 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
High-Resolution Swin Transformer for Automatic Medical Image Segmentation
Jul 23, 2022
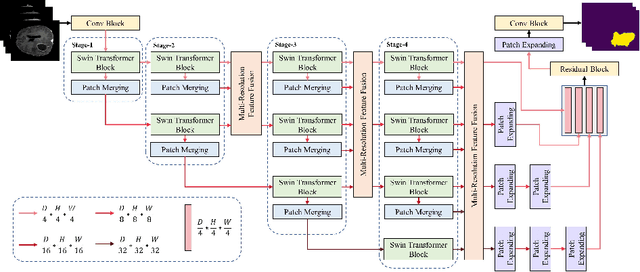
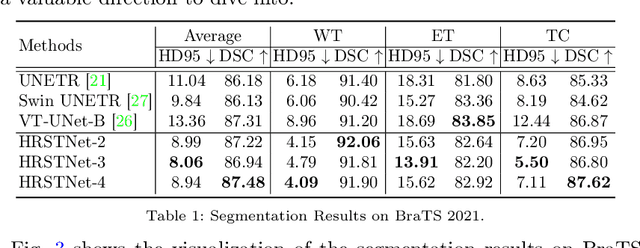
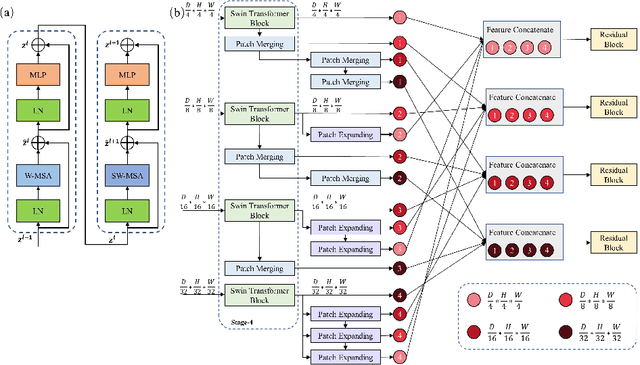
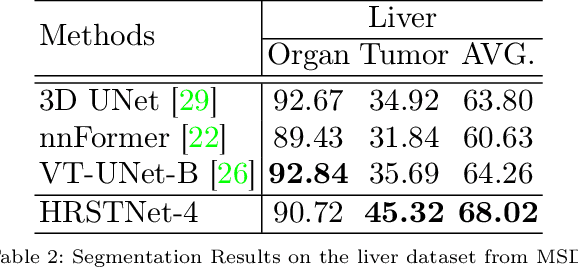
The Resolution of feature maps is critical for medical image segmentation. Most of the existing Transformer-based networks for medical image segmentation are U-Net-like architecture that contains an encoder that utilizes a sequence of Transformer blocks to convert the input medical image from high-resolution representation into low-resolution feature maps and a decoder that gradually recovers the high-resolution representation from low-resolution feature maps. Unlike previous studies, in this paper, we utilize the network design style from the High-Resolution Network (HRNet), replace the convolutional layers with Transformer blocks, and continuously exchange information from the different resolution feature maps that are generated by Transformer blocks. The newly Transformer-based network presented in this paper is denoted as High-Resolution Swin Transformer Network (HRSTNet). Extensive experiments illustrate that HRSTNet can achieve comparable performance with the state-of-the-art Transformer-based U-Net-like architecture on Brain Tumor Segmentation(BraTS) 2021 and the liver dataset from Medical Segmentation Decathlon. The code of HRSTNet will be publicly available at https://github.com/auroua/HRSTNet.
Feature Representation Learning for Unsupervised Cross-domain Image Retrieval
Jul 20, 2022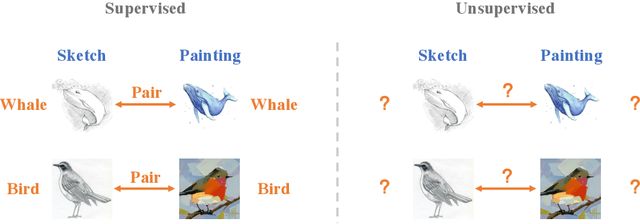
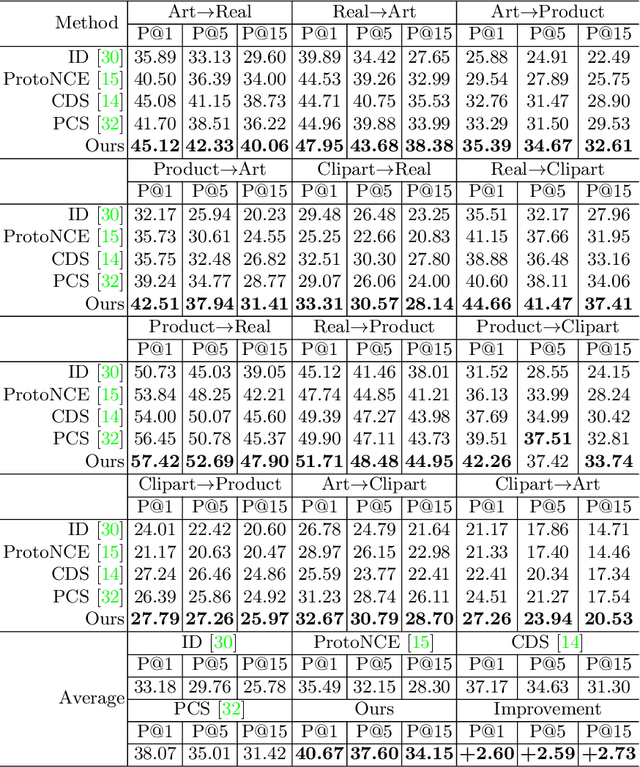
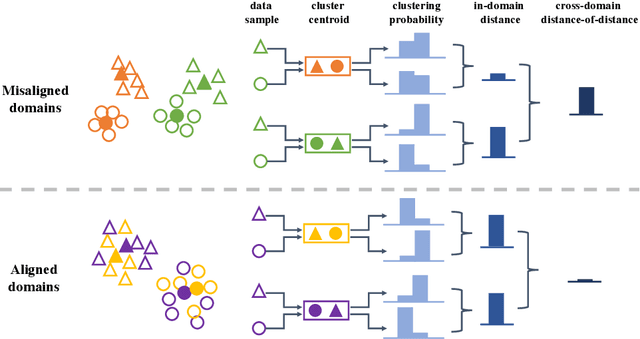
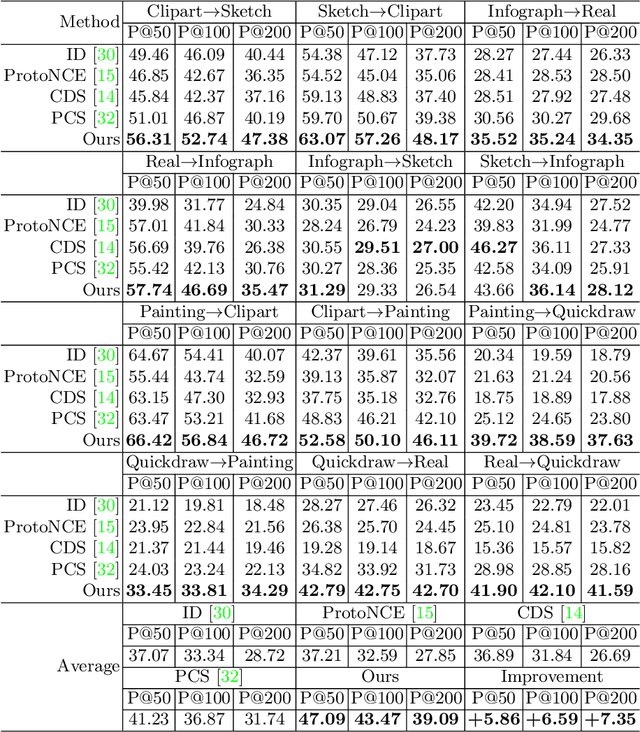
Current supervised cross-domain image retrieval methods can achieve excellent performance. However, the cost of data collection and labeling imposes an intractable barrier to practical deployment in real applications. In this paper, we investigate the unsupervised cross-domain image retrieval task, where class labels and pairing annotations are no longer a prerequisite for training. This is an extremely challenging task because there is no supervision for both in-domain feature representation learning and cross-domain alignment. We address both challenges by introducing: 1) a new cluster-wise contrastive learning mechanism to help extract class semantic-aware features, and 2) a novel distance-of-distance loss to effectively measure and minimize the domain discrepancy without any external supervision. Experiments on the Office-Home and DomainNet datasets consistently show the superior image retrieval accuracies of our framework over state-of-the-art approaches. Our source code can be found at https://github.com/conghuihu/UCDIR.
CyCLIP: Cyclic Contrastive Language-Image Pretraining
May 28, 2022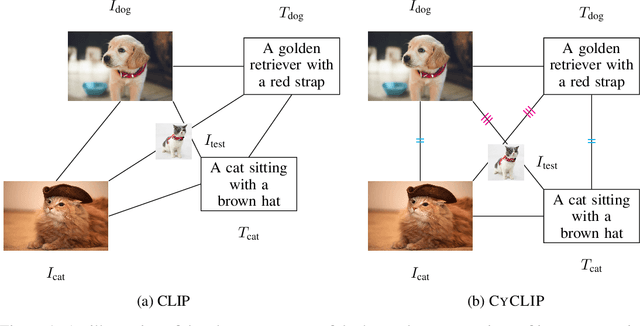
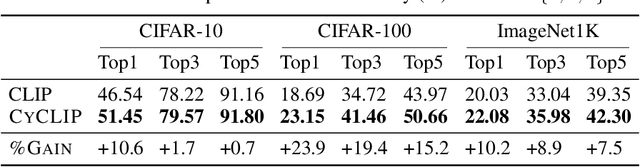
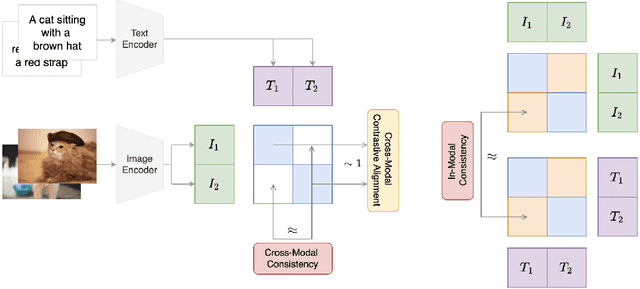
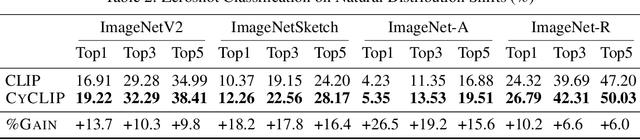
Recent advances in contrastive representation learning over paired image-text data have led to models such as CLIP that achieve state-of-the-art performance for zero-shot classification and distributional robustness. Such models typically require joint reasoning in the image and text representation spaces for downstream inference tasks. Contrary to prior beliefs, we demonstrate that the image and text representations learned via a standard contrastive objective are not interchangeable and can lead to inconsistent downstream predictions. To mitigate this issue, we formalize consistency and propose CyCLIP, a framework for contrastive representation learning that explicitly optimizes for the learned representations to be geometrically consistent in the image and text space. In particular, we show that consistent representations can be learned by explicitly symmetrizing (a) the similarity between the two mismatched image-text pairs (cross-modal consistency); and (b) the similarity between the image-image pair and the text-text pair (in-modal consistency). Empirically, we show that the improved consistency in CyCLIP translates to significant gains over CLIP, with gains ranging from 10%-24% for zero-shot classification accuracy on standard benchmarks (CIFAR-10, CIFAR-100, ImageNet1K) and 10%-27% for robustness to various natural distribution shifts. The code is available at https://github.com/goel-shashank/CyCLIP.
Spatially Covariant Lesion Segmentation
Jan 19, 2023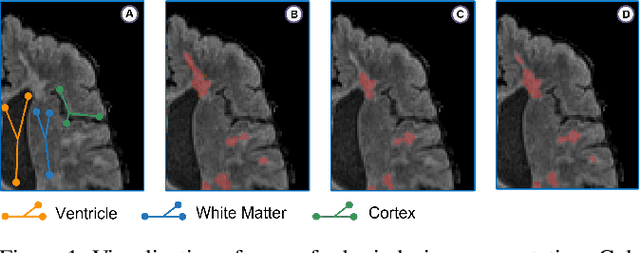
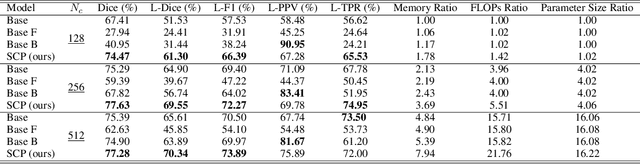
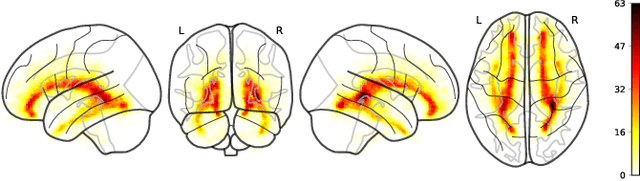
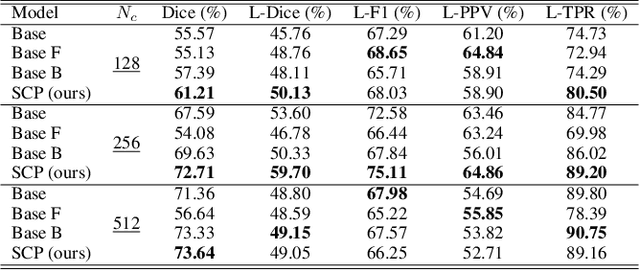
Compared to natural images, medical images usually show stronger visual patterns and therefore this adds flexibility and elasticity to resource-limited clinical applications by injecting proper priors into neural networks. In this paper, we propose spatially covariant pixel-aligned classifier (SCP) to improve the computational efficiency and meantime maintain or increase accuracy for lesion segmentation. SCP relaxes the spatial invariance constraint imposed by convolutional operations and optimizes an underlying implicit function that maps image coordinates to network weights, the parameters of which are obtained along with the backbone network training and later used for generating network weights to capture spatially covariant contextual information. We demonstrate the effectiveness and efficiency of the proposed SCP using two lesion segmentation tasks from different imaging modalities: white matter hyperintensity segmentation in magnetic resonance imaging and liver tumor segmentation in contrast-enhanced abdominal computerized tomography. The network using SCP has achieved 23.8%, 64.9% and 74.7% reduction in GPU memory usage, FLOPs, and network size with similar or better accuracy for lesion segmentation.
Weakly-Supervised Stitching Network for Real-World Panoramic Image Generation
Sep 13, 2022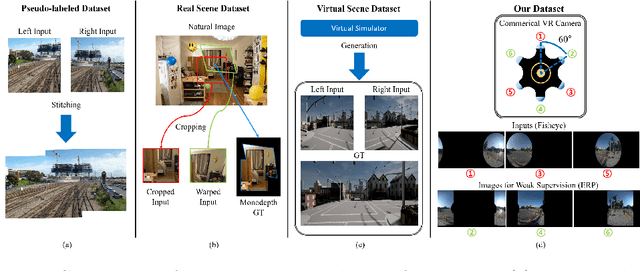
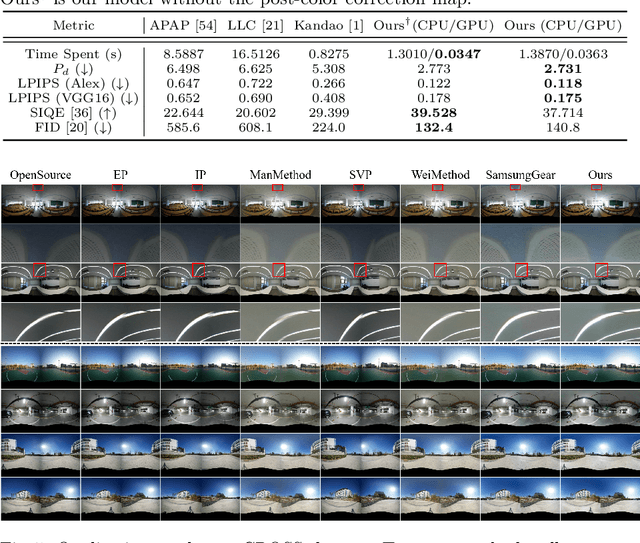
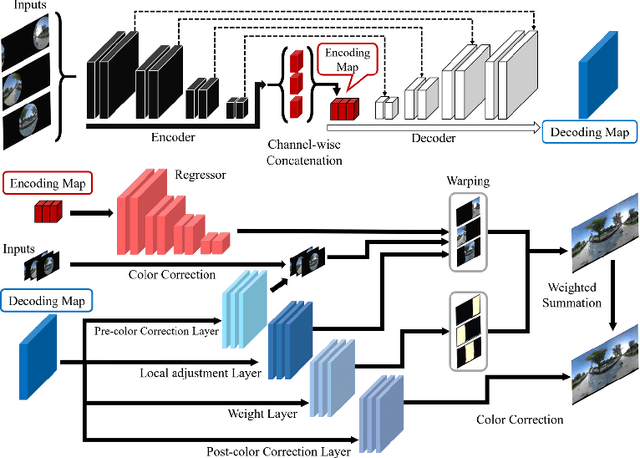

Recently, there has been growing attention on an end-to-end deep learning-based stitching model. However, the most challenging point in deep learning-based stitching is to obtain pairs of input images with a narrow field of view and ground truth images with a wide field of view captured from real-world scenes. To overcome this difficulty, we develop a weakly-supervised learning mechanism to train the stitching model without requiring genuine ground truth images. In addition, we propose a stitching model that takes multiple real-world fisheye images as inputs and creates a 360 output image in an equirectangular projection format. In particular, our model consists of color consistency corrections, warping, and blending, and is trained by perceptual and SSIM losses. The effectiveness of the proposed algorithm is verified on two real-world stitching datasets.
Video Object of Interest Segmentation
Dec 06, 2022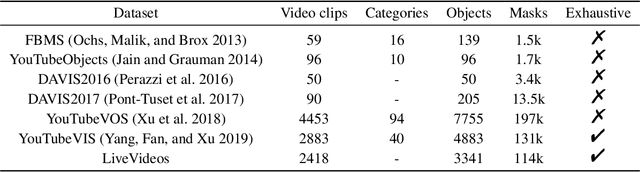



In this work, we present a new computer vision task named video object of interest segmentation (VOIS). Given a video and a target image of interest, our objective is to simultaneously segment and track all objects in the video that are relevant to the target image. This problem combines the traditional video object segmentation task with an additional image indicating the content that users are concerned with. Since no existing dataset is perfectly suitable for this new task, we specifically construct a large-scale dataset called LiveVideos, which contains 2418 pairs of target images and live videos with instance-level annotations. In addition, we propose a transformer-based method for this task. We revisit Swin Transformer and design a dual-path structure to fuse video and image features. Then, a transformer decoder is employed to generate object proposals for segmentation and tracking from the fused features. Extensive experiments on LiveVideos dataset show the superiority of our proposed method.
Perceptual Attacks of No-Reference Image Quality Models with Human-in-the-Loop
Oct 03, 2022


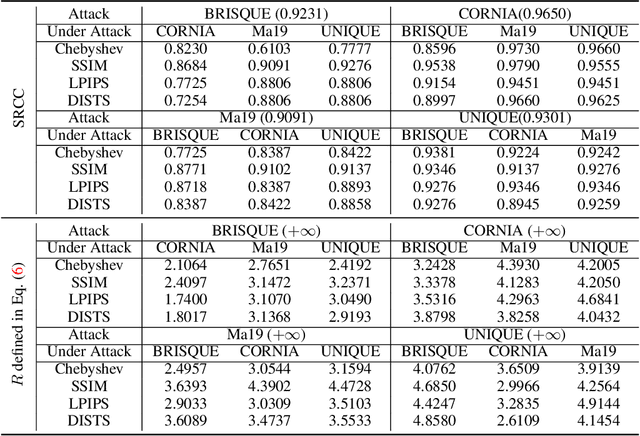
No-reference image quality assessment (NR-IQA) aims to quantify how humans perceive visual distortions of digital images without access to their undistorted references. NR-IQA models are extensively studied in computational vision, and are widely used for performance evaluation and perceptual optimization of man-made vision systems. Here we make one of the first attempts to examine the perceptual robustness of NR-IQA models. Under a Lagrangian formulation, we identify insightful connections of the proposed perceptual attack to previous beautiful ideas in computer vision and machine learning. We test one knowledge-driven and three data-driven NR-IQA methods under four full-reference IQA models (as approximations to human perception of just-noticeable differences). Through carefully designed psychophysical experiments, we find that all four NR-IQA models are vulnerable to the proposed perceptual attack. More interestingly, we observe that the generated counterexamples are not transferable, manifesting themselves as distinct design flows of respective NR-IQA methods.
Point-E: A System for Generating 3D Point Clouds from Complex Prompts
Dec 16, 2022
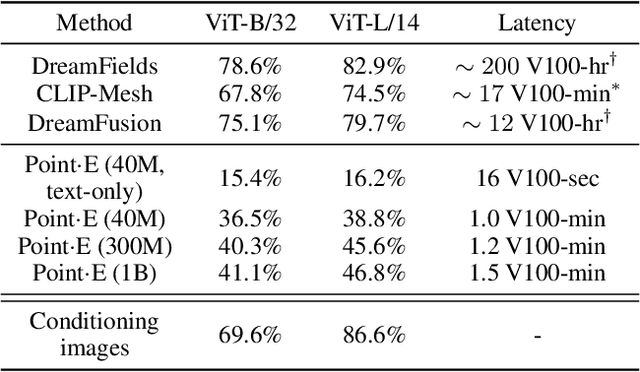

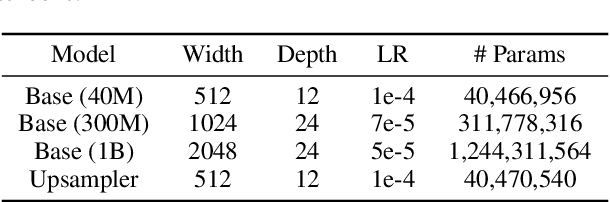
While recent work on text-conditional 3D object generation has shown promising results, the state-of-the-art methods typically require multiple GPU-hours to produce a single sample. This is in stark contrast to state-of-the-art generative image models, which produce samples in a number of seconds or minutes. In this paper, we explore an alternative method for 3D object generation which produces 3D models in only 1-2 minutes on a single GPU. Our method first generates a single synthetic view using a text-to-image diffusion model, and then produces a 3D point cloud using a second diffusion model which conditions on the generated image. While our method still falls short of the state-of-the-art in terms of sample quality, it is one to two orders of magnitude faster to sample from, offering a practical trade-off for some use cases. We release our pre-trained point cloud diffusion models, as well as evaluation code and models, at https://github.com/openai/point-e.
Labeling instructions matter in biomedical image analysis
Jul 20, 2022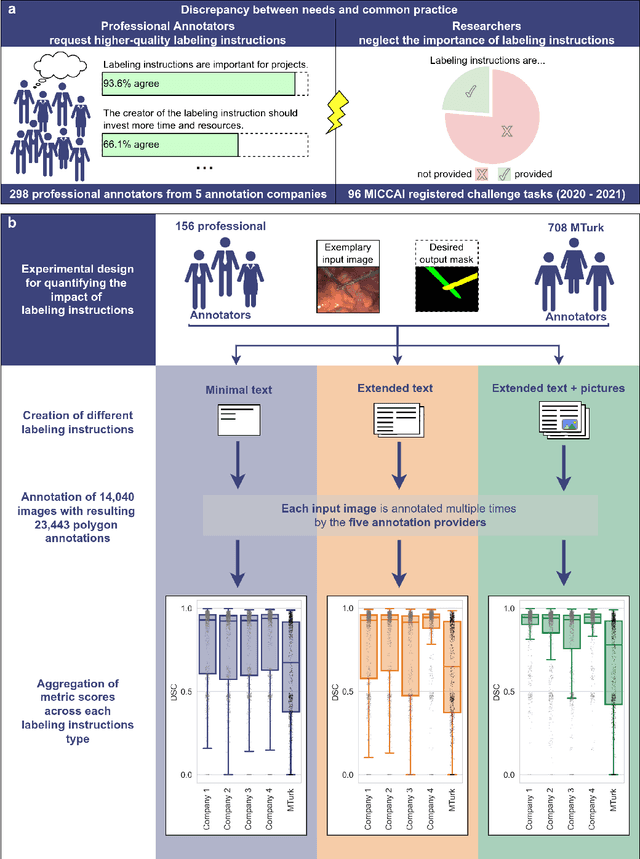
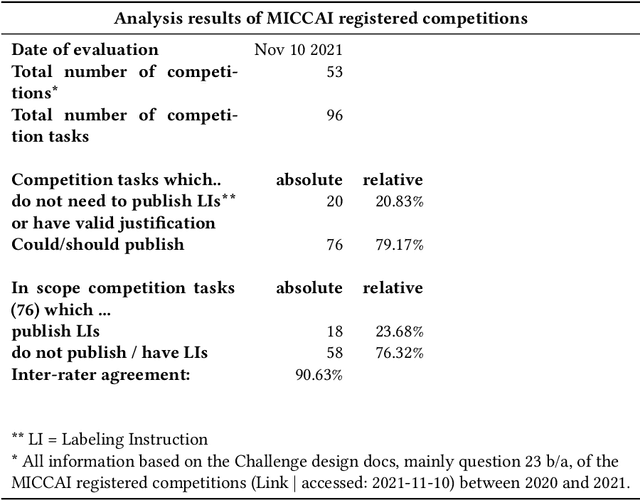
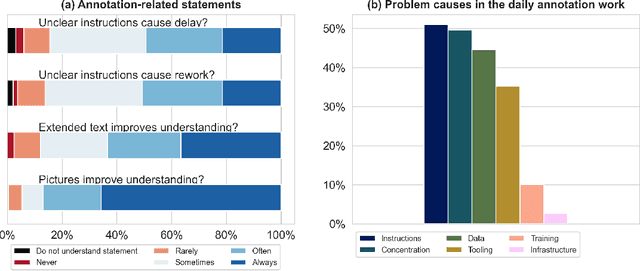
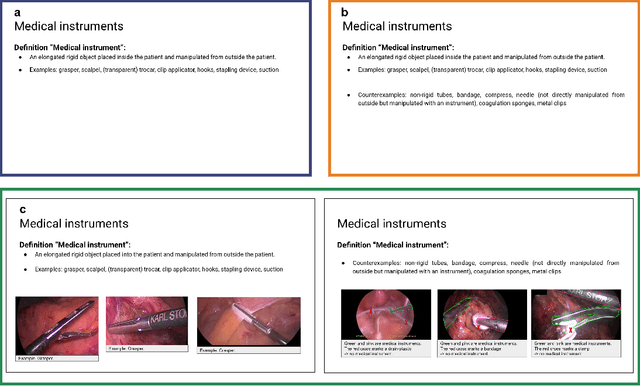
Biomedical image analysis algorithm validation depends on high-quality annotation of reference datasets, for which labeling instructions are key. Despite their importance, their optimization remains largely unexplored. Here, we present the first systematic study of labeling instructions and their impact on annotation quality in the field. Through comprehensive examination of professional practice and international competitions registered at the MICCAI Society, we uncovered a discrepancy between annotators' needs for labeling instructions and their current quality and availability. Based on an analysis of 14,040 images annotated by 156 annotators from four professional companies and 708 Amazon Mechanical Turk (MTurk) crowdworkers using instructions with different information density levels, we further found that including exemplary images significantly boosts annotation performance compared to text-only descriptions, while solely extending text descriptions does not. Finally, professional annotators constantly outperform MTurk crowdworkers. Our study raises awareness for the need of quality standards in biomedical image analysis labeling instructions.
Testing Relational Understanding in Text-Guided Image Generation
Jul 29, 2022
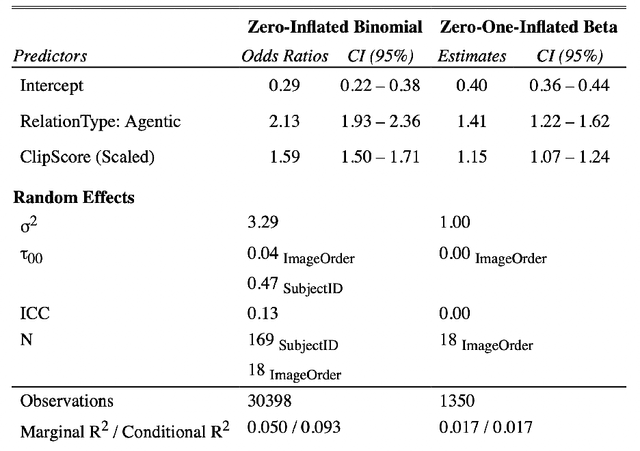
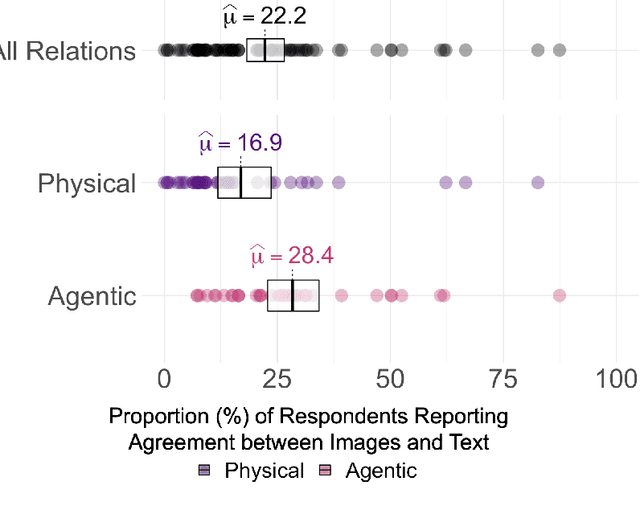
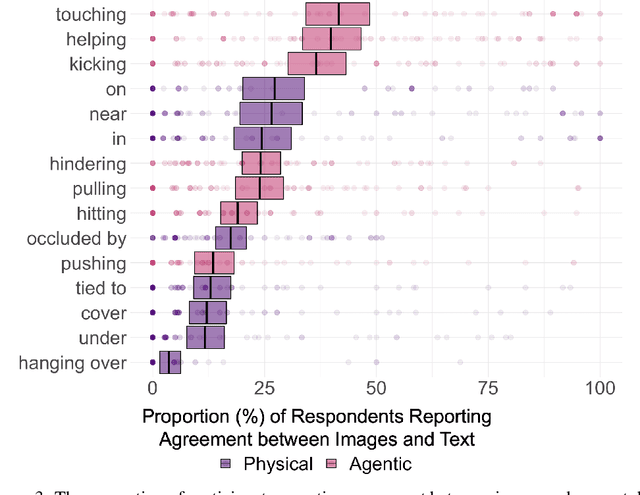
Relations are basic building blocks of human cognition. Classic and recent work suggests that many relations are early developing, and quickly perceived. Machine models that aspire to human-level perception and reasoning should reflect the ability to recognize and reason generatively about relations. We report a systematic empirical examination of a recent text-guided image generation model (DALL-E 2), using a set of 15 basic physical and social relations studied or proposed in the literature, and judgements from human participants (N = 169). Overall, we find that only ~22% of images matched basic relation prompts. Based on a quantitative examination of people's judgments, we suggest that current image generation models do not yet have a grasp of even basic relations involving simple objects and agents. We examine reasons for model successes and failures, and suggest possible improvements based on computations observed in biological intelligence.