 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Topological Loss Function for Low-Light Image Denoising
Aug 18, 2022

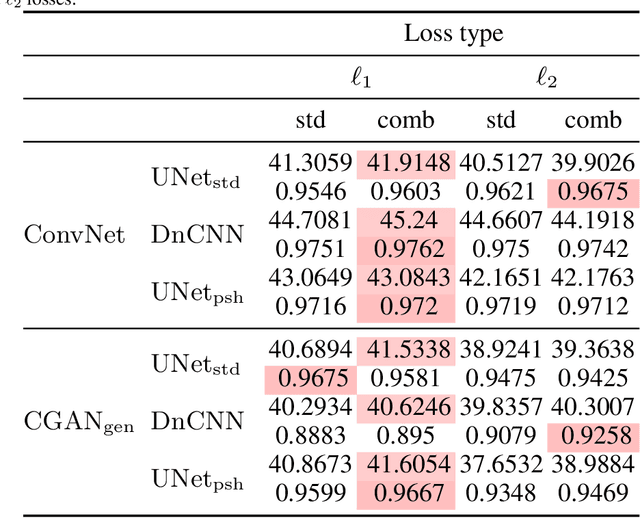

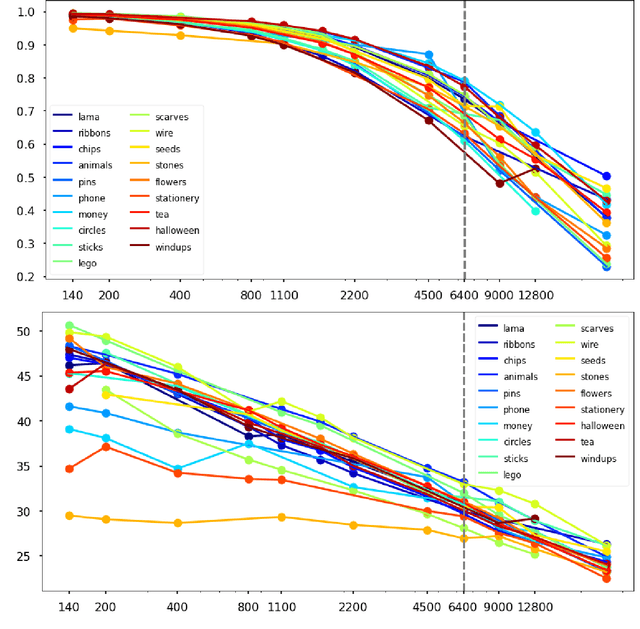
Although image denoising algorithms have attracted significant research attention, surprisingly few have been proposed for, or evaluated on, noise from imagery acquired under real low-light conditions. Moreover, noise characteristics are often assumed to be spatially invariant, leading to edges and textures being distorted after denoising. Here, we introduce a novel topological loss function which is based on persistent homology, offering true features with resistance to noise across multiple scales. The method performs in the space of image patches, where topological invariants are calculated and represented in persistent diagrams. The loss function is a combination of $\ell_1$ or $\ell_2$ losses with the new persistence-based topological loss. We compare its performance across popular denoising architectures, training the networks on our new comprehensive dataset of natural images captured in low-light conditions -- BVI-LOWLIGHT. Analysis reveals that this approach outperforms existing methods, adapting well to edges and complex structures and suppressing common artifacts.
Context-Consistent Semantic Image Editing with Style-Preserved Modulation
Jul 13, 2022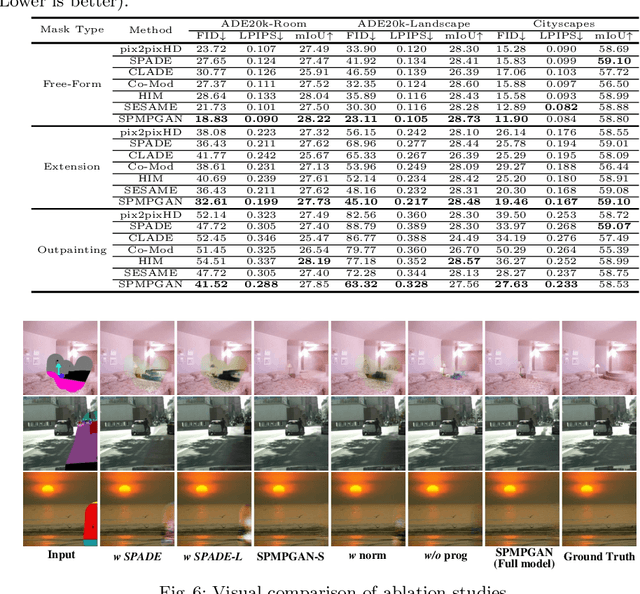
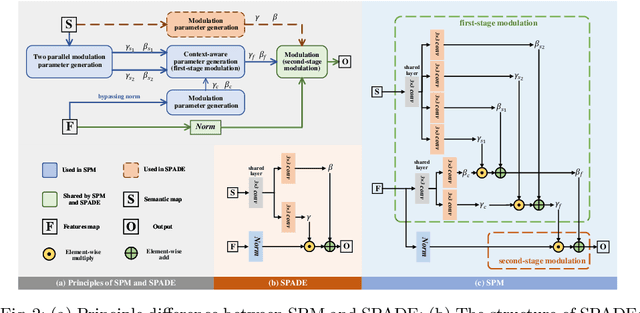
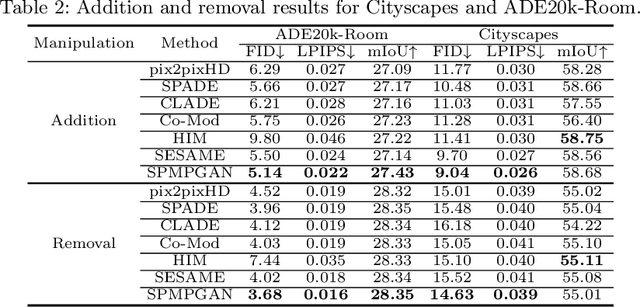
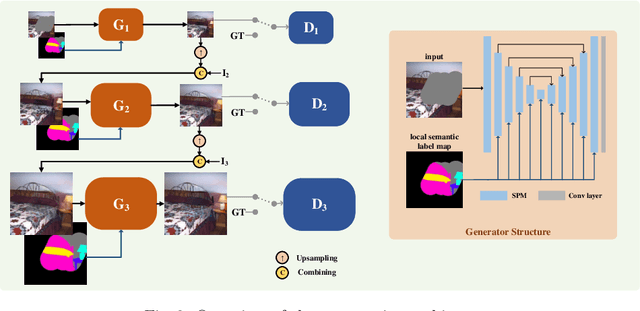
Semantic image editing utilizes local semantic label maps to generate the desired content in the edited region. A recent work borrows SPADE block to achieve semantic image editing. However, it cannot produce pleasing results due to style discrepancy between the edited region and surrounding pixels. We attribute this to the fact that SPADE only uses an image-independent local semantic layout but ignores the image-specific styles included in the known pixels. To address this issue, we propose a style-preserved modulation (SPM) comprising two modulations processes: The first modulation incorporates the contextual style and semantic layout, and then generates two fused modulation parameters. The second modulation employs the fused parameters to modulate feature maps. By using such two modulations, SPM can inject the given semantic layout while preserving the image-specific context style. Moreover, we design a progressive architecture for generating the edited content in a coarse-to-fine manner. The proposed method can obtain context-consistent results and significantly alleviate the unpleasant boundary between the generated regions and the known pixels.
Imitating Human Behaviour with Diffusion Models
Jan 25, 2023
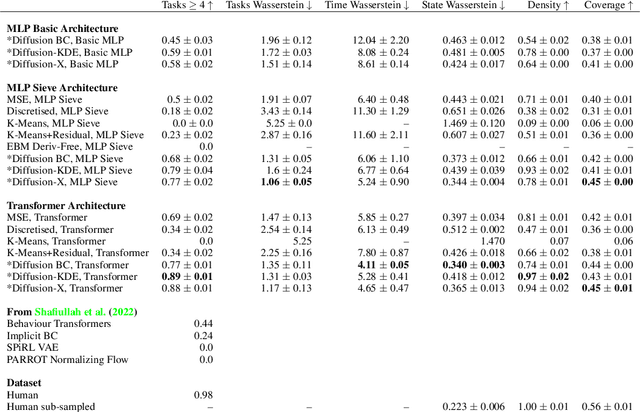
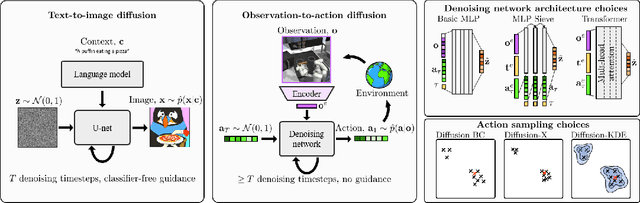
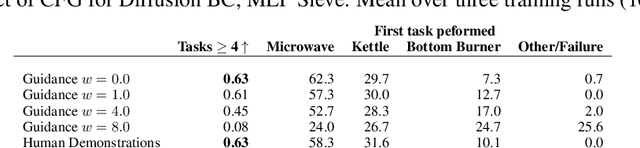
Diffusion models have emerged as powerful generative models in the text-to-image domain. This paper studies their application as observation-to-action models for imitating human behaviour in sequential environments. Human behaviour is stochastic and multimodal, with structured correlations between action dimensions. Meanwhile, standard modelling choices in behaviour cloning are limited in their expressiveness and may introduce bias into the cloned policy. We begin by pointing out the limitations of these choices. We then propose that diffusion models are an excellent fit for imitating human behaviour, since they learn an expressive distribution over the joint action space. We introduce several innovations to make diffusion models suitable for sequential environments; designing suitable architectures, investigating the role of guidance, and developing reliable sampling strategies. Experimentally, diffusion models closely match human demonstrations in a simulated robotic control task and a modern 3D gaming environment.
* Published in ICLR 2023
Differentially Private Image Classification from Features
Nov 24, 2022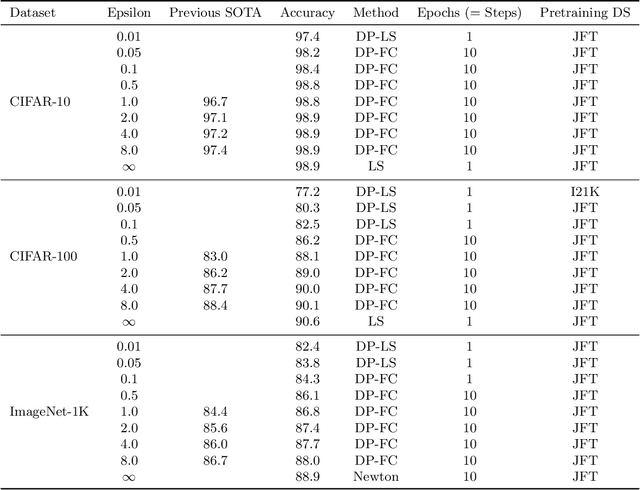
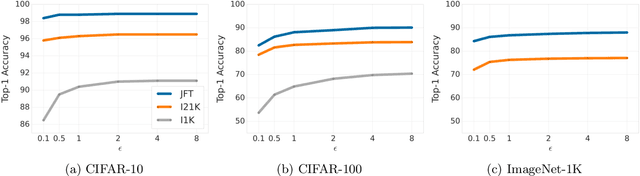
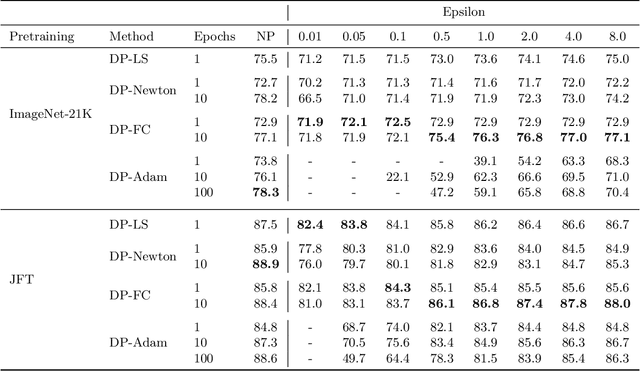
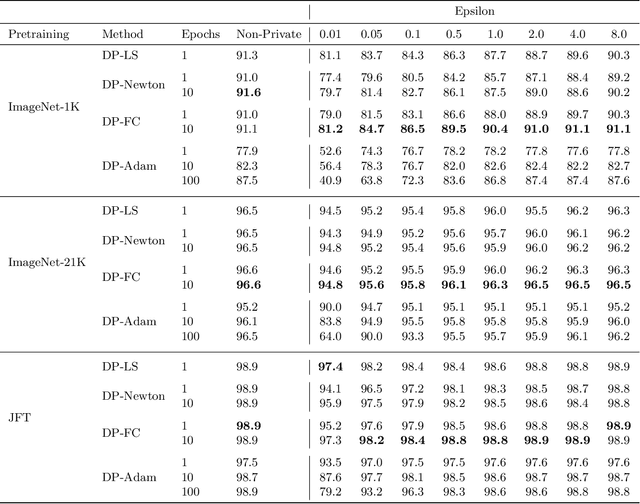
Leveraging transfer learning has recently been shown to be an effective strategy for training large models with Differential Privacy (DP). Moreover, somewhat surprisingly, recent works have found that privately training just the last layer of a pre-trained model provides the best utility with DP. While past studies largely rely on algorithms like DP-SGD for training large models, in the specific case of privately learning from features, we observe that computational burden is low enough to allow for more sophisticated optimization schemes, including second-order methods. To that end, we systematically explore the effect of design parameters such as loss function and optimization algorithm. We find that, while commonly used logistic regression performs better than linear regression in the non-private setting, the situation is reversed in the private setting. We find that linear regression is much more effective than logistic regression from both privacy and computational aspects, especially at stricter epsilon values ($\epsilon < 1$). On the optimization side, we also explore using Newton's method, and find that second-order information is quite helpful even with privacy, although the benefit significantly diminishes with stricter privacy guarantees. While both methods use second-order information, least squares is effective at lower epsilons while Newton's method is effective at larger epsilon values. To combine the benefits of both, we propose a novel algorithm called DP-FC, which leverages feature covariance instead of the Hessian of the logistic regression loss and performs well across all $\epsilon$ values we tried. With this, we obtain new SOTA results on ImageNet-1k, CIFAR-100 and CIFAR-10 across all values of $\epsilon$ typically considered. Most remarkably, on ImageNet-1K, we obtain top-1 accuracy of 88\% under (8, $8 * 10^{-7}$)-DP and 84.3\% under (0.1, $8 * 10^{-7}$)-DP.
PSENet: Progressive Self-Enhancement Network for Unsupervised Extreme-Light Image Enhancement
Oct 03, 2022
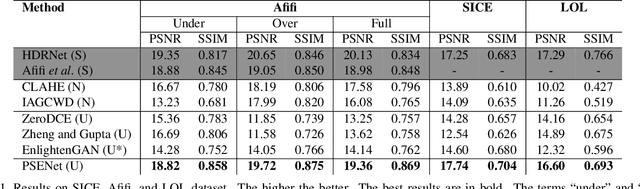
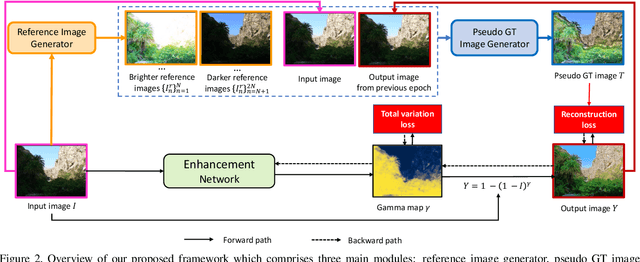

The extremes of lighting (e.g. too much or too little light) usually cause many troubles for machine and human vision. Many recent works have mainly focused on under-exposure cases where images are often captured in low-light conditions (e.g. nighttime) and achieved promising results for enhancing the quality of images. However, they are inferior to handling images under over-exposure. To mitigate this limitation, we propose a novel unsupervised enhancement framework which is robust against various lighting conditions while does not require any well-exposed images to serve as the ground-truths. Our main concept is to construct pseudo-ground-truth images synthesized from multiple source images that simulate all potential exposure scenarios to train the enhancement network. Our extensive experiments show that the proposed approach consistently outperforms the current state-of-the-art unsupervised counterparts in several public datasets in terms of both quantitative metrics and qualitative results. Our code is available at https://github.com/VinAIResearch/PSENet-Image-Enhancement.
Deep Class-Incremental Learning: A Survey
Feb 07, 2023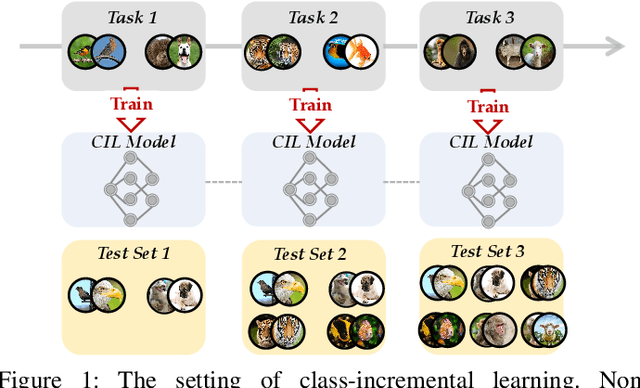
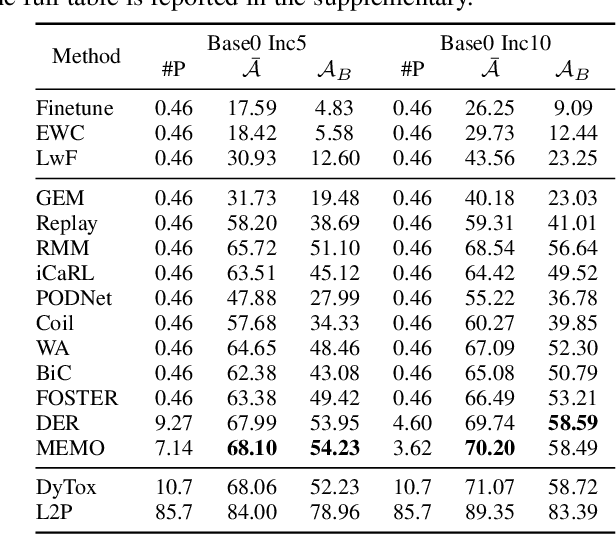
Deep models, e.g., CNNs and Vision Transformers, have achieved impressive achievements in many vision tasks in the closed world. However, novel classes emerge from time to time in our ever-changing world, requiring a learning system to acquire new knowledge continually. For example, a robot needs to understand new instructions, and an opinion monitoring system should analyze emerging topics every day. Class-Incremental Learning (CIL) enables the learner to incorporate the knowledge of new classes incrementally and build a universal classifier among all seen classes. Correspondingly, when directly training the model with new class instances, a fatal problem occurs -- the model tends to catastrophically forget the characteristics of former ones, and its performance drastically degrades. There have been numerous efforts to tackle catastrophic forgetting in the machine learning community. In this paper, we survey comprehensively recent advances in deep class-incremental learning and summarize these methods from three aspects, i.e., data-centric, model-centric, and algorithm-centric. We also provide a rigorous and unified evaluation of 16 methods in benchmark image classification tasks to find out the characteristics of different algorithms empirically. Furthermore, we notice that the current comparison protocol ignores the influence of memory budget in model storage, which may result in unfair comparison and biased results. Hence, we advocate fair comparison by aligning the memory budget in evaluation, as well as several memory-agnostic performance measures. The source code to reproduce these evaluations is available at https://github.com/zhoudw-zdw/CIL_Survey/
Formalising and Learning a Quantum Model of Concepts
Feb 07, 2023

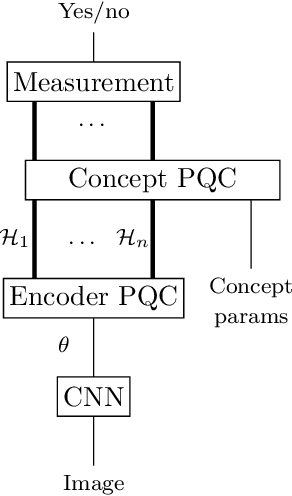
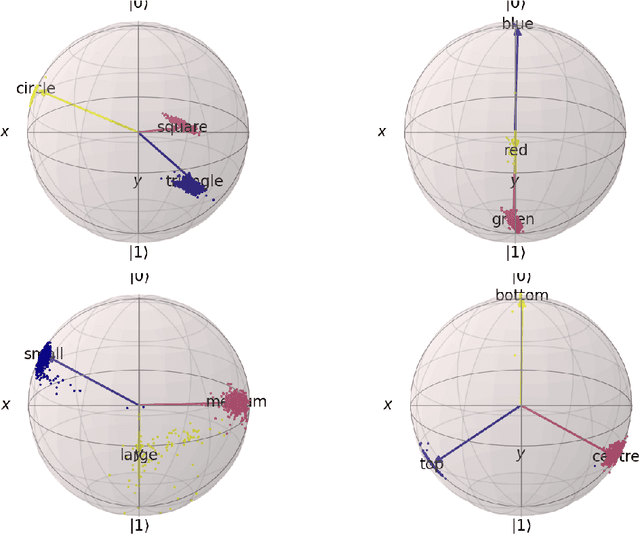
In this report we present a new modelling framework for concepts based on quantum theory, and demonstrate how the conceptual representations can be learned automatically from data. A contribution of the work is a thorough category-theoretic formalisation of our framework. We claim that the use of category theory, and in particular the use of string diagrams to describe quantum processes, helps elucidate some of the most important features of our quantum approach to concept modelling. Our approach builds upon Gardenfors' classical framework of conceptual spaces, in which cognition is modelled geometrically through the use of convex spaces, which in turn factorise in terms of simpler spaces called domains. We show how concepts from the domains of shape, colour, size and position can be learned from images of simple shapes, where individual images are represented as quantum states and concepts as quantum effects. Concepts are learned by a hybrid classical-quantum network trained to perform concept classification, where the classical image processing is carried out by a convolutional neural network and the quantum representations are produced by a parameterised quantum circuit. We also use discarding to produce mixed effects, which can then be used to learn concepts which only apply to a subset of the domains, and show how entanglement (together with discarding) can be used to capture interesting correlations across domains. Finally, we consider the question of whether our quantum models of concepts can be considered conceptual spaces in the Gardenfors sense.
What Does a One-Bit Quanta Image Sensor Offer?
Aug 19, 2022

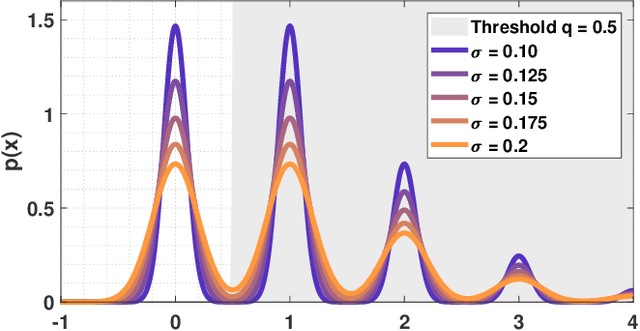
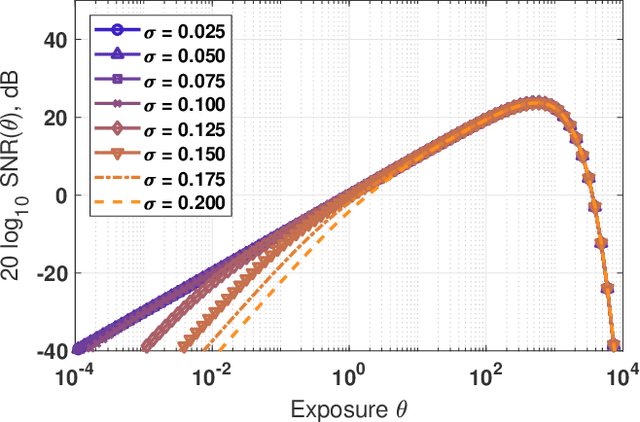
The one-bit quanta image sensor (QIS) is a photon-counting device that captures image intensities using binary bits. Assuming that the analog voltage generated at the floating diffusion of the photodiode follows a Poisson-Gaussian distribution, the sensor produces either a ``1'' if the voltage is above a certain threshold or ``0'' if it is below the threshold. The concept of this binary sensor has been proposed for more than a decade, and physical devices have been built to realize the concept. However, what benefits does a one-bit QIS offer compared to a conventional multi-bit CMOS image sensor? Besides the known empirical results, are there theoretical proofs to support these findings? The goal of this paper is to provide new theoretical support from a signal processing perspective. In particular, it is theoretically found that the sensor can offer three benefits: (1) Low-light: One-bit QIS performs better at low-light because it has a low read noise, and its one-bit quantization can produce an error-free measurement. However, this requires the exposure time to be appropriately configured. (2) Frame rate: One-bit sensors can operate at a much higher speed because a response is generated as soon as a photon is detected. However, in the presence of read noise, there exists an optimal frame rate beyond which the performance will degrade. A Closed-form expression of the optimal frame rate is derived. (3) Dynamic range: One-bit QIS offers a higher dynamic range. The benefit is brought by two complementary characteristics of the sensor: nonlinearity and exposure bracketing. The decoupling of the two factors is theoretically proved, and closed-form expressions are derived.
Advancing Radiograph Representation Learning with Masked Record Modeling
Jan 30, 2023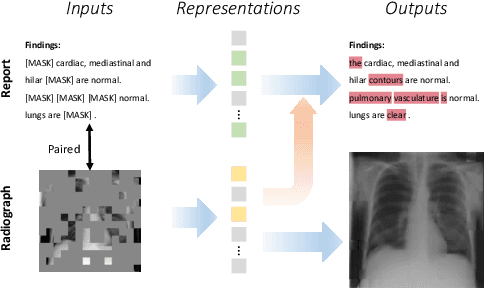
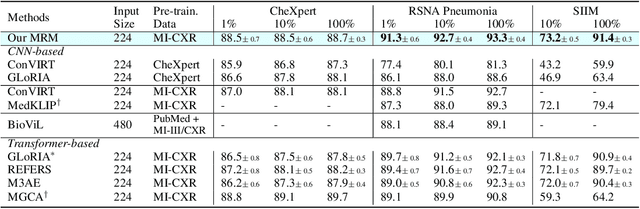
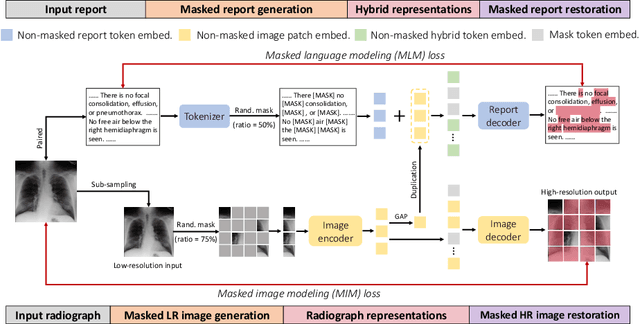
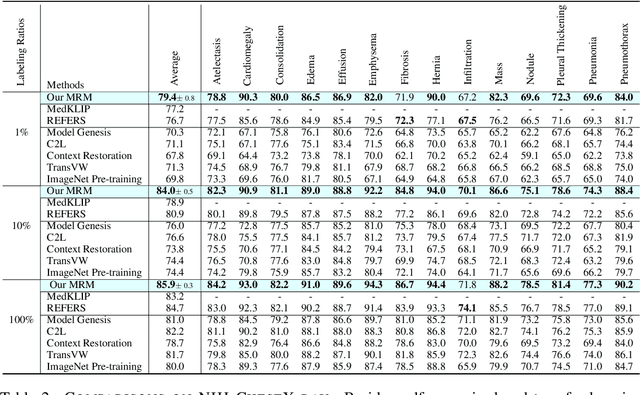
Modern studies in radiograph representation learning rely on either self-supervision to encode invariant semantics or associated radiology reports to incorporate medical expertise, while the complementarity between them is barely noticed. To explore this, we formulate the self- and report-completion as two complementary objectives and present a unified framework based on masked record modeling (MRM). In practice, MRM reconstructs masked image patches and masked report tokens following a multi-task scheme to learn knowledge-enhanced semantic representations. With MRM pre-training, we obtain pre-trained models that can be well transferred to various radiography tasks. Specifically, we find that MRM offers superior performance in label-efficient fine-tuning. For instance, MRM achieves 88.5% mean AUC on CheXpert using 1% labeled data, outperforming previous R$^2$L methods with 100% labels. On NIH ChestX-ray, MRM outperforms the best performing counterpart by about 3% under small labeling ratios. Besides, MRM surpasses self- and report-supervised pre-training in identifying the pneumonia type and the pneumothorax area, sometimes by large margins.
Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models
Jan 30, 2023
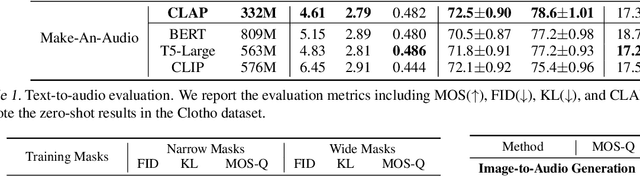
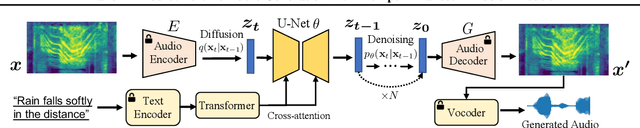
Large-scale multimodal generative modeling has created milestones in text-to-image and text-to-video generation. Its application to audio still lags behind for two main reasons: the lack of large-scale datasets with high-quality text-audio pairs, and the complexity of modeling long continuous audio data. In this work, we propose Make-An-Audio with a prompt-enhanced diffusion model that addresses these gaps by 1) introducing pseudo prompt enhancement with a distill-then-reprogram approach, it alleviates data scarcity with orders of magnitude concept compositions by using language-free audios; 2) leveraging spectrogram autoencoder to predict the self-supervised audio representation instead of waveforms. Together with robust contrastive language-audio pretraining (CLAP) representations, Make-An-Audio achieves state-of-the-art results in both objective and subjective benchmark evaluation. Moreover, we present its controllability and generalization for X-to-Audio with "No Modality Left Behind", for the first time unlocking the ability to generate high-definition, high-fidelity audios given a user-defined modality input. Audio samples are available at https://Text-to-Audio.github.io