 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Beyond Statistical Similarity: Rethinking Metrics for Deep Generative Models in Engineering Design
Feb 11, 2023
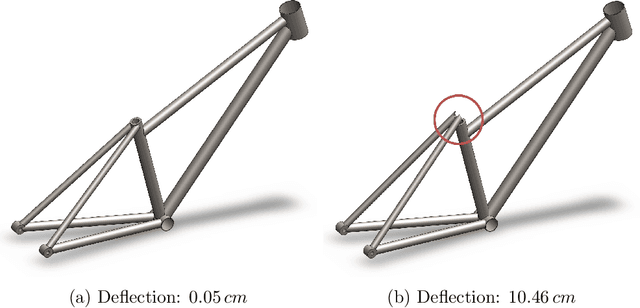
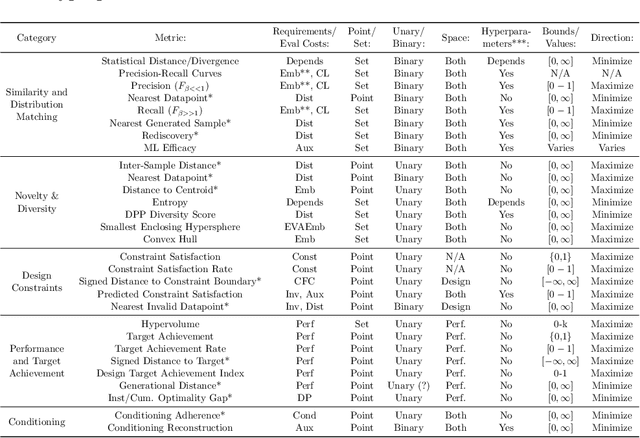
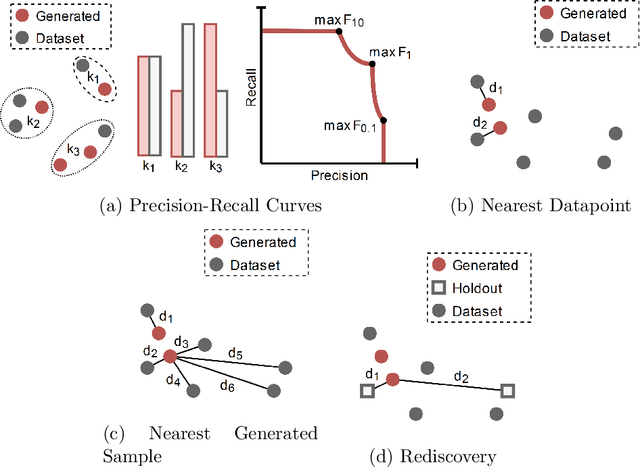
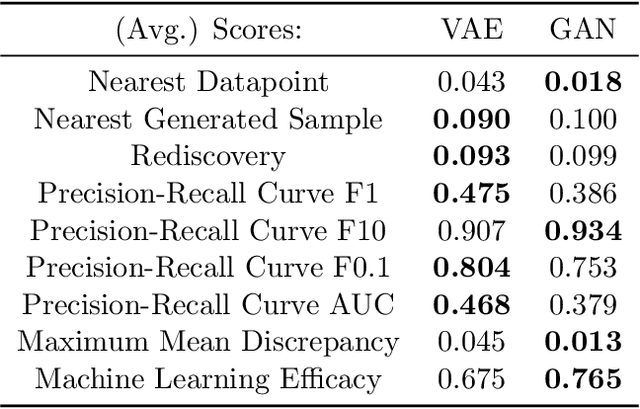
Deep generative models, such as Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), Diffusion Models, and Transformers, have shown great promise in a variety of applications, including image and speech synthesis, natural language processing, and drug discovery. However, when applied to engineering design problems, evaluating the performance of these models can be challenging, as traditional statistical metrics based on likelihood may not fully capture the requirements of engineering applications. This paper doubles as a review and a practical guide to evaluation metrics for deep generative models (DGMs) in engineering design. We first summarize well-accepted `classic' evaluation metrics for deep generative models grounded in machine learning theory and typical computer science applications. Using case studies, we then highlight why these metrics seldom translate well to design problems but see frequent use due to the lack of established alternatives. Next, we curate a set of design-specific metrics which have been proposed across different research communities and can be used for evaluating deep generative models. These metrics focus on unique requirements in design and engineering, such as constraint satisfaction, functional performance, novelty, and conditioning. We structure our review and discussion as a set of practical selection criteria and usage guidelines. Throughout our discussion, we apply the metrics to models trained on simple 2-dimensional example problems. Finally, to illustrate the selection process and classic usage of the presented metrics, we evaluate three deep generative models on a multifaceted bicycle frame design problem considering performance target achievement, design novelty, and geometric constraints. We publicly release the code for the datasets, models, and metrics used throughout the paper at decode.mit.edu/projects/metrics/.
Investigating Pulse-Echo Sound Speed Estimation in Breast Ultrasound with Deep Learning
Feb 06, 2023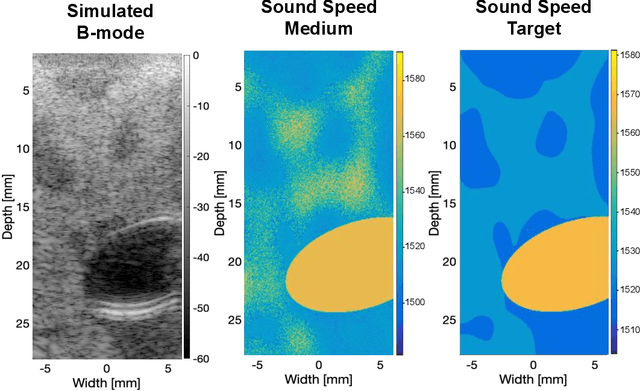

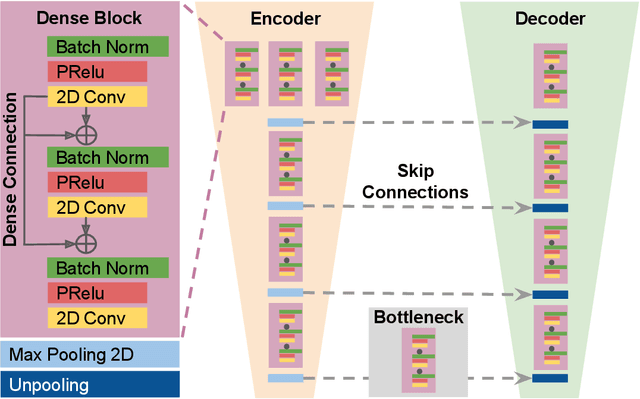
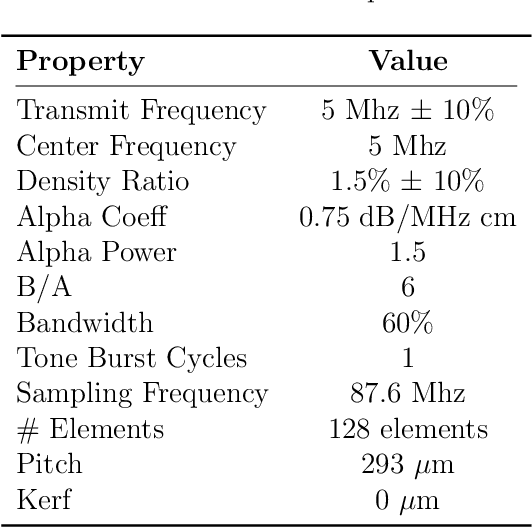
Ultrasound is an adjunct tool to mammography that can quickly and safely aid physicians with diagnosing breast abnormalities. Clinical ultrasound often assumes a constant sound speed to form B-mode images for diagnosis. However, the various types of breast tissue, such as glandular, fat, and lesions, differ in sound speed. These differences can degrade the image reconstruction process. Alternatively, sound speed can be a powerful tool for identifying disease. To this end, we propose a deep-learning approach for sound speed estimation from in-phase and quadrature ultrasound signals. First, we develop a large-scale simulated ultrasound dataset that generates quasi-realistic breast tissue by modeling breast gland, skin, and lesions with varying echogenicity and sound speed. We developed a fully convolutional neural network architecture trained on a simulated dataset to produce an estimated sound speed map from inputting three complex-value in-phase and quadrature ultrasound images formed from plane-wave transmissions at separate angles. Furthermore, thermal noise augmentation is used during model optimization to enhance generalizability to real ultrasound data. We evaluate the model on simulated, phantom, and in-vivo breast ultrasound data, demonstrating its ability to accurately estimate sound speeds consistent with previously reported values in the literature. Our simulated dataset and model will be publicly available to provide a step towards accurate and generalizable sound speed estimation for pulse-echo ultrasound imaging.
Robust Implementation of Foreground Extraction and Vessel Segmentation for X-ray Coronary Angiography Image Sequence
Sep 15, 2022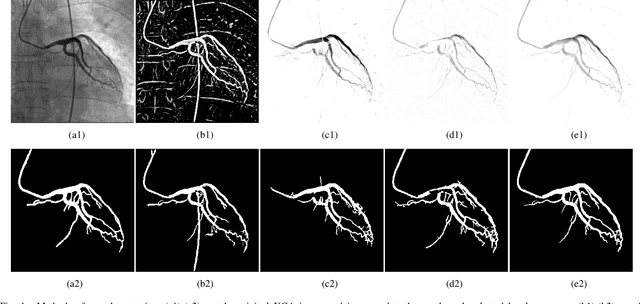
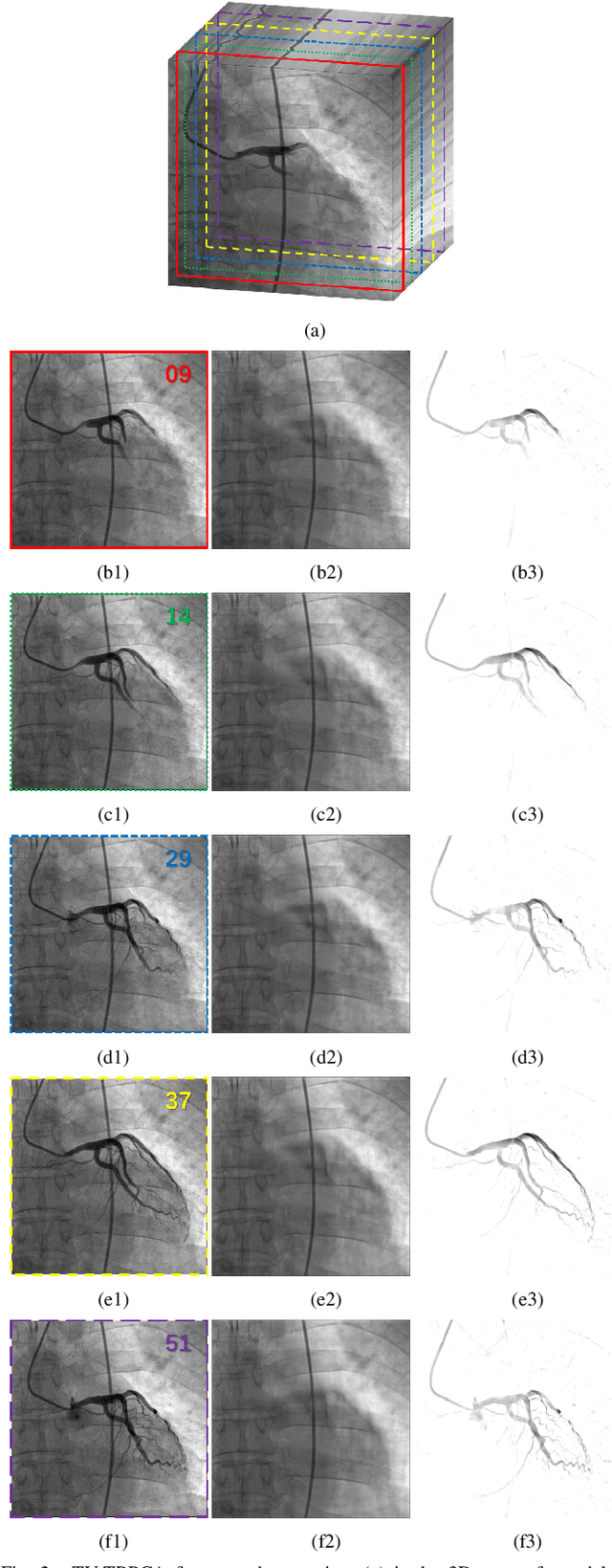
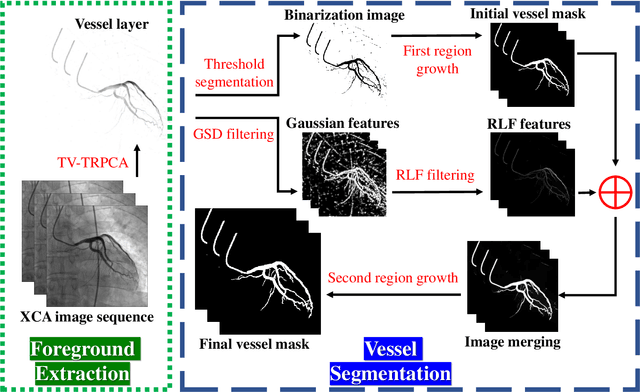

The extraction of contrast-filled vessels from X-ray coronary angiography(XCA) image sequence has important clinical significance for intuitively diagnosis and therapy. In this study, XCA image sequence O is regarded as a three-dimensional tensor input, vessel layer H is a sparse tensor, and background layer B is a low-rank tensor. Using tensor nuclear norm(TNN) minimization, a novel method for vessel layer extraction based on tensor robust principal component analysis(TRPCA) is proposed. Furthermore, considering the irregular movement of vessels and the dynamic interference of surrounding irrelevant tissues, the total variation(TV) regularized spatial-temporal constraint is introduced to separate the dynamic background E. Subsequently, for the vessel images with uneven contrast distribution, a two-stage region growth(TSRG) method is utilized for vessel enhancement and segmentation. A global threshold segmentation is used as the pre-processing to obtain the main branch, and the Radon-Like features(RLF) filter is used to enhance and connect broken minor segments, the final vessel mask is constructed by combining the two intermediate results. We evaluated the visibility of TV-TRPCA algorithm for foreground extraction and the accuracy of TSRG algorithm for vessel segmentation on real clinical XCA image sequences and third-party database. Both qualitative and quantitative results verify the superiority of the proposed methods over the existing state-of-the-art approaches.
Robust Real-World Image Super-Resolution against Adversarial Attacks
Jul 31, 2022
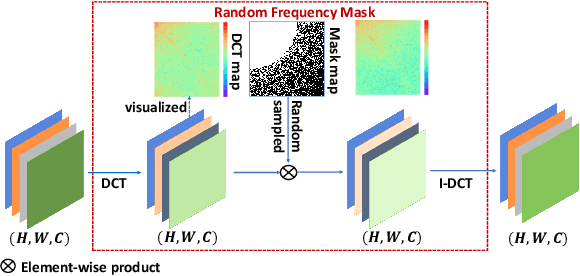
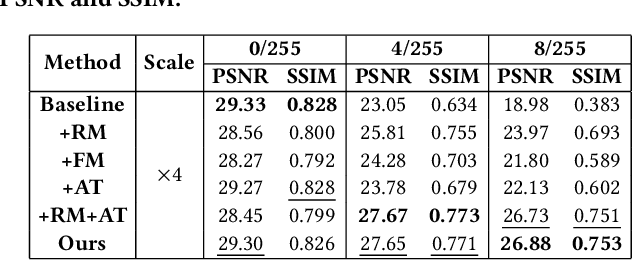
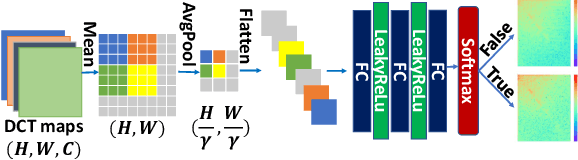
Recently deep neural networks (DNNs) have achieved significant success in real-world image super-resolution (SR). However, adversarial image samples with quasi-imperceptible noises could threaten deep learning SR models. In this paper, we propose a robust deep learning framework for real-world SR that randomly erases potential adversarial noises in the frequency domain of input images or features. The rationale is that on the SR task clean images or features have a different pattern from the attacked ones in the frequency domain. Observing that existing adversarial attacks usually add high-frequency noises to input images, we introduce a novel random frequency mask module that blocks out high-frequency components possibly containing the harmful perturbations in a stochastic manner. Since the frequency masking may not only destroys the adversarial perturbations but also affects the sharp details in a clean image, we further develop an adversarial sample classifier based on the frequency domain of images to determine if applying the proposed mask module. Based on the above ideas, we devise a novel real-world image SR framework that combines the proposed frequency mask modules and the proposed adversarial classifier with an existing super-resolution backbone network. Experiments show that our proposed method is more insensitive to adversarial attacks and presents more stable SR results than existing models and defenses.
* ACM-MM 2021, Code: https://github.com/lhaof/Robust-SR-against-Adversarial-Attacks
Learning Universal Policies via Text-Guided Video Generation
Feb 02, 2023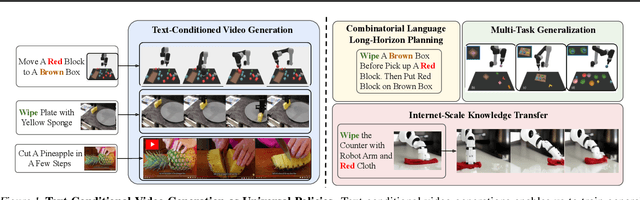
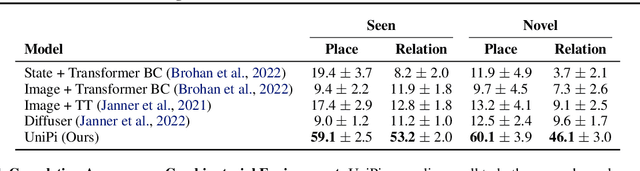
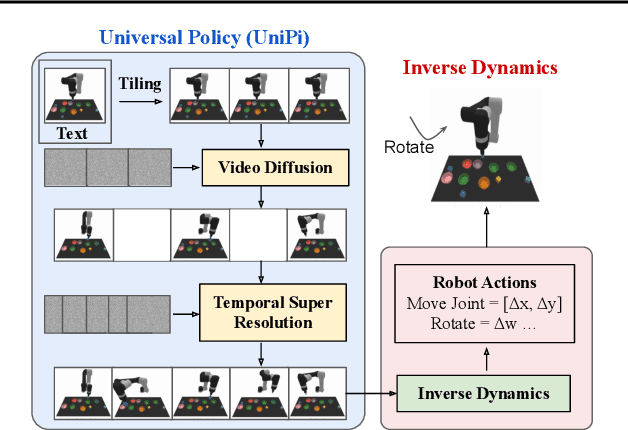
A goal of artificial intelligence is to construct an agent that can solve a wide variety of tasks. Recent progress in text-guided image synthesis has yielded models with an impressive ability to generate complex novel images, exhibiting combinatorial generalization across domains. Motivated by this success, we investigate whether such tools can be used to construct more general-purpose agents. Specifically, we cast the sequential decision making problem as a text-conditioned video generation problem, where, given a text-encoded specification of a desired goal, a planner synthesizes a set of future frames depicting its planned actions in the future, after which control actions are extracted from the generated video. By leveraging text as the underlying goal specification, we are able to naturally and combinatorially generalize to novel goals. The proposed policy-as-video formulation can further represent environments with different state and action spaces in a unified space of images, which, for example, enables learning and generalization across a variety of robot manipulation tasks. Finally, by leveraging pretrained language embeddings and widely available videos from the internet, the approach enables knowledge transfer through predicting highly realistic video plans for real robots.
Self-Supervised Relation Alignment for Scene Graph Generation
Feb 02, 2023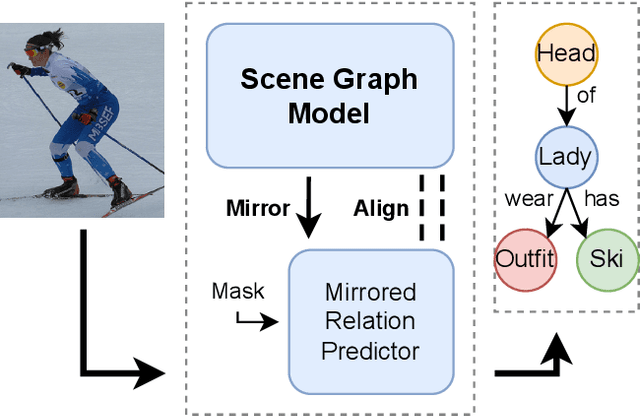
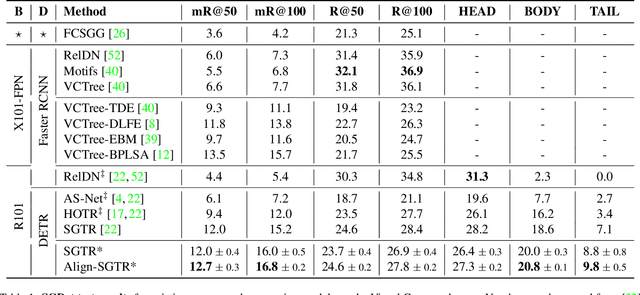
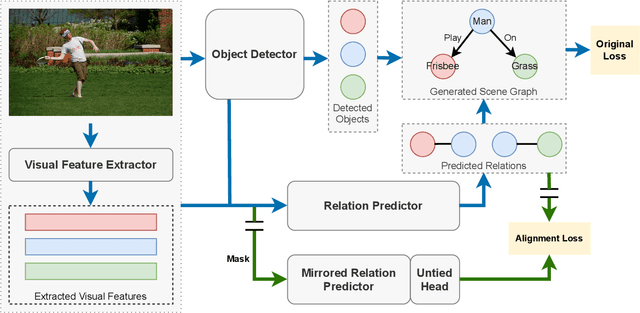
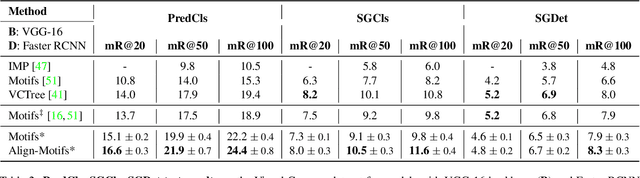
The goal of scene graph generation is to predict a graph from an input image, where nodes correspond to identified and localized objects and edges to their corresponding interaction predicates. Existing methods are trained in a fully supervised manner and focus on message passing mechanisms, loss functions, and/or bias mitigation. In this work we introduce a simple-yet-effective self-supervised relational alignment regularization designed to improve the scene graph generation performance. The proposed alignment is general and can be combined with any existing scene graph generation framework, where it is trained alongside the original model's objective. The alignment is achieved through distillation, where an auxiliary relation prediction branch, that mirrors and shares parameters with the supervised counterpart, is designed. In the auxiliary branch, relational input features are partially masked prior to message passing and predicate prediction. The predictions for masked relations are then aligned with the supervised counterparts after the message passing. We illustrate the effectiveness of this self-supervised relational alignment in conjunction with two scene graph generation architectures, SGTR and Neural Motifs, and show that in both cases we achieve significantly improved performance.
Memory-Guided Collaborative Attention for Nighttime Thermal Infrared Image Colorization
Aug 05, 2022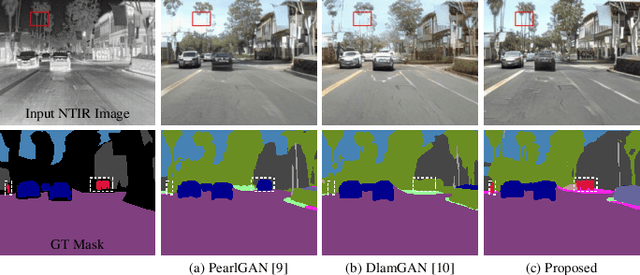
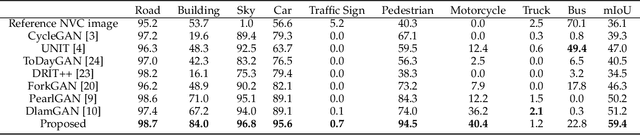
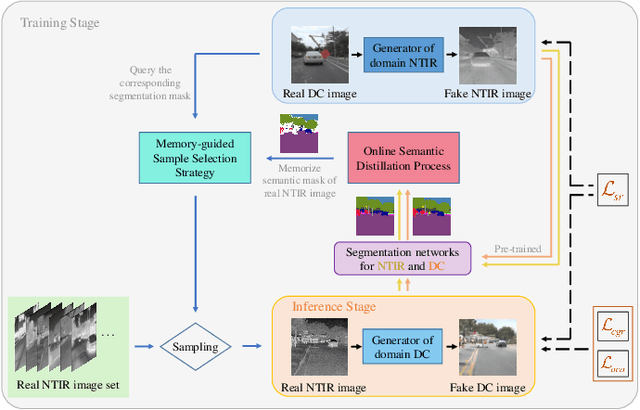
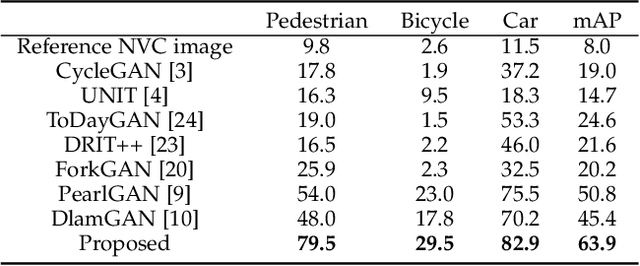
Nighttime thermal infrared (NTIR) image colorization, also known as translation of NTIR images into daytime color images (NTIR2DC), is a promising research direction to facilitate nighttime scene perception for humans and intelligent systems under unfavorable conditions (e.g., complete darkness). However, previously developed methods have poor colorization performance for small sample classes. Moreover, reducing the high confidence noise in pseudo-labels and addressing the problem of image gradient disappearance during translation are still under-explored, and keeping edges from being distorted during translation is also challenging. To address the aforementioned issues, we propose a novel learning framework called Memory-guided cOllaboRative atteNtion Generative Adversarial Network (MornGAN), which is inspired by the analogical reasoning mechanisms of humans. Specifically, a memory-guided sample selection strategy and adaptive collaborative attention loss are devised to enhance the semantic preservation of small sample categories. In addition, we propose an online semantic distillation module to mine and refine the pseudo-labels of NTIR images. Further, conditional gradient repair loss is introduced for reducing edge distortion during translation. Extensive experiments on the NTIR2DC task show that the proposed MornGAN significantly outperforms other image-to-image translation methods in terms of semantic preservation and edge consistency, which helps improve the object detection accuracy remarkably.
GDB: Gated convolutions-based Document Binarization
Feb 04, 2023
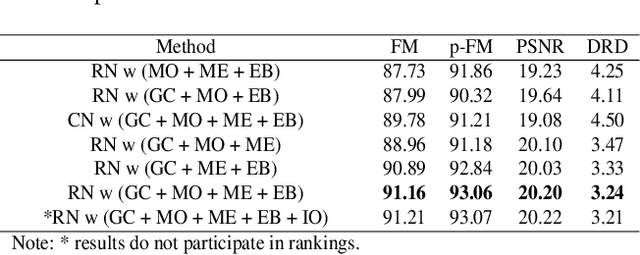
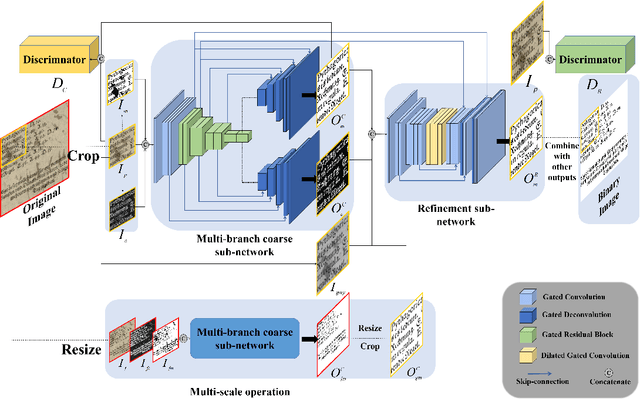
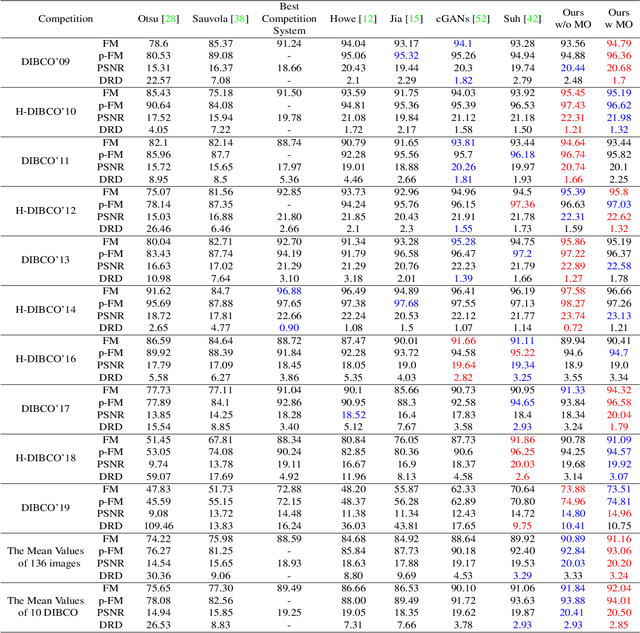
Document binarization is a key pre-processing step for many document analysis tasks. However, existing methods can not extract stroke edges finely, mainly due to the fair-treatment nature of vanilla convolutions and the extraction of stroke edges without adequate supervision by boundary-related information. In this paper, we formulate text extraction as the learning of gating values and propose an end-to-end gated convolutions-based network (GDB) to solve the problem of imprecise stroke edge extraction. The gated convolutions are applied to selectively extract the features of strokes with different attention. Our proposed framework consists of two stages. Firstly, a coarse sub-network with an extra edge branch is trained to get more precise feature maps by feeding a priori mask and edge. Secondly, a refinement sub-network is cascaded to refine the output of the first stage by gated convolutions based on the sharp edge. For global information, GDB also contains a multi-scale operation to combine local and global features. We conduct comprehensive experiments on ten Document Image Binarization Contest (DIBCO) datasets from 2009 to 2019. Experimental results show that our proposed methods outperform the state-of-the-art methods in terms of all metrics on average and achieve top ranking on six benchmark datasets.
Efficient Visual Computing with Camera RAW Snapshots
Dec 15, 2022
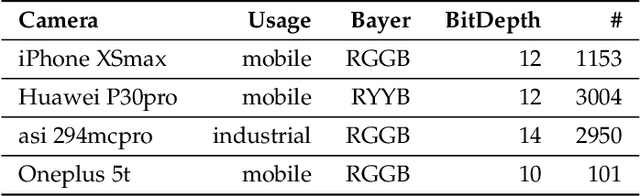

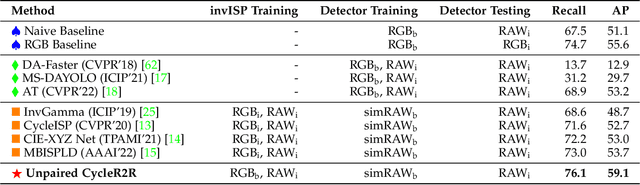
Conventional cameras capture image irradiance on a sensor and convert it to RGB images using an image signal processor (ISP). The images can then be used for photography or visual computing tasks in a variety of applications, such as public safety surveillance and autonomous driving. One can argue that since RAW images contain all the captured information, the conversion of RAW to RGB using an ISP is not necessary for visual computing. In this paper, we propose a novel $\rho$-Vision framework to perform high-level semantic understanding and low-level compression using RAW images without the ISP subsystem used for decades. Considering the scarcity of available RAW image datasets, we first develop an unpaired CycleR2R network based on unsupervised CycleGAN to train modular unrolled ISP and inverse ISP (invISP) models using unpaired RAW and RGB images. We can then flexibly generate simulated RAW images (simRAW) using any existing RGB image dataset and finetune different models originally trained for the RGB domain to process real-world camera RAW images. We demonstrate object detection and image compression capabilities in RAW-domain using RAW-domain YOLOv3 and RAW image compressor (RIC) on snapshots from various cameras. Quantitative results reveal that RAW-domain task inference provides better detection accuracy and compression compared to RGB-domain processing. Furthermore, the proposed \r{ho}-Vision generalizes across various camera sensors and different task-specific models. Additional advantages of the proposed $\rho$-Vision that eliminates the ISP are the potential reductions in computations and processing times.
ActiveLab: Active Learning with Re-Labeling by Multiple Annotators
Jan 27, 2023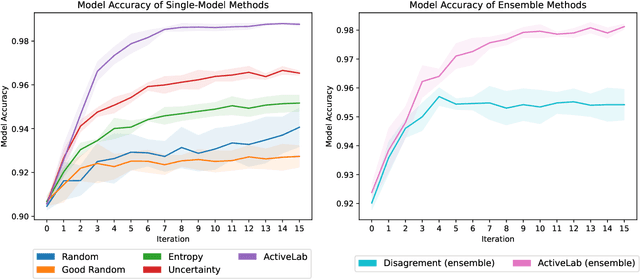
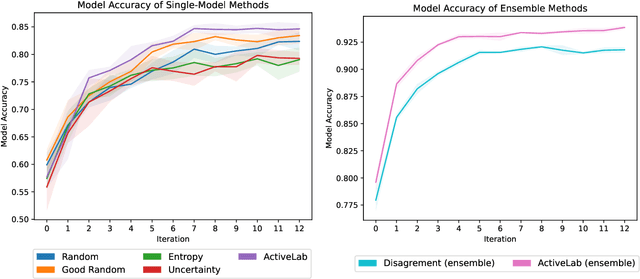
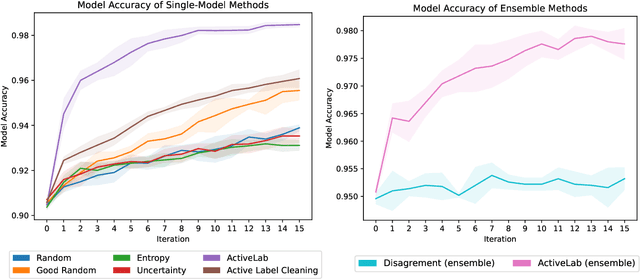
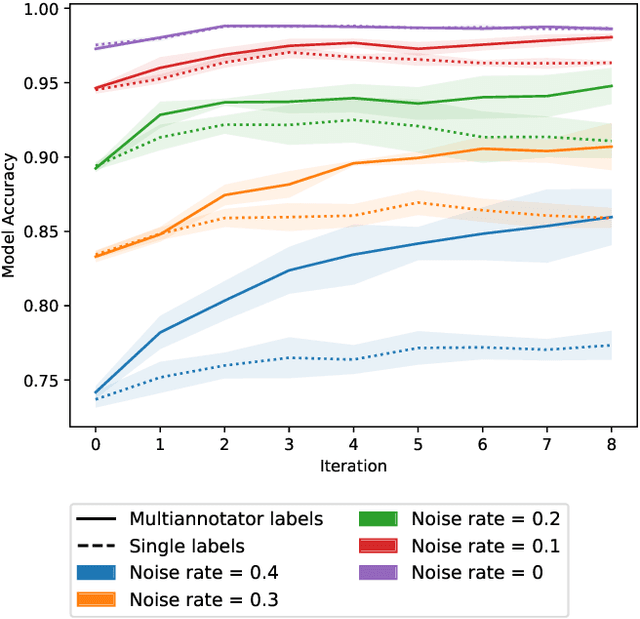
In real-world data labeling applications, annotators often provide imperfect labels. It is thus common to employ multiple annotators to label data with some overlap between their examples. We study active learning in such settings, aiming to train an accurate classifier by collecting a dataset with the fewest total annotations. Here we propose ActiveLab, a practical method to decide what to label next that works with any classifier model and can be used in pool-based batch active learning with one or multiple annotators. ActiveLab automatically estimates when it is more informative to re-label examples vs. labeling entirely new ones. This is a key aspect of producing high quality labels and trained models within a limited annotation budget. In experiments on image and tabular data, ActiveLab reliably trains more accurate classifiers with far fewer annotations than a wide variety of popular active learning methods.