 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
High-bandwidth Close-Range Information Transport through Light Pipes
Jan 19, 2023
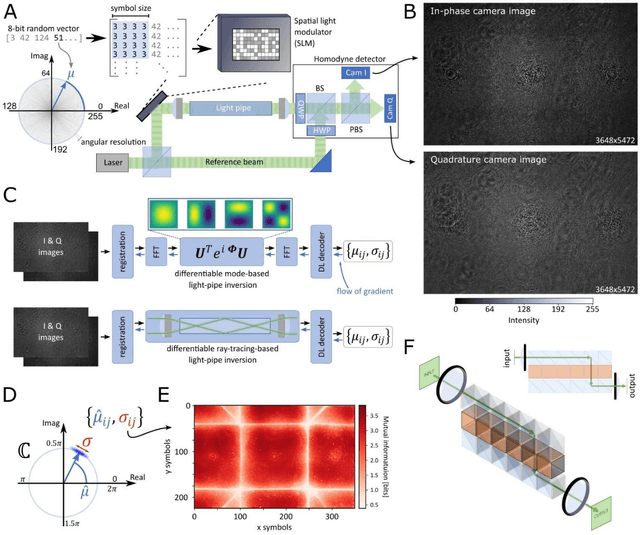
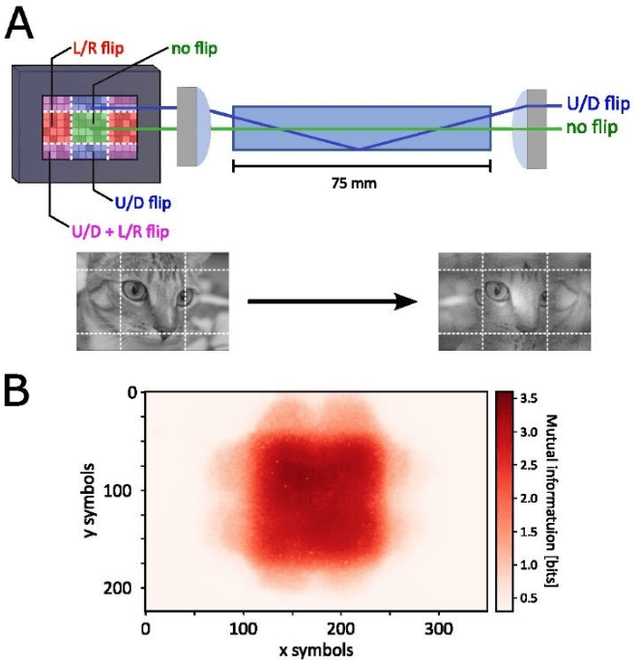

Image retrieval after propagation through multi-mode fibers is gaining attention due to their capacity to confine light and efficiently transport it over distances in a compact system. Here, we propose a generally applicable information-theoretic framework to transmit maximal-entropy (data) images and maximize the information transmission over sub-meter distances, a crucial capability that allows optical storage applications to scale and address different parts of storage media. To this end, we use millimeter-sized square optical waveguides to image a megapixel 8-bit spatial-light modulator. Data is thus represented as a 2D array of 8-bit values (symbols). Transmitting 100000s of symbols requires innovation beyond transmission matrix approaches. Deep neural networks have been recently utilized to retrieve images, but have been limited to small (thousands of symbols) and natural looking (low entropy) images. We maximize information transmission by combining a bandwidth-optimized homodyne detector with a differentiable hybrid neural-network consisting of a digital twin of the experiment setup and a U-Net. For the digital twin, we implement and compare a differentiable mode-based twin with a differentiable ray-based twin. Importantly, the latter can adapt to manufacturing-related setup imperfections during training which we show to be crucial. Our pipeline is trained end-to-end to recover digital input images while maximizing the achievable information page size based on a differentiable mutual-information estimator. We demonstrate retrieval of 66 kB at maximum with 1.7 bit per symbol on average with a range of 0.3 - 3.4 bit.
Prototypical Contrastive Language Image Pretraining
Jun 22, 2022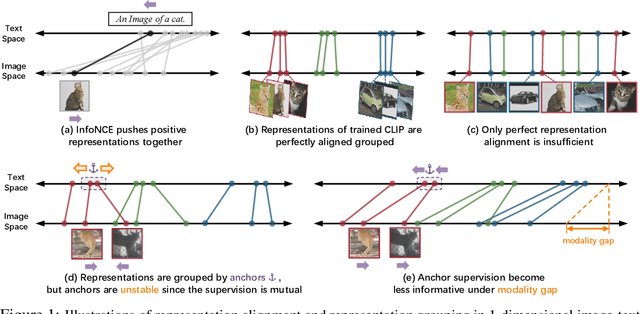
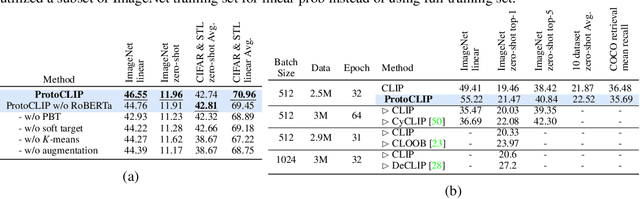

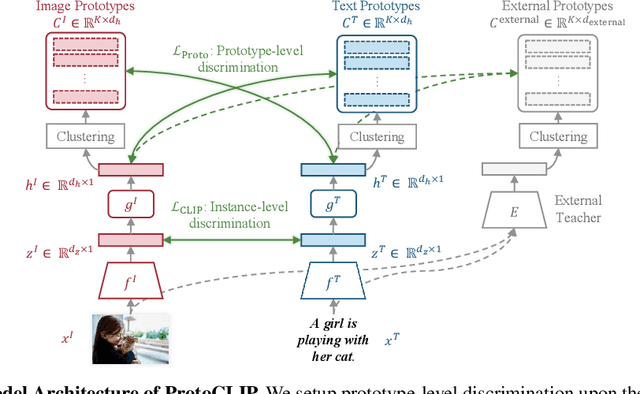
Contrastive Language Image Pretraining (CLIP) received widespread attention since its learned representations can be transferred well to various downstream tasks. During CLIP training, the InfoNCE objective aims to align positive image-text pairs and separate negative ones. In this paper, we show a representation grouping effect during this process: the InfoNCE objective indirectly groups semantically similar representations together via randomly emerged within-modal anchors. We introduce Prototypical Contrastive Language Image Pretraining (ProtoCLIP) to enhance such grouping by boosting its efficiency and increasing its robustness against modality gap. Specifically, ProtoCLIP sets up prototype-level discrimination between image and text spaces, which efficiently transfers higher-level structural knowledge. We further propose Prototypical Back Translation (PBT) to decouple representation grouping from representation alignment, resulting in effective learning of meaningful representations under large modality gap. PBT also enables us to introduce additional external teachers with richer prior knowledge. ProtoCLIP is trained with an online episodic training strategy, which makes it can be scaled up to unlimited amounts of data. Combining the above novel designs, we train our ProtoCLIP on Conceptual Captions and achieved an +5.81% ImageNet linear probing improvement and an +2.01% ImageNet zero-shot classification improvement. Codes are available at https://github.com/megvii-research/protoclip.
Conditional Flow Matching: Simulation-Free Dynamic Optimal Transport
Feb 01, 2023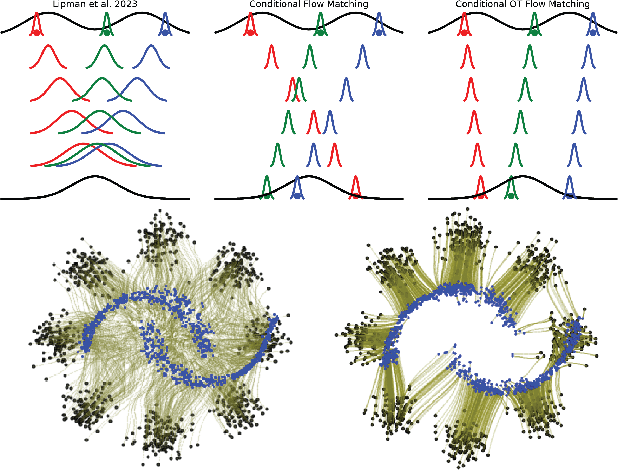

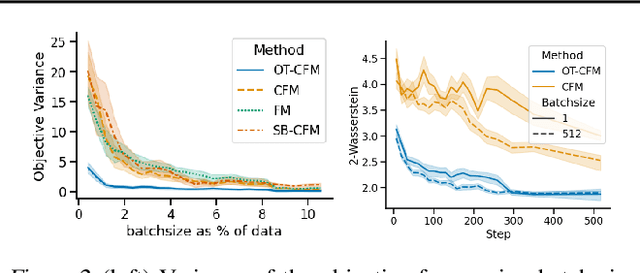
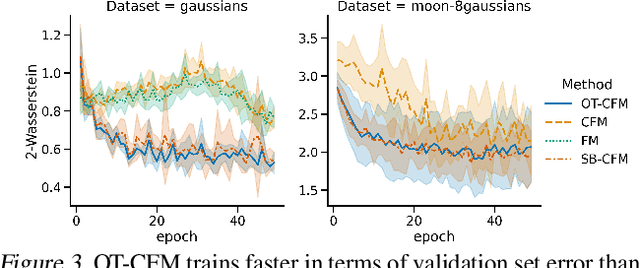
Continuous normalizing flows (CNFs) are an attractive generative modeling technique, but they have thus far been held back by limitations in their simulation-based maximum likelihood training. In this paper, we introduce a new technique called conditional flow matching (CFM), a simulation-free training objective for CNFs. CFM features a stable regression objective like that used to train the stochastic flow in diffusion models but enjoys the efficient inference of deterministic flow models. In contrast to both diffusion models and prior CNF training algorithms, our CFM objective does not require the source distribution to be Gaussian or require evaluation of its density. Based on this new objective, we also introduce optimal transport CFM (OT-CFM), which creates simpler flows that are more stable to train and lead to faster inference, as evaluated in our experiments. Training CNFs with CFM improves results on a variety of conditional and unconditional generation tasks such as inferring single cell dynamics, unsupervised image translation, and Schr\"odinger bridge inference. Code is available at https://github.com/atong01/conditional-flow-matching .
Density peak clustering using tensor network
Feb 01, 2023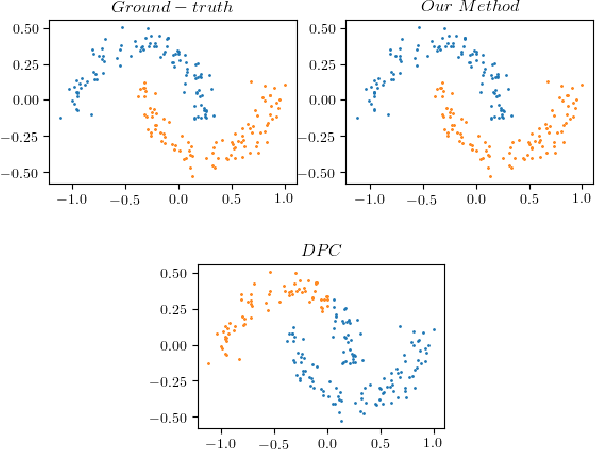
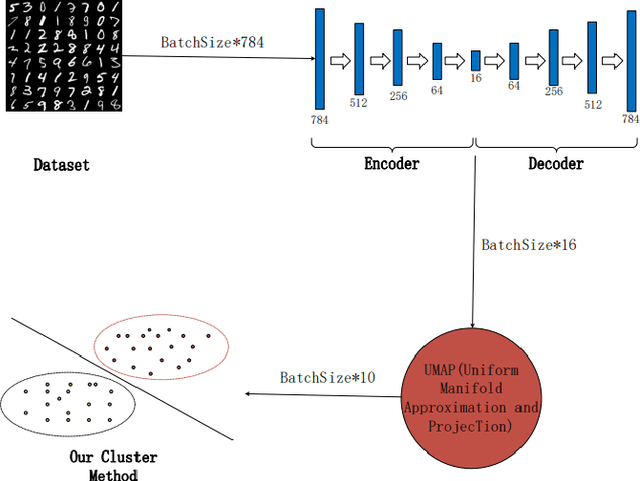
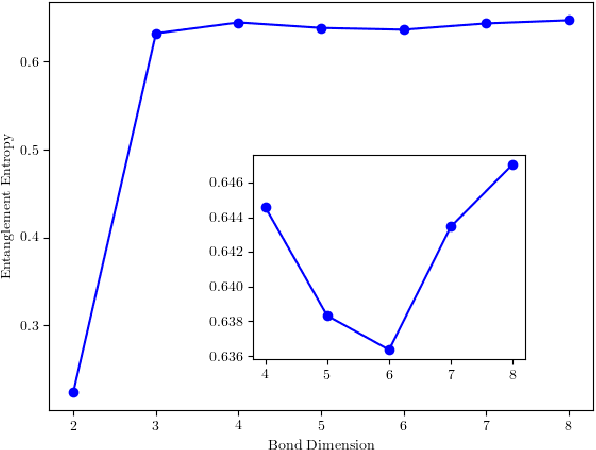
Tensor networks, which have been traditionally used to simulate many-body physics, have recently gained significant attention in the field of machine learning due to their powerful representation capabilities. In this work, we propose a density-based clustering algorithm inspired by tensor networks. We encode classical data into tensor network states on an extended Hilbert space and train the tensor network states to capture the features of the clusters. Here, we define density and related concepts in terms of fidelity, rather than using a classical distance measure. We evaluate the performance of our algorithm on six synthetic data sets, four real world data sets, and three commonly used computer vision data sets. The results demonstrate that our method provides state-of-the-art performance on several synthetic data sets and real world data sets, even when the number of clusters is unknown. Additionally, our algorithm performs competitively with state-of-the-art algorithms on the MNIST, USPS, and Fashion-MNIST image data sets. These findings reveal the great potential of tensor networks for machine learning applications.
Multi-view Kernel PCA for Time series Forecasting
Jan 24, 2023
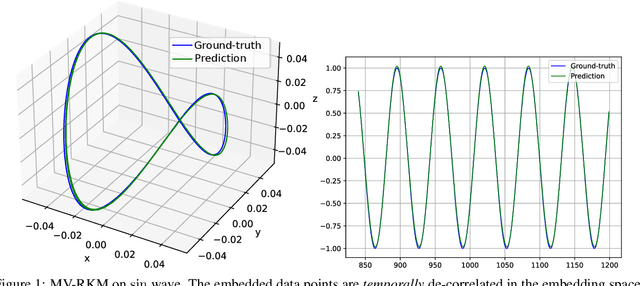
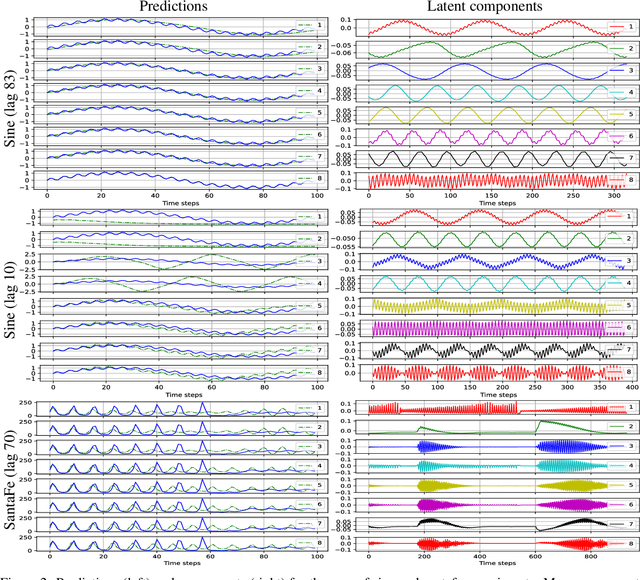
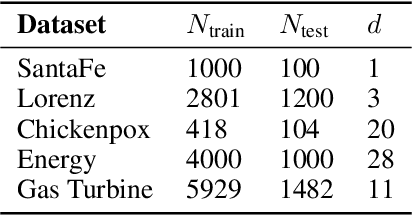
In this paper, we propose a kernel principal component analysis model for multi-variate time series forecasting, where the training and prediction schemes are derived from the multi-view formulation of Restricted Kernel Machines. The training problem is simply an eigenvalue decomposition of the summation of two kernel matrices corresponding to the views of the input and output data. When a linear kernel is used for the output view, it is shown that the forecasting equation takes the form of kernel ridge regression. When that kernel is non-linear, a pre-image problem has to be solved to forecast a point in the input space. We evaluate the model on several standard time series datasets, perform ablation studies, benchmark with closely related models and discuss its results.
Learning Multimodal Data Augmentation in Feature Space
Dec 29, 2022

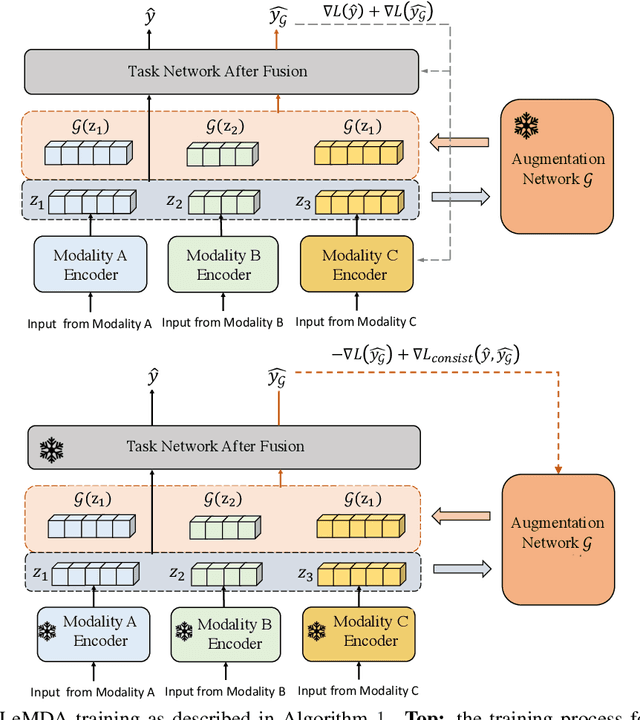
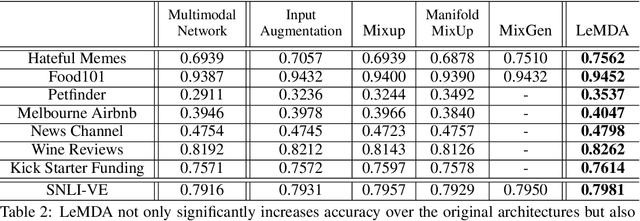
The ability to jointly learn from multiple modalities, such as text, audio, and visual data, is a defining feature of intelligent systems. While there have been promising advances in designing neural networks to harness multimodal data, the enormous success of data augmentation currently remains limited to single-modality tasks like image classification. Indeed, it is particularly difficult to augment each modality while preserving the overall semantic structure of the data; for example, a caption may no longer be a good description of an image after standard augmentations have been applied, such as translation. Moreover, it is challenging to specify reasonable transformations that are not tailored to a particular modality. In this paper, we introduce LeMDA, Learning Multimodal Data Augmentation, an easy-to-use method that automatically learns to jointly augment multimodal data in feature space, with no constraints on the identities of the modalities or the relationship between modalities. We show that LeMDA can (1) profoundly improve the performance of multimodal deep learning architectures, (2) apply to combinations of modalities that have not been previously considered, and (3) achieve state-of-the-art results on a wide range of applications comprised of image, text, and tabular data.
Efficient Modeling of Future Context for Image Captioning
Jul 22, 2022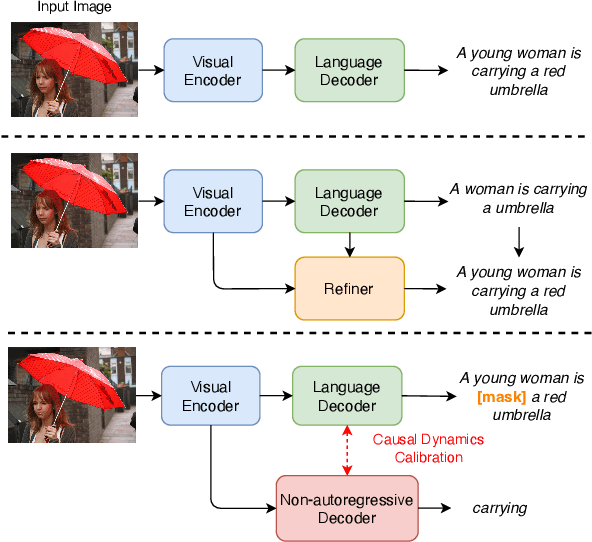

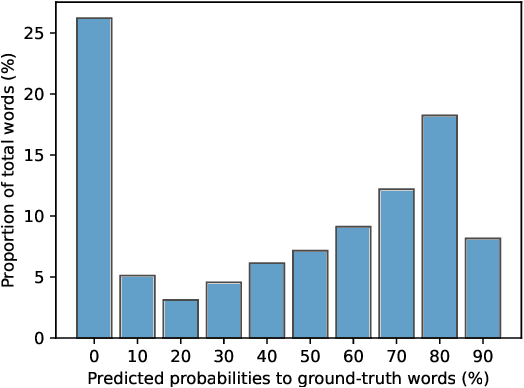
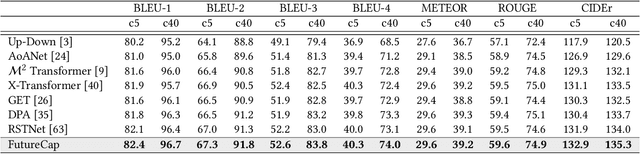
Existing approaches to image captioning usually generate the sentence word-by-word from left to right, with the constraint of conditioned on local context including the given image and history generated words. There have been many studies target to make use of global information during decoding, e.g., iterative refinement. However, it is still under-explored how to effectively and efficiently incorporate the future context. To respond to this issue, inspired by that Non-Autoregressive Image Captioning (NAIC) can leverage two-side relation with modified mask operation, we aim to graft this advance to the conventional Autoregressive Image Captioning (AIC) model while maintaining the inference efficiency without extra time cost. Specifically, AIC and NAIC models are first trained combined with shared visual encoders, forcing the visual encoder to contain sufficient and valid future context; then the AIC model is encouraged to capture the causal dynamics of cross-layer interchanging from NAIC model on its unconfident words, which follows a teacher-student paradigm and optimized with the distribution calibration training objective. Empirical evidences demonstrate that our proposed approach clearly surpass the state-of-the-art baselines in both automatic metrics and human evaluations on the MS COCO benchmark. The source code is available at: https://github.com/feizc/Future-Caption.
Swin MAE: Masked Autoencoders for Small Datasets
Jan 05, 2023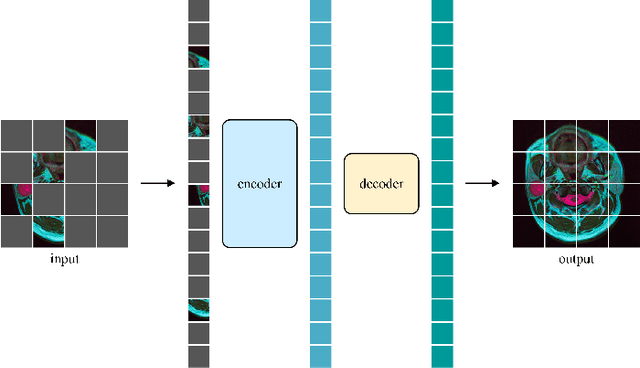
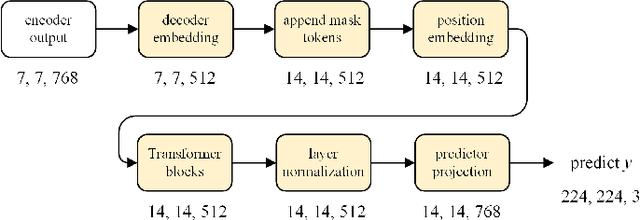
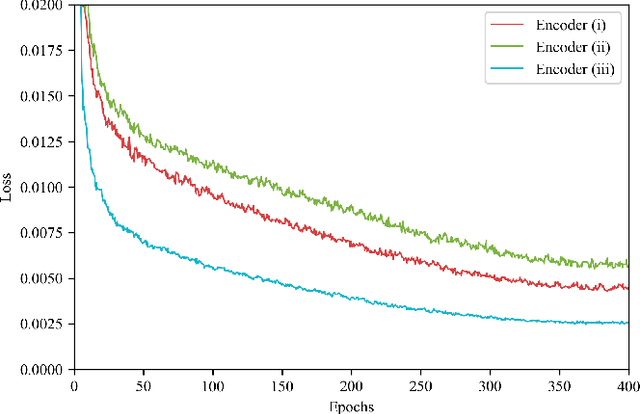
The development of deep learning models in medical image analysis is majorly limited by the lack of large-sized and well-annotated datasets. Unsupervised learning does not require labels and is more suitable for solving medical image analysis problems. However, most of the current unsupervised learning methods need to be applied to large datasets. To make unsupervised learning applicable to small datasets, we proposed Swin MAE, which is a masked autoencoder with Swin Transformer as its backbone. Even on a dataset of only a few thousand medical images and without using any pre-trained models, Swin MAE is still able to learn useful semantic features purely from images. It can equal or even slightly outperform the supervised model obtained by Swin Transformer trained on ImageNet in terms of the transfer learning results of downstream tasks. The code is publicly available at https://github.com/Zian-Xu/Swin-MAE.
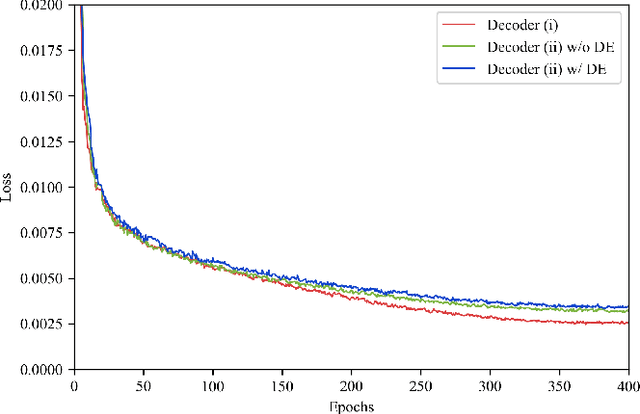
Sobolev Training for Implicit Neural Representations with Approximated Image Derivatives
Jul 21, 2022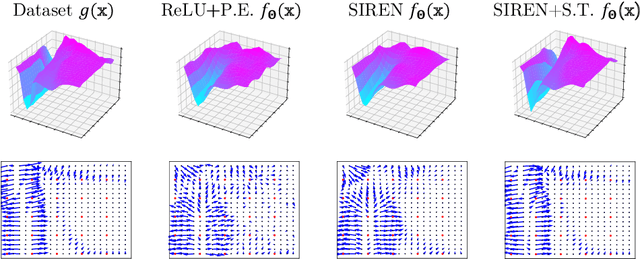
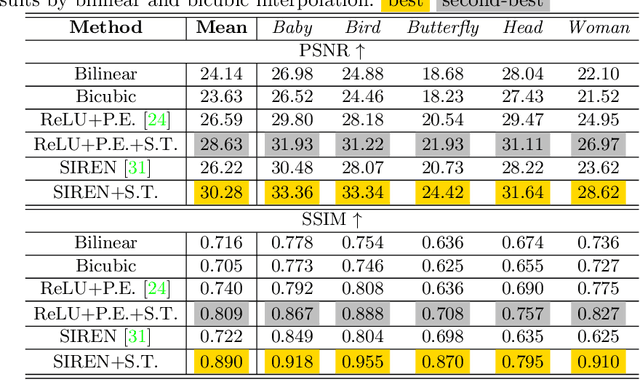
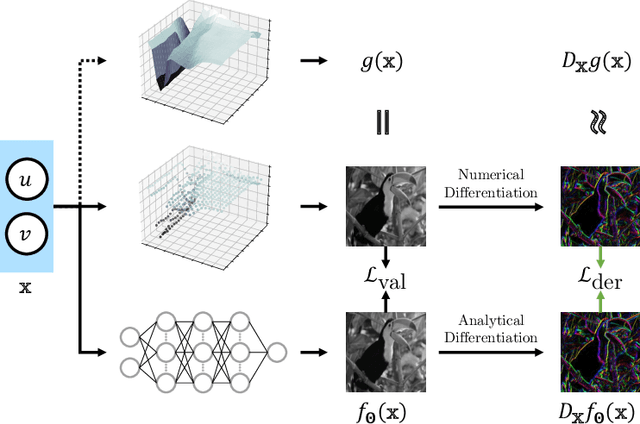
Recently, Implicit Neural Representations (INRs) parameterized by neural networks have emerged as a powerful and promising tool to represent different kinds of signals due to its continuous, differentiable properties, showing superiorities to classical discretized representations. However, the training of neural networks for INRs only utilizes input-output pairs, and the derivatives of the target output with respect to the input, which can be accessed in some cases, are usually ignored. In this paper, we propose a training paradigm for INRs whose target output is image pixels, to encode image derivatives in addition to image values in the neural network. Specifically, we use finite differences to approximate image derivatives. We show how the training paradigm can be leveraged to solve typical INRs problems, i.e., image regression and inverse rendering, and demonstrate this training paradigm can improve the data-efficiency and generalization capabilities of INRs. The code of our method is available at \url{https://github.com/megvii-research/Sobolev_INRs}.
Unified Interactive Image Matting
May 23, 2022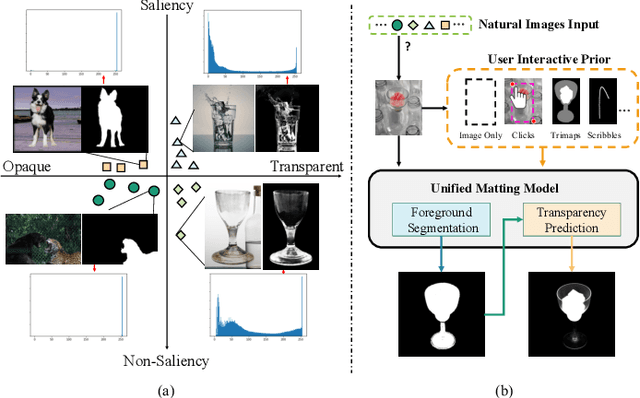

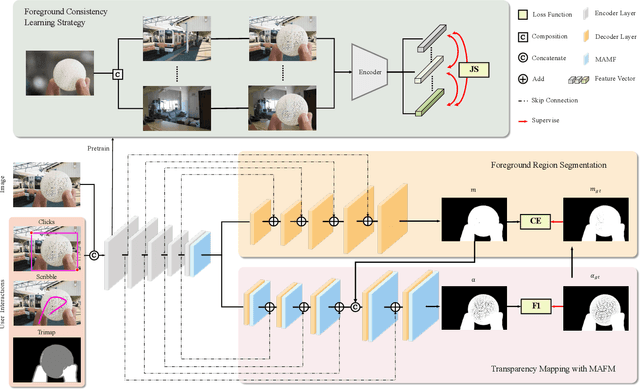
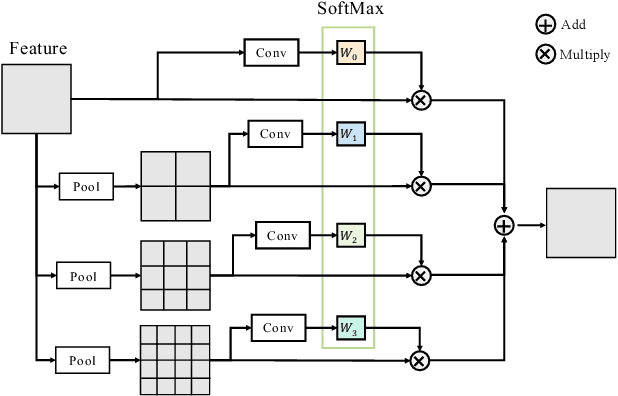
Recent image matting studies are developing towards proposing trimap-free or interactive methods for complete complex image matting tasks. Although avoiding the extensive labors of trimap annotation, existing methods still suffer from two limitations: (1) For the single image with multiple objects, it is essential to provide extra interaction information to help determining the matting target; (2) For transparent objects, the accurate regression of alpha matte from RGB image is much more difficult compared with the opaque ones. In this work, we propose a Unified Interactive image Matting method, named UIM, which solves the limitations and achieves satisfying matting results for any scenario. Specifically, UIM leverages multiple types of user interaction to avoid the ambiguity of multiple matting targets, and we compare the pros and cons of different annotation types in detail. To unify the matting performance for transparent and opaque objects, we decouple image matting into two stages, i.e., foreground segmentation and transparency prediction. Moreover, we design a multi-scale attentive fusion module to alleviate the vagueness in the boundary region. Experimental results demonstrate that UIM achieves state-of-the-art performance on the Composition-1K test set and a synthetic unified dataset. Our code and models will be released soon.