 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Triple-View Feature Learning for Medical Image Segmentation
Aug 12, 2022
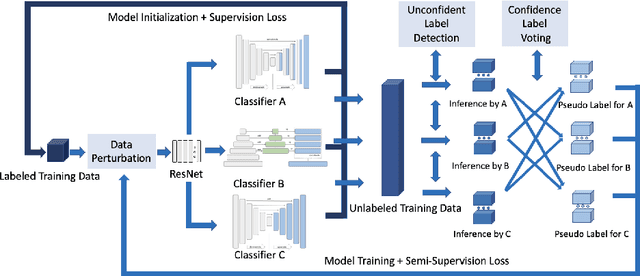
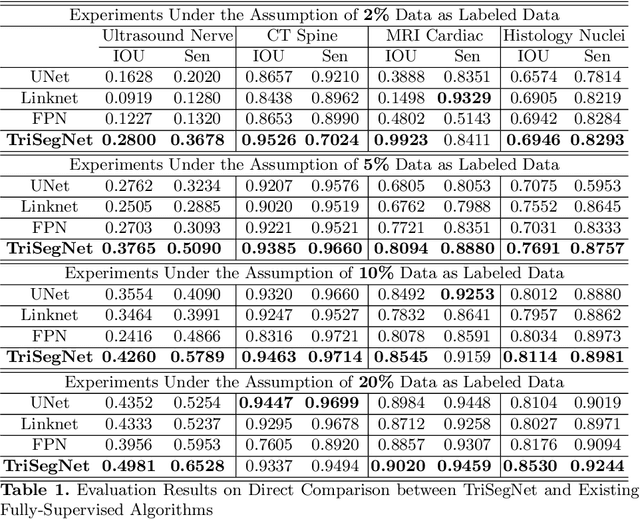
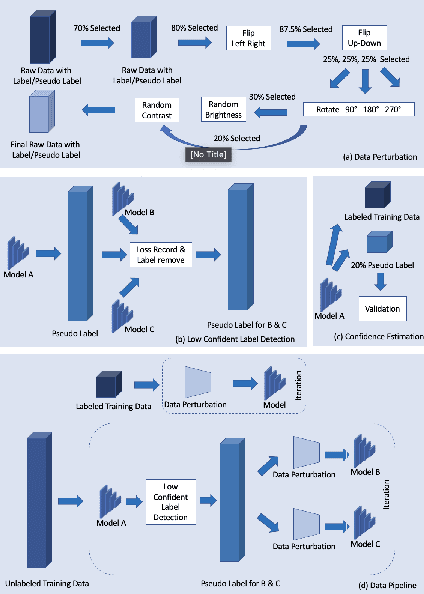
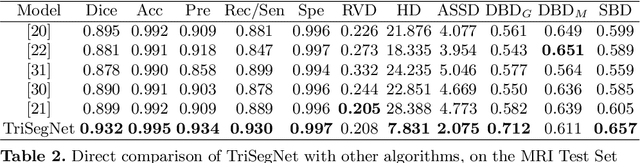
Deep learning models, e.g. supervised Encoder-Decoder style networks, exhibit promising performance in medical image segmentation, but come with a high labelling cost. We propose TriSegNet, a semi-supervised semantic segmentation framework. It uses triple-view feature learning on a limited amount of labelled data and a large amount of unlabeled data. The triple-view architecture consists of three pixel-level classifiers and a low-level shared-weight learning module. The model is first initialized with labelled data. Label processing, including data perturbation, confidence label voting and unconfident label detection for annotation, enables the model to train on labelled and unlabeled data simultaneously. The confidence of each model gets improved through the other two views of the feature learning. This process is repeated until each model reaches the same confidence level as its counterparts. This strategy enables triple-view learning of generic medical image datasets. Bespoke overlap-based and boundary-based loss functions are tailored to the different stages of the training. The segmentation results are evaluated on four publicly available benchmark datasets including Ultrasound, CT, MRI, and Histology images. Repeated experiments demonstrate the effectiveness of the proposed network compared against other semi-supervised algorithms, across a large set of evaluation measures.
Extending TrOCR for Text Localization-Free OCR of Full-Page Scanned Receipt Images
Dec 13, 2022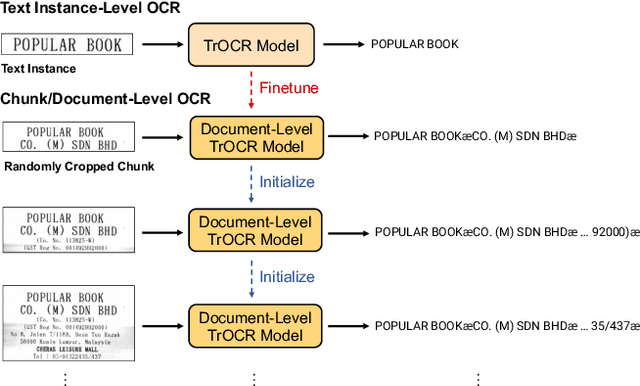
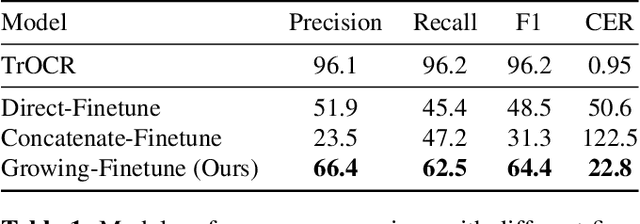
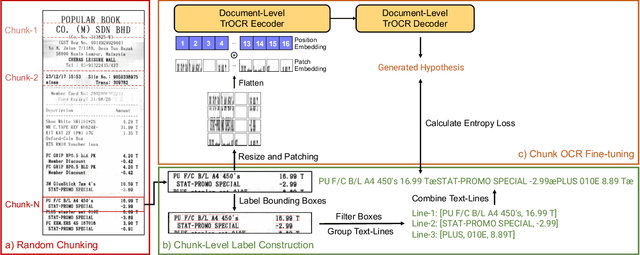
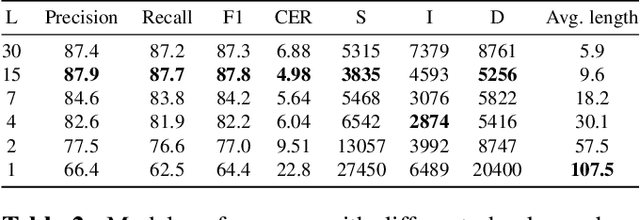
Digitization of scanned receipts aims to extract text from receipt images and save it into structured documents. This is usually split into two sub-tasks: text localization and optical character recognition (OCR). Most existing OCR models only focus on the cropped text instance images, which require the bounding box information provided by a text region detection model. Introducing an additional detector to identify the text instance images in advance is inefficient, however instance-level OCR models have very low accuracy when processing the whole image for the document-level OCR, such as receipt images containing multiple text lines arranged in various layouts. To this end, we propose a localization-free document-level OCR model for transcribing all the characters in a receipt image into an ordered sequence end-to-end. Specifically, we finetune the pretrained Transformer-based instance-level model TrOCR with randomly cropped image chunks, and gradually increase the image chunk size to generalize the recognition ability from instance images to full-page images. In our experiments on the SROIE receipt OCR dataset, the model finetuned with our strategy achieved 64.4 F1-score and a 22.8% character error rates (CER) on the word-level and character-level metrics, respectively, which outperforms the baseline results with 48.5 F1-score and 50.6% CER. The best model, which splits the full image into 15 equally sized chunks, gives 87.8 F1-score and 4.98% CER with minimal additional pre or post-processing of the output. Moreover, the characters in the generated document-level sequences are arranged in the reading order, which is practical for real-world applications.
Learning to Unlearn: Instance-wise Unlearning for Pre-trained Classifiers
Jan 27, 2023
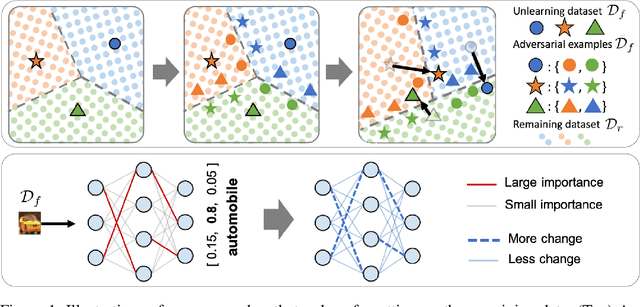
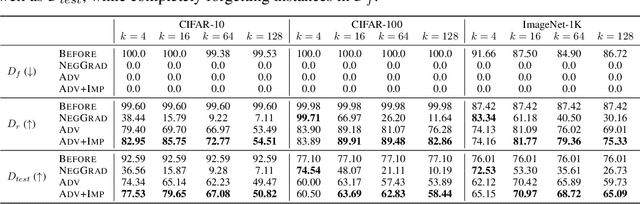
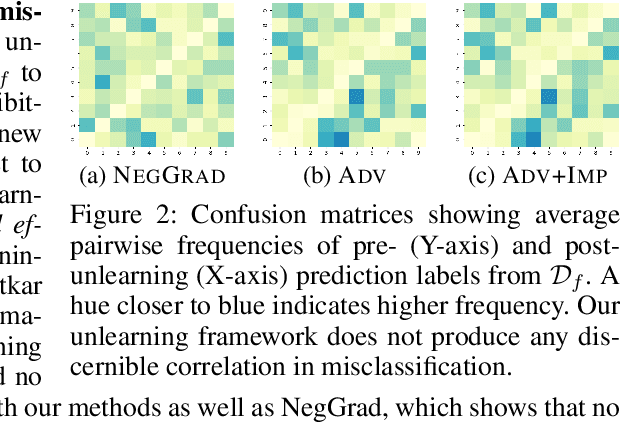
Since the recent advent of regulations for data protection (e.g., the General Data Protection Regulation), there has been increasing demand in deleting information learned from sensitive data in pre-trained models without retraining from scratch. The inherent vulnerability of neural networks towards adversarial attacks and unfairness also calls for a robust method to remove or correct information in an instance-wise fashion, while retaining the predictive performance across remaining data. To this end, we define instance-wise unlearning, of which the goal is to delete information on a set of instances from a pre-trained model, by either misclassifying each instance away from its original prediction or relabeling the instance to a different label. We also propose two methods that reduce forgetting on the remaining data: 1) utilizing adversarial examples to overcome forgetting at the representation-level and 2) leveraging weight importance metrics to pinpoint network parameters guilty of propagating unwanted information. Both methods only require the pre-trained model and data instances to forget, allowing painless application to real-life settings where the entire training set is unavailable. Through extensive experimentation on various image classification benchmarks, we show that our approach effectively preserves knowledge of remaining data while unlearning given instances in both single-task and continual unlearning scenarios.
CADyQ: Content-Aware Dynamic Quantization for Image Super-Resolution
Jul 21, 2022
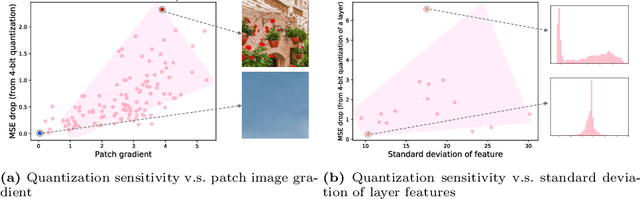
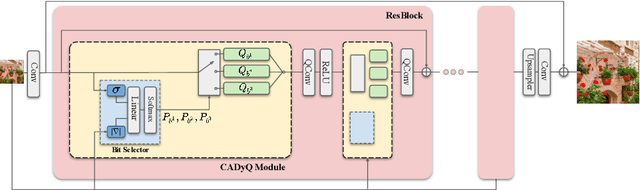
Despite breakthrough advances in image super-resolution (SR) with convolutional neural networks (CNNs), SR has yet to enjoy ubiquitous applications due to the high computational complexity of SR networks. Quantization is one of the promising approaches to solve this problem. However, existing methods fail to quantize SR models with a bit-width lower than 8 bits, suffering from severe accuracy loss due to fixed bit-width quantization applied everywhere. In this work, to achieve high average bit-reduction with less accuracy loss, we propose a novel Content-Aware Dynamic Quantization (CADyQ) method for SR networks that allocates optimal bits to local regions and layers adaptively based on the local contents of an input image. To this end, a trainable bit selector module is introduced to determine the proper bit-width and quantization level for each layer and a given local image patch. This module is governed by the quantization sensitivity that is estimated by using both the average magnitude of image gradient of the patch and the standard deviation of the input feature of the layer. The proposed quantization pipeline has been tested on various SR networks and evaluated on several standard benchmarks extensively. Significant reduction in computational complexity and the elevated restoration accuracy clearly demonstrate the effectiveness of the proposed CADyQ framework for SR. Codes are available at https://github.com/Cheeun/CADyQ.
Inverted Semantic-Index for Image Retrieval
Jun 25, 2022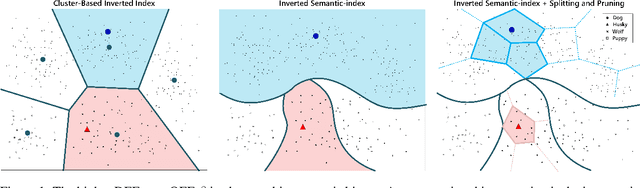

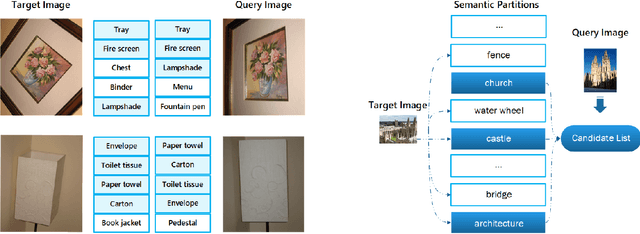
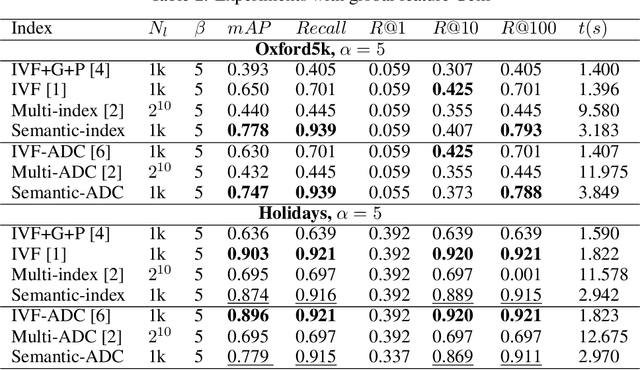
This paper addresses the construction of inverted index for large-scale image retrieval. The inverted index proposed by J. Sivic brings a significant acceleration by reducing distance computations with only a small fraction of the database. The state-of-the-art inverted indices aim to build finer partitions that produce a concise and accurate candidate list. However, partitioning in these frameworks is generally achieved by unsupervised clustering methods which ignore the semantic information of images. In this paper, we replace the clustering method with image classification, during the construction of codebook. We then propose a merging and splitting method to solve the problem that the number of partitions is unchangeable in the inverted semantic-index. Next, we combine our semantic-index with the product quantization (PQ) so as to alleviate the accuracy loss caused by PQ compression. Finally, we evaluate our model on large-scale image retrieval benchmarks. Experiment results demonstrate that our model can significantly improve the retrieval accuracy by generating high-quality candidate lists.
Three-stage binarization of color document images based on discrete wavelet transform and generative adversarial networks
Nov 29, 2022
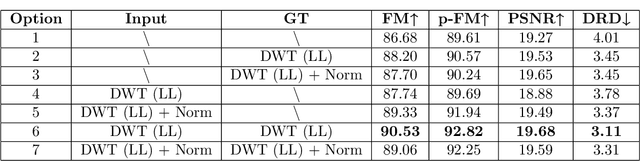
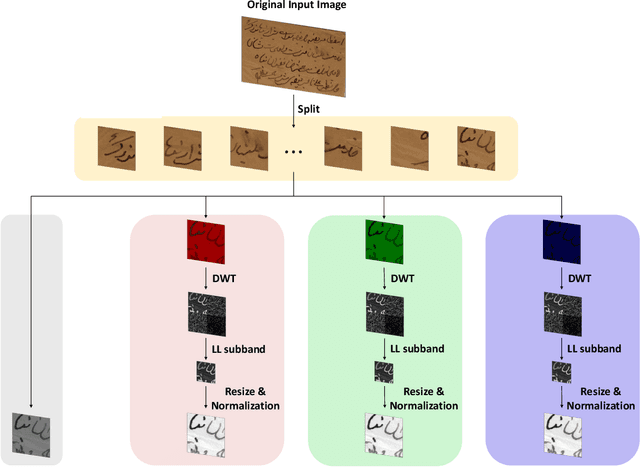
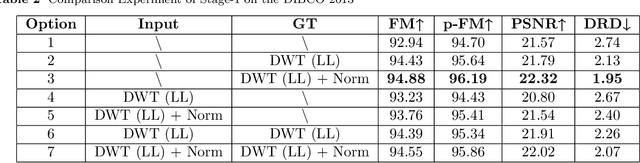
The efficient segmentation of foreground text information from the background in degraded color document images is a hot research topic. Due to the imperfect preservation of ancient documents over a long period of time, various types of degradation, including staining, yellowing, and ink seepage, have seriously affected the results of image binarization. In this paper, a three-stage method is proposed for image enhancement and binarization of degraded color document images by using discrete wavelet transform (DWT) and generative adversarial network (GAN). In Stage-1, we use DWT and retain the LL subband images to achieve the image enhancement. In Stage-2, the original input image is split into four (Red, Green, Blue and Gray) single-channel images, each of which trains the independent adversarial networks. The trained adversarial network models are used to extract the color foreground information from the images. In Stage-3, in order to combine global and local features, the output image from Stage-2 and the original input image are used to train the independent adversarial networks for document binarization. The experimental results demonstrate that our proposed method outperforms many classical and state-of-the-art (SOTA) methods on the Document Image Binarization Contest (DIBCO) dataset. We release our implementation code at https://github.com/abcpp12383/ThreeStageBinarization.
Reducing The Amortization Gap of Entropy Bottleneck In End-to-End Image Compression
Sep 02, 2022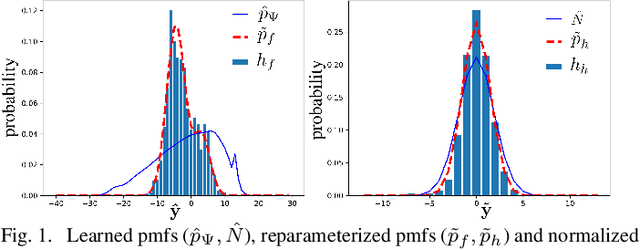
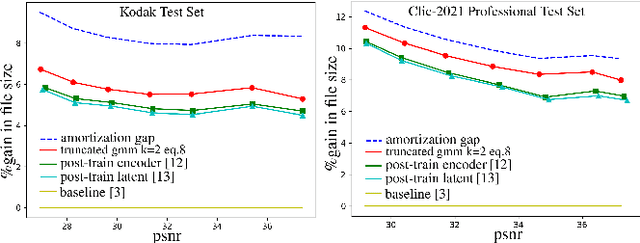
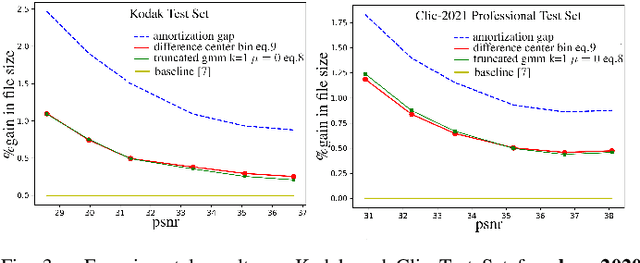
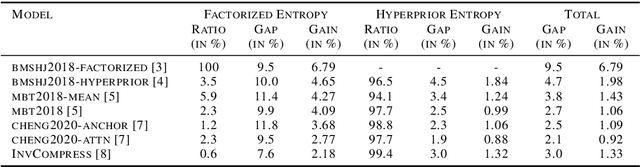
End-to-end deep trainable models are about to exceed the performance of the traditional handcrafted compression techniques on videos and images. The core idea is to learn a non-linear transformation, modeled as a deep neural network, mapping input image into latent space, jointly with an entropy model of the latent distribution. The decoder is also learned as a deep trainable network, and the reconstructed image measures the distortion. These methods enforce the latent to follow some prior distributions. Since these priors are learned by optimization over the entire training set, the performance is optimal in average. However, it cannot fit exactly on every single new instance, hence damaging the compression performance by enlarging the bit-stream. In this paper, we propose a simple yet efficient instance-based parameterization method to reduce this amortization gap at a minor cost. The proposed method is applicable to any end-to-end compressing methods, improving the compression bitrate by 1% without any impact on the reconstruction quality.
Weakly-Supervised Deep Learning Model for Prostate Cancer Diagnosis and Gleason Grading of Histopathology Images
Dec 25, 2022Prostate cancer is the most common cancer in men worldwide and the second leading cause of cancer death in the United States. One of the prognostic features in prostate cancer is the Gleason grading of histopathology images. The Gleason grade is assigned based on tumor architecture on Hematoxylin and Eosin (H&E) stained whole slide images (WSI) by the pathologists. This process is time-consuming and has known interobserver variability. In the past few years, deep learning algorithms have been used to analyze histopathology images, delivering promising results for grading prostate cancer. However, most of the algorithms rely on the fully annotated datasets which are expensive to generate. In this work, we proposed a novel weakly-supervised algorithm to classify prostate cancer grades. The proposed algorithm consists of three steps: (1) extracting discriminative areas in a histopathology image by employing the Multiple Instance Learning (MIL) algorithm based on Transformers, (2) representing the image by constructing a graph using the discriminative patches, and (3) classifying the image into its Gleason grades by developing a Graph Convolutional Neural Network (GCN) based on the gated attention mechanism. We evaluated our algorithm using publicly available datasets, including TCGAPRAD, PANDA, and Gleason 2019 challenge datasets. We also cross validated the algorithm on an independent dataset. Results show that the proposed model achieved state-of-the-art performance in the Gleason grading task in terms of accuracy, F1 score, and cohen-kappa. The code is available at https://github.com/NabaviLab/Prostate-Cancer.
FLAIR: Federated Learning Annotated Image Repository
Jul 18, 2022
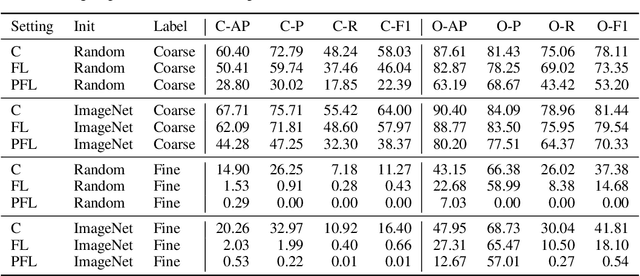
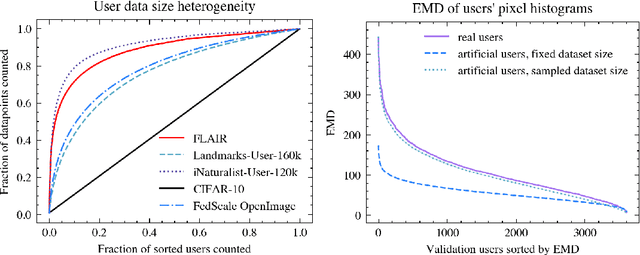
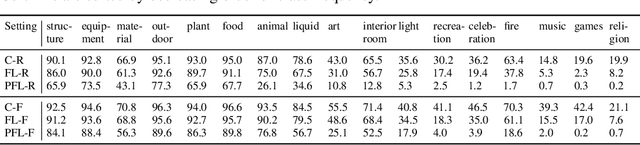
Cross-device federated learning is an emerging machine learning (ML) paradigm where a large population of devices collectively train an ML model while the data remains on the devices. This research field has a unique set of practical challenges, and to systematically make advances, new datasets curated to be compatible with this paradigm are needed. Existing federated learning benchmarks in the image domain do not accurately capture the scale and heterogeneity of many real-world use cases. We introduce FLAIR, a challenging large-scale annotated image dataset for multi-label classification suitable for federated learning. FLAIR has 429,078 images from 51,414 Flickr users and captures many of the intricacies typically encountered in federated learning, such as heterogeneous user data and a long-tailed label distribution. We implement multiple baselines in different learning setups for different tasks on this dataset. We believe FLAIR can serve as a challenging benchmark for advancing the state-of-the art in federated learning. Dataset access and the code for the benchmark are available at \url{https://github.com/apple/ml-flair}.
Evaluating the Possibility of Integrating Augmented Reality and Internet of Things Technologies to Help Patients with Alzheimer's Disease
Jan 20, 2023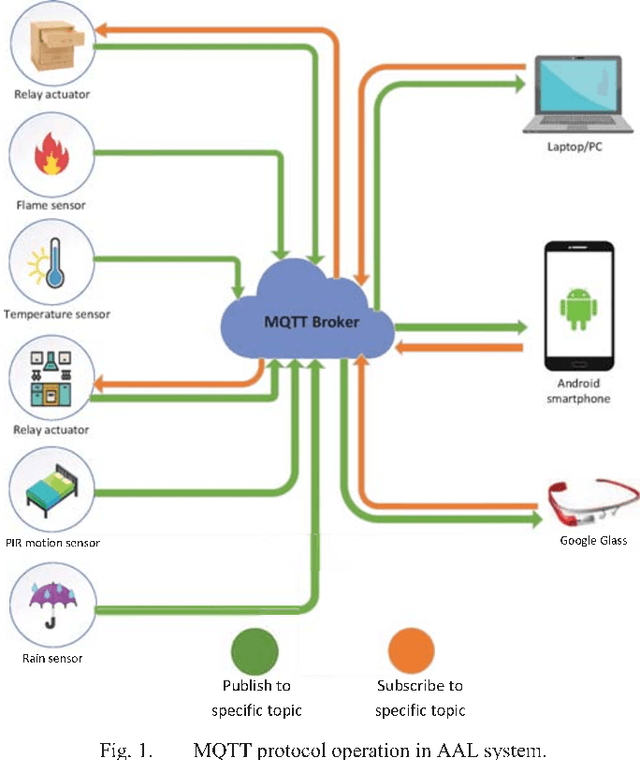
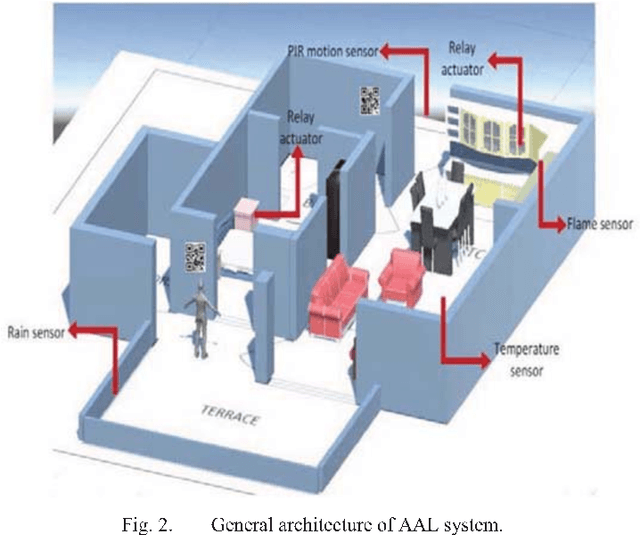
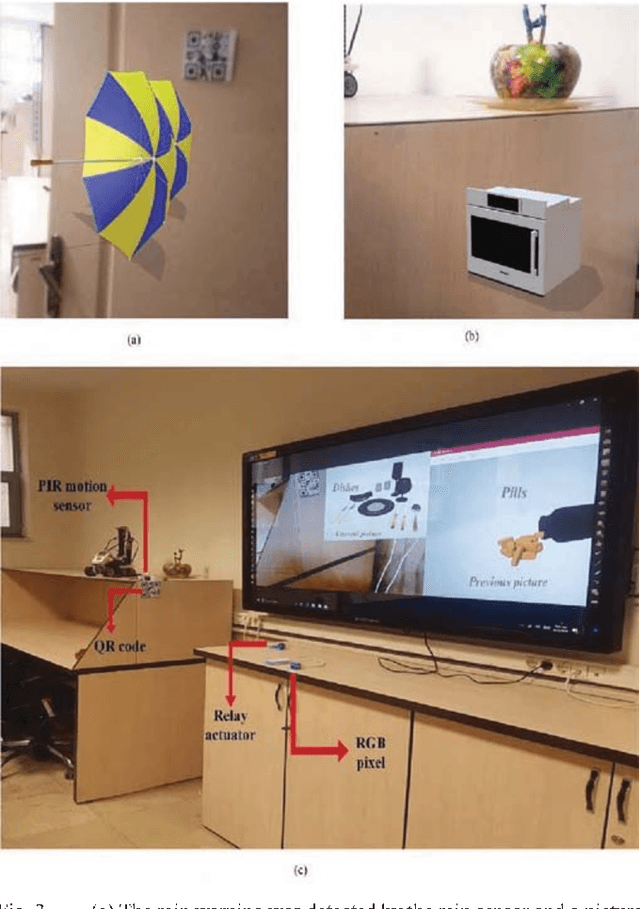
People suffering from Alzheimer's disease (AD) and their caregivers seek different approaches to cope with memory loss. Although AD patients want to live independently, they often need help from caregivers. In this situation, caregivers may attach notes on every single object or take out the contents of a drawer to make them visible before leaving the patient alone at home. This study reports preliminary results on an Ambient Assisted Living (AAL) real-time system, achieved through the Internet of Things (IoT) and Augmented Reality (AR) concepts, aimed at helping people suffering from AD. The system has two main sections: the smartphone or windows application allows caregivers to monitor patients' status at home and be notified if patients are at risk. The second part allows patients to use smart glasses to recognize QR codes in the environment and receive information related to tags in the form of audio, text, or three-dimensional image. This work presents preliminary results and investigates the possibility of implementing such a system.