 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Analysis of displacement compensation methods for wavelet lifting of medical 3-D thorax CT volume data
Jan 11, 2023
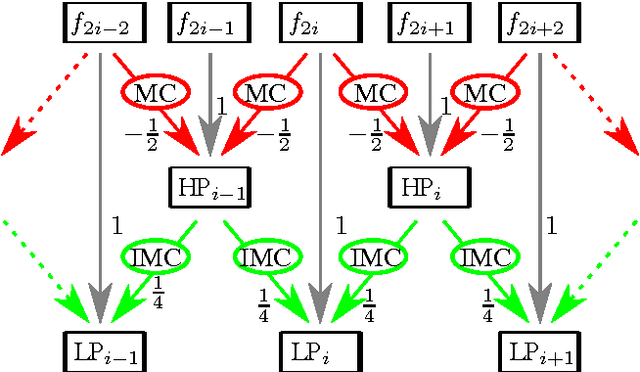
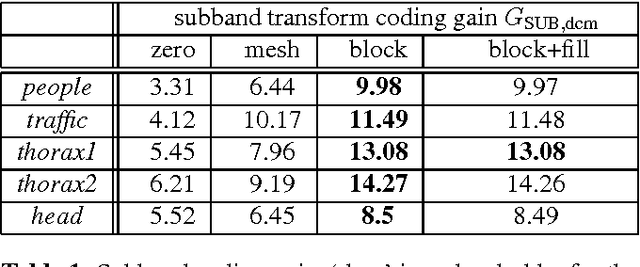
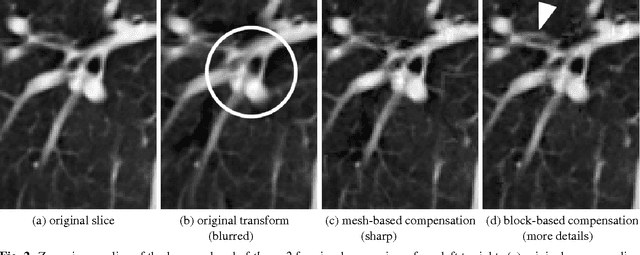
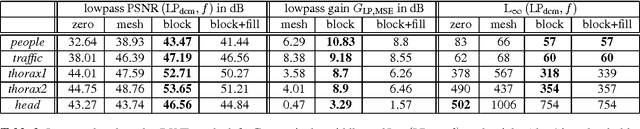
A huge advantage of the wavelet transform in image and video compression is its scalability. Wavelet-based coding of medical computed tomography (CT) data becomes more and more popular. While much effort has been spent on encoding of the wavelet coefficients, the extension of the transform by a compensation method as in video coding has not gained much attention so far. We will analyze two compensation methods for medical CT data and compare the characteristics of the displacement compensated wavelet transform with video data. We will show that for thorax CT data the transform coding gain can be improved by a factor of 2 and the quality of the lowpass band can be improved by 8 dB in terms of PSNR compared to the original transform without compensation.
Augmenting Ego-Vehicle for Traffic Near-Miss and Accident Classification Dataset using Manipulating Conditional Style Translation
Jan 06, 2023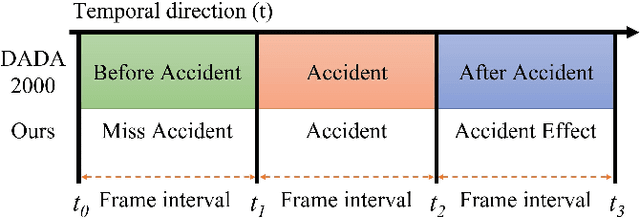
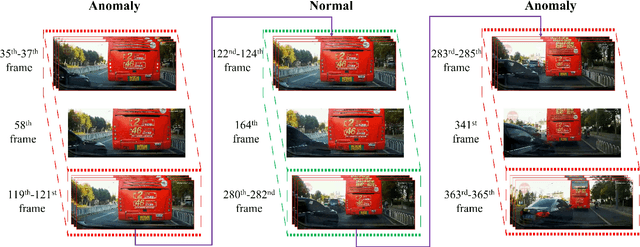

To develop the advanced self-driving systems, many researchers are focusing to alert all possible traffic risk cases from closed-circuit television (CCTV) and dashboard-mounted cameras. Most of these methods focused on identifying frame-by-frame in which an anomaly has occurred, but they are unrealized, which road traffic participant can cause ego-vehicle leading into collision because of available annotation dataset only to detect anomaly on traffic video. Near-miss is one type of accident and can be defined as a narrowly avoided accident. However, there is no difference between accident and near-miss at the time before the accident happened, so our contribution is to redefine the accident definition and re-annotate the accident inconsistency on DADA-2000 dataset together with near-miss. By extending the start and end time of accident duration, our annotation can precisely cover all ego-motions during an incident and consistently classify all possible traffic risk accidents including near-miss to give more critical information for real-world driving assistance systems. The proposed method integrates two different components: conditional style translation (CST) and separable 3-dimensional convolutional neural network (S3D). CST architecture is derived by unsupervised image-to-image translation networks (UNIT) used for augmenting the re-annotation DADA-2000 dataset to increase the number of traffic risk accident videos and to generalize the performance of video classification model on different types of conditions while S3D is useful for video classification to prove dataset re-annotation consistency. In evaluation, the proposed method achieved a significant improvement result by 10.25% positive margin from the baseline model for accuracy on cross-validation analysis.
* 8 pages, conference
Understanding Masked Image Modeling via Learning Occlusion Invariant Feature
Aug 08, 2022



Recently, Masked Image Modeling (MIM) achieves great success in self-supervised visual recognition. However, as a reconstruction-based framework, it is still an open question to understand how MIM works, since MIM appears very different from previous well-studied siamese approaches such as contrastive learning. In this paper, we propose a new viewpoint: MIM implicitly learns occlusion-invariant features, which is analogous to other siamese methods while the latter learns other invariance. By relaxing MIM formulation into an equivalent siamese form, MIM methods can be interpreted in a unified framework with conventional methods, among which only a) data transformations, i.e. what invariance to learn, and b) similarity measurements are different. Furthermore, taking MAE (He et al.) as a representative example of MIM, we empirically find the success of MIM models relates a little to the choice of similarity functions, but the learned occlusion invariant feature introduced by masked image -- it turns out to be a favored initialization for vision transformers, even though the learned feature could be less semantic. We hope our findings could inspire researchers to develop more powerful self-supervised methods in computer vision community.
Unifying Synergies between Self-supervised Learning and Dynamic Computation
Jan 22, 2023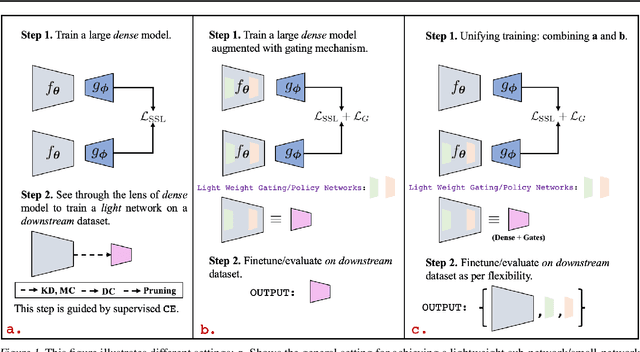
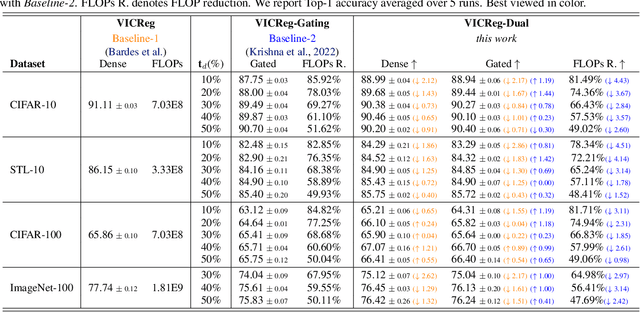

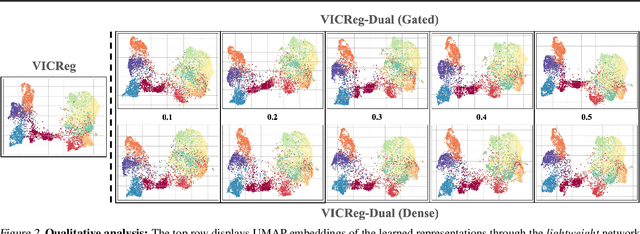
Self-supervised learning (SSL) approaches have made major strides forward by emulating the performance of their supervised counterparts on several computer vision benchmarks. This, however, comes at a cost of substantially larger model sizes, and computationally expensive training strategies, which eventually lead to larger inference times making it impractical for resource constrained industrial settings. Techniques like knowledge distillation (KD), dynamic computation (DC), and pruning are often used to obtain a lightweight sub-network, which usually involves multiple epochs of fine-tuning of a large pre-trained model, making it more computationally challenging. In this work we propose a novel perspective on the interplay between SSL and DC paradigms that can be leveraged to simultaneously learn a dense and gated (sparse/lightweight) sub-network from scratch offering a good accuracy-efficiency trade-off, and therefore yielding a generic and multi-purpose architecture for application specific industrial settings. Our study overall conveys a constructive message: exhaustive experiments on several image classification benchmarks: CIFAR-10, STL-10, CIFAR-100, and ImageNet-100, demonstrates that the proposed training strategy provides a dense and corresponding sparse sub-network that achieves comparable (on-par) performance compared with the vanilla self-supervised setting, but at a significant reduction in computation in terms of FLOPs under a range of target budgets.
The most general manner to injectively align true and predicted segments
Dec 27, 2022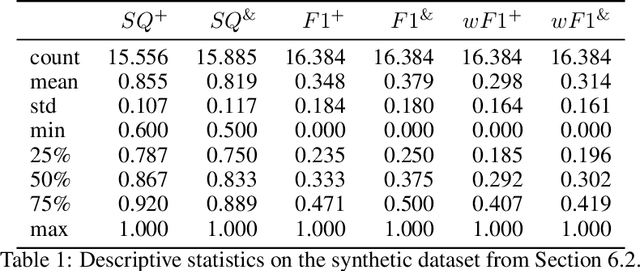
Kirilov et al (2019) develop a metric, called Panoptic Quality (PQ), to evaluate image segmentation methods. The metric is based on a confusion table, and compares a predicted to a ground truth segmentation. The only non straightforward part in this comparison is to align the segments in the two segmentations. A metric only works well if that alignment is a partial bijection. Kirilov et al (2019) list 3 desirable properties for a definition of alignment: it should be simple, interpretable and effectively computable. There are many definitions guaranteeing a partial bijection and these 3 properties. We present the weakest: one that is both sufficient and necessary to guarantee that the alignment is a partial bijection. This new condition is effectively computable and natural. It simply says that the number of correctly predicted elements (in image segmentation, the pixels) should be larger than the number of missed, and larger than the number of spurious elements. This is strictly weaker than the proposal in Kirilov et al (2019). In formulas, instead of |TP|> |FN\textbar| + |FP|, the weaker condition requires that |TP|> |FN| and |TP| > |FP|. We evaluate the new alignment condition theoretically and empirically.
A Constrained Deformable Convolutional Network for Efficient Single Image Dynamic Scene Blind Deblurring with Spatially-Variant Motion Blur Kernels Estimation
Aug 23, 2022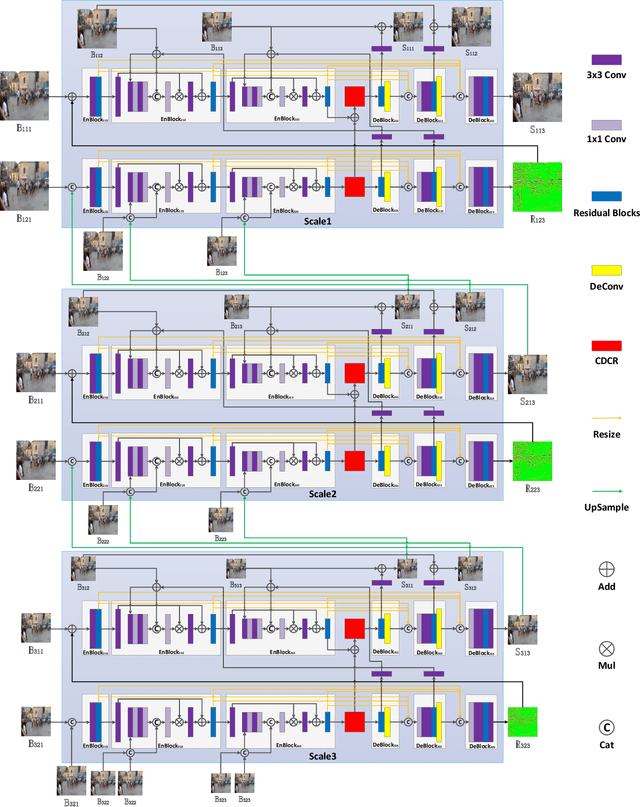
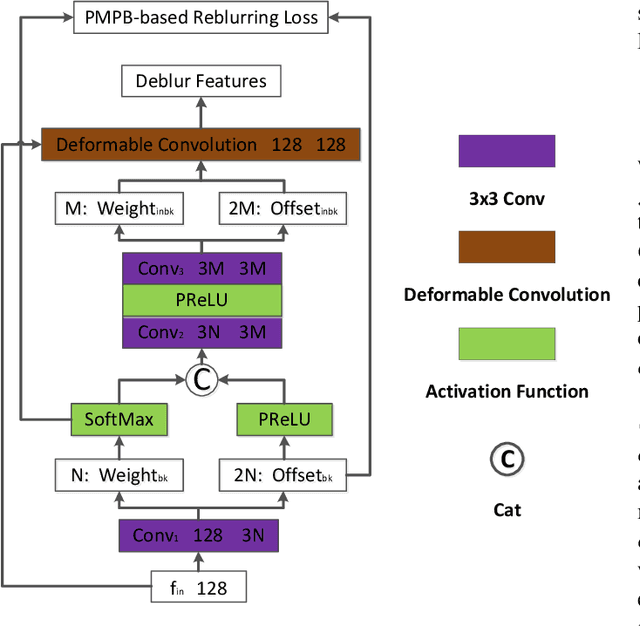

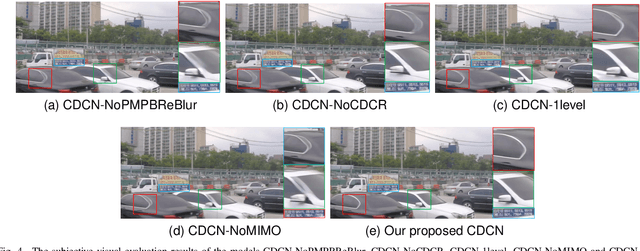
Most existing deep-learning-based single image dynamic scene blind deblurring (SIDSBD) methods usually design deep networks to directly remove the spatially-variant motion blurs from one inputted motion blurred image, without blur kernels estimation. In this paper, inspired by the Projective Motion Path Blur (PMPB) model and deformable convolution, we propose a novel constrained deformable convolutional network (CDCN) for efficient single image dynamic scene blind deblurring, which simultaneously achieves accurate spatially-variant motion blur kernels estimation and the high-quality image restoration from only one observed motion blurred image. In our proposed CDCN, we first construct a novel multi-scale multi-level multi-input multi-output (MSML-MIMO) encoder-decoder architecture for more powerful features extraction ability. Second, different from the DLVBD methods that use multiple consecutive frames, a novel constrained deformable convolution reblurring (CDCR) strategy is proposed, in which the deformable convolution is first applied to blurred features of the inputted single motion blurred image for learning the sampling points of motion blur kernel of each pixel, which is similar to the estimation of the motion density function of the camera shake in the PMPB model, and then a novel PMPB-based reblurring loss function is proposed to constrain the learned sampling points convergence, which can make the learned sampling points match with the relative motion trajectory of each pixel better and promote the accuracy of the spatially-variant motion blur kernels estimation.
Learning with Limited Annotations: A Survey on Deep Semi-Supervised Learning for Medical Image Segmentation
Jul 28, 2022
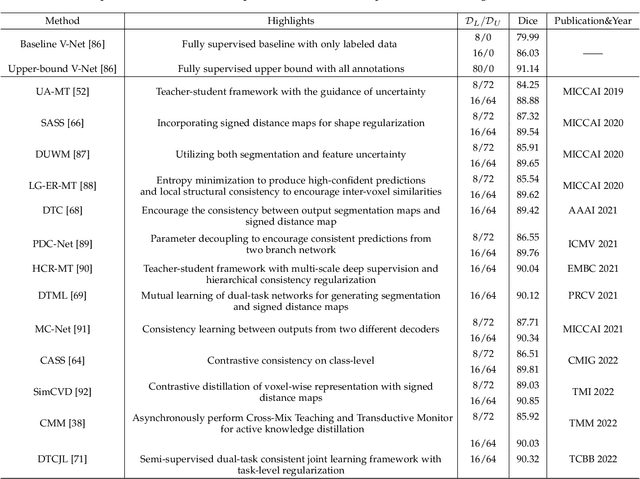
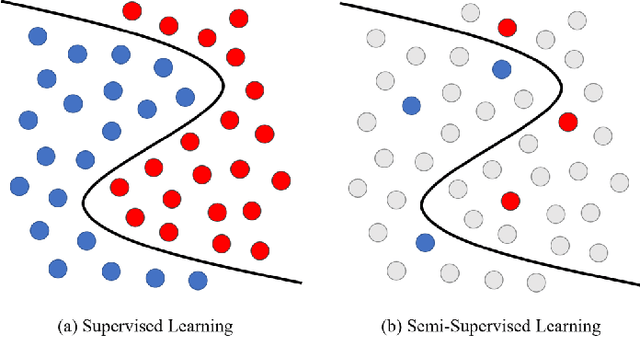
Medical image segmentation is a fundamental and critical step in many image-guided clinical approaches. Recent success of deep learning-based segmentation methods usually relies on a large amount of labeled data, which is particularly difficult and costly to obtain especially in the medical imaging domain where only experts can provide reliable and accurate annotations. Semi-supervised learning has emerged as an appealing strategy and been widely applied to medical image segmentation tasks to train deep models with limited annotations. In this paper, we present a comprehensive review of recently proposed semi-supervised learning methods for medical image segmentation and summarized both the technical novelties and empirical results. Furthermore, we analyze and discuss the limitations and several unsolved problems of existing approaches. We hope this review could inspire the research community to explore solutions for this challenge and further promote the developments in medical image segmentation field.
Automatic Classification of Single Tree Decay Stages from Combined ALS Data and Aerial Imagery using Machine Learning
Jan 04, 2023
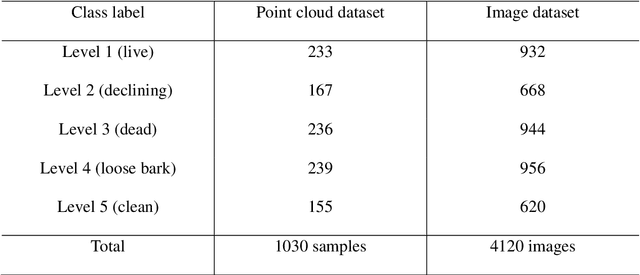

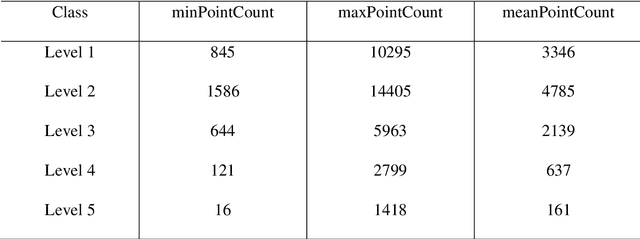
Understanding forest health is of great importance for the conservation of the integrity of forest ecosystems. The monitoring of forest health is, therefore, indispensable for the long-term conservation of forests and their sustainable management. In this regard, evaluating the amount and quality of dead wood is of utmost interest as they are favorable indicators of biodiversity. Apparently, remote sensing-based machine learning techniques have proven to be more efficient and sustainable with unprecedented accuracy in forest inventory. However, the application of these techniques is still in its infancy with respect to dead wood mapping. This study investigates for the first time the automatic classification of individual coniferous trees into five decay stages (live, declining, dead, loose bark, and clean) from combined airborne laser scanning (ALS) point clouds and CIR images using three Machine Learning methods - 3D point cloud-based deep learning (PointNet), Convolutional Neural Network (CNN), and Random Forest (RF). All models achieved promising results, reaching overall accuracy (OA) up to 90.9%, 90.6%, and 80.6% for CNN, RF, and PointNet, respectively. The experimental results reveal that the image-based approach notably outperformed the 3D point cloud-based one, while spectral image texture is of the highest relevance to the success of categorizing tree decay. Our models could therefore be used for automatic determination of single tree decay stages and landscape-wide assessment of dead wood amount and quality using modern airborne remote sensing techniques with machine/deep learning. The proposed method can contribute as an important and rigorous tool for monitoring biodiversity in forest ecosystems.
Weakly Supervised Annotations for Multi-modal Greeting Cards Dataset
Dec 01, 2022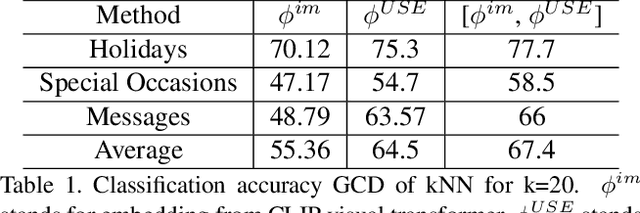
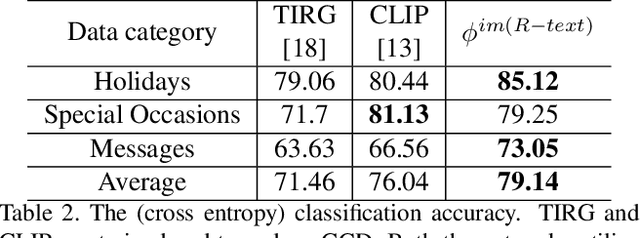
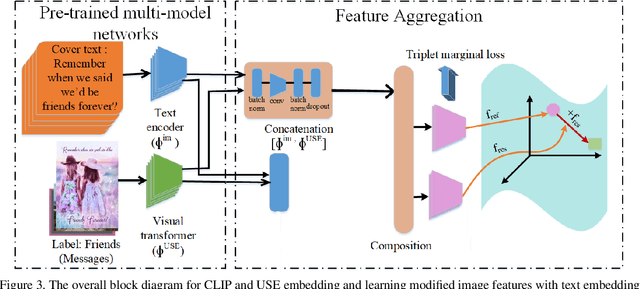

In recent years, there is a growing number of pre-trained models trained on a large corpus of data and yielding good performance on various tasks such as classifying multimodal datasets. These models have shown good performance on natural images but are not fully explored for scarce abstract concepts in images. In this work, we introduce an image/text-based dataset called Greeting Cards. Dataset (GCD) that has abstract visual concepts. In our work, we propose to aggregate features from pretrained images and text embeddings to learn abstract visual concepts from GCD. This allows us to learn the text-modified image features, which combine complementary and redundant information from the multi-modal data streams into a single, meaningful feature. Secondly, the captions for the GCD dataset are computed with the pretrained CLIP-based image captioning model. Finally, we also demonstrate that the proposed the dataset is also useful for generating greeting card images using pre-trained text-to-image generation model.
Semi-supervised GAN for Bladder Tissue Classification in Multi-Domain Endoscopic Images
Dec 21, 2022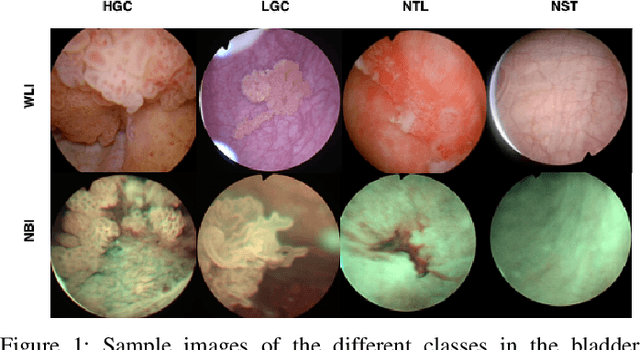
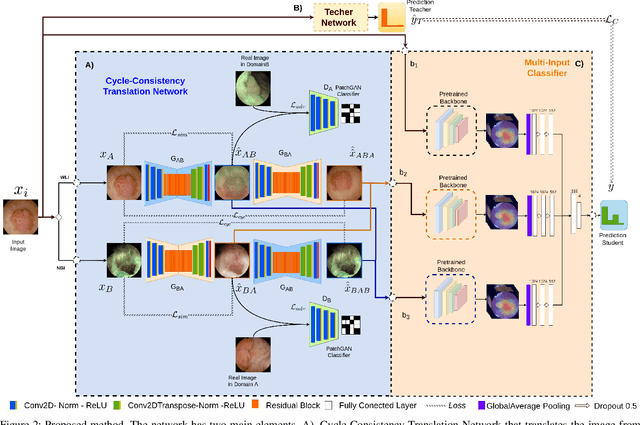
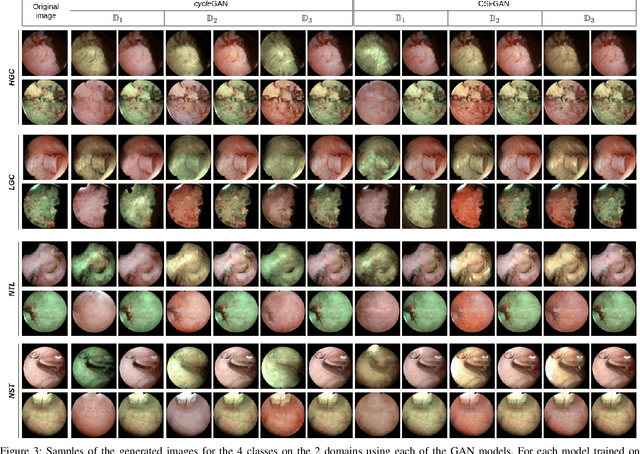
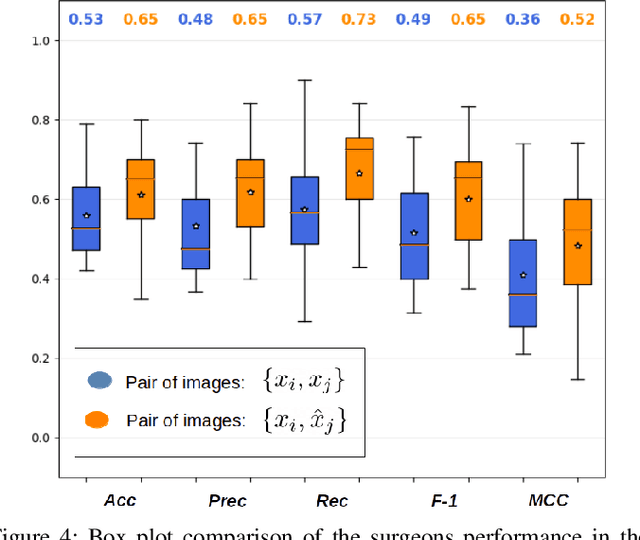
Objective: Accurate visual classification of bladder tissue during Trans-Urethral Resection of Bladder Tumor (TURBT) procedures is essential to improve early cancer diagnosis and treatment. During TURBT interventions, White Light Imaging (WLI) and Narrow Band Imaging (NBI) techniques are used for lesion detection. Each imaging technique provides diverse visual information that allows clinicians to identify and classify cancerous lesions. Computer vision methods that use both imaging techniques could improve endoscopic diagnosis. We address the challenge of tissue classification when annotations are available only in one domain, in our case WLI, and the endoscopic images correspond to an unpaired dataset, i.e. there is no exact equivalent for every image in both NBI and WLI domains. Method: We propose a semi-surprised Generative Adversarial Network (GAN)-based method composed of three main components: a teacher network trained on the labeled WLI data; a cycle-consistency GAN to perform unpaired image-to-image translation, and a multi-input student network. To ensure the quality of the synthetic images generated by the proposed GAN we perform a detailed quantitative, and qualitative analysis with the help of specialists. Conclusion: The overall average classification accuracy, precision, and recall obtained with the proposed method for tissue classification are 0.90, 0.88, and 0.89 respectively, while the same metrics obtained in the unlabeled domain (NBI) are 0.92, 0.64, and 0.94 respectively. The quality of the generated images is reliable enough to deceive specialists. Significance: This study shows the potential of using semi-supervised GAN-based classification to improve bladder tissue classification when annotations are limited in multi-domain data.