 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Explicit Image Caption Editing
Jul 20, 2022
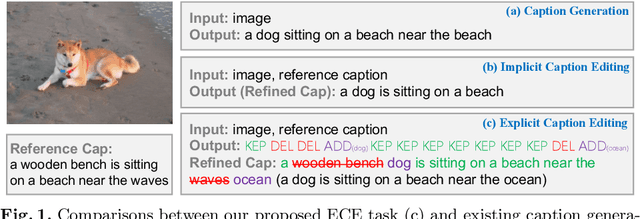
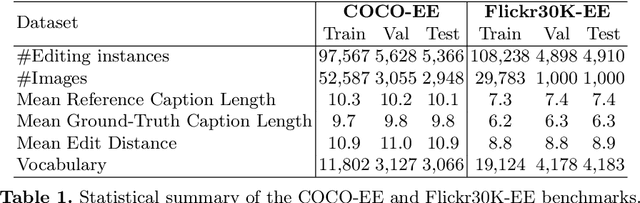

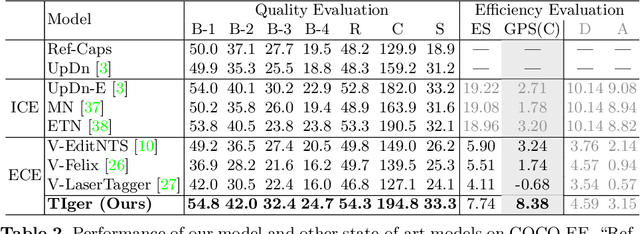
Given an image and a reference caption, the image caption editing task aims to correct the misalignment errors and generate a refined caption. However, all existing caption editing works are implicit models, ie, they directly produce the refined captions without explicit connections to the reference captions. In this paper, we introduce a new task: Explicit Caption Editing (ECE). ECE models explicitly generate a sequence of edit operations, and this edit operation sequence can translate the reference caption into a refined one. Compared to the implicit editing, ECE has multiple advantages: 1) Explainable: it can trace the whole editing path. 2) Editing Efficient: it only needs to modify a few words. 3) Human-like: it resembles the way that humans perform caption editing, and tries to keep original sentence structures. To solve this new task, we propose the first ECE model: TIger. TIger is a non-autoregressive transformer-based model, consisting of three modules: Tagger_del, Tagger_add, and Inserter. Specifically, Tagger_del decides whether each word should be preserved or not, Tagger_add decides where to add new words, and Inserter predicts the specific word for adding. To further facilitate ECE research, we propose two new ECE benchmarks by re-organizing two existing datasets, dubbed COCO-EE and Flickr30K-EE, respectively. Extensive ablations on both two benchmarks have demonstrated the effectiveness of TIger.
Privacy-Preserving Image Classification Using ConvMixer with Adaptive Permutation Matrix
Aug 04, 2022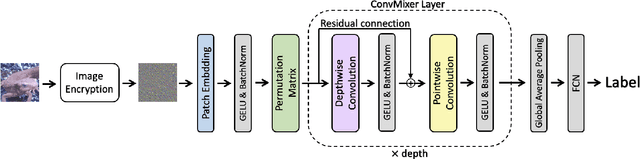

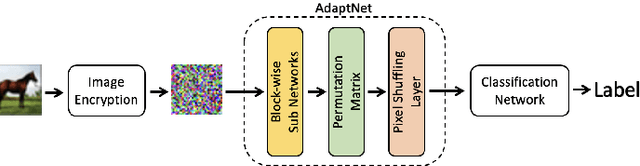
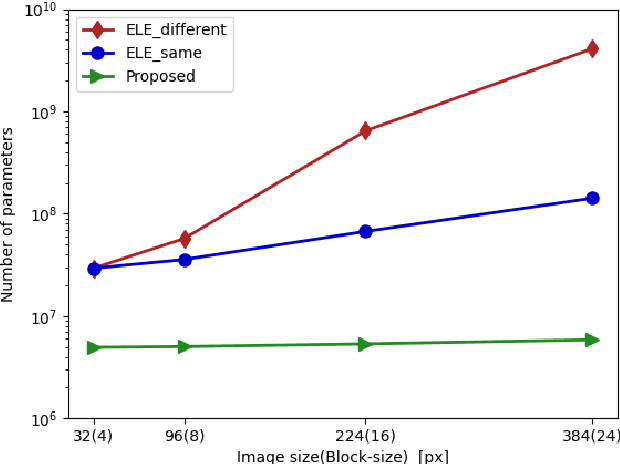
In this paper, we propose a privacy-preserving image classification method using encrypted images under the use of the ConvMixer structure. Block-wise scrambled images, which are robust enough against various attacks, have been used for privacy-preserving image classification tasks, but the combined use of a classification network and an adaptation network is needed to reduce the influence of image encryption. However, images with a large size cannot be applied to the conventional method with an adaptation network because the adaptation network has so many parameters. Accordingly, we propose a novel method, which allows us not only to apply block-wise scrambled images to ConvMixer for both training and testing without the adaptation network, but also to provide a higher classification accuracy than conventional methods.
Exploiting Partial Common Information Microstructure for Multi-Modal Brain Tumor Segmentation
Feb 06, 2023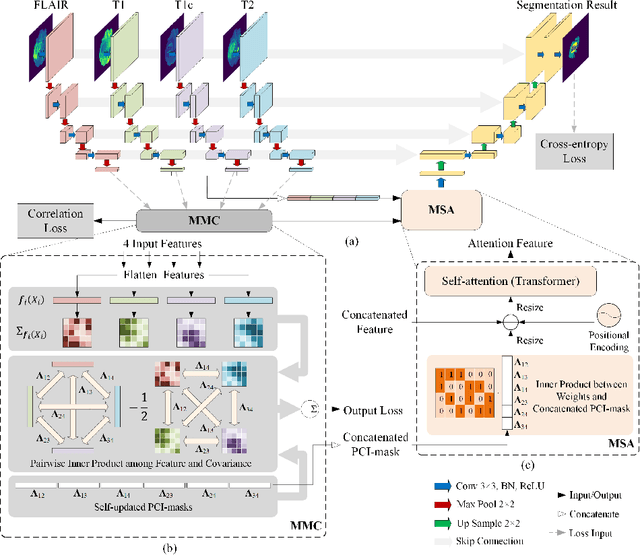


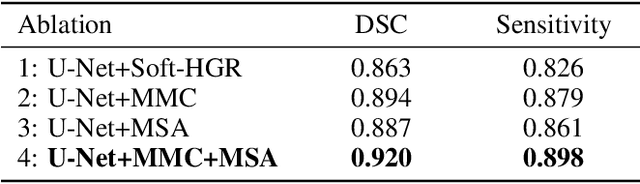
Learning with multiple modalities is crucial for automated brain tumor segmentation from magnetic resonance imaging data. Explicitly optimizing the common information shared among all modalities (e.g., by maximizing the total correlation) has been shown to achieve better feature representations and thus enhance the segmentation performance. However, existing approaches are oblivious to partial common information shared by subsets of the modalities. In this paper, we show that identifying such partial common information can significantly boost the discriminative power of image segmentation models. In particular, we introduce a novel concept of partial common information mask (PCI-mask) to provide a fine-grained characterization of what partial common information is shared by which subsets of the modalities. By solving a masked correlation maximization and simultaneously learning an optimal PCI-mask, we identify the latent microstructure of partial common information and leverage it in a self-attention module to selectively weight different feature representations in multi-modal data. We implement our proposed framework on the standard U-Net. Our experimental results on the Multi-modal Brain Tumor Segmentation Challenge (BraTS) datasets consistently outperform those of state-of-the-art segmentation baselines, with validation Dice similarity coefficients of 0.920, 0.897, 0.837 for the whole tumor, tumor core, and enhancing tumor on BraTS-2020.
Artifact Removal in Histopathology Images
Dec 16, 2022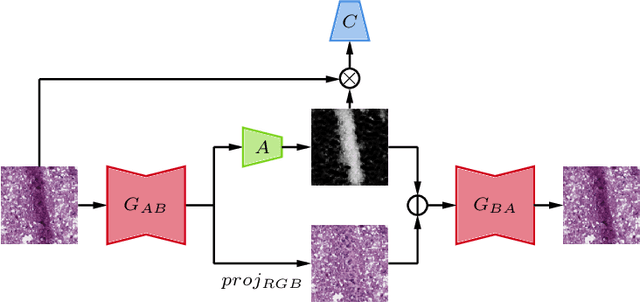

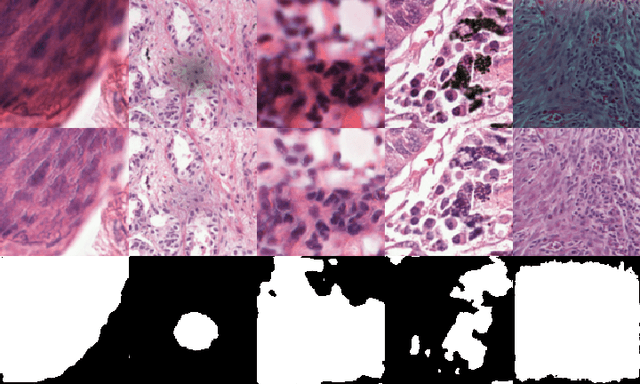

In the clinical setting of histopathology, whole-slide image (WSI) artifacts frequently arise, distorting regions of interest, and having a pernicious impact on WSI analysis. Image-to-image translation networks such as CycleGANs are in principle capable of learning an artifact removal function from unpaired data. However, we identify a surjection problem with artifact removal, and propose an weakly-supervised extension to CycleGAN to address this. We assemble a pan-cancer dataset comprising artifact and clean tiles from the TCGA database. Promising results highlight the soundness of our method.
LidarCLIP or: How I Learned to Talk to Point Clouds
Dec 13, 2022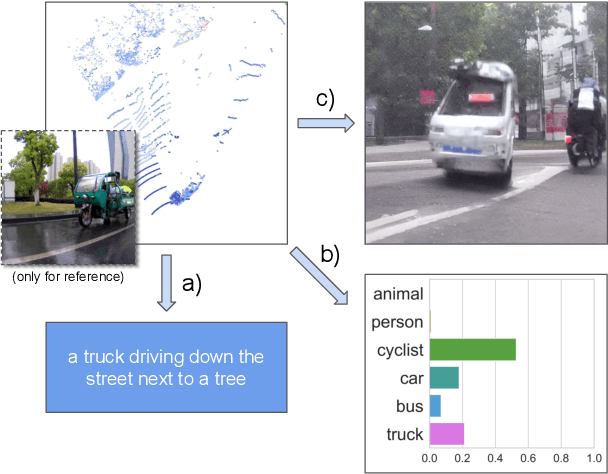
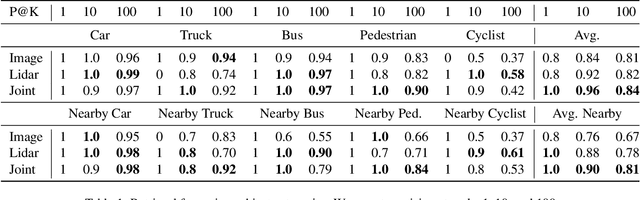
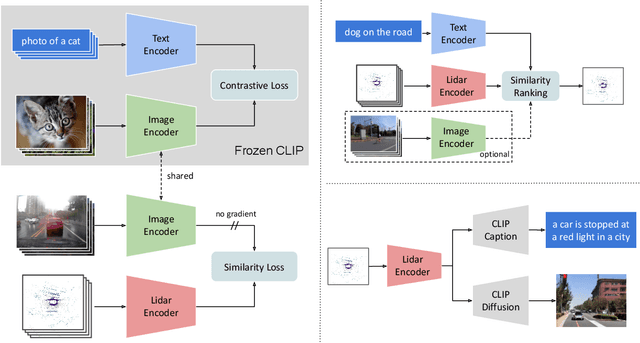

Research connecting text and images has recently seen several breakthroughs, with models like CLIP, DALL-E 2, and Stable Diffusion. However, the connection between text and other visual modalities, such as lidar data, has received less attention, prohibited by the lack of text-lidar datasets. In this work, we propose LidarCLIP, a mapping from automotive point clouds to a pre-existing CLIP embedding space. Using image-lidar pairs, we supervise a point cloud encoder with the image CLIP embeddings, effectively relating text and lidar data with the image domain as an intermediary. We show the effectiveness of LidarCLIP by demonstrating that lidar-based retrieval is generally on par with image-based retrieval, but with complementary strengths and weaknesses. By combining image and lidar features, we improve upon both single-modality methods and enable a targeted search for challenging detection scenarios under adverse sensor conditions. We also use LidarCLIP as a tool to investigate fundamental lidar capabilities through natural language. Finally, we leverage our compatibility with CLIP to explore a range of applications, such as point cloud captioning and lidar-to-image generation, without any additional training. We hope LidarCLIP can inspire future work to dive deeper into connections between text and point cloud understanding. Code and trained models available at https://github.com/atonderski/lidarclip.
ICC++: Explainable Image Retrieval for Art Historical Corpora using Image Composition Canvas
Jun 22, 2022
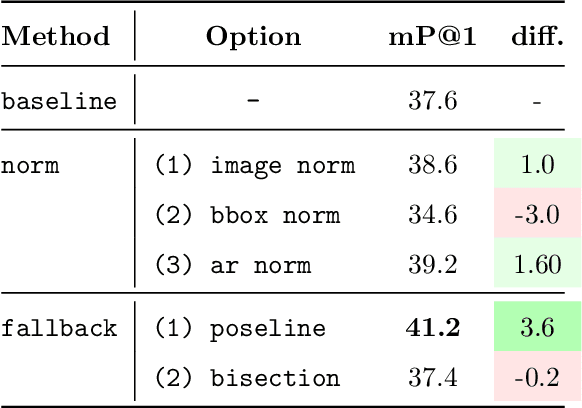
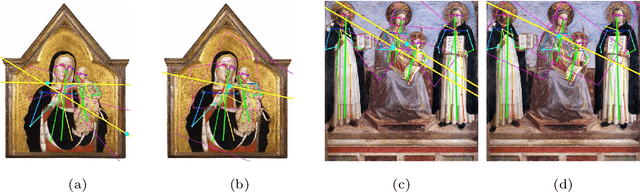
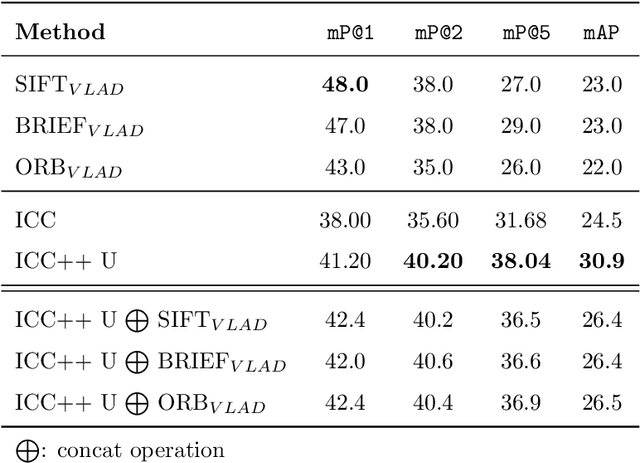
Image compositions are helpful in the study of image structures and assist in discovering the semantics of the underlying scene portrayed across art forms and styles. With the digitization of artworks in recent years, thousands of images of a particular scene or narrative could potentially be linked together. However, manually linking this data with consistent objectiveness can be a highly challenging and time-consuming task. In this work, we present a novel approach called Image Composition Canvas (ICC++) to compare and retrieve images having similar compositional elements. ICC++ is an improvement over ICC specializing in generating low and high-level features (compositional elements) motivated by Max Imdahl's work. To this end, we present a rigorous quantitative and qualitative comparison of our approach with traditional and state-of-the-art (SOTA) methods showing that our proposed method outperforms all of them. In combination with deep features, our method outperforms the best deep learning-based method, opening the research direction for explainable machine learning for digital humanities. We will release the code and the data post-publication.
DeltaGAN: Towards Diverse Few-shot Image Generation with Sample-Specific Delta
Jul 28, 2022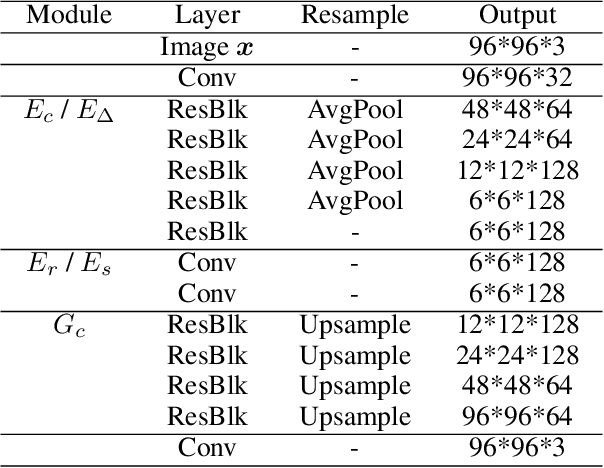

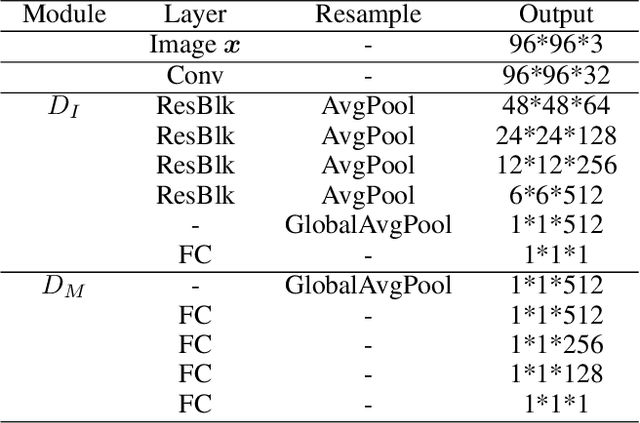

Learning to generate new images for a novel category based on only a few images, named as few-shot image generation, has attracted increasing research interest. Several state-of-the-art works have yielded impressive results, but the diversity is still limited. In this work, we propose a novel Delta Generative Adversarial Network (DeltaGAN), which consists of a reconstruction subnetwork and a generation subnetwork. The reconstruction subnetwork captures intra-category transformation, i.e., delta, between same-category pairs. The generation subnetwork generates sample-specific delta for an input image, which is combined with this input image to generate a new image within the same category. Besides, an adversarial delta matching loss is designed to link the above two subnetworks together. Extensive experiments on six benchmark datasets demonstrate the effectiveness of our proposed method. Our code is available at https://github.com/bcmi/DeltaGAN-Few-Shot-Image-Generation.
GLEAN: Generative Latent Bank for Image Super-Resolution and Beyond
Jul 29, 2022
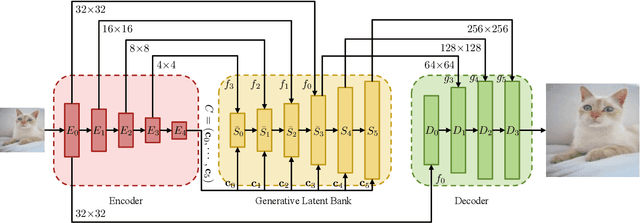
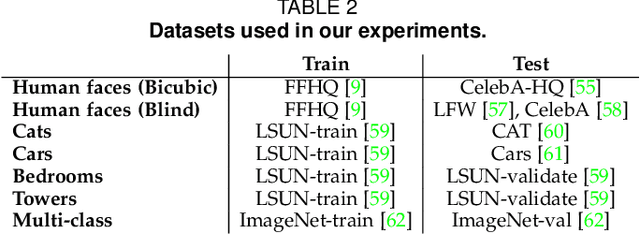
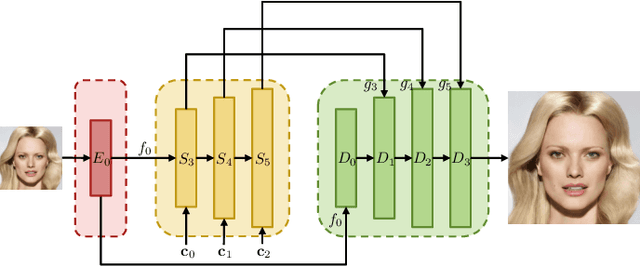
We show that pre-trained Generative Adversarial Networks (GANs) such as StyleGAN and BigGAN can be used as a latent bank to improve the performance of image super-resolution. While most existing perceptual-oriented approaches attempt to generate realistic outputs through learning with adversarial loss, our method, Generative LatEnt bANk (GLEAN), goes beyond existing practices by directly leveraging rich and diverse priors encapsulated in a pre-trained GAN. But unlike prevalent GAN inversion methods that require expensive image-specific optimization at runtime, our approach only needs a single forward pass for restoration. GLEAN can be easily incorporated in a simple encoder-bank-decoder architecture with multi-resolution skip connections. Employing priors from different generative models allows GLEAN to be applied to diverse categories (\eg~human faces, cats, buildings, and cars). We further present a lightweight version of GLEAN, named LightGLEAN, which retains only the critical components in GLEAN. Notably, LightGLEAN consists of only 21% of parameters and 35% of FLOPs while achieving comparable image quality. We extend our method to different tasks including image colorization and blind image restoration, and extensive experiments show that our proposed models perform favorably in comparison to existing methods. Codes and models are available at https://github.com/open-mmlab/mmediting.
GibbsDDRM: A Partially Collapsed Gibbs Sampler for Solving Blind Inverse Problems with Denoising Diffusion Restoration
Jan 30, 2023
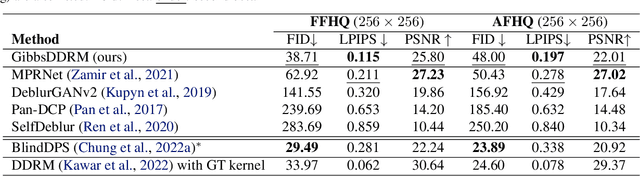
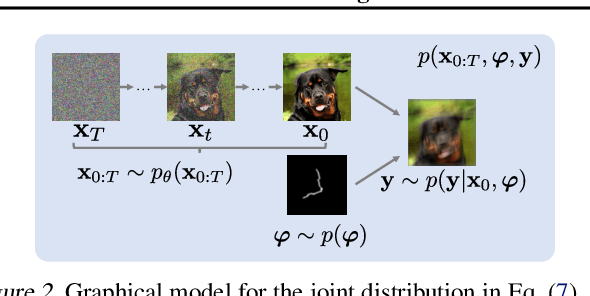
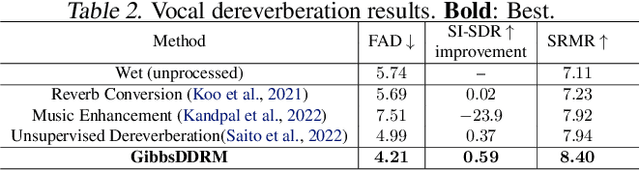
Pre-trained diffusion models have been successfully used as priors in a variety of linear inverse problems, where the goal is to reconstruct a signal from noisy linear measurements. However, existing approaches require knowledge of the linear operator. In this paper, we propose GibbsDDRM, an extension of Denoising Diffusion Restoration Models (DDRM) to a blind setting in which the linear measurement operator is unknown. GibbsDDRM constructs a joint distribution of the data, measurements, and linear operator by using a pre-trained diffusion model for the data prior, and it solves the problem by posterior sampling with an efficient variant of a Gibbs sampler. The proposed method is problem-agnostic, meaning that a pre-trained diffusion model can be applied to various inverse problems without fine tuning. In experiments, it achieved high performance on both blind image deblurring and vocal dereverberation tasks, despite the use of simple generic priors for the underlying linear operators.
Equivariant Differentially Private Deep Learning
Jan 30, 2023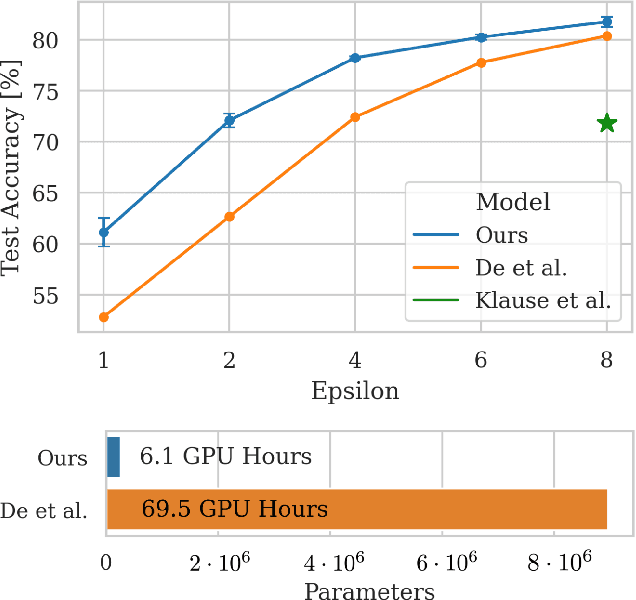
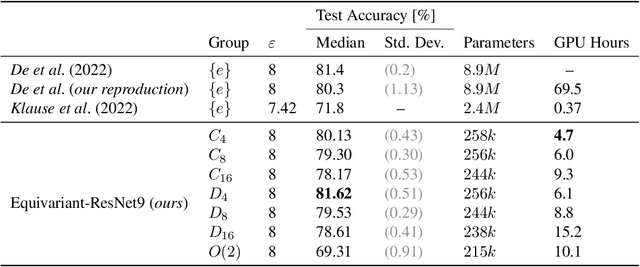
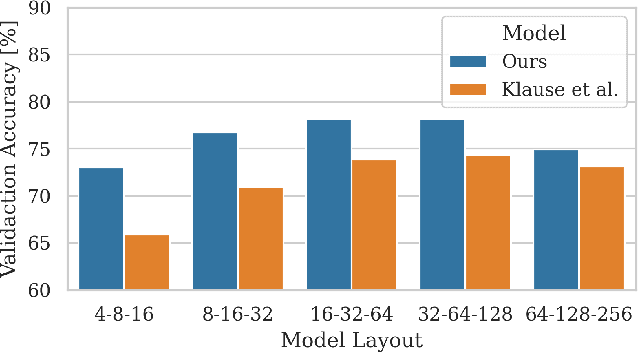

The formal privacy guarantee provided by Differential Privacy (DP) bounds the leakage of sensitive information from deep learning models. In practice, however, this comes at a severe computation and accuracy cost. The recently established state of the art (SOTA) results in image classification under DP are due to the use of heavy data augmentation and large batch sizes, leading to a drastically increased computation overhead. In this work, we propose to use more efficient models with improved feature quality by introducing steerable equivariant convolutional networks for DP training. We demonstrate that our models are able to outperform the current SOTA performance on CIFAR-10 by up to $9\%$ across different $\varepsilon$-values while reducing the number of model parameters by a factor of $35$ and decreasing the computation time by more than $90 \%$. Our results are a large step towards efficient model architectures that make optimal use of their parameters and bridge the privacy-utility gap between private and non-private deep learning for computer vision.