 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Recent Advances in Scene Image Representation and Classification
Jun 15, 2022
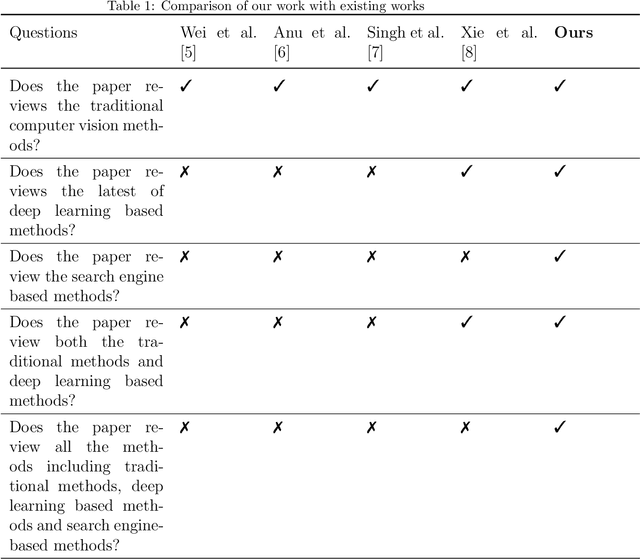
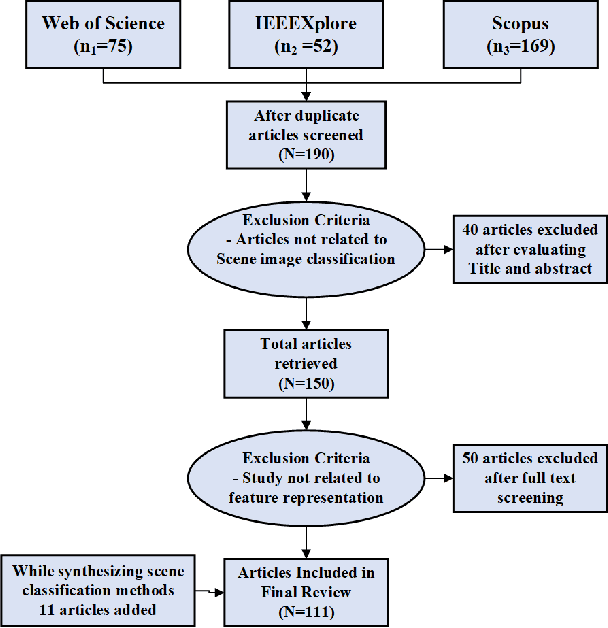
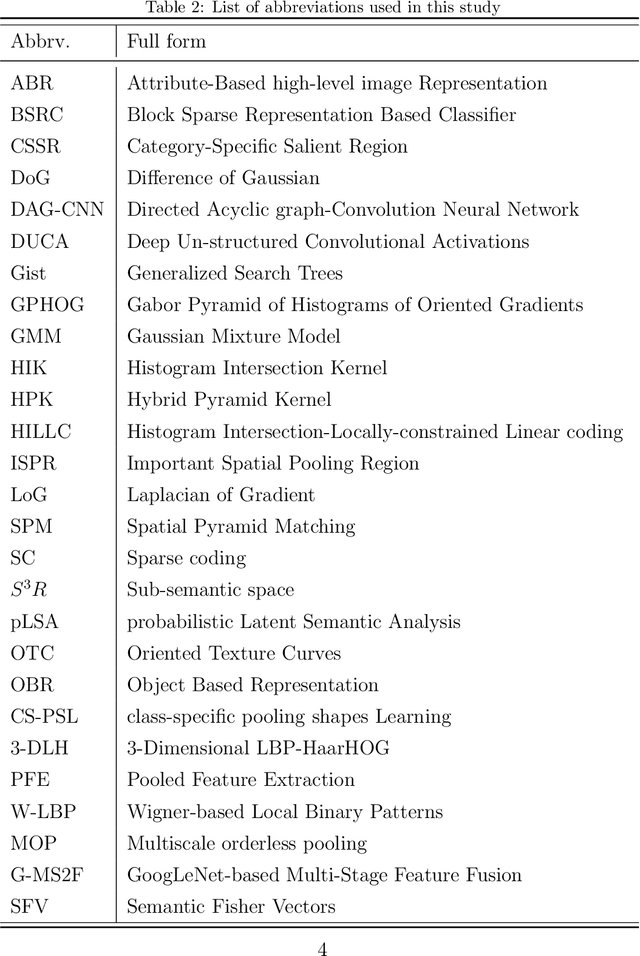
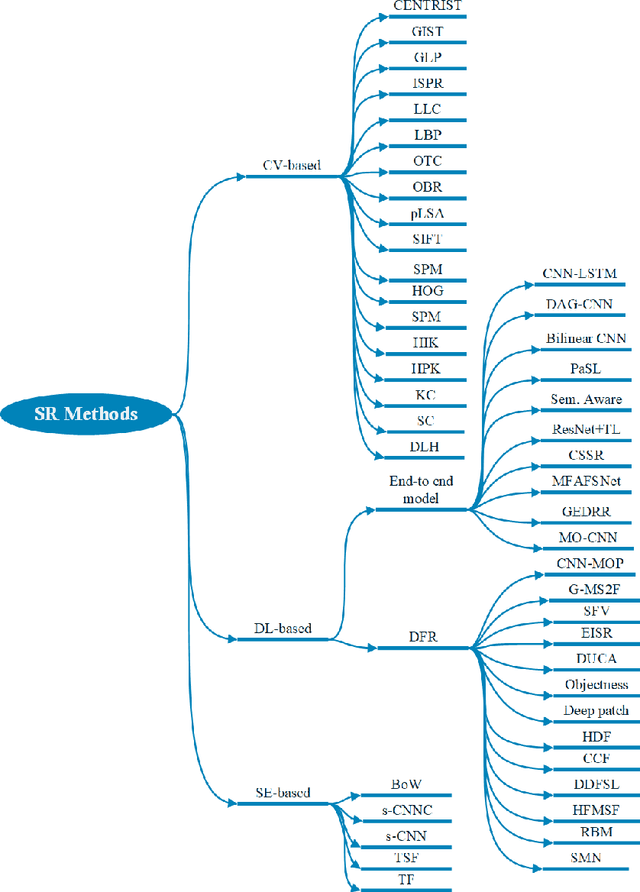
With the rise of deep learning algorithms nowadays, scene image representation methods on big data (e.g., SUN-397) have achieved a significant performance boost in classification. However, the performance is still limited because the scene images are mostly complex in nature having higher intra-class dissimilarity and inter-class similarity problems. To deal with such problems, there are several methods proposed in the literature with their own advantages and limitations. A detailed study of previous works is necessary to understand their pros and cons in image representation and classification. In this paper, we review the existing scene image representation methods that are being used widely for image classification. For this, we, first, devise the taxonomy using the seminal existing methods proposed in the literature to this date. Next, we compare their performance both qualitatively (e.g., quality of outputs, pros/cons, etc.) and quantitatively (e.g., accuracy). Last, we speculate the prominent research directions in scene image representation tasks. Overall, this survey provides in-depth insights and applications of recent scene image representation methods for traditional Computer Vision (CV)-based methods, Deep Learning (DL)-based methods, and Search Engine (SE)-based methods.
Test-time image-to-image translation ensembling improves out-of-distribution generalization in histopathology
Jun 30, 2022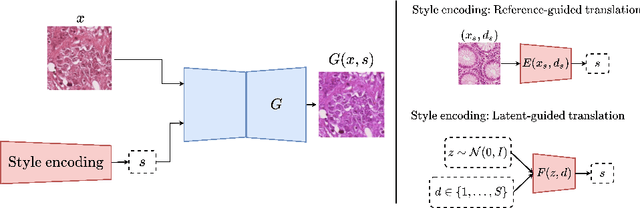
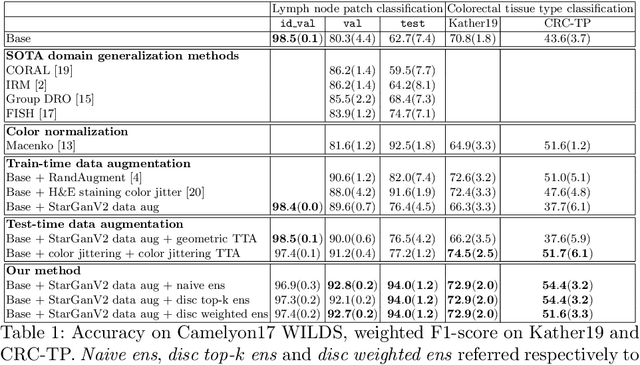
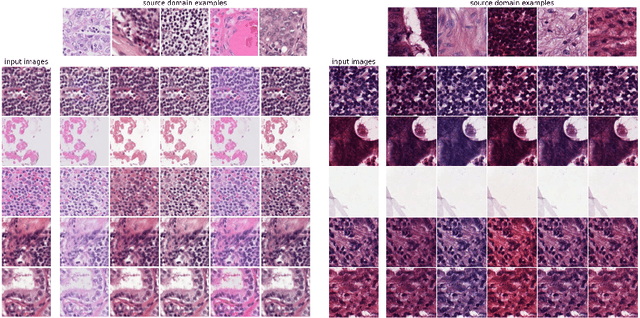
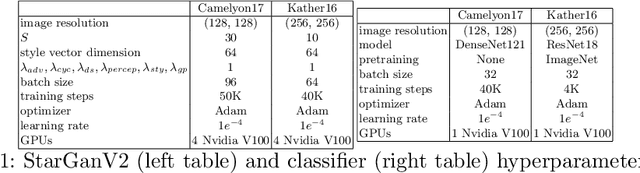
Histopathology whole slide images (WSIs) can reveal significant inter-hospital variability such as illumination, color or optical artifacts. These variations, caused by the use of different scanning protocols across medical centers (staining, scanner), can strongly harm algorithms generalization on unseen protocols. This motivates development of new methods to limit such drop of performances. In this paper, to enhance robustness on unseen target protocols, we propose a new test-time data augmentation based on multi domain image-to-image translation. It allows to project images from unseen protocol into each source domain before classifying them and ensembling the predictions. This test-time augmentation method results in a significant boost of performances for domain generalization. To demonstrate its effectiveness, our method has been evaluated on 2 different histopathology tasks where it outperforms conventional domain generalization, standard H&E specific color augmentation/normalization and standard test-time augmentation techniques. Our code is publicly available at https://gitlab.com/vitadx/articles/test-time-i2i-translation-ensembling.
SR-GNN: Spatial Relation-aware Graph Neural Network for Fine-Grained Image Categorization
Sep 05, 2022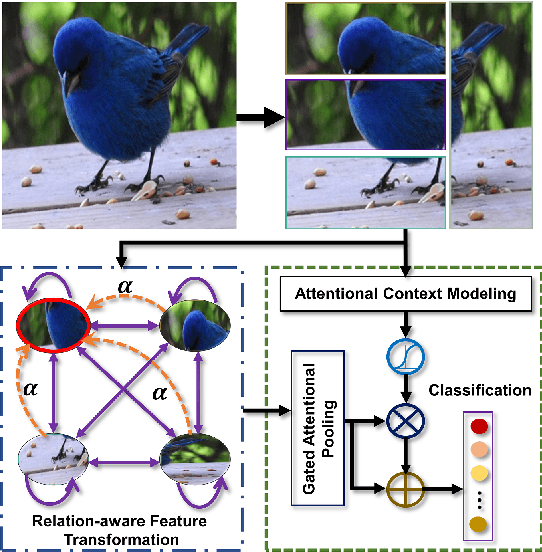
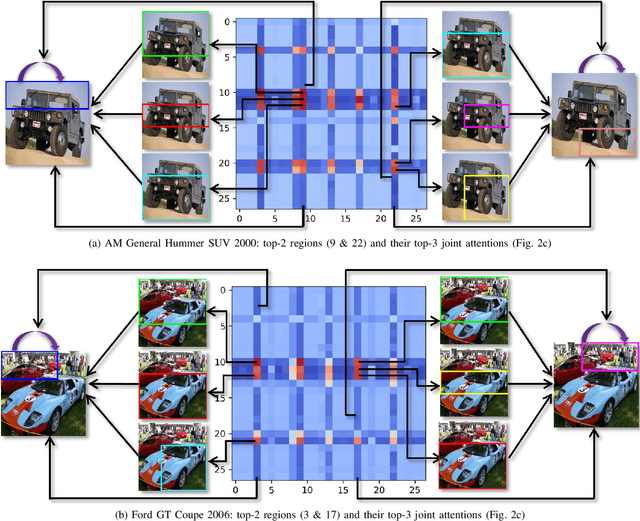
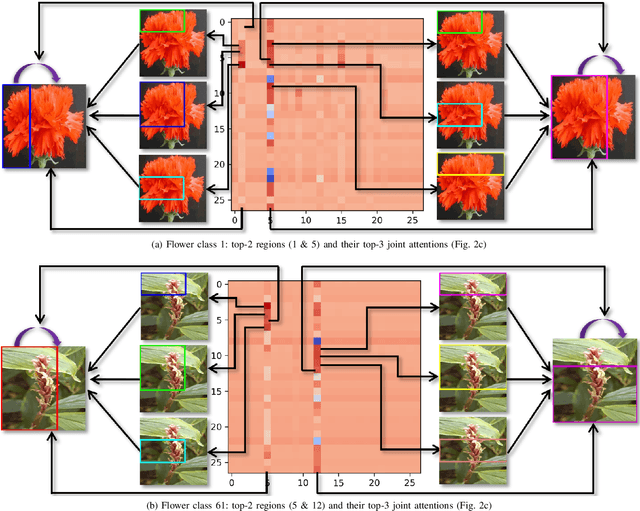
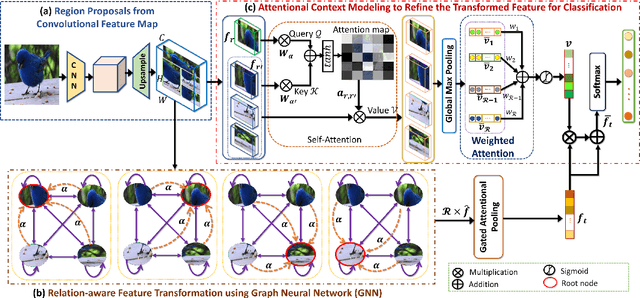
Over the past few years, a significant progress has been made in deep convolutional neural networks (CNNs)-based image recognition. This is mainly due to the strong ability of such networks in mining discriminative object pose and parts information from texture and shape. This is often inappropriate for fine-grained visual classification (FGVC) since it exhibits high intra-class and low inter-class variances due to occlusions, deformation, illuminations, etc. Thus, an expressive feature representation describing global structural information is a key to characterize an object/ scene. To this end, we propose a method that effectively captures subtle changes by aggregating context-aware features from most relevant image-regions and their importance in discriminating fine-grained categories avoiding the bounding-box and/or distinguishable part annotations. Our approach is inspired by the recent advancement in self-attention and graph neural networks (GNNs) approaches to include a simple yet effective relation-aware feature transformation and its refinement using a context-aware attention mechanism to boost the discriminability of the transformed feature in an end-to-end learning process. Our model is evaluated on eight benchmark datasets consisting of fine-grained objects and human-object interactions. It outperforms the state-of-the-art approaches by a significant margin in recognition accuracy.
Paired Cross-Modal Data Augmentation for Fine-Grained Image-to-Text Retrieval
Jul 29, 2022
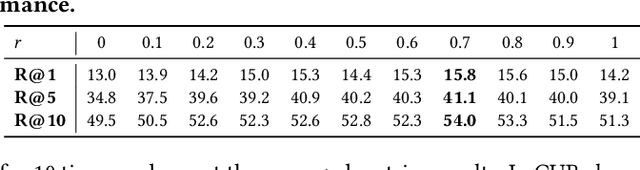
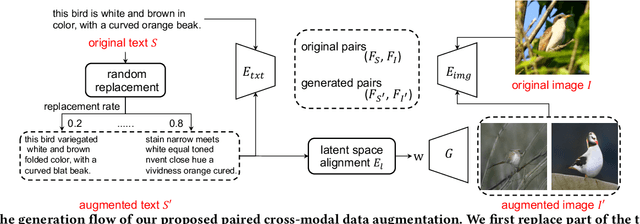
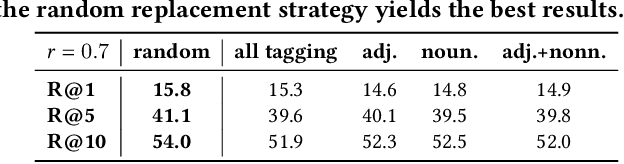
This paper investigates an open research problem of generating text-image pairs to improve the training of fine-grained image-to-text cross-modal retrieval task, and proposes a novel framework for paired data augmentation by uncovering the hidden semantic information of StyleGAN2 model. Specifically, we first train a StyleGAN2 model on the given dataset. We then project the real images back to the latent space of StyleGAN2 to obtain the latent codes. To make the generated images manipulatable, we further introduce a latent space alignment module to learn the alignment between StyleGAN2 latent codes and the corresponding textual caption features. When we do online paired data augmentation, we first generate augmented text through random token replacement, then pass the augmented text into the latent space alignment module to output the latent codes, which are finally fed to StyleGAN2 to generate the augmented images. We evaluate the efficacy of our augmented data approach on two public cross-modal retrieval datasets, in which the promising experimental results demonstrate the augmented text-image pair data can be trained together with the original data to boost the image-to-text cross-modal retrieval performance.
Exploring Negatives in Contrastive Learning for Unpaired Image-to-Image Translation
Apr 23, 2022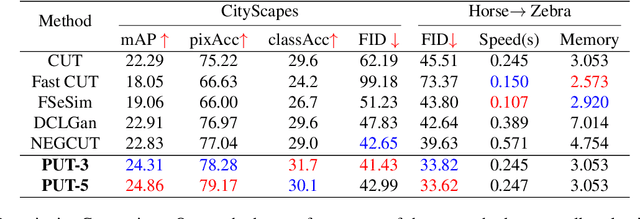
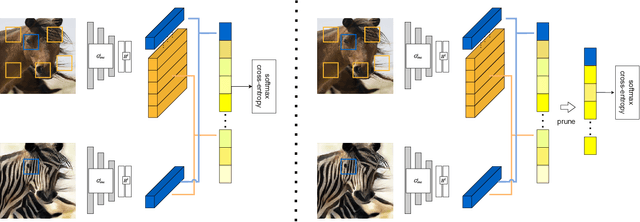

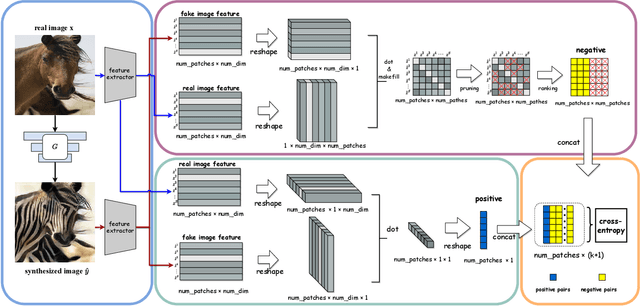
Unpaired image-to-image translation aims to find a mapping between the source domain and the target domain. To alleviate the problem of the lack of supervised labels for the source images, cycle-consistency based methods have been proposed for image structure preservation by assuming a reversible relationship between unpaired images. However, this assumption only uses limited correspondence between image pairs. Recently, contrastive learning (CL) has been used to further investigate the image correspondence in unpaired image translation by using patch-based positive/negative learning. Patch-based contrastive routines obtain the positives by self-similarity computation and recognize the rest patches as negatives. This flexible learning paradigm obtains auxiliary contextualized information at a low cost. As the negatives own an impressive sample number, with curiosity, we make an investigation based on a question: are all negatives necessary for feature contrastive learning? Unlike previous CL approaches that use negatives as much as possible, in this paper, we study the negatives from an information-theoretic perspective and introduce a new negative Pruning technology for Unpaired image-to-image Translation (PUT) by sparsifying and ranking the patches. The proposed algorithm is efficient, flexible and enables the model to learn essential information between corresponding patches stably. By putting quality over quantity, only a few negative patches are required to achieve better results. Lastly, we validate the superiority, stability, and versatility of our model through comparative experiments.
Domain Generalization via Ensemble Stacking for Face Presentation Attack Detection
Jan 05, 2023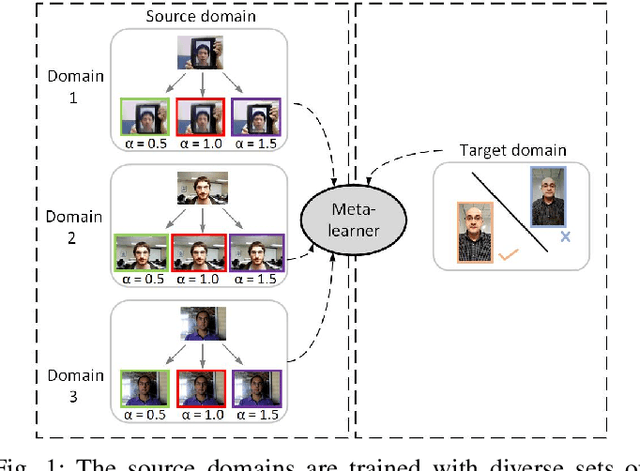
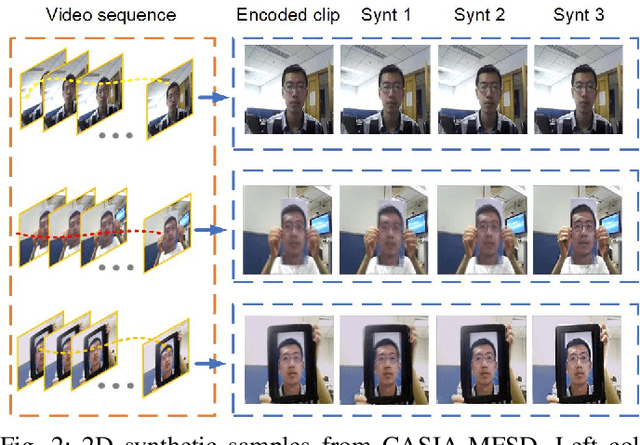
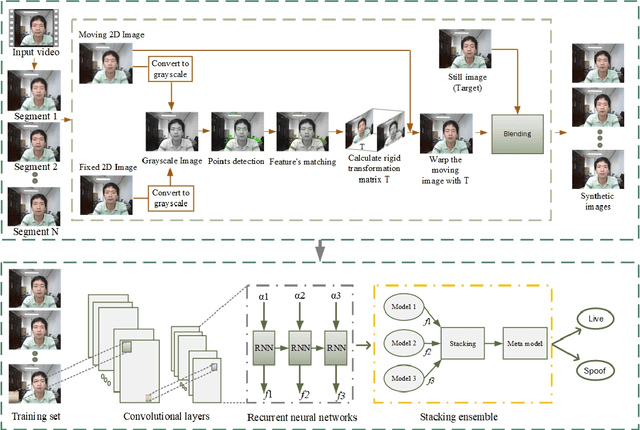

Face presentation attack detection (PAD) plays a pivotal role in securing face recognition systems against spoofing attacks. Although great progress has been made in designing face PAD methods, developing a model that can generalize well to an unseen test domain remains a significant challenge. Moreover, due to different types of spoofing attacks, creating a dataset with a sufficient number of samples for training deep neural networks is a laborious task. This work addresses these challenges by creating synthetic data and introducing a deep learning-based unified framework for improving the generalization ability of the face PAD. In particular, synthetic data is generated by proposing a video distillation technique that blends a spatiotemporal warped image with a still image based on alpha compositing. Since the proposed synthetic samples can be generated by increasing different alpha weights, we train multiple classifiers by taking the advantage of a specific type of ensemble learning known as a stacked ensemble, where each such classifier becomes an expert in its own domain but a non-expert to others. Motivated by this, a meta-classifier is employed to learn from these experts collaboratively so that when developing an ensemble, they can leverage complementary information from each other to better tackle or be more useful for an unseen target domain. Experimental results using half total error rates (HTERs) on four PAD databases CASIA-MFSD (6.97 %), Replay-Attack (33.49%), MSU-MFSD (4.02%), and OULU-NPU (10.91%)) demonstrate the robustness of the method and open up new possibilities for advancing presentation attack detection using ensemble learning with large-scale synthetic data.
CLIP4IDC: CLIP for Image Difference Captioning
Jun 01, 2022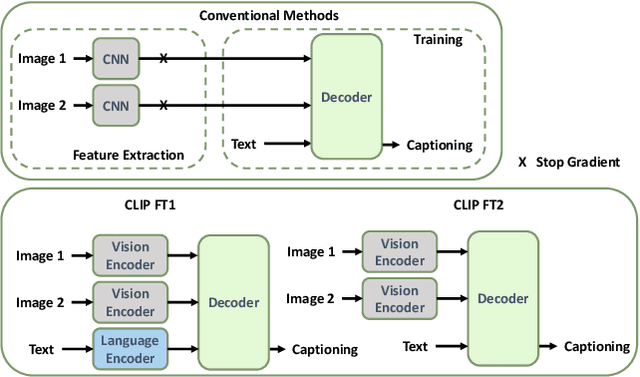
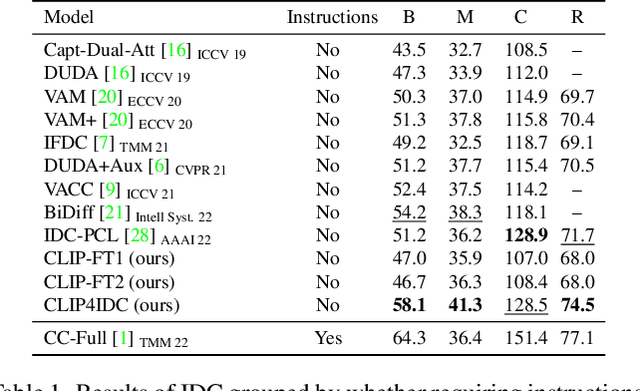
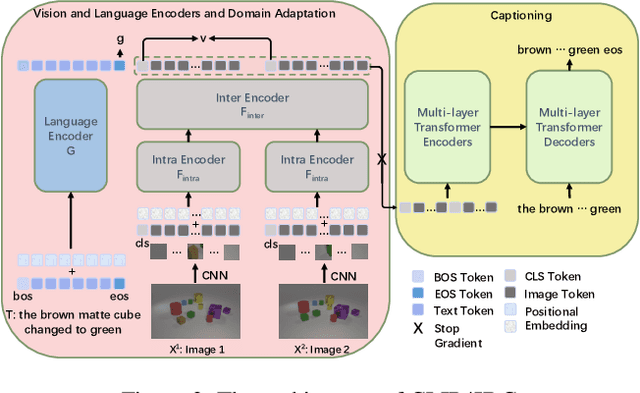
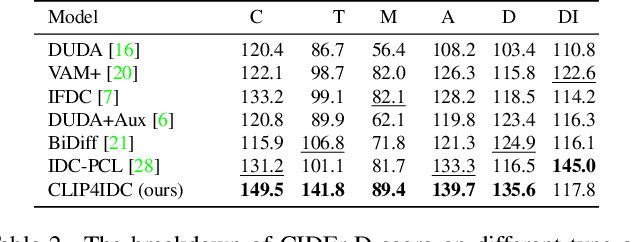
Image Difference Captioning (IDC) aims at generating sentences to describe the differences between two similar-looking images. The conventional approaches learn captioning models on the offline-extracted visual features and the learning can not be propagated back to the fixed feature extractors pre-trained on image classification datasets. Accordingly, potential improvements can be made by fine-tuning the visual features for: 1) narrowing the gap when generalizing the visual extractor trained on image classification to IDC, and 2) relating the extracted visual features to the descriptions of the corresponding changes. We thus propose CLIP4IDC to transfer a CLIP model for the IDC task to attain these improvements. Different from directly fine-tuning CLIP to generate sentences, a task-specific domain adaptation is used to improve the extracted features. Specifically, the target is to train CLIP on raw pixels to relate the image pairs to the described changes. Afterwards, a vanilla Transformer is trained for IDC on the features extracted by the vision encoder of CLIP. Experiments on three IDC benchmark datasets, CLEVR-Change, Spot-the-Diff and Image-Editing-Request, demonstrate the effectiveness of CLIP4IDC. Our code and models will be released at https://github.com/sushizixin/CLIP4IDC.
ChiQA: A Large Scale Image-based Real-World Question Answering Dataset for Multi-Modal Understanding
Aug 05, 2022
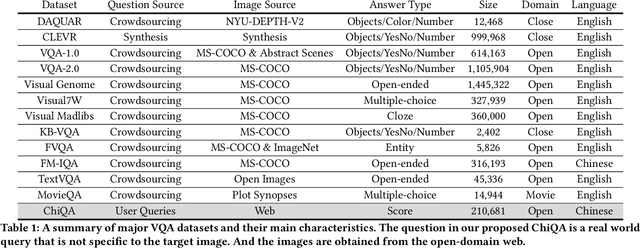

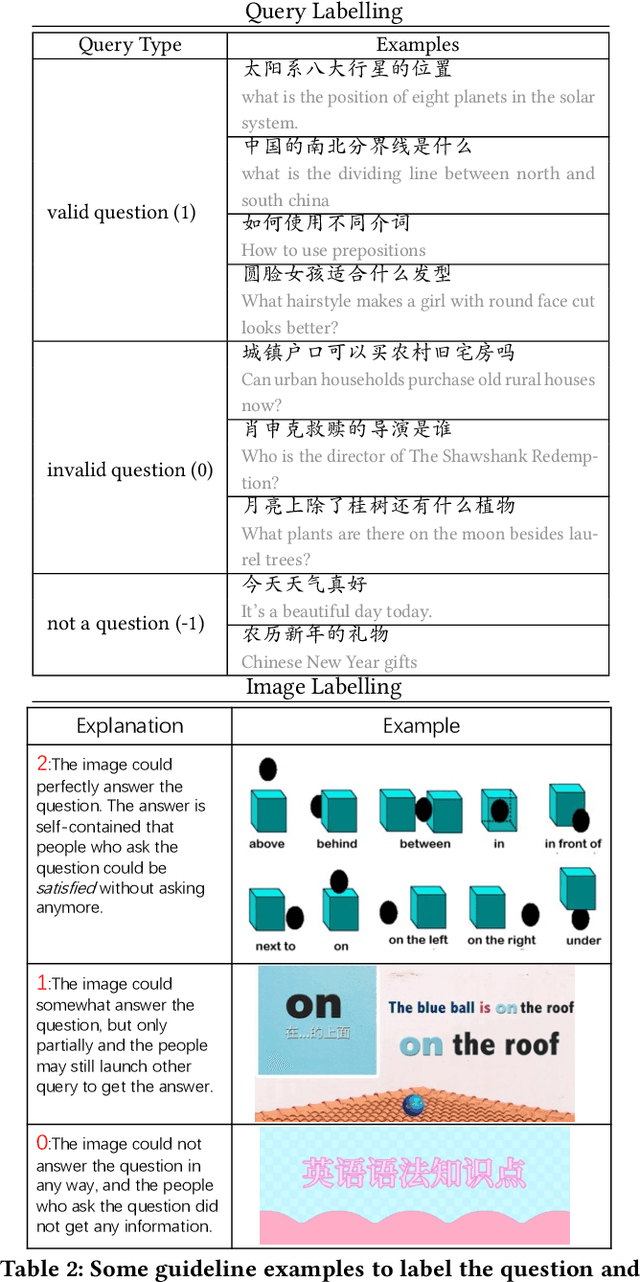
Visual question answering is an important task in both natural language and vision understanding. However, in most of the public visual question answering datasets such as VQA, CLEVR, the questions are human generated that specific to the given image, such as `What color are her eyes?'. The human generated crowdsourcing questions are relatively simple and sometimes have the bias toward certain entities or attributes. In this paper, we introduce a new question answering dataset based on image-ChiQA. It contains the real-world queries issued by internet users, combined with several related open-domain images. The system should determine whether the image could answer the question or not. Different from previous VQA datasets, the questions are real-world image-independent queries that are more various and unbiased. Compared with previous image-retrieval or image-caption datasets, the ChiQA not only measures the relatedness but also measures the answerability, which demands more fine-grained vision and language reasoning. ChiQA contains more than 40K questions and more than 200K question-images pairs. A three-level 2/1/0 label is assigned to each pair indicating perfect answer, partially answer and irrelevant. Data analysis shows ChiQA requires a deep understanding of both language and vision, including grounding, comparisons, and reading. We evaluate several state-of-the-art visual-language models such as ALBEF, demonstrating that there is still a large room for improvements on ChiQA.
Learning Transformations To Reduce the Geometric Shift in Object Detection
Jan 13, 2023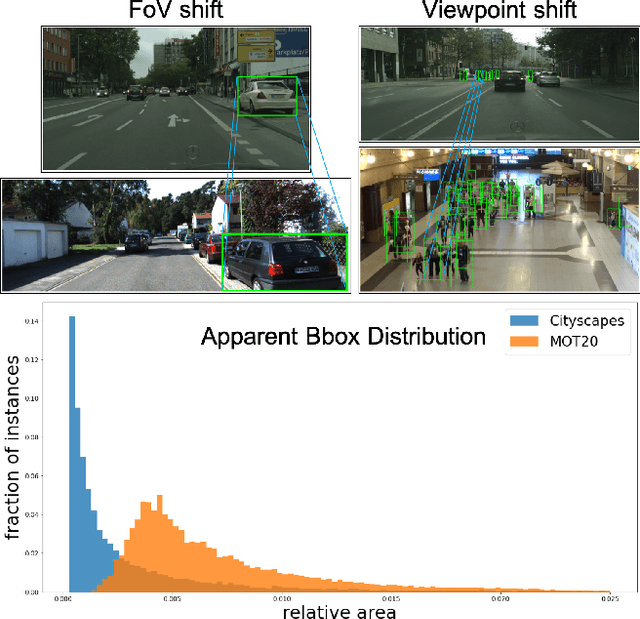


The performance of modern object detectors drops when the test distribution differs from the training one. Most of the methods that address this focus on object appearance changes caused by, e.g., different illumination conditions, or gaps between synthetic and real images. Here, by contrast, we tackle geometric shifts emerging from variations in the image capture process, or due to the constraints of the environment causing differences in the apparent geometry of the content itself. We introduce a self-training approach that learns a set of geometric transformations to minimize these shifts without leveraging any labeled data in the new domain, nor any information about the cameras. We evaluate our method on two different shifts, i.e., a camera's field of view (FoV) change and a viewpoint change. Our results evidence that learning geometric transformations helps detectors to perform better in the target domains.
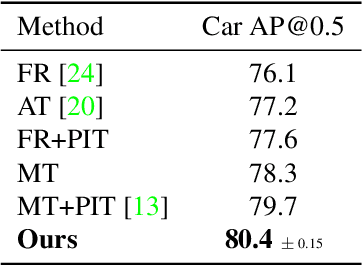
Detecting Objects with Graph Priors and Graph Refinement
Dec 23, 2022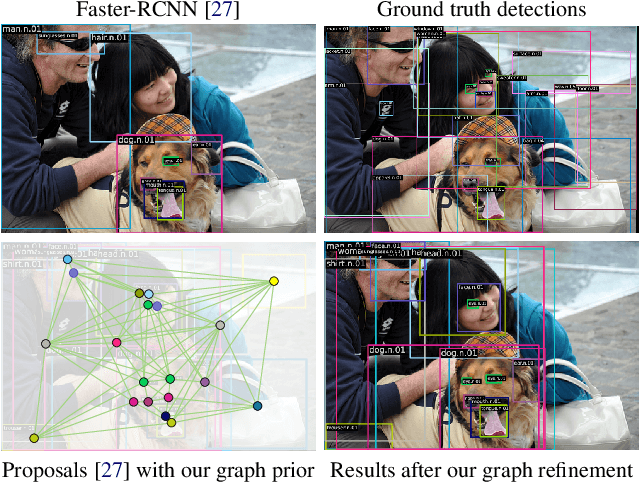
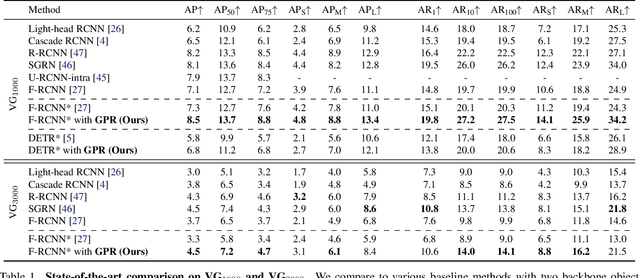
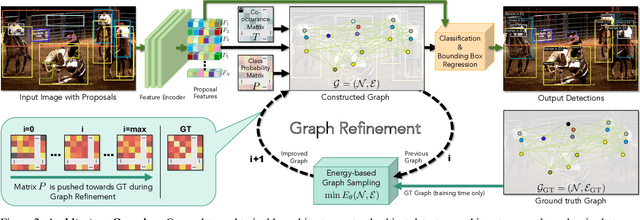
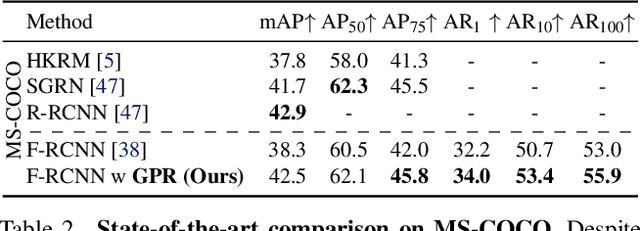
The goal of this paper is to detect objects by exploiting their interrelationships. Rather than relying on predefined and labeled graph structures, we infer a graph prior from object co-occurrence statistics. The key idea of our paper is to model object relations as a function of initial class predictions and co-occurrence priors to generate a graph representation of an image for improved classification and bounding box regression. We additionally learn the object-relation joint distribution via energy based modeling. Sampling from this distribution generates a refined graph representation of the image which in turn produces improved detection performance. Experiments on the Visual Genome and MS-COCO datasets demonstrate our method is detector agnostic, end-to-end trainable, and especially beneficial for rare object classes. What is more, we establish a consistent improvement over object detectors like DETR and Faster-RCNN, as well as state-of-the-art methods modeling object interrelationships.