and setup requirements. We show that training on synthetic correspondences provides descriptor consistency across a broad range of camera views. We compare against training with geometric correspondence from multiple views and provide ablation studies. We also show a robotic bin-picking experiment using descriptors learned from a fix-mounted camera for defining grasp preferences.
A Systematic Review of Green AI
Jan 26, 2023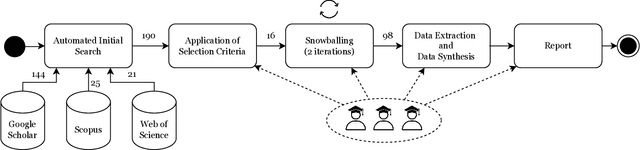
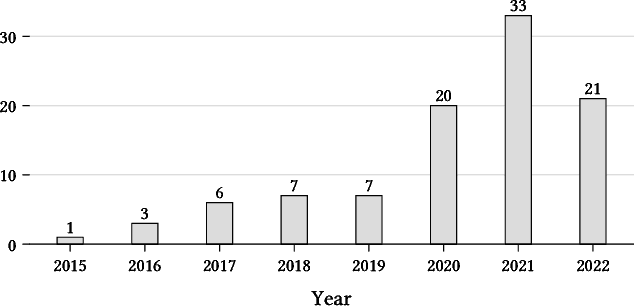
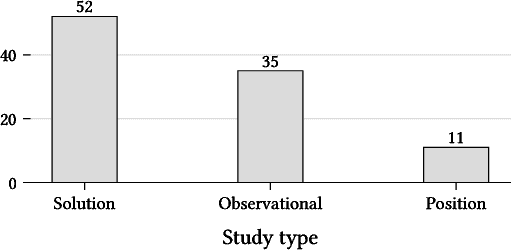
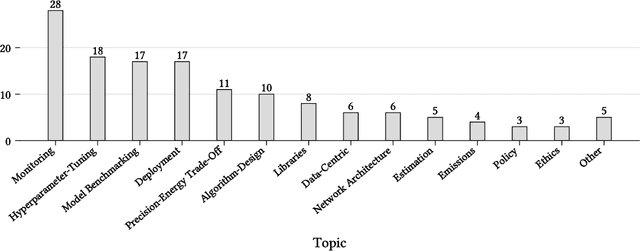
With the ever-growing adoption of AI-based systems, the carbon footprint of AI is no longer negligible. AI researchers and practitioners are therefore urged to hold themselves accountable for the carbon emissions of the AI models they design and use. This led in recent years to the appearance of researches tackling AI environmental sustainability, a field referred to as Green AI. Despite the rapid growth of interest in the topic, a comprehensive overview of Green AI research is to date still missing. To address this gap, in this paper, we present a systematic review of the Green AI literature. From the analysis of 98 primary studies, different patterns emerge. The topic experienced a considerable growth from 2020 onward. Most studies consider monitoring AI model footprint, tuning hyperparameters to improve model sustainability, or benchmarking models. A mix of position papers, observational studies, and solution papers are present. Most papers focus on the training phase, are algorithm-agnostic or study neural networks, and use image data. Laboratory experiments are the most common research strategy. Reported Green AI energy savings go up to 115%, with savings over 50% being rather common. Industrial parties are involved in Green AI studies, albeit most target academic readers. Green AI tool provisioning is scarce. As a conclusion, the Green AI research field results to have reached a considerable level of maturity. Therefore, from this review emerges that the time is suitable to adopt other Green AI research strategies, and port the numerous promising academic results to industrial practice.
CLIP is Also an Efficient Segmenter: A Text-Driven Approach for Weakly Supervised Semantic Segmentation
Dec 20, 2022
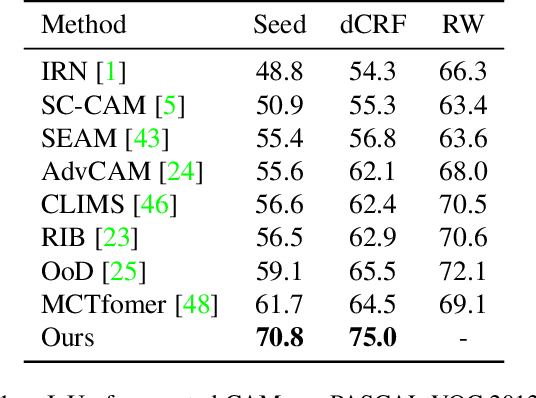
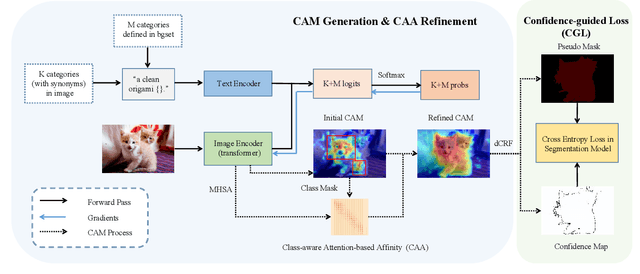
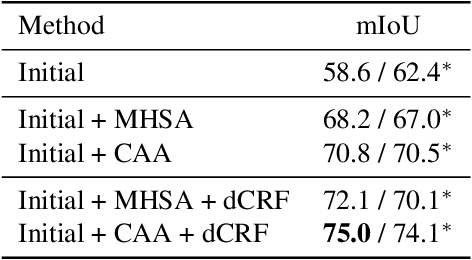
Weakly supervised semantic segmentation (WSSS) with image-level labels is a challenging task in computer vision. Mainstream approaches follow a multi-stage framework and suffer from high training costs. In this paper, we explore the potential of Contrastive Language-Image Pre-training models (CLIP) to localize different categories with only image-level labels and without any further training. To efficiently generate high-quality segmentation masks from CLIP, we propose a novel framework called CLIP-ES for WSSS. Our framework improves all three stages of WSSS with special designs for CLIP: 1) We introduce the softmax function into GradCAM and exploit the zero-shot ability of CLIP to suppress the confusion caused by non-target classes and backgrounds. Meanwhile, to take full advantage of CLIP, we re-explore text inputs under the WSSS setting and customize two text-driven strategies: sharpness-based prompt selection and synonym fusion. 2) To simplify the stage of CAM refinement, we propose a real-time class-aware attention-based affinity (CAA) module based on the inherent multi-head self-attention (MHSA) in CLIP-ViTs. 3) When training the final segmentation model with the masks generated by CLIP, we introduced a confidence-guided loss (CGL) to mitigate noise and focus on confident regions. Our proposed framework dramatically reduces the cost of training for WSSS and shows the capability of localizing objects in CLIP. Our CLIP-ES achieves SOTA performance on Pascal VOC 2012 and MS COCO 2014 while only taking 10% time of previous methods for the pseudo mask generation. Code is available at https://github.com/linyq2117/CLIP-ES.