 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
KinD-LCE Curve Estimation And Retinex Fusion On Low-Light Image
Jul 19, 2022
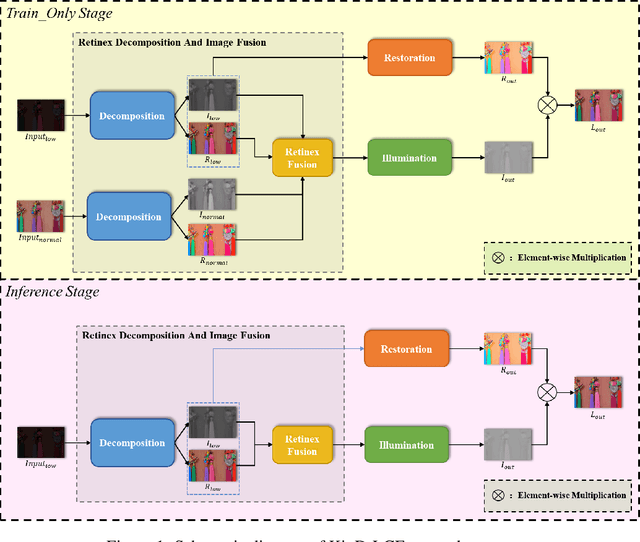

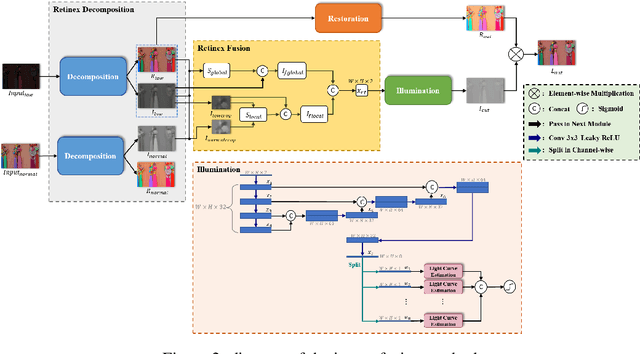

The problems of low light image noise and chromatic aberration is a challenging problem for tasks such as object detection, semantic segmentation, instance segmentation, etc. In this paper, we propose the algorithm for low illumination enhancement. KinD-LCE uses the light curve estimation module in the network structure to enhance the illumination map in the Retinex decomposed image, which improves the image brightness; we proposed the illumination map and reflection map fusion module to restore the restored image details and reduce the detail loss. Finally, we included a total variation loss function to eliminate noise. Our method uses the GladNet dataset as the training set, and the LOL dataset as the test set and is validated using ExDark as the dataset for downstream tasks. Extensive Experiments on the benchmarks demonstrate the advantages of our method and are close to the state-of-the-art results, which achieve a PSNR of 19.7216 and SSIM of 0.8213 in terms of metrics.
Data class-specific all-optical transformations and encryption
Dec 25, 2022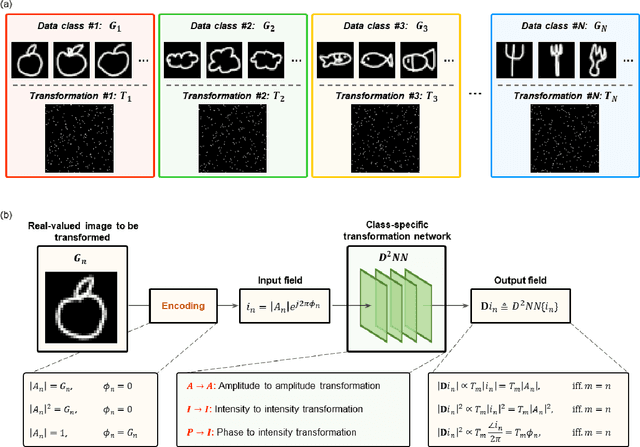
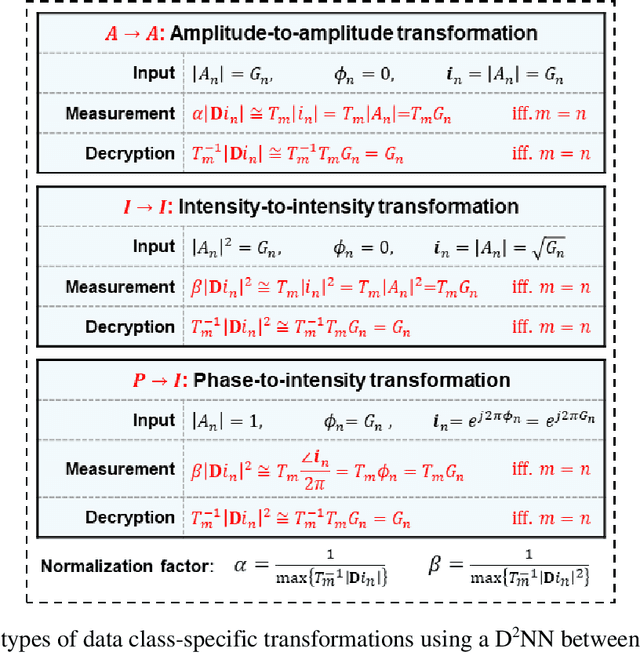
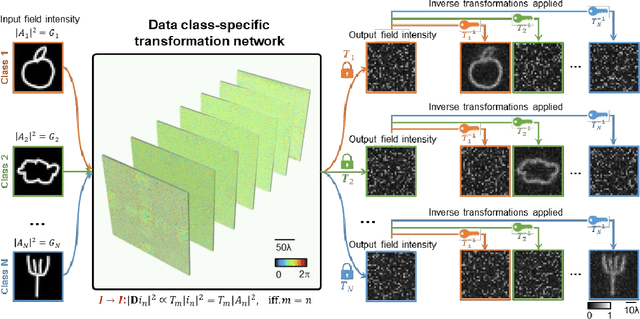
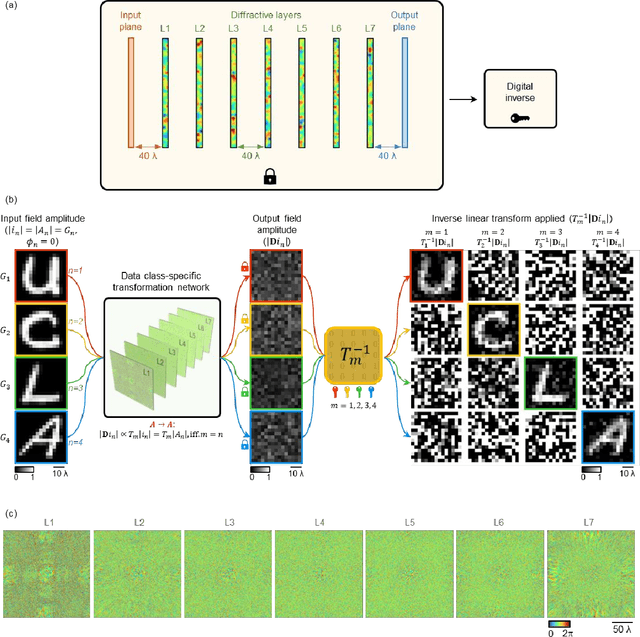
Diffractive optical networks provide rich opportunities for visual computing tasks since the spatial information of a scene can be directly accessed by a diffractive processor without requiring any digital pre-processing steps. Here we present data class-specific transformations all-optically performed between the input and output fields-of-view (FOVs) of a diffractive network. The visual information of the objects is encoded into the amplitude (A), phase (P), or intensity (I) of the optical field at the input, which is all-optically processed by a data class-specific diffractive network. At the output, an image sensor-array directly measures the transformed patterns, all-optically encrypted using the transformation matrices pre-assigned to different data classes, i.e., a separate matrix for each data class. The original input images can be recovered by applying the correct decryption key (the inverse transformation) corresponding to the matching data class, while applying any other key will lead to loss of information. The class-specificity of these all-optical diffractive transformations creates opportunities where different keys can be distributed to different users; each user can only decode the acquired images of only one data class, serving multiple users in an all-optically encrypted manner. We numerically demonstrated all-optical class-specific transformations covering A-->A, I-->I, and P-->I transformations using various image datasets. We also experimentally validated the feasibility of this framework by fabricating a class-specific I-->I transformation diffractive network using two-photon polymerization and successfully tested it at 1550 nm wavelength. Data class-specific all-optical transformations provide a fast and energy-efficient method for image and data encryption, enhancing data security and privacy.
Backdoor Attack and Defense in Federated Generative Adversarial Network-based Medical Image Synthesis
Oct 19, 2022

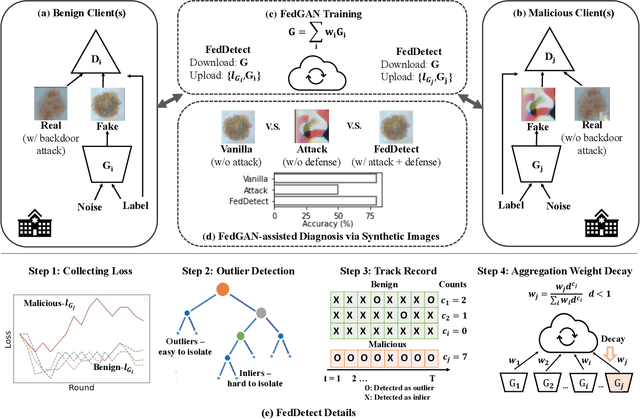
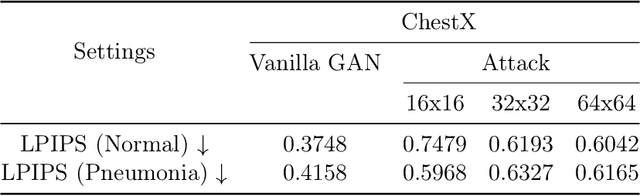
Deep Learning-based image synthesis techniques have been applied in healthcare research for generating medical images to support open research and augment medical datasets. Training generative adversarial neural networks (GANs) usually require large amounts of training data. Federated learning (FL) provides a way of training a central model using distributed data while keeping raw data locally. However, given that the FL server cannot access the raw data, it is vulnerable to backdoor attacks, an adversarial by poisoning training data. Most backdoor attack strategies focus on classification models and centralized domains. It is still an open question if the existing backdoor attacks can affect GAN training and, if so, how to defend against the attack in the FL setting. In this work, we investigate the overlooked issue of backdoor attacks in federated GANs (FedGANs). The success of this attack is subsequently determined to be the result of some local discriminators overfitting the poisoned data and corrupting the local GAN equilibrium, which then further contaminates other clients when averaging the generator's parameters and yields high generator loss. Therefore, we proposed FedDetect, an efficient and effective way of defending against the backdoor attack in the FL setting, which allows the server to detect the client's adversarial behavior based on their losses and block the malicious clients. Our extensive experiments on two medical datasets with different modalities demonstrate the backdoor attack on FedGANs can result in synthetic images with low fidelity. After detecting and suppressing the detected malicious clients using the proposed defense strategy, we show that FedGANs can synthesize high-quality medical datasets (with labels) for data augmentation to improve classification models' performance.
SuperGF: Unifying Local and Global Features for Visual Localization
Dec 23, 2022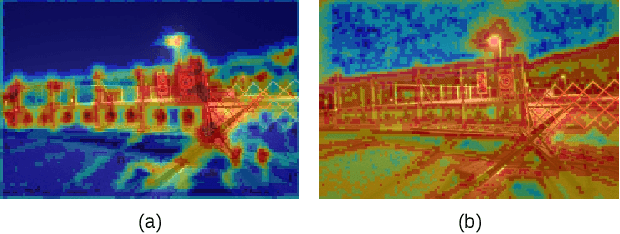
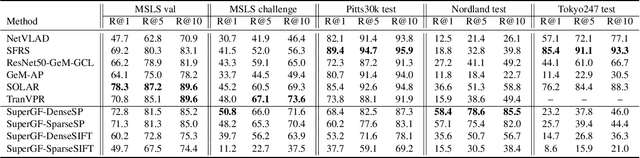
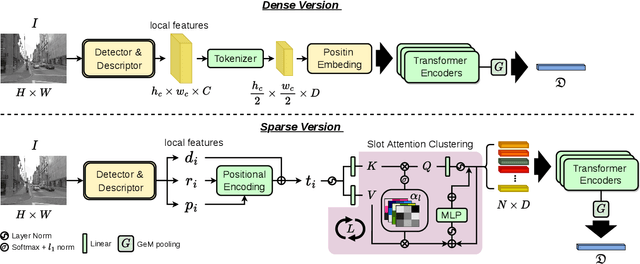
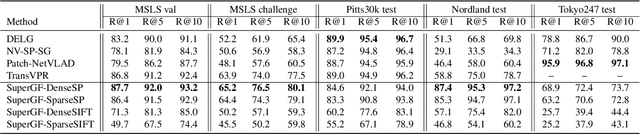
Advanced visual localization techniques encompass image retrieval challenges and 6 Degree-of-Freedom (DoF) camera pose estimation, such as hierarchical localization. Thus, they must extract global and local features from input images. Previous methods have achieved this through resource-intensive or accuracy-reducing means, such as combinatorial pipelines or multi-task distillation. In this study, we present a novel method called SuperGF, which effectively unifies local and global features for visual localization, leading to a higher trade-off between localization accuracy and computational efficiency. Specifically, SuperGF is a transformer-based aggregation model that operates directly on image-matching-specific local features and generates global features for retrieval. We conduct experimental evaluations of our method in terms of both accuracy and efficiency, demonstrating its advantages over other methods. We also provide implementations of SuperGF using various types of local features, including dense and sparse learning-based or hand-crafted descriptors.
Learning Parallax Transformer Network for Stereo Image JPEG Artifacts Removal
Jul 15, 2022
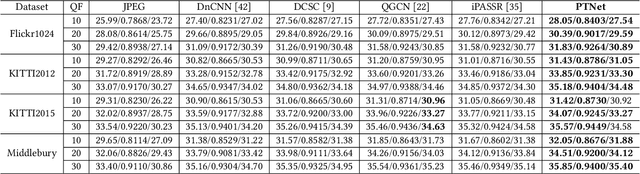
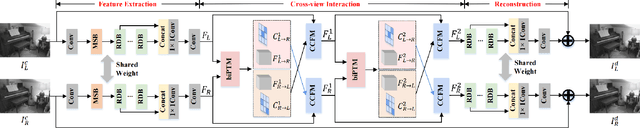
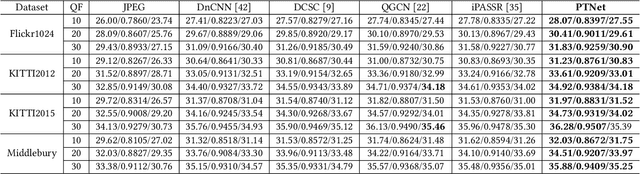
Under stereo settings, the performance of image JPEG artifacts removal can be further improved by exploiting the additional information provided by a second view. However, incorporating this information for stereo image JPEG artifacts removal is a huge challenge, since the existing compression artifacts make pixel-level view alignment difficult. In this paper, we propose a novel parallax transformer network (PTNet) to integrate the information from stereo image pairs for stereo image JPEG artifacts removal. Specifically, a well-designed symmetric bi-directional parallax transformer module is proposed to match features with similar textures between different views instead of pixel-level view alignment. Due to the issues of occlusions and boundaries, a confidence-based cross-view fusion module is proposed to achieve better feature fusion for both views, where the cross-view features are weighted with confidence maps. Especially, we adopt a coarse-to-fine design for the cross-view interaction, leading to better performance. Comprehensive experimental results demonstrate that our PTNet can effectively remove compression artifacts and achieves superior performance than other testing state-of-the-art methods.
Diverse, Difficult, and Odd Instances (D2O): A New Test Set for Object Classification
Jan 29, 2023

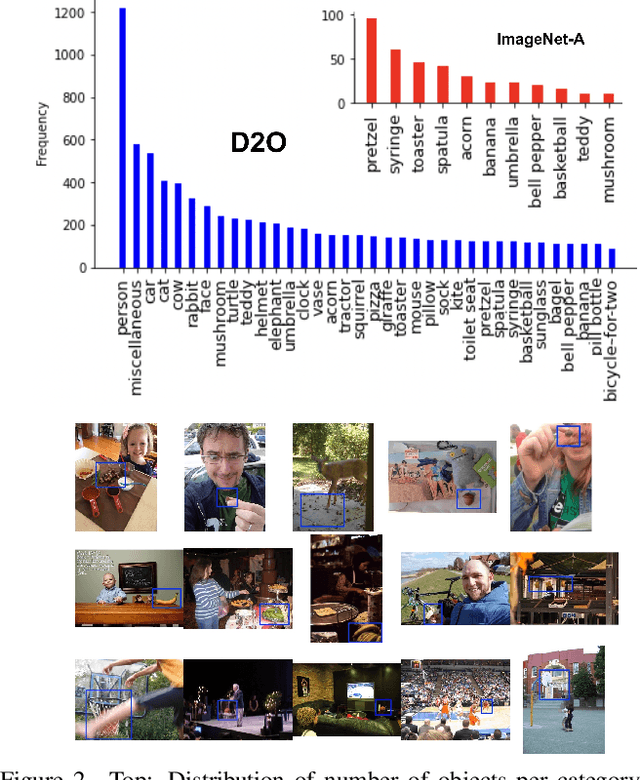
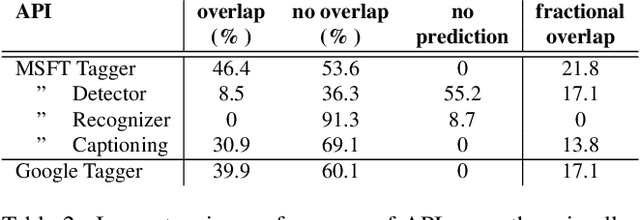
Test sets are an integral part of evaluating models and gauging progress in object recognition, and more broadly in computer vision and AI. Existing test sets for object recognition, however, suffer from shortcomings such as bias towards the ImageNet characteristics and idiosyncrasies (e.g., ImageNet-V2), being limited to certain types of stimuli (e.g., indoor scenes in ObjectNet), and underestimating the model performance (e.g., ImageNet-A). To mitigate these problems, we introduce a new test set, called D2O, which is sufficiently different from existing test sets. Images are a mix of generated images as well as images crawled from the web. They are diverse, unmodified, and representative of real-world scenarios and cause state-of-the-art models to misclassify them with high confidence. To emphasize generalization, our dataset by design does not come paired with a training set. It contains 8,060 images spread across 36 categories, out of which 29 appear in ImageNet. The best Top-1 accuracy on our dataset is around 60% which is much lower than 91% best Top-1 accuracy on ImageNet. We find that popular vision APIs perform very poorly in detecting objects over D2O categories such as ``faces'', ``cars'', and ``cats''. Our dataset also comes with a ``miscellaneous'' category, over which we test the image tagging models. Overall, our investigations demonstrate that the D2O test set contain a mix of images with varied levels of difficulty and is predictive of the average-case performance of models. It can challenge object recognition models for years to come and can spur more research in this fundamental area.
Localizing Semantic Patches for Accelerating Image Classification
Jun 07, 2022
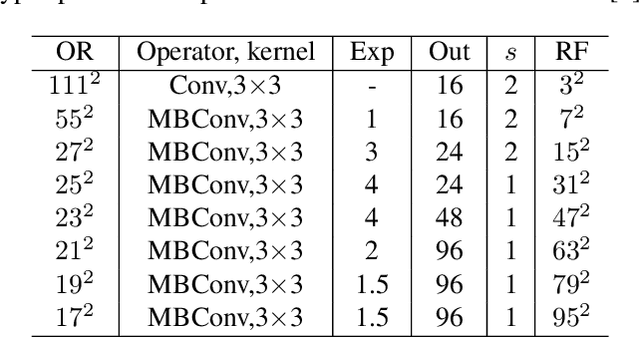
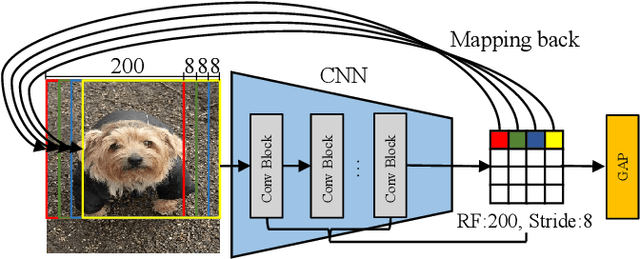
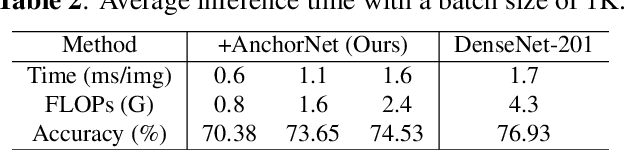
Existing works often focus on reducing the architecture redundancy for accelerating image classification but ignore the spatial redundancy of the input image. This paper proposes an efficient image classification pipeline to solve this problem. We first pinpoint task-aware regions over the input image by a lightweight patch proposal network called AnchorNet. We then feed these localized semantic patches with much smaller spatial redundancy into a general classification network. Unlike the popular design of deep CNN, we aim to carefully design the Receptive Field of AnchorNet without intermediate convolutional paddings. This ensures the exact mapping from a high-level spatial location to the specific input image patch. The contribution of each patch is interpretable. Moreover, AnchorNet is compatible with any downstream architecture. Experimental results on ImageNet show that our method outperforms SOTA dynamic inference methods with fewer inference costs. Our code is available at https://github.com/winycg/AnchorNet.
Learning Local Implicit Fourier Representation for Image Warping
Jul 05, 2022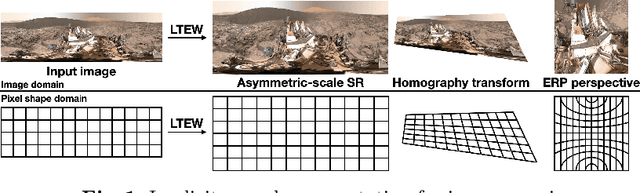
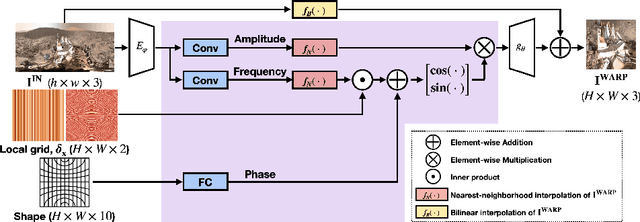
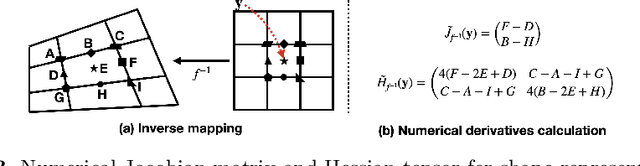
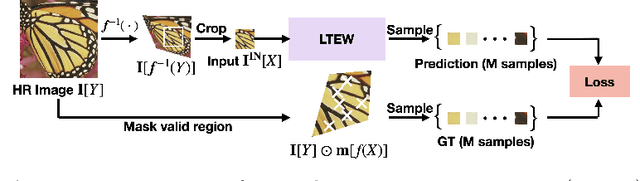
Image warping aims to reshape images defined on rectangular grids into arbitrary shapes. Recently, implicit neural functions have shown remarkable performances in representing images in a continuous manner. However, a standalone multi-layer perceptron suffers from learning high-frequency Fourier coefficients. In this paper, we propose a local texture estimator for image warping (LTEW) followed by an implicit neural representation to deform images into continuous shapes. Local textures estimated from a deep super-resolution (SR) backbone are multiplied by locally-varying Jacobian matrices of a coordinate transformation to predict Fourier responses of a warped image. Our LTEW-based neural function outperforms existing warping methods for asymmetric-scale SR and homography transform. Furthermore, our algorithm well generalizes arbitrary coordinate transformations, such as homography transform with a large magnification factor and equirectangular projection (ERP) perspective transform, which are not provided in training.
Neural Color Operators for Sequential Image Retouching
Jul 17, 2022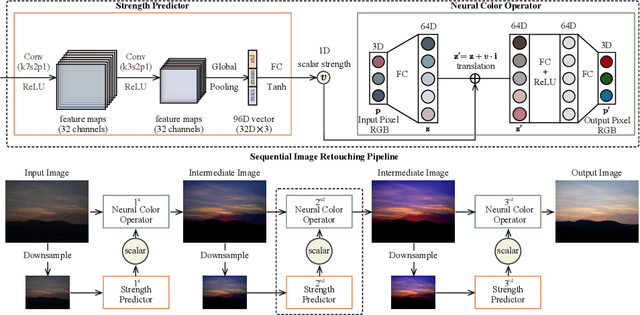
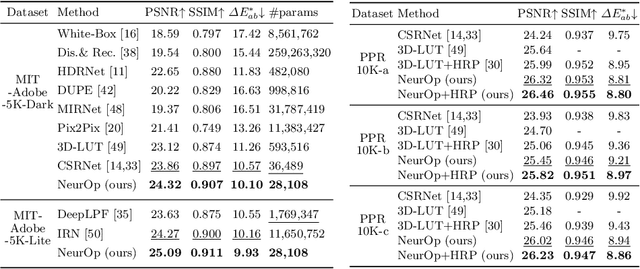


We propose a novel image retouching method by modeling the retouching process as performing a sequence of newly introduced trainable neural color operators. The neural color operator mimics the behavior of traditional color operators and learns pixelwise color transformation while its strength is controlled by a scalar. To reflect the homomorphism property of color operators, we employ equivariant mapping and adopt an encoder-decoder structure which maps the non-linear color transformation to a much simpler transformation (i.e., translation) in a high dimensional space. The scalar strength of each neural color operator is predicted using CNN based strength predictors by analyzing global image statistics. Overall, our method is rather lightweight and offers flexible controls. Experiments and user studies on public datasets show that our method consistently achieves the best results compared with SOTA methods in both quantitative measures and visual qualities. The code and data will be made publicly available.
Coil2Coil: Self-supervised MR image denoising using phased-array coil images
Aug 16, 2022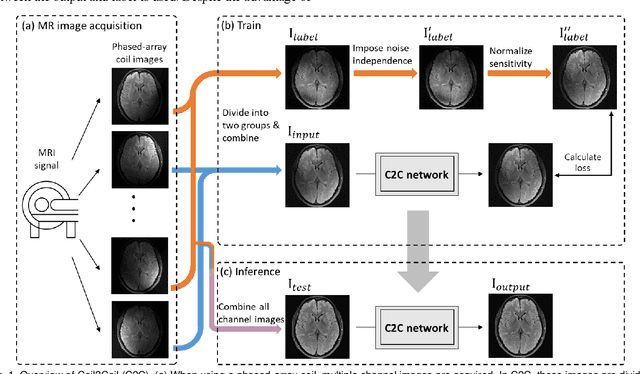
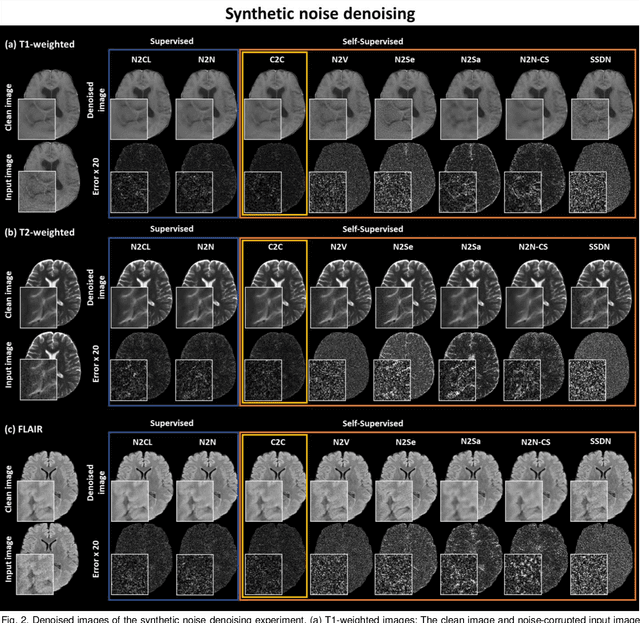
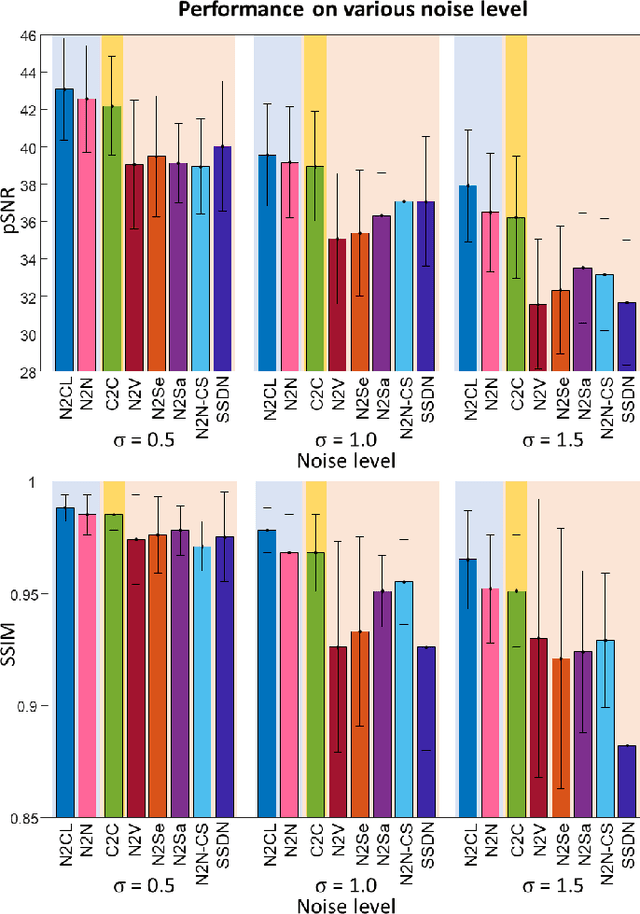
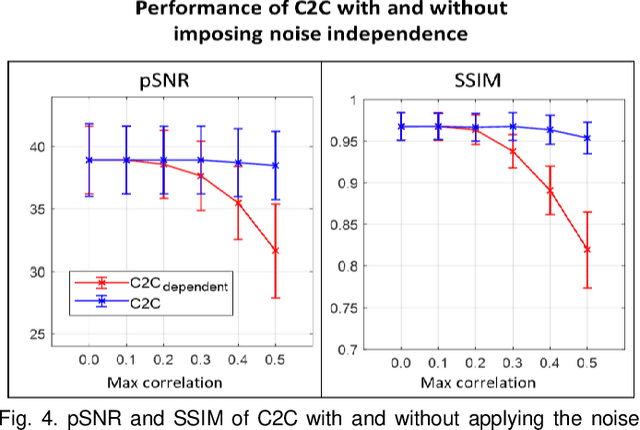
Denoising of magnetic resonance images is beneficial in improving the quality of low signal-to-noise ratio images. Recently, denoising using deep neural networks has demonstrated promising results. Most of these networks, however, utilize supervised learning, which requires large training images of noise-corrupted and clean image pairs. Obtaining training images, particularly clean images, is expensive and time-consuming. Hence, methods such as Noise2Noise (N2N) that require only pairs of noise-corrupted images have been developed to reduce the burden of obtaining training datasets. In this study, we propose a new self-supervised denoising method, Coil2Coil (C2C), that does not require the acquisition of clean images or paired noise-corrupted images for training. Instead, the method utilizes multichannel data from phased-array coils to generate training images. First, it divides and combines multichannel coil images into two images, one for input and the other for label. Then, they are processed to impose noise independence and sensitivity normalization such that they can be used for the training images of N2N. For inference, the method inputs a coil-combined image (e.g., DICOM image), enabling a wide application of the method. When evaluated using synthetic noise-added images, C2C shows the best performance against several self-supervised methods, reporting comparable outcomes to supervised methods. When testing the DICOM images, C2C successfully denoised real noise without showing structure-dependent residuals in the error maps. Because of the significant advantage of not requiring additional scans for clean or paired images, the method can be easily utilized for various clinical applications.